
ON THE EVOLUTION OF SEARCH ENGINE RANKINGS
Panagiotis Takis Metaxas
Computer Science Department, Wellesley College, Wellesley, MA02481, U.S.A.
Keywords:
Search Engines, Web search, Web graph, Link structure, PageRank, HITS, Web Spam, Social Networks.
Abstract:
Search Engines have greatly influenced the way we experience the web. Since the early days of the web, users
have been relying on them to get informed and make decisions. When the web was relatively small, web
directories were built and maintained using human experts to screen and categorize pages according to their
characteristics. By the mid 1990’s, however, it was apparent that the human expert model of categorizing web
pages does not scale. The first search engines appeared and they have been evolving ever since, taking over
the role that web directories used to play.
But what need makes a search engine evolve? Beyond the financial objectives, there is a need for quality in
search results. Users interact with search engines through search query results. Search engines know that the
quality of their ranking will determine how successful they are. If users perceive the results as valuable and
reliable, they will use it again. Otherwise, it is easy for them to switch to another search engine.
Search results, however, are not simply based on well-designed scientific principles, but they are influenced
by web spammers. Web spamming, the practice of introducing artificial text and links into web pages to affect
the results of web searches, has been recognized as a major search engine problem. It is also a serious users
problem because they are not aware of it and they tend to confuse trusting the search engine with trusting the
results of a search.
In this paper, we analyze the influence that web spam has on the evolution of the search engines and we identify
the strong relationship of spamming methods on the web to propagandistic techniques in society. Our analysis
provides a foundation for understanding why spamming works and offers new insight on how to address it. In
particular, it suggests that one could use social anti-propagandistic techniques to recognize web spam.
1 INTRODUCTION
Search Engines have greatly influenced the way we
experience the web. Since the early days of the web
people have been relying on search engines to find
useful information. When the web was relatively
small, Web directories were built and maintained that
were using human experts to screen and categorize
pages according to their characteristics. By the mid
1990’s, however, it was apparent that the human ex-
pert modelof categorizingweb pages would not scale.
The first search engines appeared and they have been
evolving ever since.
But what influences their evolution? The way
a user interacts with a search engine is through the
search results to a query that he or she has issued.
Search engines know that the quality of their rank-
ing will determine how successful they are. If users
perceive the results as valuable and reliable, they will
come again. Otherwise, it is easy for them to switch
to another search engine.
Research in Information Retrieval has produced a
large body of work that, theoretically, produces high
quality search results. Yet, search engines admit that
IR theory is but one of their considerations. One of
the major issues that influences the quality of ranking
is the effect that web spam has on their results. Web
spamming is defined as the practice of manipulating
web pages in order to influence search engines rank-
ings in ways beneficial to the spammers.
Spammers aim at search engines, but target the
end users. Their motive is usually commercial, but
can also be political or religious.
One of the reasons behind the users’ difficulty
to distinguish trustworthy from untrustworthy infor-
mation comes from the success that both search en-
gines and spammers have enjoyed in the last decade.
Users have come to trust search engines as a means of
finding information, and spammers have successfully
managed to exploit this trust.
200
Metaxas P.
ON THE EVOLUTION OF SEARCH ENGINE RANKINGS.
DOI: 10.5220/0001843102000207
In Proceedings of the Fifth International Conference on Web Information Systems and Technologies (WEBIST 2009) , page
ISBN: 978-989-8111-81-4
Copyright
c
2009 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Some estimates indicate that at least 8% of all
pages indexed is spam (Fetterly et al., 2004) while ex-
perts consider web spamming the single most difficult
challenge web searching is facing today(Henzinger
et al., 2002). Search engines typically see web spam
as an interference to their operations and would like
to restrict it, but there can be no algorithm that can
recognize spamming sites based solely on graph iso-
morphism (Bianchini et al., 2003).
First, however, we need to understand why spam-
ming works beyond the technical details, because
spamming is a social problem first, then a technical
one. In this paper we show its extensive relationship
to social propaganda, and evidence of its influence on
the evolution of search engines. Our approach can
explain the reasons why web spamming has been so
successful and suggest new ways of dealing with it.
Finally, we present a framework for the long-term ap-
proach to web spam.
1.1 Background
Web spamming has received a lot of attention lately
(Bharat et al., 2001; Bianchini et al., 2003; Fetterly
et al., 2004; Fetterly et al., 2003; Gy¨ongyi et al., 2004;
Henzinger, 2001; Henzinger et al., 2002; Introna and
Nissenbaum, 2000; Kumar et al., 1999; Lynch, 2001;
Marchiori, 1997; Pringle et al., 1998). The first papers
to raise the issue were (Marchiori, 1997; Henzinger
et al., 2002). The spammers’ success was noted in
(Bharat et al., 2001; Corey, 2001; Fetterly et al., 2004;
Fetterly et al., 2003; Hindman et al., 2003).
Characteristics of spamming sites based on di-
version from power laws are presented in (Fetterly
et al., 2004). Current tricks employed by spammers
are detailed in (Gy¨ongyi and Garcia-Molina, 2005).
An analysis of the popular PageRank method em-
ployed by many search engines today and ways to
maximize it in a spamming network is described in
(Bianchini et al., 2003). TrustRank, a modification to
the PageRank to take into account the evaluations of
a few seed pages by human editors, employees of a
search engine, is presented in (Gy¨ongyi et al., 2004).
Techniques for identifying automatically link farms
of spam pages were presented in (Wu and Davison,
2005; Bencz´ur et al., 2005).
A comprehensive treatment on social networks is
presented in (Wasserman and Faust, 1994). The con-
nection between the Web and social networks was ex-
plicitly noted in (Raghavan, 2002) and implicitly used
in (Brin and Page, 1998; Kleinberg, 1999). Iden-
tification of web communities was explored in (Ku-
mar et al., 1999; Flake et al., 2002). The effect that
search engines have on page popularity was discussed
in (Cho and Roy, 2004).
The rest of this paper is organized as follows. The
next section gives an overview of the problem of in-
formation reliability and web spamming. Section 3
has a short introduction to the theory of propaganda
detection and the next section 4 discusses the relation-
ship between the webgraph and the trust social net-
work. The following section 5 analyzes the evolution
of search engines as their response to spam. Finally,
the last section has the conclusions and a framework
for the long-term approach to web spam.
2 WEB SPAM
The web has changed the way we inform and get in-
formed. Every organization has a web site and peo-
ple are increasingly comfortable accessing it for in-
formation on any question they may have. The ex-
ploding size of the web necessitated the development
of search engines and web directories. Most peo-
ple with online access use a search engine to get in-
formed and make decisions that may have medical,
financial, cultural, political, security or other impor-
tant implications in their lives (Corey, 2001; Vedder,
2000; Hindman et al., 2003; Lynch, 2001). More-
over, 85% of the time, people do not look past the
first ten results returned by the search engine (Silver-
stein et al., 1999). Given this, it is not surprising that
anyone with a web presence struggles for a place in
the top ten positions of relevant web search results.
The importance of the top-10 placement has given
birth to a new “Search Engine Optimization” industry,
which claims to sell know-how for prominent place-
ment in search results and includes companies, pub-
lications, and even conferences. Some of them are
willing to bend the truth in order to fool the search
engines and their customers, by creating web pages
containing web spam (Fetterly et al., 2004).
Spammers attack search engines through text and
link manipulations:
• Text Spam. This includes repeating text exces-
sively and/or adding irrelevant text on the page
that will cause incorrect calculation of page rele-
vance; adding misleading meta-keywords or irrel-
evant “anchor text” that will cause incorrect appli-
cation of rank heuristics.
• Link Spam. This technique aims to change the
perceived structure of the webgraph in order to
cause incorrect calculation of page reputation.
Such examples are the so-called “link-farms,”
page “awards,”
1
domain flooding (plethora of do-
1
With this technique, the spammer pretends to run an
ON THE EVOLUTION OF SEARCH ENGINE RANKINGS
201

mains that re-direct to a target site), etc.
Both kinds of spam aim to boost the ranking of
spammed web pages. So as not to get caught, spam-
mers conceal their actions through cloacking, content
hiding and redirection. Cloaking, for example, aims
to serve different pages to search engine robots and to
web browsers (users).
For a comprehensive treatment of the spam-
ming techniques, the interested reader is referred to
(Gy¨ongyi and Garcia-Molina, 2005).
Since anyone can be an author on the web, these
practices have naturally created a question of infor-
mation reliability. An audience used to trusting the
written word of newspapers and books is unable, un-
prepared or unwilling to think critically about the in-
formation obtained from the web. A recent study
(Graham and Metaxas, 2003) found that while college
students regard the web as a primary source of infor-
mation, many do not check more than a single source,
and have trouble recognizing trustworthy sources on-
line.
We have no reason to believe that the general pub-
lic will perform any better than well-educated stu-
dents. In fact, a recent analysis of internet related
fraud by a major Wall Street law firm (Corey, 2001)
puts the blame squarely on the questionable critical
thinking skills of the investors for the success of stock
fraud cases.
3 ON PROPAGANDA THEORY
On the outset, it may seem surprising that a technical
article discusses social propaganda. This is a subject
that has been studied extensively by social scientists
and might seem out of the realm of computing. How-
ever, the web is a social network, influenced daily by
the actions (intentional or otherwise) of millions of
people. In that respect, web researchers should be
aware of social theories and practices since they may
have applicability in their work. We believe that a ba-
sic understanding of social propaganda can be valu-
able to technical people designing and using systems
that affect our social interactions.
We offer here a brief introduction to the theory of
propaganda detection.
There are many definitions of propaganda, reflect-
ing its multiple uses over time. One working defini-
tion we will use here is
organization that distributes awards for web site design or
information. The awarded site gets to display the “award”,
an image linking back to awarding organization. The effect
is that the awarded site increases the visibility of the spam-
mer’ site.
Propaganda is the attempt to modify human be-
havior, and thus influence people’s actions in ways
beneficial to propagandists.
Propaganda has a long history in modern soci-
ety and is often associated with negative connotation.
This was not always the case, however. The term was
first used in 1622, in the establishment by the Catholic
Church of a permanent Sacred Congregation de Pro-
paganda Fide (for the propagaton of faith), a depart-
ment which was trying to spread Catholicism in non-
Catholic Countries.Its current meaning comes from
the successful Enemy Propaganda Department in the
British Ministry of Information during WWI. How-
ever, it was not until 1938, in the beginning of WWII,
that a theory was developed to detect propagandistic
techniques. For the purposes of this paper we are in-
terested in ways of detecting propaganda, especially
by automatic means.
First developed by the Institute for Propaganda
Analysis (Lee and Lee(eds.), 1939), classic Propa-
ganda Theory identifies several techniques that pro-
pagandists often employ in order to manipulate per-
ception.
• Name Calling is the practice of giving an idea a
bad label. It is used to make people reject and con-
demn the idea without examining the evidence.
For example, using the term “miserable failure”
to refer to political leaders such as US President
George Bush can be thought of as an application
of name calling.
• Glittering Generalities is the mirror image
2
of
name calling: Associating an idea with a “virtue
word”, in an effort to make us accept and approve
the idea without examining the evidence. For ex-
ample, using the term “patriotic” to refer to illegal
actions is a common application of this technique.
• Transfer is the technique by which the propagan-
dist carries over the authority, sanction, and pres-
tige of something respected and revered to some-
thing he would have us accept. For example, de-
livering a political speech in a mosque or a church,
or ending a political gathering with a prayer have
the effect of transfer.
• Testimonial is the technique of having some re-
spected person comment on the quality of an is-
sue on which they have no qualifications to com-
ment. For example, a famous actor who plays a
medical doctor on a popular TV show tells the
viewers that she only uses a particular pain relief
medicine. The implicit message is that if a famous
personality trusts the medicine, we should too.
2
Name calling and glittering generalities are sometimes
referred to as “word games.”
WEBIST 2009 - 5th International Conference on Web Information Systems and Technologies
202

• Plain Folks is a technique by which speakers at-
tempt to convince their audience that they, and
their ideas, are “of the people,” the “plain folks”.
For example, politicians sometimes are seen flip-
ping burgers at a neighborhood diner.
• Card Stacking involves the selection of facts
(or falsehoods), illustrations (or distractions), and
logical (or illogical) statements in order to give an
incorrect impression. For example, some activists
refer to the Evolution Theory as a theory teaching
that humans came from apes (and not that both
apes and humans have evolved from a common
ancestor who was neither human nor ape).
• Bandwagon is the technique with which the pro-
pagandist attempts to convince us that all mem-
bers of a group we belong to accept his ideas and
so we should “jump on the band wagon”. Often,
fear is used to reinforce the message. For exam-
ple, commercials might show shoppers running to
line up in front of a store before it is open.
The reader should not have much trouble identi-
fying additional examples of such techniques used in
politics or advertising. The next section discusses the
relationship of propaganda to web spam, by first de-
scribing the similarity of social networks to the web
graph.
4 THE WEBGRAPH AS A TRUST
NETWORK
The web is typically represented by a directed graph
(Broder et al., 2000). The nodes in the webgraph are
the pages (or sites) that reside on servers on the in-
ternet. Arcs correspond to hyperlinks that appear on
web pages (or sites). In this context, web spammers’
actions can be seen as altering the contents of the web
nodes (mailnly through text spam), and the hyperlinks
between nodes (mainly through link spam).
The theory of social networks (Wasserman and
Faust, 1994) also uses directed graphs to represent
relationships between social entities. The nodes cor-
respond to social entities (people, institutions, ideas).
Arcs correspond to recommendations between the en-
tities they connect. In this context, propagandistic
techniques can be seen as altering the trust social net-
work by altering one or more of its components (i.e.,
nodes, arcs, weights, topology).
To see the correspondence more clearly, we will
examine some of the propagandistic techniques that
have been used successfully by spammers: The tech-
nique of testimonials effectively adds a link between
previously unrelated nodes. Glittering generalities
change the contents of a node, effectively changing
its perceived relevance. Mislabeled anchor text is an
example of card stacking. And the technique of band-
wagon creates many links between a group of nodes,
a “link farm”. So, we define web spam based on the
spammers actions:
Web Spam is the attempt to modify the web (its
structure and contents), and thus influence search en-
gine results in ways beneficial to web spammers.
Table 1 has the correspondence, in graph theoretic
terms, between the web graph according to a search
engine and the trust social network of a particular per-
son. Web pages or sites correspond to social entities
and hyperlinks correspond to trust opinions. The rank
that a search engine assigns to a page or a site cor-
responds to the reputation a social entity has for the
person. This rank is based on some ranking formula
that a search engine is computing, while the reputa-
tion is based on idiosyncratic components associated
with the person’s past experiences and selective appli-
cation of critical thinking skills; both are secret and
changing.
This correspondence is more than a coincidence.
The web itself is a social creation, and both PageR-
ank and HITS are socially inspired ranking formulas.
(Brin and Page, 1998; Kleinberg, 1999; Raghavan,
2002). Socially inspired systems are subject to so-
cially inspired attacks. Not surprisingly then, the the-
ory of propaganda detection can provide intuition into
the dynamics of the web graph.
PageRank is based on the assumption that the rep-
utation of an entity (a web page in this case) can be
measured as a function of both the number and repu-
tation of other entities linking to it. A link to a web
page is counted as a “vote of confidence” to this web
site, and in turn, the reputation of a page is divided
among those it is recommendingThe implicit assump-
tion is that hyperlink “voting” is taking place inde-
pendently, without prior agreement or central control.
Spammers, like social propagandists, form structures
that are able to gather a large number of such “votes
of confidence” by design, thus breaking the crucial as-
sumption of independence in a hyperlink. But while
the weights in the web graph are assigned by each
search engine, the weights in the trust social network
are assigned by each person. Since there are many
more persons than search engines, the task of a web
spammer is far easier than the task of a propagandist.
5 SEARCH ENGINE EVOLUTION
In the early 90’s, when the web numbered just a few
million servers, the first generation search engines
ON THE EVOLUTION OF SEARCH ENGINE RANKINGS
203
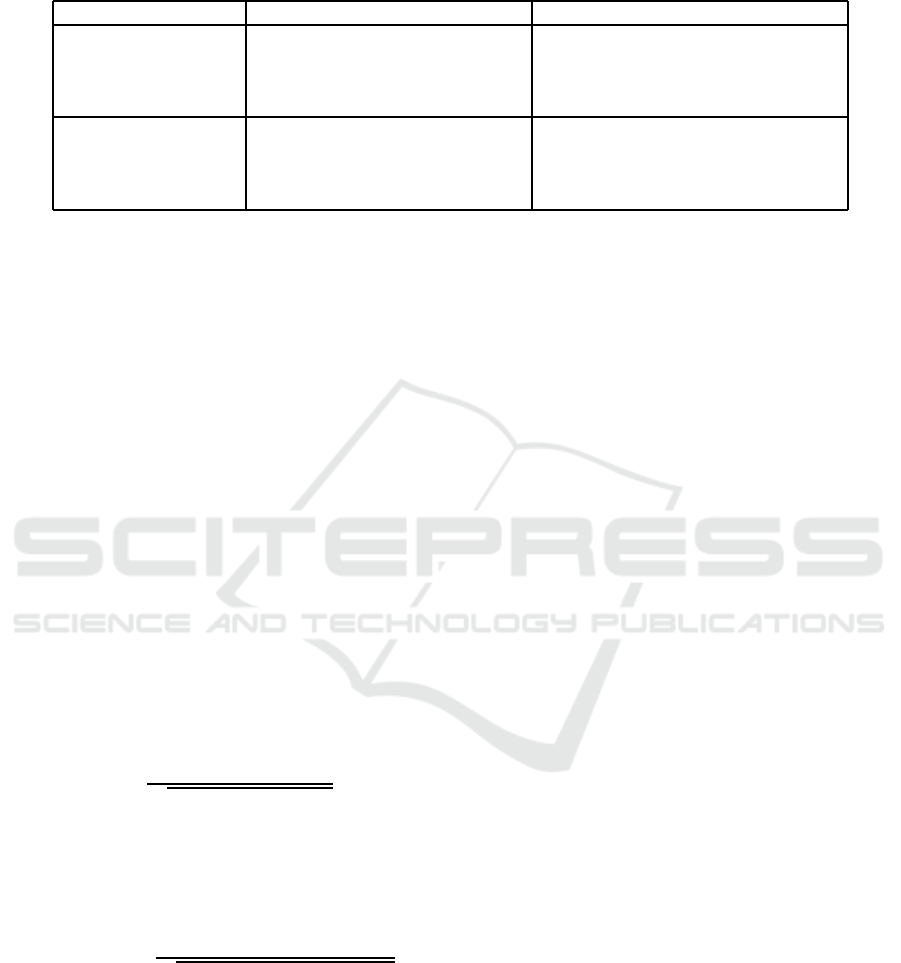
Table 1: Graph theoretic correspondence between the Webgraph and the Trust Social Network. There is a one-to-one corre-
spondence between each component of the two graphs. A major difference, however, is that, even though a person may feel
negative trust (distrust) for some entity, there is no negative weight for hyperlinks.
Graph Theory Web Graph Trust Social Network
Node web page or site social entity
weight rank (accord. to a search engine) reputation (accord. to a person)
weight computation ranking formula (e.g., pagerank) idiosyncratic (e.g., 2 recommenders)
computed continuously computed on demand
Arc hyperlink trust opinion
semantics “vote of confidence” “recommendation”
weight degree of confidence degree of entrustment
weight range [0. . . 1] [distrust . . . trust]
were ranking search results using the vector model of
classic information retrieval techniques: the more rare
words two documents share, the more similar they are
considered to be. (Salton, 1972; Henzinger, 2001)
According to the vector model in Information Re-
trieval (Salton, 1972), documents contained in a doc-
ument collection D are viewed as vectors in term
space T. Each document vector is composed of term
weights w
ik
of term T
k
appearing in document D
i
.
These weights are computed as the normalized dot
product of t f
ik
· id f
k
, where t f
ik
is the frequency of
term T
k
in document D
i
, and id f
k
is the inverse docu-
ment frequency of term T
k
in document collection D.
Typically, id f
k
is computed by a logarithmic formula
so that this term will not grow significantly as the
number of occurrences of T
k
increase. Under this for-
mulation, rare words have greater weight than com-
mon words, because they are viewed as better repre-
senting the document contents. The term weights are
then normalized to fall on a unit sphere so that longer
documents will not have an advantage over shorter
documents:
w
ik
=
t f
ik
· id f
k
p
∑
1≤k≤t
(t f
ik
)
2
(id f
k
)
2
In the vector model, document similarity sim(D
1
, D
2
)
between document vectors D
1
and D
2
is represented
by the angle between them, and is computed as
∑
1≤i≤t
w
1i
· w
2i
cosine normalized:
sim(D
1
, D
2
) =
∑
1≤i≤t
w
1i
· w
2i
p
∑
1≤i≤t
(w
1i
)
2
·
∑
1≤i≤t
(w
2i
)
2
A search query Q is considered simply a short docu-
ment and the results of a search for Q are ranked ac-
cording to their (normalized) similarity to the query.
While the exact details of the computation of term
weights were kept secret, we can say that the rank-
ing formula R
G1
in the first generation search engines
was based in the following principle: the more rare
keywords a document shares with a query, the higher
similarity it has with it, resulting in a higher ranking
score for this document:
R
G1
= f(sim(p, Q)) (1)
The first attack to this ranking came from within
the search engines. In 1996, search engines started
openly selling search keywords to advertisers (CNET-
News, 1996) as a way of generating revenue: If a
search query contained a “sold” keyword, the results
would include targeted advertisement and a higher
ranking for the link to the sponsor’s web site.
Mixing search results with paid advertisement
raised serious ethical questions, but also showed the
way to financial profits to spammers who started their
own attacks using keyword stuffing, i.e., by creat-
ing pages containing many rare keywords to obtain a
higher ranking score. In terms of propaganda theory,
the spammers employed a variation of the technique
of glittering generalities to confuse the first genera-
tion search engines (Lee and Lee(eds.), 1939, pg. 47):
The propagandist associates one or more sugges-
tive words without evidence to alter the conceived
value of a person or idea.
In an effort to nullify the effects of glittering gen-
eralities, second generation search engines started
employing additionally more sophisticated ranking
techniques. One of the more successful techniques
was based on the “link voting principle”: Each web
site s has value equal to its “popularity” |B
s
| which is
influenced by the set B
s
of sites pointing to s.
Therefore, the more sites were linking to a site
s, the higher the popularity of s’s pages. Lycos be-
came the champion of this ranking technique (Mauld-
ing, 1997) and had its own popularity skyrocket in
late 1996. Doing so, it was also distancing itself from
the ethical questions introduced by blurring advertis-
ing with ranking (CNETNews, 1996).
The ranking formula R
G2
in the second generation
search engines was a combination of a page’s similar-
ity, sim(p, Q), and its site’s popularity |B
s
|:
R
G2
= f(sim(p, Q), |B
s
|) (2)
WEBIST 2009 - 5th International Conference on Web Information Systems and Technologies
204

To avoid spammers search engines would keep se-
cret their exact ranking algorithm. Secrecy is no de-
fense, however, since secret rules were figured out
by experimentation and reverse engineering. (e.g.,
(Pringle et al., 1998; Marchiori, 1997)).
Unfortunately, this ranking formula did not suc-
ceed in stopping spammers either. Spammers started
creating clusters of interconnected web sites that had
identical or similar contents with the site they were
promoting, a technique that subsequently became
known as link farms. The link voting principle was
socially inspired, so spammers used the well known
propagandistic method of bandwagon to circumvent
it (Lee and Lee(eds.), 1939, pg. 105):
With it, the propagandist attempts to convince us
that all members of a group to which we belong are
accepting his program and that we must therefore fol-
low our crowd and “jump on the band wagon”.
Similarly, the spammer is promoting the impres-
sion of a high degree of popularity by inter-linking
many internally controlled sites that will eventually
all share high ranking.
PageRank and HITS marked the development of
the third generation search engines. The introduc-
tion of PageRank in 1998 (Brin and Page, 1998) was
a major event for search engines, because it seemed to
provide a more sophisticated anti-spamming solution.
Under PageRank, not every link contributes equally to
the “reputation” of a page PR(p). Instead, links from
highly reputable pages contribute much higher value
than links from other sites. A page p has reputation
PR(p) which is calculated as the sum of fractions of
the reputations of the set B
p
of pages pointing to p.
Let F
v
be the set of links out of page v, v ∈ B
p
. The
reputation of a page is
PR(p) =
1−t
N
+ t
∑
v∈B
p
PR(v)
|F
v
|
where t is the so-called “transport” factor and N is the
total number of pages in the collection. That way, the
link farms developed by spammers would not influ-
ence much their PageRank, and Google became the
search engine of choice. HITS is another socially-
inspired ranking which has also received a lot of at-
tention (Kleinberg, 1999) and is reportedly used by
the AskJeeves search engine. The HITS algorithm di-
vides the sites related to a query between “hubs” and
“authorities”. Hubs are sites that contain many links
to authorities, while authorities are sites pointed to by
the hubs and they both gain reputation.
Unfortunately, spammers again found ways of cir-
cumventing these rankings. In PageRank, a page
enjoys absolute reputation: its reputation is not re-
stricted on some particular issue. Spammers deploy
sites with expertise on irrelevant subjects, and they
acquire (justifiably) high ranking on their expert sites.
Then they bandwagon the irrelevant expert sites, cre-
ating what we call a mutual admiration society. In
propagandistic terms, this is the technique of testimo-
nials (Lee and Lee(eds.), 1939, pg. 74) often used by
advertisers:
Well known people (entertainers, public figures,
etc.) offer their opinion on issues about which they
are not experts.
Spammers were so aggressive in pursuing this
technique that they openly promoted “reciprocal
links”: Web masters controlling sites that had some
minimum PageRank, were invited to join a mutual
admiration society by exchanging links, so that at the
end everyone’s PageRank would increase. HITS has
also shown to be highly spammable by this technique
due to the fact that its effectiveness depends on the
accuracy of the initial neighborhood calculation.
Another heuristic that third generation search en-
gines used was that of exploiting “anchor text”. It had
been observed that users creating links to web pages
would come to use, in general, meaningful descrip-
tions of the contents of a page. (Initially, the anchor
text was non-descriptive,such as “click here”, but this
changed in the late 1990’s.) Google was the first
engine to exploit this fact noting that, even though
IBM’s web page made no mention that IBM is a com-
puter company, many users linked to it with anchor
text such as “computer manufacturer”.
Spammers were quick to exploit this feature too.
In early 2001, a group of activists started using the
anchor text “miserable failure” to link to the official
Whitehouse page of American President George W.
Bush. Using what became known as “Googlebomb”
or, more accurately, link-bomb since it does not per-
tain to Google only, other activists linked the same
anchor text to President Carter, filmmaker Michael
Moore and Senator Hilary Clinton.
Using the anchor text is socially inspired, so
spammers used the propagandistic method of card
stacking to circumvent it (Lee and Lee(eds.), 1939,
pg. 95):
Card stacking involves the selection and use of
facts or falsehoods, illustrations or distructions, and
logical or illogical statements in order to give the best
or the worst possible case for an idea, program, per-
son or product.
The ranking formula R
G3
in the third generation
search engines is, therefore, some secret combination
of a number of features, primarily the page’s simi-
larity, sim(p, Q), its site’s popularity |B
s
| and its the
page’s reputation PR(p):
R
G3
= f(sim(p, Q), |B
s
|, PR(p)) (3)
ON THE EVOLUTION OF SEARCH ENGINE RANKINGS
205
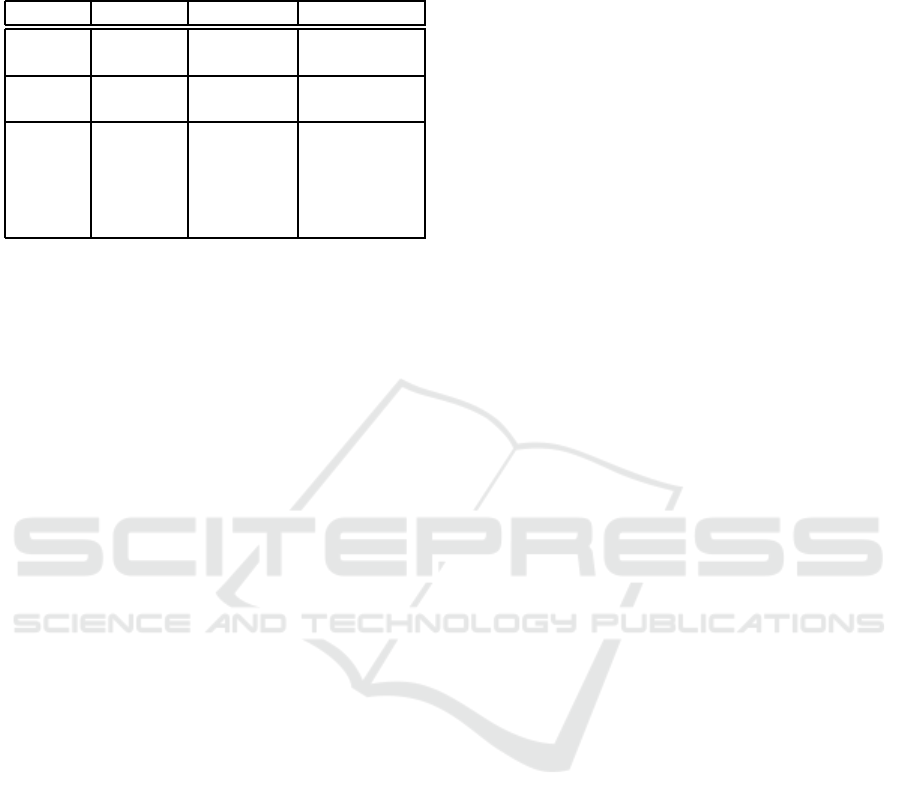
Table 2: Changes in ranking by generations of search en-
gines, the response of the web spammers and the corre-
sponding propagandistic techniques.
S.E.’s Ranking Spamming Propaganda
1st Gen Doc keyword glittering
Similarity stuffing generalities
2nd Gen + Site + link + bandwagon
popularity farms
3rd Gen + Page + mutual + testimonials
reputation admiration
societies
+ anchor + link + card
text bombs stacking
Search engines these days claim to have devel-
oped hundreds of little heuristics for improving their
web search results (Hansell, 2007) but no big idea that
would move their rankings beyond the grasp of spam-
mers. As Table 2 summarizes, for every idea that
search engines have used to improve their ranking,
spammers have managed quickly to balance it with
techniques that resemble propagandistic techniques
from society. Web search corporations are reportedly
busy developing the engines of the next generation
(Broder, 2002). The new techniques aim to be able
to recognize “the need behind the query” of the user.
Given the success the spammers have enjoyed so far,
one wonders how will they spam the fourth genera-
tion engines. Is it possible to create a ranking that is
not spammable? Put another way, can the web as a
social space be free of propaganda?
This may not be possible. Our analysis shows that
we are trying to create in cyberspace what societies
have not succeeded in creating in their real space.
However, we can learn to live in a web with spam as
we live in society with propaganda, given appropriate
education and technology. We touch upon it in our
concluding section.
6 CONCLUSIONS
In this paper we have argued that web spam is to cy-
berworld what propaganda is to society. As evidence
of the importance of this analogy, we have shown
that the evolution of search engines can be largely un-
derstood as the search engines’ responses in defend-
ing against spam. We do not suggest here that web
spam is the sole force behind the evolution of search
engines, but that it is a dominant one. New search
engines are developed when researchers believe they
have a good answer to spam because it directly affects
the quality of the search results.
Further, our findings suggests that anti-spamming
techniques can be developed by mimicking anti-
propagandistic methods. One way to do that is, of
course, discrediting spam networks wheneverthey are
recognized. Search engines are doing a fair amount
of this (Totty and Mangalindan, 2003; Fetterly et al.,
2004). A more effective way is personalizing the web
graph a user sees, effectively increasing the task dif-
ficulty of a spammer to the level of a propagandist:
As we mentioned, a spammer has an easier job than a
propagandist because he/she has to influence the web
graphs of a few search engines instead of the trust
graphs of millions of individuals. Yet another way,
is to propagate distrust to a spamming network when-
ever one of them is recognized.
But what one should do once one recognizes a
spamming network. This is a question that has not at-
tracted the necessary attention in the past. The default
approach is that a search engine would delete such
networks from its indices (Fetterly et al., 2004) or
might downgrade them by some prespecified amount
(Gy¨ongyi et al., 2004).
There are clearly cases where these approaches
are appropriate and effective. But in general, both
of these approaches require a universal agreement of
what constitutes spam. Such an agreement cannot ex-
ist; one person’s spam may be another person’s trea-
sure. Should the search engines determine what is
trustworthy and what is not? Willing or not, they
are the de facto arbiters of what information users
see (Totty and Mangalindan, 2003). As in a popu-
lar cartoon by Ohman & Willis, a kid responds to
the old man who has been searching his entire life
for the meaning of life: “[...]if it’s not on Google,
you probably won’t find it.” We believe that it is the
users’ right and responsibility to decide what is ac-
ceptable for them. Their browser, their window to cy-
berworld, should enhance their ability to make this
decision. User education is fundamental: without it,
people will largely trust what they see, regardless its
credibility. People should know how search engines
work and why, and how information appears on the
web.
But they should also have a trained browser that
can help them determine the validity and trustworthi-
ness of information.
REFERENCES
Bencz´ur, A., Csalog´any, K., Sarl´os, T., and Uher, M. (2005).
Spam Rank – Fully automatic link spam detection. In
Proceedings of the AIRWeb Workshop.
Bharat, K., Chang, B.-W., Henzinger, M. R., and Ruhl, M.
(2001). Who links to whom: Mining linkage between
WEBIST 2009 - 5th International Conference on Web Information Systems and Technologies
206

web sites. In Proceedings of the 2001 IEEE Inter-
national Conference on Data Mining, pages 51–58.
IEEE Computer Society.
Bianchini, M., Gori, M., and Scarselli, F. (2003). PageRank
and web communities. In Web Intelligence Confer-
ence 2003.
Brin, S. and Page, L. (1998). The anatomy of a large-scale
hypertextual Web search engine. Computer Networks
and ISDN Systems, 30(1–7):107–117.
Broder, A. (2002). A taxonomy of web search. SIGIR Fo-
rum, 36(2):3–10.
Broder, A., Kumar, R., Maghoul, F., Raghavan, P., Ra-
jagopalan, S., Stata, R., Tomkins, A., and Wiener, J.
(2000). Graph structure in the web. Comput. Net-
works, 33(1-6):309–320.
Cho, J. and Roy, S. (2004). Impact of search engines on
page popularity. In WWW 2004.
CNETNews (1996). Engine sells results, draws fire.
http://news.cnet.com/2100-1023-215491.html.
Corey, T. S. (2001). Catching on-line traders in a
web of lies: The perils of internet stock fraud.
Ford Marrin Esposito, Witmeyer & Glesser, LLP.
http://www.fmew.com/archive/lies/.
Fetterly, D., Manasse, M., and Najork, M. (2004). Spam,
damn spam, and statistics. In WebDB2004.
Fetterly, D., Manasse, M., Najork, M., and Wiener, J.
(2003). A large-scale study of the evolution of web
pages. In Proceedings of the twelfth international con-
ference on World Wide Web, pages 669–678. ACM
Press.
Flake, G. W., Lawrence, S., Giles, C. L., and Coetzee, F.
(2002). Self-organization of the web and identification
of communities. IEEE Computer, 35(3):66–71.
Graham, L. and Metaxas, P. T. (2003). “Of course it’s true;
i saw it on the internet!”: Critical thinking in the inter-
net era. Commun. ACM, 46(5):70–75.
Gy¨ongyi, Z. and Garcia-Molina, H. (2005). Web spam tax-
onomy. In Proceedings of the AIRWeb Workshop.
Gy¨ongyi, Z., Garcia-Molina, H., and Pedersen, J. (2004).
Combating web spam with TrustRank. In VLDB 2004.
Hansell, S. (2007). Google keeps tweaking its search en-
gine. New York Times.
Henzinger, M. R. (2001). Hyperlink analysis for the web.
IEEE Internet Computing, 5(1):45–50.
Henzinger, M. R., Motwani, R., and Silverstein, C. (2002).
Challenges in web search engines. SIGIR Forum,
36(2):11–22.
Hindman, M., Tsioutsiouliklis, K., and Johnson, J. (2003).
Googlearchy: How a few heavily-linked sites domi-
nate politics on the web. In Annual Meeting of the
Midwest Political Science Association.
Introna, L. and Nissenbaum, H. (2000). Defining the web:
The politics of search engines. Computer, 33(1):54–
62.
Kleinberg, J. M. (1999). Authoritative sources in a hyper-
linked environment. Journal of the ACM, 46(5):604–
632.
Kumar, R., Raghavan, P., Rajagopalan, S., and Tomkins,
A. (1999). Trawling the Web for emerging cyber-
communities. Computer Networks (Amsterdam,
Netherlands: 1999), 31(11–16):1481–1493.
Lee, A. M. and Lee(eds.), E. B. (1939). The Fine Art of
Propaganda. The Institute for Propaganda Analysis.
Harcourt, Brace and Co.
Lynch, C. A. (2001). When documents deceive: trust and
provenance as new factors for information retrieval in
a tangled web. J. Am. Soc. Inf. Sci. Technol., 52(1):12–
17.
Marchiori, M. (1997). The quest for correct information on
the web: hyper search engines. Comput. Netw. ISDN
Syst., 29(8-13):1225–1235.
Maulding, M. L. (1997). Lycos: Design choices in
an internet search service. IEEE Expert, January-
February(12):8–11.
Pringle, G., Allison, L., and Dowe, D. L. (1998). What is a
tall poppy among web pages? In Proceedings of the
seventh international conference on World Wide Web
7, pages 369–377. Elsevier Science Publishers B. V.
Raghavan, P. (2002). Social networks: From the web to the
enterprise. IEEE Internet Computing, 6(1):91–94.
Salton, G. (1972). Dynamic document processing. Com-
mun. ACM, 15(7):658–668.
Silverstein, C., Marais, H., Henzinger, M., and Moricz, M.
(1999). Analysis of a very large web search engine
query log. SIGIR Forum, 33(1):6–12.
Totty, M. and Mangalindan, M. (2003). As google becomes
web’s gatekeeper, sites fight to get in. In Wall Street
Journal CCXLI(39).
Vedder, A. (2000). Medical data, new information technolo-
gies and the need for normative principles other than
privacy rules. In Law and Medicine. M. Freeman and
A. Lewis (Eds.), (Series Current Legal Issues), pages
441–459. Oxford University Press.
Wasserman, S. and Faust, K. (1994). Social Network Analy-
sis: Methods and Applications. Cambridge University
Press.
Wu, B. and Davison, B. (2005). Identifying link farm spam
pages. In WWW 2005.
ON THE EVOLUTION OF SEARCH ENGINE RANKINGS
207
