
FAST SPEAKER ADAPTATION
IN AUTOMATIC ONLINE SUBTITLING
Ale
ˇ
s Pra
ˇ
z
´
ak
SpeechTech s.r.o., Morseova 5, 301 00 Plze
ˇ
n, Czech Republic
Z. Zaj
´
ıc, L. Machlica, J. V. Psutka
Department of Cybernetics, University of West Bohemia, Univerzitn
´
ı 8, 306 14 Plze
ˇ
n, Czech Republic
Keywords:
ASR, Online subtitling, Speaker adaptation, fMLLR, MAP.
Abstract:
This paper deals with speaker adaptation techniques well suited for the task of online subtitling. Two methods
are briefly discussed, namely MAP adaptation and fMLLR. The main emphasis is laid on the description of
improvements involved in the process of adaptation subject to the time requirements. Since the adaptation data
are gathered continuously, simple modifications of the accumulated statistics have to be carried out in order
to make the adaptation more accurate. Another proposed improvement efficiently employs the combination of
fMLLR and MAP. In the case of online adaptation no prior transcriptions of the data are available. They are
handled by a recognition system, thus it is suitable to assign a well-applied confidence measure to each of the
transcriptions. We have performed experiments focused on the trade-off between the adaptation speed and the
amount of adaptation data. We were able to gain a relative reduction of WER 16.2 %.
1 INTRODUCTION
The automatic online subtitling (closed captioning) of
live TV programs using automatic speech recognition
(ASR) is a very promising way, mainly for its consid-
erable cost reduction. Several years ago, BBC intro-
duced so-called ”assisted subtitling” (Evans, 2003).
This was intended for the production of well-timed
subtitles for TV programs using the program tran-
script and the recording, based on alignment using
Speaker Independent (SI) speech recognition. An-
other introduced approach, now in common use, em-
ploys a Speaker Dependent (SD) recognition of so-
called ”shadow speaker” who re-speaks the original
speech of TV program.
In these days, with support of advanced acous-
tic modeling techniques and powerful computer tech-
nology, we can use online speaker independent large
vocabulary continuous speech recognition of original
audio stream for direct subtitling of some TV pro-
grams. This fully automatic approach comes into
question for the speech-only TV programs with a
noiseless background, where high recognition accu-
racy is reached. However, some speaker adaptation
techniques with suitable fast online speaker change
detection can further increase the accuracy of gener-
ated subtitles.
This paper brings an overview of online adap-
tation techniques with some modifications and im-
provement suggestions for a discussion. Our imple-
mentation of online speaker adaptation in the task
of automatic online subtitling is presented and some
adaptation strategies are discussed. Some experimen-
tal results are presented too.
2 ADAPTATION TECHNIQUES
The difference between the adaptation and ordinary
training methods stands in the prior knowledge about
the distribution of model parameters, usually derived
from the SI model. The adaptation adjusts the model
in order to maximize the probability of adaptation
data. Hence, the new, adapted parameters can be cho-
sen as
λ
∗
= arg max
λ
p(O|λ)p(λ), (1)
where p(λ) stands for the prior information about the
distribution of the vector λ containing model param-
eters, O = {o
1
, o
2
, . . . , o
T
} is the sequence of T fea-
126
Pražák A., Zajíc Z., Machlica L. and V. Psutka J. (2009).
FAST SPEAKER ADAPTATION IN AUTOMATIC ONLINE SUBTITLING.
In Proceedings of the International Conference on Signal Processing and Multimedia Applications, pages 126-130
DOI: 10.5220/0002261701260130
Copyright
c
SciTePress

ture vectors related to one speaker, λ
∗
is the best esti-
mation of parameters of the SD model. We will focus
on HMMs with output probabilities of states repre-
sented by GMMs. GMM of the j-th state is char-
acterized by a set λ
j
= {ω
jm
, µ
jm
, C
jm
}
M
j
m=1
, where
M
j
is the number of mixtures, ω
jm
, µ
jm
and C
jm
are
weight, mean and variance of the m-th mixture, re-
spectively.
The adaptation techniques do not access the data
directly, but only through some statistics, which are
accumulated beforehand. Let us define these statis-
tics:
γ
jm
(t) =
ω
jm
p(o(t)| jm)
∑
M
m=1
ω
jm
p(o(t)| jm)
(2)
stands for the m-th mixtures’ posterior of the j-th state
of the HMM,
ε
jm
(o) =
∑
T
t=1
γ
jm
(t)o(t)
∑
T
t=1
γ
jm
(t)
, c
jm
=
∑
T
t=1
γ
jm
(t) ,
(3)
where c
jm
is the soft count of mixture m and
ε
jm
(o) represents the average of features that are as-
signed to mixture m in the j-th state of the HMM. It is
necessary to accumulate also the statistic ε
jm
(oo
T
),
which can be computed in analogy with (3). Note
that σ
2
jm
= diag(C
jm
) is the diagonal of the covari-
ance matrix C
jm
.
2.1 Maximum A-posteriori Probability
(MAP) Adaptation
MAP is based on the Bayes method for estimation
of the acoustic model parameters, with the unit loss
function (Gauvain and Lee, 1994). MAP adapts each
of the parameters separately; therefore it is necessary
to have for all the parameters enough adaptation data.
Otherwise, the result of adaptation would be negligi-
ble. The balance between old and new parameters is
determined using a user-defined parameter.
2.2 Linear Transformations based on
Maximum Likelihood
The advantage over the MAP technique is that the
number of available model parameters is reduced
via clustering of similar model components (Gales,
1996). A well suited clustering method used for this
purpose is based on Regression Trees (RTs), where
each of the leaves in the tree contains a set of mix-
ture components (e.g. mixture means). The leaves
are merged (exploiting a criterion) until the final root
node so that a RT is formed. The transformation
matrices are estimated only for nodes with sufficient
amount of data. Hence, their occupations have to be
Figure 1: Example of a binary regression tree. The num-
bers assigned to nodes/clusters are their occupation counts.
Nodes C
1
and C
2
have occupations lesser then the threshold
T h = 700, therefore the mixture components located in C
1
and C
2
will be transformed utilizing transformations com-
puted for node C
7
. D denotes the depth in the tree.
greater than an empirically determined threshold T h.
Note that the occupation of the n-th node can be com-
puted according to occ(n) =
∑
m∈K
n
c
m
, where c
m
was
specified in (3) and K
n
represents the content of the
n-th cluster. As the same transformation is used for
all parameters from the same cluster K
n
, n = 1, . . . , N,
less amount of adaptation data is needed. An example
of a RT is depicted in Figure 1.
For the task of online recognition the feature trans-
formation is preferable because of implementation
reasons (Machlica et al., 2009).
2.2.1 Feature Maximum Likelihood Linear
Regression (fMLLR)
The method is based upon feature transformation:
¯o
t
= A
(n)
o
t
+ b
(n)
= W
(n)
ξ(t) , (4)
where W
(n)
= [A
(n)
, b
(n)
] stands for the transforma-
tion matrix corresponding to the n-th cluster K
n
and
ξ(t) = [o
T
t
, 1]
T
represents the extended feature vec-
tor. The objective function that has to be maxi-
mized (Povey and Saon, 2006) has the form
log|A
(n)
| −
I
∑
i=1
w
T
(n)i
k
i
− 0.5w
T
(n)i
G
(n)i
w
(n)i
, (5)
where the column vector w
(n)i
equals the transpose of
the i-th row of W
(n)
,
k
(n)i
=
∑
m∈K
n
c
m
µ
mi
ε
m
(ξ)
σ
2
mi
, G
(n)i
=
∑
m∈K
n
c
m
ε
m
(ξξ
T
)
σ
2
mi
(6)
and
ε
m
(ξ) =
ε
T
m
(o), 1
T
, ε
m
(ξξ
T
) =
ε
m
(oo
T
) ε
m
(o)
ε
T
m
(o) 1
.
(7)
The solution can be expressed as:
w
(n)i
= G
−1
(n)i
v
(n)i
α
(n)
+ k
(n)i
, (8)
FAST SPEAKER ADAPTATION IN AUTOMATIC ONLINE SUBTITLING
127

where α
(n)
= w
T
(n)i
v
(n)i
and v
(n)i
stands for the trans-
pose of the i-th row of cofactors of the matrix A
(n)
extended with a zero in the last dimension. Note that
w
(n)i
has to be computed iteratively, thus matrices
A
(n)
and b
(n)
have to be correctly initialized first. For
further details see (Gales, 1997).
2.2.2 Incremental Approach to fMLLR
In the online recognition, the adaptation has to be per-
formed iteratively whenever the amount of adaption
data reaches the pre-specified level. Hence, the subse-
quent recognition becomes more accurate. Recall that
fMLLR operates with model dependent statistics (2)
and (3), which are in the case of incremental adapta-
tion accumulated continuously along with incoming
data. Thus, statistics happen to be inconsistent be-
tween distinct iterations.
There are two possibilities, either accumulate all
the data in the original space, or after each adapta-
tion (iteration) transform the previous statistics into
the new space formed by the new transformation ma-
trices A
k+1
(n)
, b
k+1
(n)
. In the latter case, there is no need
to transform directly the statistics ε
jm
(o), ε
jm
(oo
T
).
Instead, the matrices in (6) can be transformed, what
significantly reduces the number of multiplications
(number of mixtures vs. number of clusters). The
transformation formulas are (Li et al., 2002):
k
k+1
(n)i
=
ˆ
W k
k
(n)i
, G
k+1
(n)i
=
ˆ
W G
k
(n)i
ˆ
W
T
, (9)
where
ˆ
W =
ˆ
A
(n)
ˆ
b
(n)
0 1
, (10)
and
ˆ
A
(n)
,
ˆ
b
(n)
denote the newly computed transfor-
mation matrices. The final transformation matrices
A
k+1
(n)
, b
k+1
(n)
are given as (assuming no change in clus-
ters K
n
, n = 1, . . . , N):
A
k+1
(n)
=
ˆ
A
(n)
A
k
(n)
, b
k+1
(n)
=
ˆ
A
(n)
b
k
(n)
+
ˆ
b
(n)
. (11)
It is appropriate to wait until the increase of in-
formation is sufficient so that the newly formed trans-
formation matrices are well-conditioned and the new
iteration reasonably improves the recognition (Mach-
lica et al., 2009).
2.3 Combination of MAP and fMLLR
As MAP and fMLLR work in different ways, it would
be suitable to combine them. A simple method would
be to run MAP and fMLLR subsequently in two
passes, where fMLLR should be followed by MAP.
The fMLLR method transforms all the mixtures from
the same cluster at once, thus also mixtures with in-
sufficient amount of adaptation data. The second
pass (MAP adaptation) can be thought of as a refine-
ment stage of mixtures with sufficient amount of data
(MAP affects each of the mixtures separately – more
precise). The suitability of MAP after fMLLR com-
bination was also proved by experiments (Zaj
´
ıc et al.,
2009).
The main disadvantage of such an approach is the
need to compute the statistics defined in Section 2
twice. Hence, it would be suitable to adjust the statis-
tics accumulated in the first pass (fMLLR) without
the need to see the feature vectors once again. Be-
cause fMLLR is in use, the adaptation stands for the
transformation of feature vectors. Thus, instead of ac-
cumulating new statistics of transformed features, it is
possible to transform the already computed statistics
ε
jm
(o), ε
jm
(oo
T
) in the following way (consider ex-
pressions (3) and (4)):
¯ε
jm
(o) = A
(n)
ε
jm
(o) + b
(n)
,
¯ε
jm
(oo
T
) = A
(n)
ε
jm
(oo
T
)A
T
(n)
+
+ 2A
(n)
ε
jm
(o)b
T
(n)
+ b
(n)
b
T
(n)
,
(12)
and perform the MAP adaptation utilizing ¯ε
jm
(o),
¯ε
jm
(oo
T
). Note that the only approximation consists
in the use of untransformed mixture posteriors defined
in (2).
2.4 Adaptation of Silence
When using regression trees in fMLLR, the speech
and silence segments usually share the same cluster.
In cases where only adaptation data containing small
amount of silence frames are available, a situation
may occur that the states of silence, presented in the
HMM, are bended toward the speech data. Hence,
the silence segments can be more often recognized as
speech, mainly when channel of adaptation data sig-
nificantly varies. Generally, the speech and silence
are so much different that the idea to separate them is
straightforward. Therefore, it is suitable to establish
a special node in RT intended only for states of si-
lence. It should be mentioned that the adaptation has
to be performed only when sufficient amount of data
is available for both silence and speech parameters.
3 ONLINE ADAPTATION
IMPLEMENTATION
Described adaptation techniques require an assign-
ment of feature vectors to the HMM states and mix-
tures. This assignment is usually acquired using the
force alignment of adaptation utterances to the HMM
SIGMAP 2009 - International Conference on Signal Processing and Multimedia Applications
128

states and mixtures based on manual word transcrip-
tions (supervised approach). In case of online adap-
tation, where no manual transcriptions are available,
recognized word sequence is used instead (unsuper-
vised approach). Since the recognition process is not
error-free, some technique for confidence tagging of
recognized words should be used to choose only well-
recognized segments of speech for speaker adaption.
3.1 Confidence Measure
To apply the online speaker adaption as soon as pos-
sible, word confidences have to be evaluated very
fast for partial word sequences generated periodically
along with incoming acoustic signal. We use poste-
rior word probabilities computed on the word graph
as a confidence measure (Wessel et al., 2001). For
fast evaluation of word confidences, the size of partial
word graphs is reduced in the time axis to limit the
time of the confidence measure evaluation. In addi-
tion, a special modification of the word graph topol-
ogy is applied in the beginning and at the end of the
graph for correct estimation of word confidences near
word graph ends.
3.2 Force Alignment
The force alignment of adaptation utterances to the
HMM states and mixtures is performed only for well-
recognized segments of speech. To use only the trust-
worthy segments of speech, we use a quite strict cri-
terion for word selection - only words, which have
confidence greater than 0.99 and their neighboring
words have confidence greater than 0.99 too, are se-
lected. This ensures that the word boundaries of se-
lected words are correctly assigned. The force align-
ment is then performed in three steps. In the first step,
a state network is constructed based on phonetic tran-
scriptions of recognized words. A lexical tree struc-
ture is used in the case of more phonetic transcriptions
for one word to reduce the network size. In the second
step, the Viterbi search with the beam pruning is ap-
plied on the state network to produce a state sequence
corresponding to the selected words. Finally, feature
vectors are assigned to the HMM state mixtures based
on their posterior probability densities.
4 EXPERIMENTS
We have performed some experiments of the auto-
matic online subtitling related to a real task running in
the Czech public service television. The task concerns
subtitling of live transmissions of the Czech Parlia-
ment meetings without the use of a shadow speaker.
Hence, the original speech signal was being recog-
nized.
4.1 Experimental Setup
An acoustic model was trained on 100 hours of parlia-
ment speech records with manual transcriptions. We
use three-state HMMs and 8 mixtures of multivariate
Gaussians for each state. The total number of 43 080
Gaussians is used for the SI model. In addition,
discriminative training techniques were used (Povey,
2003). The analogue input speech signal is digitized
at 44.1 kHz sampling rate and 16-bit resolution for-
mat. We use PLP parameterization with 19 filters and
12 PLP cepstral coefficients with both delta and delta-
delta sub-features. Feature vectors are computed at
the rate of 100 frames per second.
A language model was trained on about 24M to-
kens of normalized Czech Parliament meeting tran-
scriptions (Chamber of Deputies only) from different
electoral periods. To allow subtitling of arbitrary (in-
cluding future) electoral period, five classes for rep-
resentative names in all grammatical cases were cre-
ated. See (Pra
ˇ
z
´
ak et al., 2007) for details. The vocab-
ulary size is 177 125 words. For the fast online recog-
nition, we use a class-based bigram language model
with Good-Turing discounting trained by SRI Lan-
guage Modeling Toolkit. For a more accurate con-
fidence measure of recognized words, the class-based
trigram language model is used.
The experiments were performed on 12 test
records from different parliament speakers, 5 min-
utes each, 6 612 words in total. To simulate condi-
tions during a real subtitling, the data for the adap-
tation were accumulated from the beginning of each
test record and individual adaptation steps were per-
formed iteratively whenever the amount of adaption
data reaches the pre-specified level. Evaluation of
the recognition accuracy was done on the whole test
records, thus the influence of each adaptation step ap-
proved itself only on parts of records after its applica-
tion.
4.2 Online Adaptation Strategy
There are several online adaptation strategies that
come into question. Firstly, incremental fMLLR ap-
proach should be used since it requires only moder-
ate number of adaptation data. Moreover, the num-
ber of transformation matrices should be continuously
increased as the amount of adaptation data grows.
The optimum adaptation strategy should generate
FAST SPEAKER ADAPTATION IN AUTOMATIC ONLINE SUBTITLING
129
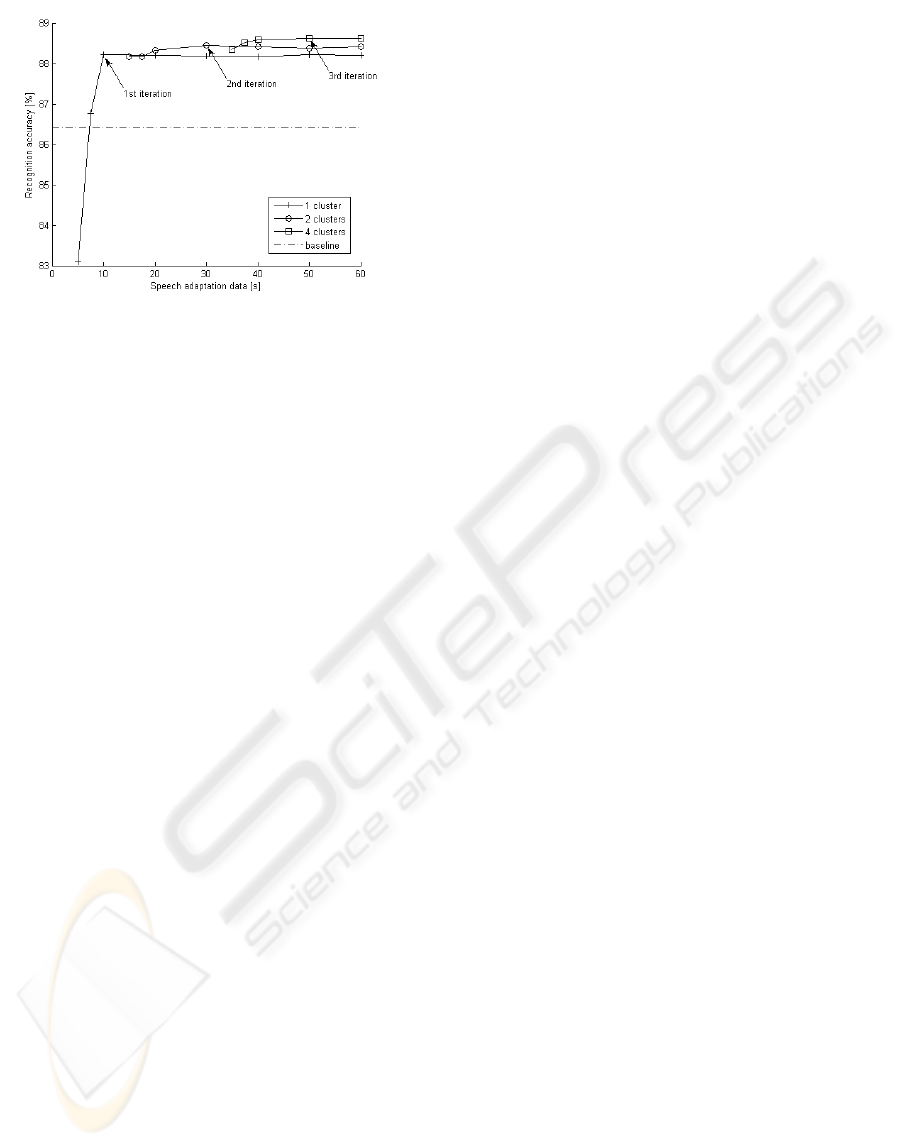
Figure 2: Recognition results using online incremental fM-
LLR adaptation.
new transformation matrices whenever new adapta-
tion data are available, this means after each newly
recognized word. Unfortunately, such an approach
is very time consuming since it takes a while to re-
compute new fMLLR matrices. In practice, it is ap-
propriate to wait until the increase of information is
sufficient so that the benefit of a new adaptation iter-
ation (with increased number of transformation ma-
trices/used clusters – see Section 2.2) is apprecia-
ble. The results of this adaptation strategy on our test
records are presented in Figure 2.
Individual iterations of the fMLLR adaptation
should be performed when sufficient amount of adap-
tation data for each cluster is available (marked by
arrows). The Word Error Rate (WER) reduction after
3rd iteration of adaptation (using 4 clusters/RT nodes)
over the baseline (without any adaption) is 16.2 % rel-
atively. It is important to note that the real speech
length is about twice longer than the speech adapta-
tion data declared in Figure 2.
Another adaptation strategy combines the benefits
from both fMLLR and MAP techniques described in
Section 2. An incremental fMLLR approach is used
as described above, but as soon as sufficient adap-
tation data for MAP are available; the whole model
is recomputed and applied. From that moment new
incremental fMLLR adaptation is started and so on.
Anyhow, the best adaptation strategy for each speaker
should be optimized based on the estimated length of
his/her speech.
5 CONCLUSIONS
We have discussed some of the techniques of online
speaker adaptation extended with several modifica-
tions and improvements. Based on the proposed on-
line adaptation strategy we have performed experi-
ments, where we were able to gain relative reduction
of WER 16.2 % over the baseline (without adapta-
tion). In the future work, we are going to investigate
the combination of fMLLR and MAP adaptation en-
hanced with the SAT approach.
ACKNOWLEDGEMENTS
This work was supported by the Ministry of Edu-
cation of the Czech Republic under projects M
ˇ
SMT
2C06020 and M
ˇ
SMT LC536.
REFERENCES
Evans, M. J. (2003). Speech recognition in assisted and live
subtitling for television. Technical report, BBC.
Gales, M. (1996). The generation and use of regression
class trees for MLLR adaptation. Technical report,
Cambridge University, Engineering Department.
Gales, M. (1997). Maximum likelihood linear transfor-
mations for HMM-based speech recognition. Tech-
nical report, Cambridge University, Engineering De-
partment.
Gauvain, J.-L. and Lee, C.-H. (1994). Maximum a-
posteriori estimation for multivariate gaussian mixture
observations of Markov chains. IEEE Transactions
On Speech and Audio Processing, 2(2):291 – 298.
Li, Y., Erdogan, H., Gao, Y., and Marcheret, E. (2002). In-
cremental on-line feature space MLLR adaptation for
telephony speech recognition. In ICSLP 2002, Inter-
national Conference on Spoken Language Processing.
Machlica, L., Zaj
´
ıc, Z., and Pra
ˇ
z
´
ak, A. (2009). Methods
of unsupervised adaptation in online speech recogni-
tion. In SPECOM 2009, International Conference on
Speech and Computer.
Povey, D. (2003). Discriminative Training for Large Vo-
cabulary Speech Recognition. PhD thesis, Cambridge
University, Engineering Department.
Povey, D. and Saon, G. (2006). Feature and model space
speaker adaptation with full covariance gaussians. In
INTERSPEECH 2006.
Pra
ˇ
z
´
ak, A., M
¨
uller, L., Psutka, J. V., and Psutka, J. (2007).
LIVE TV SUBTITLING - fast 2-pass LVCSR system
for online subtitling. In SIGMAP 2007, International
Conference on Signal Processing and Multimedia Ap-
plications.
Wessel, F., Schl
¨
uter, R., Macherey, K., and Ney, H. (2001).
Confidence measures for large vocabulary continuous
speech recognition. IEEE Transactions on Speech and
Audio Processing, 9(3).
Zaj
´
ıc, Z., Machlica, L., and M
¨
uller, L. (2009). Refine-
ment approach for adaptation based on combination of
MAP and fMLLR. In TSD 2009, International Con-
ference on Text, Speech and Dialogue.
SIGMAP 2009 - International Conference on Signal Processing and Multimedia Applications
130
