
Testing Fuzzy Hypotheses with Fuzzy Data and Defuzzification of the
Fuzzy p-value by the Signed Distance Method
R
´
edina Berkachy and Laurent Donz
´
e
Applied Statistics and Modelling, Department of Informatics, Faculty of Economics and Social Sciences,
University of Fribourg, Boulevard de P
´
erolles 90, 1700 Fribourg, Switzerland
Keywords:
Fuzzy P-Value, Fuzzy Statistics, Fuzzy Hypotheses, Fuzzy Data, One-Sided and Two-Sided Tests, Defuzzifi-
cation, Signed Distance Method.
Abstract:
We extend the classical approach of hypothesis testing to the fuzzy environment. We propose a method based
on fuzziness of data and on fuzziness of hypotheses at the same time. The fuzzy p-value with its α-cuts
is provided and we show how to defuzzify it by the signed distance method. We illustrate our method by
numerical applications where we treat a one and a two sided test. For the one-sided test, applying our method
to the same data and performing tests on the same significance level, we compare the defuzzified p-values
between different cases of null and alternative hypotheses.
1 INTRODUCTION AND
MOTIVATION
The so-called classical approach of the statistical in-
ference is the most used one in statistics. Its exten-
sion to the fuzzy environment was of a big discussion
in many research papers in the last decade. Several
testing methods and approaches in the fuzzy context
were treated. We mention for example (Filzmoser
and Viertl, 2004), (Parchami et al., 2010), (Grze-
gorzewski, 2000) and many others. For instance,
(Grzegorzewski, 2000) proposed a fuzzy test based
on confidence intervals. This test leads to a fuzzy de-
cision, which provides a degree of conviction, mean-
ing a degree of acceptability of the null and alterna-
tive hypotheses. From another side, (Filzmoser and
Viertl, 2004) extended the classical test to a fuzzy test
asserting that the fuzziness is a matter of data. They
proposed a fuzzy p-value and a “three decision” pro-
cedure where no rejection of both null and alternative
hypotheses is considered. (Parchami et al., 2010) rea-
soned similarly to (Filzmoser and Viertl, 2004) but as-
sumed that the fuzziness is coming from the hypothe-
ses instead of the data.
On the other hand, defuzzifying a fuzzy p-value
could be in several situations important to make a
decision. (Grzegorzewski, 2001) presented differ-
ent defuzzification operators to defuzzify his pro-
posed fuzzy p-value. In the same way, (Berkachy and
Donz
´
e, 2017), based on the work of (Grzegorzewski,
2000), described how one can defuzzify a fuzzy deci-
sion by the so-called signed distance defuzzification
method. This method was basically used for instance
by (Berkachy and Donz
´
e, 2016) in the context of eval-
uating linguistic questionnaires.
In this paper, we reconsider the tests’ procedures
described by (Filzmoser and Viertl, 2004) and (Par-
chami et al., 2010). We propose an inference method
based on both fuzzy data and fuzzy hypotheses. We
also put our attention on fuzzy p-value with its α-cuts,
and show how to apply the signed distance method to
defuzzify this fuzzy p-value. We know that while the
defuzzification of a fuzzy set reduces some informa-
tions of it, defuzzifying a fuzzy p-value can be useful
in several cases of decision making. At last, we give
two numerical examples of a one-sided and a two-
sided tests. On the same occasion, we play with a
set of different fuzzy null and alternative hypotheses
in order to be able to compare and understand the dif-
ferences between cases.
To summarize, we present in Section 2 some use-
ful definitions and notations. The Section 3 is devoted
to a brief presentation of the signed distance defuzzi-
fication method. In Section 4, we recall briefly the
classical testing approach, and we describe the proce-
dure of testing fuzzy hypotheses with fuzzy data. We
finally end in Section 5 with two numerical examples.
Berkachy R. and DonzÃl’ L.
Testing Fuzzy Hypotheses with Fuzzy Data and Defuzzification of the Fuzzy p-value by the Signed Distance Method.
DOI: 10.5220/0006500602550264
In Proceedings of the 9th International Joint Conference on Computational Intelligence (IJCCI 2017), pages 255-264
ISBN: 978-989-758-274-5
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 DEFINITIONS AND
NOTATIONS
Let us recall some fundamental definitions and nota-
tions useful in further sections.
Definition 2.1 (Fuzzy Set).
If A is a collection of objects denoted generically by x
then a fuzzy set
˜
X in A is a set of ordered pairs:
˜
X = {(x,µ
˜
X
(x)) : x ∈ A}, (1)
where µ
˜
X
(x) is the membership function of x in
˜
X
which maps A to the closed interval [0,1] that char-
acterizes the degree of membership of x in
˜
X.
Definition 2.2 (Fuzzy Number).
A fuzzy number
˜
X is a convex and normalized fuzzy set
on R, such that its membership function is continuous
and its support is bounded.
Definition 2.3 (α-cut of a Fuzzy Number).
The α-cut of a fuzzy number
˜
X is a non-fuzzy set de-
fined as:
˜
X
α
= {x ∈R : µ
˜
X
(x) > α}. (2)
The fuzzy number
˜
X can be represented by the family
set {
˜
X
α
: α ∈ [0,1]} of its α-cuts.
The α-cut of a fuzzy number
˜
X is the closed in-
terval [
˜
X
L
α
,
˜
X
R
α
].
˜
X
L
α
= inf{x ∈ R : µ
˜
X
(x) > α)} is its
left α-cut and
˜
X
R
α
= sup{x ∈R : µ
˜
X
(x) > α)} its right
one. We note that the α-cut of a fuzzy number
˜
X is
a union of finite compact and bounded intervals. Fur-
thermore, the least-upper bound property generalized
to ordered sets and the extension principle induces the
following expression of the membership function of
˜
X
(see (Viertl, 2011)):
µ
˜
X
(x) = max{αI
˜
X
α
(x) : α ∈ [0,1]}, (3)
where I
˜
X
α
(x) is the following indicator function:
I
˜
X
α
(x) = I
{x∈R;µ
˜
X
≥α}
(x)
=
(
1 if µ
˜
X
(x) ≥ α,
0 otherwise.
(4)
Definition 2.4 (Triangular Fuzzy Number).
A triangular fuzzy number
˜
X is a fuzzy number with
membership function given as follows:
µ
˜
X
(x) =
x−u
v−u
if u < x ≤v,
x−w
v−w
if v < x ≤w,
0 elsewhere.
(5)
It is common to represent a triangular fuzzy num-
ber by the tuple of three values u, v and w, i.e.
˜
X =
(u,v, w), where u < v < w ∈ R. For a triangular fuzzy
number, the left and right α-cuts
˜
X
L
α
and
˜
X
R
α
are given
respectively by
(
˜
X
L
α
= u + (v −u)α,
˜
X
R
α
= w −(w −v)α.
(6)
3 THE SIGNED DISTANCE
DEFUZZIFICATION METHOD
The signed distance defuzzification method was
described mainly by (Yao and Wu, 2000) and (Lin
and Lee, 2010). (Berkachy and Donz
´
e, 2016) use
it extensively in the context of evaluating linguistic
questionnaires. The method appears to have nice
properties and will be implemented in our test proce-
dure for the defuzzification of the fuzzy p-values. Let
us define briefly this measure.
Definition 3.1. The signed distance d
0
(e,0) mea-
sured from 0 for a real value e in R is e.
Definition 3.2. Let
˜
X be a fuzzy set on R, such as
˜
X = {(x, µ
˜
X
(x))|x ∈ R} where µ
˜
X
(x) is the member-
ship function of x in
˜
X. Suppose that the α-cuts
˜
X
L
α
and
˜
X
R
α
exist, and as a function of α are integrable for
α ∈ [0,1]. The signed distance of
˜
X measured from
the fuzzy origin
˜
0 is:
d(
˜
X,
˜
0) =
1
2
Z
1
0
[
˜
X
L
α
+
˜
X
R
α
]dα. (7)
4 TESTING FUZZY
HYPOTHESES WITH FUZZY
DATA
(Filzmoser and Viertl, 2004) and (Parchami et al.,
2010) were ones of many that treated the problem of
testing hypotheses in the fuzzy environment. They
introduced as instance the concept of fuzzy p-value.
Inspired by their methods, we propose a hypotheses
testing method based on fuzzy hypotheses and fuzzy
data at the same time. The signed distance will be
applied in order to defuzzify the fuzzy p-value. But,
first, let us recall the main ideas of the classical ap-
proach.

4.1 Testing Hypotheses in the Classical
Approach
We consider a population described by a probability
distribution P
θ
depending on the parameter θ, and be-
longing to a family of distributions P = {P
θ
: θ ∈ Θ}.
Testing hypotheses on a parameter θ in the classical
approach consists on considering a null hypothesis
denoted by H
0
, H
0
: θ ∈ Θ
H
0
and an alternative one
denoted by H
1
, H
1
: θ ∈ Θ
H
1
. Θ
H
0
and Θ
H
1
are
subsets of Θ such that Θ
H
0
∩Θ
H
1
=
/
0. A test statistic
is a function of a random sample Y
1
,. .. ,Y
n
used in
testing the null hypothesis against the alternative one.
We call T such a test statistic, where T : R
n
7→ R. For
this test, two decisions are often treated: not reject
the null hypothesis H
0
or reject the null hypothesis
H
0
. However, the Neyman-Pearson testing approach
(Neyman and Pearson, 1933) could consider the pos-
sibility of having a three decision procedure where
a third case appears: both the null and alternative
hypotheses are neither rejected or not rejected.
The hypothesis testing dilemma is reduced to a
decision problem based on the test statistic T , where
the space of possible values of T is decomposed into
a rejection region R and its complement R
c
. Three
forms of R are possible depending on the alternative
hypotheses H
1
.
Let us suppose the following three tests:
1. H
0
: θ ≥ θ
0
vs. H
1
: θ < θ
0
; (8)
2. H
0
: θ ≤ θ
0
vs. H
1
: θ > θ
0
; (9)
3. H
0
: θ = θ
0
vs. H
1
: θ 6= θ
0
; (10)
where θ is the parameter to test and θ
0
a particular
value of this parameter.
Then, we would reject the null hypothesis H
0
if re-
spectively:
1. T ≤ t
l
(one-sided test); (11)
2. T ≥ t
r
(one-sided test); (12)
3. T /∈ (t
a
,t
b
) (two-sided test); (13)
where t
l
, t
r
, t
a
and t
b
are quantiles of the distribution
of T .
From another side, we denote by δ the significance
level of the test. The quantiles of the distribution t
l
,
t
r
, t
a
, and t
b
are found such that the following proba-
bilities hold:
1. P(T ≤ t
l
) = δ, (14)
2. P(T ≥ t
r
) = δ, (15)
3. P(T ≤ t
a
) = P(T ≥t
b
) =
δ
2
. (16)
By this method, we decide to reject the null hypoth-
esis if the value of the test statistic t = T (y
1
,. .. ,y
n
)
falls into the rejection region R.
A pratical way to take a decision is to calculate the
p-value in order to decide whether we reject or don’t
the null hypothesis H
0
. Notice that a p-value depends
on different elements as, for instance, the sample and
its distribution, the boundary of the null hypothesis,
the distribution of the test statistic and its observed
value. We define a p-value p
θ∗
as function of the
boundary θ∗ of the null-hypothesis. This p-value for
the three cases (11), (12) and (13) can be written re-
spectively as follows:
1. p
θ
∗
= P
θ
∗
(T ≤t), (17)
2. p
θ
∗
= P
θ
∗
(T ≥t), (18)
3. p
θ
∗
= 2min[P
θ
∗
(T ≤t),P
θ
∗
(T ≥t)], (19)
where “P
θ
∗
” means that the probability distribution
depends on the boundary θ
∗
.
The decision is made by comparing the p-value to
the significance level δ: If the p-value is smaller than
δ, we reject the null hypothesis H
0
. Otherwise, we
don’t reject it.
4.2 Fuzzy Hypotheses
In their paper, (Filzmoser and Viertl, 2004) discussed
the test of hypotheses in the case of fuzzy data.
However, (Parchami et al., 2010) asserted that the
fuzziness is rather coming from the hypothesis. In
the following, we are treating a case inspired by the
above papers but where both data and hypotheses are
fuzzy. First, let us define a fuzzy hypothesis.
Definition 4.1 (Fuzzy Hypothesis).
A fuzzy hypothesis
˜
H on the parameter θ, denoted as
“
˜
H : θ is H”, is a fuzzy subset of the parameter space
Θ with its corresponding membership function µ
˜
H
.
Remark 4.1. A given fuzzy hypothesis
˜
H reduces to
a crisp hypothesis H when the membership function
µ
˜
H
= I
Θ
.

It is common practice to postulate as membership
functions of a fuzzy left one-sided hypothesis (an in-
creasing function) or of a fuzzy right one-sided hy-
pothesis (a decreasing function) respectively the fol-
lowing functions:
µ
˜
H
OL
(x) =
0 if x < u;
x−u
v−u
if u ≤ x < v;
1 if x ≥v.
(20)
µ
˜
H
OR
(x) =
1 if x ≤u;
x−v
u−v
if u < x ≤ v;
0 if x > v;
(21)
In that case, we simply note these fuzzy hypotheses
as
˜
H
OL
= (u,v) and
˜
H
OR
= (u,v).
A fuzzy two-sided hypothesis
˜
H
T
is gener-
ally treated as a triangular fuzzy number, i.e.
˜
H
T
= (u,v, w), with membership function (5).
Consider now a crisp random sample Y
1
,. .. ,Y
n
with probability distribution P
θ
and a corresponding
fuzzy random sample
˜
X = (
˜
X
1
,. .. ,
˜
X
n
) where
˜
X
i
is a
fuzzy number as described in Definition 2.2. We de-
note by µ
˜
X
the membership function of
˜
X, where µ
˜
X
:
R
n
→[0,1]. We suppose that it exists a given value of
x, x considered as a n-dimensional vector, for which
µ
˜
X
(x) reaches 1, and that the α-cuts of µ
˜
X
build a
closed compact and convex subset of R
n
. On the other
hand, consider furthermore a real valued function φ
such as φ: R
n
→R. Denote by the fuzzy number
˜
Z the
result of applying the function φ to the fuzzy random
sample, i.e.
˜
Z = φ(
˜
X
1
,. .. ,
˜
X
n
). Then, by the extension
principle (Zadeh, 1965), the membership function µ
˜
Z
of
˜
Z is written in the following manner:
µ
˜
Z
(z) =
(
sup{µ
˜
X
(x) : φ(x) = z} if ∃x : φ(x) = z,
0 if @x : φ(x) = z,
(22)
for all z ∈ R. Furthermore, the α-cuts of
˜
Z are given
by:
˜
Z
α
= [min
x∈
˜
X
α
φ(x),max
x∈
˜
X
α
φ(x)], (23)
for all α ∈ (0,1] (Viertl, 2011).
Finally, we have to define the fuzzy boundaries of
fuzzy hypotheses.
Definition 4.2 (Boundary of a Hypothesis).
The boundary
˜
H
∗
of a hypothesis
˜
H : θ is H, is a fuzzy
subset of Θ, with membership function µ
H
∗
.
As instance, the fuzzy boundaries corresponding
to the tests (8), (9) and (10) are given respectively by:
1.
˜
H
∗
= H if θ ≤ θ
0
, 0 otherwise,
(
˜
H is left one-sided and µ
˜
H
OL
increasing);
2.
˜
H
∗
= H if θ ≥ θ
0
, 0 otherwise,
(
˜
H is right one-sided and µ
˜
H
OR
decreasing);
3.
˜
H
∗
= H, (
˜
H is two-sided).
4.3 Fuzzy p-value
Considering hypotheses as fuzzy let us as well see p-
values as fuzzy ones, and in this case taking α-cuts
of the fuzzy p-values can help to evaluate the results
of the tests. Taking in consideration the three possi-
ble rejection regions as defined in (11), (12) and (13),
the following proposition shows how to calculate the
corresponding α-cuts.
Proposition 4.1. Given a test procedure based on
fuzziness of data and hypotheses. Considering the
three rejection regions (11), (12) and (13), the α-cuts
of the fuzzy p-value ˜p are given by:
1. ˜p
α
= [P
θ
R
(T ≤
˜
t
L
α
),P
θ
L
(T ≤
˜
t
R
α
)]; (24)
2. ˜p
α
= [P
θ
L
(T ≥
˜
t
R
α
),P
θ
R
(T ≥
˜
t
L
α
)]; (25)
3. ˜p
α
=
[2P
θ
R
(T ≤
˜
t
L
α
),2P
θ
L
(T ≤
˜
t
R
α
)] if A
l
> A
r
,
[2P
θ
L
(T ≥
˜
t
R
α
),2P
θ
R
(T ≥
˜
t
L
α
)] if A
l
≤ A
r
;
(26)
for all α ∈(0, 1], where
˜
t
L
α
and
˜
t
R
α
are the left and right
α-cuts of
˜
t = φ(
˜
X
1
,. .. ,
˜
X
n
), θ
L
and θ
R
are the α-cuts of
the boundary of
˜
H
0
, A
l
is the area under the member-
ship function µ
˜
t
of the fuzzy number
˜
t on the left side
of the median, and A
r
is the one on the right side. In
this case, one has to decide on which side the median
is located based on the biggest amount of fuzziness.
Proof 4.1. Since we are treating the case of both
fuzzy data and fuzzy hypotheses, the proof of the
Proposition 4.1 will be done in three steps:
1. According to the above sections, the resulting
fuzzy value
˜
t = T (
˜
X
1
,. .. ,
˜
X
n
) is fuzzy with its
membership function µ
˜
t
. We denote by supp(µ
˜
t
),
the support of µ
˜
t
given by supp(µ
˜
t
) = {x ∈ R :
µ
˜
t
(x) > 0}. Using the extension principle, (Filz-
moser and Viertl, 2004) wrote the (precise) p-
value p for
˜
T for a one-sided test respectively to
cases (8) and (9) as follows:
1. p = P(T ≤t = max supp(µ
˜
t
)); (27)
2. p = P(T ≥t = min supp(µ
˜
t
)). (28)

Our purpose at this moment is to write the α-cuts
of the fuzzy p-value ˜p. Hence, we know that µ
˜
t
is a membership function and all its α-cuts are
compact and closed on R, then we can define the
α-cuts of the p-value ˜p
D
related to (27) and (28)
by
1. ˜p
FV
α
= [P(T ≤
˜
t
L
α
),P(T ≤
˜
t
R
α
)]; (29)
2. ˜p
FV
α
= [P(T ≥
˜
t
R
α
),P(T ≥
˜
t
L
α
)]. (30)
The same procedure can be easily written for the
two-sided test.
2. From another side, we want to extend these for-
mulas to the case of fuzzy hypothesis. (Parchami
et al., 2010) related the fuzziness to the hypothe-
sis and presented the α-cuts of the fuzzy p-value
in the following form:
1. ˜p
PA
α
= [P
θ
R
(T ≤t),P
θ
L
(T ≤t)]; (31)
2. ˜p
PA
α
= [P
θ
L
(T ≥t),P
θ
R
(T ≥t)]; (32)
3. ˜p
PA
α
=
(
[2P
θ
R
(T ≤t),2P
θ
L
(T ≤t)] if A
l
> A
r
,
[2P
θ
L
(T ≥t),2P
θ
R
(T ≥t)] if A
l
≤ A
r
;
(33)
Referring to the Equations (17), (18), (29), (30),
to the Definition 4.1 and to the fuzzy p-value dis-
cussed by (Parchami et al., 2010), we get ˜p
R
α
and
˜p
R
α
, the left and right α-cuts of the fuzzy p-values
based on fuzziness of data and hypotheses given
by Proposition 4.1.
3. We finally have to be sure that the properties of
the membership function are fulfilled: the facts
that µ
˜
t
and µ
˜
H
0
are membership functions and
the probabilities are restricted to [0, 1] induce
that the resulting membership functions of ˜p
are between 0 and 1 and reach 1 for a given
value. Furthermore, the α-cuts of each case
form a closed finite interval and thus they are
compact and convex subsets of R for all α ∈(0,1].
For the decision making, (Filzmoser and Viertl,
2004) asserted that a three-decision problem is
adopted based on the left and right α-cuts of ˜p. For a
test with a significance level δ, the decisions are made
by the following rules:
• ˜p
R
α
< δ: reject the null hypothesis;
• ˜p
L
α
> δ: not reject the null hypothesis;
• δ ∈ [ ˜p
L
α
, ˜p
R
α
]: both null and alternative hypothesis
are neither rejected or not.
4.4 Defuzzification of the Fuzzy p-value
by the Signed Distance
As mentioned above, the signed distance method is
an attractive one to defuzzify fuzzy numbers. Thus,
we intend to apply this operator in order to defuzzify
the fuzzy p-value and understand whether the deci-
sion made with resulting p-value is similar to the one
in the classical and fuzzy approaches. The idea is to
consider the α-cuts of the fuzzy p-values found in the
previous section. We use the equation (7) to defuzzify
the fuzzy p-value given in equations (24), (25) and
(26). The defuzzified p-values are written as follows:
1. d( ˜p,
˜
0) =
1
2
Z
1
0
(P
θ
R
(T ≤
˜
t
L
α
) + P
θ
L
(T ≤
˜
t
R
α
))dα;
(34)
2. d( ˜p,
˜
0) =
1
2
Z
1
0
(P
θ
L
(T ≥
˜
t
R
α
) + P
θ
R
(T ≥
˜
t
L
α
))dα;
(35)
3. d( ˜p,
˜
0) =
1
2
R
1
0
(2P
θ
R
(T ≥
˜
t
L
α
) + 2P
θ
L
(T ≥
˜
t
R
α
))dα, if A
l
> A
r
,
1
2
R
1
0
(2P
θ
L
(T ≤
˜
t
R
α
) + 2P
θ
R
(T ≤
˜
t
L
α
))dα, if A
l
≤ A
r
.
(36)
To interpret, the decision of this testing problem
using the defuzzified p-values is similar to the classi-
cal approach where two main decisions are taken into
account:
• d( ˜p,
˜
0) < δ: reject the null hypothesis;
• d( ˜p,
˜
0) > δ: not reject the null hypothesis;
• d( ˜p,
˜
0) = δ (a rare case): one should decide
whether to reject or not the null hypothesis.
The decision of no rejecting H
0
or H
1
doesn’t oc-
cur in this case since the p-value is now on crisp. We
remember that in the fuzzy sense, the no-decision case
is considered. Thus, if one has to defuzzify the p-
value, this case will no longer be possible. Not detect-
ing the no-decision region might be a disadvantage of
defuzzifying the fuzzy p-value.
5 NUMERICAL APPLICATIONS
In this section, we propose two numerical applica-
tions to help the reader to understand the reasoning.
The first one treats a one-sided test as (9), and the
second one a two-sided test as (10).

Example 5.1. Consider a random sample of size n =
9 from a normal distribution with an unknown mean
and a standard deviation of 1, N (µ,1). The aim is to
test on the significance level δ = 0.05 the following
hypotheses:
˜
H
0
: µ is approximately 15,
˜
H
1
: µ is approximately bigger than 15.
Suppose that not only the hypotheses are fuzzy but
the sample as well. Let us assume that the fuzzy
null hypothesis is given by the triangular fuzzy num-
ber
˜
H
T
0
= (14.8,15,15.2) and the alternative one by
˜
H
OR
1
= (15,16). These hypotheses are shown in Fig-
ure 2. We write the α-cuts of
˜
H
T
0
as:
(
˜
H
T
0
)
α
=
(
(
˜
H
T
0
)
L
α
= 14.8 + 0.2α;
(
˜
H
T
0
)
R
α
= 15.2 −0.2α.
(37)
We assume furthermore that the membership func-
tion of the observed fuzzy sample mean
˜
X is given by
the following:
µ
˜
X
(x) =
2x −31 if 15.5 < x ≤16;
−2x + 33 if 16 < x ≤16.5;
0 otherwise;
(38)
with the corresponding α-cuts:
˜
X
α
=
(
˜
X
L
α
= 15.5 + 0.5α;
˜
X
R
α
= 16.5 −0.5α.
(39)
The rejection region in this one-sided test is given
by equation (12). Hence, the expression of the corre-
sponding α-cuts ˜p
α
of the fuzzy p-value are given by
equation (25). Combining all the previous informa-
tions, ˜p
α
is as follows:
˜p
α
= [
Z
∞
θ
1
(α)
(2π)
−
1
2
exp(
−u
2
2
)du,
Z
∞
θ
2
(α)
(2π)
−
1
2
exp(
−u
2
2
)du], (40)
where θ
1
(α) et θ
2
(α) are the following functions of α
based on Equations 37 and 39:
θ
1
(α) =
˜
X
R
α
−(
˜
H
T
0
)
L
α
σ /
√
n
= 5.1 −2.1 ×α
and
θ
2
(α) =
˜
X
L
α
−(
˜
H
T
0
)
R
α
σ /
√
n
= 0.9 + 2.1 ×α.
1
1
The sum S
˜
X
1
,
˜
X
2
of two fuzzy numbers
˜
X
1
and
˜
X
2
with
The membership function induced by the fuzzy p-
value ˜p is shown in Figure 3. Since the fuzzy p-value
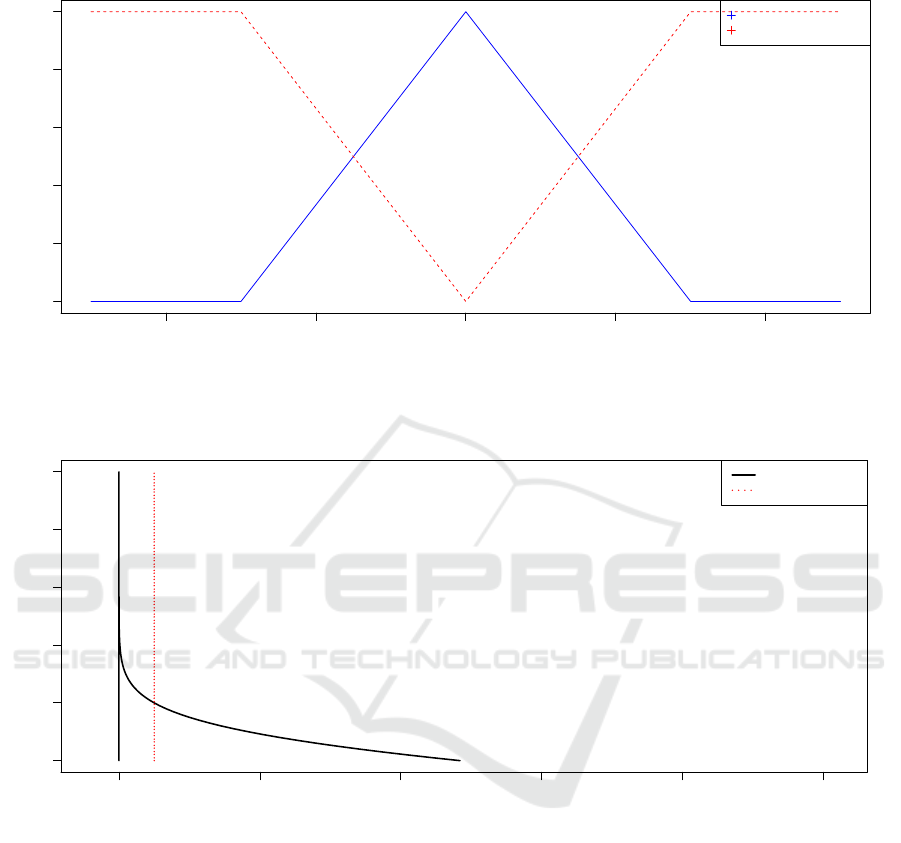
and the significance level overlap, we cannot make
any decision visually. In order to make one, we de-
fuzzify the fuzzy p-value. Applying the signed distance
method (equation (35)), we get the following result:
d( ˜p,
˜
0) =
1
2
Z
1
0
(P
θ
L
(T ≥
˜
t
R
α
) + P
θ
R
(T ≥
˜
t
L
α
))dα
=
1
2
Z
1
0
(
Z
∞
5.1−2.1×α
(2π)
−
1
2
exp(
−u
2
2
)du +
Z
∞
0.9+2.1×α
(2π)
−
1
2
exp(
−u
2
2
)du)dα
= 0.0239.
We remark that the defuzzified p-value (0.0239)
is smaller than the significance level (0.05). In this
case, the decision is to reject the null hypothesis at
the level δ = 0.05.
Furthermore, we are interested in understanding
the influence of the form of the fuzzy hypotheses on
the decision of the test. Let us view some variations of
the fuzzy hypotheses. Table 1 shows the tests where
we change the null or the alternative fuzzy hypothe-
ses of Example 5.1. Figure 1 displays the member-
ship functions of the fuzzy p-values obtained from all
these tests. We can see that although the fuzzy al-
ternative hypothesis determines the rejection region,
then it does not influence anymore the decision of the
test. Hence, the defuzzified p-value is sensitive to the
fuzzy null hypothesis. From another side, if one has
to compare between defuzzified p-values of the tests
simulated versus the fuzzy p-values illustrated in Fig-
ure 1, we can say that the highest p-value corresponds
to the largest spreaded fuzzy p-value. It is the oppo-
site for the lowest one. Therefore, we can say that
the defuzzified p-value can be a relevant indicator of
fuzziness of the null hypothesis in order to make the
most convenient decision.
Example 5.2. Consider again a random sample of
size n = 49 from a normal distribution with an un-
known mean and a standard deviation of 1, N (µ,1).
their corresponding α-cuts
˜
X
1
α
= [
˜
X
1
L
α
,
˜
X
1
R
α
] and
˜
X
2
α
=
[
˜
X
2
L
α
,
˜
X
2
R
α
] is written by:
S
˜
X
1
,
˜
X
2
=
˜
X
1
α
+
˜
X
2
α
= [
˜
X
1
L
α
+
˜
X
2
L
α
,
˜
X
1
R
α
+
˜
X
2
R
α
],
and their difference D
˜
X
1
,
˜
X
2
given by:
D
˜
X
1
,
˜
X
2
=
˜
X
1
α
−
˜
X
2
α
= [
˜
X
1
L
α
−
˜
X
2
R
α
,
˜
X
1
R
α
−
˜
X
2
L
α
].
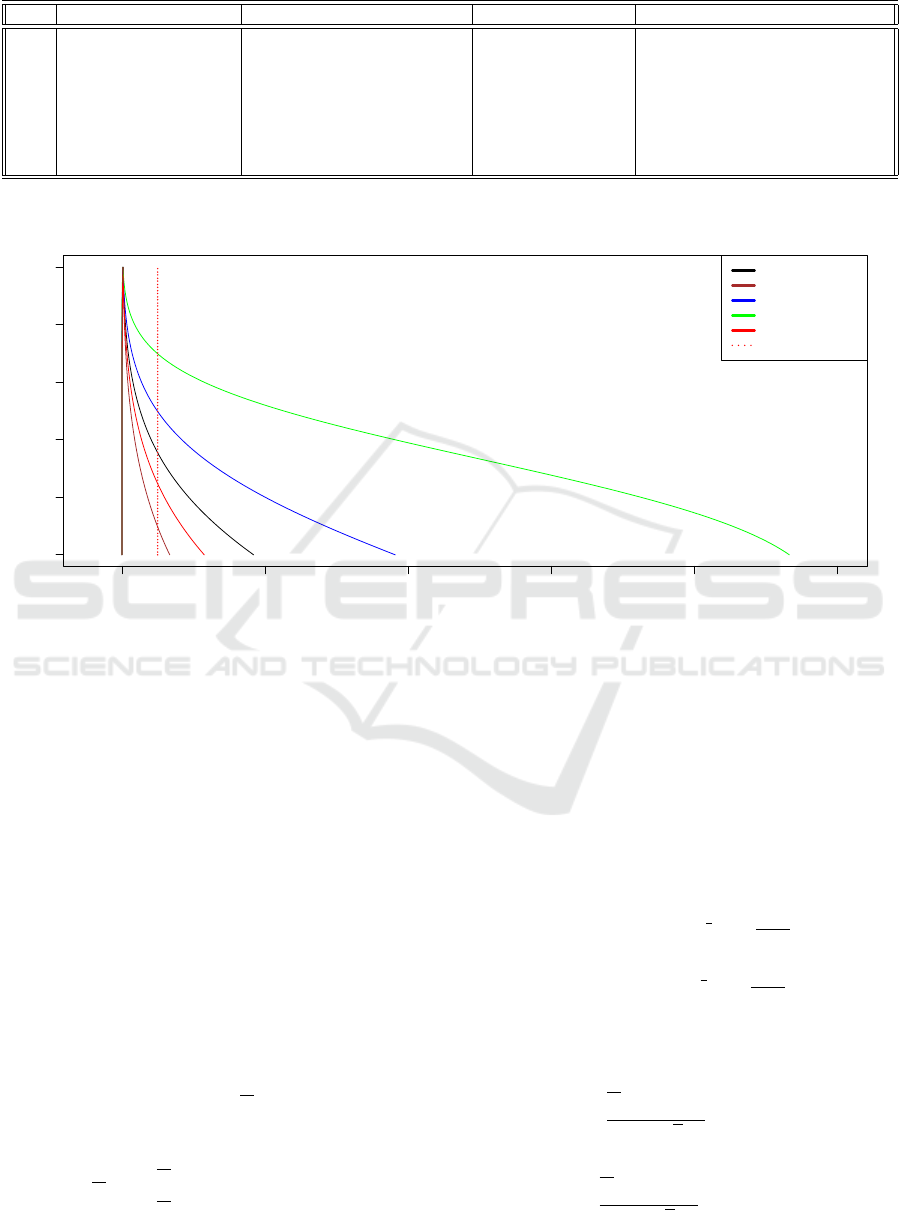
Table 1: Testing different hypotheses on the significance level δ = 0.05 - Example 5.1.
Test Fuzzy null hypothesis Fuzzy alternative hypothesis Defuzzified p-value Decision
1
˜
H
T
0
= (14.8, 15.0, 15.2)
˜
H
OR
1
= (15, 16) 0.0239 Reject the null hypothesis
2
˜
H
T
0
= (14.8, 15.0, 15.2)
˜
H
OR
1
= (16, 17) 0.0239 Reject the null hypothesis
3
˜
H
T
0
= (14.8, 15.0, 15.2)
˜
H
OR
1
= (16, 16) 0.0239 Reject the null hypothesis
4
˜
H
T
0
= (15.0, 15.0, 15.0)
˜
H
OR
1
= (15, 16) 0.0098 Reject the null hypothesis
5
˜
H
T
0
= (14.6, 15.0, 15.4)
˜
H
OR
1
= (15, 16) 0.0494 Slightly Reject the null hypothesis
6
˜
H
T
0
= (14.0, 15.0, 16.0)
˜
H
OR
1
= (15, 16) 0.1699 Not Reject the null hypothesis
7
˜
H
T
0
= (14.9, 15.0, 15.1)
˜
H
OR
1
= (15, 16) 0.0156 Reject the null hypothesis
0.0 0.2 0.4 0.6 0.8 1.0
0.0 0.2 0.4 0.6 0.8 1.0
Membership functions of the fuzzy p−values corresponding to different tests
p
µ
Test 1, 2 and 3
Test 4
Test 5
Test 6
Test 7
Significance level
Figure 1: Membership functions of the fuzzy p-values corresponding to the tests in Table 5.1 at the significance level δ = 0.05.
The aim is to test on the significance level δ = 0.05
the following hypotheses
˜
H
0
: µ is near 100,
˜
H
1
: µ is away from 100.
Let us suppose that the null and alternative hypothe-
ses are fuzzy and given by the fuzzy triangular num-
bers
˜
H
T
0
= (99.7,100,100.3) and the alternative one
by
˜
H
T
1
= 1 −
˜
H
T
0
as seen in Figure 4. The α-cuts of
˜
H
T
0
are:
(
˜
H
T
0
)
α
=
(
(
˜
H
T
0
)
L
α
= 99.7 + 0.3α;
(
˜
H
T
0
)
R
α
= 100.3 −0.3α.
(41)
Furthermore let us assume that the α-cuts of the
observed fuzzy sample mean
˜
X are given by the fol-
lowing:
˜
X
α
=
(
˜
X
L
α
= 100.4 + 0.6α;
˜
X
R
α
= 101.6 −0.6α.
(42)
The rejection region in this two-sided test is given
by the equation (13). We note that in a standardized
normal distribution, the median is equal to the mean,
thus we consider that the fuzzy median is equal to the
one expressed by the null hypothesis. The α-cuts ˜p
α
of
the fuzzy p-value can be computed by equation (26).
And since we are in the case of A
l
≤ A
r
, we get that
˜p
α
is as follows:
˜p
α
= [2
Z
∞
θ
1
(α)
(2π)
−
1
2
exp(
−u
2
2
)du,
2
Z
∞
θ
2
(α)
(2π)
−
1
2
exp(
−u
2
2
)du]. (43)
where θ
1
(α) et θ
2
(α) are the following functions of
α:
θ
1
(α) =
˜
X
R
α
−(
˜
H
T
0
)
L
α
σ /
√
n
= 0.9 + 8.1 ×α
and
θ
2
(α) =
˜
X
L
α
−(
˜
H
T
0
)
R
α
σ /
√
n
= 17.1 −8.1 ×α.

Figure 5 shows the fuzzy p-value at the signifi-
cance level δ = 0.05.
We defuzzify this fuzzy p-value by the signed dis-
tance method using the equation (36) and we obtain
the following distance:
d( ˜p,
˜
0) =
1
2
Z
1
0
2 ×(P
θ
L
(T ≥
˜
t
R
α
) + 2 ×P
θ
R
(T ≥
˜
t
L
α
))dα
=
1
2
Z
1
0
(2 ×
Z
∞
0.9+8.1×α
(2π)
−
1
2
exp(
−u
2
2
)du +
2 ×
Z
∞
17.1−8.1×α
(2π)
−
1
2
exp(
−u
2
2
)du)dα
= 0.0123989.
The defuzzified p-value (0.0123989) is smaller
than the significance level (0.05), then the decision
will be to reject the null hypothesis at the level δ =
0.05.
6 CONCLUSION
In this work, we presented a hypothesis testing proce-
dure when both data and hypotheses are fuzzy. We
introduced as well a fuzzy p-value with its α-cuts.
We discussed after the defuzzification of this fuzzy p-
value by the so-called ”signed distance method”. We
finally proposed numerical examples of one-sided and
two-sided tests, in addition to a small comparison be-
tween different null and alternative hypotheses with
the same hypothetical sample at the same significance
level. To conclude, despite the fact that the defuzzi-
fication step reduces the amount of information con-
tained in a fuzzy p-value, we thought that in many
cases defuzziying these p-values with the signed dis-
tance can be of a high relevance. In addition, since
testing hypotheses on linguistic variables is in most
cases complicated and not feasible in classical statis-
tics, proposing such an approach to deal with fuzzi-
ness and obtaining a p-value deserves merit in deci-
sion making. Indeed, we can see the defuzzied p-
value as an ”informal indicator” of rejecting or not a
given null hypothesis. For further researches, we will
be interested in testing the method with many other
statistical distributions.
REFERENCES
Berkachy, R. and Donz
´
e, L. (2016). Individual and global
assessments with signed distance defuzzification, and
characteristics of the output distributions based on an
empirical analysis. In Proceedings of the 8th Inter-
national Joint Conference on Computational Intelli-
gence - Volume 1: FCTA,, pages 75 – 82.
Berkachy, R. and Donz
´
e, L. (2017). Defuzzification of
a fuzzy hypothesis decision by the signed distance
method. In Proceedings of the 61st World Statistics
Congress, Marrakech, Morocco.
Filzmoser, P. and Viertl, R. (2004). Testing hypotheses with
fuzzy data: The fuzzy p-value. Metrika, Springer-
Verlag, 59:21–29.
Grzegorzewski, P. (2000). Testing statistical hypotheses
with vague data. Fuzzy Sets and Systems, 112(3):501
– 510.
Grzegorzewski, P. (2001). Fuzzy tests - defuzzification and
randomization. Fuzzy Sets and Systems, 118(3):437 –
446.
Lin, L. and Lee, H. (2009). Fuzzy assessment method on
sampling survey analysis. Expert Systems with Appli-
cations, 36(3):5955 – 5961.
Lin, L. and Lee, H. (2010). Fuzzy assessment for sampling
survey defuzzification by signed distance method. Ex-
pert Systems with Applications, 37(12):7852 – 7857.
Neyman, J. and Pearson, E. S. (1933). The testing of sta-
tistical hypotheses in relation to probabilities a priori.
Mathematical Proceedings of the Cambridge Philo-
sophical Society, 29(04):492–510.
Parchami, A., Taheri, S. M., and Mashinchi, M. (2010).
Fuzzy p-value in testing fuzzy hypotheses with crisp
data. Stat Pap, 51(1):209–226.
Torabi, H. and Mirhosseini, S. M. The most powerful tests
for fuzzy hypotheses testing with vague data.
Viertl, R. (2011). Statistical methods for fuzzy data. John
Wiley and Sons, Ltd.
Yao, J. and Wu, K. (2000). Ranking fuzzy numbers
based on decomposition principle and signed distance.
Fuzzy sets and Systems, 116(2):275 – 288.
Zadeh, L. (1965). Fuzzy sets. Information and Control,
8(3):338 – 353.
Zadeh, L. (1996). Fuzzy Sets, Fuzzy Logic, and Fuzzy Sys-
tems: Selected Papers of Lotfi A. Zadeh, G. J. Klir and
B. Yuan, Eds., Advances in Fuzzy Systems – Applica-
tions and Theory, volume 6. World Scientific.
Zimmermann, H. (2010). Fuzzy set theory. Wiley Interdis-
ciplinary Reviews: Computational Statistics, 2(3):317
– 332.
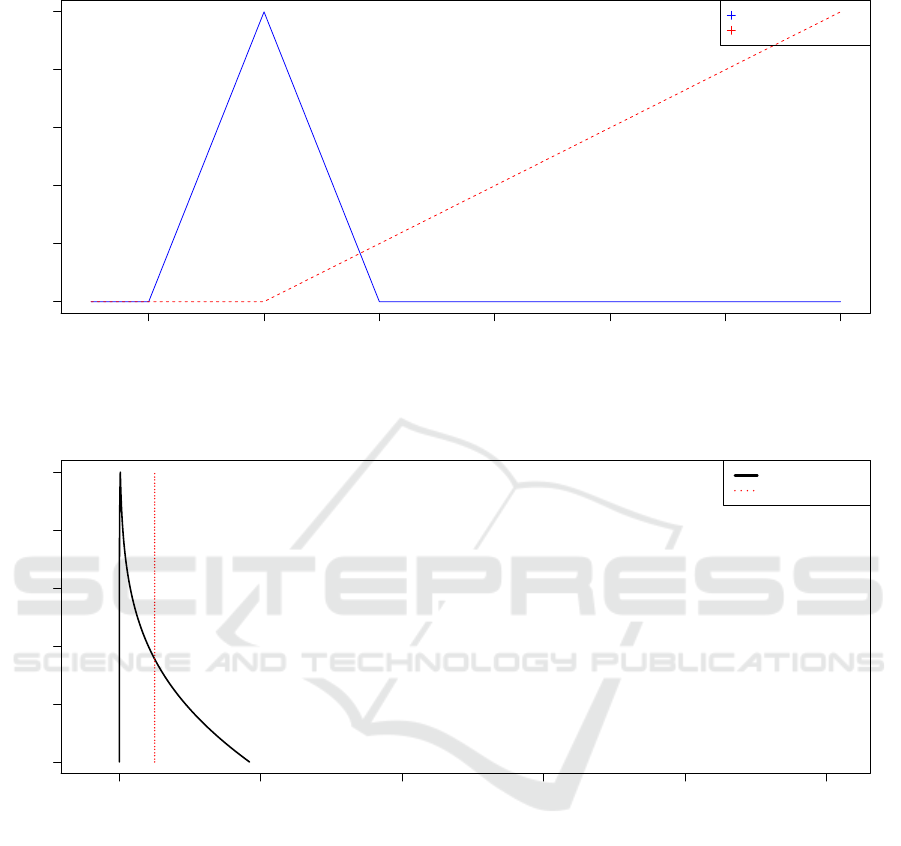
14.8 15.0 15.2 15.4 15.6 15.8 16.0
0.0 0.2 0.4 0.6 0.8 1.0
Membership functions of the null and alternative hypotheses
x
µ
Null hypothesis
Alternative hypothesis
Figure 2: The membership functions of the null and the alternative hypotheses - Example 5.1.
0.0 0.2 0.4 0.6 0.8 1.0
0.0 0.2 0.4 0.6 0.8 1.0
Membership function of the fuzzy p−value and the significance level
p
µ
Fuzzy p−value
Significance level
Figure 3: The membership function of the fuzzy p-value ˜p
α
- Example 5.1.
99.6 99.8 100.0 100.2 100.4
0.0 0.2 0.4 0.6 0.8 1.0
Membership functions of the null and alternative hypotheses
x
µ
Null hypothesis
Alternative hypothesis
Figure 4: The membership functions of the null and the alternative hypotheses - Example 5.2.
0.0 0.2 0.4 0.6 0.8 1.0
0.0 0.2 0.4 0.6 0.8 1.0
Membership function of the fuzzy p−value and the significance level
p
µ
Fuzzy p−value
Significance level
Figure 5: The membership function of the fuzzy p-value ˜p
α
- Example 5.2.
