
FURTHER ANALYSIS ON THE APPLICATION OF MOBILE
AGENTS IN NETWORK ROUTING
Wenyu Qu and Hong Shen
Graduate School of Information Science
Japan Advanced Institute of Science and Technology
1-1 Asahidai, Tatsunokuchi, Ishikawa, 923-1292, Japan
John Sum
Department of Computing
Hong Kong Polytechnic University
Hung Hom, KLN, Hong Kong
Keywords:
Mobile agents, routing, probability of success, population distribution.
Abstract:
Mobile agent-based routing is a newly proposed routing technique for using in large networks. In order to
save network resources, it is desirable to dispatch a small number of mobile agents to get a high probability
of finding the destination (probability of success). Therefore, it is not only necessary but also important to
analyze the searching activity and the population growth of mobile agents for improving the performance
in agent-driven networks. Yet currently there is a lack of such analysis. In this paper, we present a new
mobile agent-based routing model for describing the behavior of mobile agents for network routing. Then we
analyze both the probability of success and the population growth of mobile agents running in the network.
The theoretical results show that the probability of success and the number of mobile agents can be controlled
by adjusting relevant parameters according various network characteristics. Our results reveal new theoretical
insights into the statistical behaviors of mobile agents and provide useful tools for effectively managing mobile
agents in large networks.
1 INTRODUCTION
With dramatic advances in the Internet and in the
computer industry, computers are no longer isolated
number factories. Many new applications, from e-
business to e-government and e-education, have been
created, thanks to the exponential growth of the In-
ternet user base and the widespread popularity of the
World Wide Web. Mobile agents, programs that can
migrate from host to host in a network, at times and to
places of their own choosing (Kotz and Gray, 1999),
are changing the face of e-business and reshaping cur-
rent business models (Wagner and Turban, 2002). In
(Lange and Osima, 1999), Lange et al. concluded
that mobile agents can reduce network load, over-
come network latency, encapsulate protocols, execute
autonomously and asynchronously, and adapt dynam-
ically. They are naturally heterogeneous, robust and
fault-tolerant to changing environments. In short, mo-
bile agents are software entities that “bring the com-
putation to the data rather than the data to the compu-
tation” (Schoder and Eymann, 2000).
Routing is at the core of e-business(D.M. Piscitello
and Chapin, 1993), especially in large-scale networks
(K. Curran and Bradley, 2003). By the definition in
(Caro and Dorigo, 1998a), routing is the distributed
activity of building and using routing tables, one for
each node in the network, which tell incoming data
packets which outgoing link to use to continue their
travel towards the destination node. The main task of
a routing algorithm is to direct data flow from source
to destination nodes by maximizing network perfor-
mance and minimizing user’s costs.
Mobile agent-based routing is a newly proposed
technique which adapts to the tremendous growth of
the size of the Internet and the latest development of
mobile computing. In a mobile agent-based routing
algorithm (White, 1997), once a request for sending
a message is received from the server, the server will
generate a number of mobile agents. Those agents
will then move out from the server and search for the
destination. Once an agent has reached the destina-
tion, it turns back to the server along the searched
path, and reports the path to the server. The server
picks up the desired path from all the path collected,
sends the message along the selected path, and up-
dates its routing table at the same time. The report
of an agent is given to the server only when the agent
finishes its trip, but not in the middle of the trip; thus,
there are very few communications between the agent
204
Qu W., Shen H. and Sum J. (2004).
FURTHER ANALYSIS ON THE APPLICATION OF MOBILE AGENTS IN NETWORK ROUTING.
In Proceedings of the First International Conference on E-Business and Telecommunication Networks, pages 204-212
DOI: 10.5220/0001405902040212
Copyright
c
SciTePress

and the server during the searching process. There-
fore, the network traffic generated by mobile agents
is very light.
Different mobile agent-based routing schemes re-
sult in different network performance in terms of both
quality and quantity of delivered service (Caro and
Dorigo, 1998b). Two parameters are important in
estimating a mobile agent-based routing model: the
probability of finding the destination and the number
of mobile agents being employed. It is easy to see
that mobile agents will be generated and dispatched
into the network frequently. Thus, they will certainly
consume a certain amount of network resources. To
save network resources, it is desirable to dispatch a
small number of mobile agents and achieve a good
probability of success. Therefore, performance anal-
ysis of the searching activity and population growth
of agents is not just important, but necessary for im-
proving performance of agent-driven networks. Un-
fortunately, such analysis of mobile agent behavior is
in its infancy (Kim and Robertazzi, 2000), and little
attention has been paid to the probability of success.
In this paper, we propose a new mobile agent-based
routing model which tallies with the non-stationary
stochastic nature of the Internet. Then we analyze it
on both the probability of success and the population
growth of mobile agents. The communication net-
work we focused on is a connecting network with ir-
regular topology. Our results show that both the prob-
ability of success and the number of mobile agents
can be controlled by tuning the number of agents gen-
erated per request and the number of jumps each mo-
bile agent can move.
The rest of this paper is organized as follows. Sec-
tion 2 presents our model, section 3 introduces the no-
tation used in this paper and analyzes both the proba-
bility of success and the population of agents in net-
work routing, and section 4 concludes our paper.
2 MATHEMATICAL MODEL
In a mobile agent-based network routing model, a
mobile agent will visit a sequence of hosts. The
sequence of hosts between the server and the des-
tination is called the itinerary of the mobile agent.
Whereas a static itinerary is entirely defined at the
server and does not change during the agent travel-
ling. A dynamic itinerary is subject to modifications
by the agent itself. In this paper, we propose a dy-
namic routing model that is well suited for routing in
a faulty network or mobile network. Our model can
be seen as an extended ant routing.
2.1 An Ant Routing Algorithm
As searching for the optimal path between two hosts
in a stationary network is already a difficult prob-
lem, searching for the optimal path in a faulty net-
work or mobile network will be much more diffi-
cult (Garey and Johnson, 1979). The ant routing
algorithm is a recently proposed routing algorithm
for use in this environment. The idea is inspired by
the observation of real ant colonies. Individual ants
are behaviorally simple insects with limited memory
and exhibiting activity that has a stochastic compo-
nent. However, ant colonies can accomplish com-
plex tasks due to highly structured social organiza-
tions (M. Dorigo, 2000). Ant routing algorithm is de-
signed taking inspiration from studies of the behavior
of ant colonies (J. Sum and Young, 2003). The basic
idea can be described as follows: Once a connection
request has been received from a server, the server
will generate a number of ants (the explorer agents).
Those ants will then leave the source and explore the
network. On each intermediary host, they choose a
path with a probability proportional to the heuristic
value (function of the cost and the favorite level) asso-
ciated with the link. The ants cannot visit a host twice
(they keep a tabu list of their visited hosts) and can-
not use a link if there is insufficient bandwidth avail-
able. Once the destination is reached, the ants return
from whence they came by popping their tabu list. On
their way back, they lay down a pheromone-like trail.
The server decides the desirable path from those col-
lected, and sends a special kind of ant, the allocator, to
allocate the bandwidth on all links used between the
source and the destination. When the path is no longer
required, a de-allocator agent is sent out to deallocate
the network resources used on the hosts and links.
2.2 Our Model
In our model, mobile agents possess of some capabil-
ities which real ants have not but are well suited to
the network routing applications. For example, mo-
bile agents are sighted (they can check information of
both the host it stays and the neighbor hosts) which
can improve the work efficiency of agents. They are
restricted with a life-span limit (an agent will die if it
can not find its destination in given steps) which can
eliminate unnecessary searching in the network. Our
model makes the following assumptions:
1. There are n hosts in the network, and each host has
the same probability of 1/n to be the destination
host.
2. At any time t, the expected number of requests
keyed in one host is m. Once a request arrives, k
agents are created and sent out into the network.
FURTHER ANALYSIS ON THE APPLICATION OF MOBILE AGENTS IN NETWORK ROUTING
205

3. When an agent reaches a host, it will check whether
that current host is its destination. If the agent can-
not find its destination in the current host, it will
jump to one of the neighboring hosts.
4. Once an agent reaches its destination, it submits its
goods list to the host and dies. After the host fulfils
the relevant requirements, a new agent is generated
and dispatched to the server with the resulting in-
formation.
5. To prevent the user from waiting too long, and to
reduce unnecessary searching in the network, we
further assume that if an agent cannot find its des-
tination in d jumps, it will die.
Our model works as follows: At any time, there are
lots of requests keyed in the network. Once a request
is received from a server, a number of agents are cre-
ated and sent out into the network. Those agents tra-
verse the network from the server to search for the
destination. At each host, the agents check informa-
tion of both the host itself and its neighbor hosts. The
probability that an agent can find its destination at its
jth jump is p(j). If an agent has reached its desti-
nation, it sends the collected information back to the
server along the path searched immediately. Other-
wise, the agent will select neighbor host and move
on. An agent will die if it has not found its destina-
tion before the life-span expires.
3 ANALYSIS
Although mobile agents are emerging in diverse ap-
plication fields, and their effectiveness and efficiency
have been demonstrated and reported in the literature,
the theoretical analysis of mobile agent behavior is in
its infancy. For filling this need, we develop some
stochastic analysis on both the probability of success
and the population distribution of mobile agents run-
ning in the network in this section. First we introduce
the notations and definitions used in our analysis.
3.1 Notions and Definitions
The topology of a network can be uniquely decided
by its connectivity matrix. In this paper, we make
use of the connectivity matrix in our analysis. The
network topology we consider in this context is a
connected graph, thus there is at least one link be-
tween any two hosts. Let matrix C = (c
ij
)
n×n
be
the connectivity matrix which describes the connec-
tivity of the graph, i.e., if there is a direct link be-
tween host i and host j, then c
ij
= c
ji
= 1; oth-
erwise, c
ij
= c
ji
= 0. Let c
j
be the jth col-
umn vector of matrix C: C = (c
1
, c
2
, ··· , c
n
).
d
j
= kc
j
k
1
=
P
n
i=1
|c
ij
|, σ
1
= max
1≤j≤n
d
j
,
©
©
©
©
©
©
,
,
,
,
¿
¿
¿
\
\
\
¯
¯
¯
L
L
L
v
v v
v v
1
2
3
4
5
Figure 1: An Example of a Small Network
σ
n
= min
1≤j≤n
d
j
. D = diag(d
1
, d
2
, ··· , d
n
) is a
diagonal matrix. It is easy to see that d
j
is the number
of neighboring hosts of the jth host including itself ,
and kCk
1
= max
1≤j≤n
kc
j
k
1
= σ
1
. For example,
Figure 1 shows the graphical structure of a small net-
work. Accordingly, n = 5, σ
1
= 4, and σ
5
= 3.
Matrix C is as follows:
C =
1 1 1 0 0
1 1 0 1 1
1 0 1 1 1
0 1 1 1 0
0 1 1 0 1
3.2 Probability of Success
The probability of success directly affects the search-
ing process, and affects the network performance as
a result. However, it has not been sufficiently taken
into account in existing works. In this section, the
probability of success for both single agent and mul-
tiple agents are analyzed. Our results show that the
probability of success is affected by the connectivity
matrix of the network, the number of mobile agents,
and the life-span limit. The following lemmas give
both upper bound and lower bound on the probability
of success that an agent can find its destination at dth
jump:
Lemma 1 The probability of success, p(t), that an
agent can find its destination at the tth jump, satisfies
the following inequality:
σ
n
n
³
1 −
σ
1
n
´
t
< p(t) <
σ
1
n
³
1 −
σ
n
n
´
t
Proof Denote the sequence of the host in the
itinerary of an agent by J
0
, J
1
, ···, and denote the
set of neighbor hosts of the jth host by NB(j).
After being generated by the server, J
0
, the agents
begin searching for the destination. Then, p(0),
the probability that an agent can find its destina-
tion at birth, equals to d
J
0
/n, and the probability
that it can not find the destination before the first
jump, equals to 1 − d
J
0
/n. If the agent can not
find its destination, it will jump out and search on.
The probability that it can find its destination at the
first jump is p(1) =
P
i∈NB(J
0
)
1
d
J
0
[1 − p(0)]
d
i
n
.
ICETE 2004 - GLOBAL COMMUNICATION INFORMATION SYSTEMS AND SERVICES
206
Then, p(2), the probability that an agent can find
its destination at the second jump is p(2) =
P
j∈NB(J
1
)
1
d
J
1
[1 − p(0)] [1 − p(1)]
d
j
n
. By recur-
sion, it is easy to prove that the probability, p(t), that
an agent can find its destination at the tth jump satis-
fies:
p(t) =
X
l∈NB(t−1)
(
1
d
J
t−1
·
d
l
n
·
t−1
Y
k=0
[1 − p(k)]
)
Due to σ
n
≤ d
J
i
≤ σ
1
for any i, it is easy to prove
that
σ
n
n
t−1
Y
k=0
[1 − p(k)] ≤ p(t) ≤
σ
1
n
t−1
Y
k=0
[1 − p(k)]
Hence, the lemma is proven. ¤
It is easy to see that the probability p(d) is mono-
tonically decreasing function in terms of the topology
of the network and the number of jumps. With the
number of jumps increasing, the probability of suc-
cess decreases rapidly.
With the result of probability of success for each
jump, we can estimate the probability of success for
an agent during its life-span as follows:
Theorem 1 The probability of success, P (d), that an
agent can find its destination in d jumps satisfies:
σ
n
(n − σ
1
)
2
n
2
σ
1
·
1 −
³
1 −
σ
1
n
´
d−1
¸
< P (d) <
σ
1
(n − σ
n
)
2
n
2
σ
n
·
1 −
³
1 −
σ
n
n
´
d−1
¸
Proof In our model, agents will not be generated
and dispatched into the network if the destination is
the server or a neighbor host of the server. Based on
Lemma 1 and the fact that P (d) =
P
d
t=2
p(t), the
theorem is easily proven. ¤
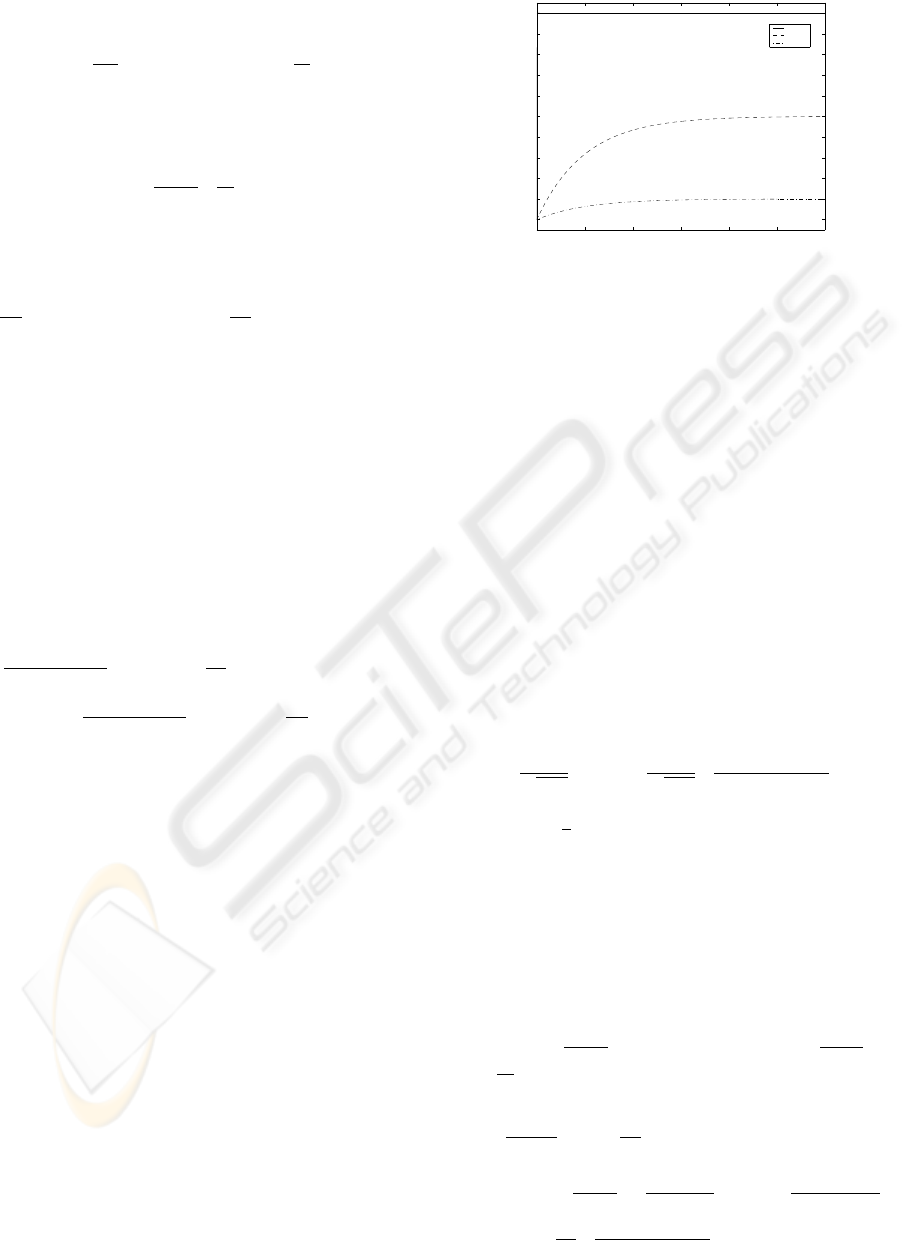
The significance of Theorem 1 can be visualized
from Figure 2.
We have conducted may experiments on various
cased. Due to space limitation, we only list three
cases for the purpose of explanation.
• Case 1: n = 10000, σ
1
= σ
n
= n;
• Case 2: n = 10000, σ
1
= 100, σ
n
= 50;
• Case 3: n = 10000, σ
1
= 100, σ
n
= 10.
Case 1 illustrates a complete connected network,
since any host in such a network knows the address of
all the other hosts in the same network, P (d) equals
to a constant 1. In both case 2 and case 3, P (d) is
a monotonically increasing function on the jumping
hops d. The connectivity of the network affects the
increase of the probability of success. It also can be
0 100 200 300 400 500 600
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
The Number of Jumping Hops
The Probability of Success
case 1
case 2
case 3
Figure 2: Variety of P (d) with d.
seen that P (d) increases slower and slower with the
increase of d. When d is large enough, the increase
of P (d) is little; therefore, it is not necessary to go
on searching if the increase of P (d) is small enough.
So, the life-span of an agent can be set according to a
threshold value ² such that P (d) − P (d − 1) ≤ ².
In a multi-agent system, multiple agents may be
dispatched to search for the same destination. For
the case that the user doesn’t really want all the dis-
patched agents, but part of them, find the destination,
we estimate the probability of success that at least s
agents from k agents can find its destination. Based
on the conclusions above, we present the following
theorem:
Theorem 2 The probability of success, P
s
, that at
least s agents from k agents can find the destination
in d jumps satisfies the following inequality:
4
s
√
2πs
< P
s
<
4
s
√
2πs
·
1
1 − λ/(s + 1)
(1)
where 4 =
λ
s
e
1−λ/s
, λ = kP (d).
Proof This probability satisfies binomial distribu-
tion, so we have
P
s
=
k
X
i=s
C
i
k
P (d)
i
[1 − P (d)]
k−i
It can be approximated by a Poison distribution as
P
s
≈
P
k
i=s
λ
i
e
−λ
i!
. Besides, we have
P
k
i=s
λ
i
e
−λ
i!
>
e
−λ
λ
s
s!
and
k
X
i=s
λ
i
e
−λ
i!
≤ e
−λ
λ
s
s!
·
·
1 +
λ
s + 1
+
λ
2
(s + 1)
2
+ ··· +
λ
k−s
(s + 1)
k−s
¸
≤ e
−λ
λ
s
s!
·
1
1 − λ/(s + 1)
FURTHER ANALYSIS ON THE APPLICATION OF MOBILE AGENTS IN NETWORK ROUTING
207

Applying Stirling’s formula: n! ≈
√
2πnn
n
e
−n
for
large n, we have
4
s
√
2πs
< P
s
<
4
s
√
2πs
1
1 − λ/(s + 1)
Hence, the theorem is proven. ¤
Especially, P
k
, the probability of success that all
the k agents find the destination, is no more than
P (d)
k
, and P
1
, the probability of success that at least
one agent from k agents can find the destination, is no
more than 1 − [1 − P (d)]
k
. Furthermore, from The-
orem 1 and Theorem 2, we have the following corol-
lary:
Corollary 1 The probability of success, P
s
, that at
least s agents from k agents can find the destination
in d jumps satisfies the following inequality:
P
s
<
1
√
2πs[1 − kα/(s + 1)]
(2)
where α = [σ
1
(n − σ
n
)
2
]/[n
2
σ
n
].
Proof If we denote x = λ/s in equation (1), then
4 = e · xe
−x
. Let f (x) = xe
−x
, it is easy to prove
that f(x) gets the maximum value when x = 1. That
is 4 ≤ 1. Furthermore, P (d) < α, hence the corol-
lary is proven. ¤
3.3 Population of Agents
In this section, we estimate the number of agents run-
ning both in the network and on each host. Accord-
ing to the number of requests keyed in the network,
mobile agents will be generated and dispatched to the
network frequently. If the number of mobile agents
is small, it can not ensure that the destination can be
found quickly. But if there are too many agents in
the network, they will introduce too much computa-
tional overhead to host machines, which will eventu-
ally become very busy and indirectly block the net-
work traffic. In order to reduce the agents’ popula-
tion in the network, a life-span limit d is assumed.
Generally, there are two approaches for designing the
life-span limit d for mobile agents. One is to set d ac-
cording to the expected number of hops an agent can
jump, another is to set d by a threshold ² such that
P {steps ≥ d} ≤ ². In this context, d is given before
agents dispatched into the network.
In the first instance, we analyze the distribution of
mobile agents running in the network without consid-
ering about the bound of jumping hops for each mo-
bile agent. It is easy to see that the distribution of
mobile agents is a stochastic process. Assume that at
time t −1, there are p
i
(t−1) agents running in the ith
host, then at time t, those agents that can not find the
destination will either jump to the neighboring hosts
of the ith host or die. As described in the model, the
mean number of agents jumping into each neighbor-
ing host from the ith host at time t is (1 −
d
i
n
)
p
i
(t−1)
d
i
−1
.
Therefore, at time t, the number of agents running
in the jth host consists of two parts: km agents
are newly generated, and
P
i∈NB(j)
(1 −
d
i
n
)
p
i
(t−1)
d
i
−1
agents come from the neighboring hosts of the jth
host, where NB(j) is a set which consists by all the
neighboring hosts of the jth host, and m is the aver-
age number of requests initiated at time t in a host.
This dynamic process can be described as follows:
p
j
(t) = km +
X
i∈NB(j)
µ
1 −
d
i
n
¶
p
i
(t − 1)
d
i
− 1
(3)
which is obviously a Markov Process . Let
−→
p (t) =
(p
1
(t), p
2
(t), ··· , p
n
(t))
T
, A = (C − I)(D −
I)
−1
[I − (1/n)D] is a matrix decided by the net-
work (obviously we have kAk
1
= 1 − σ
n
/n) and
−→
e = (1, 1, ··· , 1)
T
, then we can represent the pop-
ulation distribution of mobile agents running in the
network in matrix-vector format as follows,
−→
p (t) = km
−→
e + A
−→
p (t − 1) (4)
where the first term represents the newly generated
agents and the second term is for those surviving
agents generated previously. Equation (4) shows that
the distribution of mobile agents running in the net-
work is decided by the connectivity matrix of the net-
work, the time mobile agents alive, the initial distri-
bution of the mobile agents, and the generating rate of
mobile agents per request. From Equation (4), we can
obtain the following lemma:
Lemma 2 Assume that there are
−→
q (t − d) agents
generated at time t − d for t > d. Then the distri-
bution of these agents at time t is A
d
km
−→
q (t − d).
Proof As shown in Equation (4), the distribution for-
mula of mobile agents should be
−→
q (t) = A
−→
q (t − 1)
Hence, by recursion, the lemma is proven. ¤
Lemma 2 indicates that the number of mobile
agents decreases with time t and the decreasing rate
is decided by the connectivity matrix of network.
Based on the analysis above, we further analyze
the distribution of mobile agents running in the net-
work under the assumption that each agent can jump
at most d hops. The distribution of mobile agents after
d jumps is shown in the following lemma.
From Equation 4 and Lemma 2, the distribution of
mobile agents running in the network under the as-
sumption that each agent can jump at most d hops can
be expressed as follows:
ICETE 2004 - GLOBAL COMMUNICATION INFORMATION SYSTEMS AND SERVICES
208

Theorem 3 The distribution of agents can be de-
scribed as:
−→
p (t) =
0 t = 0
P
t−1
i=0
A
i
km
−→
e 0 < t ≤ d
P
d−1
i=0
A
i
km
−→
e t > d
(5)
Proof By Lemma 2, if the distribution of newly gen-
erated agents is km
−→
e , then the distribution of these
agents after d hops is A
d
km
−→
e . In our model, all
agents generated at time t − d will die after dhops
at time t. Therefore, these agents will be deduced
from the total distribution. From Equation (4) and the
assumption
−→
p (0) = 0, we can get the following con-
clusion by recursion:
−→
p (t) = A
−→
p (t − 1) + km
−→
e
= (I + A + ··· + A
t−1
)km
−→
e
when t ≤ d. As a result, when t ≥ d,
−→
p (t) = A
−→
p (t − 1) + km
−→
e − A
d
km
−→
e
= A
t−d
−→
p (d) + (I + A + ··· + A
t−d−1
)km
−→
e
−A
d
(I + A + ··· + A
t−d−1
)km
−→
e
= (I + A + A
2
+ ··· + A
d−1
)km
−→
e
Hence, the theorem is proven. ¤
Theorem 3 indicates that the numbers of agents
running in the network and in each host are decided
by the size of the network, the connectivity of the net-
work, and m, k, d. From this result, we can further
estimate the total number of agents running in the net-
work or on each host:
Theorem 4 The total number of agents running in
the network is less than (n − σ
n
)(d − 1)km.
Proof By equation (5) and the definition of matrix
norm, we can get
n
X
j=1
p
j
(t) = k
−→
p (t)k
1
≤
0 t = 0
t−1
X
s=1
kAk
s
1
· kmk
−→
e k
1
0 < t ≤ d
d−1
X
s=1
kAk
s
1
· kmk
−→
e k
1
t > d
≤
d−1
X
s=1
kAk
s
1
· nkm
Since kAk
1
< 1, the theorem is proven. ¤
Theorem 4 indicates that there is an upper bound
of the number of agents which is decided by the size
of the network, the connectivity of the network, the
number of requests received, the number of agents
generated per request, and the life-span limit of the
agents. Thus, the total number of agents running in
the network will not increase infinitely with time t,
we can control the total number of agents by tuning
relevant parameters.
Now, we focus on the number of agents running
in each host. We can get an upper bound of p
j
(t) as
follows:
Theorem 5 The number of agents running in the jth
host satisfies the following inequality:
p
j
(t) ≤ km +
n − σ
n
n(σ
n
− 1)
(d − 1)(d
j
− 1)km (6)
Proof See Appendix. ¤ The significance of Theo-
rem 5 can be visualized from Figure 3.
0 500 1000 1500 2000 2500 3000 3500 4000
−1
0
1
2
3
4
5
6
7
x 10
6
The time t
The population of mobile agents
case 1
case 2
case 3
Figure 3: Variety of p
j
(t) with t.
Similarly, we still consider the following three
cases in Figure 2 for explanation:
• Case 1: n = 10000, σ
1
= σ
n
= n;
• Case 2: n = 10000, σ
1
= 100, σ
n
= 50;
• Case 3: n = 10000, σ
1
= 100, σ
n
= 10.
Once a request is received from a server in a complete
connected network, the server knows the address of
the corresponding destination and need not generate
any mobile agents for routing. Therefore, the popu-
lation of mobile agents in Case 1 equals to a constant
0. In both case 2 and case 3, p
j
(t) is a monotonically
increasing function on time t. The connectivity of the
network affects the increase of the population of mo-
bile agents. It also can be seen that p
j
(t) increases
slower and slower with time goes, and it will never
exceed finite upper bound, as we have proved.
It is easy to understand that the term (1 −
d
j
/n)p
j
(t −1)/d
j
in Equation (3) indicates the num-
ber of agents moving out from the jth host to each of
its neighbor hosts at time t. Thus, from Theorem 5,
we can further estimated it as follows:
FURTHER ANALYSIS ON THE APPLICATION OF MOBILE AGENTS IN NETWORK ROUTING
209

Corollary 2 The number of agents moving out from
the jth host at time t, denoted by f
j
(t), satisfies:
f
j
(t) ≤
n − σ
n
n(σ
n
− 1)
(d − 1)km (7)
Proof As shown in Theorem 5, we have the follow-
ing inequality:
f
j
(t) =
µ
1 −
d
j
n
¶
p
j
(t − 1)
d
j
− 1
≤ km +
1
σ
n
− 1
km
t−2
X
i=1
³
1 −
σ
n
n
´
i
−
σ
n
n
km ·
t−2
X
i=0
³
1 −
σ
n
n
´
i
−
µ
1 −
1
σ
n
− 1
¶
km
³
1 −
σ
n
n
´
t−1
=
n − σ
n
n(σ
n
− 1)
km
t−2
X
i=0
³
1 −
σ
n
n
´
i
≤
n − σ
n
n(σ
n
− 1)
(d − 1)km
By the definition of f
j
(t), the corollary is proved. ¤
4 CONCLUDING REMARKS
In this paper, we analyzed the application of mobile
agents in network routing. We first proposed a model
for applying mobile agents in network routing, and
then presented some analysis on both the probability
of success and the population distribution of mobile
agents. The parameters we analyzed include the prob-
ability of success, the total number of mobile agents
running in the network, the number of mobile agents
running in each host, and the number of mobile agents
moving through each link. Our results showed that
these parameters are decided by the number of mo-
bile agents generated per request, the time that each
mobile agent has to search for the destination, and the
connectivity matrix of network. It is possible to dis-
patch a small number of mobile agents to get a high
probability of success by tuning the relevant param-
eters. The main analytical results given in this paper
are summarized in Table 1.
ACKNOWLEDGEMENT
This work was supported by Japan Society for the
Promotion of Science (JSPS) Grant-in-Aid for Scien-
tific Research under its grant for Research in Special
Research Domains.
PROOF OF THEOREM 5
Proof First, we prove that
p
j
(t) ≤ d
j
km +
d
j
− 1
σ
n
− 1
km ·
t−2
X
i=1
³
1 −
σ
n
n
´
i
−
σ
n
n
(d
j
− 1)km ·
t−2
X
i=0
³
1 −
σ
n
n
´
i
−
µ
1 −
1
σ
n
− 1
¶
(d
j
− 1)km
³
1 −
σ
n
n
´
t−1
Assume that at time t = 0, there is no agent running in
the network, that is,
−→
p (0) = (0, 0, ··· , 0)
T
, and that
each time the number of requests keyed in one host is
m, k is the number of agents generated per request.
Then, we have
p
j
(1) = km
p
j
(2) = km +
X
i∈NB(j)
µ
1 −
d
i
n
¶
p
i
(1)
d
i
− 1
= km +
X
i∈NB(j)
·
1 −
d
i
n
−
µ
1 −
d
i
n
¶µ
1 −
1
d
i
− 1
¶¸
p
i
(1)
≤ d
j
−
σ
n
n
(d
j
− 1)km
−
³
1 −
σ
n
n
´
µ
1 −
1
σ
n
− 1
¶
(d
j
− 1)km
We assume that
p
j
(t − 1) ≤ d
j
km +
d
j
− 1
σ
n
− 1
km ·
t−3
X
i=1
³
1 −
σ
n
n
´
i
−
σ
n
n
(d
j
− 1)km ·
t−3
X
i=0
³
1 −
σ
n
n
´
i
−
µ
1 −
1
σ
n
− 1
¶
(d
j
− 1)km
³
1 −
σ
n
n
´
t−2
ICETE 2004 - GLOBAL COMMUNICATION INFORMATION SYSTEMS AND SERVICES
210
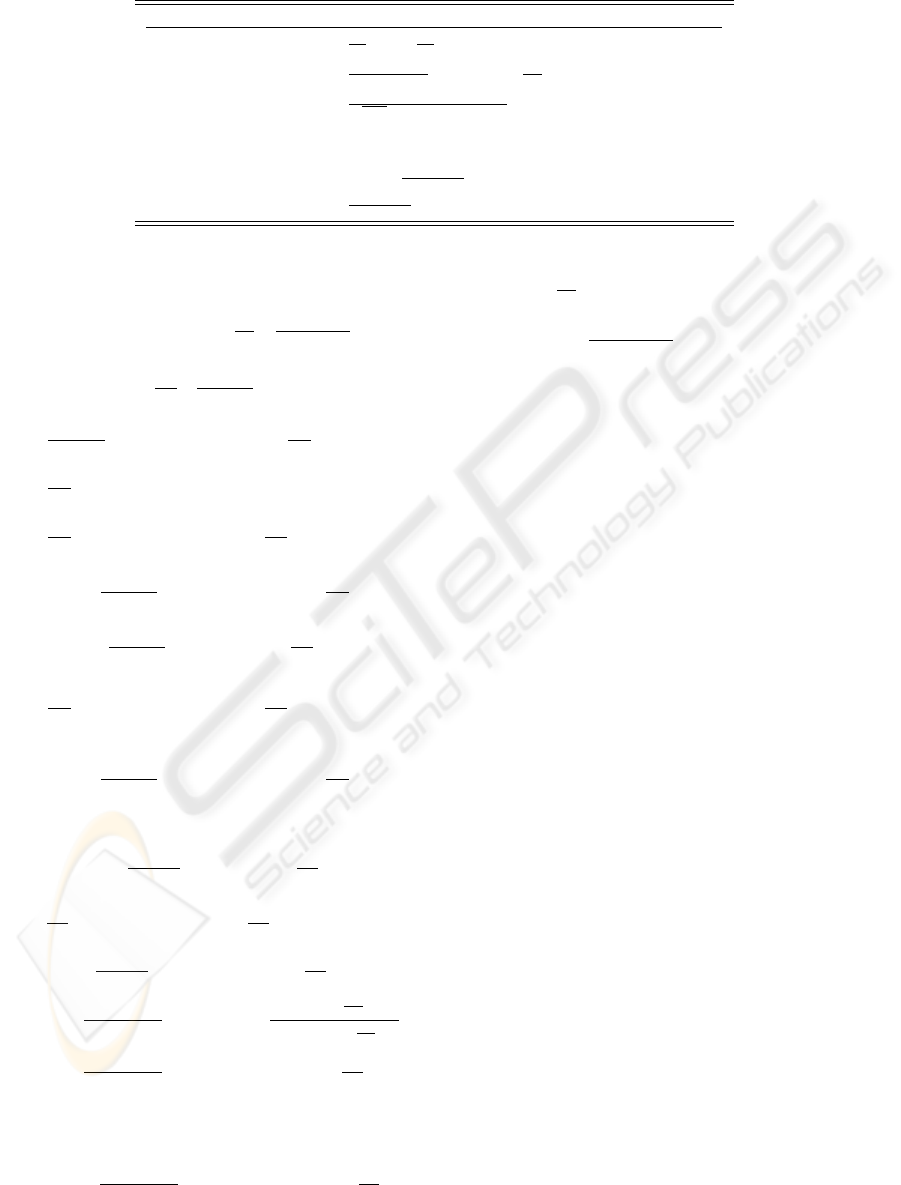
Table 1: Summary of the Main Results Given in This Paper.
No. Result Remark
1 p(d) ≤
σ
1
n
¡
1 −
σ
1
n
¢
d
Prob.
2 P (d) ≤
σ
1
(n−σ
n
)
2
n
2
σ
n
h
1 −
¡
1 −
σ
n
n
¢
d−1
i
Prob.
3 P
s
≤
1
√
2πs[1−kP (d)/(s+1)]
Prob.
4
−→
p (t) = km
−→
e + A
−→
p (t − 1) Prob.
5 k
−→
p (t)k
1
≤ (n − σ
n
)(d − 1)km Prob.
6 p
j
(t) ≤ km +
n−σ
n
n(σ
n
−1)
(d − 1)(d
j
− 1)km Prob.
7 f
j
(t) ≤
n−σ
n
n(σ
n
−1)
(d − 1)km Prob.
then at time t, we have
p
j
(t) = km +
X
i∈NB(j)
µ
1 −
d
j
n
¶
p
i
(t − 1)
d
j
≤ d
j
km +
³
1 −
σ
n
n
´
1
σ
n
− 1
(d
j−1
)km
+
1
σ
n
− 1
(d
j
− 1)km
t−2
X
i=2
³
1 −
σ
n
n
´
i
−
σ
n
n
(d
j
− 1)km
−
σ
n
n
(d
j
− 1)km ·
t−2
X
i=1
³
1 −
σ
n
n
´
i
−
µ
1 −
1
σ
n
− 1
¶
(d
j
− 1)km
³
1 −
σ
n
n
´
t−1
≤ d
j
km +
d
j
− 1
σ
n
− 1
km ·
t−2
X
i=1
³
1 −
σ
n
n
´
i
−
σ
n
n
(d
j
− 1)km ·
t−2
X
i=0
³
1 −
σ
n
n
´
i
−
µ
1 −
1
σ
n
− 1
¶
(d
j
− 1)km
³
1 −
σ
n
n
´
t−1
Thus, the first result is proven.
p
j
(t) ≤ d
j
km +
d
j
− 1
σ
n
− 1
km ·
t−2
X
i=1
³
1 −
σ
n
n
´
i
−
σ
n
n
(d
j
− 1)km ·
t−2
X
i=0
³
1 −
σ
n
n
´
i
−
µ
1 −
1
σ
n
− 1
¶
(d
j
− 1)km
³
1 −
σ
n
n
´
t−1
= km +
n − σ
n
n(σ
n
− 1)
(d
j
− 1)km ·
1 −
¡
1 −
σ
n
n
¢
t−1
1 −
¡
1 −
σ
n
n
¢
≤ km +
n − σ
n
n(σ
n
− 1)
(d
j
− 1)km ·
t−2
X
i=0
³
1 −
σ
n
n
´
i
Since p
j
(t) ≤ p
j
(d) when t ≤ d, and p
j
(t) = p
j
(d)
when t ≥ d, we have
p
j
(t) ≤ km +
n − σ
n
n(σ
n
− 1)
(d
j
− 1)km ·
d−2
X
i=0
³
1 −
σ
n
n
´
i
Due to 1 −
σ
n
n
≤ 1, we have
p
j
(t) ≤ km +
n − σ
n
n(σ
n
− 1)
(d
j
− 1)(d − 1)km
Hence, the theorem is proven. ¤
REFERENCES
Caro, G. and Dorigo, M. (1998a). AntNet: Distributed
Stigmergetic Control for Communications Networks.
Journal of Artificial Intelligence Research, Vol. 9, pp.
317-365.
Caro, G. and Dorigo, M. (1998b). Mobile agents for adap-
tive routing. In Thirty-First Hawaii International
Conference on Systems.
D.M. Piscitello, B. C. and Chapin, A. (1993). Introduc-
tion to Routing. http:// www.corecom.com /html /OS-
Nconnexions.html.
Garey, M. and Johnson, D. (1979). Ant Algorithms and Stig-
mergy. Computers and Intractability: A Guide to the
Theory of NP-Completeness, New York: Freeman.
J. Sum, H. Shen, C. L. and Young, G. (2003). Analysis
on a Mobile Agent-Based Ant routing Algorithm for
Network Routing and Management. IEEE Transaction
on Paralell and Distributed Systems, Vol. 14, No. 3,
pp. 193-202.
K. Curran, D. Woods, N. M. and Bradley, C. (2003). The
Effects of Badly Behaved Routers on Internet Conges-
tion. International Journal of Network Management,
Vol. 13, pp. 83-94.
Kim, S. and Robertazzi, T. (2000). Mobile Agent Modelling.
SUNY at Stony Brook Technical Report 786.
Kotz, D. and Gray, R. (1999). Mobile Agents and the Future
of the Internet. ACM Operating Systems Review, Vol.
33(3), pp. 7-13.
Lange, D. and Osima, M. (1999). Seven Good Reasons for
Mobile Agents. Communications of the ACM, Vol. 42,
pp. 88-89.
FURTHER ANALYSIS ON THE APPLICATION OF MOBILE AGENTS IN NETWORK ROUTING
211

M. Dorigo, E. Bonabeau, G. T. (2000). Ant Algorithms
and Stigmergy. Future Generation Computer Systems,
Vol. 16, No. 9, pp. 851-871.
Schoder, D. and Eymann, T. (2000). The Real Challenges
of Mobile Agents. Communications of the ACM, Vol.
43, No. 6, pp. 111-112.
Wagner, C. and Turban, E. (2002). Are Intelligent E-
commerce Agents Partners or Predators? Commu-
nications of the ACM, Vol. 45, No. 5, pp. 84-90.
White, T. (1997). Routing with Swarm Intelligence. Tech-
nical Report SCE-97-15, Systems and Computer En-
gineering, Carleton University.
ICETE 2004 - GLOBAL COMMUNICATION INFORMATION SYSTEMS AND SERVICES
212
