
Debiasing Sentence Embedders Through Contrastive Word Pairs
Philip Kenneweg
a
, Sarah Schr
¨
oder
b
, Alexander Schulz
c
and Barbara Hammer
d
CITEC, University of Bielefeld, Inspiration 1, 33615 Bielefeld, Germany
Keywords:
NLP, Bias, Transformers, BERT, Debias.
Abstract:
Over the last years, various sentence embedders have been an integral part in the success of current machine
learning approaches to Natural Language Processing (NLP). Unfortunately, multiple sources have shown that
the bias, inherent in the datasets upon which these embedding methods are trained, is learned by them. A va-
riety of different approaches to remove biases in embeddings exists in the literature. Most of these approaches
are applicable to word embeddings and in fewer cases to sentence embeddings. It is problematic that most
debiasing approaches are directly transferred from word embeddings, therefore these approaches fail to take
into account the nonlinear nature of sentence embedders and the embeddings they produce. It has been shown
in literature that bias information is still present if sentence embeddings are debiased using such methods. In
this contribution, we explore an approach to remove linear and nonlinear bias information for NLP solutions,
without impacting downstream performance. We compare our approach to common debiasing methods on
classical bias metrics and on bias metrics which take nonlinear information into account.
1 INTRODUCTION
In the last couple of years, the transformer archi-
tecture pioneered by (Vaswani et al., 2017) has en-
abled large pre-trained neural networks to efficiently
tackle previously difficult NLP tasks with relatively
few training examples. A common tool deployed to
facilitate fast transfer of knowledge are Sentence Em-
bedders which produce a vectorized representation of
a given text input, where the original text T can be of
arbitrary length. However, longer text passages pro-
duce more diluted embeddings.
Sentence Embedders produce a summarization of
the content that is easy to process for a multitude of
different tasks by e.g. shallow neural networks.
Many common architectures need a fine-tuning
step on a specific task to achieve good performance
(Devlin et al., 2018; Liu et al., 2019). Recent litera-
ture has shown that language models are inherently
biased with regard to different protected attributes
(Bolukbasi et al., 2016; Caliskan et al., 2017). Com-
monly, investigated bias attributes are religion, gen-
der, etc. (May et al., 2019).
Though the most common source of bias is the
training data, other factors can have a mitigating or
a
https://orcid.org/0000-0002-7097-173X
b
https://orcid.org/0000-0002-7954-3133
c
https://orcid.org/0000-0002-0739-612X
d
https://orcid.org/0000-0002-0935-5591
magnifying effect.
Many approaches to reduce bias in word/sentence
embeddings exist (Cheng et al., 2021; Ravfogel et al.,
2020; Manzini et al., 2019), though most of these ap-
proaches were designed for word embeddings which
produce linearly combinable embeddings. Sentence
embeddings are based upon the vastly more complex
transformer architecture, furthermore they are often
processed by nonlinear multilayer networks. Many of
the most common debiasing methods and metrics to
evaluate bias in word/sentence embeddings are based
upon the assumption of linearity in the embedding
space. As this can no longer be guaranteed in sen-
tence embeddings, new debiasing methods and ways
to measure bias have to be considered.
In this paper we propose a new additional training
objective that can debias sentence embeddings pro-
vided with only a few contrastive words that implic-
itly define the bias direction. Contrastive objectives,
which are the basis for popular recent models such as
CLIP (Radford et al., 2021) and the thereupon based
DALL-E 2 (Ramesh et al., 2022), have proven to be
particularly promising. Our proposed debiasing ob-
jective can be applied during the standard fine-tuning
procedure required for many tasks or during the pre-
training and provides better results than other debias-
ing procedures as we demonstrate, especially in the
case of nonlinear bias.
Kenneweg, P., Schröder, S., Schulz, A. and Hammer, B.
Debiasing Sentence Embedders Through Contrastive Word Pairs.
DOI: 10.5220/0011615300003411
In Proceedings of the 12th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2023), pages 205-212
ISBN: 978-989-758-626-2; ISSN: 2184-4313
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
205

2 RELATED WORK
The most commonly used architecture for sentence
embedders is the transformer architecture, which is
pre-trained on large textual datasets. Common objec-
tives for transformer based pre-training are masked
language modeling (MLM) and next sentence predic-
tion (NSP) (Devlin et al., 2018).
A variety of previous works have shown that lan-
guage models capture biases in their training data,
which can manifest in text representations produced
by these models (Bolukbasi et al., 2016; Caliskan
et al., 2017). This issue can further lead to issues in
downstream tasks. For instance, Abid, Abubakar et al.
(Abid et al., 2021) showed that GPT-3 produces texts
inheriting muslim-violence biases (e.g. in prompt
completion). Such findings motivated many works to
develop measures for biases in language models such
as word and sentence embeddings (Bolukbasi et al.,
2016; Caliskan et al., 2017) and debiasing algorithms
(Bolukbasi et al., 2016; Liang et al., 2020).
2.1 Measuring Bias in Sentence
Embeddings
Multiple different approaches to measuring bias in
sentence embeddings exist. Some focus on the ge-
ometric relations of words in the embedding space
(Caliskan et al., 2017; May et al., 2019; Bolukbasi
et al., 2016; Manzini et al., 2019), others on the in-
fluence of bias on classification, clustering or other
downstream tasks (Gonen and Goldberg, 2019; Zhao
et al., 2018). In the course of our work, we use the
classification and clustering test by (Gonen and Gold-
berg, 2019). No universally agreed upon test to de-
termine bias exists, and many tests used for bias mea-
surement in sentence embeddings are adapted from
word embeddings. This is accomplished by inserting
words which are defining the bias space into carefully
chosen neutral sentences. Since the sentence em-
bedding space is in many cases highly nonlinear and
more complex in contrast to many classical word em-
bedding counterparts (e.g. word2vec (Mikolov et al.,
2013) uses a single layer without an activation func-
tion to produce the word embedding), it is not clear if
the most common bias measuring methods applied in
the word case can be applied to the sentence embed-
ding case. Further, even in the word embedding con-
text there exists criticism towards many bias metrics
(Gonen and Goldberg, 2019; Schr
¨
oder et al., 2023).
(Gonen and Goldberg, 2019) propose a classifica-
tion test for bias, where a classifier is trained to dis-
criminate theoretically neutral words by stereotypical
associations (in their case with gender). If the classi-
fier can generalize these associations onto unseen em-
beddings, they are considered biased. The authors use
a RBF-kernel SVM for classification. The test can be
easily expanded to sentence embedding by inserting
such words into neutral sentences and then classifying
on these sentences. In our experiments, we use a list
of occupations used in the work of (Bolukbasi et al.,
2016) as theoretically neutral words compared to gen-
der attributes. Furthermore, the choice of classifier
influences which kinds of biases are detected, linear
classifiers can only detect linear biases, whereas non-
linear classifiers can be used to detect more complex
biases. The classification test can only detect the pres-
ence of bias and the relative amount, but it can not
guarantee that no bias is present.
2.2 Removing Bias in Sentence
Embeddings
Word embeddings are well researched in comparison
to sentence embeddings with regards to their bias.
Since most word embeddings methods are inherently
linear, the approaches used for debiasing cannot be
directly applied to sentence embeddings.
Most recent work on removing bias in sentence em-
beddings is focused on removing the bias while treat-
ing the neural network as a black box and only ap-
plying their debiasing procedure post-hoc on the sen-
tence embeddings (Liang et al., 2020; Cheng et al.,
2021). Other work tries to debias sentence embed-
ders by retraining them on unbiased data (Zhao et al.,
2019). Obtaining large quantities of unbiased data
however proves difficult.
In this paper, we will directly retrain the network
using a custom loss function, assuming that the ca-
pabilities of transformers to understand complex rela-
tions also make them perform well at debiasing.
(Liang et al., 2020) propose the Sent-Debias ap-
proach. It utilizes PCA to capture the gender dimen-
sion in a large variety of sentences, by replacing gen-
der sensitive words by their counterparts and comput-
ing the difference of the produced sentence embed-
ding. Furthermore, many different naturally occur-
ring sentences from a text corpus are utilized, thus
capturing more complexity of sentence embeddings
than by using purely simple sentence templates.
Null-It-Out (Ravfogel et al., 2020) approaches the
problem differently by looking at an SVM classifier
and a corresponding bias related task. Then their so
called iterative nullspace projection algorithm is per-
formed that results in the SVM classifier no longer
producing meaningful predictions.They also highlight
that the proposed approach only works for linear clas-
sifiers and the corresponding information can be eas-
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
206

ily recovered by a nonlinear model. We will compare
to this model in our experiments.
FairFil (Cheng et al., 2021) has a similar approach
to generating contrastive sentences as our approach,
but uses only a comparatively small set of manually
selected sentences. Moreover, the neural network is
treated as a black box on which the generated sen-
tence embeddings are debiased using an extra filter.
3 PROPOSED DEBIASING
APPROACH
Approaches like Sent-Debias (Liang et al., 2020) or
Null It Out (Ravfogel et al., 2020) are only capable of
removing linear biases and dependencies in the sen-
tence embeddings. Simple three layer deep neural
networks are able to recover most bias from examples
that are debiased using these methods, see Tables 1,
2 and 3. For this reason we try to remove linear and
nonlinear information present in the embeddings re-
garding the bias, while retaining performance on a va-
riety of classification tasks. In literature (Liang et al.,
2020) the importance of using a wide variety of dif-
ferent sentences in a semi-supervised fashion is high-
lighted to generate better debiasing. We will follow
this concept in the present paper. In contrast to (Liang
et al., 2020) using linear projections as calculated by
a PCA to perform their debiasing, we will focus in
this work on potential improvements by training the
whole network with an additional cost function dur-
ing fine tuning, pre-training or both.
3.1 Definition
First we choose word pairs K
1
, K
2
, ..K
n
that con-
trastively define the bias subspace. For example:
K
1
= [men, women], K
2
= [boy, girl], K
3
= [muslim,
christian, jew].
The words chosen should only differ in their meaning
by the targeted bias.
In the next step a large text data set D is searched for
occurrences of any of these words k ∈ K
i
∃i. When-
ever a sentence S is found in which one of these words
k occurs, the original sentence S
o
and a variation S
c
,
where the word k ∈ K
i
is replaced by one of its coun-
terparts in K
i
, is added as a pair S
o
, S
c
to the debias
training examples. If multiple counterparts k ∈ K
i
are
available as is the case in our religion example one
is selected at random. Accordingly, we propose the
following loss objective upon which the network is
additionally trained:
L(S
o
, S
c
) = ∥E(S
o
) − E(S
c
)∥ (1)
And the overall debiasing loss for one training epoch
is:
L =
∑
S
o
,S
c
L(S
o
, S
c
) (2)
Thereby, E() is the embedding function produced by
the network and ∥.∥ is the euclidean norm. The intu-
ition behind this objective is to penalize the network
for producing different/biased embeddings if only the
gender information differs in the sentences. Overall
this incentivizes the network to not convey any bias
related information in its embedding.
The additional objective function we propose can be
applied during fine-tuning on a final classification
task, or during pre-training of the model.
It is always necessary to perform another training
objective (for example the fine tuning task, or a vari-
ety of different pre-training task) concurrently since a
clear solution to minimize the loss described in equa-
tion 2 is to produce the same embedding/shrink all
embeddings for every input.
Our additional objective is semi-supervised to lever-
age the capability of understanding complex relations
of transformers with large amounts of data. All in all,
we propose three schemes for debiasing by augment-
ing the training with equation 2:
• include the proposed cost function during pre-
training, further referred to as pre
p
• include the proposed cost function during fine-
tuning, further referred to as f ine
p
• include the proposed cost function during pre-
training and fine-tuning, further referred to as
pre f ine
p
We utilize the letter p to refer to our approach pair-
wise contrastive bias reduction.
4 EXPERIMENTAL APPROACH
In this section we detail our employed experimental
design to investigate the effects of our proposed ap-
proaches fine
p
, pre
p
and pre f ine
p
with respect to the
reduction of bias and the performance on downstream
tasks. We utilize the BertHugginface library (Wolf
et al., 2020) for implementation and the pre-trained
Bert model (’bert-base-uncased’) for all experiments
in order to reduce training time.
4.1 Generating Contrastive Sentences
In order to produce comparable results, we follow a
large line of work of in the literature and employ gen-
der attributes for debiasing evaluation. The word pairs
Debiasing Sentence Embedders Through Contrastive Word Pairs
207
we use to define the gender dimensions could for ex-
ample be:
women - men and girl - boy.
A larger selection of word pairs consisting of 11 pairs
is used for our experiments. For each bias attribute a
large amount of sentences (20,000 in our case) of the
News Corpus Multi-News (Fabbri et al., 2019) was
found in which the bias definition words are present.
These are then utilized as sentences S
o
and S
c
for our
proposed approaches.
4.2 Datasets
The Glue dataset by (Wang et al., 2019) is a collec-
tion of other datasets and is widely used to evaluate
common natural language processing capabilites of a
variety of networks. All datasets used are the version
provided by tensorflow-datasets 4.0.1.
4.3 Implementation Details
Occupation Task:(Gonen and Goldberg, 2019) pro-
pose a classification test to determine bias, where a
classifier C is trained to discriminate for embeddings
of occupations E(w), whether E(w) is typically male
or female. A high accuracy in this setting corresponds
to a stereotype present in the embedding.
This test can be directly expanded to the sentence
embedding context by inserting such words into neu-
tral sentences and then classifying these sentences. In
our experiments, we utilize a list of occupations used
in the work of (Bolukbasi et al., 2016) as theoretically
neutral words compared to gender attributes. Since
these occupations are rated by (Bolukbasi et al., 2016)
by how stereotypical they are male/female, the classi-
fication task from (Bolukbasi et al., 2016) is modified
to be a regression to these ratings.
This test is highly relevant for the purposes of this
paper since it can easily be modified to be only able
to distinguish linear bias information (by using only a
single layer without an activation function), as well as
nonlinear information (using an MLP). Furthermore
the reported results of this test have low standard de-
viations compared to the SEAT (Liang et al., 2020)
test, additionally the results of the SEAT test have
low statistical significance as reported in (Gonen and
Goldberg, 2019).
In our work, we implement the occupation task
by the BERT architecture sentence embedder, which
was pre-trained and/or fine-tuned using the parame-
ters supplied by the BERT paper. During the training
of the bias regressor this part of the network is kept
frozen. The produced embeddings are then fed into a
Multi Layer Perceptron. In the linear case the MLP
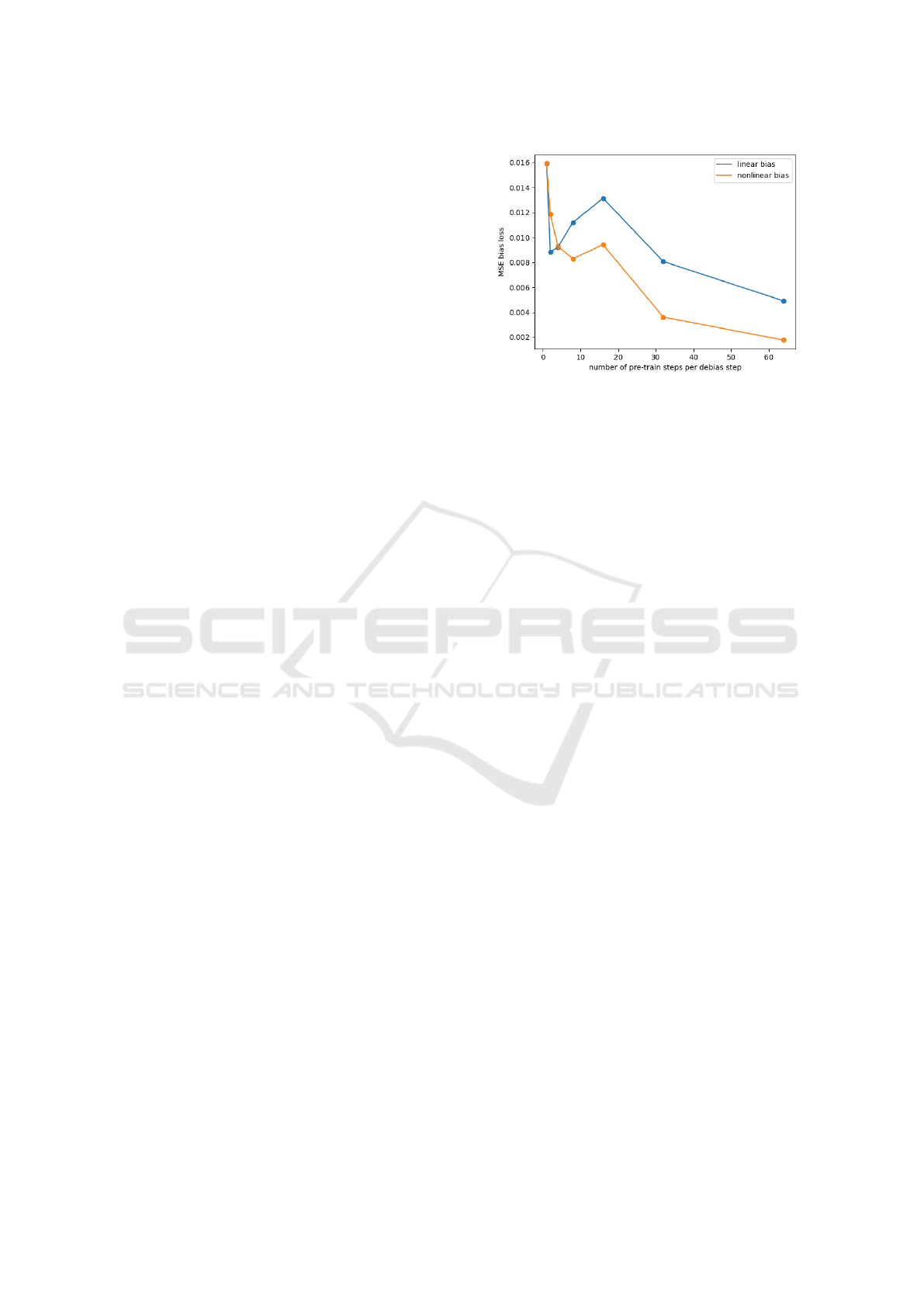
Figure 1: Number of pre-training steps per debiasing step
vs detected bias. Higher Occupation task loss denotes less
bias present in the embedding.
consists of just a single neuron with a sigmoid acti-
vation function. In the nonlinear case it consists of
3 Dense Layers with 20 neurons each and Rectified
Linear Unit (RELU) activation functions inbetween.
Again a single neuron with a sigmoid activation func-
tion acts as the output.
Each model is trained for 50 epochs on the train-
ing data or until the validation accuracy does not im-
prove for 5 epochs. The optimizer used is SGD with
a learning rate of 0.01. The utilized loss function to
compute the regression loss is the Mean Squared Er-
ror (MSE).
Finally, the resulting loss on the test set after train-
ing is the score used in Figure 1, 2 and Table 1, 2, 3.
4.3.1 Pre Training
During additional pre-training of pre
p
and pre f ine
p
we use the pre-trained Bert Model and train it on a
news corpus using the MLM task concurrently with
our debiasing method for gender for 400,000 training
steps. Using an already pre-trained model is done to
speed up convergence.
If the debias loss is balanced with the MLM loss
correctly, only the bias relevant information should
be removed from the model, while retaining high
performance on the MLM task and possible down-
stream tasks. In order to estimate a good balance
between these two objectives, we evaluate different
ratios of MLM steps per debias step on the Occupa-
tion task (see Figure 1). The debiasing performance
clearly drops when the number of pre-training steps
per debias step increases. However, the MLM pre-
training loss is not affected(not depicted). Accord-
ingly, we use the ratio of 1:1 for the training of pre
p
and pre f ine
p
.
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
208

4.3.2 Fine-Tuning
During fine-tuning of pre f ine
p
and f ine
p
we employ
the pre-trained Bert Model provided by Huggingface
(Wolf et al., 2020) or pre
p
.
Figure 2: Number of fine-tune steps per debiasing step vs
detected bias. Higher bias classifier loss denotes less bias
present in the embedding. The red line denotes the accuracy
on the downstream task. The blue line shows the bias loss
of the linear model and the yellow line denotes the bias loss
of the nonlinear model. The bias scores and accuracies are
averaged over 5 runs.
In order to estimate the same balance between our
debiasing objective and the fine-tuning objective, we
perform a search on the relative number of steps on
the glue task vs steps on the debiasing task. Since
we are in a fine-tuning scenario, we can now incorpo-
rate the accuracy on a downstream task for our search.
The result is shown in Figure 2. A clear downward
trend can be observed for the nonlinear bias score
(lower score equals more bias present in the embed-
ding) and less clearly for the linear one, in case of
more fine-tuning steps per debiasing step. While the
accuracy does seem to be negatively affected in this
case, this effect is rather minor (in the range of 1-
2%). Following this, the same amount of steps with
our custom training objective are performed as on the
classification task during fine-tuning (1:1).
For each fine-tuning task, the pre-trained BERT
architecture is used and a single new fully connected
layer after the sentence embeddings is added, then the
whole network is trained on the fine-tuning task. All
fine-tuning runs are trained for 5 epochs with 7,200
training examples per epoch. Longer training times
and hyperparameter tuning could have resulted in bet-
ter performance, but since the topic of this paper is de-
biasing these models, only the relative performance of
the different training setups matter. The used hyper-
parameters are the same as recommended in the orig-
inal BERT paper (Devlin et al., 2018). All fine-tuning
experiments are performed 5 times and their aver-
ages are reported. This is done to reduce variation
in results, since BERT fine-tuning is very sensitive to
small changes. The same run can vary in performance
up to 5% just due to non-deterministic training on the
graphics card.
4.4 Experimental Setup
In the following, we evaluate the performance of our
debiasing approach and investigate possible perfor-
mance drops on downstream tasks
For the glue tasks, we consider a pre-trained Bert
model which we fine-tune on one downstream task
together with different debiasing approaches: pre-
trained and fine-tuned Bert without debiasing (re-
ferred to as original Bert), pre-trained and fine-tuned
Bert with subsequent debiasing by the Sent-Debias
approach (referred to as Sent-Debias), pre-trained and
fine-tuned Bert with subsequent debiasing by Null-
it-Out (referred to as Null-it-Out), pre-trained Bert
together with our proposed f ine
p
debiasing (which
involves fine-tuning; referred to as f ine
p
) and pre-
trained Bert together with our proposed pre f ine
p
de-
biasing (which involves fine-tuning; referred to as
pre f ine
p
). Each of these combinations is, after per-
forming the debiasing (see the descriptions in sec.
4.3), evaluated on a test set of the according down-
stream task giving the accuracy values shown in the
tables. Subsequently, we employ the occupation task
in order to estimate the amount of bias present in the
models. This is done by adding (a) new layer(s),
which parameters are trained to estimate the gender
of a job embedded in a sentence (see secs. 4.1 and 4.3
for more details). According to the number of these
new layers we refer to linear bias (one layer) or non-
linear bias (multiple layers, with activation functions
in between) and high values imply low bias. The re-
sults of these experiments are depicted in section 5.1.
In a second series of experiments we investigate
debiasing capabilities on pre-trained models that are
not fine-tuned. These are displayed in section 5.2.
5 RESULTS
This section displays the results of the four experi-
mental series described previously.
5.1 GLUE
For evaluation, 3 Glue (Wang et al., 2019) tasks
(CoLA, SST2, QNLI) are considered. The results are
described in the following three subsections.
Debiasing Sentence Embedders Through Contrastive Word Pairs
209

Table 1: Classification accuracies, linear and nonlinear bias (loss on the occupation task) on the Corpus of Linguistic Accept-
ability task after fine tuning. All fine tuning runs were performed five times and scores averaged. Higher bias scores indicate
lower bias present in the embeddings. Baseline bias score (average prediction) equals to 0.0197.
method accuracy ↑ linear bias ↑ nonlinear bias ↑
original Bert 0.783 ± 0.0072 0.00677 ± 0.00106 0.00315 ± 0.00093
Sent-Debias 0.781 ± 0.0095 0.00705 ± 0.00085 0.00258 ± 0.00085
Null-It-Out 0.765 ± 0.0154 0.01635 ± 0.00116 0.00593 ± 0.00524
f ine
p
0.765 ± 0.0084 0.00806 ± 0.00375 0.00393 ± 0.00386
pre f ine
p
0.771 ± 0.0147 0.01100 ± 0.00452 0.01310 ± 0.00617
Table 2: Classification accuracies, linear and nonlinear bias on the Stanford Sentiment Treebank task after fine tuning. All
fine tuning runs were performed five times and their scores averaged. Baseline bias score (average prediction) equals 0.0197.
method accuracy ↑ linear bias ↑ nonlinear bias ↑
original Bert 0.870 ± 0.0092 0.00473 ± 0.00075 0.00259 ± 0.00044
Sent-Debias 0.851 ± 0.0084 0.00482 ± 0.00072 0.00254 ± 0.00047
Null-It-Out 0.864 ± 0.0247 0.01539 ± 0.00105 0.00110 ± 0.00055
f ine
p
0.858 ± 0.0122 0.00553 ± 0.00269 0.00288 ± 0.00187
pre f ine
p
0.851 ± 0.0434 0.00989 ± 0.00101 0.00856 ± 0.00236
5.1.1 Corpus of Linguistic Acceptability
The results for the CoLA data set are summarized in
Table 1. The accuracy for the CoLA task does not
change strongly when fine-tuning or pre-training with
our additional debiasing objective. The best perform-
ing model is the original BERT. While Sent-Debias
is able to increase performance on the linear occu-
pation task (i.e. reduce bias), it actually performes
worse than the original BERT on the nonlinear oc-
cupation task. Null-It-Out does significantly decrease
the linear bias detected and even decreases the nonlin-
ear bias found. Both proposed debiasing approaches
are able to decrease the evaluated bias significantly,
compared to the original BERT model. Especially
the pre f ine method achieves significantly higher de-
bias scores in the nonlinear domain, whereas the f ine
method only decreases the measured bias slightly.
5.1.2 Stanford Sentiment Treebank
The results for the SST2 data set are display in Table
2. The best accuracy on this task is achieved by the
original BERT. pre f ine
p
performes 1.9% worse on
accuracy while achieving almost 100% better perfor-
mance on the linear debias score and more than 100%
improvement on the nonlinear debias score. Interest-
ingly, pre f ine
p
performs better on the occupation task
than f ine
p
, while Sent-Debias along with the original
BERT perform worse than pre f ine
p
. Null-It-Out per-
forms the best on the linear bias score, but decreases
performance on the nonlinear bias score.
5.1.3 Stanford Question Answering Dataset
The results for the QNLI data set are given in Table
3. Here, the best accuracy is achieved by the original
BERT. The best debiasing performance is achieved by
pre f ine
p
in linear and nonlinear bias. f ine
p
and Sent-
Debias performed very similar to the original BERT.
While Null-It-Out performs well on the linear bias
score, it fails to debias the occupations nonlinearly.
5.2 Pre-Trained Models
A variety of machine learning models try to use sen-
tence embeddings without any fine-tuning. Hence,
we investigate the performance of various debiasing
methods without any fine-tuning to a specific task.
In Table 4, pre
p
performs the best with regards to
the bias score. As no task is associated with pure sen-
tence embeddings no accuracy can be given to com-
pare the performance of the embeddings. For perfor-
mance comparison see Tables 1, 2 and 3, here pre
p
is
further trained with the additional debias loss to pro-
duce pre f ine
p
. It can be seen, that the performance
of pre f ine
p
is lower than the original BERT perfor-
mance on the Glue tasks by 1.3% on average.
5.2.1 Summary
Overall, the additional debiasing objectives (our pro-
posed ones and sent-debias) do not significantly im-
pact the glue tasks performance compared to the orig-
nal BERT model. Models where our debiasing objec-
tive was applied during fine-tuning or fine-tuning and
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
210

Table 3: Classification accuracies, linear and nonlinear bias on the Stanford Question Answering Dataset task after fine tuning.
Baseline bias score (average prediction) equals 0.0197.
method accuracy ↑ linear bias ↑ nonlinear bias ↑
original Bert 0.817 ± 0.0060 0.0103 ± 0.0023 0.0070 ± 0.0041
Sent-Debias 0.803 ± 0.0056 0.0108 ± 0.0025 0.0049 ± 0.0024
Null-It-Out 0.814 ± 0.0073 0.0166 ± 0.0015 0.0029 ± 0.0047
f ine
p
0.807 ± 0.0153 0.0089 ± 0.0032 0.0053 ± 0.0032
pre f ine
p
0.807 ± 0.0100 0.0202 ± 0.0020 0.0191 ± 0.0009
Table 4: Linear and nonlinear bias of the pretrained em-
bedding models without any finetuning to a specific task.
Higher bias scores indicate lower bias present in the em-
beddings. Baseline indicates the average prediction.
method linear bias ↑ nonlinear bias ↑
original Bert 0.0047 0.0018
Sent-Debias 0.0046 0.0020
Null-It-Out 0.0157 0.0021
pre
p
0.0159 0.0159
baseline 0.0197 0.0197
pre-training report only minor accuracy losses.
In summary, the best performing version of our
debiasing algorithms is pre f ine
p
. It beats the orig-
inal BERT and Sent-Debias in all cases regarding
bias score on the occupation task, while the accuracy
on the glue tasks is mostly retained. While Null-It-
Out performs well on the linear debiasing measure,
it completely fails to reduce the nonlinear measure.
f ine
p
often improves the bias score (by a smaller mar-
gin than pre f ine
p
) and is a valid option due to being
simpler and computationally cheaper than pre f ine
p
.
To further gain an intuition into the proposed debi-
asing method and its effects on the embedding space,
we visualize the average sentence embeddings of the
occupations from the bias classification task using
DeepView (Schulz et al., 2020). In the linear case
it can be seen that the lighter areas, denoting more
uncertainty on the part of the classifier, have grown
compared to the original example and that the dis-
tinction between the two classes is not as large for
the debiased case. Interestingly the performance on
the classification task of the nonlinear classifier has
decreased significantly after debiasing from 99.84 %
to 83.75 % accuracy (The average classifier which al-
ways produces as an output the male class achieves
an accuracy of 83.33), even though the visualization
does not seem to have changed extensively.
6 CONCLUSIONS
In this paper we presented an easy to implement ad-
ditional training objective that can be applied dur-
Figure 3: DeepView visualization of the original BERT
embedding vs pre
p
embeddings. Dark areas denote re-
gions of space where the predictor has a high confidence
value, whereas lighter areas indicate greater uncertainty.
Light blue points indicate female occupations and dark blue
points indicate male occupations.
ing pre-training and/or fine-tuning of the network. It
decreases the bias measured by the occupation task
clearly, while not impacting the accuracy on down-
stream task. Furthermore we show that, using this
method, we can strongly reduce nonlinear gender in-
formation in contrast to most other debiasing algo-
rithms, which can otherwise easily be recovered by a
multilayer perceptron.
Overall, further research on this topic is required,
as there is still no consensus regarding suitable met-
rics for detecting and comparing biases in sentence
embeddings. Even though our debiasing approach
seems promising in erasing bias related information
in sentence embeddings, it is not able to reliably erase
all information present. Thus debiasing algorithms
which are able to completely, precisely and reliably
erase linear and nonlinear information targeting a cer-
tain bias concept are still needed.
Debiasing Sentence Embedders Through Contrastive Word Pairs
211

All code for this paper can be found on
https://github.com/TheMody/Debiasing- Sentence-
Embedders-through-contrastive-word-pairs.
ACKNOWLEDGEMENTS
We gratefully acknowledge funding by the BMWi
(01MK20007E) in the project AI-marketplace.
REFERENCES
Abid, A., Farooqi, M., and Zou, J. (2021). Persistent anti-
muslim bias in large language models. In Proceed-
ings of the 2021 AAAI/ACM Conference on AI, Ethics,
and Society, AIES ’21, page 298–306, New York, NY,
USA. Association for Computing Machinery.
Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., and
Kalai, A. T. (2016). Man is to computer programmer
as woman is to homemaker? debiasing word embed-
dings. In Lee, D., Sugiyama, M., Luxburg, U., Guyon,
I., and Garnett, R., editors, Advances in Neural Infor-
mation Processing Systems, volume 29, pages 4349–
4357. Curran Associates, Inc.
Caliskan, A., Bryson, J. J., and Narayanan, A. (2017). Se-
mantics derived automatically from language corpora
contain human-like biases. Science, 356(6334):183–
186.
Cheng, P., Hao, W., Yuan, S., Si, S., and Carin, L. (2021).
Fairfil: Contrastive neural debiasing method for pre-
trained text encoders. CoRR, abs/2103.06413.
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2018).
BERT: pre-training of deep bidirectional transformers
for language understanding. Proceedings of the 2019
Conference of the North American Chapter of the As-
sociation for Computational Linguistics: Human Lan-
guage Technologies, abs/1810.04805.
Fabbri, A. R., Li, I., She, T., Li, S., and Radev, D. R. (2019).
Multi-news: a large-scale multi-document summa-
rization dataset and abstractive hierarchical model.
Gonen, H. and Goldberg, Y. (2019). Lipstick on a pig: De-
biasing methods cover up systematic gender biases in
word embeddings but do not remove them. In Pro-
ceedings of the 2019 Conference of the North Amer-
ican Chapter of the Association for Computational
Linguistics: Human Language Technologies.
Liang, P. P., Li, I. M., Zheng, E., Lim, Y. C., Salakhutdinov,
R., and Morency, L.-P. (2020). Towards debiasing sen-
tence representations.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D.,
Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov,
V. (2019). Roberta: A robustly optimized BERT pre-
training approach. CoRR, abs/1907.11692.
Manzini, T., Yao Chong, L., Black, A. W., and Tsvetkov,
Y. (2019). Black is to criminal as caucasian is to po-
lice: Detecting and removing multiclass bias in word
embeddings. In Proceedings of the 2019 Conference
of the North American Chapter of the Association for
Computational Linguistics: Human Language Tech-
nologies, Volume 1.
May, C., Wang, A., Bordia, S., Bowman, S. R., and
Rudinger, R. (2019). On measuring social biases in
sentence encoders.
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013).
Efficient estimation of word representations in vector
space.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G.,
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark,
J., et al. (2021). Learning transferable visual models
from natural language supervision. In International
Conference on Machine Learning, pages 8748–8763.
PMLR.
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen,
M. (2022). Hierarchical text-conditional image gener-
ation with clip latents. OpenAI papers.
Ravfogel, S., Elazar, Y., Gonen, H., Twiton, M., and Gold-
berg, Y. (2020). Null it out: Guarding protected at-
tributes by iterative nullspace projection. In Proceed-
ings of the 58th Annual Meeting of the Association for
Computational Linguistics.
Schr
¨
oder, S., Schulz, A., Kenneweg, P., and Hammer, B.
(2023). So can we use intrinsic bias measures or not?
In International Conference on Pattern Recognition
Applications and Methods.
Schulz, A., Hinder, F., and Hammer, B. (2020). Deep-
view: Visualizing classification boundaries of deep
neural networks as scatter plots using discriminative
dimensionality reduction. Proceedings of the Twenty-
Ninth International Joint Conference on Artificial In-
telligence.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L. u., and Polosukhin,
I. (2017). Attention is all you need. In Guyon,
I., Luxburg, U. V., Bengio, S., Wallach, H., Fer-
gus, R., Vishwanathan, S., and Garnett, R., editors,
Advances in Neural Information Processing Systems,
volume 30. Curran Associates, Inc.
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and
Bowman, S. R. (2019). GLUE: A multi-task bench-
mark and analysis platform for natural language un-
derstanding. In the Proceedings of ICLR.
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C.,
Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz,
M., Davison, J., Shleifer, S., von Platen, P., Ma, C.,
Jernite, Y., Plu, J., Xu, C., Scao, T. L., Gugger, S.,
Drame, M., Lhoest, Q., and Rush, A. M. (2020). Hug-
gingface’s transformers: State-of-the-art natural lan-
guage processing.
Zhao, J., Wang, T., Yatskar, M., Cotterell, R., Ordonez, V.,
and Chang, K.-W. (2019). Gender bias in contextual-
ized word embeddings.
Zhao, J., Wang, T., Yatskar, M., Ordonez, V., and Chang,
K.-W. (2018). Gender bias in coreference resolution:
Evaluation and debiasing methods. In Proceedings of
the 2018 Conference of the North American Chapter
of the Association for Computational Linguistics: Hu-
man Language Technologies, Volume 2.
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
212
