
Multi-user Feedback for Large-scale Cross-lingual Ontology Matching
Mamoun Abu Helou
1
and Matteo Palmonari
2
1
Department of Management Information Systems, Al-Istiqlal University, Palestine
2
Department of Informatics, Systems and Communication, University of Milan-Bicocca, Italy
Keywords:
Users Feedback, Interactive Mapping, Cross-Lingual Ontology Mapping.
Abstract:
Automatic matching systems are introduced to reduce the manual workload of users that need to align two
ontologies by finding potential mappings and determining which ones should be included in a final alignment.
Mappings found by fully automatic matching systems are neither correct nor complete when compared to
gold standards. In addition, automatic matching systems may not be able to decide which one, among a
set of candidate target concepts, is the best match for a source concept based on the available evidence. To
handle the above mentioned problems, we present an interactive mapping Web tool named ICLM (Interactive
Cross-lingual Mapping), which aims to improve an alignment computed by an automatic matching system by
incorporating the feedback of multiple users. Users are asked to validate mappings computed by the automatic
matching system by selecting the best match among a set of candidates, i.e., by performing a mapping selection
task. ICLM tries to reduce users’ effort required to validate mappings. ICLM distributes the mapping selection
tasks to users based on the tasks’ difficulty, which is estimated by considering the lexical characterization of
the ontology concepts, and the confidence of automatic matching algorithms. Accordingly, ICLM estimates
the effort (number of users) needed to validate the mappings. An experiment with several users involved in
the alignment of large lexical ontologies is discussed in the paper, where different strategies for distributing
the workload among the users are evaluated. Experimental results show that ICLM significantly improves the
accuracy of the final alignment using the strategies proposed to balance and reduce the user workload.
1 INTRODUCTION
With the emergence of the Semantic Web vision, the
Web has witnessed an enormous growth in the amount
of multilingual data that exist in a large number of re-
sources. Since then, there has been an increasing in-
terest in accessing and integrating these multilingual
resources (Hovy et al., 2012). Ontologies have been
proposed for the ease of data exchange and integra-
tion across applications. When data sources using dif-
ferent ontologies have to be integrated, mappings be-
tween the concepts described in these ontologies have
to be established. This task is also called ontology
mapping. Ontology mapping methods perform two
main sub tasks: in candidate match retrieval, a first
set of potential matches is found; in mapping selec-
tion, a subset of the potential matches is included in a
final alignment.
The problem of finding mappings between con-
cepts lexicalized in different languages has been ad-
dressed in the field of Cross-lingual Ontology Map-
ping (Spohr et al., 2011). Cross-lingual ontology
mapping is currently considered an important chal-
lenge (Garcia et al., 2012), which plays a fundamental
role in establishing semantic relations between con-
cepts lexicalized in different languages, in order to
align two language-based resources (Trojahn et al.,
2014), create multilingual lexical resources with rich
lexicalizations (Navigli and Ponzetto, 2012), or sup-
port bilingual data annotation (Zhang, 2014). Auto-
matic matching systems are introduced to ease this
task by finding potential mappings and determin-
ing which ones should be included in a final align-
ment. Automatic cross-lingual mapping methods can
be used either to compute mappings automatically
(de Melo and Weikum, 2012), even at the price of ac-
curacy, or to support semi-automatic mapping work-
flows by recommending mappings to users (Pazienza
and Stellato, 2006).
In a recent work, we define a lexical similarity
measure based on evidence collected from transla-
tion resources and we run a local similarity opti-
mization algorithm to improve the assignments be-
tween source and target concepts (Abu Helou and
Palmonari, 2015). In particular, we define selection
task as the task of selecting the correct target con-
Abu Helou M. and Palmonari M.
Multi-user Feedback for Large-scale Cross-lingual Ontology Matching.
DOI: 10.5220/0006503200570066
In Proceedings of the 9th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (KEOD 2017), pages 57-66
ISBN: 978-989-758-272-1
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

cept, which one source concept should be mapped to
among a set of candidates ranked by similarity. The
selection of a correct mapping from a set of candi-
date matches still remains a difficult task, in partic-
ular when contextual knowledge is limited or can-
not be used to disambiguate the meaning of the con-
cepts. For instance, mappings involving lexicalized
concepts by only one word (synonymless), which
has several meaning (polysemous), e.g., the concept
{table}(defined in Table 1), are harder to filter out
within the mapping selection task (Abu Helou et al.,
2016). With automatic matching systems, different
candidates may be evaluated as equally good matches
for a source concept based on the available evidence,
i.e., a tie occurs among a set of top-ranked matches.
In this case, the mapping for this source concept is
undecidable, and no mapping for this concept is in-
cluded in the final alignment (otherwise, we say that
the mapping is decidable). Resolving ties by ran-
domly selecting one of the highest ranked candidate
matches comes at the price of precision. Otherwise,
no mapping for this concept can be included in the
final alignment at the price of recall.
This paper investigates, in the cross-lingual on-
tology matching domain, the adoption of semi-
automatic matching methods where multiple users are
involved in the mapping selection processes. Web
applications have been proposed to help individual
users with difficult cross-lingual matching tasks, as
the task of linking short service descriptions lexical-
ized in different languages (Narducci et al., 2017).
Beyond this, interactive matching processes that ag-
gregate feedback provided by multiple users, either
experts (Cruz et al., 2014) or crowd workers (Sara-
sua et al., 2012) seem particularly promising for large
scale cross-lingual matching tasks. For instance, if a
correct match can be found among a set of top-ranked
candidate matches, and if this set is reasonably small,
one could use interactive mapping approaches to let
users decide about the mappings. Early experiments
conducted in previous work, in which such scenarios
were investigated, showed potential improvement in
recall (Abu Helou and Palmonari, 2015).
This paper presents ICLM (Interactive Cross-
lingual Mapping) application, which is a semi-
automatic matching approach that supports feedback
provided by multiple users. In the approach proposed
in this paper, an alignment is first computed using au-
tomatic matching methods. Then, users are asked to
establish mappings for a subset of source concepts
that are estimated to require the user feedback to be
mapped. In particular, the same selection task is as-
signed to more users to collect consensus over the
decision. Users can also decide the type of relation
defined by the mapping between the source and the
target concepts (equivalent to, more specific than, or
more general than, as explained in detail in Section
5). We define a new strategy to select the mappings
that are worth being validated by the users, based on
the evaluation of the difficulty of the selection tasks.
This evaluation is based on the lexical characteriza-
tion of concepts under evaluation, i.e., on the estima-
tion of the ambiguity conveyed by the concepts in-
volved in mappings (Abu Helou et al., 2016), under
the hypothesis that most difficult selection tasks re-
quire the agreement of more users. Using the same
principle, we estimate the number of users that are
asked to perform a selection task, which determines
the overall user effort consumed to decide upon a se-
lection task. Experimental results show that the pro-
posed interactive matching method, with dynamic se-
lection of selection tasks on which the user feedback
is required and the dynamic allocation of user effort,
improves significantly the quality of the final align-
ment both in terms of precision and recall.
The rest of this paper is organized as follows. Sec-
tion 2 overviews related work. Section 3 overviews
ICLM and provides more insights on the functional-
ities provided by the approach and on the interface
provided to users. Further, Section 4 describes the
key elements of the proposed approach: strategies to
estimate the validation efforts required from users for
each source concept. In Section 5, we discuss the con-
ducted experiment: the dataset, a model for evaluating
the quality of the mappings and users effort, and the
results. Finally, in Section 6, we draw some conclu-
sions and describe future work.
2 RELATED WORK
In this section we review related work on engaging
users feedback in matching processes, and highlight
the role of concept lexicalizations in estimating the
selection tasks’ difficulties in the cross-lingual match-
ing domain.
Since the performance of automatic matching sys-
tems is limited; leveraging the contribution of the user
feedback has been recognized as a fundamental step
to validate candidate matches. Semi-automatic map-
ping workflows has been adopted in several data in-
tegration systems, including ontology matching sys-
tems; either by collecting feedback given by a single
user or multiple users, to support validation processes.
Approaches designed for a single-user scenario
are developed first. Some heuristics are used to sup-
port the user in building the MultiWordNet, a mul-
tilingual lexical ontologies (Pianta et al., 2002), by

suggesting a set of potential mappings. An entity link-
ing web application CroSeR developed to support the
cross-language linking of e-Government services to
the Linked Open Data cloud (Narducci et al., 2013;
Narducci et al., 2017). The user can select a service
in a source catalog and use the ranked list of matches
suggested by CroSeR to select the equivalent service.
The approach may be used to find more candidate tar-
get concepts; however, in this paper we focus more
on the problem of mapping selection; so this is left
for future work. Moreover, several research works
used the single-user scenario; including works pro-
posed in (Noy and Musen, 2003; Shi et al., 2009;
Cruz et al., 2012; Jimnez-Ruiz et al., 2012). How-
ever, in this paper we focus on the problem of involv-
ing multiple users in the mapping selection tasks.
On the other hand, multi-user feedback scenarios
are also used (Cruz et al., 2014; Sarasua et al., 2012;
Demartini et al., 2012). Crowdsourcing approach is
used to collect feedback from multiple users (called
workers) for individual candidate mappings. They in-
clude CrowdMap (Sarasua et al., 2012) for ontology
matching, ZenCrowd (Demartini et al., 2012) for en-
tity linking. Crowdsourcing based systems assign the
same number of users for every task; in this paper we
investigate a controlled strategy for dynamically de-
termine the number of users required for each match-
ing task. We distribute the mapping selection tasks
over some users based on the difficulty of the selec-
tion tasks. In our approach, similar to CrowdMap,
consensus is obtained on the mappings before they
are included in the final alignment. Mappings in Zen-
Crowd are considered correct if they have a poste-
rior probability that is greater than a threshold. A
pay-as-you-go approach in which the alignment is re-
fined after each iteration is used in (Cruz et al., 2014;
Cruz et al., 2016), in which they adopted a feedback
propagation strategy; at each iteration the alignment
is recomputed using the full mapping space, which
makes it unfeasible when considering large ontolo-
gies as the ones considered in this paper. In addi-
tion, since we are focusing on mappings between lex-
ical ontologies, we use insights about lexical ambi-
guity gained in previous work (Abu Helou and Pal-
monari, 2015; Abu Helou et al., 2016), in which the
Local Similarity Optimization Algorithm (LSOA) is
introduced. LSOA automatically selects the mappings
based on merging locally optimal assignments com-
puted for each source concept. In this paper we con-
sider LSOA focusing on cross-lingual mapping sce-
narios where lexically-rich resources are not struc-
tured and to leverage the concepts’ lexicalization to
estimate the selection tasks difficulties. However,
structural matching methods (Shvaiko and Euzenat,
2013; Trojahn et al., 2014; Cruz et al., 2009) can be
easily incorporated in the similarity evaluation step
without major changes to our approach.
We find that, the observations derived from study-
ing the difficulty of the mapping selection tasks
(Abu Helou et al., 2016) are particularly useful for
similar approaches, because they can help to decide
on which mappings the user inputs are more valu-
able. In particular, when we consider the undecidable
mappings. A large-scale study, which include cross-
lingual mappings from large lexical ontologies in four
different languages, is conducted on the effectiveness
of automatic translation resources on cross-lingual
matching (Abu Helou et al., 2016). Concepts (or,
synsets: sets of synonym words) are classified based
on different lexical characteristics: word ambiguity
(e.g., monosemous vs polysemous), number of syn-
onyms (e.g., synonymful vs synonymless), and posi-
tion in a concept hierarchy (e.g., leaves vs intermedi-
ate concepts). Table 1 summarizes the lexical classi-
fication of concepts. Using these classifications, the
effectiveness of automatic translations is evaluated by
studying the performance on the cross-lingual map-
ping tasks executed using automatic translations for
different categories of concepts. Evidence collected
from automatic translations is used in a baseline map-
ping selection approach, i.e., majority voting, to eval-
uate the difficulty of the mapping selection task. The
study reveals several observations; for instance, for
synonymful concepts, the larger the number of syn-
onym words covered by translations, the easier the
mapping selection task is. While mapping involving
polysemous but synonymless concepts (P&OW S) are
harder to filter out within mapping selection task; thus
we need to collect more evidence, or to involve (more)
users, to select the correct mappings.
For rich studies on involving users during the
matching processes, and on estimating the selection
task difficulties; we refer to the work of (Dragisic
et al., 2016) and (Abu Helou et al., 2016), respec-
tively.
3 ICLM OVERVIEW
ICLM
1
, Interactive Cross-Lingual Mapping, is a Web
application that supports a semi-automatic mapping
procedure aiming at speeding up and improving an
automatically generated alignment. ICLM tries to re-
duce the users’ efforts in validating cross-lingual con-
cept mappings. Figure 1 shows the home page of
ICLM. ICLM distributes the mapping selection tasks
1
http://193.204.59.21:1982/iclm/

Table 1: Concepts (synsets) categories.
Category Synset name Definition “synsets that have...”
OW S One-Word only one word (synonymless synset).
MW S Many-Words two or more synonym words (synonymful synset).
M&OW S Monosemous and OW S only one word, which is also a monosemous word (e.g., {desk}).
M&MW S Monosemous and MWS two or more synonym words, which are all monosemous words (e.g, {tourism, touristy}).
MIX MIXed monosemous and polysemous synonym words (e.g., {table, tabular array}).
P&OW S Polysemous and OWS only one word, which is also a polysemous word (e.g., {table}).
P&MW S Polysemous and MW S two or more synonym words, which are polysemous words (e.g,{board, table}).
Figure 1: ICLM home page.
on users based on the mapping tasks’ difficulties, i.e.,
in the selection process, ICLM defines the number of
users based on the difficulty of the mapping selec-
tion task. ICLM estimates the difficulties of the map-
ping selection tasks based on lexical characteristics
(explained in Section 4) of concepts under evaluation
and on how confident the automatic matching algo-
rithm is, i.e., ICLM estimates the selection task dif-
ficulty and accordingly estimates the expected users
effort (number of users to validate a mapping task).
Initially the source concepts will be automatically
matched against the target concepts using automatic
matching methods. Then, the system estimates the
mapping selection tasks difficulty; and accordingly
defines the number of users to validate each task (ex-
plained in details in Section 4). In this way, ICLM
distributes the mapping tasks over some users based
on the estimated efforts of selection tasks, unlike pure
crowdsourcing models, e.g., (Sarasua et al., 2012),
which equally assign the same number of users for ev-
ery task. The user is free to select any source concept
from the source list. Once the user identifies the po-
tentially correct candidate match, he can choose one
relationship that reflects his decision (described in de-
tails in Section 5).
Since more than one user is involved, ICLM uses a
consensus-based approach to decide whether a map-
ping belongs to the final alignment. Similar to pre-
vious work (Cruz et al., 2014), ICLM uses a consen-
sus model based on simple majority vote, where V is
an odd number of validations considered sufficient to
decide by majority (ICLM does not require that all
the users validate each mapping task); thus, minimum
consensus, µ = b(V/2) + 1c, is the minimum number
of similar vote that is needed to make a final decision
on a mapping. For example, if V = 5 is the number of
validations considered sufficient to decide by major-
ity, a final decision on a mapping can be taken when
µ = 3 similar vote are assigned to a mapping by the
users. Every mapping that obtains the minimum con-
sensus of votes will be confirmed, i.e., included in the
final alignment, and will be removed from the source
concepts list for this specific user. Once the user fin-
ishes his task, a confirmation message is sent, and the
corresponding task is removed from the source list.
However, other users may still find it, for instance, if
the minimum consensus of votes has not reached. Af-
ter each validation task, ICLM updates the source list
until the whole mappings are validated. In this way,
ICLM reduces and saves more of users efforts. Cases
where agreement (the minimum consensus of votes)
is not achieved, the match which has the highest rank
and received more votes will be included in the final
alignment. Otherwise, it will not be included in the
final alignment.
Observe that the agreement factor (i.e., the mini-
mum consensus of votes) can be tuned in a favor to
increase the mapping accuracy by increasing this fac-
tor. However, this comes at a price of increasing the
users effort. Furthermore, different agreement strate-
gies can be adopted. For example, mapping tasks will
be confirmed only if a given number of users have
agreed without controlling the number of users who
are validating the mapping tasks. This of course will
increase the users efforts. One may consider feedback
reconciliation models more sophisticated than major-
ity or weighted majority voting, for example, tourna-
ment solutions (Cruz et al., 2014). This would be an
interesting direction as a future work to explore.
Next, we provide more insight on the functionali-

Figure 2: ICLM: supports user with useful details.
ties provided by the application and on the Web GUI
2
.
Figure 2 illustrates ICLM’s functionalities. Before the
users start using the application, the source concepts
(e.g., in Arabic) are automatically matched to the En-
glish target concepts using a lexical based disam-
biguation algorithm; the Translation-based Similar-
ity Measure with Local Similarity Optimization Al-
gorithm (T SM + LSOA) (Abu Helou and Palmonari,
2015). The first step that the ICLM user should per-
form is to Register and Login, so to enable all the
validation functionalities. After that, he select the re-
spective language of concepts to be mapped to con-
cepts in the English WordNet (Fellbaum, 1998). The
user is now able to explore the source concepts by
scrolling the whole list of concepts (Source Concepts)
or by performing a keyword-based search (see Fig-
ure 2). Next, the user selects a source concepts and
ICLM retrieves a list of candidate English concepts
(Top Candidate Matches), that are potentially equiva-
lent. The number of retrieved matches is configurable
by the user through the GUI (e.g., the 40 top-ranked
matches).
Since, the connection between the source concept
and the target concept could be not straightforward
by simply comparing concepts’ lexicalization, a user
can then select a candidate match and look at fur-
ther details (Matches Info) directly gathered from the
English WordNet. Moreover, the user can click the
source and target concepts lexicalization to get further
information, as depicted in Figure 3. For instance, the
user will be able to access an online glossary for the
source language
3
, as well as navigate through the se-
mantic hierarchy of the English WordNet via the on-
2
ICLM Web GUI has been adapted from CroSeR Web
GUI (Narducci et al., 2013).
3
In the current implementation, for Arabic ICLM uses
Al-maany glossary: http://www.almaany.com/ar/dict/ar-ar/,
which returns all possible senses of a given word (i.e, the
word is not disambiguated).
line English WordNet website
4
. Finally, the user can
switch on the feedback mode of ICLM which would
store the selected relation between the source concept
and the English concept. For each mapping selection
task ICLM logs the users’ activities: the elapsed time
of each mapping selection task; and users’ navigation
activities (accessing the external resources: the glos-
sary or the online English WordNet). In this way, we
can evaluate the effectiveness and usability of ICLM,
discussed in Section 5.
4 ESTIMATING THE
DIFFICULTY OF THE
SELECTION TASKS
The basic idea behind ICLM is to reduce the users’
effort in validating a pre-defined alignment, and thus
speeding up the mapping process. In order to estimate
the mapping selection tasks’ difficulties, so as to es-
timate the required efforts (number of users required
for validation), ICLM leverages the lexical character-
istics of concepts under evaluation, where the confi-
dence of the candidate matches is based on the lex-
ical based disambiguation algorithm T SM + LSOA
(Abu Helou and Palmonari, 2015).
ICLM considers the following features of con-
cepts under evaluation to estimate the validation tasks
difficulties, Table 1 illustrates some examples:
• Ambiguity of lexicalization:
– Monosemous words: words that have only one
sense (meaning), e.g., the word “tourism” is a
monosemous.
– Polysemous words: words that have two or
more senses, e.g., the word “table” is a poly-
semous.
4
http://wordnetweb.princeton.edu/perl/webwn
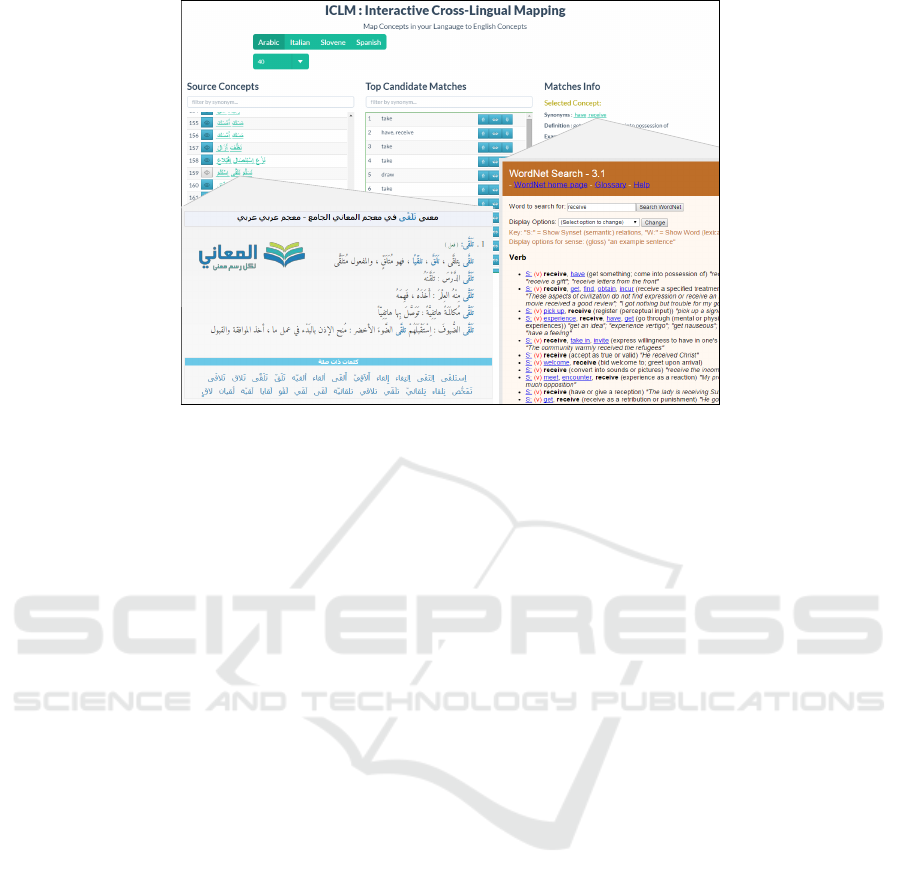
Figure 3: ICLM’s details snapshot.
Polysemous words are more difficult to disam-
biguate than the monosemous words when con-
textual knowledge is limited.
• Synonym-richness:
– Synonymless: a concept that is lexicalized with
one word, e.g., the concept {table}.
– Synonymful: a concept that is lexicalized with
many words, e.g., the concept {board, table}.
The more the coverage for synonym words (in
synonymful synsets), the easier is the mapping
selection task.
• Uncertainty in the selection Step: matches which
can be obtained by an automatic cross-lingual
mapping systems, in which the candidate matches
are ranked based on their similarity degree with
the source concepts.
– TopOne: if there exists a unique top-ranked
candidate match for the source synset.
– TopSet: if there exists a tie (a set of top-ranked
matches), i.e., a unique top-voted candidate
match does not exist for the source synset.
Three validation strategies have been defined in
ICLM: Low, Mid, and High levels of difficulty. Re-
spectively, in each level (l := {L,M,H}), different
number of users are required to validate the mapping
of each source concept, i.e., the number of mapping
selection tasks that are considered sufficient to decide
by majority (V
l
≥ 0). The validation strategies levels
are as follow:
• Low-difficulty: V
L
validation tasks are required.
• Mid-difficulty: V
M
validation tasks are required.
• High-difficulty: V
H
validation tasks are required.
Each level can have a different agreement factor,
i.e., the minimum consensus of votes. Accordingly,
different configurations can be considered as trade-
offs between mappings accuracy and users efforts.
For instances, V
l
= 0 suggests that mappings will be
directly included in the final alignment without any
feedback (validation). An increase in the value of
V
l
means increasing the users efforts and the map-
ping accuracy, under the assumption that users are
expected to identify the correct relation with out in-
troducing errors (which is not always the case (Cruz
et al., 2014)). Observe that, more validation strat-
egy levels can be introduced, based on application re-
quirements.
ICLM applies the following rules in order to select
the respective validation strategy, i.e., define the num-
ber of validation tasks that are considered sufficient to
decide by majority:
• Low-difficulty: if a monosemous synset is under
evaluation and TopOne candidate match exist, OR
if a synonymfull synset is under evaluation and
TopOne candidate match exist.
• Mid-difficulty: if a source synset does not have a
TopOne match.
• High-difficulty: if a source synset is polysemous
and synonymless (P&OWS).
5 EXPERIMENT
The goal of this experiment is to investigate the ef-
fectiveness of ICLM in suggesting good candidate
matches; not only for equivalent relation but also

Table 2: Sample dataset: distribution by category.
Concepts category
M&OWS M&MWS MIX P&OWS P&MWS Total
EnWN (%) 33596 (28.6 ) 23819 (20.2) 18676 (15.9) 30279 (25.7) 11289 (9.6) 147306 (100.0)
ArWN (%) 1995 (19.3) 1386 (13.4) 2559 (24.7) 2194 (21.2) 2215 (21.4) 13866 (100.0)
Sample (#concepts) 48 36 62 52 52 250
#Decidable mappings 24 18 31 26 26 125
#Undecidable mappings 24 18 31 26 26 125
for relationships different from the equivalent rela-
tion, i.e., specific/general concepts. This experiment
also investigates the quality of the classification ap-
proach, which is used to define the validation strate-
gies, hence, estimate the number of validation tasks
(i.e., number of users). In other words, the experiment
investigates if the estimated difficulties of the map-
ping selection tasks confirms the observations con-
cluded from the study in (Abu Helou et al., 2016).
We evaluate the performance of ICLM consider-
ing two different configurations; based on the number
of validation tasks assigned to each validation diffi-
culty level:
• BRAVE strategy (V
L
=0, V
M
=1, V
H
=3), the Low-
difficulty tasks will be included into the final
alignment without validation; and
• CAUTIOUS strategy (V
L
=1, V
M
=3, V
H
=5), every
task will be validated by some users.
We evaluate the performance of the alignments
found with every configuration against a gold stan-
dard. We use the well-know performance measures
of Precision, Recall, and F
1
-measure, to quantify
the performance of the alignments. We compare
the two configurations with an alignment automati-
cally obtained using the configuration T SM + LSOA
(Abu Helou and Palmonari, 2015), i.e, without vali-
dation (V
L
=0, V
M
=0, V
H
=0).
Next, We describe the experimental settings. the
gold standard and the users involved in the validation
tasks. Further, We describe the validation tasks (steps
that users follows). Finally, We report the main results
of the experiment. In what follows, we consider the
scenario of mapping Arabic concepts to concepts in
the English WordNet.
In this experiment six bilingual speakers, from
different background: geography, computer science,
law, medicine, management, and engineering are
asked to link a set of Arabic concepts, taken from
the Arabic wordnet (ArWN) (Rodr
´
ıguez et al., 2008),
to concepts in the English WordNet by using ICLM.
Users are undergraduate students (2), postgraduate
students (2), and doctorates (2). These users are
knowledgeable about ICLM and its goals. For each
source concept ICLM retrieves the set of candidate
Table 3: Sample dataset: distribution by task’s difficulty.
Validation strategy
Low Mid High Total
difficulty difficulty difficulty
Sample (#concepts) 99 99 52 250
Sample (%) 39.6 39.6 20.8 100.0
Table 4: Sample dataset: distribution by synonym words.
#Synonym
words
1 2 3 4 5 6 7 9 Total
Sample
(#concepts)
101 72 47 18 6 2 3 1 250
Table 5: Sample dataset: distribution by word type.
Word Type noun verb adjective adverb Total
ArWN(%) 68.8 24.3 5.9 1.0 100.0
Sample (#concepts) 166 62 19 3 250
Sample(%) 66.4 24.8 7.6 1.2 100.0
matches, which are ranked based on their similarity
with the source concept.
Dataset and Sampling Criteria. We randomly se-
lected 250 concepts from the Arabic wordnet, such
that certain condition are satisfied. The concepts are
selected to reflect a uniform distribution (w.r.t the gold
standard, see Table 2) of concepts category (described
in Table 1) as well as tasks difficulty. The following
factors are considered while selecting the sample con-
cepts: decidable vs undecidable mappings, the num-
ber of synonym words in a source concept, the type
(part of speech) of concepts lexicalization, the size of
the top-ranked matches in the undecidable mappings,
and the position of concepts in the semantic hierar-
chy (concepts’ specialization); i.e., the position that
synsets occupy in the semantic hierarchies; such that
domain-specific concepts are positioned at lower po-
sitions, e.g., synsets that occur as leaf nodes in the se-
mantic hierarchies, where as synsets at top positions
express more the general concepts. Tables 2, 3, 4, 5, 6,
and 7 report these details.
The validation tasks are processed as follows:
After registration, a user can access and start validat-
ing the matches. The following instructions (guide-
lines) are provided to the users:
• register to the system and login;
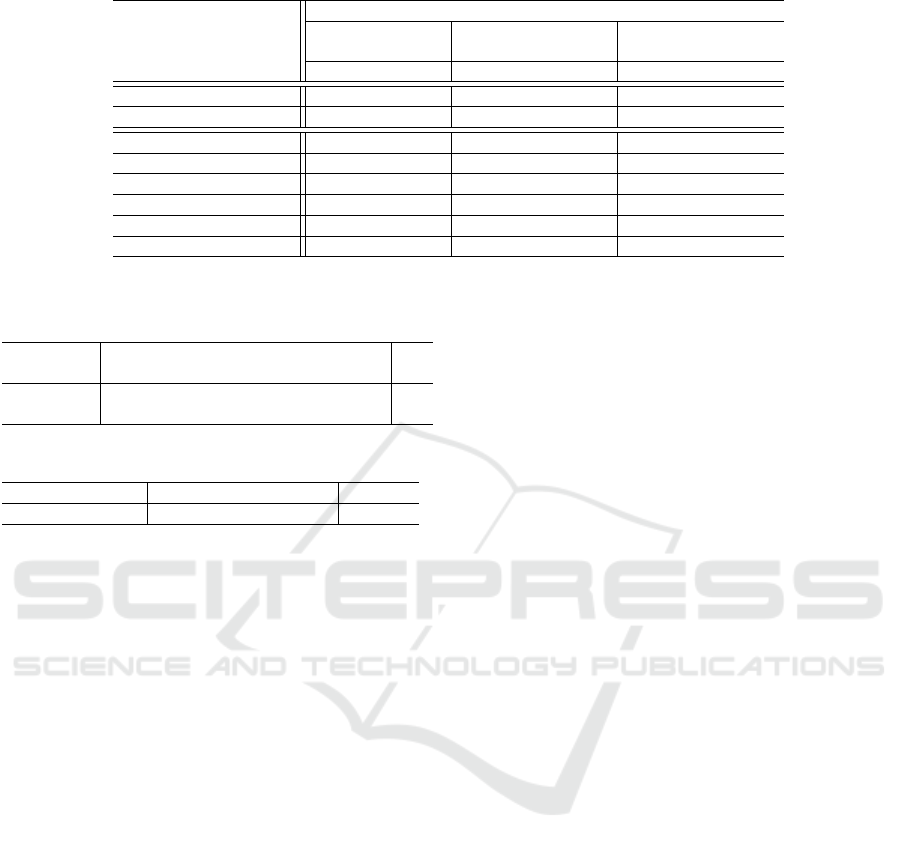
Table 8: Performance results: different validation configurations.
Configuration
TSM+LSOA BRAVE validation CAUTIOUS validation
V
L
=V
M
=V
H
=0 V
L
=0,V
M
=1,V
H
=3 V
L
=1,V
M
=3,V
H
=5
Relation R P F1 R P F1 R P F1
Equivalent 0.50 0.50 0.50 0.596 0.667 0.630 0.684 0.718 0.701
Equivalent, Specific, General - - - 0.672 0.676 0.674 0.796 0.734 0.764
# Required validation - [203-255] [453-650]
# Preformed validation - 233 556
# Avg. time/validation (sec) - 97 89
# Equivalent relation - 149 171
# Specific relation - 11 16
# General relation - 8 12
Table 6: Sample dataset: distribution by (noun) concepts
specialization.
Position in
the hierarchy
[1-3] [4-6] [7-9] [10-12] [13-15] Total
Sample
(#concepts)
2 47 88 26 2 166
Table 7: Sample dataset: distribution by TopSet cardinality.
Cardinality of TopSet [4-10] [11-20] [21-40] Total
Sample (#concepts) 93 24 8 125
• select the respective language (Arabic) of the
source concept list;
• select the Full List of candidate matches;
• select one of the source concepts from the Arabic
concept (Source Concepts);
• evaluate the list of candidate matches (Top Candi-
date Matches);
• if the lexicalization (synonyms) of a candidate
matches is not sufficient to validate the mapping,
click on the candidate match for getting more de-
tails. In the Matches Info side one can find more
useful details, which includes definitions, exam-
ples, and neighbor (parent and sibling) concepts.
These information are navigable to the online En-
glish WordNet. Similarly, an online Arabic glos-
sary (Al-maany glossary website) is also accessi-
ble and linked to each source synonym word (see
Figure 3). Use the full-text search if a correct can-
didate match does not appear in the top positions;
• once identified the potentially correct candidate
match, choose one of the following relationships:
– General (⇑): the candidate concept is more
generic with respect to the source concept;
– Equivalent (⇔): the candidate concept is equiv-
alent to the source concept;
– Specific (⇓): the candidate concept is more spe-
cific with respect to the source concept;
• select another concept from the source list until all
the concept have been evaluated.
5.1 Results and Discussion
Table 8 reports the performance measures for the
three configurations. Precision (P) measures how
many selected relation are correct w.r.t the gold stan-
dard. Recall (R) measures how many correct relations
are selected w.r.t the gold standard. F
1
-measure is the
harmonic mean of the two measures. The first row re-
ports the performance of selecting the equivalent rela-
tions, while the second row reports if also specific or
general relations are also correctly selected. The third
row reports the required number of validations: the
lower bound refers to the minimum number of valida-
tions, which happen if a consensus agreement occurs
for each source concept; whereas the upper bound
refers to the maximum number of validations when
no agreement achieved. The fourth row reports the
number of validations performed by the users. The
average elapsed time that users spent to validate a
mapping is reported in the last row. Observe that, the
performance without validation, in the first column,
is 50%, since 50% of the sample dataset (Table 2) are
decidable mappings, i.e., the candidate matches in-
clude the correct match that is ranked as TopOne.
Table 8 reports that the average elapsed time in
the CAUTIOUS validation is less than the time in the
BRAVE validation; one reason might be due to the
increase of users awareness of the system.
The last three rows in Table 8 report the number of
relations that users define through the selection tasks.
The defined relationships are split as follows. In the
BRAVE validation; 11 of type specific relation, 8 of
type general relation, and 149 of type equivalent re-
lation; in the CAUTIOUS validation: 16 of type spe-
cific relation, 12 of type general relation, and 171 of
type equivalent relation. Based on the minimum con-
sensus agreement approach users effort is reduced by

5.8% and 15.4% in the BRAVE and CAUTIOUS vali-
dations restrictively, w.r.t the maximum number of the
required validations.s
Moreover, an important observation is that, users
have not reached an agreement in the High-difficulty
validation in most cases. This is due to the fact that
the available evidence, even for the users, are not suf-
ficient to decide and select the correct relation. If
definitions or examples (sense tagged sentences) are
available for the source concepts, i.e., any further con-
textual knowledge, it would be easier for the users
to select the correct relation. For instance, in most
of the High-difficulty validations users accessed the
online glossary aiming to find more evidence, how-
ever, the glossary provides all the possible defini-
tions (senses) of the word without disambiguating its
sense. While information provided about the candi-
date matches (Matches Info) seems to be sufficient for
the users, few of them accessed the online WordNet in
order to navigate the wordnet hierarchic. In fact, this
confirms the usefulness of the classification method
defined (Abu Helou et al., 2016), and the efficiency
in estimating the difficulty of the mapping selection
tasks based on the available evidence.
6 CONCLUSIONS
The paper presented a semi-automatic cross-lingual
matching system using multi-user feedback scenario,
called Interactive Cross-Lingual Mapping (ICLM).
ICLM is a Web application that supports users with
quality mappings by leveraging translation evidence
and lexical characteristics using a lexical based dis-
ambiguation algorithm. ICLM reduces the users ef-
fort by distributing the mapping selection tasks to a
different number of users based on an estimated dif-
ficulty of these mappings, and accordingly collects
users feedback in more efficient way, in contrast to
pure crowdsourcing models where tasks are equally
assigned to a fixed number of users. A user study is
conducted to evaluate ICLM’s strategies in estimating
and distributing the validation tasks. The experimen-
tal results provide evidence that the estimated difficul-
ties to a large extent are precise, and the classification
method used to classify these task is useful.
As a future direction, we plan to use and adapt
the ICLM approach described here to support match-
ing of lexical resources in the context of the EW-
Shopp
5
(Supporting Event and Weather-based Data
Analytics and Marketing along the Shopper Journey)
and EuBusinessGraph
6
(Enabling the European Busi-
5
www.ew-shopp.eu
6
http://eubusinessgraph.eu/
ness Graph for Innovative Data Products and Ser-
vices) H2020 EU projects. In particular, ICLM can
be helpful to support alignment of resources such as
product descriptions and categories, or business clas-
sification systems, published in different languages in
Europe.
In the future, we also plan to investigate further
strategies to distribute the selection tasks over users.
For instance, we would like to investigate an active
learning model presented in (Cruz et al., 2014). An-
other interesting direction would be to consider more
languages and incorporate more users. In addition,
to learn from users behavior in order to reconfigure
the difficulty estimation is another interesting direc-
tion to explore. Moreover, an in-depth analyze w.r.t
each concept category should be also considered.
ACKNOWLEDGEMENTS
The work presented in this paper has been partially
supported by EU projects funded under the H2020 re-
search and innovation programme: EW-Shopp, Grant
n. 732590, and EuBusinessGraph, Grant n. 732003.
REFERENCES
Abu Helou, M. and Palmonari, M. (2015). Cross-lingual
lexical matching with word translation and local sim-
ilarity optimization. In Proceedings of the 10th Inter-
national Conference on Semantic Systems, SEMAN-
TiCS 2015, Vienna, Austria, September.
Abu Helou, M., Palmonari, M., and Jarrar, M. (2016). Ef-
fectiveness of automatic translations for cross-lingual
ontology mapping. J. Artif. Intell. Res. (JAIR) Spe-
cial Track on Cross-language Algorithms and Appli-
cations, 55:165–208.
Cruz, I., Loprete, F., Palmonari, M., Stroe, C., and Taheri,
A. (2014). Pay-as-you-go multi-user feedback model
for ontology matching. In Janowicz, K., Schlobach,
S., Lambrix, P., and Hyvnen, E., editors, Knowledge
Engineering and Knowledge Management, volume
8876 of Lecture Notes in Computer Science, pages
80–96. Springer International Publishing.
Cruz, I. F., Antonelli, F. P., and Stroe, C. (2009). Agree-
mentmaker: Efficient matching for large real-world
schemas and ontologies. PVLDB.
Cruz, I. F., Palmonari, M., Loprete, F., Stroe, C., and Taheri,
A. (2016). Quality-based model for effective and ro-
bust multi-user pay-as-you-go ontology matching. Se-
mantic Web, 7(4):463–479.
Cruz, I. F., Stroe, C., and Palmonari, M. (2012). Interactive
user feedback in ontology matching using signature
vectors. In Kementsietsidis, A. and Salles, M. A. V.,
editors, ICDE, pages 1321–1324. IEEE Computer So-
ciety.

de Melo, G. and Weikum, G. (2012). Constructing and uti-
lizing wordnets using statistical methods. Language
Resources and Evaluation, 46(2):287–311.
Demartini, G., Difallah, D. E., and Cudr-Mauroux, P.
(2012). Zencrowd: leveraging probabilistic reason-
ing and crowdsourcing techniques for large-scale en-
tity linking. In Mille, A., Gandon, F. L., Misselis, J.,
Rabinovich, M., and Staab, S., editors, WWW, pages
469–478. ACM.
Dragisic, Z., Ivanova, V., Lambrix, P., Faria, D., Jimenez-
Ruiz, E., and Pesquita, C. (2016). User validation
in ontology alignment. In Proceedings of the Inter-
national Semantic Web Conference, volume 9981 of
LNCS.
Fellbaum, C., editor (1998). WordNet An Electronic Lexical
Database. The MIT Press, Cambridge, MA ; London.
Garcia, J., Montiel-Ponsoda, E., Cimiano, P., G
´
omez-P
´
erez,
A., Buitelaar, P., and McCrae, J. (2012). Challenges
for the multilingual web of data. Web Semantics: Sci-
ence, Services and Agents on the World Wide Web,
11(0).
Hovy, E., Navigli, R., and Ponzetto, S. P. (2012). Collabo-
ratively built semi-structured content and artificial in-
telligence: The story so far. Artificial Intelligence.
Jimnez-Ruiz, E., Grau, B. C., Zhou, Y., and Horrocks, I.
(2012). Large-scale interactive ontology matching:
Algorithms and implementation. In Raedt, L. D.,
Bessire, C., Dubois, D., Doherty, P., Frasconi, P.,
Heintz, F., and Lucas, P. J. F., editors, ECAI, volume
242 of Frontiers in Artificial Intelligence and Applica-
tions, pages 444–449. IOS Press.
Narducci, F., Palmonari, M., and Semeraro, G. (2013).
Cross-language semantic matching for discovering
links to e-gov services in the lod cloud. In Vlker, J.,
Paulheim, H., Lehmann, J., Niepert, M., and Sack, H.,
editors, KNOW@LOD, volume 992 of CEUR Work-
shop Proceedings, pages 21–32. CEUR-WS.org.
Narducci, F., Palmonari, M., and Semeraro, G. (2017).
Cross-lingual link discovery with TR-ESA. Inf. Sci.,
394:68–87.
Navigli, R. and Ponzetto, S. P. (2012). Babelnet: The au-
tomatic construction, evaluation and application of a
wide-coverage multilingual semantic network. Artif.
Intell., 193:217–250.
Noy, N. F. and Musen, M. A. (2003). The PROMPT suite:
interactive tools for ontology merging and mapping.
International Journal of Human-Computer Studies,
59(6):983–1024.
Pazienza, M. and Stellato, A. (2006). An open and scal-
able framework for enriching ontologies with natu-
ral language content. In Ali, M. and Dapoigny, R.,
editors, Advances in Applied Artificial Intelligence,
volume 4031 of Lecture Notes in Computer Science,
pages 990–999. Springer Berlin Heidelberg.
Pianta, E., Bentivogli, L., and Girardi, C. (2002). Multi-
wordnet: developing an aligned multilingual database.
In Proceedings of the First International Conference
on Global WordNet.
Rodr
´
ıguez, H., Farwell, D., Farreres, J., Bertran, M., Mart,
M. A., Black, W., Elkateb, S., Kirk, J., Vossen, P., and
Fellbaum, C. (2008). Arabic wordnet: Current state
and future extensions. In Proceedings of the Forth
International Conference on Global WordNet.
Sarasua, C., Simperl, E., and Noy, N. F. (2012). Crowdmap:
Crowdsourcing ontology alignment with microtasks.
In Proceedings of the 11th International Semantic
Web Conference (ISWC2012).
Shi, F., Li, J., Tang, J., Xie, G. T., and Li, H. (2009). Ac-
tively learning ontology matching via user interaction.
In Bernstein, A., Karger, D. R., Heath, T., Feigen-
baum, L., Maynard, D., Motta, E., and Thirunarayan,
K., editors, International Semantic Web Conference,
volume 5823 of Lecture Notes in Computer Science,
pages 585–600. Springer.
Shvaiko, P. and Euzenat, J. (2013). Ontology matching:
State of the art and future challenges. IEEE Trans.
Knowl. Data Eng., 25(1):158–176.
Spohr, D., Hollink, L., and Cimiano, P. (2011). A machine
learning approach to multilingual and cross-lingual
ontology matching. In International Semantic Web
Conference (1), pages 665–680.
Trojahn, C., Fu, B., Zamazal, O., and Ritze, D. (2014).
State-of-the-art in Multilingual and Cross-Lingual
Ontology Matching. Springer.
Zhang, Z. (2014). Towards efficient and effective seman-
tic table interpretation. In The Semantic Web - ISWC
2014 - 13th International Semantic Web Conference,
Riva del Garda, Italy, October 19-23, 2014. Proceed-
ings, Part I, pages 487–502.
