
LANGUAGE MODEL BASED ON POS TAGGER
Bartosz Zi
´
ołko, Suresh Manandhar, Richard C. Wilson
Department of Computer Science, University of York, U.K.
Mariusz Zi
´
ołko
Department of Electronics, AGH University of Science and Technology, Krak
´
ow, Poland
Keywords:
POS-tagging, language modelling, speech recognition, Polish.
Abstract:
Language models are necessary for any large vocabulary speech recogniser. There are two main types of
information which can be used to support modelling a language: syntactic and semantic. One of the ways to
apply syntactic modelling is to use POS taggers. Morphological information can be statistically analysed to
provide probability of a sequence of words using their POS tags. The results for Polish language modelling
are presented.
1 INTRODUCTION
Part-of-speech (POS) (Brill, 1995) tagging is the pro-
cess of marking up the words as corresponding to
a particular part of speech, based on both its def-
inition, as well as its context, using their relation-
ship with other words in a phrase, sentence, or para-
graph (Brill, 1995; Cozens, 1998). POS tagging is
more than providing a list of words with their parts
of speech, because many words represent more than
one part of speech at different times. The first ma-
jor corpus of English for computer analysis was the
Brown Corpus (Kucera and Francis, 1967). It con-
sists of about 1,000,000 words, made up of 500 sam-
ples from randomly chosen publications. In the mid
1980s, researchers in Europe began to use HMMs to
disambiguate parts of speech, when working to tag
the Lancaster-Oslo-Bergen Corpus (Johansson et al.,
1978). HMMs involve counting cases and making a
table of the probabilities of certain sequences. For ex-
ample, once an article has been recognised, the next
word is a noun with probability of 40%, an adjective
with 40%, and a number with 20%. Markov Models
are a common method for assigning POS tags. The
methods already discussed involve operations on a
pre-existing corpus to find tag probabilities. Unsuper-
vised tagging is also possible by bootstraping. Those
techniques use an untagged corpus for their training
data and produce the tagset by induction. That is,
they observe patterns in word structures, and pro-
vide POS types. These two categories can be fur-
ther subdivided into rule-based, stochastic, and neu-
ral approaches. Some current major algorithms for
POS tagging include the Viterbi algorithm, the Brill
tagger (Brill, 1995), and the Baum-Welch algorithm
(also known as the forward-backward algorithm). The
HMM and visible Markov model taggers can both be
implemented using the Viterbi algorithm.
POS tagging of Polish was started by govern-
mental research institute IPI PAN. They created a
relatively large corpus which is partly hand tagged
and partly automatically tagged (Przepi
´
orkowski,
2004; A.Przepi
´
orkowski, 2006; De¸bowski, 2003;
Przepi
´
orkowski and Woli
´
nski, 2003). The tagging
was later improved by focusing on hand-written and
automatically acquired rules rather than trigrams by
Piasecki (Piasecki, 2006). The best and latest version
of the tagger has accuracy 93.44%.
2 APPLYING POS TAGGERS FOR
LANGUAGE MODELLING IN
SPEECH RECOGNITION
There is little interest in using POS tags in ASR. Their
usefulness was investigated. POS tags trigrams, a ma-
trix grading possible neighbourhoods or probabilistic
tagger can be created and used to predict a word being
recognised based on left context analysed by a tagger.
It is very difficult to provide tree structures, necessary
for context-free grammars, which represent all possi-
ble sentences in case of Polish, as the order of words
can vary significantly. Some POS tags are much more
177
Ziółko B., Manandhar S., C. Wilson R. and Ziółko M. (2008).
LANGUAGE MODEL BASED ON POS TAGGER.
In Proceedings of the International Conference on Signal Processing and Multimedia Applications, pages 177-180
DOI: 10.5220/0001931701770180
Copyright
c
SciTePress
0−0.1 0.1−0.2 0.2−0.3 0.3−0.4 04−0.5 0.5−0.6 0.6−0.7 0.7−0.8 0.8−0.9 0.9−1
0
20
40
60
80
100
120
140
160
180
probability
counts
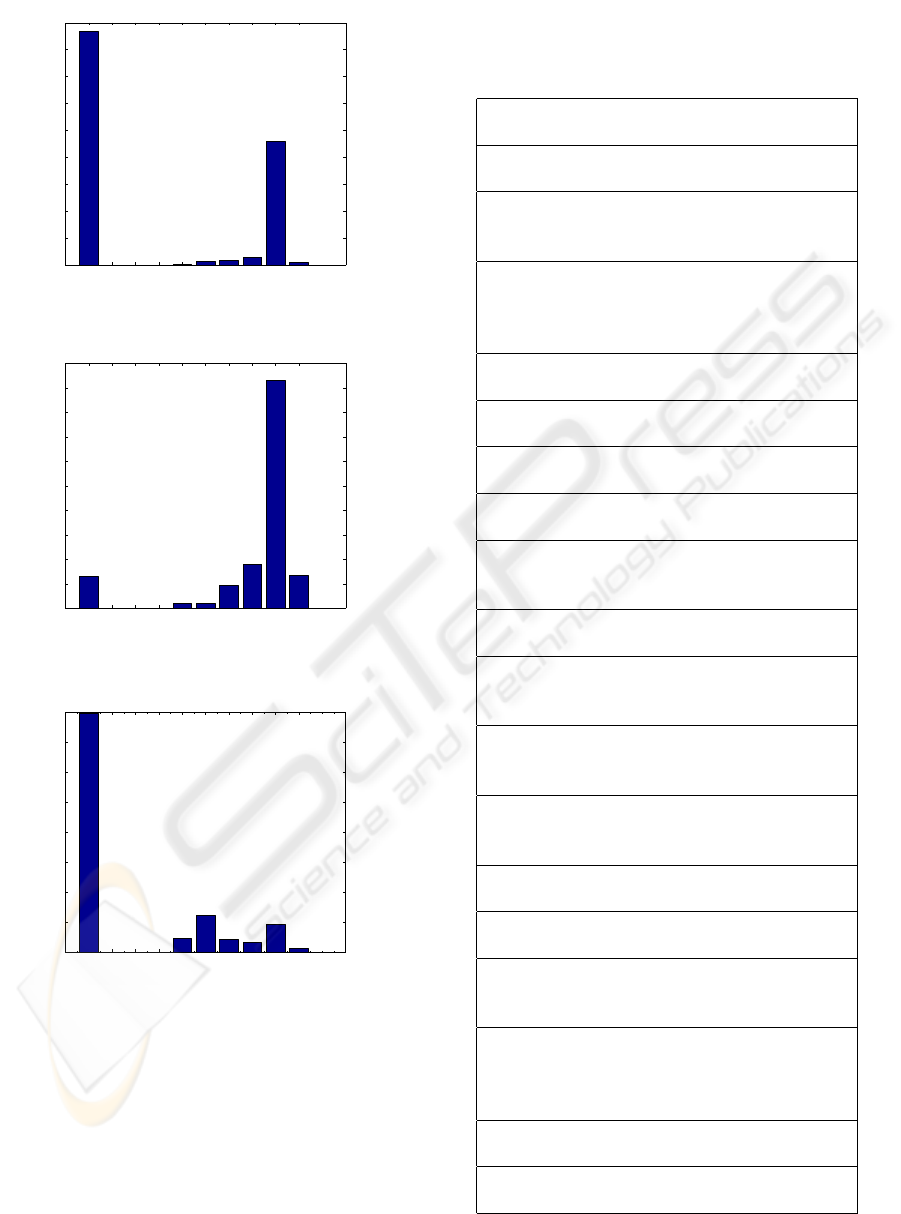
Histogram of probabilities for correct hypotehsis
Figure 1: Histogram of POS tagger probabilities for hy-
potheses which are correct recognitions.
0−0.1 0.1−0.2 0.2−0.3 0.3−0.4 0.4−0.5 0.5−0.6 0.6−0.7 0.7−0.8 0.8−0.9 0.9−1
0
200
400
600
800
1000
1200
1400
1600
1800
2000
probability
counts
Histogram of probabilities of hypothesis with wrong recognitions
Figure 2: Histogram of POS tagger probabilities for hy-
potheses which are wrong recognitions.
0−0.1 0.1−0.2 0.2−0.3 0.3−0.4 0.4−0.50.5−0.6 0.6−0.7 0.7−0.8 0.8−0.9 0.9−1
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
probability
ratio
Ratio of correct hypothesis to all hypothesis
Figure 3: Ratio of correct recognitions to all for different
probabilities from POS tagger.
probable in context of some others, which can be used
in language modelling.
Experiments on applying morphological informa-
tion to ASR of Polish language were undertaken us-
ing the best available POS tagger for Polish (Piasecki,
2006; Przepi
´
orkowski, 2004). The results were unsat-
isfying, probably because to high ambiguity. An aver-
age word in Polish has two POS tags which gives too
many possible combinations for a sentence. Briefly
Table 1: Results od applying the POS tagger to language
modelling. First, a sentence in Polish is given, then a posi-
tion of a correct recognition in a 10 best list. The description
of tagger grade for the correct recognition follows.
Lubi
´
c czardaszowy pla¸s
1, Tagger grade is very low.
Cudzy brzuch i buzia w drzewie
4, Tagger grade is higher than for wrong recognitions.
Krociowych sum nie
˙
zal mi
1, Tagger grade is higher or similar then
other recognitions in top 6 but lower then 7th.
M
´
oc czu
´
c ka
˙
zdy odczynnik
6, Tagger grade is lower than for most of the wrong
recognitions including first two. However, the highest
probability wrong recognition is grammatically correct.
On łom kładzie lampy i kołpak
7, Tagger grade is low.
On liczne ta
´
smy w cuglach da
2, Tagger grade low but the highest in the first 5 hypoth.
W
´
or rur
˙
zelaznych wa
˙
zył
3, Tagger grade is lower than for the first sentence.
Bo
´
s cały w wi
´
sniowym soku
3, Tagger grade is higher then for 7 top hypotheses.
Lech by
´
c podlejszym chce
1, Tagger grade is the lowest in top 5 hypotheses but
most of them are grammatically correct.
˙
Zre je
˙
z zioła jak d
˙
zem John
1, Tagger grade is higher than for top 4 hypotheses.
Masz dzisiaj r
´
o
˙
zyczke¸ zielona¸
1, Tagger grade is lower than for the second hypothesis
which has no sense but morphologicaly is correct.
We
´
z daj im soli drogi dyzmo
2, Tagger grade is very close to the most probable
hypothesis, which is grammatically correct.
We
´
z masz ramki opolskie
1, Tagger grade is higher than for the second hypothesis
but lower than for the third one.
D
´
zgna¸ł nas cicho pod zamkiem
1, Tagger grade is highest of all.
Tam
´
spi wojsko z bronia¸
6, Tagger grade is second, the highest one is 5th.
Nie odchod
´
z bo
˙
zona idzie
3, Tagger grade is highest but equal to three others,
which has acoustical probability lower.
Tym mo
˙
zna atakowa
´
c
5, Tagger grade is higher than for the acoustically most
probable sentence but lower than for all other between
1 and 5, however all of them are grammatically correct.
Zmy
´
slny kot psotny ujdzie
1, Tagger grade is higher then 2nd and 3rd hypothesis.
Niech pan sunie na wsch
´
od
4, Tagger grade is higher than for 7 most probable.
SIGMAP 2008 - International Conference on Signal Processing and Multimedia Applications
178

Table 2: Results od applying the POS tagger on its training
corpus. First version of a sentence is a correct one, second
is a recognition using just HTK and third one using HTK
and POS tagging.
htk is better
skine¸ła głowa¸ zawstydzona
skine¸ła głowa¸ zawstydzona
skine¸ła bo w w w zawstydzona
pole
˙
z teraz spokojnie
pole
˙
z teraz spokojnie
pole
˙
z z teraz spokojnie
pamie¸tasz
˙
ze opu
´
sciła sanktuarium
pamie¸ta
˙
ze opu
´
sciła sanktuarium
pamie¸ta
˙
ze opu
´
sciła sanktuarium w
o tak pamie¸tała wszystko powr
´
ociło z pełna¸ wyrazisto
´
scia¸
o tak pamie¸ta wszystko powr
´
ociło pełna¸ wyrazisto
´
scia¸
o tak w pamie¸ta wszystko powr
´
ociło pełna¸ wyrazisto
´
scia¸
same
nie m
´
owia¸c o tym kim ja jestem
nie w wiem nocy nocy nie jestem
nie w wiem nocy nocy nie jestem
zasłonie¸ okno bo widze¸
˙
ze
´
swiatło cie¸ razi
zasłonie¸ o okno bo widze¸ cie¸
´
swiatło cie¸ razi
zasłonie¸ o okno bo widze¸ cie¸
´
swiatło cie¸ razi
zobaczysz wszystko be¸dzie dobrze
zobaczysz wszystko be¸dzie dobrze
zobaczysz wszystko be¸dzie dobrze
speaking applying POS tagging for modelling of Pol-
ish is a process of guessing based on uncertain infor-
mation.
HTK (Young, 1996; Young et al., 2005) was used
to provide 10 best list of acoustic hypotheses for sen-
tences from CORPORA. This model was trained in a
way which allowed all possible combinations of all
words in a dictionary. Then probabilities of those hy-
potheses using the POS tagger (Piasecki, 2006) were
calculated. Acoustic model can be easily combined
with language models using Bayes’ rule by multiply-
ing both probabilities.
3 EXPERIMENTAL RESULTS
Our experiments were conducted applying HTK on
a corpus called CORPORA, created under supervision
of Stefan Grocholewski in Institute of Computer Sci-
ence, Pozna
´
n University of Technology in 1997 (Gro-
cholewski, 1995). Speech files in CORPORA were
recorded with the sampling frequency f
0
= 16 kHz
equivalent to sampling period t
0
= 62.5 µs. Speech
was recorded in an office with a working computer in
the background which makes the corpus not perfectly
clean. SNR (Signal to Noise Ratio) is not stated in
the description of the corpus. It can be assumed that
SNR is very high for actual speech but minor noise is
detectable for periods of silence. The database con-
tains 365 utterances (33 single letters, 10 digits, 200
names, 8 short computer commands and 114 simple
sentences), each spoken by 11 females, 28 males and
6 children (45 people), giving 16425 utterances in to-
tal. One set spoken by a male and one by a female
were hand segmented. The rest were segmented by
a dynamic programming algorithm which was trained
on hand segmented ones. None of the CORPORA ut-
terances were in the original set used during develop-
ment.
Trigrams of tags were calculated using transcrip-
tions of spoken language and existing tagging tools.
Results were saved in XML.
The results were compared giving different
weights for probabilities from HTK acoustic model
and POS tagger language model. In all situations
the outcome probability gave worse results then pure
HTK model. Histograms of probabilities for correct
and wrong recognition were also calculated and they
showed unuseful correlation. Some examples of sen-
tences were also analysed and described by human
supervisor. They are presented in Table 1.
In total 331 occurrences were analysed. Only 282
of them had correct recognition in the whole 10 best
list of a given utterence. An average HTK probability
of correct sentences was 0.1105. Exactly 244 of all
occurrences had a correct hypothesis on the 1 posi-
tion of the 10 best list. 0.7372 % of occurrences were
correctly recognised while using only HTK acous-
tic model. Only 53 occurrences were recognised ap-
plying probabilities from the POS tagger, even when
HTK probabilities were 4 times more important than
those from POS tagger. The weight was applied by
raising HTK probability to power of 4. It gives 0.1601
% of correct recognitions for a model with POS tag
probabilities, which is a disapointing result.
Another way of proving usefulness of a model
is through calculating histograms p
posc
of probabil-
ities received from the tagger for hypotheses which
are correct recognitions (Fig. 1) and histogram p
posw
of probabilities received from semantic model for hy-
potheses which are wrong recognitions (Fig. 2). The
ratio p
posc
/(p
posc
+ p
posw
) is presented in Fig. 3. It
shows that there is no correlation between high prob-
ability from the tagger and correctness of recognition.
The POS tagger was trained on a different cor-
pus than the one used in an experiment described
above. This is why we decided to conduct an addi-
tional experiment. We recorded 11 sentences from the
POS tagger training corpus. They were recognised
LANGUAGE MODEL BASED ON POS TAGGER
179

by HTK, providing 10 best list and used in a similar
experiment as the one described above. The amount
of data is not enough to provide statistical results but
observations on exact sentences (Table 2 ) provide
the same conclusion as in the main experiment. The
recognitions, which were found using HTK only, had
fewer errors for 6 sentences. then 5 times the number
of errors was the same. One sentence was correctly
recognised for both models. One more was correctly
recognised using just HTK acoustic model.
4 RECOGNITION USING
LANGUAGE MODEL
Recognition can be conducted by finding the most co-
herent set of POS tags in a provided hypothesis. The
tagger calculates P
pos
, which can be used as additional
weight in providing speech recognition due to Bayes’
theorem. The values of p
htk
probability gained from
HTK model tend to be very similar for all hypotheses
in the 10 best list of a particular utterance. This is why
an extra weighting w was introduced to favour proba-
bilities from audio model over p
pos
received from the
tagger. The final measure can be obtained applying
Bayes’ rule
p = p
w
htk
p
pos
. (1)
Bayes rule is often used to compute posterior
probabilities given observations. It can be used to
compute the probability that a proposed hypothesis
is correct, given an observation. It is often applied
to combine probabilities of different models. p
htk
is
a probability of acoustic units given a word and p
pos
is a probability of word. There should division by a
probability of acoustic for normalisation purposes. It
can be skipped as long as we deliver normalisation in
another way or we accept the fact that final result is
not a probability function, as it does not take values
from 0 to 1. We can easily accept it if we are inter-
ested only in argument of a maximum of the result
and we do not need proper probability values. Ap-
plying some linguistical data in speech recognition is
necessary because acoustic models are not effective
enough. However, the model based on POS tagger
seems to not solve the issue.
5 CONCLUSIONS
It seems that POS tags are too ambiguous to be used
effectively in modelling Polish for ASR. Another
source of linguistical data has to be used to provide
effective language model.
ACKNOWLEDGEMENTS
We received a significant help from Maciej Piasecki
from the Technical University of Wrocław by provid-
ing tagger output and from Stefan Grocholewski from
technical University of Poznan by letting us experi-
ment on CORPORA.
REFERENCES
A.Przepi
´
orkowski (2006). The potential of the IPI PAN
corpus. Pozna
´
n Studies in Contemporary Linguistics,
41:31–48.
Brill, E. (1995). Transformation-based error-driven learn-
ing and natural language processing: A case study in
part of speech tagging. Computational Linguistics,
December:543–565.
Cozens, S. (1998). Primitive part-of-speech tagging using
word length and sentential structure. Computaion and
Language.
De¸bowski, Ł. (2003). A reconfigurable stochastic tagger for
languages with complex tag structure. The Proceed-
ings of the Workshop on Morphological Processing of
Slavic Languages, EACL.
Grocholewski, S. (1995). Zało
˙
zenia akustycznej bazy
danych dla je¸zyka polskiego na no
´
sniku cd rom (eng.
Assumptions of acoustic database for Polish lan-
guage). Mat. I KK: Głosowa komunikacja człowiek-
komputer, Wrocław, pages 177–180.
Johansson, S., Leech, G., and Goodluck, H. (1978). Man-
ual of Information to Accompany the Lancaster-
Olso/Bergen Corpus of British English, for Use with
Digital Computers. Department of English, Univer-
sity of Oslo.
Kucera, H. and Francis, W. (1967). Computational Analysis
of Present Day American English. Brown University
Press Providence.
Piasecki, M. (2006). Hand-written and automatically ex-
tracted rules for polish tagger. Lecture Notes in Arti-
ficial Intelligence, Springer, W P. Sojka, I. Kopecek,
K. Pala, eds. Proceedings of Text, Speech, Dialogue
2006:205–212.
Przepi
´
orkowski, A. (2004). The IPI PAN Corpus: Prelimi-
nary version. IPI PAN.
Przepi
´
orkowski, A. and Woli
´
nski, M. (2003). The unbear-
able lightness of tagging: A case study in morphosyn-
tactic tagging of Polish. Proceedings of the 4th Inter-
national Workshop on Linguistically Interpreted Cor-
pora (LINC-03), EACL 2003.
Young, S. (1996). Large vocabulary continuous speech
recognition: a review. IEEE Signal Processing Maga-
zine, 13(5):45–57.
Young, S., Evermann, G., Gales, M., Hain, T., Kershaw, D.,
Moore, G., Odell, J., Ollason, D., Povey, D., Valtchev,
V., and Woodland, P. (2005). HTK Book. Cambridge
University Engineering Department, UK.
SIGMAP 2008 - International Conference on Signal Processing and Multimedia Applications
180
