
CONTINUAL HTN PLANNING AND ACTING IN OPEN-ENDED
DOMAINS
Considering Knowledge Acquisition Opportunities
Dominik Off and Jianwei Zhang
TAMS, University of Hamburg, Vogt-Koelln-Strasse 30, Hamburg, Germany
Keywords:
Continual planning, HTN planning, Reasoning, Knowledge representation, Plan execution.
Abstract:
Generating plans in order to perform high-level tasks is difficult for agents that act in open-ended domains
where it is unreasonable to assume that all necessary information is available a priori. This paper addresses this
challenge by presenting a planning-based control system that is able to perform tasks in open-ended domains.
The control system is based on a new HTN planning approach that additionally considers decompositions that
would be applicable with respect to a consistent extension of the domain model at hand. The proposed control
system constitutes a continual planning and acting system that interleaves planning and acting so that missing
information can be acquired by means of active information gathering. Experimental results demonstrate
that this control architecture can perform tasks in several domains even if the agent initially has no factual
knowledge.
1 INTRODUCTION
If we instruct artificial agents to perform a task, then
we usually want to tell them what to do, but not how
to do it (e.g., in terms of a detailed sequence of low-
level commands). In other words, we want agents
to autonomously and flexibly plan how they can rea-
sonably perform a given task. Planning their future
course of action is particularly difficult for agents
(e.g., robots) that act in a dynamic and open-ended
environment where it is unreasonable to assume that
a complete representation of the state of the domain is
available. We define an open-ended domain as a do-
main in which an agent can in general neither be sure
to have all information nor to know all possible states
(e.g., all objects) of the world it inhabits.
Planning algorithms have been developed that in
principle are efficient enough to solve complex plan-
ning problems in real time. However, “classical”
planning approaches fail to generate plans when nec-
essary information is not available at planning time,
because they rely on having a complete representation
of the current state of the world (Nau, 2007).
Conformant, contingent or probabilistic planning
approaches can be used to generate plans in situa-
tions where insufficient information is available at
planning time (Russell and Norvig, 2010; Ghallab
et al., 2004). These approaches generate conditional
plans—or policies—for all possible contingencies.
Unfortunately, these approaches are computationally
hard, scale badly in dynamic unstructured domains
and are only applicable if it is possible to foresee all
possible outcomes of a knowledge acquisition pro-
cess (Rintanen, 1999; Littman et al., 1998). There-
fore, these approaches can hardly be applied to the
dynamic and open-ended domains we are interested
in. Consider, for example, a robot agent that is in-
structed to bring Bob’s mug into the kitchen, but does
not know the location of the mug. Generating a plan
for all possible locations in a three dimensional space
obviously is unreasonable and practically impossible.
A more promising approach for agents that act in
open-ended domains is continual planning (Brenner
and Nebel, 2009) which enables the interleaving of
planning and execution so that missing information
can be acquired by means of active information gath-
ering. Existing continual planning systems can deal
with incomplete information. However, they usually
rely on the assumption that all possible states of a do-
main are known. This makes it, for example, difficult
to deal with a priori unknown object instances. An-
other important issue that is not directly considered by
previous work is the fact that a knowledge acquisition
task task
1
can—like any other task—make the execu-
tion of an additional knowledge acquisition task task
2
necessary which might require the execution of the
16
Off D. and Zhang J..
CONTINUAL HTN PLANNING AND ACTING IN OPEN-ENDED DOMAINS - Considering Knowledge Acquisition Opportunities.
DOI: 10.5220/0003704500160025
In Proceedings of the 4th International Conference on Agents and Artificial Intelligence (ICAART-2012), pages 16-25
ISBN: 978-989-8425-95-9
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)
knowledge acquisition task task
3
and so on. Consider,
for example, a situation where a robot is instructed to
deliver Bob’s mug into Bob’s office. Moreover, let
us assume that the robot does know that Bob’s mug
is in the kitchen, but does not know the exact loca-
tion of the mug. Is this situation the robot needs to
perform a knowledge acquisition task that determines
the exact location of Bob’s mug. However, in order
to do that via perception the robot first needs to go
into the kitchen. If the robot does not have all neces-
sary information in order to plan how to get into the
kitchen (e.g., it is unknown whether the kitchen door
is open or closed), then it needs to first perform ad-
ditional knowledge acquisition tasks that acquire this
information. Existing continual planning approaches
usually fail to cope with such a situation. In contrast,
we propose a continual planning and acting approach
that is able to deal with these kind of situations and
thus can enable an agent to perform tasks in a larger
set of situations.
We assume that agents are able to acquire infor-
mation from external sources. The key problem we
are trying to address is not how to generate a plan for
a knowledge acquisition task, since planning to ac-
quire certain information (e.g., determining whether
the kitchen door is open) technically does not differ
from generating plans for other tasks (e.g., making a
cup of coffee). In contrast, we are trying to give an
answer to the following questions: How can an agent
determine knowledge acquisition activities that make
it possible to find a plan when necessary information
is missing? When is it more reasonable to acquire ad-
ditional information prior to continuing the planning
process? How to automatically switch between plan-
ning and acting?
The main contributions of this work are:
• to propose the new HTN planning system
ACogPlan that additionally considers planning al-
ternatives that are possible with respect to a con-
sistent extension of the domain model at hand, and
is able to autonomously decide when it is more
reasonable to acquire additional information prior
to continuing the planning process;
• to propose the ACogPlan based high-level control
system ACogControl that enables an agent to per-
form tasks in open-ended domains;
• and to present a set of experiments that demon-
strate the performance characteristics of the over-
all approach.
2 HTN PLANNING IN
OPEN-ENDED DOMAINS
In this section we present the ACogPlan continual
HTN planning system. We describe the planning
phase of the overall continual planning and acting
control architecture.
2.1 General Idea
The proposed planning system ACogPlan is an exten-
sion of the SHOP (Nau et al., 1999) forward search
(i.e., forward decomposition) Hierarchical Task Net-
work (HTN) planning system. The SHOP algorithm
plans by successively choosing an instance of a rele-
vant
1
HTN method or planning operator for which an
instance of the precondition can be derived with re-
spect to the domain model at hand. However, in open-
ended domains it will often be possible to instantiate
additional HTN methods or planning operators (i.e.,
which precondition is not derivable) if additional in-
formation is available. The general idea of the pro-
posed planning system ACogPlan is to also consider
instances of relevant HTN methods and planning op-
erators for which the precondition cannot be derived
but might be derivable with respect to a consistent ex-
tension of the domain model (i.e., if additional infor-
mation is available).
method inst. 1 (applicable)
move to(kitchen)
approach(door1)
cross(door1)
method inst. 2 (possibly-applic.)
move to(kitchen)
approach(door2)
cross(door2)
Acqusition:
{det(open(door2),percept)}
method inst. 3 (possibly-applic.)
move to(kitchen)
approach(X)
cross(X)
Acqusition:
{det(connect(lab,X,kitchen),
percept), det(open(X),percept)}
relevant method
task: move to(Room)
precond: [
at(agent,Room1)
^ connect(Room1,D,Room2)
^ open(D)]
subtasks: [approach(D),
cross(D)]
derivable instances
at(agent,lab)
connect(lab,door1,kitchen)
connect(lab,door2,kitchen)
open(door1)
Figure 1: Applicable and possibly-applicable method in-
stances for the task move to(kitchen).
For example, consider a simple situation
where a robot is instructed to perform the task
1
as defined in (Ghallab et al., 2004, Definition 11.4)
CONTINUAL HTN PLANNING AND ACTING IN OPEN-ENDED DOMAINS - Considering Knowledge Acquisition
Opportunities
17

move to(kitchen) as illustrated by Figure 1.
2
In this
situation there is only one relevant HTN method. It is
known that the robot is in the lab, the lab is connected
to the kitchen via door1 and door2, and door1 is
open. For the illustrated example, existing HTN
planners would only consider the first instance of
the relevant HTN method that plans to approach and
cross door1. The proposed HTN planning algorithm
ACogPlan, however, also considers two additional
instances of the relevant HTN method which cannot
directly be applied, but are applicable in a consistent
extension of the given domain. Methods or planning
operators that are only applicable with respect to
an extension of an agent’s domain model are called
possibly-applicable. For example, it will also be
possible to cross door2 if the robot could find out
that this door is open. Moreover, in open-ended
domains it can also be possible that there is another
door which connects the lab and the kitchen.
Additionally considering possibly-applicable
HTN methods or planning operators is important
in situations where one cannot assume that all
information is available at the beginning of the
planning process. It often enables the generation—
and execution—of additional plans. In particular,
it can enable a planner to generate plans where it
would otherwise be impossible to generate any plan
at all. For example, if it were unknown whether
door1 is open or closed, then there would only be
possibly-applicable method instances. Hence, with-
out considering possible-applicable method instances
a planner would fail to generate a plan for the task
move to(kitchen) and thus the agent would be
unable to achieve its goals. Moreover, if the optimal
plan requires knowledge acquisition, then the optimal
plan can only be found if possibly-applicable method
and planning operator instances are considered. In
other words, one can also benefit from the proposed
approach in situations where it is possible to gen-
erate a complete plan without acquiring additional
information.
2.2 Open-Ended Domain Model
A planner that wants to consider possibly-applicable
HTN methods or planning operators needs to be
able to reason about extensions of its domain model.
Most existing automated planning systems are unable
to do that, since their underlying domain model is
based on the assumption that all information is avail-
able at the beginning of the planning process (Nau,
2
Please note that in the context of this work variables
will be written as alphanumeric identifiers beginning with
capital letters.
2007). In contrast, the proposed HTN planning sys-
tem ACogPlan is based on the open-ended domain
model ACogDM. ACogDM enables the planner to
reason about relevant extensions of its domain model.
The key concepts of ACogDM are described briefly
in this section.
A planner should only consider domain model ex-
tensions that are possible and relevant with respect to
the overall task. However, how can a planner infer
what is relevant and possible? The domain informa-
tion encoded in HTN methods can nicely be exploited
in order to infer which information is relevant. A rel-
evant method or planning operator can actually be ap-
plied if and only if its precondition p holds (i.e., an
instance pσ
3
is derivable) with respect to the given
domain model. Therefore, we define the set of rel-
evant preconditions with respect to a given planning
context (i.e., a domain model and a task list) to be
the set of all preconditions of relevant methods or
planning operators. An HTN planner cannot—except
backtracking—continue the planning process in situa-
tions where no relevant precondition is derivable with
respect to the domain model at hand. The notation
of a relevant precondition is a first step to determine
relevant extensions of a domain model, since only do-
main model extensions that make the derivation of an
additional instance of a relevant precondition possible
constitute an additional way to continue the planning
process. All other possible extensions are irrelevant,
because they do not imply additional planning alter-
natives. In other words, if it were possible to acquire
additional information which implies the existence of
a new instance of a relevant precondition, then the
planning process could be continued in an alternative
manner. As already pointed out, this is particularly
relevant for situations in which it would otherwise be
impossible to find any plan at all.
In order to formalize this we introduce the follow-
ing concepts: a possibly-derivable statement (e.g., a
precondition) and an open-ended literal. Let L
x
be
a set of literals and p be a precondition. p is called
possibly-derivable iff the existence of a new instance
lσ for each l ∈ L
x
implies the existence of a new in-
stance pσ of p. Obviously this definition is only use-
ful if the existence of an additional instance for each
l ∈ L
x
is possible. A literal for which the existence
of non-derivable instances is possible is called open-
ended. Based on that, one can say that a possibly-
derivable precondition constitutes the partition of a
precondition into a derivable and an open-ended part
(i.e., a set of open-ended literals).
For example, consider the situation illustrated by
Figure 1. In this example there are three differ-
3
In the context of this work σ denotes a substitution.
ICAART 2012 - International Conference on Agents and Artificial Intelligence
18

ent situations in which the precondition of the HTN
method is possibly-derivable. In all cases Room1 is
substituted with lab and Room2 is substituted with
kitchen. Furthermore, in the first situation D is sub-
stituted with door1 and the precondition is possibly-
derivable with respect to the agents domain model
and the set of open-ended literals {}. In the second
case, D is substituted with door2 and the precondi-
tion is possibly-derivable with respect to the set of
open-ended literals {open(door2)}. In the last case,
D is not instantiated and the precondition is possibly-
derivable with respect to the set of open-ended literals
{connect(lab,D,kitchen),open(D)}. Thus, in
this example the open-ended domain model ACogDM
can tell the robot agent that it can cross door1, or cross
door2 if it can find out that door2 is open, or cross an-
other door D if it finds another door D that connects the
lab and the kitchen and is open. In this way, ACogDM
can enable a planner to reason about possible and rel-
evant extensions of its domain model.
2.3 Planning Algorithm
In this section we present the key conceptualizations
and the algorithm of the proposed planning system.
2.3.1 Preliminaries
If we want agents to acquire additional instances of a
set of open-ended literals, then it should be consid-
ered that there might be dependencies between lit-
erals. For example, for the set of open-ended lit-
erals {mug(X),color(X, red)} one cannot indepen-
dently acquire an instance of mug(X) and an instance
of color(X, red), because one needs to find an in-
stance of X which represents a mug as well as a red
object. Let l
1
,l
2
be literals that are part of a precon-
dition p in disjunctive normal form and var(l) denote
the set of variables of a literal l. l
1
and l
2
are called de-
pendent (denoted as l
1
↔ l
2
) iff l
1
and l
2
are part of the
same conjunctive clause and ((var(l
1
) ∩ var(l
2
) 6=
/
0)
or l
1
and l
2
are identical or (∃
l
3
l
1
↔ l
3
∧ l
3
↔ l
2
)).
Agents (e.g., robots) can usually acquire informa-
tion from a multitude of sources. These sources are
called external knowledge sources. While submitting
questions to external databases or reasoning compo-
nents might be “simply” achieved by calling external
procedures, submitting questions to other sources
(e.g., perception), however, involves additional
planning and execution. For the purpose of enabling
ACogPlan to generate knowledge acquisition plans
we use a particular kind of task, namely a knowledge
acquisition task. A Knowledge acquisition task has
the form det(l,I,C,ks) where l is a literal, I is the set
of all derivable instances of l, C is a set of literals that
are dependent on l, and ks is a knowledge source. In
other words, det(l,I,C, ks) is the task of acquiring an
instance lσ of l from the knowledge source ks such
that lσ /∈ I (i.e., lσ is not already derivable) and for
all c ∈ C an instance of cσ is derivable. For example,
det(open(kitchen door),
/
0,
/
0, percept) is the task
of determining whether the kitchen door is open
by means of perception. Furthermore, det(mug(X),
[mug(bobs mug)],[in room(X,r1), red(X)],hri(bob))
constitutes the task of finding a red mug which is
located in the room r1 and is not Bob’s mug by
means of human robot interaction with Bob. Like for
other tasks, we can define HTN methods that describe
how to perform a knowledge acquisition task. For
example, Figure 2 shows a method for the acquisition
task of determining whether a door is open. Every
method has an expected cost that describes how
expensive it is to perform a task as described by the
method. In this example the cost is “hard-coded”, but
it is also possible to calculate a situation dependent
cost.
method( d et ( op e n ( Door ) ,I , C , per c e pt ) ,
( door ( Door )) ,
% prec o n d i t i on
[ a pp r o ac h ( Door ) , % s ub t a sk s
sense ( open ( D o o r ), perc e p t )] ,
50). % c o s t
Figure 2: Example HTN method for an acquisition task.
Knowledge acquisition tasks enable the planner to
reason about possible knowledge acquisitions since
they describe (1) what knowledge acquisitions are
possible under what conditions, (2) how expensive it
is to acquire information from a specific knowledge
source, and (3) how to perform a knowledge acquisi-
tion task.
It might be possible that the same information
can be acquired from different external knowledge
sources and the expected cost to acquire the same
information can be completely different for each
source. Thus, in order to acquire additional in-
stances for each literal of a set of open-ended liter-
als, a planner needs to decide for each literal from
which knowledge source it should try to acquire
an additional instance. The result of this decision
process is called a knowledge acquisition scheme.
A knowledge acquisition scheme is a set of tu-
ples (l,ks) where l is a literal and ks is an exter-
nal knowledge source. It represents one possible
combination of trying to acquire a non-derivable in-
stance for each open-ended literal by an adequate
knowledge source. For example, the knowledge
acquisition scheme {(on table(bobs mug), percept),
(white coffee(bob),hri(bob))} represents the fact that
CONTINUAL HTN PLANNING AND ACTING IN OPEN-ENDED DOMAINS - Considering Knowledge Acquisition
Opportunities
19

the query on table(bobs mug)? should be answered
by perception and the query white coffee(bob)?
should be submitted to Bob. Formally a knowledge
acquisition scheme is defined as follows:
Definition 1 (Knowledge Acquisition Scheme). Let
st be a statement that is possibly-derivable with re-
spect to D
M
and the set of open-ended literals L
x
=
S
1≤i≤n
{l
i
}. Moreover let KS be the set of knowledge
sources. A set kas := {
S
1≤i≤n
{(l
i
,k
i
)}|k
i
∈ K S} is
called a knowledge acquisition scheme for st w.r.t.
D
M
. If L
X
=
/
0, then the corresponding knowledge
acquisition scheme is also
/
0.
However, a knowledge acquisition scheme is only
helpful for an agent if it is actually able to perform
the corresponding knowledge acquisition tasks. For
example, if a robot in principle is not able to find
out whether a door is open, then the planner does not
have to consider method instance 2 and 3 for the situa-
tion illustrated by Figure 1. A knowledge acquisition
scheme for which all necessary knowledge acquisi-
tion tasks can be possibly performed by the agent is
called possibly-acquirable and more formally defined
as follows:
Definition 2 (Possibly-acquirable). An acquisition
(l, ks) is called possibly-acquirable w.r.t. to a do-
main Model D
M
iff there is an applicable or possibly-
applicable planning step for the knowledge acquisi-
tion task det(l,I,C, ks) such that I are all derivable
instances of l w.r.t. D
M
and C is the context. More-
over, a knowledge acquisition scheme kas is called
possibly-acquirable iff all (l,ks) ∈ kas are possibly-
acquirable.
Let D be the set of domain models, T L be the set
of task lists, P be the set of plans and K AS be the
set of knowledge acquisition schemes. We call ps ∈
D × T L × P × K AS a planning state. A planning
state is called final if the task list is empty and called
intermediate if the task list is not empty. ps
D
denotes
the domain model, ps
t
the task list, ps
p
the plan and
ps
kas
the knowledge acquisition scheme of a planning
state ps.
The term planning step is used in this work as
an abstraction of (HTN) methods and planning op-
erators. A planning step s is represented by a 4-tuple
(s
task
,s
cond
,s
e f f
,s
cost
). s
task
is an atomic formula that
describes for which task s is relevant, s
cond
is a state-
ment that constitutes the precondition of s, s
e f f
is the
effect of the s, and s
cost
represents the expected cost
of the plan that results from the application of s.
Let PS be the set of planning states. s
eff
is a func-
tion s
eff
: PS → PS. Thus, a planning step maps the
current planning state to a resulting planning state.
In this sense operators map the current planning state
to a resulting state by removing the next task from
the task list, adding a ground instance of this task to
the plan and updating the domain model according to
the effects of the operator. In contrast, HTN methods
transform the current planning state by replacing an
active task by a number of subtasks.
Furthermore, we define the concept of a possibly-
applicable planning step introduced in Section 2.1 as
follows:
Definition 3 (Possibly-applicable). A planning step
s is called possibly-applicable w.r.t. a domain model
D
M
and a knowledge acquisition scheme kas iff kas
is possibly-acquirable and a knowledge acquisition
scheme for s
cond
.
A possibly-applicable planning step can only be
applied after necessary information has been acquired
by the execution of corresponding knowledge acqui-
sition tasks. For example, consider the second method
of the situation illustrated by Figure 1. This method
instance can only be applied if the robot has perceived
that door2 is open. The fact that possibly-applicable
planning step instances require the execution of addi-
tional tasks (i.e., knowledge acquisition tasks) needs
to be consider by the expected cost. The cost of
a possibly-applicable planning step is defined as the
sum of the cost for the step if it is applicable and the
expected cost of all necessary knowledge acquisition
tasks.
For example, let us assume that the cost of
the plan that results from applying the method
for move
to(Room) is always 100. More-
over, let us assume that the cost of perform-
ing the task det(open(door2),
/
0,
/
0,percept)
is 50 (see Figure 2) and the cost of perform-
ing the task det(connect(lab,X,kitchen),
[connect(lab,door1,kitchen), connect(lab,
door2,kitchen)],open(X),percept) is 300. In
this situation the cost of method instance 1 is 100, the
cost of method instance 2 is 100 +50 = 150, and the
cost of method instance 3 is 100 + 50 + 300 = 450.
Thus, in this case the applicable instance has the less
expected cost. However, this does not always have to
be the case.
2.3.2 Algorithm
The simplified algorithm of the proposed HTN plan-
ning system is shown by Algorithm 1. The algorithm
is an extension of the SHOP (Nau et al., 1999) algo-
rithm that additionally considers possibly-applicable
decompositions.
A planning state is the input of the recursive plan-
ning algorithm. If the task list of the given planning
state is empty, then the planning process successfully
ICAART 2012 - International Conference on Agents and Artificial Intelligence
20

Algorithm 1: Plan(ps).
Result: a planning state ps
0
, or failure
1 if ps is a final planning state then
2 return ps;
3 steps ← {(s,σ,kas)|s is the instance of a
planning step, σ is a substitution such that sσ is
relevant for the next task, s is applicable or
possibly-applicable w.r.t. ps
D
and the
knowledge acquisition scheme kas};
4 if choose (s,σ,kas) ∈ steps with the minimum
overall cost then
5 if kas =
/
0 then
6 ps
0
← s
eff
(ps);
7 ps
00
← plan(ps
0
);
8 if ps
00
6= failure then
9 return ps
00
;
10 else
11 return (ps
D
, ps
t
, ps
p
,kas);
12 else
13 return failure;
generated a complete plan and the given planning
state is returned. Otherwise, the algorithm succes-
sively chooses the applicable or possibly-applicable
step with the lowest expected cost. If the planner
chooses an applicable planning step (i.e., no knowl-
edge acquisition is necessary and the knowledge ac-
quisition scheme is the empty set), then it applies the
step and recursively calls the planning algorithm with
the updated planning state (line 5-9).
In contrast, if the planner chooses an only
possibly-applicable planning step, then it stops the
planning process and returns the current (intermedi-
ate) planning state including the knowledge acquisi-
tion scheme of the chosen planning step (line 10-11).
In this way the planner automatically decides whether
it is more reasonable to continue the planning or to
first acquire additional information. In other words,
it decides when to switch between planning and act-
ing. If it is neither possible to continue the planning
process nor to acquire relevant information, then the
planner backtracks to the previous choice point or re-
turns failure if no such choice point exists.
3 CONTINUAL PLANNING AND
ACTING
The overall idea of the proposed continual planning
and acting system is to interleave planning and acting
so that missing information can be acquired by means
of active information gathering. In Section 2 we de-
scribed a new HTN planning system for open-ended
domains. Based on that, we describe the high-level
control system ACogControl in this section.
The overall architecture is sketched in Figure 3.
The central component in this architecture is the con-
troller. When the agent is instructed to perform a list
of tasks then this list is sent to the controller. The
controller calls the planner described in Section 2 and
decides what to do in situations where the planner
only returns an intermediate planning state. Further-
more, the controller invokes the executor in order to
execute—complete or partial—plans. The executor
is responsible for the execution and execution moni-
toring of actions. In order to avoid unwanted loops
(e.g., perform similar tasks more than once) it is es-
sential to store relevant information of the execution
process in the memory system. The executor stores
information about the executed actions and the out-
come of a sensing action in the memory system such
that the domain model can properly be updated. This
information includes acquired information as well as
knowledge acquisition attempts. Knowledge acquisi-
tion attempts are stored to avoid submitting the same
query more than once to a certain knowledge source.
controller
planner
reasoner
memory
executor
tasks
query
plan
store
Figure 3: Illustration of the planning-based control archi-
tecture.
The behavior of the controller is specified by Al-
gorithm 2. When the controller is invoked it first con-
structs an initial planning state based on the given task
list and invokes the planner (lines 1-2). If the planner
returns a final planning state (i.e., a planning state that
contains a complete plan), then the controller directly
forwards the generated plan to the executor.
However, if the planner returns an intermediate
planning state (i.e., a planning state that only contains
a partial plan), then the controller performs a prefix of
the already generated plan, chooses the knowledge ac-
quisition with the minimum expected cost, performs
the knowledge acquisition task and continues to per-
form the remaining tasks. Please note that knowledge
acquisition tasks can also require it to perform addi-
tional knowledge acquisition tasks. Which tasks still
need to be performed in order to perform the initial
CONTINUAL HTN PLANNING AND ACTING IN OPEN-ENDED DOMAINS - Considering Knowledge Acquisition
Opportunities
21

Algorithm 2: Perform(tasks).
1 ps ←create-intial-ps(tasks);
2 ps
0
← plan(ps);
3 if ps is a final planning state then
4 r ← execute(ps
p
);
5 return r;
6 else
7 r ←perform(p
0
⊆ ps
p
);
8 if r is a success then
9 choose ac ∈ ps
kas
with the minimum
cost;
10 t
ac
← acquisition-task(ac);
11 perform([t
ac
]);
12 tasks
rem
← memory.remaining-tasks();
13 perform(tasks
rem
);
task list (i.e., the remaining tasks) can easily be
deduced by the memory, since the memory retains
knowledge of all actions that have already been ex-
ecuted. It is more difficult to determine which part of
the already generated plan should be executed. For
example, if one instructs a robot agent to deliver a
cup into the kitchen, but it is unknown whether the
door of the kitchen is open or closed, then it is rea-
sonable to start grasping the cup, move to the kitchen
door, sense its state and then continue the planning
process. In contrast, it usually should be avoided to
execute critical actions that cannot be undone until a
complete plan is generated. The default strategy of
the proposed controller is to execute the whole plan
prefix prior to the execution of knowledge acquisition
tasks. However, due to the fact this is not always the
best strategy it is possible to specify domain specific
control rules.
4 EXPERIMENTAL RESULTS
In this section, we present a simple case study with a
mobile robot and a set of simulated experiments with
several domains.
4.1 A Case Study with a Mobile Robot
The proposed planning based control system is imple-
mented on a mobile service robot platform TASER.
We performed a first simple test case in the office
environment of our institute in order to demonstrate
the system behaviour. The only used external knowl-
edge source in this test case is perception. The robot
was instructed to perform the task of delivering a mug
(Bob’s mug) into the kitchen. In this test run the robot
has no information about the state of doors and there-
fore cannot generate a complete plan in advance.
The robot successfully performed the task. The
overall execution is composed of six planning and ex-
ecution phases as illustrated in Figure 4. Actions that
are directly executed by a corresponding robot control
program are printed blue and marked with the symbol
“I”. All other tasks are non-primitive and cannot be
directly executed. The fact that only a partial plan ex-
ists for a task is illustrated by a subsequent “[...]”.
Furthermore, the result of a sensing action is shown
under the corresponding task.
Phase 1
deliver(bobs mug,kitchen)[...]
pick up(bobs mug)
move to(lab)
§ approach(table1)
§ localize(bobs mug)
§ reach for(bobs mug)
§ grasp(bobs mug)
move to(kitchen) [...]
Phase 2
det(open(door1),[],[],percept)
§ approach(door1)
§ sense(open(door1),percept)
[sensed:neg open(door1)]
Phase 3
det(open(door2),[],[],percept)
§ approach(door2)
§ sense(open(door2),percept)
[sensed:open(door2)]
Phase 4
deliver(bobs mug,kitchen)[...]
pick up(bobs mug)
move to(kitchen) [...]
move to(corridor)
§ cross(door2)
Phase 5
det(open(door4),[],[],percept)
§ approach(door4)
§ sense(open(door4),percept)
[sensed:open(door4)]
Phase 6
deliver(bobs mug,kitchen)
pick up(bobs mug)
move to(kitchen)
§ approach(door4)
§ cross(door4)
§ approach(table4)
§ place down(bobs mug,table4)
Figure 4: Execution phases of the full system test case.
At the first planning phase the planner generates a
complete plan that determines how to pick up Bob’s
mug. Non-primitive tasks that have no subsequent
“[...]” and are not further decomposed usually in-
dicate the situation that nothing has to be done to
perform the task. For example, in the first phase
the task move to(lab) is not further decomposed, be-
cause the robot initially is in the lab. Due to the fact
that the planner had no information about the state
of the doors it could not generate a plan for the task
move to(kitchen). The planner decides to execute the
plan for pick up(bobs mug) and then starts the sec-
ond planning and execution phase in order to deter-
mine whether the first lab door is open. During the
second execution phase the robot determines that the
first lab door is closed. In order to avoid the more ex-
pensive door opening procedure the planner decides
to determine whether the second lab door is open at
the third planning and execution phase. The robot
determines that the second lab door is open and can
continue to perform the initial task (i.e., bring Bob’s
mug into the kitchen). In the fifth phase, the robot de-
termines that the kitchen door is open. After the fifth
phase all necessary information is available and the
ICAART 2012 - International Conference on Agents and Artificial Intelligence
22

robot successfully finishes its task in the last execu-
tion phase.
4.2 ACogSim
Providing an environment for the evaluation of
continual planning is not a trivial task (Brenner
and Nebel, 2009). We implemented a simula-
tor, namely ACogSim, for the environment in or-
der to make it possible to systematically evaluate
the whole high-level control architecture—including
execution—described in Section 3. The ACogSim
simulator works similar to MAPSIM as described in
(Brenner and Nebel, 2009). In contrast to the agent
ACogSim has a complete model of the domain. When
the executor executes an action, then the action is sent
to ACogSim. ACogSim checks the precondition of
actions at runtime prior to the execution and updates
its simulation model according to the effect of the ac-
tions. In this way ACogSim simulates the execution
of actions and guarantees that the executed plans are
correct.
The outcome of sensing actions is also simulated
by ACogSim. Let D
Msim
be the (complete) domain
model of the ACogSim instance. The result of a sens-
ing action sense(l,I,C, ks) is an additional instance lσ
of l if such an instance can be derived with respect to
D
Msim
; impossible if it can be derived that the exis-
tence of an additional instance of l is impossible; or
indeterminable otherwise.
4.3 Performing Tasks with a Decreasing
Amount of Initial Knowledge
We used ACogSim in order to evaluate the behavior
of the overall control system for several domains. The
objective of the conducted experiments is to deter-
mine the behavior of the system in situations where
an agent needs additional information to perform a
given task, but sufficient information can in principle
be acquired by the agent.
4.3.1 Setup
We used an adapted version of the rover domain with
1756 facts and an instance of the depots domain with
880 facts from IPC planning competition 2002; an in-
stance of an adapted blocks world domain with 2050
facts; and a restaurant (109 facts) and an office do-
main (88 facts) used to control a mobile service robot.
All domain model instances contain sufficient in-
formation to generate a complete plan without the
need to acquire additional information. The simula-
tor (ACogSim) is equipped with a complete domain
model. In contrast, the agent has only an incomplete
domain model where a set of facts has randomly been
removed. For each domain the agent always had to
perform the same task.
The objective of this experimental setup is to get
deeper insights into the performance of the proposed
control system. In particular, we are interested in find-
ing an answer to the following questions: Is ACog-
Control always able to perform the given task? How
often switches ACogControl between planning and
acting? How much time is necessary for the whole
planning and reasoning process? How long is an av-
erage planning phase? How does the performance
change with a decreasing amount of initial knowl-
edge?
We conducted 10 experiments for all domains
with 1000 runs per experiment, except for the last ex-
periment where 1 run was sufficient. Let f
all
be the
number of facts in a domain, then
i
10
f
all
facts were
removed in all runs of the ith experiment from the do-
main model of the agent. Hence, in the last exper-
iment all facts are removed (for each domain) from
the agent’s domain model.
The experiments where conducted on a 64-bit In-
tel Core 2 Quad Q9400 with 4 GB memory.
4.3.2 Results
ACogControl was able to correctly perform the given
task for all domains and all runs—even in situations
where all facts were removed from the domain model
of the agent. The average number of necessary plan-
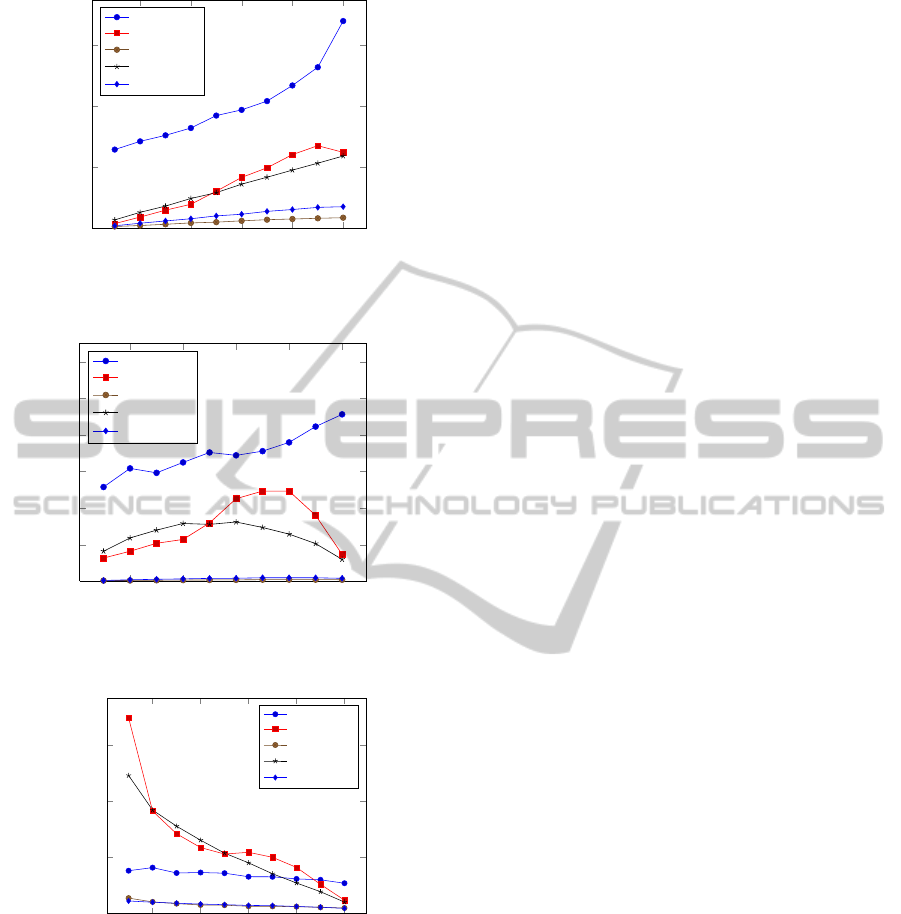
ning and execution phases is show in Figure 5. The
average number of planning and execution phases
increases with a decreasing number of initial infor-
mation, since the agent needs to stop the planning
process and execute knowledge acquisition activities
more often. We also expected the overall CPU time of
the reasoning and planning process to increase for all
domains with a decreasing amount of initial knowl-
edge. However, Figure 6 shows that this is only true
for the rover, the office and the restaurant domain.
The blocks and the depots domain show a different
behavior. For these domains the overall CPU time in-
creases until 60 respectively 80 percent of the facts
are removed from the domain model of the agent and
then decreases until all facts are removed. The re-
sults shown in Figure 7 might give an explanation for
this. They show that the average time for a planning
phase decreases with a decreasing amount of informa-
tion that initially is available for the agent. Together
with the results shown in Figure 5 these results indi-
cate that the more planning phases are performed the
shorter are the individual phases. Thus, the proposed
continual planning system, so to speak, partitions the
CONTINUAL HTN PLANNING AND ACTING IN OPEN-ENDED DOMAINS - Considering Knowledge Acquisition
Opportunities
23
0.2 0.4 0.6 0.8 1
0
100
200
300
removed facts
phases
mars rover
depots
restaurant
blocks
office
Figure 5: Average number of planning and execution
phases.
0.2 0.4 0.6 0.8 1
0
2
4
6
8
10
12
removed facts
overall planning CPU time
mars rover
depots
restaurant
blocks
office
Figure 6: Average CPU time of the overall planning and
reasoning process.
0.2 0.4 0.6 0.8 1
0
5 · 10
−2
0.1
0.15
removed facts
planning CPU time / phases
mars rover
depots
restaurant
blocks
office
Figure 7: Average CPU time of a single planning phase.
overall planning problem into a set of simpler plan-
ning problems. Moreover, the depots and the blocks
world domain indicate that the sum of the individual
planning phases can be lower even if the number of
planning phases is higher as shown by Figure 6.
5 RELATED WORK
Most of the previous approaches that are able to gen-
erate plans in partially known environments gener-
ate conditional plans—or policies—for all possible
contingencies. This includes conformant, contin-
gent or probabilistic planning approaches (Russell
and Norvig, 2010; Ghallab et al., 2004). Several plan-
ning approaches that generate conditional plans, in-
cluding (Ambros-Ingerson and Steel, 1988; Etzioni
et al., 1992; Golden, 1998; Knoblock, 1995), use
runtime variables for the purpose of representing un-
known information. Runtime variables can be used as
action parameters and enable the reasoning about un-
known future knowledge. Nevertheless, the informa-
tion represented by runtime variables is limited since
the only thing that is known about them is the fact
that they have been sensed. Furthermore, planning
approaches that generate conditional plans are com-
putationally hard, scale badly in open-ended domains
and are only applicable if it is possible to foresee all
possible outcomes of a sensing action (Ghallab et al.,
2004; Brenner and Nebel, 2009).
The most closely related previous work is (Bren-
ner and Nebel, 2009). The proposed continual plan-
ning system also deals with the challenge of generat-
ing a plan without initially having sufficient informa-
tion. In contrast to our work, this approach is based
on classical planning systems that do not natively sup-
port the representation of incomplete state models and
are unable to exploit domain specific control knowl-
edge in the form of HTN methods. Moreover, it is not
stated whether the approach can deal with open-ended
domains in which it is not only necessary to deal with
incomplete information, but also essential to, for ex-
ample, consider the existence of a priori completely
unknown objects or relations between entities of a do-
main. Furthermore, the approach is based on the as-
sumption that all information about the precondition
of a sensing action is a priori available and thus will
often (i.e., whenever this information is missing) fail
to achieve a given goal in an open-ended domain.
The Golog family of action languages—which
are based on the situation calculus (Reiter, 2001)—
have received much attention in the cognitive robotics
community. The problem of performing tasks in
open-ended domains is most extensively considered
by the IndiGolog language (Giacomo and Levesque,
1999), since programs are executed in an on-line man-
ner and thus the language to some degree is applicable
to situations where the agent posses only incomplete
information about the state of the world. Regrettably,
IndiGolog only supports binary sensing actions.
Besides Golog the only other known agent pro-
gramming language is FLUX (Thielscher, 2005)
which is based on the Fluent Calculus. FLUX is a
powerful formalism, but uses a restricted form of con-
ICAART 2012 - International Conference on Agents and Artificial Intelligence
24

ditional planning. As already pointed out, conditional
planning is not seen as an adequate approach for the
scenarios we are interested in.
6 DISCUSSION AND
CONCLUSIONS
State-of-the-art planning techniques can provide arti-
ficial agents to a certain degree with autonomy and
robustness. Unfortunately, reasoning about external
information and the acquisition of relevant knowledge
has not been sufficiently considered in existing plan-
ning approaches and is seen as an important direction
of further growth (Nau, 2007).
We have proposed a new continual HTN plan-
ning based control system that can reason about pos-
sible, relevant and possibly-acquirable extensions of
a domain model. It makes an agent capable of au-
tonomously generating and answering relevant ques-
tions. The domain specific information encoded in
HTN methods not only helps to prune the search
space for classical planning problems but can also
nicely be exploited to rule out irrelevant extensions
of a domain model.
Planning in open-ended domains is obviously
more difficult than planning based on the assump-
tion that all information is available at planning time.
Nevertheless, the experimental results indicate that
the proposed approach partitions the overall planning
problem into a number of simpler planning prob-
lems. This effect can make continual planning in
open-ended domains sufficiently fast for real world
domains. Additionally, it should be considered that
the execution of a single action is often much more
time intensive for several agents (e.g., robots) than the
planning phases of the evaluated domains.
Like classical HTN planning the proposed con-
tinual planning and acting based control system is
domain-configurable
4
. This means that the core plan-
ning, reasoning and controlling engines are domain
independent, but can exploit domain specific informa-
tion. For all evaluated domains we only defined a few
simple HTN methods. We expect that the evaluation
results will be significantly better if one adds more so-
phisticated domain specific information to the domain
models.
ACKNOWLEDGEMENTS
This work is founded by the DFG German Research
4
as described in (Nau, 2007)
Foundation (grant #1247) – International Research
Training Group CINACS (Cross-modal Interactions
in Natural and Artificial Cognitive Systems).
REFERENCES
Ambros-Ingerson, J. A. and Steel, S. (1988). Integrating
planning, execution and monitoring. In AAAI, pages
83–88.
Brenner, M. and Nebel, B. (2009). Continual plan-
ning and acting in dynamic multiagent environ-
ments. Autonomous Agents and Multi-Agent Systems,
19(3):297–331.
Etzioni, O., Hanks, S., Weld, D. S., Draper, D., Lesh, N.,
and Williamson, M. (1992). An approach to planning
with incomplete information. In KR, pages 115–125.
Ghallab, M., Nau, D., and Traverso, P. (2004). Automated
Planning Theory and Practice. Elsevier Science.
Giacomo, G. D. and Levesque, H. J. (1999). An incremen-
tal interpreter for high-level programs with sensing. In
Levesque, H. J. and Pirri, F., editors, Logical Founda-
tion for Cognitive Agents: Contributions in Honor of
Ray Reiter, pages 86–102. Springer, Berlin.
Golden, K. (1998). Leap before you look: Information gath-
ering in the puccini planner. In AIPS, pages 70–77.
Knoblock, C. A. (1995). Planning, executing, sensing, and
replanning for information gathering. In IJCAI, pages
1686–1693.
Littman, M. L., Goldsmith, J., and Mundhenk, M. (1998).
The computational complexity of probabilistic plan-
ning. J. Artif. Intell. Res. (JAIR), 9:1–36.
Nau, D. S. (2007). Current trends in automated planning.
AI Magazine, 28(4):43–58.
Nau, D. S., Cao, Y., Lotem, A., and Mu
˜
noz-Avila, H.
(1999). Shop: Simple hierarchical ordered planner.
In IJCAI, pages 968–975.
Reiter, R. (2001). Knowledge in Action: Logical Founda-
tions for Specifying and Implementing Dynamical Sys-
tems. The MIT Press, illustrated edition edition.
Rintanen, J. (1999). Constructing conditional plans by a
theorem-prover. J. Artif. Intell. Res. (JAIR), 10:323–
352.
Russell, S. J. and Norvig, P. (2010). Artificial Intelligence:
A Modern Approach. Prentice Hall.
Thielscher, M. (2005). FLUX: A logic programming
method for reasoning agents. Theory Pract. Log. Pro-
gram., 5:533–565.
CONTINUAL HTN PLANNING AND ACTING IN OPEN-ENDED DOMAINS - Considering Knowledge Acquisition
Opportunities
25
