
Fuzzy Logic for Diabetes Predictions: A Literature Review
Alice Tissot Garcia Pintanel
1,∗
, Grac¸aliz Pereira Dimuro
2
, Eduardo Nunes Borges
2
, Giancarlo Lucca
2
and Camila Rose Guadalupe Barcelos
3
1
Computational Modeling, Federal University of Rio Grande (FURG), Rio Grande, RS, Brazil
2
Center for Computational Sciences (C3), Federal University of Rio Grande (FURG), Rio Grande, RS, Brazil
3
Hospital Sirio Libanes, S
˜
ao Paulo, SP, Brazil
Keywords:
Diabetes, Machine Learning, Classification Problems, Systematic Literature Review.
Abstract:
The use of methodologies based on machine learning is being increasingly used in health systems today,
addressing different areas such as food, society, health and others. In terms of health, different techniques were
applied to classify different diseases. In this sense, diabetes is an important and silent disease that deserves
special attention and care. Individuals often do not know they have it, and, therefore, seeking alternatives to
predict this disease is an important contribution to the health area. Thinking about it, in this work we present
a systematic review of the literature with the objective of observing which strategies are currently being used
to predict and classify diseases using fuzzy logic, in particular, diabetes. For this, 6 works were selected and
analyzed, where the technique for obtaining the considered information is the blood test, in order to understand
the current state of the art.
1 INTRODUCTION
Health has always been and will be an extremely im-
portant subject to be debated. Either through the in-
cessant search for new methods that can mitigate the
risks of getting diseases, or through the search for
new strategies that can somehow contribute to the im-
provement of the health system.
The use of machine learning techniques (Bonac-
corso, 2017) has been increasingly used in several
areas of society, including medicine. For example,
in (Saleck et al., 2017) the authors used a cluster-
ing algorithm to detect tumors in mammography im-
ages. In (Bergquist et al., 2017), the authors used ma-
chine learning to classify lung cancer patients receiv-
ing chemotherapy into early-stage versus advanced-
stage cancer.
Diabetes is a disease caused by insufficient pro-
duction or poor absorption of insulin, a hormone that
regulates blood glucose and provides energy for the
body (Grillo and Gorini, 2007). Diabetes can cause
increased blood glucose and can lead to complica-
tions in the heart, arteries, eyes, kidneys and nerves.
In more severe cases, diabetes can even lead to death.
According to the Brazilian Society of Diabetes
1
,
∗
PhD student
1
https://diabetes.org.br/
at the end of 2021, Brazil had more than 13 mil-
lion people living with diabetes, which represents
about 6.9% of the Brazilian population. Diabetes can
present itself in different ways and has several dif-
ferent types, with type 2 diabetes being the one that
most affects people, about 90% of people with dia-
betes have type 2. Depending on the severity, dia-
betes can be controlled with physical activity and di-
etary planning, but in other cases, it requires the use
of insulin and/or other medications to control glucose
(Lyra et al., 2006).
One of the tasks most used by machine learning
techniques refers to the prediction problem. Predic-
tive analysis basically consists of applying algorithms
to understand the existing data structure and gener-
ate ways to help predict new cases. According to
(Dos Santos et al., 2019), in the health area, predictive
models can be used to estimate the risk of a given out-
come occurring, considering a set of characteristics,
such as: socioeconomic and demographic aspects, re-
lated to lifestyle and health conditions, among oth-
ers. In addition, the correct use of prediction models
can result in positive implications in terms of cost re-
duction and the effectiveness of interventions, such as
treatments and preventive actions.
Considering the severity and consequences that
diabetes can have on people’s lives, it was understood
476
Pintanel, A., Dimuro, G., Borges, E., Lucca, G. and Barcelos, C.
Fuzzy Logic for Diabetes Predictions: A Literature Review.
DOI: 10.5220/0011851500003467
In Proceedings of the 25th International Conference on Enterprise Information Systems (ICEIS 2023) - Volume 1, pages 476-483
ISBN: 978-989-758-648-4; ISSN: 2184-4992
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

that monitoring the variables involved in the detection
of diabetes could be a way of mitigating the risks for
those people who already have the disease, or even
prevent the disease from manifesting itself in new
people. In addition, the need to control several vari-
ables that can aggravate or even cause diabetes also
led to the need not only to monitor, but also to control
such variables.
For this, however, it was necessary to know the
state of the art with regard to methodologies used in
the health area in the classification and prediction pro-
cess that could help in understanding the problem and
in the elaboration of a new methodology.
In order to try to map which techniques are being
most used in the prediction of diseases and, mainly,
in the prediction of diabetes, it was decided to carry
out a systematic review, so that one could find what is
currently state-of-the-art in what concerns related to
disease prediction.
In addition, the idea is also to find, from the sys-
tematic review, how fuzzy logic (Zadeh et al., 1996)
is being used in this area, since it is an approach that
uses linguistic terms and therefore manages to re-
turn interpretable results. We pointed out that fuzzy
logic allows the possibility of modeling such linguis-
tic terms according to the domain expert, which can
be an advantage over other methods. Therefore, fuzzy
logic based questions were included in this review.
Then, a systematic review of the literature was car-
ried out, in 4 bibliographical sources (BS), consider-
ing 4 research questions.
The general objective of this work is to iden-
tify the prediction and classification methodologies,
mainly involving fuzzy logic, which are being used in
the health field, in particular, in relation to diabetes.
The rest of the article is divided into four sec-
tions. The first presents the definition and steps to
build a systematic review; the second presents the
methodology adopted for carrying out the system-
atic research, as well as the discussion in each of the
stages; the third presents the obtained results; and the
last presents the conclusions obtained from the con-
struction of this work.
2 SYSTEMATIC REVIEW
According to (Cordeiro et al., 2007), the System-
atic Literature Review (SLR) consists of a research
method that aims to identify, evaluate and interpret all
relevant research on specific issues or area of interest.
From the use of the SLR it is possible to sort and syn-
thesize studies from the definition of questions and/or
keywords, making the review much fairer.
A research protocol must be defined and must con-
tain four generic steps: the first one is responsible
for defining the research questions that the system-
atic review intends to answer and that will serve as a
guideline for the study; the second defines the search
strategy, including the databases and search terms that
will be considered to identify and select the articles;
the third defines the inclusion and exclusion criteria;
and the fourth and last, is responsible for defining how
to characterize the studies, which information will be
extracted and how it will be synthesized and analyzed
(Keele et al., 2007) (Ercole et al., 2014).
The main advantage with regard to carrying out a
systematic review, according to (Ercole et al., 2014),
consists in the fact that a well-defined methodology
ends up making it less likely that the results of the
literature are biased, that is, it tends to prevent articles
from chosen by the writer are only those who support
his/her point of view.
3 METHODOLOGY
The methodology used to carry out the systematic re-
view followed the method presented by (Keele et al.,
2007), and is summarized in the flowchart presented
by Figure 1. In it, as the process evolves, the articles
found in searches are removed from the scope of the
study. Below, for each one of the four keys stages
of the systematic review process, the adopted criteria
will be discussed in detail.
3.1 Research Questions
The first step, to start the systematic review process,
is related with the definition the research questions
necessarily to be answerd. Such questions are re-
sponsible for giving rise to the search terms and com-
binations of keywords used during searches in the
databases used.
Considering the problem previously discussed in
the Introduction, four research questions were sepa-
rated, namely:
• Question 1: What are the predictive methods
used to adjust models on different blood labora-
tory test variables?
• Question 2: Which classification methods are
used to fit models on different blood laboratory
test variables?
• Question 3: What are the predictive meth-
ods used to adjust models on different health
databases?
Fuzzy Logic for Diabetes Predictions: A Literature Review
477

Research Questions
Search Terms
Search Terms
Data
base
Books or
Chapters
Articles
Published
until 2017
Published
after 2017
Year Title
No
Yes
Relevant
Abstract
Yes
Relevant
Introduction
Conclusion
NoNo
Yes
Relevant
Figure 1: Flowchart of the theoretical review methodology (Source: Elaborated by the author).
• Question 4: Which classification methods are
used to fit models on different health databases?
It should be noted that for each of the planned
surveys, the existing fuzzy logic related to predictive
methods was also analyzed, since the idea of the work
is to use fuzzy logic to predict diabetes based on in-
formation extracted from blood tests.
3.2 Search Terms
The search terms were defined from the four research
questions previously presented. We highlight the fact
that we chose to consider the search terms only in En-
glish.
The search terms considered for the construction
of combinations of keywords were: blood test, health
database, classification, prediction and fuzzy. From
these selected search terms, some combinations of
keywords were elaborated that were used in the sys-
tematic research in the selected databases. In Table 1,
the relation of keywords (K) used are presented.
3.3 Considered Data Bases
To perform a complete and more robust search, dif-
ferent digital libraries were considered. Precisely, the
queries were performed in:
• IEEE Xplore
2
;
2
https://ieeexplore-ieee-
Table 1: Keyword combinations used.
K Combination
1 “blood test” and “prediction”
2 “blood test” and “classification”
3 “blood test” and “prediction” and “fuzzy”
4 “blood test” and “classification” and “fuzzy”
5 “health database” and “prediction”
6 “health database” and “classification”
7 “health database” and “prediction” and “fuzzy”
8 “health database” and “classification” and “fuzzy”
• ACM Digital Library
3
;
• Scopus
4
;
• SpringerLink
5
.
3.4 Exclusion/Inclusion Criteria
Exclusion Criteria (EC) are defined as aspects of the
study that meet the inclusion criteria, but have addi-
tional characteristics that could interfere with the suc-
cess of the study or increase the risk of obtaining un-
necessary information for the study. The considered
ECs were:
• EC 1: Articles published before 2017, because
org.ez40.periodicos.capes.gov.br/Xplore/guesthome.jsp
3
https://dl-acm-org.ez40.periodicos.capes.gov.br/
4
https://www-scopus.ez40.periodicos.capes.gov.br/
search/form.uri?display=basic#basic
5
https://link-springer-com.ez40.periodicos.capes.gov.br/
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
478
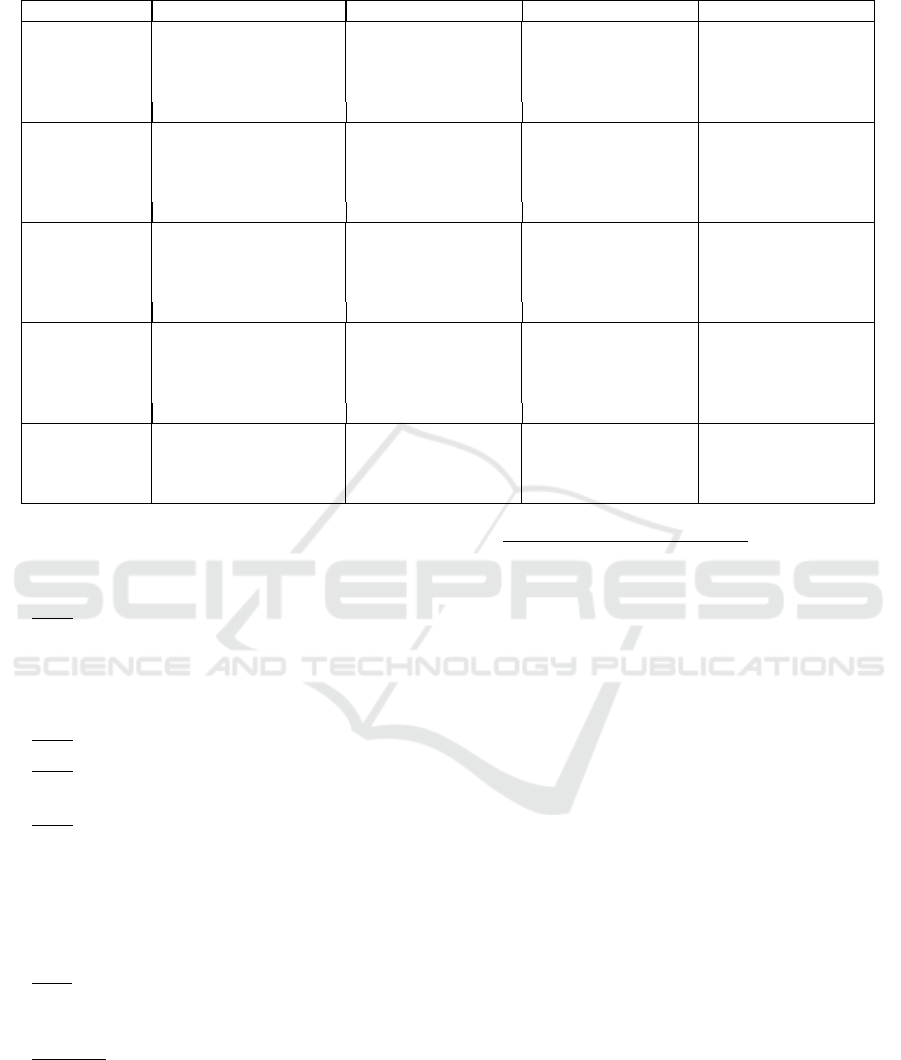
Table 2: Total articles returned for each of the steps described.
BS Initial EC 1 EC 2 e 4 EC 3
K1: 30 K5: 4 K1: 20 K5: 4 K1: 18 K5: 4 K1: 18 K5: 4
K2: 32 K6: 1 K2: 20 K6: 1 K2: 19 K6: 1 K2: 19 K6: 1
IEEE Xplore K3: 2 K7: 0 K3: 2 K7: 0 K3: 2 K7: 0 K3: 2 K7: 0
K4: 2 K8: 0 K4: 1 K8: 0 K4: 1 K8: 0 K4: 1 K8: 0
Total: 71 Total: 48 Total: 45 Total: 45
K1: 9251 K5: 596 K1: 5052 K5: 374 K1: 2902 K5: 190 K1: 2892 K5: 190
K2: 17494 K6: 1355 K2: 8812 K6: 766 K2: 5549 K6: 527 K2: 5345 K6: 526
SpringerLink K3: 861 K7: 106 K3: 624 K7: 81 K3: 123 K7: 9 K3: 123 K7: 9
K4: 991 K8: 116 K4: 679 K8: 87 K4: 143 K8: 13 K4: 143 K8: 13
Total: 30770 Total: 16475 Total: 9456 Total: 9241
K1: 1321 K5: 67 K1: 698 K5: 44 K1: 672 K5: 41 K1: 636 K5: 41
K2: 974 K6: 148 K2: 488 K6: 75 K2: 475 K6: 65 K2: 441 K6: 65
Scopus K3: 7 K7: 0 K3: 6 K7: 0 K3: 6 K7: 0 K3: 6 K7: 0
K4: 7 K8: 1 K4: 2 K8: 0 K4: 2 K8: 0 K4: 2 K8: 0
Total: 2525 Total: 1313 Total: 1261 Total: 1191
K1: 92 K5: 13 K1: 66 K5: 6 K1: 45 K5: 4 K1: 45 K5: 4
K2: 152 K6: 18 K2: 69 K6: 6 K2: 49 K6: 5 K2: 49 K: 5
ACM K3: 16 K7: 2 K3: 12 K7: 0 K3: 7 K7: 0 K3: 7 K7: 0
K4: 23 K8: 3 K4: 12 K8: 0 K4: 8 K8: 0 K4: 8 K8: 0
Total: 319 Total: 171 Total: 118 Total: 118
K1: 10694 K5: 680 K1: 5836 K5: 428 K1: 3637 K5: 239 K1: 3591 K5: 239
Total by K K2: 18652 K6: 1522 K2: 9389 K6: 848 K2: 6092 K6: 598 K2: 5854 K6: 597
K3: 886 K7: 108 K3: 644 K7: 81 K3: 138 K7: 9 K3: 138 K7: 9
K4: 1023 K8: 120 K4: 694 K8: 87 K4: 154 K8: 13 K4: 154 K8: 13
the idea is to observe what is newest being de-
veloped and studied by scholars and researchers
in the area;
• EC 2: Books and book chapters, because the idea
is to find what is being developed by other re-
searchers in recent years and not the concepts and
definitions related to the subject addressed in the
work;
• EC 3
: Works that are not in English;
• EC 4: Works that are not fully published. Ex.
drafts;
• EC 5: Articles returned in combinations that do
not involve fuzzy logic.
Inclusion Criteria (IC) are defined as the key char-
acteristics of the population or research being carried
out. The ICs are used to answer the research questions
and are presented below:
• Title: Does the paper deal with machine learning
with diabetes or prediction or classification using
fuzzy logic for diabetes?
• Abstract: Does the article explain the use of
fuzzy logic in predicting blood test data? Does
the paper explain about the use of fuzzy logic in
classifying blood test data? Does the paper de-
scribe methods of predicting or classifying blood
test data? Does the paper present prediction or
classification in a blood test database?
• Introduction and Conclusion: Are the objec-
tives clearly defined? Are the prediction or classi-
fication methods clearly defined? Does the study
present the idea of using fuzzy logic in predicting
or classifying blood tests? Does the study present
the blood test database used?
3.5 Selecting Works
In this subsection, the data related to exclusion and
inclusion criteria are presented, as well as the number
of articles that were returned from the application of
each of the previously listed criteria.
The first step consisted of carrying out a search
for each of the previously highlighted keyword in the
considered databases, without considering, at first,
any exclusion criteria. In Table 2, the total number
of articles returned for each search order. By line, the
digital libraries are considered and by columns, the
stages of the review process (see Figure 1).
Then, it was decided to apply the exclusion crite-
rion related to the year of publication of the returned
results. For this case, therefore, only the results pub-
lished from 2017 to the present were considered. This
exclusion criterion reduced the total number of re-
turned results, as shown in column “EC 1” of Table
2.
The next steps consisted of applying the other ex-
clusion criteria. The column “EC 2 e 4” of Table 2
presents the results after excluding books and book
Fuzzy Logic for Diabetes Predictions: A Literature Review
479

chapters and also articles that were not fully pub-
lished, while the column “EC 3” of Table 2 presents
the results after the application of the EC referring to
the language in which the article was published.
In short, Table 2 presents for each of the biblio-
graphic sources the total number of articles returned
for each K, as well as the total number of articles re-
turned per database. In addition, through Table 2 it
can be observed that with each EC applied, the total
number of articles returned, not only by K, but also
by bibliographic source, decreased.
After evaluating the returned results, it was found
that a very large number of results had been returned
in combinations of words that did not include the
word ”fuzzy”. Thus, it was decided to remove such
combinations from the analysis, since the main focus
of this work was to find studies that used fuzzy logic
in the process of predicting or classifying health prob-
lems. Thus, instead of 8 Ks, only 4 were considered,
as shown in Table 3.
Table 3: Total articles selected from the application of all
exclusion criteria.
K
IEEE
Xplore
Springer
Link
Scopus
ACM
Dig.
Lib.
Total
3 2 123 6 7 138
4 1 143 2 8 154
7 0 9 0 0 9
8 0 13 0 0 13
Total 3 288 8 15 314
Analyzing Table 3, it can be seen that the IEEE
Xplore library was the one that returned a smaller
number of articles considering all Ks. On the other
hand, SpringerLink was the library that returned the
highest number of results. In addition, the K that re-
turned the most articles was K4, which considered the
relationship of “blood test” and “classification” and
“fuzzy”.
After applying all the previously listed exclusion
criteria, the next step is to apply the inclusion crite-
ria. In this case, the title of all pre-selected works is
initially evaluated. If the title did not meet the es-
tablished criteria, the article was rejected, if it did, it
moved on to the next analysis. After checking the title
of the 314 articles that had remained, 124 articles still
remained. It is noteworthy that, at that time, they were
not yet being analyzed whether the same article was
appearing in more than one combination or in more
than one database.
The next step consisted of analyzing the abstract
and the idea was similar to that of the title, if the
abstract did not present the desired information, the
work was discarded, otherwise, the introduction and
conclusion of the work were evaluated. Figure 2
presents the summary of the number of articles ex-
cluded from the application of each exclusion and in-
clusion criteria considered in this systematic review.
Therefore, after applying all the inclusion criteria,
the total number of selected articles was equal to 6,
whose title information, authors and year of publica-
tion are presented in Table 4.
Next, the 6 selected articles will be briefly dis-
cussed, using each of the considered research ques-
tions as a guide. It should also be noted that a certain
study can answer one or more questions.
4 RESULTS
In this section, each of the selected articles is briefly
presented, highlighting the questions that each one
of them answers, as well as highlighting their main
points.
However, before starting such an analysis, it was
decided to create a word cloud from the six selected
articles. The cloud was generated from the full text
of all articles, that is, all sections of each article were
considered and not just any specific one. The purpose
of creating a word cloud is to observe which words
appear more frequently in the analyzed articles. For
the construction of the cloud presented by Figure 3 the
words/terms that appear more than fifty times were
considered.
Thus, it can be concluded that the words that ap-
pear most frequently are precisely those words that
form the scope of study of this work, that is, those
words that formed the queries. In addition to these,
words such as patients and diabetes also appear fre-
quently, since even though they were not part of the
queries, they were terms that were part of the general
scope of the work and were even used as inclusion
criteria for the selection of articles.
The study presented by (Goldar et al., 2020) arises
as an answer to research questions 1 and 2, since it
works with a prediction system for laboratory tests.
The prediction techniques used were Takagi-Sugeno
zero order fuzzy modeling and sequential direct se-
lection method. The authors proposed a prediction
approach in order to predict values of laboratory tests
of patients admitted to the ICU with gastrointestinal
hemorrhage.
A study that helps answer research question 2
and 4 is presented (Wedagu et al., 2020). The
study disregards the question of blood tests, since
it aims to propose a recommendation method called
DIMERS (Diabetes Medicine Recommendation Sys-
tem, which combines a previous medical knowl-
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
480

71 Citations identified
by searching the
IEEE Xplore database
30770 Citations
identified by searching
the Springer Link
database
2525 Citations
identified by
searching the Scopus
database
319 Citations
identified by
searching the ACM
database
33685 Records
screened
10810 Full-text
articles assessed
for eligibility
22875 Records excluded
- 15678 CE 1
- 7127 CE 2 e 4
- 70 CE 3
10496 Records
excluded referring to
queries 1, 2, 5 and 6
314 Full-text
articles assessed
for eligibility
308 Full-text articles excluded
- 124 title
- 102 abstract
- 82 introduction and conclusion
6 Studies included
in the systematic
review
Figure 2: PRISMA Flow Diagram (Source: Elaborated by the author).
edge of doctors with bidirectional long-term memory
(BiLSTM), in order to correctly recommend medi-
cations for diabetes. Also, according to this study,
more than 250,000 people die from medication errors,
which makes it necessary to use machine learning ap-
proaches to correct such problems. However, most of
the approaches adopted do not consider prior medical
knowledge, meaning that they do not have a result as
satisfactory as what is being proposed in the study.
The study presented by (Deif et al., 2021), despite
not meeting the inclusion criteria IC1, was considered
as it aims to use an Adaptive Neuro-Fuzzy Inference
System (ANFIS) to quickly detect cases of COVID-
19 from commonly available laboratory tests . Thus,
this study answers research question 1, since it uses
the fuzzy methodology to predict, from blood tests,
whether or not the patient has COVID-19.
Fasting blood glucose is considered one of the
most important indicators of diabetes, but its testing
is not feasible for the public and requires prior prepa-
rations before implementation. Thus, the study pre-
sented by (Faraji-Biregani and Nematbakhsh, 2019)
aims to present a model for predicting fasting blood
sugar from other factors in blood tests. For this,
the sine-cosine optimization algorithm and neural net-
works (RNN) are used to perform the prediction. The
study was the one of that best answered the research
questions, being able to answer the four questions si-
multaneously.
Different machine learning techniques, such as the
Adaptive Neuro-Fuzzy Inference System (ANFIS),
K-Nearest Neighbors (KNN) and Decision Tree (DT)
were applied in (Kalaiselvi et al., 2022). Such tech-
niques can help in decision making of the physician’s
decision in the process of predicting liver disease.
This study answers questions 1 and 2, since, based
on blood tests, it uses machine learning techniques to
help physicians predict and classify liver diseases. In
addition, one of the techniques presented by the study
makes use of fuzzy logic, which is also of interest to
be analyzed. Together with the study presented in the
previous paragraph, this work was classified as one
that best answered the listed research questions.
In (Jamuna and Mohan Kumar, 2020), it is pre-
Fuzzy Logic for Diabetes Predictions: A Literature Review
481

Table 4: Basic information of selected articles.
Title Authors Year Total Ci-
tations
Diabetes Fuzzy
Predicting lab values for gastroin-
testinal bleeding patients in the in-
tensive care unit: A comparative
study on the impact of comorbidi-
ties and medications
Mahani, Golnar K and Pa-
joohan, Mohammad-Reza
2019 2 No Yes
Medicine Recommendation System
For Diabetes Using Prior Medical
Knowledge
Wedagu, Mulubrhan Ay-
alew and Chen, Dehua and
Hussain, Muhammad Ather
Iqbal and Gebremeskel,
Tsegay and Orlando,
Mayugi Tanguy and Man-
zoor, Arslan
2020 0 Yes No
Adaptive neuro-fuzzy inference
system (ANFIS) for rapid diagnosis
of COVID-19 cases based on
routine blood tests
Deif, Mohanad and Ham-
mam, Rania and Solyman,
Ahmed
2021 9 No Yes
Diabetes Prediction Recommender
System based on Artificial Neu-
ral Networks and Sine-Cosine Op-
timization Algorithm
Faraji-Biregani, Maryam
and Nematbakhsh, Nasser
2019 1 Yes No
Liver Disease Prediction Using Ma-
chine Learning Algorithms
Kalaiselvi, R and Meena, K
and Vanitha, V
2021 1 No Yes
Prediction of Diabetes and Cluster-
ing Based on its Levels using Fuzzy
C Means Algorithm
S. Jamuna, K. Mohan Ku-
mar
2020 1 Yes Yes
Figure 3: Word cloud assembled from the six selected arti-
cles (Source: Elaborated by the author).
sented a study that aims to classify patients accord-
ing to three levels of diabetes: non-diabetic, pre-
diabetic or diabetic. For this, it makes use of the
Fuzzy C−Means algorithm. The information used by
the algorithm comes from blood tests of patients. Like
the last two works, this study was also considered one
of the three that best answered the research questions,
since it answers all the items of research question 2,
since it is based on blood test data, uses fuzzy tech-
niques, performing the classification of patients ac-
cording to the level of diabetes.
Finally, we highlight the fact that the questions
that were best answered are related to the prediction
and classification methodologies used in the health
area. In summary, it can be concluded that of the 6 se-
lected articles: 4 of them answered research question
1, 5 papers answered question 2, 1 answered question
3 and 2 answered question 4.
5 CONCLUSION
Methodologies based on machine learning are in-
creasingly being used to solve problems associated
with healthcare. Diabetes is a disease that needs spe-
cial care because it is a silent disease, making many
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
482

individuals not even know they have such a disease.
Considering the problems mentioned above, the
objective of this work is to identify forecasting and
classification methodologies, mainly involving fuzzy
logic, used to help the health area.
To this end, a systematic review was carried out
with the objective of finding prediction and classifica-
tion methods for diabetes or even for other diseases,
but that could help in understanding the state of the
art, that is, that could facilitate the understanding of
which techniques, currently, are being used to predict
or classify health problems.
In order to carry out the systematic review, inclu-
sion and exclusion criteria were considered so that the
works found could be filtered and, at the end, those
that best met the pre-established conditions could be
studied.
Thus, at the end of the work, it was possible to
observe that techniques using fuzzy logic, such as:
Fuzzy C−Means, ANFIS and Takagi-Sugeno zero or-
der fuzzy modeling are being used and from that it
can be observed which is the best way to contribute
in the area proposing techniques that can improve
the quality/perfomance/explainability/interpretability
of the existing related methods.
The next step, therefore, consists of implementing
a fuzzy methodology for predicting diabetes based on
blood test variables and also on information provided
by the patients themselves, such as: sleep, physical
activity and diet.
ACKNOWLEDGEMENTS
This work is supported by the Academic Master’s
and Doctorate Program for Innovation of the National
Council for Scientific and Technological Develop-
ment CNPq.
Public Notice FAPERGS/CNPq 07/2022 - Pro-
gram to Support the Settlement of Young Doctors in
Brazil
REFERENCES
Bergquist, S. L., Brooks, G. A., Keating, N. L., Landrum,
M. B., and Rose, S. (2017). Classifying lung can-
cer severity with ensemble machine learning in health
care claims data. In Machine Learning for Healthcare
Conference, pages 25–38. PMLR.
Bonaccorso, G. (2017). Machine learning algorithms.
Packt Publishing Ltd.
Cordeiro, A. M., Oliveira, G. M. d., Renter
´
ıa, J. M., and
Guimar
˜
aes, C. A. (2007). Revis
˜
ao sistem
´
atica: uma
revis
˜
ao narrativa. Revista do Col
´
egio Brasileiro de
Cirurgi
˜
oes, 34:428–431.
Deif, M., Hammam, R., and Solyman, A. (2021). Adaptive
neuro-fuzzy inference system (anfis) for rapid diagno-
sis of covid-19 cases based on routine blood tests. Int.
J. Intell. Eng. Syst, 14(2):178–189.
Dos Santos, H. G., do Nascimento, C. F., Izbicki, R.,
de Oliveira Duarte, Y. A., and Chiavegatto Filho, A.
D. P. (2019). Machine learning for predictive analy-
ses in health: an example of an application to predict
death in the elderly in s
˜
ao paulo, brazil. Cadernos de
saude publica, 35(7):e00050818.
Ercole, F. F., Melo, L. S. d., and Alcoforado, C. L. G. C.
(2014). Revis
˜
ao integrativa versus revis
˜
ao sistem
´
atica.
Revista Mineira de Enfermagem, 18(1):9–12.
Faraji-Biregani, M. and Nematbakhsh, N. (2019). Dia-
betes prediction recommender system based on artifi-
cial neural networks and sine-cosine optimization al-
gorithm. In 2019 5th Conference on Knowledge Based
Engineering and Innovation (KBEI), pages 263–268.
IEEE.
Goldar, S. Z., Ghiasi, A. R., Badamchizadeh, M. A., et al.
(2020). An anfis-pso algorithm for predicting four
grades of non-alcoholic fatty liver disease. In 2020
International Congress on Human-Computer Interac-
tion, Optimization and Robotic Applications (HORA),
pages 1–5. IEEE.
Grillo, M. d. F. F. and Gorini, M. I. P. C. (2007).
Caracterizac¸
˜
ao de pessoas com diabetes mellitus tipo
2. Revista Brasileira de Enfermagem, 60:49–54.
Jamuna, S. and Mohan Kumar, K. (2020). Prediction of
diabetes and clustering based on its levels using fuzzy
c means algorithm. International Journal of Scientific
and Technology Research, 9(2):3222–3225.
Keele, S. et al. (2007). Guidelines for performing system-
atic literature reviews in software engineering. Tech-
nical report, Technical report, ver. 2.3 ebse technical
report. ebse.
Lyra, R., Oliveira, M., Lins, D., and Cavalcanti, N.
(2006). Prevenc¸
˜
ao do diabetes mellitus tipo 2. Ar-
quivos Brasileiros de Endocrinologia & Metabologia,
50:239–249.
Saleck, M. M., ElMoutaouakkil, A., and Mouc¸ouf, M.
(2017). Tumor detection in mammography images us-
ing fuzzy c-means and glcm texture features. In 2017
14th International Conference on Computer Graph-
ics, Imaging and Visualization, pages 122–125.
Wedagu, M. A., Chen, D., Hussain, M. A. I., Gebremeskel,
T., Orlando, M. T., and Manzoor, A. (2020). Medicine
recommendation system for diabetes using prior med-
ical knowledge. In Proceedings of the 2020 4th In-
ternational Conference on Vision, Image and Signal
Processing, pages 1–5.
Zadeh, L. A., Klir, G. J., and Yuan, B. (1996). Fuzzy sets,
fuzzy logic, and fuzzy systems: selected papers, vol-
ume 6. World Scientific.
Fuzzy Logic for Diabetes Predictions: A Literature Review
483
