
A NEW MULTIPLE CLASSIFIER SYSTEM FOR SEMI-SUPERVISED
ANALYSIS OF HYPERSPECTRAL IMAGES
Jun Li
1
, Prashanth Reddy Marpu
2
, Antonio Plaza
1
, Jose Manuel Bioucas Dias
3
and Jon Atli Benediktsson
2
1
Hyperspectral Computing Laboratory, University of Extremadura, Avda. de la Universidad s/n, 10003 Caceres, Spain
2
Faculty of Electrical and Computer Engineering, University of Iceland, 101 Reykjavik, Iceland
3
Instituto de Telecomunicac¸˜oes, Instituto Superior T´ecnico, Av. Rovisco Pais, 1049-001 Lisbon, Portugal
Keywords:
Multiple classifier system, Remotely sensed hyperspectral images, Semi-supervised learning.
Abstract:
In this work, we propose a new semi-supervised algorithm for remotely sensed hyperspectral image classi-
fication which belongs to the family of multiple classifier systems. The proposed approach combines the
output of two well-established discriminative classifiers: sparse multinomial logistic regression (SMLR) and
quadratic discriminant analysis (QDA). Our approach follows a two-step strategy. First, both SMLR and QDA
are trained from the same set of labeled training samples and make predictions for the unlabeled samples in
the image. Second, the set of unlabeled training samples is expanded by combining the estimates obtained by
both classifiers in the previous step. The effectiveness of the proposed method is evaluated via experiments
with a widely used hyperspectral image, collected by the Airborne Visible Infra-Red Imaging Spectrometer
(AVIRIS) over the Indian Pines region in Indiana. Our results indicate that the proposed multiple classifier
method provides state-of-the-art performance when compared to other methods.
1 INTRODUCTION
The recent availability of remotely sensed hyper-
spectral images in different application domains has
fostered the development of techniques able to in-
terpret this kind of high-dimensional data in many
different contexts (Landgrebe, 2003). Specifically,
many techniques for hyperspectral image classifica-
tion have been proposed in recent years, with the ulti-
mate goal of taking advantageof the detailed informa-
tion contained in hyperspectral pixel vectors (spectral
signatures) to generate thematic maps (Plaza et al.,
2009). A relevant challenge for supervised classifi-
cation techniques (which assume prior knowledge in
the form of class labels for some spectral signatures)
is the limited size of training sets, since their collec-
tion generally involves expensive ground campaigns.
As a result, there is an unbalance between the number
of available training samples and the high dimension-
ality of the hyperspectral data, which potentially re-
sults in the Hughes phenomenon (Landgrebe, 2003).
The development of techniques intended to address
this phenomenon constitutes a very active area of re-
search in hyperspectral image classification (Camps-
Valls and Bruzzone, 2005; Fauvel et al., 2008).
While the collection of labeled samples is gen-
erally difficult, expensive and time-consuming, un-
labeled samples can be generated in a much easier
way. This observation fostered the idea of semi-
supervised learning (Zhu, 2005), which has recently
become a very active area of research in hyperspectral
image classification (Camps-Valls et al., 2006; Tuia
and Camps-Valls, 2009; Camps-Valls et al., 2007; Li
et al., 2009; Velasco-Forero and Manian, 2009; Li
et al., 010c; Li et al., 010a). The main assumption of
these techniques is that new (unlabeled) training sam-
ples can be obtained from the (limited) set of avail-
able labeled samples without significant effort/cost,
and without the need to design a ground campaign
(Krishnapuram et al., 2004). Most available semi-
supervised learning algorithms use some type of reg-
ularization which encourages that “similar” features
belong to the same class. The effect of this regular-
ization is to push the boundaries between classes to-
wards regions with low data density (Chapelle et al.,
2006), where a rather usual way of building such reg-
ularizers is to associate the vertices of a graph with the
complete set of samples and then build the regularizer
depending on the variables defined on such vertices.
406
Li J., Reddy Marpu P., Plaza A., Manuel Bioucas Dias J. and Atli Benediktsson J..
A NEW MULTIPLE CLASSIFIER SYSTEM FOR SEMI-SUPERVISED ANALYSIS OF HYPERSPECTRAL IMAGES.
DOI: 10.5220/0003849504060411
In Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods (PRARSHIA-2012), pages 406-411
ISBN: 978-989-8425-98-0
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

Although a good performance can in general be ex-
pected from these methods, difficulties arise from the
viewpoint of the complexity of the model and its high
computational cost, which call for new developments
in this area.
In this paper, we present a new multiple classi-
fier system (Xu et al., 1992; Kittler and Roli, 2000)
intended to specifically cope with the limited avail-
ability of training samples. The proposed semi-
supervised algorithm is based on two discrimina-
tive classifiers: sparse multinomial logistic regression
(SMLR) (Krishnapuram et al., 2005) and quadratic
discriminant analysis (QDA) (Duda et al., 200). Ow-
ing to their rather different structures, these two clas-
sifiers exhibit complementary discriminatory capabil-
ities, a necessary condition for the success of any
multiple classifier system. In this work, we adopt
a decision-directed semi-supervision strategy (Roli,
2005). First, SMLR and QDA are trained using la-
beled samples. Second, a set of unlabeled training
samples is created and expanded by taking advantage
of the estimates obtained in the previous step. Specif-
ically, we implement a simple strategy to enlarge the
available training set; our assumption is that, if both
classifiers obtain the same estimate of the class la-
bel for a given pixel, then this sample is included
into the set of unlabeled samples and the procedure
is repeated again, thus growing the unlabeled train-
ing set without significant effort. The effectiveness
of the proposed method is evaluated via experiments
with a well-known hyperspectral image collected by
the Airborne Visible Infra-Red Imaging Spectrometer
(AVIRIS) (Green et al., 1998) over the Indian Pines
region in Indiana.
The remainder of the paper is organized as fol-
lows. Section 2 introduces the two considered dis-
criminative classifiers. Section 3 presents the pro-
posed multiple classifier system for semi-supervised
learning based on the aforementioned classifiers. Sec-
tion 4 reports classification results on the considered
AVIRIS hyperspectral data set. Section 5 concludes
with some remarks and future lines.
2 BASE CLASSIFIERS
First, we briefly define the mathematical nota-
tions adopted hereinafter. Let K ≡ {1,... ,K} de-
note a set of K class labels, S ≡ {1,. ..,n} a
set of integers indexing the n pixels of an im-
age, x ≡ (x
1
,. .. ,x
n
) an image of d-dimensional fea-
ture vectors, y ≡ (y
1
,. .. ,y
n
) an image of labels,
D
L
≡ {(y
1
,x
1
),. ..,(y
L
,x
L
)} a set of labeled sam-
ples, Y
L
≡ {y
1
,. .. ,y
L
} the set of labels in D
L
, X
L
≡
{x
1
,. .. ,x
L
} the set of feature vectors in D
L
, D
∗
U
≡
{(y
∗
L+1
,x
L+1
),. ..,(y
∗
L+U
,x
L+U
)} a set of pairs made
up of unlabeled feature vectors and pseudo-labels ob-
tained from the base classifiers, as described below.
Next, we revisit the SMLR (Krishnapuram et al.,
2005) and QDA classifiers with the objective of de-
veloping a new multiple classifier system.
2.1 Sparse Multinomial Logistic
Regression (SMLR)
The multinomial logistic regression (MLR) (B¨ohning,
1992) models the posterior class probabilities as
p(y
i
= k|x
i
,ω) ≡
exp(ω
(k)
h(x
i
))
∑
K
k=1
exp(ω
(k)
h(x
i
))
, (1)
where h(x
i
) ≡ [h
1
(x
i
),..., h
l
(x
i
)]
T
is a vector of l fixed
functions of the input, often termed features; ω de-
notes the regressors and ω ≡ [ω
(1)
T
,..., ω
(K−1)
T
]
T
.
Since the density (1) does not depend on transla-
tions on the regressors ω
(k)
, in this work we have
ω
(K)
= 0. It should be noted that the function h
may be linear (i.e., h(x
i
) = [1, x
i,1
,..., x
i,d
]
T
, where
x
i, j
is the j-th component of x
i
) or nonlinear. A
kernel is some symmetric function which offers a
mechanism to deal with the nonlinear case, i.e.,
h(x
i
) = [1, K
x,x
1
,..., K
x,x
l
]
T
, where K
x
i
,x
j
= K(x
i
,x
j
)
and K(·,·). Kernels have been largely used in this
context since they tend to improve data separability in
a transformed space. In this work, we use the Gaus-
sian Radial Basis Function (RBF) kernel: K(x,z) ≡
−exp(kx− zk
2
/(2σ
2
)), which has been widely used
in hyperspectral image classification (Camps-Valls
and Bruzzone, 2005). In order to control the ma-
chine complexity and, thus, its generalization capac-
ity, the SMLR algorithm introduced in (Krishnapuram
et al., 2005) models ω as a random vector with Lapla-
cian density and computes its maximum a posteriori
(MAP) estimate.
If the features are given by kernels, then the origi-
nal SMLR algorithm is limited to data sets with prod-
ucts L×K not larger than, say, 1000. Therefore, most
hyperspectral data sets are beyond the reach of this
algorithm. This difficulty was removed by the intro-
duction of the LORSAL algorithm (Bioucas-Dias and
Figueiredo, 2009), which is able to deal with training
set sizes in the order of a few thousands, regardless of
the number of classes. LORSAL plays a central role,
for example, in (Li et al., 010c; Li et al., 010b).
A NEW MULTIPLE CLASSIFIER SYSTEM FOR SEMI-SUPERVISED ANALYSIS OF HYPERSPECTRAL IMAGES
407

2.2 Quadratic Discriminant Analysis
(QDA)
QDA has been widely used in pattern recognition ap-
plications (Bishop, 2007). The concept can be simply
explained as follows. Let µ
(k)
and σ
(k)
be the mean
vector and covariance matrix of a given class k, then
the decision function for the QDA classifier is given
by:
log p(y
i
= k|x
i
,µ
(k)
,σ
(k)
) ≡
−
1
2
(x
i
− µ
(k)
)
T
(σ
(k)
)
−1
(x
i
− µ
(k)
)
−
1
2
log|σ
(k)
| + log p(y
i
= k) +C,
(2)
where p(y
i
= k) is the prior probability of class k, and
C is an additive constant.
3 MULTIPLE CLASSIFIER
SYSTEM
In this section, we present a new multiple classi-
fier system which exploits unlabeled training samples
generated using both SMLR and QDA classifiers. In
our setup, we run the classifiers in iterative fashion.
First, SMLR and QDA are trained by using the same
set of labeled samples. Second, we form and increase
a set of unlabeled samples by fusing the results ob-
tained (in consensus) by both classifiers. This proce-
dure has similarities with active data selection (Krish-
napuram et al., 2004; Mackay, 1992), in which un-
labeled samples are sequentially selected according
to a given criterion. In the proposed approach, we
actively increase the unlabeled training set based on
fusing the results which are obtained in agreement by
both SMLR and QDA.
Let D
L+U
≡ {D
L
,D
∗
U
} be a joint training set made
up of labeled and unlabeled samples. Similarly, let
S
U
be the set of unlabeled image pixels, and let
b
y
SMLR
and
b
y
QDA
be the classification results obtained by the
SMLR and QDA classifiers, respectively. The basic
strategy of the proposed method can be simply de-
scribed as follows. For any given pixel {x
i
, i ∈ S
U
},
if both SMLR and QDA obtain the same class label
k, i.e., by
i
SMLR
= by
i
QDA
= k, then we increment the un-
labeled set D
U
by assigning k to y
i
, i.e., y
i
= k, and
D
∗
U
≡ {D
∗
U
, (x
i
,y
i
)}.
A pseudo-code for the proposed semi-supervised
algorithm is shown in Algorithm 1, where u denotes
the number of unlabeled samples selected in each it-
eration and stopping criterion denotes the criterion
used to terminate the semi-supervised algorithm, e.g,
a maximum number of unlabeled samples. Line 2
combines the labeled and unlabeled samples as a joint
training set. Lines 3 and 4 compute the classifi-
cation estimates using the SMLR and QDA classi-
fiers, respectively. In line 5, function F (·) selects u
unlabeled samples from the unlabeled set S
U
based
on the classification results obtained by the SMLR
and QDA, according to the proposed semi-supervised
strategy. Let U
all
denote the number of samples in
which a consensus was achieved by both classifiers,
i.e., U
all
=
∑
(
b
y
SMLR
=
b
y
QDA
). In general, at each itera-
tion the size of U
all
is quite large. In this work, other
than using all of the available U
all
unlabeled samples,
we resort to an iterative scheme mainly due to two
reasons: (i) computational complexity: the cost of
the learning stage is related to the number of train-
ing samples), and (ii) balance: there is no parame-
ter intended to control the trade-off between the num-
ber of labeled and unlabeled samples, hence an iter-
ative scheme can balance the impact of using unla-
beled samples in case of poor generalization ability.
This often happens when very few labeled samples
are used. In practice, we empirically set u ≤ L, which
leads to good performance results as it will be shown
in the following section.
Algorithm 1: The proposed multiple classifier-based semi-
supervised algorithm.
Require: x, D
L
, D
∗
U
, S
U
, u
1: repeat
2: D
L+U
≡ {D
L
,D
∗
U
}
3:
b
y
MLR
:= MLR classifier(x,D
L+U
)
4:
b
y
QDA
:= QDA classifier(x,D
L+U
)
5: D
u
≡ F (
b
y
MLR
,
b
y
QDA
,S
U
),u
6: D
∗
U
= D
∗
U
+ D
u
7: S
U
= S
U
− {1,...,u}
8: until some stopping criterion is met
4 EXPERIMENTAL RESULTS
The well-known AVIRIS Indian Pines scene was used
in our experiments. The data were collected over
Northwestern Indiana in June of 1992 (Landgrebe,
2003), and contains 145× 145 pixels and 220 spec-
tral bands. A total of 20 bands were removed prior
to experiments due to noise and water absorption in
those channels. The ground-truth data contains 16
mutually exclusive classes, and a total of 10366 la-
beled pixels. This image is a classic benchmark to
validate the accuracy of hyperspectral image analy-
sis algorithms and constitutes a challenging problem
due to the significant presence of mixed pixels in all
available classes, and also because of the unbalanced
number of available labeled pixels per class. In this
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
408
0 200 400 600 800
40
45
50
55
60
65
The number of unlabeled samples
Overall Accuracy (%)
Whole Image
SMLR classifier
QDA classifier
0 100 200 300 400 500 594
68
72
76
80
84
The number of unlabeled samples
Overall Accuracy (%)
Subset
SMLR classifier
QDA classifier
(a) (b)
Figure 1: (a) OA results (as a function of the number of unlabeled samples) obtained after 100 Monte Carlo runs using the
proposed multiple classifier strategy on the whole AVIRIS Indian Pines hyperspectral image; (b) The same OA results for the
subset.
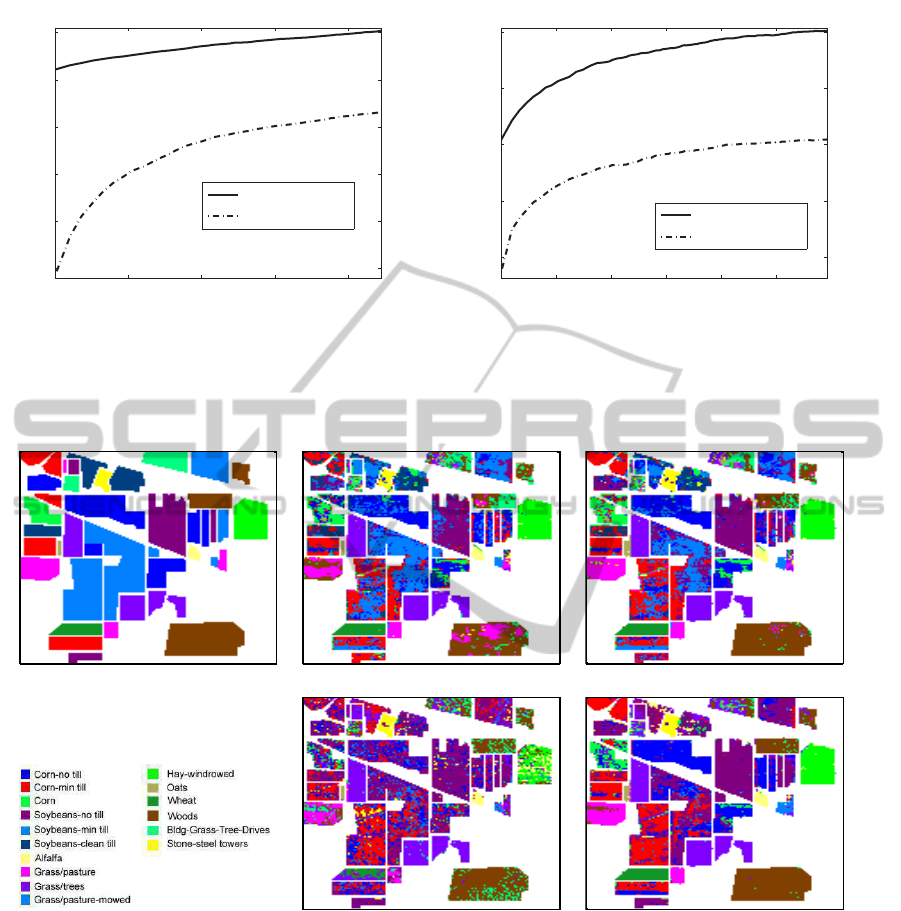
(a) (b) (c)
(d) (e)
Figure 2: Classification maps obtained for the whole AVIRIS Indian Pines image by using 160 labeled samples and 892
unlabeled samples. (a) Ground-truth image. (b) Supervised SMLR classifier: OA = 61.2%. (c) Semi-supervised SMLR
classifier with the proposed multiple classifier strategy: OA = 65.1%. (d) Supervised QDA classifier: OA = 40.7%. (e)
Semi-supervised QDA classifier with the proposed multiple classifier strategy: OA = 58.2%.
work, we consider two scenes: (a) the full image with
16 classes, and (b) a subset (consisting of pixels in
columns [27-94] and rows [31-116]) with total size
of 68× 86 pixels and 4 ground-truth classes. In our
experiments, labeled training samples are randomly
selected from the ground-truth data, whereas the re-
maining samples are used as the validation set. In
order to increase the statistical significance of the re-
sults, each value of overall accuracy (OA) reported
in this work is obtained as the average of 100 Monte
Carlo runs.
Prior to the analysis of our results, we would like
to emphasize that, for the SMLR classifier, we use all
available spectral bands. However, for the QDA clas-
sifier feature extraction needs to be applied. This is
because the QDA requires that the number of labeled
A NEW MULTIPLE CLASSIFIER SYSTEM FOR SEMI-SUPERVISED ANALYSIS OF HYPERSPECTRAL IMAGES
409

(a) (b) (c) (d) (e)
Figure 3: Classification maps obtained for the subset by using 20 labeled samples and 594 unlabeled samples. (a) Ground-
truth image. (b) Supervised SMLR classifier: OA = 76.1%. (c) Semi-supervised SMLR classifier with the proposed multiple
classifier strategy: OA = 84.9%. (d) Supervised QDA classifier: OA = 63.1%. (e) Semi-supervised QDA classifier with the
proposed multiple classifier strategy: OA = 82.3%.
samples per class be larger than the dimensionality of
the feature space [see (3)]. For dimensionality reduc-
tion, we use the hyperspectral signal identification by
minimum error (HySime) algorithm (Dias and Nasci-
mento, 2008). However, other feature extraction tech-
niques can also be used.
Fig. 1 illustrates the obtained OA results as a func-
tion of the number of unlabeled training samples in
the following cases: (a) 160 labeled samples (10 sam-
ples per class, which constitutes a very low number)
for the whole AVIRIS Indian Pines image; and (b) 20
labeled samples (5 samples per class, which is even
lower) for the subset. Notice that both (a) and (b)
constitute very difficult problems, both for supervised
techniques (as very few labeled samples are avail-
able and poor generalization capability is expected)
and for semi-supervised techniques (since the trade-
off between a large number of unlabeled samples ver-
sus a small number of labeled samples could bias the
learning process). In both cases, we adopted a mul-
tiple classification strategy in which one of the clas-
sifiers (either SMLR or QDA) was used as a baseline
and then the proposed multiple classifier-based strat-
egy was used to generate additional unlabeled sam-
ples so that the classifiers can benefit from additional
unlabeled samples. Several conclusions can be drawn
from the experimental results reported in Fig. 1:
• First and foremost, it can be seen that the pro-
posed multiple classifier-based strategy increases
the OA for both classifiers. This is particularly the
case when the QDA classifier is used as a base-
line. For this classifier, the incorporation of ad-
ditional unlabeled samples by means of the pro-
posed strategy greatly improves the final classifi-
cation results.
• Second, it can be seen that the SMLR classifier
can significantly increase the OA results by in-
cluding unlabeled training samples. For exam-
ple, an OA higher than 65% was obtained for the
whole image by using only 160 labeled samples
and around 900 unlabeled samples. For the sub-
set, only 5 labeled samples per class and around
600 unlabeled samples in total allowed increasing
the OA to around 84%.
• Another important observation is that, with the
considered number of unlabeled samples, none of
the two considered classifiers converged in terms
of the achieved OAs. This indicates that both
methods can still benefit from the inclusion of ad-
ditional unlabeled samples, thus leaving an open
path for future developments of the method.
For illustrative purposes, Figs. 2 and 3 show the
obtained classification maps along with the respective
ground-truth images in the considered experiments.
The improvements of the proposed multiple classifier-
based strategy to each of the baseline methods can be
observed in the results reported in these figures.
5 CONCLUSIONS
In this work, we have proposed a simple strategy
for incorporating additional unlabeled samples in
semi-supervised hyperspectralimage classification by
means of the consensus of multiple classifiers. The
proposed system has been validated using two dis-
criminative classifiers: (i) sparse multinomial logis-
tic regression (SMLR), and (ii) quadratic discriminant
analysis (QDA). The proposed approach is simple yet
highly effective, as illustrated by our experimental re-
sults conducted with the famous AVIRIS Indian Pines
dataset. Compared to the baseline supervised clas-
sifiers, the proposed semi-supervised method has the
potential to greatly improve classification accuracies
with very little effort, by simply including additional
unlabeled samples after the consensus of the consid-
ered classifiers. This strategy is applicable to other
classifiers but has been tested in this work only with
the SMLR and QDA to illustrate its potential. In the
future, additional classifiers and data sets will be used
in the experimental validation of our proposed mul-
tiple classifier system. Also, we will target efficient
mechanisms for exploiting the unlabeled information
in a more efficiently way, e.g. by means of active
learning. A more detailed evaluation of the computa-
tional complexity of the proposed approach (includ-
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
410

ing potential mechanisms able to reduce such cost)
will be also explored in future developments of the
method.
REFERENCES
Bioucas-Dias, J. and Figueiredo, M. (2009). Logistic
regression via variable splitting and augmented la-
grangian tools. Technical report, Instituto Superior
Tecnico, TULisbon.
Bishop, C. M. (2007). Pattern Recognition and Ma-
chine Learning (Information Science and Statistics).
Springer, 1st edition.
B¨ohning, D. (1992). Multinomial logistic regression algo-
rithm. Annals of the Institute of Statistical Mathemat-
ics, 44:197–200.
Camps-Valls, G., Bandos, T., and Zhou, D. (2007). Semi-
supervised graph-based hyperspectral image classifi-
cation. IEEE T. Geoscience and Remote Sensing,
45(10):3044–3054.
Camps-Valls, G. and Bruzzone, L. (2005). Kernel-based
methods for hyperspectral image classification. IEEE
T. Geoscience and Remote Sensing, 43(6):1351–1362.
Camps-Valls, G., Gomez-Chova, L., Muoz-Mar, J., Vila-
Francs, J., and Calpe-Maravilla, J. (2006). Composite
kernels for hyperspectral image classification. IEEE
Geoscience and Remote Sensing Letters.
Chapelle, O., Chi, M., and Zien, A. (2006). A continuation
method for semi-supervised svms. In Proceedings of
the 23rd International Conference on Machine Learn-
ing, pages 185–192. ACM Press.
Dias, J. and Nascimento, J. M. P. (2008). Hyperspectral
subspace identification. IEEE Trans. on Geoscience
and Remote Sensing, 46(8):2435–2445.
Duda, R. O., Hart, P. E., and Stork, D. G. (200). Pattern
Classification. Wiley-Interscience, 2nd edition.
Fauvel, M., Benediktsson, J. A., Chanussot, J., and Sveins-
son, J. R. (2008). Spectral and spatial classification of
hyperspectral data using svms and morphological pro-
files. IEEE Transactions on Geoscience and Remote
Sensing, 46(11):3804–3814.
Green, R. O., Eastwood, M. L., Sarture, C. M., Chrien,
T. G., Aronsson, M., Chippendale, B. J., Faust, J. A.,
Pavri, B. E., Chovit, C. J., Solis, M., and et al (1998).
Imaging spectroscopy and the airborne visible/ in-
frared imaging spectrometer (aviris). Remote Sensing
of Environment, 65(3):227–248.
Kittler, J. and Roli, F. (2000). Multiple classifier systems. In
In Proc. of the First Int. Workshop MCS 2000. Lecture
Notes in Computer Science, volume 1857.
Krishnapuram, B., Carin, L., Figueiredo, M., and
Hartemink, A. (2005). Sparse multinomial logistic re-
gression: Fast algorithms and generalization bounds.
IEEE Transactions on Pattern Analysis and Machine
Intelligence, 27(6):957968.
Krishnapuram, B., Williams, D., Xue, Y., Hartemink, A.,
Carin, L., and Figueiredo, M. (2004). On semisuper-
vised classification. In Proc. 18th Annual Conference
on Neural Information Processing Systems, Vancou-
ver, Canada.
Landgrebe, D. A. (2003). Signal Theory Methods in Multi-
spectral Remote Sensing. John Wiley, Hoboken, NJ.
Li, J., Bioucas-Dias, J., and Plaza, A. (2009). Semisu-
pervised hyperspectral image classification based on a
markov random field and sparse multinomial logistic
regression. In Proc. IEEE International Geoscience
and Remote sensing Symposium.
Li, J., Bioucas-Dias, J., and Plaza, A. (2010a). Exploiting
spatial information in semi-supervised hyperspectral
image segmentation. In IEEE GRSS Workshop on Hy-
perspectral Image and Signal Processing: Evolution
in Remote Sensing (WHISPERS10).
Li, J., Bioucas-Dias, J., and Plaza, A. (2010b). Hyper-
spectral image segmentation using a new bayesian ap-
proach with active learning. In IEEE Transactions on
Geoscience and Remote Sensing (submitted).
Li, J., Bioucas-Dias, J., and Plaza, A. (2010c). Semisuper-
vised hyperspectral image segmentation using multi-
nomial logistic regression with active learning. In
IEEE Transactions on Geoscience and Remote Sens-
ing, volume 48, page 40854098.
Mackay, D. (1992). Information-based objective functions
for active data selection. Neural Computation, 4:590–
604.
Plaza, A., Benediktsson, J. A., Boardman, J. W., Brazile, J.,
Bruzzone, L., Camps-Valls, G., Chanussot, J., Fauvel,
M., Gamba, P., Gualtieri, A., Marconcini, M., Tilton,
J. C., and Trianni, G. (2009). Recent advances in tech-
niques for hyperspectral image processing. Remote
Sensing of Environment, 113(110-122).
Roli, F. (2005). Semi-supervised multiple classifier sys-
tems: Background and research directions. Multiple
Classifier Systems, pages 1–11.
Tuia, D. and Camps-Valls, G. (2009). Semi-supervised hy-
perspectral image classification with cluster kernels.
IEEE Geoscience and Remote Sensing Letters.
Velasco-Forero, S. and Manian, V. (2009). Improving hy-
perspectral image classification using spatial prepro-
cessing. IEEE Geoscience and Remote Sensing Let-
ters, 6:297–301.
Xu, L., Krzyzak, A., , and Suen, C. Y. (1992). Methods for
combining multiple classifiers and their applications
to handwriting recognition. IEEE Trans. on Systems,
Man and cyb., 22:418435.
Zhu, X. (2005). Semi-supervised learning literature survey.
technical report 1530, computer sciences. Technical
report, University of Wisconsin-Madison.
A NEW MULTIPLE CLASSIFIER SYSTEM FOR SEMI-SUPERVISED ANALYSIS OF HYPERSPECTRAL IMAGES
411
