
Improved ACO Rank-Based Algorithm for Use in Selecting Features for
Classification Models
Roberto Alexandre Delamora
1,2 a
, Bruno Naz
´
ario Coelho
3 b
and Jodelson Aguilar Sabino
4 c
1
Graduate Program in Instrumentation, Control and Automation of Mining Process,
Federal University of Ouro Preto, Instituto Tecnol
´
ogico Vale, Ouro Preto, Brazil
2
Vale S.A., Nova Lima, Brazil
3
Graduate Program in Instrumentation, Control and Automation of Mining Process,
Federal University of Ouro Preto, Instituto Tecnol
´
ogico Vale, Ouro Preto, Brazil
4
Artificial Intelligence Center, Vale S.A., Vit
´
oria, Espirito Santo, Brazil
Keywords:
Wrapper-Filter Method, Ant Colony Optimization, Metaheuristic, Machine-Learning, Feature Selection,
Dimensionality Reduction.
Abstract:
Attribute selection is a process by which the best subset of attributes in a given dataset is searched. In a world
where decisions are increasingly based on data, it is essential to develop tools that allow this selection of
attributes to be more efficiently performed, aiming to improve the final performance of the models. Ant colony
optimization (ACO) is a well-known metaheuristic algorithm with several applications and recent versions
developed for feature selection (FS). In this work, we propose an improvement in the general construction
of ACO, with improvements and adjustments for subset evaluation in the original Rank-based version by
BulInheimer et al. to increase overall efficiency. The proposed approach was evaluated on several real-life
datasets taken from the UCI machine-learning repository, using various classifier models. The experimental
results were compared with the recently published WFACOFS method by Ghosh et al., which shows that our
method outperforms WFACOFS in most cases.
1 INTRODUCTION
The opportunity that data innovation offers the world
is virtually unprecedented. Innovative machine-
learning tools are already revolutionizing our lives in
incredible ways. Now, these tools are helping peo-
ple to uncover the hidden answers with the growing
abundance of data resources. These transformative
new technologies are converting data into new prod-
ucts, solutions, and innovations that promise to sig-
nificantly change people’s lives and relationships with
the world.
From an economic point of view and on a conser-
vative estimate, economists estimate that if more ef-
fective use of data generated small gains, making sec-
tors of activity only 1% more efficient, this would add
almost US$15 trillion to global GDP by 2030. (BSA
The Software Alliance, 2015).
a
https://orcid.org/0000-0003-2609-8862
b
https://orcid.org/0000-0002-2809-7778
c
https://orcid.org/0000-0003-1690-7849
Inserted within the context of Industry 4.0, large
volumes of data in different formats have been gener-
ated, captured, and stored, representing an excellent
opportunity to transform them into information that
adds value to the business (Ayres et al., 2020).
The big question in this context is not just about
having more data, as this will happen naturally, but
knowing which data should be used to achieve the ex-
pected objective in the best way and minimizing the
expenditure of time and resources, material and finan-
cial.
While its value proposition is undeniable, to live
up to its promise, data needs to meet some basic pa-
rameters of usability and quality. Not all data is help-
ful for all tasks, i.e., the data needs to match the tasks
for which it is intended to be used (Sharda et al.,
2019).
Machine-learning algorithms are pretty efficient at
discovering patterns in large volumes of data, but con-
tradictorily, they are also greatly affected by biases
and relationships contained in that data. Redundant
attributes impair the machine-learning algorithm per-
Delamora, R., Coelho, B. and Sabino, J.
Improved ACO Rank-Based Algorithm for Use in Selecting Features for Classification Models.
DOI: 10.5220/0011725300003467
In Proceedings of the 25th International Conference on Enterprise Information Systems (ICEIS 2023) - Volume 1, pages 291-302
ISBN: 978-989-758-648-4; ISSN: 2184-4992
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
291

formance, both in terms of speed due to the dimen-
sionality of the data, and the success rate, since the
presence of redundant information can confuse the al-
gorithm instead of helping it to find a correct model
for knowledge. (Witten et al., 2005). Furthermore,
keeping irrelevant attributes in a dataset can result in
overfitting leading to a loss of generalizability and
performance.
The feature selection process primarily focuses
on removing redundant or uninformative predictors
from the model (Kuhn et al., 2013). A valuable way
of thinking about the feature selection problem is a
search in solution space. The search space is discrete
and consists of all possible combinations of selectable
features in the dataset. The objective is to navigate
the solution space and find the best match or a match
good enough to improve performance relative to us-
ing all features (Brownlee, 2014).
Thus, in a world where decisions are increasingly
based on data, it is essential to develop tools that al-
low the selection of features to be more efficiently
performed, aiming to improve the final performance
of the models, removing those features from the anal-
ysis context. That are not significant, or that harm the
final result.
The present work focuses on the development of
improvements in the computational model of feature
selection based on the ACO - Ant Colony Optimiza-
tion (St
¨
utzle et al., 1999) class of algorithms, more
specifically on the metaheuristic AS
rank
- Ant System
with elitist strategy and ranking (Bullnheimer et al.,
1997). This metaheuristic was developed in 1997 as
an evolution of the original AS (Ant System) (Dorigo
et al., 1991) model and is still widely used today as
a basis for new models adapted to specific needs and
applications.
Although ACO (St
¨
utzle et al., 1999) and AS
rank
(Bullnheimer et al., 1997) were initially developed
to solve the Traveling Salesman Problem (TSP), they
can be customized to fit the FS domain.
Using as reference the WFACOFS - Wrapper-
Filter ACO Feature Selection (Ghosh et al., 2019), a
FS algorithm of the Wrapper-filter type, and consid-
ering as an evaluation function the accuracy measure
obtained through the classification of subsets of se-
lected attributes, this work proposes adjustments to
the AS
rank
seeking performance improvements, not
only in the accuracy values but also in reducing the
dimensionality of the datasets.
Currently, the WFACOFS (Ghosh et al., 2019)
method is one of the ones that has presented bet-
ter results in the studied bases. Develop an evolu-
tion from the already widely known algorithm AS
rank
(Bullnheimer et al., 1997), implementing adjustments
to perform the selection of features and use corre-
lation statistics as a reference of distances in order
to obtain an improved algorithm that can match the
WFACOFS or even to partially or totally surpass it,
would be an outstanding contribution to the theme.
In this way, the present work seeks to contribute
to the search for new solutions to the issue of fea-
ture selection by proposing a new approach built from
a metaheuristic created initially to search for better
routes and which presents very desirable characteris-
tics in the proposed problem.
2 LITERATURE STUDY
2.1 Feature Selection
As datasets become complex and voluminous, the FS
is necessary to refine the information by restricting
only relevant and useful features to the process. Con-
sequently, there is also a reduction in computational
effort and time due to the reduction in the dimension-
ality of the data (Ayres et al., 2020).
Given a set of features of dimension n, the FS pro-
cess aims to find a minimum subset of features of di-
mension m (m < n) adequate to represent the original
set. It is a widely used technique and stands out in
Data Mining (Garc
´
ıa et al., 2015).
The literature describes three approaches to the FS
processes, Filter, Wrapper, and Embedded (Dong and
Liu, 2018), each with different selection strategies.
Filter methods work on the intrinsic properties of
data and do not require a learning algorithm. It tends
to make them very fast, but as FS is done without
consultation of a learning algorithm, the accuracy of
FS using filter methods is generally less than wrapper
methods. Wrapper methods require a learning algo-
rithm that leads to a higher accuracy and computation
time. A compromise between these two methods is
embedded methods which are built using a combina-
tion of filter and wrapper methods. These techniques
balance the two classes of methods and try to incor-
porate learning algorithms and intrinsic data proper-
ties in a method. There may be an acceptable trade-
off between computation time and accuracy or even a
lower computation cost with no accuracy degradation.
Therefore, the general trend has moved to the design
of embedded systems (Ghosh et al., 2019).
2.2 Algorithm ACO
The Ant Colony Algorithm (ACO) is a metaheuris-
tic for combinatorial optimization that was created
to solve computational problems that involve finding
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
292

paths in graphs and is based on probability and popu-
lation search methods.
It represents the simulation of the behavior of a
set of agents (ants) belonging to a colony in the food
search, cooperating to optimize the path to be fol-
lowed between the colony and the food source, using
indirect communication.
Computationally, the ACO metaheuristic is a con-
structive search method in which a population of
agents (artificial ants) cooperatively construct candi-
date solutions for a given problem. The construction
is probabilistic, guided by the heuristic of the problem
and by a shared memory between the agents, contain-
ing the experience of previous iterations. This mem-
ory consists of an artificial pheromone trail based on
assigning weights to the features of the candidate so-
lutions (Gaspar-Cunha et al., 2012).
This idea of ACO was first implemented by
(Dorigo et al., 1996), and they named it AS - Ant
System. Since then, many modifications to ACO have
taken place over the years (Ghosh et al., 2019).
Ants are considered stochastic procedures and
construct the subsets of features iteratively, using both
heuristic information and the amount of pheromone
accumulated in the trails. The stochastic compo-
nent brings a complete solution to space exploration
and creates a greater variety of subsets than a greedy
heuristic. The ant search strategy is reminiscent of
reinforcement learning (Dorigo and St
¨
utzle, 2019).
The process is characterized by a positive feed-
back loop, where the probability of an ant choosing a
path increases with the number of ants that previously
chose the same path (Dorigo et al., 1991).
The AS has very desirable characteristics, accord-
ing to (Dorigo et al., 1996):
• It is versatile as it can be applied to similar ver-
sions of the same problem;
• It is robust, as it can be applied with only min-
imal changes to other combinatorial optimization
problems;
• It is a population-based approach. It is interest-
ing because it allows the exploitation of positive
feedback as a search engine.
These desirable properties are counterbalanced
because, for some applications, AS can be overcome
by more specialized algorithms. It is a problem also
shared by other popular methods like Simulated An-
nealing and Tabu Search (Dorigo et al., 1996).
Several improvements were proposed and tested
in the TSP from this first model. All these improved
versions of AS have in common a stronger exploration
of the best solutions found to drive the ant search pro-
cess. They differ mainly in some aspects of the search
control (St
¨
utzle et al., 1999).
Recently authors have suggested an unsupervised
FS algorithm based on ACO. In this method, when
ants construct solutions, they use a similarity ma-
trix to select the next feature based on the similar-
ity between the last selected feature and the feature
to be selected next. After constructing the solutions,
pheromones are updated only based on the frequency
of the selection of features (Ghosh et al., 2019).
While FS is a crucial application domain for ACO,
several works have also focused on other domains.
Even in economics, ACO is used to predict a finan-
cial crisis (Uthayakumar et al., 2020). It goes a long
way in ascertaining the popularity and applicability of
ACO.
2.3 WFACOFS
The hybrid-type WFACOFS (Ghosh et al., 2019) al-
gorithm was implemented to combine the best advan-
tages of the Filter and Wrapper-type methods. For its
development, the UFSACO (Tabakhi et al., 2014) and
TFSACO (Aghdam et al., 2009) algorithms were con-
sidered as a basis, proposing successful techniques to
overcome the deficiencies observed in each one.
WFACOFS introduced new concepts, such as the
normalization of pheromone values, to prevent the FS
process from becoming biased and to improve the
exploration of the solution space. Pheromone up-
dating is done globally and locally in the standard
ACO and the predecessor algorithms on which WFA-
COFS was built, but the pheromone value is not de-
limited. Thus, a feature chosen more often acquires a
high pheromone value leading to its selection multiple
times.
Another critical contribution of WFACOFS is that
the algorithm works with the proposal of carrying out
the pheromone deposit in the node and not in the path
(edge). It also established the calculation of cosine
symmetry between the features for setting up the dis-
tance matrix, a parameter required by the ACO.
3 PRESENT WORK
The basis for our proposed method is described in
Sect. 3.1 while our proposed method is detailed in
Sect. 3.2.
3.1 Basis of Proposed Method
The present work focuses on the development of the-
oretical research and practical experiments using a
Improved ACO Rank-Based Algorithm for Use in Selecting Features for Classification Models
293
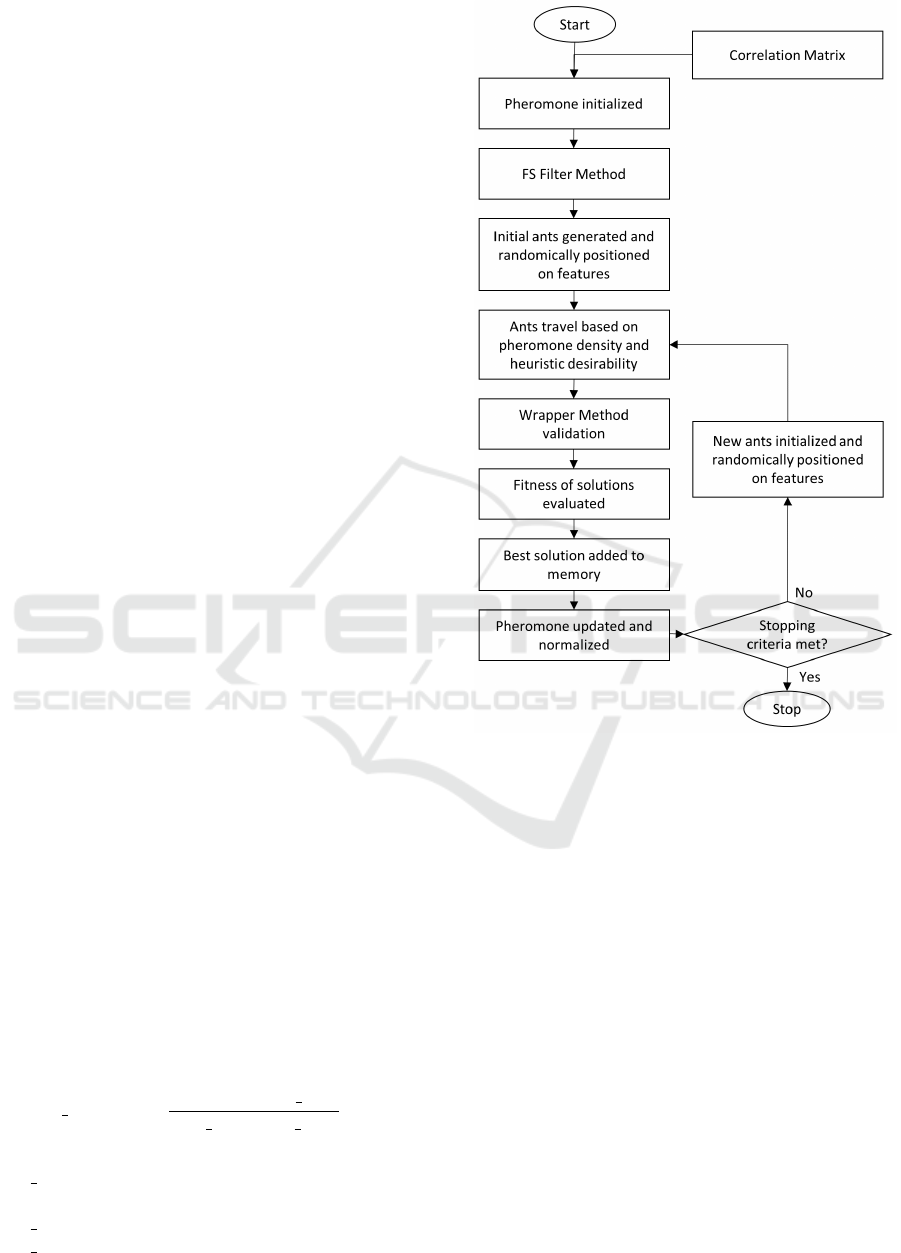
modified version of the algorithm Rank-based Sys-
tem (AS
rank
) (Bullnheimer et al., 1997) to perform the
FS in datasets and considers the WFACOFS algorithm
(Ghosh et al., 2019) as reference for the comparison
of results.
The algorithm AS
rank
, developed by (Bullnheimer
et al., 1997), was chosen to be the basis for this work
because it has favorable characteristics compared to
previous versions of AS: (i) excellent performance
in solving problems and (ii) speed in converging to
reasonable solutions.
In order to provide maximum comparability be-
tween the scenario presented by WFACOFS and that
presented by our method, the same datasets were con-
sidered in studies involving both models.
3.2 Proposed Method
For simplicity, we use the alias ACOFS
rank
- ACO
Feature Selection Rank-Based System for our pro-
posed method. A flowchart of the entire work is given
in Figure 1.
The application of the ACOFS
rank
algorithm to
perform the FS requires the prior evaluation of these
features. This work assumes that the dataset has al-
ready undergone the initial data transformation and
treatment processes to make it consistent and suitable
for use in machine-learning algorithms. Anomaly sit-
uations, lack of data, errors in description, and data
imbalance, among other problems usually found in
the original datasets would already be solved or, at
least, mitigated to a large extent.
The statistical correlation metric is used to build
the model’s matrix. Correlation is not commonly
used in this application, but it was considered to bring
a new perspective to the method’s operation. The
Spearman Correlation (Spearman, 1904) was used to
calculate the correlation for its straightforward inter-
pretation and explanation.
As the correlation value can assume values be-
tween [0, 1] and the value 0 is not desired because it
can generate division by zero errors during the algo-
rithm’s execution, a re-scaling operation is applied to
the matrix so that all values are in the range of [1, 10].
This operation follows the calculation presented in
Equation 1.
cor ad justed =
9 ∗ (value − cor min)
cor max − cor min
+ 1 (1)
wherein:
cor ad justed correlation after re-scaling process
value original correlation value
cor min minimum value on matrix
cor max maximum value on matrix
Figure 1: Flowchart for proposed ACOFS
rank
.
After the initialization of the pheromone matrix,
the Filter method is applied in the first step of FS.
Filter-based FS methods use statistical measures to
score the dependence between input features that
can be filtered to choose the most relevant resources
(Brownlee, 2019).
The main objective to be achieved in this step is
to produce a minority reduction in the total amount of
features, eliminating those that, in a more statistically
evident way, do not add value or have a low influence
on the response feature.
The practical implementation of the Filter method
was carried out using the ANOVA (Analysis Of Vari-
ance) statistical test, taking into account the F-score
coefficient as a validation metric. ANOVA is a sta-
tistical method to verify if there are significant dif-
ferences between the means of groups of data, being
possible to infer if the features are dependent on each
other (Santos, 2021).
Also, as presented by (Gajawada, 2019), the vari-
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
294

ance of an independent feature determines how much
it impacts the response feature. If the variance is low,
this characteristic has no significant impact on the re-
sponse and vice versa.
ANOVA calculates the variance ratio between
groups divided by variance within groups as described
in Equation 2. Thus, the greater the variance between
the groups, the more different the two features will be
and the greater the F-score (Santos, 2021).
F − score =
Variance among groups
Variance within groups
(2)
F-score is a univariate feature selection method,
which means it scores each feature (x
1
, x
2
, x
3
, ...) in-
dividually without considering that one feature may
present better results if combined with others. The
higher the F-score, the more likely this feature is to
be more discriminating (Chen and Lin, 2006).
ANOVA uses verification by the F-test table to
validate if there is any significant difference between
the groups of values that make up a feature. If there
is no significant difference between the groups, it can
be assumed that, statistically, all variances are equal.
This feature must then be removed from the (Ga-
jawada, 2019) template.
Once ANOVA is applied to compare each inde-
pendent feature with the response feature, a F-score
coefficient associated with each is obtained. This co-
efficient represents the influence of the feature’s be-
havior on the response feature’s behavior or, in other
words, it represents the share of explainability of the
behavior of the response feature that is attributed to
this feature under analysis.
In this work, the features that, in the accumu-
lated sum of the individual F-scores, represent 95%
of the explainability of the response feature will be
maintained. This way, removing unimportant features
from a statistical point of view is carried out without
significant loss of information. A process example is
described in Figure 2, which shows a graph with the
F-Score values for each feature on the Wine dataset
and its accumulated value. The dotted line indicates
the 95% cutoff threshold.
Figure 2: F-score analysis using ANOVA.
After selecting the features in the Filter method
step, a new dataset is generated with only the re-
maining features, which follow the algorithm’s flow
of analysis and processing.
The ants are randomly placed on these remain-
ing features. According to (Bullnheimer et al., 1997),
ACO achieves better results when the number of ants
equals the number of features, and each ant starts its
journey in a different feature. This setting was also
used in ACOFS
rank
.
The definition of using an ant for each variable has
its pros and cons. One benefit is that it increases the
search space, ensuring that more subsets of variables
are analyzed. On the other hand, it increases com-
plexity and computational cost, especially in datasets
with a large number of features.
From there, each ant traverses a number of fea-
tures that is also randomly defined. In this way, solu-
tions with different amounts of features are built and
analyzed, allowing the model to autonomously ex-
plore and discover reasonable solutions with reduced
numbers of features.
Starting from a different initial feature, each ant
chooses the next feature to be visited, considering
a probability that is a function of the correlation
value between the features and the amount of resid-
ual pheromone present on the edge that connects to
this feature. The probability calculation is defined by
Equation 3.
p
k
i j
=
[τ
i j
(t)]
α
· [η
i j
(t)]
β
∑
h∈Ω
([τ
ih
(t)]
α
· [η
ih
(t)]
β
)
(3)
η
i j
=
1
d
i j
wherein:
τ
i j
intensity of the pheromone present in the edge
between features i and j
Improved ACO Rank-Based Algorithm for Use in Selecting Features for Classification Models
295

α influence of the pheromone
β influence of the correlation between the features
i and j
d
i j
correlation between features i and j
η
i j
visibility between features i and j
Ω list of features not yet visited by the ant
As in AS
rank
(Bullnheimer et al., 1997), a memory
of the features already visited is kept in each ant, thus
preventing repetitions of features in the same stretch.
Likewise, the pheromone is only updated at the end
of the construction phase.
The best global track is always used to upgrade
pheromone levels, which characterizes an elitist strat-
egy. Also, only some of the best ants from the cur-
rent iteration can add pheromones. The amount of
pheromone an ant can deposit is defined according to
the ranking index r. Only the best (ω − 1) ants from
each iteration can deposit pheromone. The best global
solution is given the weight ω. The rth best ant of the
iteration contributes to the pheromone update with a
weight given by max{0, ω − r} (St
¨
utzle et al., 1999).
The way the pheromone is updated in Equations 4
and 5 allows the success of the previous iterations to
be reflected in future generations. The constant φ de-
fines the balance between the importance of accuracy
and the number of features used in the solution.
After updating the pheromone matrix, the solu-
tions found (a subset of features) are ordered accord-
ing to the level of pheromone present. The best solu-
tion among them is chosen and stored. It is up to the
Wrapper method to define the values of the statistical
metric associated with each solution.
τ
i j
(t + 1) = (1 − ρ) · τ
i j
(t)+
ω
∑
r=1
(ω − r) · ∆τ
r
i j
(t) + ω · γ
best
(4)
∆τ
r
i j
(t) =
(
φ · γ(G) +
(1−φ)·(n−|G|)
n
, if i ∈ G
0 , otherwise
(5)
wherein:
n number of ants
r ranking of ants
∆τ
r
i j
increase of pheromone by rth ant
ω number of elitists ants
φ balance of accuracy
G a subgroup of selected features
γ(G) accuracy for selected features defined by rth
ant
γ
best
accuracy of the best ant
A new cycle or iteration is started with new ants
being built, and the pheromone matrix is maintained.
In this way, the pheromones matrix works as a solu-
tions’ memory mapped in the previous cycle and iden-
tifies those considered the best.
The values of α and β provide the necessary bal-
ance between exploitation and exploration. Using ρ
i
(pheromone on the ith feature) provides the scope of
including previous success in decision-making.
Even though it is a stochastic process, or even be-
cause of it, the undesired situation of having solutions
that are precisely the same as those previously gen-
erated by other ants may occur. In these cases, the
duplicated solution is discarded, and a new option is
then constructed, following the same precepts of ran-
domness in the definition of each solution. This pro-
cess aims to increase the exploration of the solution
space, preventing the algorithm from remaining stuck
in a particular search region.
There may also be cases in which solutions with
different features but in the same amount have equal
accuracy values. To mitigate the problem mentioned
above, after executing the Wrapper method, a func-
tion to validate the fitness of the solutions was im-
plemented in the algorithm. For its implementation,
the statistical measure F-measure (also known as F1-
score) is used, which is the harmonic mean between
precision and recall and can be interpreted as a mea-
sure of the reliability of accuracy. A high value on this
measure means that the accuracy is relevant (Silva,
2018). Equation 6 provides the objective function in
determining the fitness of a subset of features G.
f it = w
1
· γ(G) + F1(G) + w
2
· e
−
r
n
(6)
wherein:
w
1
weight to the accuracy
w
2
weight to the ratio of unselected features to
the feature dimension
γ(G) accuracy of the selected group
F1(G) F-measure of the selected subgroup
n total number of features
r number of features of the solution created
by the ant
4 EXPERIMENTAL RESULTS
To evaluate the performance of ACOFS
rank
con-
cerning to WFACOFS, the same datasets used in
WFACOFS were selected, which were still available.
These datasets are available through the UCI (Dua
and Graff, 2017) repository and are frequently cited
in the literature for evaluating machine-learning mod-
els. This chapter presents the results achieved.
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
296

Table 1 details the properties of these datasets,
which were categorized according to the number
of features, following the same criteria defined by
(Ghosh et al., 2019): Accuracy per classifier with 10,
20, and 30 iterations
1. Small → features ≤ 10
• Breast Cancer (BC)
2. Medium → 10 < features ≤ 100
• Wine (WI)
• Ionosphere (IO)
• Soybean Small (SS)
• Hill Valley (HV)
Table 1: Description of the datasets used in the present
work.
Dataset Features Classes Samples
Breast Cancer 9 2 699
Wine 13 3 178
Ionosphere 34 2 351
Soybean Small 35 4 47
Hill Valley 100 2 606
Datasets with a high number of features (above
100) require an analysis of their performance in pro-
cessing time and are generally datasets with dense
data characteristics (Ayres, 2021). There are no re-
strictions on using ACO in this type of dataset, but
they were not considered in this work and are part of
the proposal for improvements and future work.
The ACOFS
rank
algorithm was developed in
Python language version 3.8.3, using the Spyder IDE
v.4. All computational experiments were performed
on an Intel Core i5-7200U CPU @ 2.50GHz (2 pro-
cessing cores) with 16GB of RAM and Windows
Home 10 64-bit operating system.
All hyper-parameters used in the algorithm are
given in Table 2. The calibration of the values ap-
plicable to the hyper-parameters ρ, α, β, φ, w
1
and
w
2
were done using the IRACE library (L
´
opez-Ib
´
a
˜
nez
et al., 2016), which uses the statistical software pack-
age R (R, 2015).
Figure 3 presents the values used by IRACE to
define the best set of hyper-parameters, and Figure 4
contains the screen with the final results presented by
the tool as optimal options. According to the IRACE
documentation, the final options presented by the tool
are equivalent in terms of algorithm performance and
any of them can be chosen. The selection of hyper-
parameters adopted in ACOFS
rank
is highlighted in
Figure 4.
The algorithm had been run on all bases and with
all classifiers in three blocks, with 10, 20, and 30 iter-
ations.
Figure 3: Ranges of hyper-parameters used in IRACE.
Figure 4: IRACE final results and chosen hyper-parameters
set.
Table 3 and Figure 5 show the results achieved in
experiments. The number of features selected in each
case is described in parentheses, and the best result
for each dataset is in bold and underlined.
After obtaining the feature subset through the Fil-
ter method, we used different classifiers to evaluate
the solutions obtained by each ant in each iteration.
The classifiers used are K-Nearest Neighbors - KNN
(Luz, 2018) (Brownlee, 2020); MLP (Ferreira, 2019)
(Mohanty, 2019) (Moreira, 2018); XGBoost (Chen
and Guestrin, 2016) (Brownlee, 2020); and Random
Forest (Ho, 1995) (Brownlee, 2020).
The KNN algorithm is a non-parametric, super-
vised learning classifier which uses proximity to make
classifications or predictions about the grouping of an
individual data point. While it can be used for ei-
ther regression or classification problems, it is typi-
cally used as a classification algorithm, working off
the assumption that similar points can be found near
one another (IBM, 2020). This classifier is very pop-
ular due to its simplicity and efficiency at the same
time.
MLP is a popularly used and efficient classifier. It
is a feed-forward artificial neural network consisting
of three layers — input, hidden, and output. The lay-
ers form a connected graph and are assigned random
weights, modified during training using the backprop-
agation algorithm (Ghosh et al., 2019).
XGBoost is an efficient open-source implementa-
tion of the gradient-boosted trees algorithm. Gradient
Improved ACO Rank-Based Algorithm for Use in Selecting Features for Classification Models
297

Table 2: Description of algorithm hyperparameters.
Parameter Description Value
n Number of ants Equal to the number of features
m Number of elitists ants 30% of the number of features, limited to 15
α Pheromone influence 2.0
β Correlation between features influence 1.0
Iterations Number of iterations 10, 20 and 30
ρ Pheromone evaporation factor 0.15
φ Balance factor for accuracy 0.50
w
1
Weight parameter for accuracy 150
w
2
Weight parameter for the number of features
of the selected subset
2
Table 3: Accuracy per classifier with 10, 20, and 30 iterations.
boosting is a supervised learning algorithm that at-
tempts to accurately predict a target variable by com-
bining the estimates of a set of simpler, weaker mod-
els (AWS, 2022).
Random forest is a supervised learning algorithm
that can be used both for classification and regression.
It is also the most flexible and easy to use. A for-
est is comprised of trees, and it is said that the more
trees it has, the more robust a forest is. Random forest
creates decision trees on randomly selected data sam-
ples, gets predictions from each tree, and selects the
best solution through voting. It also provides a good
indicator of the feature’s importance (Naviani, 2018).
Table 4 presents the percentage number of features
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
298

Figure 5: Accuracy per classifier with 10, 20, and 30 iterations.
selected by each classifier in each dataset concern-
ing the total number of features. The values obtained
by ACOFS
rank
are compared to the values defined
in WFACOFS. Note that the ACOFS
rank
achieves a
more significant reduction in the dimensionality of the
datasets.
Table 5 shows a comparison among the best val-
ues of accuracy obtained by the algorithms in each
dataset. These results do not consider the type of clas-
sifier but only the best accuracy result obtained. The
number of features selected in each case is described
in parentheses, and the best result for each dataset is
in bold and underlined.
From Tables 3, 4, and 5, it can be observed that the
proposed model is comparable to WFACOFS. Thus,
we can state that ACOFS
rank
is a model which applies
to FS problems with some important gains. It uses
the Filter approach to reduce the computational cost
of the system and the power of a Wrapper approach
to enhance the classification ability, which makes it
an overall robust embedded model. It also uses corre-
lation as the primary statistical metric to fill the dis-
Improved ACO Rank-Based Algorithm for Use in Selecting Features for Classification Models
299

Table 4: No. of features considered for the best accuracy
about the total of features.
Table 5: Comparison of our proposed approach with WFA-
COFS algorithm.
tances matrix and applies additional validation on the
fitness function to select the best solution, even on un-
balanced datasets.
5 CONCLUSION AND FUTURE
WORKS
In this work, we propose an improvement in the gen-
eral construction of the well-known AS
rank
algorithm
(Bullnheimer et al., 1997) to obtain an increase in per-
formance with a reduction in the dimensionality of
the datasets applying a FS process. The proposed al-
gorithm was compared to WFACOFS (Ghosh et al.,
2019), a recently developed embedded algorithm that
presents excellent results in the analyzed aspects.
It can be considered that the general objective of
creating an improved algorithm using the Rank-based
Ant System (AS
rank
) metaheuristic was achieved, tak-
ing into account that the results obtained by the new
proposed ACOFS
rank
algorithm surpassed in most of
the databases those obtained by the reference model
WFACOFS. Furthermore, the reduction in dimen-
sionality promoted by ACOFS
rank
was more signifi-
cant than that of WFACOFS.
Despite being a more complex solution than other
already available, the results demonstrate the poten-
tial of ACOFS
rank
in FS operations in a wide range
of datasets. The possibility of using different robust
classifiers through parameterization characterizes the
good adaptability and flexibility of the algorithm.
As a proposal for future scope, one might consider
exploring new ways of measuring heuristic desirabil-
ity using other filter methods instead of ANOVA. Us-
ing other classifiers for the Wrapper method and for
evaluating the values in the fitness function is also
very interesting and can present promising results.
Adapting the algorithm to work with classification
and regression algorithms will bring greater flexibil-
ity for broader use in projects involving these two
strands.
ACKNOWLEDGEMENTS
This study was financed in part by the Coordenac¸
˜
ao
de Aperfeic¸oamento de Pessoal de N
´
ıvel Supe-
rior - Brasil (CAPES) - Finance Code 001, the
Conselho Nacional de Desenvolvimento Cient
´
ıfico
e Tecnol
´
ogico (CNPQ), the Instituto Tecnol
´
ogico
Vale (ITV), the Universidade Federal de Ouro Preto
(UFOP) and the Vale S.A..
REFERENCES
Aghdam, M. H., Ghasem-Aghaee, N., and Basiri, M. E.
(2009). Text feature selection using ant colony
optimization. Expert systems with applications,
36(3):6843–6853.
AWS (2022). How xgboost works. https://docs.aws.amazo
n.com/sagemaker/latest/dg/xgboost-HowItWorks.ht
ml. (accessed on March 16, 2022).
Ayres, P. F. (2021). Selec¸
˜
ao de atributos baseado no al-
goritmo de otimizac¸
˜
ao por col
ˆ
onia de formigas para
processos mineradores. Master’s thesis, UFOP -
Universidade Federal de Ouro Preto, Ouro Preto.
(Mestrado Profissional em Instrumentac¸
˜
ao, Controle
e Automac¸
˜
ao de Processos de Minerac¸
˜
ao).
Ayres, P. F., Sabino, J. A., and Coelho, B. N. (2020).
Selec¸
˜
ao de vari
´
aveis baseado no algoritmo otimizac¸
˜
ao
col
ˆ
onia de formigas: Estudo de caso na ind
´
ustria de
minerac¸
˜
ao. In Congresso Brasileiro de Autom
´
atica-
CBA, volume 2.
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
300

Brownlee, J. (2014). Feature selection to improve accuracy
and decrease training time. https://machinelearningm
astery.com/feature-selection-to-improve-accuracy-a
nd-decrease-training-time/. (accessed on September
30, 2022).
Brownlee, J. (2019). How to choose a feature selection
method for machine learning. https://machinelearn
ingmastery.com/feature-selection-with-real-and-cat
egorical-data/. (accessed on July 22, 2022).
Brownlee, J. (2020). How to calculate feature importance
with python. https://machinelearningmastery.com/c
alculate-feature-importance-with-python/. (accessed
on March 2, 2022).
BSA The Software Alliance, B. (2015). What is the big
deal with data? https://data.bsa.org/wp-content/u
ploads/2015/12/bsadatastudy\ en.pdf. (accessed on
September 4, 2022).
Bullnheimer, B., Hartl, R. F., and Strauss, C. (1997). A new
rank-based version of the ant system. a computational
study.
Chen, T. and Guestrin, C. (2016). Xgboost: A scalable tree-
boosting system. In Proceedings of the 22nd ACM
Sigkdd international conference on knowledge discov-
ery and data mining, pages 785–794.
Chen, Y.-W. and Lin, C.-J. (2006). Combining svms with
various feature selection strategies. In Feature extrac-
tion, pages 315–324. Springer.
Dong, G. and Liu, H. (2018). Feature engineering for ma-
chine learning and data analytics. CRC Press.
Dorigo, M., Maniezzo, V., and Colorni, A. (1991). Positive
feedback as a search strategy.
Dorigo, M., Maniezzo, V., and Colorni, A. (1996). Ant sys-
tem: optimization by a colony of cooperating agents.
IEEE Transactions on Systems, Man, and Cybernet-
ics, Part B (Cybernetics), 26(1):29–41.
Dorigo, M. and St
¨
utzle, T. (2019). Ant colony optimization:
overview and recent advances. Handbook of meta-
heuristics, pages 311–351.
Dua, D. and Graff, C. (2017). Uci machine learning reposi-
tory.
Ferreira, C. A. (2019). Mlp classifier. https://medium.c
om/@carlosalbertoff/mlp-classifier-526978d1c638.
(accessed on March 2, 2022).
Gajawada, S. K. (2019). Anova for feature selection in ma-
chine learning. https://towardsdatascience.com/anova
-for-feature-selection-in-machine-learning-d9305e2
28476. (accessed on August 3, 2022).
Garc
´
ıa, S., Luengo, J., and Herrera, F. (2015). Data prepro-
cessing in data mining, volume 72. Springer.
Gaspar-Cunha, A., Takahashi, R., and Antunes, C. H.
(2012). Manual de computac¸
˜
ao evolutiva e meta-
heur
´
ıstica. Coimbra University Press.
Ghosh, M., Guha, R., Ram, S., and Ajith, A. (2019). A
wrapper-filter feature selection technique based on ant
colony optimization. Neural Computing & Applica-
tions, 32(12):7839–7857.
Ho, T. K. (1995). Random decision forests. In Proceedings
of 3rd international conference on document analysis
and recognition, volume 1, pages 278–282. IEEE.
IBM (2020). What is the k-nearest neighbors algorithm?
https://www.ibm.com/topics/knn#:
∼
:text=The\%
20k\%2Dnearest\%20neighbors\%20algorithm\%
2C\%20also\%20known\%20as\%20KNN\%20
or,of\%20an\%20individual\%20data\%20point.
(accessed on March 2, 2022).
Kuhn, M., Johnson, K., et al. (2013). Applied predictive
modeling, volume 26. Springer.
L
´
opez-Ib
´
a
˜
nez, M., Dubois-Lacoste, J., C
´
aceres, L. P., Bi-
rattari, M., and St
¨
utzle, T. (2016). The irace package:
Iterated racing for automatic algorithm configuration.
Operations Research Perspectives, 3:43–58.
Luz, F. (2018). Algoritmo knn para classificac¸
˜
ao. https:
//inferir.com.br/artigos/algoritimo-knn-para-classific
acao/. (accessed on March 2, 2022).
Mohanty, A. (2019). Multi-layer perceptron (mlp) models
on real-world banking data. https://becominghuman.
ai/multi-layer-perceptron-mlp-models-on-real-world
-banking-data-f6dd3d7e998f. (accessed on March 2,
2022).
Moreira, S. (2018). Multi-layer perceptron (mlp) models on
real-world banking data. https://medium.com/ensin
a-ai/rede-neural-perceptron-multicamadas-f9de847
1f1a9#:
∼
:text=Perceptron\%20Multicamadas\%2
0(PMC%20ou\%20MLP,sa\%C3\%ADda\%20de
sejada\%20nas\%20camadas\%20intermedi\%C3\
%A1rias. (accessed on March 2, 2022).
Naviani, A. (2018). Understanding random forests classi-
fiers in python tutorial. https://www.datacamp.com/t
utorial/random-forests-classifier-python. (accessed
on March 22, 2022).
R, C. T. (2015). R: A language and environment for statisti-
cal computing. https://www.R-project.org. (accessed
on September 20, 2022).
Santos, G. (2021). Estat
´
ıstica para selec¸
˜
ao de atributos. ht
tps://medium.com/data-hackers/estat%C3%ADstic
a-para-sele%C3%A7%C3%A3o-de-atributos-81bdc
274dd2c. (accessed on July 10, 2022).
Sharda, R., Delen, D., and Turban, E. (2019). Busi-
ness Intelligence e An
´
alise de Dados para Gest
˜
ao do
Neg
´
ocio-4. Bookman Editora.
Silva, T. A. (2018). Como implementar as m
´
etricas pre-
cis
˜
ao, revocac¸
˜
ao, acur
´
acia e medida-f. https://tiago.bl
og.br/precisao-revocacao-acuracia-e-medida-/\#:\
∼
:
text=Medida\%20F\%20(F\%20Measure\%2C\%
20F1,medida\%20de\%20confiabilidade\%20da\%
20acur\%C3\%A1cia. (accessed on September 20,
2022).
Spearman, C. (1904). The proof and measurement of asso-
ciation between two things. Amer. Journal of Psychol-
ogy, 15(1):72–101.
St
¨
utzle, T., Dorigo, M., et al. (1999). Aco algorithms for the
traveling salesman problem. Evolutionary algorithms
in engineering and computer science, 4:163–183.
Tabakhi, S., Moradi, P., and Akhlaghian, F. (2014). An
unsupervised feature selection algorithm based on ant
colony optimization. Engineering Applications of Ar-
tificial Intelligence, 32:112–123.
Uthayakumar, J., Metawa, N., Shankar, K., and Laksh-
manaprabu, S. (2020). Financial crisis prediction
Improved ACO Rank-Based Algorithm for Use in Selecting Features for Classification Models
301

model using ant colony optimization. International
Journal of Information Management, 50:538–556.
Witten, I. H., Frank, E., Hall, M. A., and Pal, C. J.
(2005). Data mining practical machine learning tools
and techniques. volume 2.
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
302
