
AN EXPERIENCE IN MANAGEMENT OF IMPRECISE SOIL
DATABASES BY MEANS OF FUZZY ASSOCIATION RULES AND
FUZZY APPROXIMATE DEPENDENCIES
1
J. Calero, G. Delgado, M. S
´
anchez-Mara
˜
n
´
on
Department of Pedology and Agricultural Chemistry. University of Granada
D. S
´
anchez, M.A.Vila
Department of Computer Science and A.I. University of Granada
J.M. Serrano
Department of Computer Science. University of Jaen
Keywords:
Expert soil knowledge, aggregated soil databases, imprecision factors in soil knowledge, fuzzy data mining.
Abstract:
In this work, we start from a database built with soil information from heterogeneous scientific sources (Local
Soil Databases, LSDB). We call this an Aggregated Soil Database (ASDB). We are interested in determining
if knowledge obtained by means of fuzzy association rules or fuzzy approximate dependencies can represent
adequately expert knowledge for a soil scientific, familiarized with the study zone. A master relation between
two soil attributes was selected and studied by the expert, in both ASDB and LSDB. Obtained results reveal
that knowledge extracted by means of fuzzy data mining tools is significatively better than crisp one. Moreover,
it is highly satisfactory from the soil scientific expert’s point of view, since it manages with more flexibility
imprecision factors (IFASDB) commonly related to this type of information.
1 INTRODUCTION
Soil survey data is required for different kinds of en-
vironmental and agronomic studies, specially for es-
timation of soil quality indicators and other very im-
portant soil characteristics over large areas (Cazemier
et al., 2001). Many of these parameters present a high
degree of spatial variability, and they obstruct knowl-
edge extraction when soil survey scale is small or very
small (1:200000 or lower). In other order of things,
obtaining a high precision map can be very expen-
sive in time and resources, as a minimum number of
measures would be desirable for resource optimiza-
tion. Due to costs related to the schedule of a cartog-
raphy or soil survey at a high scale in large geographic
areas, researchers must recur in many occasions to
knowledge fusion from different local soil databases
for regional or national level studies (Bui and Moran,
2003).
Information sources in local soil databases present
a very heterogeneous nature, combining not only soil
cartographies but also Ph.D. thesis, monographes and
other diverse works. This fact implies that result-
ing databases from local soil databases fusion (Ag-
1
This work is supported by the research project Fuzzy-
KIM, CICYT TIC2002-04021-C02-02.
gregated soil databases, ASDB) present an additional
imprecision or uncertainty degree related to local in-
formation aggregation processes.
Statistical analysis techniques are frequently ap-
plied in soil study: analysis of variance (Ulery and
Graham, 1993), regression analysis (Qian et al.,
1993), main components analysis (S
´
anchez-Mara
˜
n
´
on
et al., 1996) and discriminant analysis (Scheinost and
Schwertmann, 1999). These techniques, based on sta-
tistical probability theory, are adequate for dealing
with uncertainty derived from randomness. Neverthe-
less, they are not suitable when managing imprecision
or uncertainty related to qualitative character in many
attributes (soil structure, consistency), of subjective
nature and hard for mathematical treatment (Webster,
1977), as the ones in the ASDB.
Data mining techniques (such as association rules
or approximate dependencies) have been proven as
effective tools when looking for hidden or implicit re-
lations between attributes in a large database (ASDB)
and they do not have the limitations of statistical pro-
cedures commented above. In particular, fuzzy data
mining tools can be specially suitable when we con-
sider intrinsically fuzzy information, as soil data.
In this work, our objective is to extract knowledge
from an ASDB obtained from local heterogeneous in-
formation sources. We want to test that fuzzy data
138
Calero J., Delgado G., Sánchez-Marañón M., Sánchez D., A. Vila M. and M. Serrano J. (2004).
AN EXPERIENCE IN MANAGEMENT OF IMPRECISE SOIL DATABASES BY MEANS OF FUZZY ASSOCIATION RULES AND FUZZY APPROXIMATE
DEPENDENCIES.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 138-146
DOI: 10.5220/0002653601380146
Copyright
c
SciTePress

mining tools can manage the increment in impreci-
sion or uncertainty degree related to an aggregation
process, better than crisp tools. In order to accom-
plish this, we introduce a methodology of knowledge
extraction and interpretation on an ASDB real case,
in a large area in Iberian Peninsula Southeast. From
this, the domain expert will estimate the suitability of
the proposed tools for this particularly difficult case
of databases.
2 PROBLEM STATEMENT
We consider several soil databases with an analo-
gous structure, but obtained from different sources, by
means of different criteria. Modelling these sources
and criteria as discriminant attributes, we can fuse all
these databases into an ASDB. Also, in order to model
soil data more accurately, we consider fuzzy similar-
ity relations and sets of linguistic labels over some
soil attributes.
Formally, let RE = {A
1
, . . . , A
m
, B} be a rela-
tional scheme, and r an instance of RE. Let S
RE
=
{S
A
k
} be a set of fuzzy similarity relations over at-
tributes in RE. Also, given t ∈ r a tuple, let t[A
k
] be
the intersection of t and A
k
, and µ
t[A
k
]
the member-
ship degree of the value.
Finally, let B be a discriminant attribute, and
dom(B) = {b
1
, . . . , b
l
} the set of possible values
of B. Our idea when using discriminant attributes is
to generate more homogenous sets of objects from a
database, according to the attribute values. That is,
we can perform a query as the following,
select A
1
, . . . , A
m
from r where B = b
j
;
obtaining r
j
, a subset of r. Each subrelation r
j
can
be viewed as a LSDB, obtained according to a given
criterium.
Moreover, if we apply some data mining tech-
niques (i.e., association rules or approximate depen-
dencies, see below), we can obtain the following,
• R
G
, the set of all rules from r.
• R
j
, the set of all rules from r
j
.
We are interested in the study of possible existing
correspondences between these sets of rules:
• Can we find rules in R
j
that do not hold in R
G
, and
viceversa?
• Can imprecision or uncertainty management in
data generate more accurate rules from domain ex-
perts’ point of view, at both levels R
G
and R
j
?
Our proposed methodology is the following:
1. To define a set of criteria for decomposition of a
given ASDB (r) into several LSDB (r
j
), according
to B, discriminant attribute, values.
2. To extract (fuzzy) approximate dependencies be-
tween attributes in r and in every subset of r.
3. To describe the obtained dependencies at a local
level, by means of (fuzzy) association rules.
4. To compare the resulting sets of rules and depen-
dencies in order to discover possible couplings at
different levels.
5. To study in which real world problems imprecision
and uncertainty management in data can generate
better rules or dependencies, that is, when domain
experts find more interesting and reasonable the ob-
tained results.
3 DATA MINING TOOLS
In this section we summarize the techniques we have
employed to analyze data corresponding to soil color
and properties.
3.1 Association rules
Given a set I (”set of items”) and a set of transac-
tions T (also called T-set), each transaction being a
subset of I, association rules are ”implications” of
the form A ⇒ C that relate the presence of itemsets
(sets of items) A and C in transactions of T , assuming
A, C ⊆ I, A ∩ C = ∅ and A, C 6= ∅.
In the case of relational databases, it is usual to
consider that items are pairs hattribute, valuei, and
transactions are tuples in a table. For example, the
item hX, x
0
i is in the transaction associated to a tuple
t iff t[X] = x
0
.
The ordinary measures proposed in (Agrawal et al.,
1993) to assess association rules are confidence (the
conditional probability p(C|A)) and support (the
joint probability p(A ∪ C)).
An alternative framework was proposed in (Berzal
et al., 2001; Berzal et al., 2002). In this frame-
work, accuracy is measured by means of Short-
liffe and Buchanan’s certainty factors (Shortliffe and
Buchanan, 1975), in the following way: the certainty
factor of the rule A ⇒ C is
CF (A ⇒ C) =
(Conf(A ⇒ C)) − S(C)
1 − S(C)
(1)
if Conf(A ⇒ C) > S(C), and
CF (A ⇒ C) =
(Conf(A ⇒ C)) − S(C)
S(C)
(2)
if Conf(A ⇒ C) < S(C), and 0 otherwise.
Certainty factors take values in [−1, 1], indicating
the extent to which our belief that the consequent is
true varies when the antecedent is also true. It ranges
AN EXPERIENCE IN MANAGEMENT OF IMPRECISE SOIL DATABASES BY MEANS OF FUZZY ASSOCIATION
RULES AND FUZZY APPROXIMATE DEPENDENCIES
139

from 1, meaning maximum increment (i.e., when A is
true then C is true) to -1, meaning maximum decre-
ment.
3.2 Approximate dependencies
A functional dependence V → W holds in a rela-
tional scheme RE if and only if V, W ⊆ RE and for
every instance r of RE
∀t, s ∈ r if t[V ] = s[V ] then t[W ] = s[W ] (3)
Approximate dependencies can be roughly defined
as functional dependencies with exceptions. The def-
inition of approximate dependence is then a matter of
how to define exceptions, and how to measure the ac-
curacy of the dependence (Bosc and Lietard, 1997).
We shall follow the approach introduced in (Delgado
et al., 2000; Blanco et al., 2000), where the same
methodology employed in mining for AR’s is applied
to the discovery of AD’s.
The idea is that, since a functional dependency
”V → W ” can be seen as a rule that relates the equal-
ity of attribute values in pairs of tuples (see equation
(3)), and association rules relate the presence of items
in transactions, we can represent approximate depen-
dencies as association rules by using the following in-
terpretations of the concepts of item and transaction:
• An item is an object associated to an attribute of
RE. For every attribute At
k
∈ RE we note it
At
k
the associated item.
• We introduce the itemset I
V
to be
I
V
= {it
At
k
| At
k
∈ V }
• T
r
is a T-set that, for each pair of tuples
< t, s > ∈ r × r contains a transaction ts ∈ T
r
verifying
it
At
k
∈ ts ⇔ t[At
k
] = s[At
k
]
It is obvious that |T
r
| = |r × r| = n
2
.
Then, an approximate dependence V → W in the
relation r is an association rule I
V
⇒ I
W
in T
r
(Del-
gado et al., 2000; Blanco et al., 2000). The support
and certainty factor of I
V
⇒ I
W
measure the interest
and accuracy of the dependence V → W .
3.3 Fuzzy association rules
In (Delgado et al., 2003), the model for association
rules is extended in order to manage fuzzy values in
databases. The approach is based on the definition
of fuzzy transactions as fuzzy subsets of items. Let
I = {i
1
, . . . , i
m
} be a set of items and T
0
be a set of
fuzzy transactions, where each fuzzy transaction is a
fuzzy subset of I. Let ˜τ ∈ T
0
be a fuzzy transaction,
we note ˜τ(i
k
) the membership degree of i
k
in ˜τ. A
fuzzy association rule is an implication of the form
A ⇒ C such that A, C ⊂ RE and A ∩ C = ∅.
It is immediate that the set of transactions where a
given item appears is a fuzzy set. We call it repre-
sentation of the item. For item i
k
in T
0
we have the
following fuzzy subset of T
0
:
˜
Γ
i
k
=
X
˜τ ∈T
0
˜τ(i
k
)/˜τ (4)
This representation can be extended to itemsets as
follows: let I
0
⊂ I be an itemset, its representation is
the following subset of T
0
:
˜
Γ
I
0
=
\
i∈I
0
˜
Γ
i
= min
i∈I
0
˜
Γ
i
(5)
In order to measure the interest and accuracy of a
fuzzy association rule, we must use approximate rea-
soning tools, because of the imprecision that affects
fuzzy transactions and, consequently, the representa-
tion of itemsets. In (Delgado et al., 2003), a semantic
approach is proposed based on the evaluation of quan-
tified sentences (see (Zadeh, 1983)). Let Q be a fuzzy
coherent quantifier:
• The support of an itemset
˜
Γ
I
0
is equal to the result
of evaluating the quantified sentence Q of T
0
are
˜
Γ
I
0
.
• The support of the fuzzy association rule A ⇒ C
in the FT-set T
0
, Supp(A ⇒ C), is the evaluation
of the quantified sentence Q of T are
˜
Γ
A∪C
= Q of
T are (
˜
Γ
A
∩
˜
Γ
C
).
• The confidence of the fuzzy association rule A ⇒
C in the FT-set T
0
, Conf (A ⇒ C), is the evalua-
tion of the quantified sentence Q of
˜
Γ
A
are
˜
Γ
C
.
As seen in (Delgado et al., 2003), the proposed
method is a generalization of the ordinary association
rule assessment framework in the crisp case.
3.4 Fuzzy approximate dependencies
As seen in (Bosc and Lietard, 1997), it is possible to
extend the concept of functional dependence in sev-
eral ways by smoothing some of the elements of the
rule in equation 3. We want to consider as much cases
as we can, integrating both approximate dependen-
cies (exceptions) and fuzzy dependencies. For that
purpose, in addition to allowing exceptions, we have
considered the relaxation of several elements of the
definition of functional dependencies. In particular
we consider membership degrees associated to pairs
(attribute, value) as in the case of fuzzy association
rules, and also fuzzy similarity relations to smooth the
equality of the rule in equation 3.
ICEIS 2004 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
140

We shall define fuzzy approximate dependencies in
a relation as fuzzy association rules on a special FT-
set obtained from that relation, in the same way that
approximate dependencies are defined as association
rules on a special T-set.
Let I
RE
= {it
At
k
|At
k
∈ RE} be the set of items
associated to the set of attributes RE. We define a
FT-set T
0
r
associated to table r with attributes in RE
as follows: for each pair of rows < t, s > in r × r we
have a fuzzy transaction ts in T
0
r
defined as
∀it
At
k
∈ T
0
r
, ts(it
At
k
) =
min(µ
t
(At
k
), µ
s
(At
k
), S
At
k
(t(At
k
), s(At
k
))) (6)
This way, the membership degree of a certain item
it
At
k
in the transaction associated to tuples t and s
takes into account the membership degree of the value
of At
k
in each tuple and the similarity between them.
This value represents the degree to which tuples t and
s agree in At
k
, i.e., the kind of items that are related
by the rule in equation 3. On this basis, we define
fuzzy approximate dependencies as follows (Berzal
et al., 2003; Serrano, 2003):
Let X, Y ⊆ RE with X ∩ Y = ∅ and X, Y 6= ∅.
The fuzzy approximate dependence X → Y in r is
defined as the fuzzy association rule I
X
⇒ I
Y
in T
0
r
.
The support and certainty factor of I
X
⇒ I
Y
are
calculated from T
0
r
as explained in sections 3.3 and
3.1, and they are employed to measure the importance
and accuracy of X → Y .
A FAD X → Y holds with total accuracy (cer-
tainty factor CF (X → Y ) = 1) in a relation r iff
ts(I
X
) ≤ ts(I
Y
) ∀ts ∈ T
0
r
(let us remember that
ts(I
X
) = min
At
k
∈X
ts(it
At
k
) ∀X ⊆ RE). More-
over, since fuzzy association rules generalize crisp as-
sociation rules, FAD’s generalize AD’s.
Additional properties and an efficient algorithm for
computing FAD’s can be found in (Berzal et al., 2003;
Serrano, 2003).
3.5 Fuzzy association rules with
fuzzy similarity relations
Fuzzy logic can be an effective tool for representa-
tion of heterogeneous data. In fact, fuzzy similarity
relations allow us to establish semantic links between
values.
Several fuzzy association rules definitions can be
found in the literature but, to our knowledge, none of
them contemplates fuzzy similarity relations between
values. Given two items i
0
=< A, a
0
> and i
1
=<
A, a
1
>, and a similarity degree S
A
(a
0
, a
1
) = α, it
would be desirable to have into account how the sup-
port of an item is affected by appearances of similar
items.
In (S
´
anchez et al., 2004), we extend the definition
of fuzzy association rule (section 3.3)in the following
way. Let A ∈ RE be an attribute, and dom(A) =
{a
1
, . . . , a
p
} the set of possible values of A. For each
a
i
∈ A, we define a linguistic label E
a
i
as the func-
tion
E
a
i
: A → [0, 1]; E
a
i
(a) = S
A
(a
i
, a) (7)
where S
A
(a
i
, a) is the similarity degree between a
i
and a. Let I
A
be the set of items where each item is
associated to a pair < A, E
a
i
>, |I
A
| = |dom(A)|.
This way, each time an item appears, we reflect its
similarity with other items as the compatibility degree
returned by its linguistic label. Moreover, according
to this representation, we can apply the same method-
ology proposed in (Delgado et al., 2003) in order to
obtain fuzzy association rules.
4 EXPERIMENTS
To carry out the aggregation process, we started from
14 databases, created from local information sources,
that constitute the so called Local Soil Databases
(LSDB). In this context, we denominated ”local” in-
formation source each one of the categories for Dis-
criminant Attributes in Table 1. Likewise, the Aggre-
gated Soil Database (ASDB) results from the ”aggre-
gation” or inclusion in one large database of every lo-
cal information source. During this process, a number
of factors, that we called imprecision factors in Ag-
gregated Soil Databases (IFASDB), appeared, caus-
ing a loss of accuracy and effectiveness in representa-
tion, extraction and management of knowledge allu-
sive to the problem in the real world at ASDB level.
We could describe several IFASDB, but in this work
we considered only three that resume, in great part, all
the others. This factors are: the ecogeographical vari-
ability, the bibliography from we extracted data and
the set of protocols and standard techniques used by
authors to describe and analyze soils (discriminant at-
tributes Mesoenvironment, Bibliographic Source and
Protocol, respectively, in Table 1). At this point,
we must also describe the mesoenvironments (Sierra
Nevada, Sierra of G
´
ador and Southeast). Relations
between soil attributes and values that can be studied
by means of our data mining techniques are very nu-
merous. The expert can enumerate a huge amount of
basic well-known relations in Soil Science, i.e: mean
annual rainfall and altitude, % of slope and % of clay,
% of CaCO
2
and pH, original material and effective
soil thickness, structure type and Horizon type, etc.
We called all this rules A Priori Expert Rules (PER).
From the set of PERs, we selected the rules derived
from the dependence
HorizonT ype → %OrganicCarbon
AN EXPERIENCE IN MANAGEMENT OF IMPRECISE SOIL DATABASES BY MEANS OF FUZZY ASSOCIATION
RULES AND FUZZY APPROXIMATE DEPENDENCIES
141

This relates two very meaningful attributes in Soil
Science:
• The horizon type definition and classification are
conditioned for OC (Organic Carbon) content, a
diagnostic feature in most employed systems of
soil classification (Soil-Survey-Staff, 1975; FAO,
1998).
• OC content is highly sensitive to ecological and
geographical variability in Mediterranean climate
type.
• Both attributes are good indicators for several
soil forming processes as melanization, accumu-
lation, vertisolation, isohumification, horizonation,
mineralization. . .
• OC content is an useful index for physical and bio-
chemical degradation of soils, and it is in strict de-
pendence with management.
• Analytical methods for OC content determination
are not very sensitive to uncertainty, as opposed to
the type of horizon. The latter is highly imprecise
and is closely related with the analyst’s competence
and finality.
Once PERs are selected, we study the obtained
ARs, ADs, FARs and FADs at both local and ag-
gregated levels (LSDB and ASDB, respectively). By
means of CF, we assess the extracted knowledge and
suggest appropriate considerations for use of this data
mining techniques, from an expert’s point of view.
4.1 Knowledge sources.
Pretreatment of soil information
The ASDB included soil information about three
mesoenvironments from the South and Southeast of
the Iberian Peninsula under Mediterranean climate:
Sierra Nevada, Sierra of G
´
ador and Southeast (involv-
ing part of the provinces of Murcia and Almer
´
ıa). Ta-
ble 1 shows the main characteristics of local informa-
tion sources. We used two Ph.D. Thesis and five car-
tographic sheets from LUCDEME, scale 1:100000.
Data from Sierra of G
´
ador was extracted from (Oy-
onarte, 1990) and consists of 70 soil profiles and 176
horizons. Altitude fluctuates from 100 to 2200 m, and
rainfall from 213 mm/year (semiarid climate) to 813
mm/year (wet climate), with a mean annual rainfall of
562 mm/year. Lowest annual mean temperature is 6.4
C and the highest is 21.0 C, with a mean of 12.7 C.
Original soil materials are of carbonated type, mainly
limestones and dolomites.
Data from Southeast was extracted from
LUCDEME soil maps, specifically from sheets
1041 from Vera, Almer
´
ıa (Delgado et al., 1991),
911 from Cehegin, Murcia (Alias, 1987), 1030 from
Tabernas, Almer
´
ıa (P
´
erez Pujalte, 1987), 912 from
Mula, Murcia (Alias, 1986) and 1031 from Sorbas,
Almer
´
ıa (P
´
erez Pujalte, 1989). There is a total of 89
soil profiles and 262 horizons. Altitude fluctuates
from 65 to 1120 m, and rainfall from 183 mm/year
(arid climate) to 359 mm/year (semiarid climate),
with a mean annual rainfall of 300 mm/year. Lowest
annual mean temperature is 13.2 C and the highest
is 19.0 C, with a mean of 17.0 C. Geological envi-
ronment and Original soil materials are extremely
different, we can find carbonated, acids and volcanic
rocks.
Data from Sierra Nevada was extracted from
(S
´
anchez-Mara
˜
n
´
on, 1992). There is a total of 35
soil profiles and 103 horizons. Altitude fluctuates
from 1320 to 3020 m, and rainfall from 748 mm/year
(semihumid climate) to 1287 mm/year (hiperhumid
climate), with a mean annual rainfall of 953 mm/year.
Lowest annual mean temperature is 0.0 C and the
highest is 12.1 C. Geological environment and Origi-
nal soil materials are mainly acids, but it is not strange
to find basic rocks.
Attributes with numeric domains were discretized,
following some of the methodologies discussed
in (Hussain et al., 1999), under supervision of
domain experts. A set of linguistic labels
{Low, M edium, High} was defined for every nu-
meric attribute. Attributes with categorical domains
were fuzzified considering fuzzy similarity relations.
4.2 Analyzing discovered knowledge
4.2.1 Crisp case
When we considered crisp relations from ASDB (Ta-
ble 2), we found only one AD, HorizonT ype →
%OrganicCarbon with CF 0.089, that reveal a
strong grade of independence between these at-
tributes. Provisionally, this conclusion contradicts the
expert experience, confirmed in the bibliography. As
we could expect, we obtained only four ARs, mainly
with consequent [%OrganicCarbon = Low]. This
fact was not surprising to us, because the ”Low” cate-
gory had a high support (70%) ASDB. As the support
threshold for rules was 10%, rules having ”Medium”
and ”High” categories, were not found. In both cases,
crisp data mining was not satisfactory enough for Soil
Scientists, and we could not ”fuse” ASDB and ex-
pert knowledge. Otherwise, when we considered sep-
arately the information stored in LSDBs (Table 3), we
obtained approximate dependencies with higher CF
than in ASDB. This phenomenon could reflect the ac-
tion of IFASDB. Despite of this, some local depen-
dencies showed smaller CF values than in the aggre-
gated case, and express a total independence.
ICEIS 2004 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
142

4.2.2 Fuzzy case
Observing FADs from ASDB, a CF of 0.31 is found
(Table 2). Despite of this low CF, the dependence
degree shown between HorizonT ype and OC con-
tent was more informative than in the crisp case. It
reflected better the expert knowledge. Even though,
initially, the soil scientist expected a higher degree, it
can be explained due to the influence of soils placed
at Southeast Mesoenvironment in ASDB. Indeed, due
to the arid nature of this climate, it could be expected
that one of the main soil forming factors, OC content
incorporated to soil from vegetation, were low and
homogenous. The latter conclusion can be checked
regarding Table 4. Moreover, fuzzy data mining let
us obtain a higher number of rules than in crisp case.
This supposes, quantitatively, a higher volume of dis-
covered knowledge.
A good example of correspondence or ”fusion”
between databases and expert knowledge could be
obtained comparing ARs from Sierra of G
´
ador with
Southeast ones. The former had rules with ”moder-
ate” and ”high” OC content in consequent, whereas
the latter had a ”low” value in consequent. Sierra
of G
´
ador has a higher mean altitude and mean an-
nual rainfall, and, consequently, more vegetation in
soil and horizons (especially in Ah type). Look-
ing at this, the fuzzy model reflects more accurately
soil forming processes as melanization and accumu-
lation. We can also examine others IFSDB in addi-
tion to Mesoenvironment. I.e., Protocol constitute an
important source of variability in ASDB. Comparing
”Perez” and ”Alias” categories, the former has more
ARs (Table 6) and relates more categories, reflecting
a more detailed and precise knowledge than ”Alias”.
”Perez” protocols (including field description, anal-
ysis and other techniques) seem to be more reliable
than ”Alias” ones.
5 CONCLUSIONS
We have seen how large databases can be divided into
homogeneous subsets defining one or more discrim-
inant attributes. This division, followed by a knowl-
edge discovery process, can allow us to discover pre-
viously unnoticed relations in data.
We conclude that, for this particular case, knowl-
edge extracted by means of fuzzy data mining was
more suitable to ”fusion” or comparison with ex-
pert knowledge that crisp. Moreover, fuzzy data
mining was sensitive to low support categories as
[%OrganicCarbon = Low] or [HorizonT ype =
Bk or Btk], discarded in crisp data mining.
We could confirm that fuzzy data mining is highly
sensitive to latent knowledge in ASDBs. That fact is
very important for a soil scientist, since lets us apply
it with the assurance that imprecision and uncertainty
factors (IFASDB) will not distort or alter the knowl-
edge discovery process.
As a future task, we propose to solve this same
problem in a general case. With a domain expert aid,
we must define the set of criteria for database decom-
position but also discern when fuzzy techniques get
better results than crisp ones.
REFERENCES
Agrawal, R., Imielinski, T., and Swami, A. (1993). Min-
ing association rules between sets of items in large
databases. In Proc. Of the 1993 ACM SIGMOD Con-
ference, pages 207–216.
Alias, J. (1986). Mapa de suelos de Mula. Mapa 1:100000
y memoria. LUCDEME; MAPA-ICONA-University
of Murcia.
Alias, J. (1987). Mapa de suelos de Cehegin. Mapa
1:100000 y memoria. LUCDEME; MAPA-ICONA-
University of Murcia.
Berzal, F., Blanco, I., S
´
anchez, D., Serrano, J., , and Vila,
M. (2003). A definition for fuzzy approximate depen-
dencies. Fuzzy Sets and Systems. Submitted.
Berzal, F., Blanco, I., S
´
anchez, D., and Vila, M. (2001). A
new framework to assess association rules. In Hoff-
mann, F., editor, Advances in Intelligent Data Anal-
ysis. Fourth International Symposium, IDA’01. Lec-
ture Notes in Computer Science 2189, pages 95–104.
Springer-Verlag.
Berzal, F., Blanco, I., S
´
anchez, D., and Vila, M. (2002).
Measuring the accuracy and interest of association
rules: A new framework. Intelligent Data Analysis.
An extension of (Berzal et al., 2001), submitted.
Blanco, I., Mart
´
ın-Bautista, M., S
´
anchez, D., and Vila, M.
(2000). On the support of dependencies in relational
databases: strong approximate dependencies. Data
Mining and Knowledge Discovery. Submitted.
Bosc, P. and Lietard, L. (1997). Functional dependencies
revisited under graduality and imprecision. In Annual
Meeting of NAFIPS, pages 57–62.
Bui, E. and Moran, C. (2003). A strategy to fill gaps
in soil over large spatial extents: An example from
the murray-darlin basin of australia. Geoderma, 111,
pages 21–44.
Cazemier, D., Lagacherie, P., and R., M.-C. (2001). A pos-
sibility theory approach from estimating available wa-
ter capacity from imprecise information contained in
soil databases. Geoderma, 103, pages 113–132.
Delgado, G., Delgado, R., Gamiz, E., P
´
arraga, J.,
S
´
anchez Mara
˜
non, M., Medina, J., and Mart
´
ın-Garc
´
ıa,
J. (1991). Mapa de Suelos de Vera. LUCDEME,
ICONA-Universidad de Granada.
AN EXPERIENCE IN MANAGEMENT OF IMPRECISE SOIL DATABASES BY MEANS OF FUZZY ASSOCIATION
RULES AND FUZZY APPROXIMATE DEPENDENCIES
143

Delgado, M., Mar
´
ın, N., S
´
anchez, D., and Vila, M. (2003).
Fuzzy association rules: General model and applica-
tions. IEEE Transactions on Fuzzy Systems 11(2),
pages 214–225.
Delgado, M., Mart
´
ın-Bautista, M., S
´
anchez, D., and Vila,
M. (2000). Mining strong approximate dependen-
cies from relational databases. In Proceedings of
IPMU’2000.
FAO (1998). The world reference base for soil re-
sources. world soil resources. Technical Report 84,
ISSS/AISS/IBG/ISRIC/FAO, Rome.
Hussain, F., Liu, H., Tan, C., and Dash, M. (1999). Dis-
cretization: An enabling technique. Technical report,
The National University of Singapore.
Oyonarte, C. (1990). Estudio Ed
´
afico de la Sierra de G
´
ador
(Almera). Evaluaci
´
on para usos forestales. PhD the-
sis, University of Granada.
P
´
erez Pujalte, A. (1987). Mapa de suelos de Tabernas.
Mapa 1:100000 y memoria. LUCDEME; MAPA-
ICONA-CSIC.
P
´
erez Pujalte, A. (1989). Mapa de suelos de Sorbas. Mapa
1:100000 y memoria. LUCDEME; MAPA-ICONA-
CSIC.
Qian, H., Klinka, K., and Lavkulich, L. (1993). Relation-
ships between color value and nitrogen in forest min-
eral soils. Can. J. Soil Sci., 73, pages 61–72.
S
´
anchez, D., S
´
anchez, J. R., Serrano, J. M., and Vila, M. A.
(2004). Association rules over imprecise domains in-
volving fuzzy similarity relations. To be submitted to
Estylf 2004.
S
´
anchez-Mara
˜
n
´
on, M. (1992). Los suelos del Macizo de
Sierra Nevada. Evaluaci
´
on y capacidad de uso (in
Spanish). PhD thesis, University of Granada.
S
´
anchez-Mara
˜
n
´
on, M., Delgado, R., P
´
arraga, J., and Del-
gado, G. (1996). Multivariate analysis in the quanti-
tative evaluation of soils for reforestation in the sierra
nevada (southern spain). Geoderma, 69, pages 233–
248.
Scheinost, A. and Schwertmann, U. (1999). Color identi-
fication of iron oxides and hydroxisulfates: Uses and
limitations. Soil Sci. Soc. Am. J., 65, pages 1463–
1461.
Serrano, J. (2003). Fusin de Conocimiento en Bases
de Datos Relacionales: Medidas de Agregacin y
Resumen (in Spanish). PhD thesis, University of
Granada.
Shortliffe, E. and Buchanan, B. (1975). A model of inexact
reasoning in medicine. Mathematical Biosciences, 23,
pages 351–379.
Soil-Survey-Staff (1975). Soil Taxonomy. U.S. Dept. Agri.
Handbook No. 436.
Ulery, A. and Graham, R. (1993). Forest-fire effects on soil
color and texture. Soil Sci. Soc. Am. J., 57, pages 135–
140.
Webster, R. (1977). Quantitative and Numerical Methods
in Soil Classification and Survey. Claredon Press, Ox-
ford.
Zadeh, L. (1983). A computational approach to fuzzy quan-
tifiers in natural languages. Computing and Mathe-
matics with Applications, 9(1):149–184.
Table 1: Discriminant attributes for the soil database
Mesoenvironment Soil profile Horizon
Sierra Nevada [SN] 35 103
Sierra G
´
ador[SB] 70 176
Southeast [SE] 89 262
Bibliographic source Soil profile Horizon
Ph.D. Thesis [MARA
˜
NON] 35 103
Ph.D. Thesis [OYONARTE] 70 176
LUCDEME sheet 1014, Vera.[VERA] 29 76
LUCDEME sheet 1030, Tabernas.
[TABERNA]
14 37
LUCDEME sheet 1031, Sorbas. [SOR-
BAS]
24 72
LUCDEME sheet 912, Cehegn. [CEHE-
GIN]
10 32
LUCDEME sheet 911, Mula. [MULA] 12 45
Acting protocol Soil profile Horizon
S
´
anchez-Mara
˜
non, M. [SANCHEZ] 35 103
Oyonarte, C. [CECILIO] 70 176
P
´
erez-Pujalte, A. [PEREZ] 67 185
Al
´
ıas, L. [ALIAS] 22 77
Table 2: Obtained CF in ASDB (HorizonT ype →
%OrganicCarbon)
Approx. Dep. CF 0.09
Assoc. Rules [C] ⇒ [L], CF 0.8
[Bw] ⇒ [L], CF 0.7
[Ah] ⇒ [L], CF -0.39
[Ah] ⇒ [M ], CF 0.41
F. Approx. Dep. CF 0.31
F. Assoc. Rules [Ck] ⇒ [L], CF 0.53
[C] ⇒ [L], CF 0.69
[Bwk] ⇒ [L], CF 0.23
[Bw] ⇒ [L], CF 0.41
[Bw] ⇒ [M], CF 0.25
[Btk] ⇒ [L], CF 0.81
[Bt] ⇒ [L], CF 1
[Bk] ⇒ [L], CF 0.49
[Ap] ⇒ [L], CF 0.50
[Ah] ⇒ [L], CF -0.01
[Ah] ⇒ [M ], CF 0.13
[Ah] ⇒ [H], CF 0.28
ICEIS 2004 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
144
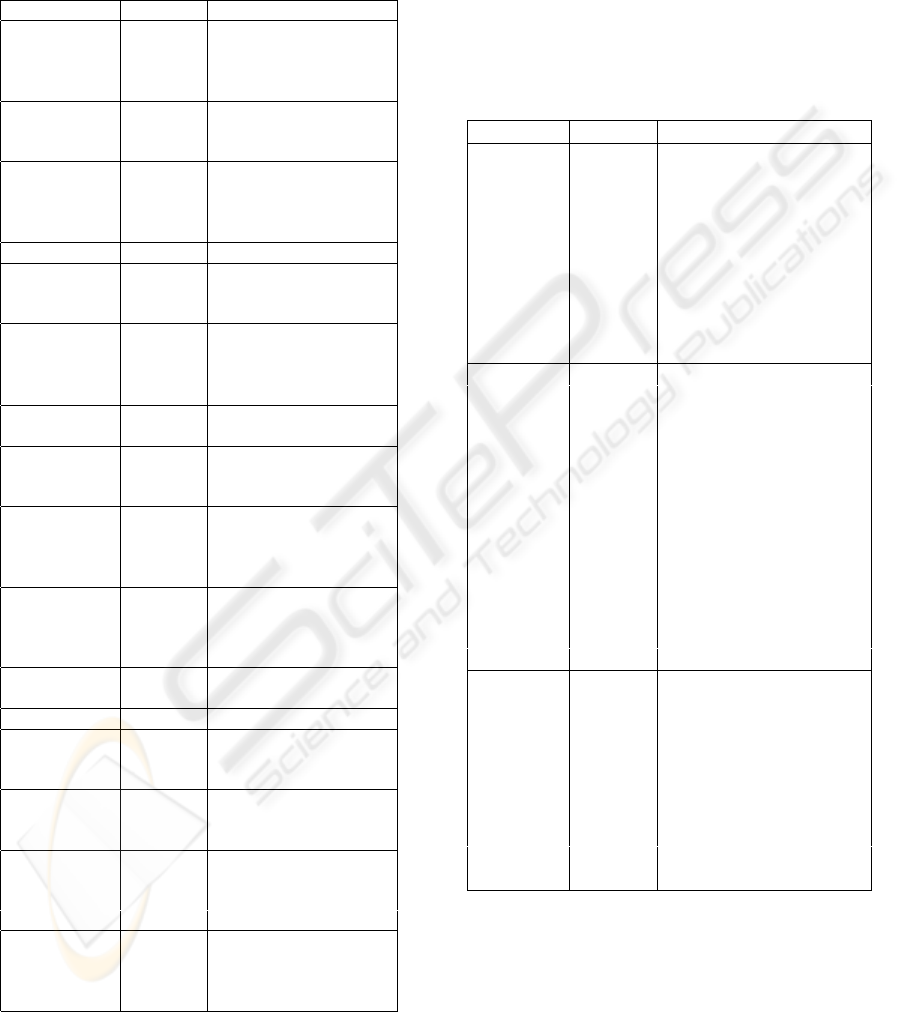
Table 3: Obtained CF in crisp LSDB (HorizonT ype →
%OrganicCarbon)
Mesoenv. AD AR
[Ap] ⇒ [L], CF 0.56
SE CF 0.01 [Bw] ⇒ [L], CF 0.81
[Ah] ⇒ [L], CF -0.19
[Ah] ⇒ [M ], CF 0.23
[Bw] ⇒ [L], CF 0.65
SB CF 0.37 [Ah] ⇒ [L], CF -0.58
[Ah] ⇒ [M ], CF 0.57
[C] ⇒ [L], CF 1
SN CF 0.11 [Bw] ⇒ [L], CF 1
[Ah] ⇒ [L], CF -0.35
[Ah] ⇒ [M ], CF 0.35
Bib. source AD AR
[Ck] ⇒ [L], CF -0.15
CEHEGIN CF 0.12 [Ap] ⇒ [L], CF 1
[Ah] ⇒ [L], CF -0.32
[C] ⇒ [L], CF 1
MARA
˜
NON CF 0.11 [Bw] ⇒ [L], CF 1
[Ah] ⇒ [L], CF -0.35
[Ah] ⇒ [M ], CF 0.35
[C] ⇒ [L], CF 1
MULA CF 0.73 [Ap] ⇒ [L], CF 1
[Bw] ⇒ [L], CF 0.65
OYONARTE CF 0.37 [Ah] ⇒ [L], CF -0.58
[Ah] ⇒ [M ], CF 0.57
[C] ⇒ [L], CF 1
SORBAS CF -0.01 [Bw] ⇒ [L], CF 1
[Ap] ⇒ [L], CF -0.07
[Ah] ⇒ [M ], CF -0.02
[C] ⇒ [L], CF -0.03
TABERNAS CF -0.02 [Bw] ⇒ [L], CF 1
[Ap] ⇒ [L], CF -0.13
[Ah] ⇒ [L], CF -0.01
[C] ⇒ [L], CF 0.5
VERA CF 0.07 [Ap] ⇒ [L], CF -0.23
Acting prot. AD AR
[Ck] ⇒ [L], CF -0,23
ALIAS CF 0.53 [Ck] ⇒ [L], CF 1
[Ck] ⇒ [L], CF 1
[Bw] ⇒ [L], CF 0.65
CECILIO CF 0.37 [Ah] ⇒ [L], CF -0.58
[Ah] ⇒ [M ], CF 0.57
[C] ⇒ [L], CF 1
SANCHEZ CF 0.11 [Bw] ⇒ [L], CF 1
[Ah] ⇒ [L], CF -0.35
[Ah] ⇒ [M ], CF 0.35
[C] ⇒ [L], CF 0.41
PEREZ CF -0.04 [Bw] ⇒ [L], CF 0.81
[Ah] ⇒ [L], CF -0.16
[Ah] ⇒ [M ], CF 0.19
Table 4: Obtained CF in fuzzy LSDB (HorizonT ype →
%OrganicCarbon) (i)
Mesoenv. FAD FAR
[Ck] ⇒ [L], CF 0.54
SE CF 0.38 [C] ⇒ [L], CF 0.73
[Bwk] ⇒ [L], CF 0.43
[Bw] ⇒ [L], CF 0.80
[Btk] ⇒ [L], CF 0.88
[Bt] ⇒ [L], CF 0.61
[Bk] ⇒ [L], CF -0.03
[Ap] ⇒ [L], CF 0.66
[Ah] ⇒ [L], CF 0.23
[Ah] ⇒ [M ], CF 0.18
[C] ⇒ [M ], CF -0.05
SB CF 0.35 [C] ⇒ [H], CF -0.05
[Bwk] ⇒ [M], CF 0.57
[Bwk] ⇒ [H], CF 0.06
[Btk] ⇒ [M], CF -0.05
[Btk] ⇒ [H], CF -0.05
[Bw] ⇒ [M], CF 0.48
[Bw] ⇒ [H], CF 0.11
[Bt] ⇒ [M], CF 0.31
[Bt] ⇒ [H], CF -0.05
[Ap] ⇒ [M ], CF 0.30
[Ap] ⇒ [H], CF -0.05
[Ah] ⇒ [M ], CF 0.07
[Ah] ⇒ [H], CF 0.37
[Ck] ⇒ [L], CF 0.80
SN CF 0.34 [C] ⇒ [L], CF 0.72
[Bwk] ⇒ [L], CF 0.81
[Bw] ⇒ [L], CF 0.41
[Bw] ⇒ [M], CF 0.30
[Bt] ⇒ [L], CF -0.01
[Ap] ⇒ [L], CF -0.01
[Ah] ⇒ [L], CF 0.26
[Ah] ⇒ [M ], CF 0.15
[Ah] ⇒ [H], CF 0.05
AN EXPERIENCE IN MANAGEMENT OF IMPRECISE SOIL DATABASES BY MEANS OF FUZZY ASSOCIATION
RULES AND FUZZY APPROXIMATE DEPENDENCIES
145

Table 5: Obtained CF in fuzzy LSDB (HorizonT ype →
%OrganicCarbon) (ii)
Bib. source FAD FAR
[Ck] ⇒ [L], CF 0.55
CEHEGIN CF 0.52 [C] ⇒ [L], CF 0.80
[Bwk] ⇒ [L], CF 0.85
[Bw] ⇒ [L], CF 0.85
[Ap] ⇒ [L], CF 0.34
[Ap] ⇒ [M ], CF 0.26
[Ah] ⇒ [L], CF 0.09
[Ah] ⇒ [M ], CF 0.48
[Ck] ⇒ [L], CF 0.77
MULA CF 0.72 [C] ⇒ [L], CF 0.81
[Bwk] ⇒ [L], CF -0.03
[Bw] ⇒ [L], CF -0.03
[Ap] ⇒ [L], CF 0.80
[Ah] ⇒ [L], CF 0.33
[Ck] ⇒ [L], CF 0.96
SORBAS CF 0.65 [C] ⇒ [L], CF 0.96
[Bw] ⇒ [L], CF 0.95
[Bt] ⇒ [L], CF 0.96
[Ap] ⇒ [L], CF 0.85
[Ah] ⇒ [L], CF 0.66
[Ck] ⇒ [L], CF 0.93
TABERNAS CF 0.52 [C] ⇒ [L], CF 0.78
[Bwk] ⇒ [L], CF 0.93
[Bw] ⇒ [L], CF 0.91
[Bt] ⇒ [L], CF 0.93
[Ap] ⇒ [L], CF 0.72
[Ah] ⇒ [M ], CF 0.52
[Ck] ⇒ [M ], CF 0.79
VERA CF 0.25 [C] ⇒ [L], CF 0.44
[Bwk] ⇒ [L], CF 0.77
[Bw] ⇒ [L], CF 0.60
[Btk] ⇒ [L], CF 0.78
[Bt] ⇒ [L], CF 0.24
[Bt] ⇒ [M], CF 0.37
[Ap] ⇒ [L], CF 0.45
[Ap] ⇒ [M ], CF 0.14
[Ah] ⇒ [L], CF 0.05
[Ah] ⇒ [M ], CF 0.16
[Ah] ⇒ [H], CF 0.23
Table 6: Obtained CF in fuzzy LSDB (HorizonT ype →
%OrganicCarbon) (iii)
Acting prot. FAD FAR
[Ck] ⇒ [L], CF 0.50
ALIAS CF 0.61 [C] ⇒ [L], CF 0.85
[Bwk] ⇒ [L], CF 0.44
[Bw] ⇒ [L], CF 0.44
[Ap] ⇒ [L], CF 0.62
[Ah] ⇒ [L], CF 0.19
[Ah] ⇒ [M ], CF 0.33
[Ck] ⇒ [L], CF 0.57
PEREZ CF 0.33 [C] ⇒ [L], CF 0.66
[Bwk] ⇒ [L], CF 0.43
[Bw] ⇒ [L], CF 0.82
[Btk] ⇒ [L], CF 0.87
[Bt] ⇒ [L], CF 0.60
[Bk] ⇒ [L], CF -0.01
[Ap] ⇒ [L], CF 0.67
[Ah] ⇒ [L], CF 0.25
[Ah] ⇒ [M ], CF 0.15
[Ah] ⇒ [H], CF 0.24
ICEIS 2004 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
146
