
Daily Pain Prediction in Workplace Using Gaussian Processes
Chetanya Puri
1 a
, Stijn Keyaerts
2,3 b
, Maxwell Szymanski
4,5 c
, Lode Godderis
2,3 d
,
Katrien Verbert
4 e
, Stijn Luca
6,∗ f
and Bart Vanrumste
1,∗ g
1
eMedia Lab and STADIUS, Department of Electrical Engineering (ESAT), KU Leuven, Belgium
2
Knowledge, Information and Research Center (KIR), Group Idewe (External Service for Prevention and
Protection at Work), Leuven, Belgium
3
Department of Public Health and Primary Care, KU Leuven, Leuven, Belgium
4
Department of Computer Science, KU Leuven, Belgium
5
Human-computer Interaction research group, Department of Computer Science, KU Leuven, Belgium
6
Department of Data Analysis and Mathematical Modelling, Ghent University, Ghent, Belgium
Keywords:
Pain Management, Public Health Informatics, Time Series Forecasting, Bayesian Prediction.
Abstract:
Work-related Musculoskeletal disorders (MSDs) account for 60% of sickness-related absences and even per-
manent inability to work in the Europe. Long term impacts of MSDs include “Pain chronification” which is
the transition of temporary pain into persistent pain. Preventive pain management can lower the risk of chronic
pain. It is therefore important to appropriately assess pain in advance, which can assist a person in improving
their fear of returning to work. In this study, we analysed pain data acquired over time by a smartphone ap-
plication from a number of participants. We attempt to forecast a person’s future pain levels based on his or
her prior pain data. Due to the self-reported nature of the data, modelling daily pain is challenging due to the
large number of missing values. For pain prediction modelling of a test subject, we employ a subset selection
strategy that dynamically selects a closest subset of individuals from the training data. The similarity between
the test subject and the training subjects is determined via dynamic time warping-based dissimilarity measure
based on the time limited historical data until a given point in time. The pain trends of these selected subset
subjects is more similar to that of the individual of interest. Then, we employ a Gaussian processes regression
model for modelling the pain. We empirically test our model using a leave-one-subject-out cross validation to
attain 20% improvement over state-of-the-art results in early prediction of pain.
1 INTRODUCTION
Musculoskeletal disorders (MSD) are presently a
widespread type of work-related health problem and
a leading cause for absenteeism from work across
all sectors and occupations. Around 60% of all the
health related problems in Europe (EU) are work-
related MSDs that account for 60% of sickness related
a
https://orcid.org/0000-0002-3474-4898
b
https://orcid.org/0000-0001-6431-092X
c
https://orcid.org/0000-0002-6506-3198
d
https://orcid.org/0000-0003-4764-8835
e
https://orcid.org/0000-0001-6699-7710
f
https://orcid.org/0000-0002-6781-7870
g
https://orcid.org/0000-0002-9409-935X
∗
These Authors Contributed Equally.
absences and even permanent inability to work (Com-
munication from the Commission to the European
Parliament, the Council, the European Economic and
Social Committee and the Committee of the Regions,
2017). This creates a financial burden on individuals,
businesses, and society (Kok et al., 2020). Prevention
of MSDs from the outset of a person’s career will al-
low for an extended work life and better job satisfac-
tion (Kim, 2018). MSD prevention can also address
the long-term implications of demographic ageing, as
outlined in the objectives of the Europe 2020 strategy
for smart, sustainable, and inclusive growth. Conse-
quently, MSDs are not only an occupational burden,
but also a public health and societal challenge (Kok
et al., 2020).
Long-term impacts of MSDs include “Pain
chronification”, which is the transformation of tran-
Puri, C., Keyaerts, S., Szymanski, M., Godderis, L., Verbert, K., Luca, S. and Vanrumste, B.
Daily Pain Prediction in Workplace Using Gaussian Processes.
DOI: 10.5220/0011611200003414
In Proceedings of the 16th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2023) - Volume 5: HEALTHINF, pages 239-247
ISBN: 978-989-758-631-6; ISSN: 2184-4305
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
239

sient pain into permanent pain as a result of re-
current physical strain sustained while doing work-
related activities (Morlion et al., 2018). Other than
physical pain experience, there is vast amount of
evidence on the importance of pain coping strate-
gies, cognitive appraisals (e.g. catastrophizing, high
threat values, and fear-avoidance believes), nega-
tive emotions and expectations (Moseley and Arntz,
2007), (Nijs et al., 2011), (Edwards et al., 2016).
These factors influence how sensory information is
processed in the spinal cord and the brain. There
are several models that integrate different biopsy-
chosocial factors to the perception of pain such
as the fear-avoidance model (Vlaeyen and Lin-
ton, 2000), avoidance-endurance model (Hasenbring
et al., 2012), and the common sense model (Bunzli
et al., 2017). These models illustrate how various
persons experience pain, which results in the subjec-
tivity of pain assessments. Thus, predicting pain in
a personalised manner for early intervention is essen-
tial for preventing pain persistence. It is crucial that
both patients and medical practitioners have the ed-
ucation and abilities necessary to manage pain cor-
rectly (Morlion et al., 2018).
Currently, pain management is done based on the
initial patient evaluation (history, physical examina-
tion) which is followed by prompt treatment based
on the level of the pain (Morlion et al., 2018). This
is especially true for the acute stages of pain. In
cases of chronic pain, evidence suggests that thera-
pies should be directed less by current pain levels and
more by participation in valued activities despite dis-
comfort (McCracken and Eccleston, 2005). There-
fore, appropriately measuring pain in early stages
can aid in pain management by evaluating medica-
tion efficacy, comprehending the complicated rela-
tionship between pain and personal/contextual fac-
tors, and preparing patients and healthcare providers
for a challenging period with flare-ups. Preventative
pain management can also reduce the likelihood of it
becoming chronic. Multiple pain management appli-
cations exists but are only limited to maintaining logs
of the level/intensity of the pain (Lalloo et al., 2015).
However, for more successful pain management, it is
essential to accurately estimate the pain in advance,
preferably several days ahead, which can help a per-
son moderate his or her expectations and anxieties
about returning to work. Additionally, pain prediction
can provide healthcare practitioners with a better un-
derstanding of the required treatment and assist with
individualised planning.
This study attempts to forecast the pain experi-
enced by workers from various industries several days
ahead based on the daily recorded history of pain. To
this end, workers were asked to record their daily lev-
els of satisfaction and pain in a smartphone applica-
tion on a scale from 0 (no pain) to 100 (worst possible
pain). Then, we attempt to forecast future pain levels
by modelling individual pain levels recorded until a
certain day. This is technically difficult because the
data is self-reported, and app users did not always in-
dicate their pain levels on a daily basis, resulting in
missing data. Fig. 1 shows how an individual’s pain
data looks like with respect to time. With the study
data of over 300 days, more than 70% of the partici-
pants lack 66% of the daily data (< 100 entries).
0 50 100 150 200
0
20
40
60
80
100
Pain [0-100]
(a)
0 100 200 300
time [days]
0
20
40
60
80
100
(b)
Figure 1: Two distinct users documented their pain levels
over a 300-day period using (a) as few as 22 samples and
(b) as many as 228 samples.
The lack of observations in an individual’s time
series data restricts the application of traditional time
series modelling techniques such as the autoregres-
sive integrated moving average model (ARIMA),
which requires uniformly sampled data (Shumway
and Stoffer, 2017).
Authors in (L
¨
otsch and Ultsch, 2018) provide an
extensive survey of the application of modern ma-
chine learning techniques for the estimation or detec-
tion of pain. The majority of the pain experiences
discussed in the literature (L
¨
otsch and Ultsch, 2018)
are related to a hospital or post-operative scenario,
rather than persistent workplace-related pain. Fur-
thermore, pain forecasting models that use machine
learning are built on clinical data (e.g. drugs ad-
ministered, patient comorbidity data) collected during
pain experiences post a surgical operation, enriching
the information available for modelling (Tighe et al.,
2015), (Lee et al., 2019).
Deep learning (DL) is a branch of machine learn-
ing that, when given massive volumes of data, may
automatically learn representations from raw data
to achieve a specific objective, such as classifica-
tion or regression (Lai et al., 2018), (Laptev et al.,
2017), (De Brouwer et al., 2019), (Liu et al., 2021).
DL has been used in multiple healthcare related ap-
plications that can predict the health of an individ-
HEALTHINF 2023 - 16th International Conference on Health Informatics
240

ual from the time series data. For example, detecting
cardiac abnormality (Strodthoff and Wagner, 2020) or
forecasting glucose levels (Li et al., 2019) in individ-
uals. Works such as (Lipton et al., 2016), (Futoma
et al., 2017) developed deep learning techniques that
can address the non-uniformly sampled time-series
data when a large training dataset is available. Tra-
ditional machine learning strategies, however, outper-
form deep learning strategies when training data is in-
sufficient (Makridakis et al., 2018).
In this work, we follow the method proposed
in (Puri et al., 2019), where a subset of the train-
ing data is selected followed by learning a regression
model based on Gaussian processes (GP). Here, we
would like to showcase the efficacy of the subset se-
lection approach followed by GP based regression to
model an individual’s pain measurements until a cer-
tain day. The subset selection approach works by first
selecting individuals from training data that resemble
closely the progression of pain over time to that of
the target individual. The number of individuals to be
selected is chosen dynamically based on the similari-
ties across individuals. The dynamically chosen sub-
set along with the avaiable data from the target subject
is then used to train a regression model for improved
prediction performance. However, directly applying
the method of (Puri et al., 2019) doesn’t give the best
results owing to the subjective nature of the pain mea-
surements. Hence, we add a pre-processing treatment
of the data prior to subset selection and learning the
GP model. We explain the need to do so as follows,
1. Pain measurements of an individual vary a lot
across time. This might be because of the pain
persistence over time or by the number of individ-
ual days with more stress resulting in more pain.
Hence, unlike a general increasing trend in gesta-
tional weight gain (Puri et al., 2019), it is difficult
to find a pattern in the pain measurements over
time. Thus, there are anomalous instances in the
pain measurements that can result in an inaccurate
general model.
2. Pain measurements are self-reported and are
highly subjective in nature. This means that indi-
viduals have certain biases to only rate their pain
(scored between [0-100]) around a fixed baseline,
e.g., a person with a baseline reported pain of 20
will seldom report a pain of 80. Thus, scaling
individual pain measurements for modelling is a
necessary step.
The objective of this work is to study if:
• It is possible to estimate an individual’s pain lev-
els from a small number of non-uniformly col-
lected historical pain measurements.
• Given the subjective nature of pain data, is it pos-
sible to use previous pain measurements of other
individuals in a training dataset to enhance pain
prediction?
The main contributions of this paper are:
1. We develop models of daily pain data to forecast
and manage pain level trends over time.
2. We propose a two-step pre-processing strategy to
enhance pain prediction modelling. This is ac-
complished by smoothing the pain time series in
training data and self-normalising the target indi-
vidual’s pain data with the few measurements pro-
vided.
3. We use a subset-selection strategy to generate the
most informative subset of training data for a
given target individual. Individuals in this closest
subset exhibit similar pain trends to the individual
of interest.
4. We devise modelling based on the selected subset
using Gaussian processes for multi-step forecast-
ing of pain up to n-days ahead in time.
The dataset is described in section 2, followed by the
proposed methodology in section 3. In section 4, we
describe the experiments conducted to generate the
results. Results and their implications are discussed
in greater detail in section 5, and concluding remarks
are presented in section 6. Section 7 concludes the pa-
per by discussing potential future directions and con-
straints.
2 DATA
In this study, 340 participants were recruited from
various work sectors. At the start of the study, par-
ticipants were asked about different work-related fac-
tors, their pain complaints, pain-related perceptions,
coping strategies, and other contextual factors (in-
deed, such as physical activity and time spent sitting).
From January 2021 to May 2022, they were required
to maintain a daily journal in which they recorded
their overall pain levels, mood (not with yes/no ques-
tions), stress levels, and satisfaction along with base-
line questions such as age, gender, height, weight,
and industry of employment. The pain levels were
recorded on a scale of 0 (best) to 100 (worst) using an
mHealth smartphone application.
1
. Yes/No questions
such as mood (sad, angry, happy, fatigued, cheerful)
were also part of the daily journal.
190 participants were excluded because they did
not record daily pain values at all. In addition, 51
1
https://www.idewe.be/health-empower
Daily Pain Prediction in Workplace Using Gaussian Processes
241
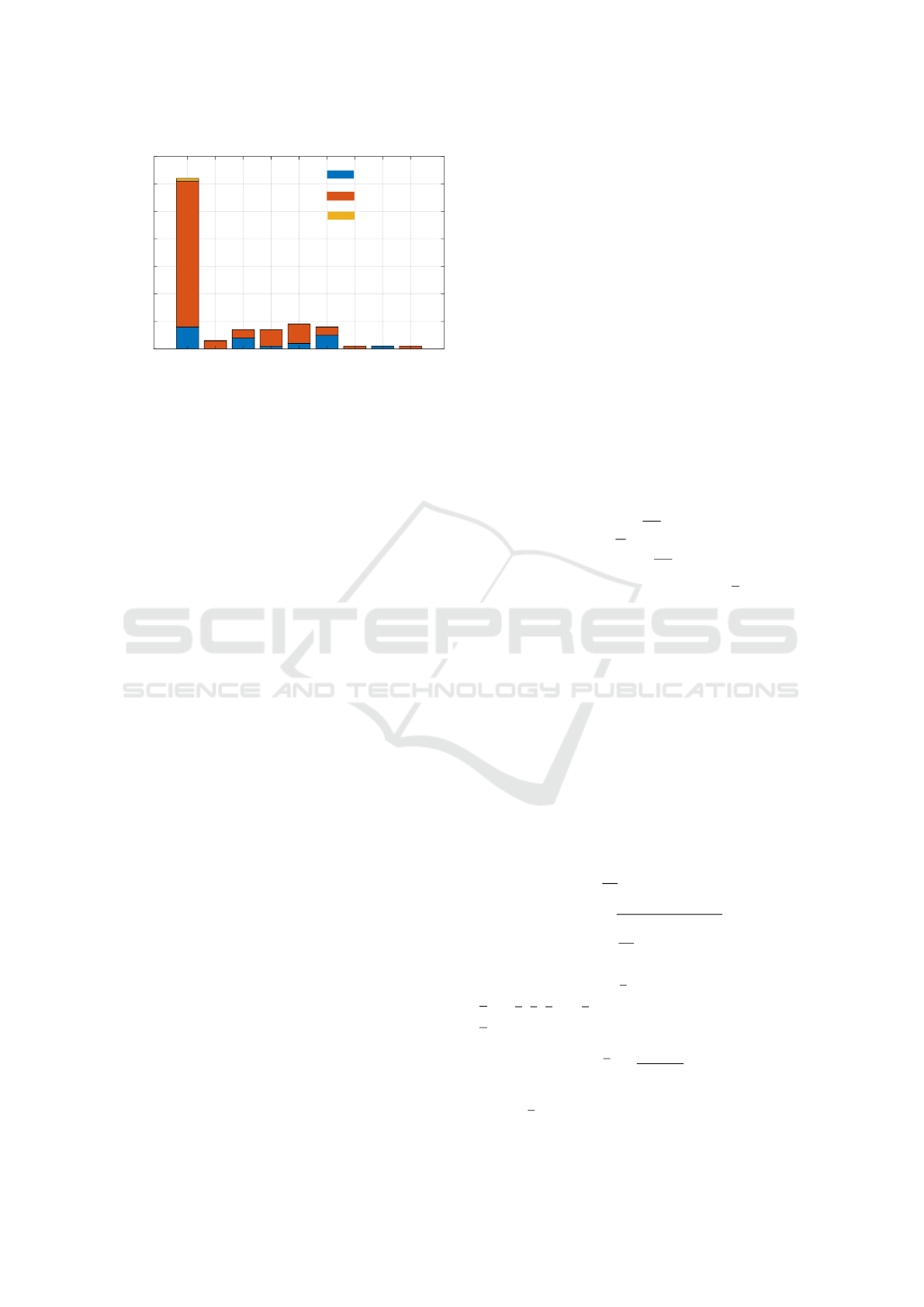
Healthcare
Food
Government
Education
Offices
Logistics
Industry
Construction
Other
Working sector
0
10
20
30
40
50
60
70
Number of subjects
Female
Other
Male
Figure 2: 21 males and 77 females participated in the study
with majority (62 out of 99) working in the healthcare in-
dustry providing care.
more individuals were removed based on the criterion
of not having more than 10 daily pain values recorded,
with more than 2 values separated by 1 week. The re-
maining 99 participants’ data were used to develop
pain prediction models. Fig. 2 presents the gender-
wise distribution of participants in different indus-
tries.
This study was conducted within the context of
the Personal Health Empowerment project, which fo-
cused on investigating and developing new monitor-
ing and treatment options for employees with MSDs.
The PHE project and corresponding studies were ap-
proved by the Social Ethics Commission of KU Leu-
ven (G-2019081713) and carried out according to the
Belgian and international privacy and ethical legis-
lation. The Belgian occupational service for protec-
tion and prevention at work (IDEWE) was responsible
for the recruitment. They distributed the information
about the project amongst their clients and employ-
ees. Interested employees had to provide informed
consent to participate.
3 METHODOLOGY
Let’s assume pain levels measured across time are
available for N subjects as ‘training data’ D =
{(x
1
, y
1
), ...(x
N
, y
N
)}, where x
i
= [t
i
1
t
i
2
t
i
3
··· t
i
m
] rep-
resents the input variable ‘time’ up to a certain day
t
i
m
and y
i
= [y
i
1
y
i
2
y
i
3
·· · y
i
m
i
] represents the output vari-
able ‘pain’ for the i
th
subject, where y
i
k
= y(t
i
k
).
In addition, data from a person of inter-
est, henceforth referred to as the target individ-
ual, are provided till a certain day t
+
d
as S =
{(t
+
1
, y
+
1
), (t
+
2
, y
+
2
), · ·· , (t
+
d
, y
+
d
)}.
We try to learn a mapping f from the training and
target data, such that,
y
+
= f (t
+
) + ε. (1)
where ε ∼ N (0, σ
2
) is independent and identically
distributed (i.i.d) gaussian.
Using the learnt model f , the target individual’s
pain measurements are then predicted at time t
+
m
i
as
y(t
+
m
i
) = f (t
+
m
i
).
3.1 Smoothing
Let’s begin by discussing the smoothing opera-
tion. Given a time series in training data y
i
=
[y
i
1
y
i
2
y
i
3
·· · y
i
m
i
], a moving average (MA) of order w
can be used to obtain a smoothed time series
ˆ
y
i
=
[ ˆy
i
1
ˆy
i
2
ˆy
i
3
·· · ˆy
i
m
i
]. This w-MA can be written as
ˆy
i
t
=
1
w
w−1
2
∑
j=−
w−1
2
y
i
t+ j
, (2)
where w is an odd integer. Moreover, ⌊
w
2
⌋ zeros are
padded to the beginning and end of the given time
series y
i
to obtain same m number of observations
in the derived w-MA time series in eq. 2. If the w-
length time window contains missing observations for
a given non-uniformly sampled time series, just the
available points are used to calculate the moving av-
erage.
3.2 Self-Normalisation
We normalise a given time-series with its avail-
able individual information. A time-series y
i
=
[y
i
1
y
i
2
y
i
3
·· · y
i
m
i
] is normalised using mean µ
y
i
and
standard deviation σ
y
i
calculated as follows:
µ
y
i
=
1
m
i
m
i
∑
j=1
y
i
j
σ
y
i
=
v
u
u
t
1
m
i
m
i
∑
j=1
(y
i
j
− µ
y
i
)
2
.
(3)
The j
th
observation (y
i
j
) of normalised time-series
y
i
= [y
i
1
y
i
2
y
i
3
·· · y
i
m
i
] is obtained from the time-series
y
i
as
y
i
j
=
y
i
j
− µ
y
i
σ
y
i
(4)
The normalised data can be rescaled to original scale
as y
i
j
= y
i
j
× σ
y
i
+ µ
y
i
.
HEALTHINF 2023 - 16th International Conference on Health Informatics
242

3.3 Regression
We use Gaussian Processes (GP) as they are the
state-of-the-art time series modelling methods when
dealing with missing data. GP is defined as a set
of random variables, such that any finite number of
them have a joint Gaussian distribution (Rasmussen,
2004). ‘ f ’ from eq. (1) is defined as a GP f (t) ∼
GP (m(t), k(t,t
′
)), with mean function m(t) and co-
variance function k(t, t
′
). We assume the data is noisy
with i.i.d gaussian noise, having noise covariance σ
2
n
,
and choose a squared exponential kernel as the gaus-
sian covariance function to model the closeness of
two observations,
k(t,t
′
) = σ
2
f
exp
−(t −t
′
)
2
2l
2
. (5)
As is evident from eqn. 5, the similarity between two
observations decreases exponentially as t begins to
differ from t
′
, i.e the similarity is highest when t = t
′
.
Thus, when two observations are far apart in time, the
kernel considers them more dissimilar than when they
are closer together in time.
Given
´
y = [y
1
1
, · ·· , y
1
m
, · ·· , y
1
N
, · ·· , y
N
N
]
T
and K as a
matrix of entries K
p,q
= k(t
p
,t
q
), ∀t
p
,t
q
∈ D. We op-
timise the hyper-parameters {σ
f
, l, σ
n
} by maximis-
ing the marginal likelihood p(
´
y|D; {σ
f
, l, σ
n
}) (Ras-
mussen, 2004). The prediction at time t
+
m
i
is given as
a gaussian distribution whose mean, µ and variance,
σ
2
are given by
µ(t
+
m
i
) = k
+
T
(K + σ
2
n
I)
−1
´
y
σ(t
+
m
) = k(t
+
m
,t
+
m
) − k
+
T
(K + σ
2
n
I)
−1
k
+
,
(6)
where k
+
= k(t
+
m
), k(t
+
m
) = [k(t
+
m
,t
1
1
), · ·· , k(t
+
m
,t
N
m
)]
T
.
Gaussian process prediction is hampered by the
fact that the computing complexity of inference and
likelihood evaluation is O(n
3
), where n is the input
size, making it impractical for bigger data sets. Next,
we will explore subset selection, which can minimise
computing complexity while enhancing prediction ac-
curacy.
3.4 Subset Selection
We follow the subset selection approach from (Puri
et al., 2019) to find a smaller but informative subset
(
ˆ
D) of the training data for a given target individual’s
data. Particularly, a subset
ˆ
D with M(<< N) individ-
uals’ data is found from the given training data D,
ˆ
D = {(x
1
, y
1
), · ·· , (x
M
, y
M
)}
=
(t
1
1
, y
1
1
), · ·· , (t
M
1
, y
M
1
), · ·· , (t
M
m
M
, y
M
m
M
)
,
(7)
such that the individuals selected in the subset are
similar to target individual’s pain trend.
Using a subset
ˆ
D with M(<< N) individuals’ data
gives a computational advantage over considering N
subjects, as the time complexity of GPs training and
inference is proportional to the cubic power of the
number of observations. Furthermore, if the most in-
formative subset is selected, the prediction capability
is improved. This is due to the fact that, during train-
ing, observations from M patients with a similar trend
in pain are close to each other and have less variabil-
ity at any given time t. Due to inter-subject variances,
this variability (at time t) is high when all N individ-
uals are considered for training Gaussian processes.
To find the closeness between two time series, we
use the Dynamic Time warping (DTW) as the dis-
tance metric. The choice of DTW metric as a dis-
tance measure is due to its capability to index time
series with unequal lengths (Keogh and Ratanama-
hatana, 2005).
The subset selection is a two-step process in which
(i) distances between the target time series and time
series in training data is calculated, and then (ii) the
nearest subset is dynamically selected based on the
calculated distances.
Distances between the target data S =
{(t
+
1
, y
+
1
), (t
+
2
, y
+
2
)..., (t
+
d
, y
+
d
)} and individual time
series in training data D are calculated using the
dynamic time warping (DTW) distance metric. Let’s
denote the DTW distance between target time series
(denoted by +) and i
th
time series in training data by
λ
i+
. Remark that that target data is only available
until t
+
d
but the time-series in training data are present
until t
i
m
(>> t
+
d
). Therefore, the data for time series
in training data are considered only until day t
+
d
to
calculate the distance λ
i+
. If the data at t
i
d
is not
available, the nearest time point < t
+
d
is chosen. The
distance vector Λ
Λ
Λ
+
= [λ
1+
λ
2+
·· · λ
N+
] is calculated
between target time series and all the time series in
training data.
Subset selection is dynamically done based on
the distance vector Λ
Λ
Λ
+
. First, Λ
Λ
Λ
+
is sorted in as-
cending order. This ensures that the subjects are ar-
ranged in order of their closeness to the target subject,
ˆ
Λ
Λ
Λ
+
= [
ˆ
λ
1+
ˆ
λ
2+
·· ·
ˆ
λ
N+
], such that
ˆ
λ
k+
≤
ˆ
λ
(k+1)+
∀k =
1, 2, ·· · , N. Second, turning points at index ‘k’ are
calculated, such that,
ˆ
λ
(k−1)+
−
ˆ
λ
(k−2)+
≤
ˆ
λ
k+
−
ˆ
λ
(k−1)+
≥
ˆ
λ
(k+1)+
−
ˆ
λ
k+
,
Multiple such turning points can exist at different in-
dexes in
ˆ
Λ
Λ
Λ
+
vector. Third, the value at the distance
value at the index k where the first turning point oc-
curs (λ
k
) is chosen as the distance threshold to calcu-
late the closest subset. i
th
time series in D is selected
in the subset if λ
i+
< λ
k
. Choosing the first turning
point enables the dynamic selection of the smallest
Daily Pain Prediction in Workplace Using Gaussian Processes
243

Subset selection
Training data
Target data
Moving averaged
Self-Normalisation
GP− >Rescaling
training data
Figure 3: An illustration of our methodology. Moving averaging is performed on the training data to smoothen it. Target data
is available until a day t
+
d
(dotted green line). Subset selection is performed on moving-averaged training data that shares
similar temporal pattern to the target observations. Each time series (target or training) is self-normalised with its available
observations before being fed to Gaussian Processes. A prediction on target data is made (red dotted line).
and most informative subset. Fig. 3 showcases the
processing pipeline where the moving average based
smoothing is done on the training data before subset
selection. Since pain levels in each individual series
are normalized using self-data, all training time series
are scaled to the same level prior to being fed into the
Gaussian process model. We will observe that this
enhances the reliability of the predictions.
4 EXPERIMENTS
We perform leave-one-subject-out (LOSO) cross-
validation to evaluate the performance of our pro-
posed approach. In each iteration, a unique individ-
ual’s data is treated as target data and rest of the sub-
jects’ data are the training data. We first smoothen
the training data and target data using a moving av-
eraging of order five (w = 5). Then, in each itera-
tion, a closest subset is evaluated dynamically with
respect to the target data followed by self-normalising
each time series (target data and selected subset) using
eq. 3 and 4. Note that our subset selection approach
dynamically selects a threshold in each iteration (i.e
for each target data). A GP based regression is per-
formed to forecast the future values for the target sub-
ject. The performance of regression was computed
using Mean Absolute Error (MAE) averaged over N
subjects. MAE for prediction at a time t
h
is given as
MAE(t
h
) =
1
N
∑
N
i=1
|y
pred
(t
i
h
) − y
orig
(t
i
h
)|.
4.1 State-of-the-Art
• Baseline: A baseline was created to judge the per-
formance of the algorithms. This baseline was
created by using the last available value of the tar-
get subject as future prediction of the daily pain
value.
• ARIMA: Auto-Regressive Integrated Moving
Average (ARIMA) has remained a state-of-the-
art time series forecasting approach with uni-
formly spaced samples of time series (Box et al.,
2015). Through linear interpolation, uniformity
was introduced into the sparsely sampled pain
time series of the subject of interest. Then, an
ARIMA(p, d, q) model was fit on the uniformly
sampled target time series. In order to find the
optimal autoregressive order (p), degree of differ-
encing (d), and moving average order (q), a grid-
search was performed to find the optimal hyperpa-
rameters following (Shibata, 1976). The learned
model is then used to make a multi-step-ahead
prediction of pain levels using the optimized hy-
perparameters.
• LSTM: Long short-Term Memory networks
(LSTM) are deep learning techniques that can
produce exceptional prediction performance by
implementing gates (forget, memory, and output)
that regulate the flow of information during train-
ing (Hochreiter and Schmidhuber, 1997). We fol-
low a similar approach as with ARIMA approach
where the avaiable data from a target subject is
uniformly sampled by linear interpolation. We
evaluate an LSTM network with 10 hidden units
and the training is done using ADAM’s optimi-
sation to minimise mean absolute error (Kingma
and Ba, 2015).
• Maximum-a-Posteriori (MAP) Estimation: A
l
th
order polynomial can be fit using available tar-
get data to estimate the polynomial coefficients
θ
i
, ∀i ∈ {1, 2, ·· · , l} (Puri et al., 2019). More-
over, subjects from training data can be used
to create priors over the polynomial coefficients
to get a better estimate known as maximum-a-
posterior (MAP) estimate (Puri et al., 2019). We
HEALTHINF 2023 - 16th International Conference on Health Informatics
244
test with polynomial of different orders (order 1 to
5) to find that the first order polynomial produces
the least mean absolute error in LOSO cross-
validation.
5 RESULTS & DISCUSSION
In this research, we investigate whether it is possible
to estimate a person’s pain levels using a small num-
ber of non-uniformly collected historical pain mea-
surements. As pain data is subjective and varies
amongst individuals, we also intended to determine
if we might improve pain prediction by incorporat-
ing the prior pain measurements of other individuals
into the training dataset. For this reason, we study the
performance of various algorithms presented in this
paper when predicting pain levels of an individual in
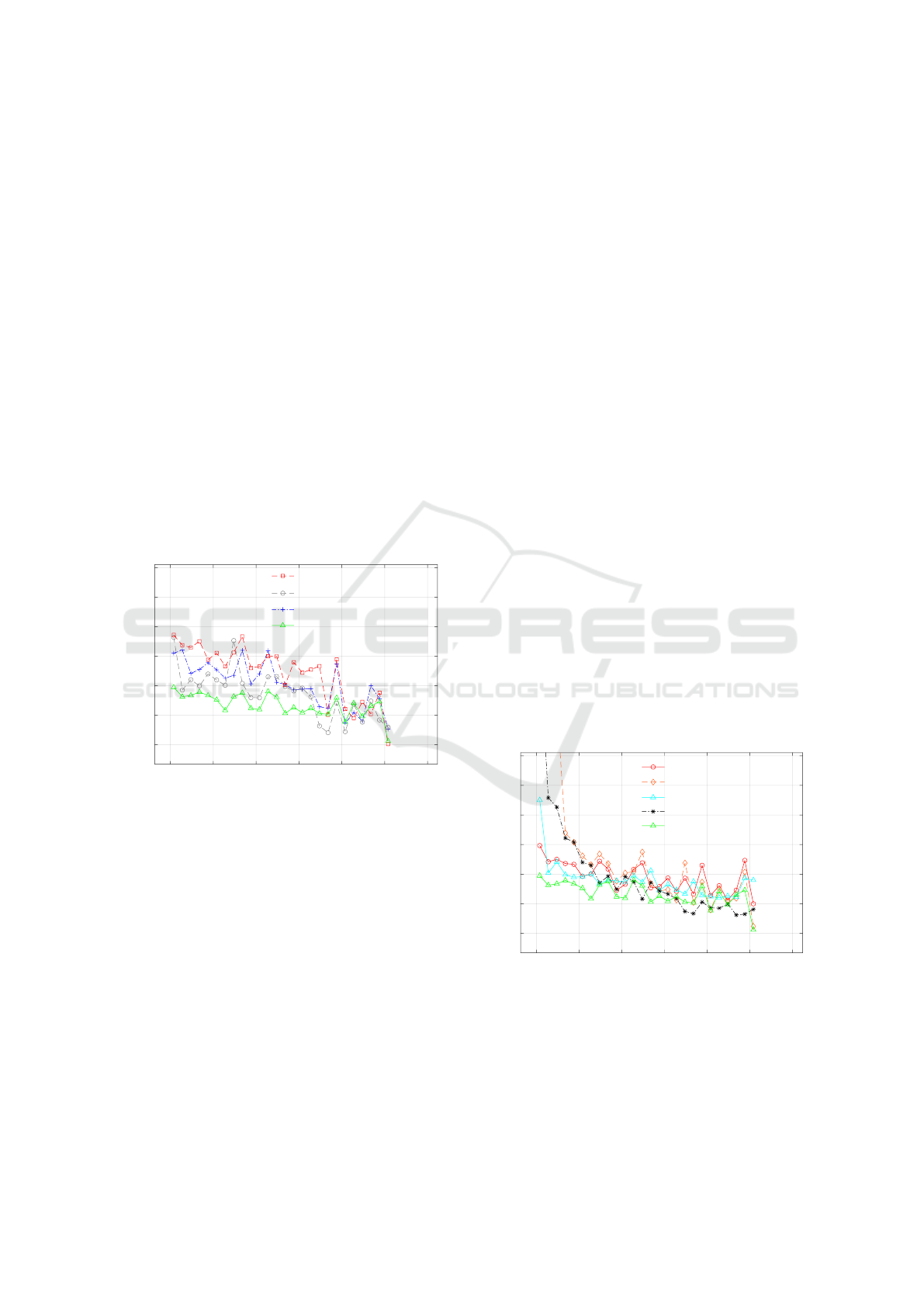
future. In Fig. 4, we present the Mean Absoute Error
(MAE) when predicting the pain 7 days ahead on the
y-axis. On the x-axis in Fig.4, the availability of tar-
get data until a certain day is presented. Subset selec-
0 50 100 150 200 250 300
training data available until [days]
0
5
10
15
20
25
30
MAE
GP+SS
GP+SS : MA
GP
GP+SS : MA +SN
Figure 4: Mean absolute error (MAE) is measured with
respect to availability of target data. Different combina-
tions of subset selection (SS) followed by Gaussian pro-
cesses (GP) were performed with proposed pre-processing
components such as moving averaging (MA) and/or self-
Normalisation (SN).
tion (SS) along with moving averaging (MA) and/or
self-Normalisation (SN) were performed and Gaus-
sian processes was used as a regression model. It is
evident from Fig. 4 that the performance of subset se-
lection (SS) followed by Gaussian processes (GP) is
demonstrably superior to that of Gaussian processes
alone. This is a result of the inclusion of an infor-
mative subset of participants in training who exhibit a
comparable trend in pain to the target data. Addition-
ally, subset selection on the moving averaged (MA)
time series of the training data, followed by self-
normalisation and subsequently the Gaussian process,
performed the best, particularly when predicting for
less available target data.
We hypothesised that pain data is subjective and
that self-reported pain measurements are biased be-
cause individuals can only compare their current pain
feelings to their past pain experiences. Therefore,
self-normalisation with respect to the historical pain
measurements of an individual provides this signifi-
cant performance improvement. In addition, as the
availability of personal pain data increases over time,
so does the accuracy of prediction. We believe that
as more training data becomes available from an in-
dividual, the selected subset will consist of subjects
whose patterns resemble that of the target subject
more closely than when there are only a few data
points. Thus, the variance in the training data avail-
able for regression is less and thus the prediction im-
proves. This is evident by the decreasing trend in
MAE when more training data becomes available. We
also tested with self-normalization prior to subset se-
lection and found no significant performance differ-
ences. This may be due to the fact that the DTW dis-
tance comparison for subset selection compares the
relative difference in distances between two time se-
ries and picks more or less similar individuals with or
without self-normalisation.
Next, we present the comparison of the proposed
approach (GP+SS:MA+SN) with state-of-the-art ap-
proaches presented in section 4.1 when predicting
pain values [0 − 100]. Fig. 5 shows that the proposed
approach’s performance is best when it comes to early
prediction using only few available data points (until
day 100).
0 50 100 150 200 250 300
training data available until [days]
0
5
10
15
20
25
30
MAE
Baseline
ARIMA
LSTM
MAP
GP+SS : MA+SN
Figure 5: Comparison of the proposed approach with state-
of-the-art approaches. When little training data is available
(until day 100), the proposed method beats SOTA, and when
more training data becomes available, it performs compara-
bly or even better.
The performance becomes comparable (if not bet-
ter) with the state-of-the-art approaches (MAP) as
Daily Pain Prediction in Workplace Using Gaussian Processes
245

more data in time becomes available for a given indi-
vidual. On the basis of a paired t-test with equal vari-
ances, the performance differences between the pro-
posed approach and other SOTA methods are statisti-
cally significant at 5% level of significance (until day
50). We discovered no statistically significant differ-
ence between the proposed method and MAP-based
polynomial estimate when training with data for more
than 100 days. Given the simplicity of the dataset,
it seems intuitive that when more pain data becomes
available, simple polynomial-based estimating algo-
rithms will perform better.
We also observed that the state-of-the-art ap-
proaches (except LSTM) perform worse than the
baseline when the availability of individual training
data is limited (at least until day 50). Remark that
the baseline is simply the previous observed value of
pain carried forward for the prediction of future val-
ues. This is due to the difficulty of modelling sparsely
sampled time series with few observations. Our pro-
posed method, on the other hand, overcomes this dif-
ficulty by incorporating the subjective nature of pain
experience and modelling information rich subset se-
lection along with personal data.
6 CONCLUSION
We proposed a novel Gaussian processes estimator
and information-rich preprocessing to model an indi-
vidual’s workplace-related pain experiences. When
time series data is irregularly sampled, the pro-
posed approach outperforms state-of-the-art time-
series forecasting algorithms for early prediction.
This can aid in the development of interventions for
managing pain in the workplace, thereby reducing the
possibility of ‘pain chronification’.
7 LIMITATIONS & FUTURE
WORK
A limitation of our approach is the scalability of
Gaussian processes as we believe that considering a
large number of subjects (N > 10
4
) will result in a
larger subset (high value of M) of training data, in-
creasing the computational complexity of our method.
Sparse GPs are model approximation techniques that,
when applied to a large number of subjects, can fur-
ther reduce complexity (Rasmussen, 2004).
In the future, we hope to broaden the modality
of the input data in order to obtain more objective
feedback on pain experiences. Finding an associa-
tion of pain with physical activity data measured by a
wearable, for example, can help as another meaning-
ful feature to improve prediction performance. Simi-
lar to the maximum-a-posteriori approach, priors on
the normalisation constants can be generated from
training data and used to adjust the self-normalisation
mean and standard deviation.
ACKNOWLEDGMENT
Chetanya Puri has received funding from the Euro-
pean Union’s Horizon 2020 research and innovation
programme under the Marie Sklodowska-Curie grant
agreement No 766139. This work is part of the re-
search project Personal Health Empowerment (PHE)
with project number HBC.2018.2012, financed by
Flanders Innovation & Entrepreneurship. This pub-
lication reflects only the authors’ view and the REA
is not responsible for any use that may be made of the
information it contains.
REFERENCES
Box, G. E., Jenkins, G. M., Reinsel, G. C., and Ljung, G. M.
(2015). Time series analysis: forecasting and control.
John Wiley & Sons.
Bunzli, S., Smith, A., Sch
¨
utze, R., Lin, I., and O’Sullivan,
P. (2017). Making sense of low back pain and pain-
related fear. journal of orthopaedic & sports physical
therapy, 47(9):628–636.
Communication from the Commission to the European Par-
liament, the Council, the European Economic and So-
cial Committee and the Committee of the Regions
(2017). Safer and Healthier Work for All — Mod-
ernisation of the EU Occupational Safety and Health
Legislation and Policy. COM.
De Brouwer, E., Simm, J., Arany, A., and Moreau, Y.
(2019). GRU-ODE-bayes: Continuous modeling of
sporadically-observed time series. In Advances in
Neural Information Processing Systems, pages 7379–
7390.
Edwards, R. R., Dworkin, R. H., Sullivan, M. D., Turk,
D. C., and Wasan, A. D. (2016). The role of psychoso-
cial processes in the development and maintenance of
chronic pain. The Journal of Pain, 17(9):T70–T92.
Futoma, J., Hariharan, S., and Heller, K. (2017). Learn-
ing to detect sepsis with a multitask gaussian process
rnn classifier. In International conference on machine
learning, pages 1174–1182. PMLR.
Hasenbring, M. I., Hallner, D., Klasen, B., Streitlein-
B
¨
ohme, I., Willburger, R., and Rusche, H. (2012).
Pain-related avoidance versus endurance in primary
care patients with subacute back pain: psychological
characteristics and outcome at a 6-month follow-up.
Pain, 153(1):211–217.
HEALTHINF 2023 - 16th International Conference on Health Informatics
246

Hochreiter, S. and Schmidhuber, J. (1997). Long short-term
memory. Neural computation, 9(8):1735–1780.
Keogh, E. and Ratanamahatana, C. A. (2005). Exact index-
ing of dynamic time warping. Knowledge and infor-
mation systems, 7(3):358–386.
Kim, D. (2018). Effect of musculoskeletal pain of care
workers on job satisfaction. Journal of Physical Ther-
apy Science, 30:164–168.
Kingma, D. P. and Ba, J. (2015). Adam: A method for
stochastic optimization. ICLR.
Kok, J., Vroonhof, P., Snijders, J., Roullis, G., Clarke,
M., Peereboom, K., Dorst, P., Isusi, I., and European
Agency for Safety and Health at Work (2020). Work-
related musculoskeletal disorders : prevalence, costs
and demographics in the EU. Publications Office.
Lai, G., Chang, W.-C., Yang, Y., and Liu, H. (2018). Mod-
eling long-and short-term temporal patterns with deep
neural networks. In The 41st International ACM SI-
GIR Conference on Research & Development in In-
formation Retrieval, pages 95–104.
Lalloo, C., Jibb, L. A., Rivera, J., Agarwal, A., and Stinson,
J. N. (2015). There’s a pain app for that. The Clinical
journal of pain, 31(6):557–563.
Laptev, N., Yosinski, J., Li, L. E., and Smyl, S. (2017).
Time-series extreme event forecasting with neural net-
works at uber. In International Conference on Ma-
chine Learning, volume 34, pages 1–5.
Lee, J., Mawla, I., Kim, J., Loggia, M. L., Ortiz, A., Jung,
C., Chan, S.-T., Gerber, J., Schmithorst, V. J., Ed-
wards, R. R., et al. (2019). Machine learning-based
prediction of clinical pain using multimodal neu-
roimaging and autonomic metrics. Pain, 160(3):550.
Li, K., Liu, C., Zhu, T., Herrero, P., and Georgiou, P. (2019).
GluNet: A deep learning framework for accurate glu-
cose forecasting. IEEE journal of biomedical and
health informatics, 24(2):414–423.
Lipton, Z. C., Kale, D., and Wetzel, R. (2016). Directly
modeling missing data in sequences with RNNs: Im-
proved classification of clinical time series. In Ma-
chine Learning for Healthcare Conference, pages
253–270.
Liu, M., Zeng, A., Xu, Z., Lai, Q., and Xu, Q. (2021).
Time series is a special sequence: Forecasting with
sample convolution and interaction. arXiv preprint
arXiv:2106.09305.
L
¨
otsch, J. and Ultsch, A. (2018). Machine learning in pain
research. Pain, 159(4):623.
Makridakis, S., Spiliotis, E., and Assimakopoulos, V.
(2018). Statistical and machine learning forecasting
methods: Concerns and ways forward. PloS one,
13(3):e0194889.
McCracken, L. M. and Eccleston, C. (2005). A prospective
study of acceptance of pain and patient functioning
with chronic pain. Pain, 118(1-2):164–169.
Morlion, B., Coluzzi, F., Aldington, D., Kocot-Kepska, M.,
Pergolizzi, J., Mangas, A. C., Ahlbeck, K., and Kalso,
E. (2018). Pain chronification: what should a non-pain
medicine specialist know? Current Medical Research
and Opinion, 34(7):1169–1178.
Moseley, G. L. and Arntz, A. (2007). The context of a
noxious stimulus affects the pain it evokes. PAIN®,
133(1-3):64–71.
Nijs, J., Van Wilgen, C. P., Van Oosterwijck, J., van Itter-
sum, M., and Meeus, M. (2011). How to explain cen-
tral sensitization to patients with ‘unexplained’chronic
musculoskeletal pain: practice guidelines. Manual
therapy, 16(5):413–418.
Puri, C., Kooijman, G., Masculo, F., Van Sambeek, S.,
Den Boer, S., Luca, S., and Vanrumste, B. (2019).
PREgDICT: Early prediction of gestational weight
gain for pregnancy care. In 2019 41st Annual In-
ternational Conference of the IEEE Engineering in
Medicine and Biology Society (EMBC), pages 4274–
4278. IEEE.
Rasmussen, C. E. (2004). Gaussian processes in machine
learning. In Advanced lectures on machine learning,
pages 63–71. Springer.
Shibata, R. (1976). Selection of the order of an au-
toregressive model by akaike’s information criterion.
Biometrika, 63(1):117–126.
Shumway, R. H. and Stoffer, D. S. (2017). Time series anal-
ysis and its applications: with R examples. Springer.
Strodthoff, N. and Wagner, P. e. (2020). Deep learning for
ECG analysis: Benchmarks and insights from PTB-
XL. IEEE Journal of Biomedical and Health Infor-
matics, 25(5):1519–1528.
Tighe, P. J., Harle, C. A., Hurley, R. W., Aytug, H.,
Boezaart, A. P., and Fillingim, R. B. (2015). Teach-
ing a machine to feel postoperative pain: combining
high-dimensional clinical data with machine learning
algorithms to forecast acute postoperative pain. Pain
Medicine, 16(7):1386–1401.
Vlaeyen, J. W. and Linton, S. J. (2000). Fear-avoidance and
its consequences in chronic musculoskeletal pain: a
state of the art. Pain, 85(3):317–332.
Daily Pain Prediction in Workplace Using Gaussian Processes
247
