
FACE MODEL FITTING WITH GENERIC, GROUP-SPECIFIC,
AND PERSON-SPECIFIC OBJECTIVE FUNCTIONS
Sylvia Pietzsch
1
, Matthias Wimmer
2
, Freek Stulp
3
and Bernd Radig
4
1
Chair for Image Understanding, Technische Universit
¨
at M
¨
unchen, Germany
2
Perceptual Computing Lab, Faculty of Science and Engineering, Waseda University, Tokyo, Japan
3
Chair for Image Understanding, Technische Universit
¨
at M
¨
unchen, Germany
4
Group of Cognitive Neuroinformatics, University of Bremen, Germany
Keywords:
Model fitting, person-specific, group-specific objective function.
Abstract:
In model-based fitting, the model parameters that best fit the image are determined by searching for the op-
timum of an objective function. Often, this function is designed manually, based on implicit and domain-
dependent knowledge. We acquire more robust objective function by learning them from annotated images, in
which many critical decisions are automated, and the remaining manual steps do not require domain knowl-
edge.
Still, the trade-off between generality and accuracy remains. General functions can be applied to a large
range of objects, whereas specific functions describe a subset of objects more accurately. (Gross et al., 2005)
have demonstrated this principle by comparing generic to person-specific Active Appearance Models. As it
is impossible to learn a person-specific objective function for the entire human population, we automatically
partition the training images and then learn partition-specific functions. The number of groups influences the
specificity of the learned functions. We automatically determine the optimal partitioning given the number of
groups, by minimizing the expected fitting error.
Our empirical evaluation demonstrates that the group-specific objective functions more accurately describe
the images of the corresponding group. The results of this paper are especially relevant to face model tracking,
as individual faces will not change throughout an image sequence.
1 INTRODUCTION
Model-based image interpretation has proven appro-
priate to extract high-level information from images.
Using a priori knowledge about the object of interest,
these methods reduce the large amount of image data
to a small number of model parameters, which facili-
tates and accelerates further interpretation. The model
parameters p describe its configuration, such as po-
sition, orientation, scaling, and deformation. Facial
expression interpretation, which is a major topic of
our research, is often implemented with model-based
techniques (Cohen et al., 2003; Tian et al., 2001; Pan-
tic and Rothkrantz, 2000).Usually, the parameters of a
deformable model describe the opening of the mouth,
the direction of the gaze, or the raising of the eye
brows, as depicted in Figure 1.
Model fitting is the computational challenge of
determining the model parameters that best match a
given image and this process usually consists of two
components: the objective function and the fitting al-
gorithm. The objective function evaluates how well
a model fits to an image. In this paper, lower val-
ues represent a better model fit. These functions are
usually designed manually by selecting salient image
features and by mathematically composing them, see
Figure 2 (left). Their appropriateness is then veri-
fied with test images. If the results are not satisfy-
ing, the objective function is tuned or redesigned from
Figure 1: In image sequences for recognizing facial expres-
sions changes between the images are small.
5
Pietzsch S., Wimmer M., Stulp F. and Radig B. (2008).
FACE MODEL FITTING WITH GENERIC, GROUP-SPECIFIC, AND PERSON-SPECIFIC OBJECTIVE FUNCTIONS.
In Proceedings of the Third International Conference on Computer Vision Theory and Applications, pages 5-12
DOI: 10.5220/0001087500050012
Copyright
c
SciTePress

Figure 2: The traditional procedure for designing objective functions (left), and the proposed method for learning objective
functions from annotated training images (right).
scratch. This approach is time-consuming and highly
depends on the designer’s intuition and his knowl-
edge of the application domain. The fitting algorithm
searches for the model parameters that constitute the
global minimum of the objective function.
Model tracking represents the very similar chal-
lenge, where the model is repeatedly fit to a sequence
of images. As changes from image to image are small,
fitting results of previous images in the sequence con-
stitute prior knowledge, which is often used to bias
the fitting process in subsequent images. In our ap-
proach, the stationarity assumption is that the appear-
ance of the face will not significantly change within
the image sequence, e.g. a bearded man will not sud-
denly lose his beard. Knowing that the visible person
has a beard, beard-specific model fitting increases fit-
ting accuracy and processing speed throughout the re-
mainder of the image sequence. In this paper, we pro-
pose to make the objective function the specific part
and use standard model fitting strategies, such as Gra-
dient Decent, CONDENSATION, Simulated Anneal-
ing, etc. We show how to learn generic and person-
specific objective functions. (Gross et al., 2005)
conduct a similar investigation comparing generic to
person-specific Active Appearance Models.
The contributions of this paper are threefold. First,
we demonstrate how to learn objective functions from
manually annotated training images in order to avoid
the shortcomings of the design approach. We auto-
mate many critical decisions, and the remaining man-
ual steps hardly require domain-dependent knowl-
edge, which simplifies the designer’s task and makes
it less error-prone. Second, we make the objective
functions specific to one person by restricting the set
of training images. This approach makes them highly
appropriate for tracking a model through a sequence
of images. We present an empirical evaluation that
shows that person-specific functions are, as expected,
more accurate than generic ones. Third, since these
functions cannot be learned for the entire human pop-
ulation in advance, we are partitioning the set of train-
ing images such that the persons within each partition
look similarly. Now, we learn partition-specific objec-
tive functions and we show the increase of accuracy,
again. Since these functions are learned in advance,
they have potential to improve face model fitting also
for previously unseen persons.
This paper elaborates on face model applications
but the insights presented are relevant for any other
model-based scenario as well.
The remainder of this paper is organized as fol-
lows: Section 2 describes how to learn objective
functions from annotated images. In Section 3, we
elaborate on learning person-specific objective func-
tions. Section 3 describes our approach to automat-
ically determine the optimal partitioning for learning
partition-specific objective functions. Section 4 com-
pares model fitting with the generic and specific func-
tions. Section 6 summarizes our approach and gives
an outlook to future work.
2 LEARNING GENERIC
OBJECTIVE FUNCTIONS
An objective function f (I, p) is either computed di-
rectly from the image I and the model parameters p
or as a sum of local objective functions f
n
(I, x), as
in Equation 1. These local functions consider the
image content in the vicinity of the model’s contour
point c
n
(p) only. They are easier to design than
global ones and therefore, this approach is widely
used in current model fitting research (Cristinacce and
Cootes, 2006; Romdhani, 2005; Hanek, 2004; Co-
hen et al., 2003). As their main advantage, their
low-dimensional search space x∈R
2
facilitates min-
imization. For a more elaborate discussion, we refer
to (Wimmer et al., 2007).
f (I, p) =
N
∑
n=1
f
n
(I, c
n
(p)) (1)
So-called ideal objective functions have two prop-
erties: First, their global minimum corresponds to the
best model fit. This implies that finding the global
minimum is sufficient for fitting the model. Second,
the objective function must have no local minimum
apart from the global minimum. This implies that any
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
6

minimum found corresponds to the global minimum,
which facilitates search. An example of an ideal local
objective function is shown in Equation 2, where the
preferred model parameters p
?
I
denote the best model
fit for a certain image I, according to human judg-
ment. Since p
?
I
is not known for unseen images, f
?
n
cannot be used in fitting applications. Instead, we take
this ideal objective function to generate training ex-
amples for learning a further objective function f
`
n
.
The key idea behind our approach is that the ideal
objective function f
?
n
is used to generate the training
data, from which f
`
n
is learned. Since f
?
n
has these two
properties of idealness, f
`
n
will approximately have
them as well. Figure 2 illustrates the five-step pro-
cedure of learning objective functions.
f
?
n
(I, x) = |x − c
n
(p
?
I
)| (2)
Different images contain faces of different sizes.
Distance measures, such as the return value of f
?
n
,
must not be biased by this variation. Therefore, we
convert all distances in pixels to the interocular mea-
sure by dividing them by the pupil-to-pupil distance.
Our methods are independent of the model. Here,
we use the Active Shape Model approach of Cootes
et al. (Cootes and Taylor, 1992) to model two-
dimensional human faces. The model parame-
ters p=(t
x
,t
y
,s, θ, b)
T
consist of translation, scaling,
rotation, and a vector of deformation parameters b.
The face model contains N=134 contour points that
are projected to the surface of the image by c
n
(p)
with 1≤n≤N, see Figure 1.
Step 1. Manually Annotate Images. A database
of images I
k
with 1≤k≤K is manually annotated with
the ideal model parameters p
?
I
k
. These parameters al-
low to compute the ideal objective function f
?
n
, see
Equation 2. For synthetic images, p
?
I
k
is known, and
can be used in such cases. For real-world images,
however, p
?
I
k
depends on the user’s judgment. An-
notating the images represents the only laborious step
of the proposed methodology. For our experiments,
we manually annotated 500 images, which takes an
experienced person around 1 minute per image.
Step 2. Generate Further Annotations. The ideal
objective function returns the minimum f
?
n
(I, x)=0
for all image annotations, because x=c
n
(p
?
I
). This
data is not sufficient to learn the characteristics
of f
`
n
. Therefore, we will acquire image annota-
tions x6=c
n
(p
?
I
), for which f
?
n
(I, x)6=0. In general, any
position within the image may represent one of these
annotations. However, it is more practicable to re-
strict this motion in terms of distance and direction,
as is done in (Ginneken et al., 2002)
Figure 3: In each of the K images, each of the N contour
points is annotated with 2D+1 displacements. Manual an-
notation is only necessary for d=0 (middle row). The other
displacements are computed automatically. The upper right
image shows the learning radius ∆. The unit of the ideal
objective function values and ∆ is the interocular measure.
Therefore, we generate a number of dis-
placements x
k,n,d
with −D≤d≤D that are lo-
cated on the perpendicular to the contour line
with a maximum distance ∆ to the contour
point. This procedure is illustrated in Figure 3.
The center row depicts the manually annotated
images, for which f
?
n
(I, x
k,n,0
)= f
?
n
(I, c
n
(p
?
I
k
))=0.
The other rows depict the displacements x
k,n,d6=0
with f
?
n
(I, x
k,n,d6=0
)>0.
Step 3. Specify Image Features. We learn a map-
ping from I
k
and x
k,n,d
to f
?
n
(I
k
, x
k,n,d
), which is
called f
`
n
. Since f
`
n
has no access to p
?
I
, it must com-
pute its value from the image content. However, we
do not directly evaluate the pixel values but apply a
feature-extraction method, see (Hanek, 2004). The
idea is to provide a multitude of features, and let the
learning algorithm choose which of them are relevant
to the calculation rules of the objective function.
Our approach takes Haar-like image features (Vi-
ola and Jones, 2001) of different styles and sizes,
which greatly cope with noisy images. They are not
only computed at the location of the contour point it-
FACE MODEL FITTING WITH GENERIC, GROUP-SPECIFIC, AND PERSON-SPECIFIC OBJECTIVE FUNCTIONS
7

Figure 4: A set of A=6·3·5·5=450 features is used for learn-
ing the objective function.
self, but also at several locations within its vicinity,
see Figure 4. This variety of 1≤a≤A image features
enables the objective function to exploit the texture of
the image at the model’s contour point and in its sur-
rounding area. Each of these features returns a scalar
value, which we denote with h
a
(I, x).
Step 4. Generate Training Data. The result of the
manual annotation step (Step 1) and the automated
annotation step (Step 2) is a list of K(2D + 1) im-
age locations x
k,n,d
for each of the N contour points.
Adding the corresponding target value f
?
n
yields the
list in Equation 3.
[ I
k
, x
k,n,d
, f
?
n
(I
k
,x
k,n,d
) ] (3)
[ h
1
(I
k
,x
k,n,d
),. . . ,h
A
(I
k
,x
k,n,d
), f
?
n
(I
k
,x
k,n,d
) ] (4)
with 1≤k≤K, 1≤n≤N, −D≤d≤D
Applying each feature to Equation 3 yields the train-
ing data in Equation 4. This step simplifies matters
greatly. We have reduced the problem of mapping
high-dimensional image data and pixel locations to
the target value f
?
n
(I, x), to mapping a list of feature
values to the target value.
Step 5. Learn Calculation Rules. The local objec-
tive function f
`
n
maps the feature values to the result
value of f
?
n
. Machine learning infers this mapping
from the training data in Equation 4. Our proof-of-
concept uses model trees (Witten and Frank, 2005;
Quinlan, 1993) for this task, which are a generaliza-
tion of decision trees. Whereas decision trees have
nominal values at their leaf nodes, model trees have
line segments, allowing them to map features to a
continuous value, such as the value returned by f
?
n
.
These trees are learned by recursively partitioning the
feature space. A linear function is then fitted to the
training data in each partition using linear regression.
One of the advantages of model trees is that they tend
to use only features that are relevant to predict the tar-
get values. Currently, we are providing A=450 im-
age features, see Figure 4. The model tree selects
around 20 of them for learning the calculation rules.
After these five steps, a local objective function is
learned for each contour point. It can now be evalu-
ated at an arbitrary pixel x of an arbitrary image I.
3 LEARNING SPECIFIC
OBJECTIVE FUNCTIONS
Without having any specific knowledge about the
given image, generic objective functions as presented
in Section 2 are able to provide an acceptable model
fit. This is a considerable challenge, because there is
an immense variation between the images, e.g. due to
gender, hair style, etc. The training images must con-
tain a high range of these conditions in order to yield
robust objective functions. In contrast, the image con-
tent between two consecutive frames does not greatly
change in image sequences. The model must be fitted
to each single image within the sequence, but the im-
age content is not arbitrary, because many image and
model descriptors are fixed or only change gradually,
such as illumination, background, or camera settings.
In the case of facial expression recognition, it can
be assumed, that the identity of the person is fixed.
Therefore, the appearance of the face only changes
slightly from frame to frame. For model fitting, it is
sufficient to apply an objective function that is spe-
cific to this person. As the advantage of this approach,
person-specific objective functions are much more ac-
curate than generic ones. Table 1 summarizes and
compares the properties and capabilities of generic
and person-specific objective functions. Note that the
learned function is highly accurate for images of the
specific person, but it yields arbitrary and potentially
bad results for images of different persons.
In this paper, we obtain person-specific objective
functions by slightly altering Step 1 of the machine
learning methodology explained in Section 2. The
here utilized image database does not consist of ar-
bitrary face images any more, but face images of
one specific person. Nevertheless, it is important
that these images still contain a considerable variation
w.r.t. further image conditions, such as illumination,
background, and facial pose. Section 4 demonstrates
the increase of fitting accuracy comparing generic and
person-specific objective functions.
3.1 Optimal Partitioning
Unfortunately, it is not possible to learn person-
specific objective functions for each individual of the
entire human population. Therefore, we acquire im-
ages of R persons and we propose to learn objective
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
8

Table 1: Comparing the properties and capabilities of generic and person-specific objective functions.
generic objective function person-specific objective function
uses knowledge about person no yes
appropriate for single image image sequence
learned with images of different persons images of a single person
accuracy any person: moderate accuracy specific person: very high
other persons: undefined, rather low
effort for learning learned once learned for every person separately
number of partitions G G = 1 G = R
functions for groups of people, comprising similari-
ties, e.g. gender, age, beard, hair style. Dividing the
set of persons into G partitions, the number of parti-
tionings possible is described by the Stirling numbers
of the Second Kind S(R, G), see Equation 5.
S(R, G) =
1
G!
G
∑
i=0
(−1)
i
(
G
i
)(G − i)
R
(5)
Setting G=1 or G=R, there is only one parti-
tioning, because S(R,1) = 1 and S(R, R) = 1 respec-
tively. In the case of G=1, one partition contains
all persons. The partition-specific objective function
is equivalent to a generic objective function. In the
case of G=R, each partition contains images of one
person only. The partition-specific objective func-
tion is equivalent to a person-specific objective func-
tion. Setting 1<G<R, the level of specificity of the
partition-specific objective functions is between the
generic and the person-specific objective function.
Higher values of G lead to more specific and accu-
rate, but to less general objective functions. Note that
in this case, there are several partitionings, because
S(R, G) > 1.
foreach partition in partitions do1
foreach image in partition do2
Perform model fitting by applying the3
correct partition-specific objective function
(e.g. f
(AB)
for images with persons A and B)
Determine the fitting error on image by4
considering the manual annotations
end5
Compute mean error over all images in partition6
end7
Compute λ, the mean error over all partitions8
Algorithm 1: Computing the error measure λ.
Accurate partition-specific objective functions
cannot be learned for every partition. Therefore, the
feasability of this method depends on the number of
partitions G and the partitions created. We compute
an error measure λ for each partitioning, see Algo-
rithm 1. The optimal partitioning is minimizes λ.
The challenge is to determine the partitioning with
the minimum error. It is obtained by exhaustive search
for small values of G only. Determining the best parti-
tioning is performed off-line, but it is computationally
expensive, especially when R and G are large.
In order to integrate partition-specific objective
functions into real-world applications, the correct par-
tition of a persons must be determined on-line. This
allows the execution of the correct partition-specific
objective function. Selecting the wrong function leads
to a much lower accuracy than selecting the generic
objective function. In order to determine the cor-
rect partition-specific objective function, we are using
state-of-the-art person identification, see (Nefian and
Hayes, 1999).
4 EXPERIMENTAL EVALUATION
This paper proposes to adapt the objective function to
particular persons or groups of persons in order to fa-
cilitate model tracking. In this section, we inspect the
increase of accuracy that is achieved with these spe-
cific objective functions. Furthermore, we evaluate
the applicability of the partitioning method proposed
in Section 3. All tests are performed using a two-
dimensional, deformable, contour model of a human
face that is build according to the Active Shape Model
approach (Cootes and Taylor, 2004).
Evaluation Data. The experiments require a data
base of several images of various persons. In order
to learn a generic objective function the training set
needs to contain a representative variation of human
faces. We extract an image sequence for R = 45 dif-
ferent persons from news broadcasts on TV. They
comprise of news anchormen and politicians as well
as passers-by giving short interviews. The image se-
quences cover a large variation of environmental as-
pects as well as faces with different properties, such as
beards, glasses, gender. Within the image sequences,
FACE MODEL FITTING WITH GENERIC, GROUP-SPECIFIC, AND PERSON-SPECIFIC OBJECTIVE FUNCTIONS
9

Figure 5: Point-to-boundary error for model fitting using a generic (gray) and person-specific objective functions (black).
persons move their head and show facial muscle ac-
tivity. We annotate ten images of each person with the
ideal model parameters, which amounts to 450 anno-
tated images and split this set up into training (70%)
and test images (30%).
Generic vs. Person-specific Objective Functions.
According to the description in Section 2, a generic
objective function f
`
is learned from the annotated
images of all R persons. Furthermore, we create
R person-specific objective functions f
r
with 1≤r≤R.
Our evaluation fits the face model to all test images
of each person using either objective function. Ac-
curacy of fitting is quantified as the average point-to-
boundary error, which is the minimum distance be-
tween the contour points c
n
(p) and the contour line
of the manually annotated model p
?
I
. This distance
is converted to the interocular measure. Figure 5
illustrates these values for the generic and person-
specific objective functions of all persons. The x-axis
denotes the person’s ID and the y-axis indicates the
mean point-to-boundary error. It is clearly visible that
learning objective functions for a specific person im-
proves the process of fitting the face model to the im-
ages that show this person. Also, Table 2 illustrates
the same evaluation for three example persons P26,
P26 P42 P44
Figure 6: An example image of each of the three persons
used for learning partition-specific objective functions.
P42, and P44. As expected, the fitting error is very
low for images of the person the objective function is
specific to.
Partition-specific Objective Functions. The previ-
ous experiment investigates the increase of accuracy
comparing person-specific objective functions over
generic ones. But as described in Section 3, this can-
not be used beneficially in real-world applications and
we propose a further method that partitions the set of
persons within the training images. In the remain-
der of this section, we verify two issues concerning
partition-specific objective functions: First, the feasi-
bility of the partitioning is shown by means of a se-
lective example. Second, the gain in accuracy holds
for partition-specific objective functions as well.
This experiment considers a rather simple case,
but it proves our statement that a decent partitioning
does affect the fitting accuracy. We extract R = 3 per-
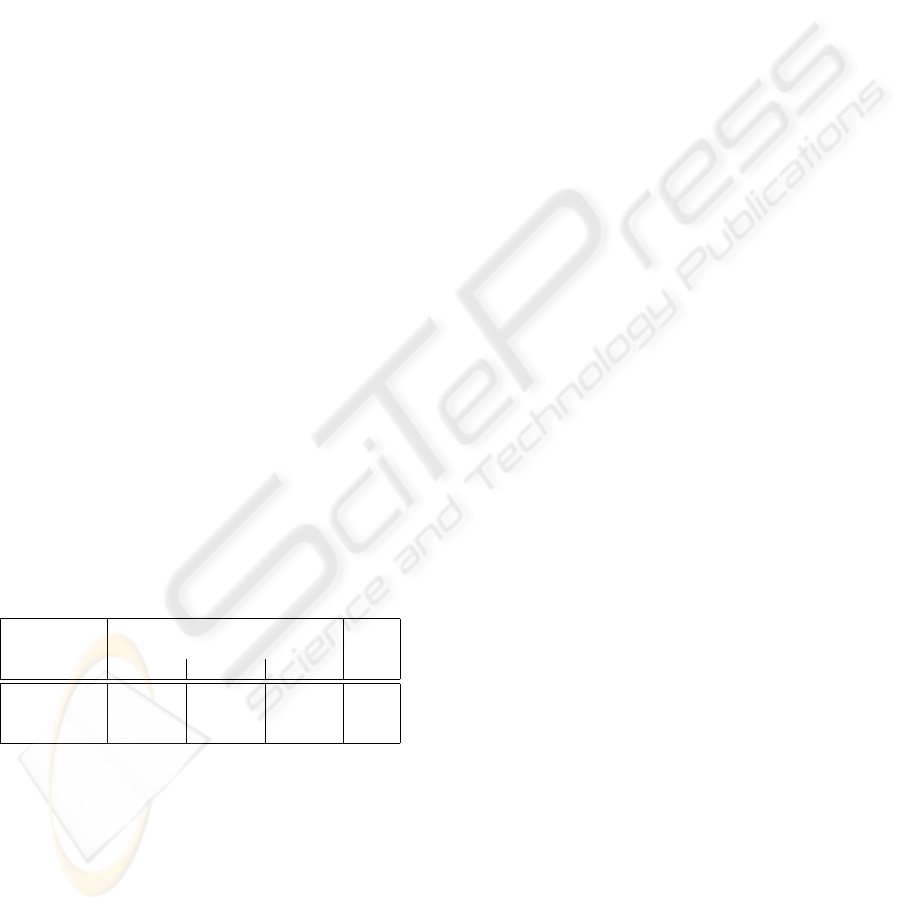
Table 2: Point-to-boundary error after model fitting. This
error is small for objective functions specific to a certain
person or partition (bold numbers).
objective function evaluated on
P26 P42 P44
generic:
f
`
7.7 7.9 9.9
person-specific:
f
26
4.0 17.0 19.0
f
42
15.6 3.9 9.8
f
44
13.6 11.5 3.2
partition-specific:
f
(26,42)
4.8 4.4 12.7
f
(42,44)
16.1 4.1 3.7
f
(26,44)
4.6 13.3 4.1
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
10
sons from our image data base, see Figure 6, and we
will refer to them as P26, P42, and P44. The set
was chosen consciously to contain two persons that
look similar (P42 and P44) and one person that dif-
fers in the outward appearance. Setting G=2 parti-
tions, we then create all S(3, 2)=3 partitionings and
learn a specific objective function f
(r
1
,...)
for each
partition. Note that a partition containing only one
person yields an objective function that is equivalent
to the person-specific objective function of this per-
son (e.g. f
26
≡ f
(26)
).
For evaluation, we fit the model to the test images
of these three persons using the pertition-specific ob-
jective functions created. Again, the accuracy is rep-
resented by the average point-to-boundary error w.r.t
the ideal model parameterization p
?
I
. Table 2 illus-
trates the fitting results applying the partition-specific
objective functions created. In all cases, the partition-
specific objective function achieves high accuracies
for the partition members.
Different Partitionings. One of the major points
of using partition-specific objective functions is how
many partitions to create and to which partitions the
persons belong to. Algorithm 1 shows how to cal-
culate an error measure λ that indicates how good
a certain partitioning is. Here, we calculate this er-
ror measure for the three partitionings of the previous
experiment, as depicted in Table 3. The partitioning
(P42,P44)(P26) turns out to be best, because it has
minimum λ = 3.9. As expected, our approach clus-
ters the two persons that look similar into one parti-
tion and the other person into the other partition.
Table 3: Compare the all partitionings of R = 3 persons into
G = 2 partitions by means of the average fitting error λ.
partitioning fitting error with correct λ
objective function
P26 P42 P44
(26)(42,44) 4.0 4.1 3.7 3.9
(42)(26,44) 4.6 3.9 4.1 4.2
(44)(26,42) 4.8 4.4 3.2 4.1
5 DISCUSSION
Learning objective functions instead of designing
them manually has several benefits both for the ob-
jective function and for the designer. First of all, it
automates design decisions which are critical to the
robustness of the resulting objective function. The
two critical decisions within the designing process are
feature selection and their mathematical composition.
In our approach, the model tree algorithm automates
both, as it tends to use only relevant features, and per-
forms a piecewise linear approximation of the target
function with these features. The selection of features
is based on objective information theoretic measures,
which model trees use to partition the space of the im-
age features, instead of relying on human intuition. A
human can only reason about a very limited amount
of features, whereas model trees are able to consider
(and discard) hundreds of features simultaneously.
The resulting objective functions are therefore more
accurate and robust, and easier to optimize. Each lo-
cal objective function f
`
n
(I, x) uses its own calculation
rules and image feature set, because a separate model
tree is learned for each contour point. Customizing
the calculation rules for each local objective func-
tion would also be possible when designing objective
functions. However, this is usually not exploited, be-
cause it is too laborious and time-consuming.
There are cases in which model fitting with
learned objective functions fails to match the face
model to the image appropriately. The objective func-
tion is only capable of computing an accurate value
for locations that are in a certain vicinity of the correct
contour point determined by the learning radius ∆.
Beyond this radius, the result of the objective function
is undefined, because this image content has not been
used for learning. In-plane rotations of the face must
not be too high, because Haar-like features are not ro-
tation invariant. Other researchers have also faced this
issue, and (Jones and Viola, 2003) propose a solution
to this shortcoming. Alternatively, integrating rota-
tion invariant features suffices as well.
Designing objective functions requires extensive
domain-dependent knowledge about model fitting and
feature extraction methods. In our approach, the main
remaining manual step is the annotation of images
with the best model fit. This annotation is intuitive,
and can be performed with little domain-dependent
knowledge. The features provided and learning al-
gorithms used are not specific for the application do-
main. Objective functions can therefore be tailored to
different domains simply by using a different model
and a different set of images annotated with this
model.
6 SUMMARY AND OUTLOOK
Due to the large variations in facial appearances in im-
ages, it is challenging to find a general model fitting
procedure that fits all faces robustly and accurately. In
this paper, we compare specific with generic objective
functions, one of the three main components in model
FACE MODEL FITTING WITH GENERIC, GROUP-SPECIFIC, AND PERSON-SPECIFIC OBJECTIVE FUNCTIONS
11

based fitting. These objective functions are learned
from annotated images. Generic and person-specific
objective functions are learned by training them with
all or only images with a specific person in them re-
spectively. In practice, it is infeasible to learn objec-
tive function for each person individually. We there-
fore extend the person-specific approach by first au-
tomatically partitioning the set of images into similar
partitions before learning, and then learning partition-
specific objective functions.
The main application of partition-specific objec-
tive functions, is tracking models through image se-
quences. Although the appearance of a face might
change during an image sequence due to lighting etc.,
the face itself does not. Therefore, once the partition
a face belongs to is established, a partition-specific
objective function can be used throughout the image
sequence.
The empirical evaluation first shows how person-
specific objective functions achieve a substantial
higher fitting accuracy for the person for which it was
trained. We then show the result of applying differ-
ent partition-specific objective functions on images in
and outside of the partition. As expected, partition-
specific objective function perform substantially bet-
ter than generic ones for persons from the partition for
which they were trained, but worse on persons not in
this partition. Higher accuracy comes at the cost of
lower generality. This trade-off is influenced by the
number of intended partitions G.
The off-line partitioning for learning partition-
specific objective functions is performed automati-
cally. We are currently investigating the use of an au-
tomatic classification to determine on-line, to which
partition a person belongs, and which objective func-
tion should be used.
ACKNOWLEDGEMENTS
This research is partially funded by a JSPS Post-
doctoral Fellowship for North American and Euro-
pean Researchers (FY2007) as well as by the German
Research Foundation (DFG) as part of the Transre-
gional Collaborative Research Center SFB/TR 8 Spa-
tial Cognition.
It has been jointly conducted by the Perceptual
Computing Lab of Prof. Tetsunori Kobayashi at
Waseda University, the Chair for Image Under-
standing at the Technische Universit
¨
at M
¨
unchen,
and the Group of Cognitive Neuroinformatics at the
University of Bremen.
REFERENCES
Chibelushi, C. C. and Bourel, F. (2003). Facial expression
recognition: A brief tutorial overview.
Cohen, I., Sebe, N., Chen, L., Garg, A., and Huang, T.
(2003). Facial expression recognition from video se-
quences: Temporal and static modeling. CVIU special
issue on face recognition, 91(1-2):160–187.
Cootes, T. F. and Taylor, C. J. (1992). Active shape models
– smart snakes. In BMVC, pp 266 – 275.
Cootes, T. F. and Taylor, C. J. (2004). Statistical models of
appearance for computer vision. Technical report, U
of Manchester, Imaging Science and Biomedical En-
gineering, Manchester M13 9PT, UK.
Cristinacce, D. and Cootes, T. F. (2006). Facial feature
detection and tracking with automatic template selec-
tion. In FGR, pp 429–434.
Ginneken, B., Frangi, A., Staal, J., Haar, B., and Viergever,
R. (2002). Active shape model segmentation with op-
timal features. IEEE Transactions on Medical Imag-
ing, 21(8):924–933.
Gross, R., Baker, S., Matthews, I., and Kanade, T. (2004).
Face recognition across pose and illumination. In
Li, S. Z. and Jain, A. K., editors, Handbook of Face
Recognition. Springer-Verlag.
Gross, R., Matthews, I., and Baker, S. (2005). Generic vs.
person specific active appearance models. Image and
Vision Computing, 23(11):1080–1093.
Hanek, R. (2004). Fitting Parametric Curve Models to Im-
ages Using Local Self-adapting Seperation Criteria.
PhD thesis, Dept of Informatics, TU M
¨
unchen.
Jones, M. J. and Viola, P. (2003). Fast multi-view face
detection. Technical Report TR2003-96, Mitsubishi
Electric Research Lab.
Nefian, A. and Hayes, M. (1999). Face recognition using an
embedded HMM. In Proc. of the IEEE Conference on
Audio and Video-based Biometric Person Authentica-
tion, pp 19–24.
Pantic, M. and Rothkrantz, L. J. M. (2000). Automatic anal-
ysis of facial expressions: The state of the art. IEEE
TPAMI, 22(12):1424–1445.
Quinlan, R. (1993). C4.5: Programs for Machine Learning.
Morgan Kaufmann, San Mateo, California.
Romdhani, S. (2005). Face Image Analysis using a Multi-
ple Feature Fitting Strategy. PhD thesis, U of Basel,
Computer Science Department, Basel, CH.
Tian, Y.-L., Kanade, T., and Cohn, J. F. (2001). Recogniz-
ing action units for facial expression analysis. IEEE
TPAMI, 23(2):97–115.
Viola, P. and Jones, M. (2001). Rapid object detection using
a boosted cascade of simple features. In CVPR, vol 1,
pp 511–518, Kauai, Hawaii.
Wimmer, M., Stulp, F., Pietzsch, S., and Radig, B. (2007).
Learning local objective functions for robust face
model fitting. In IEEE PAMI. to appear.
Witten, I. H. and Frank, E. (2005). Data Mining: Practi-
cal machine learning tools and techniques. Morgan
Kaufmann, San Francisco, 2
nd
edition.
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
12
