Towards Synthesis of Code for Calculations Using Their Specifications
Advaita Datar, Amey Zare, Venkatesh R and Asia A
TCS Research, Tata Research Development and Design Centre (TRDDC), Pune, India
Keywords:
Program Synthesis, Programming by Examples, Formal Specifications.
Abstract:
Banking, Financial Services, and Insurance (BFSI) software are calculation intensive. In general, these cal-
culations are formally specified in spreadsheets, known as Calculation Specification (CS) sheets. CS sheets
describe the calculation inputs and the business logic applied on these inputs to compute calculation output(s).
Additionally, an illustration of the calculation is provided with at least one valid value for each calculation in-
put. However, manual implementation of code corresponding to such CS sheets remains to be effort-intensive
and tedious. This includes writing database queries to retrieve values for calculation inputs from the enterprise
database and converting these queries and corresponding business logic to code. We propose a novel idea to
synthesize code corresponding to CS sheets that will i) automatically identify the calculation inputs ii) formu-
late a Programming By Example (PBE) specification for each calculation input where, PBE input is the textual
description of the calculation input, PBE output is the valid value provided in the calculation’s illustration, iii)
then for each PBE specification a) synthesize a set of possible database queries, b) manually review them and
mark the intended query, and finally iv) generate code, in desired target language, for all intended queries and
the business logic specified in CS sheets.
1 INTRODUCTION
Program synthesis is the task of automatically find-
ing a program, in the underlying programming lan-
guage, that satisfies the user intent expressed in the
form of specifications (Gulwani et al., 2017). Var-
ious formats for expressing user intent include, but
are not limited to, formal logical specifications, in-
formal natural language descriptions and illustrative
input-output examples. Writing formal specifications
is a tedious and time-consuming task, and in some
cases, it may be as complex as writing the program it-
self. On the other hand, informal specifications are of-
ten criticized for being ambiguous and verbose, even
for simple programs. As an alternative, illustrative
input-output examples, in the form of Programming
By Example (PBE) specifications (Gulwani, 2016),
are used to express user intent. While PBE specifi-
cations work well for string transformation examples
(Gulwani, 2011), they aren’t suitable for real-world
applications. This is because it is extremely diffi-
cult to specify all the requirements of such large and
complex applications using a limited number of input-
output examples. Moreover, sometimes only a subset
of the requirements of such applications need to be
implemented as the code for business rules for such
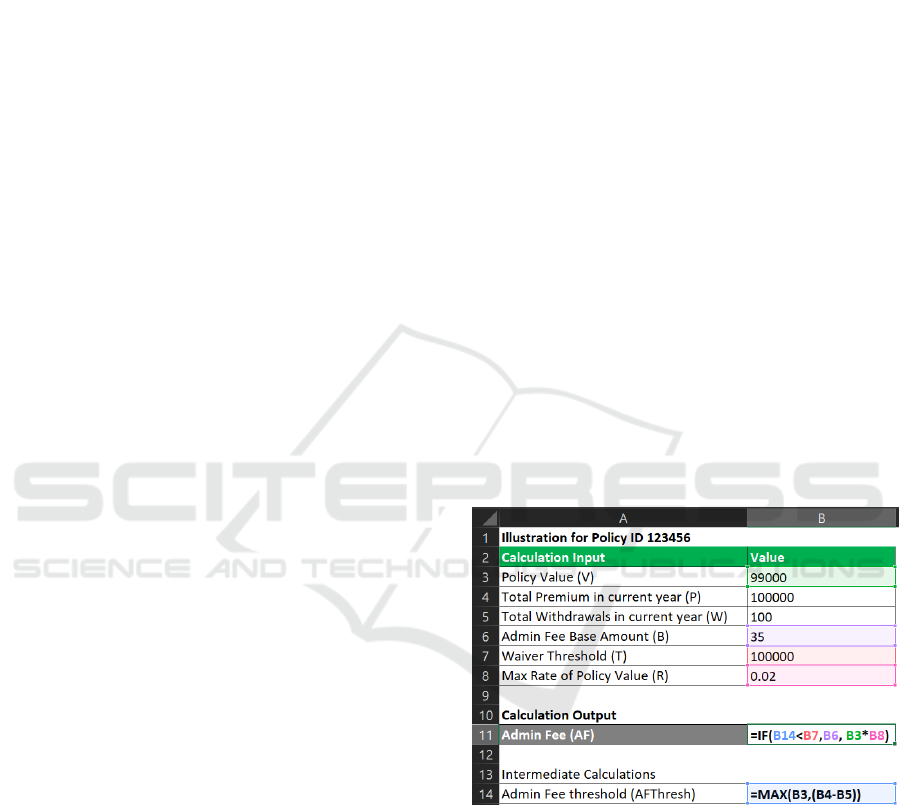
Figure 1: A sample Calculation Specifications (CS) sheet.
applications is already in place. Hence, accurately
expressing and interpreting user intent in the form of
specifications continues to be a major challenge for
program synthesis approaches.
Large enterprise applications, especially in the
Banking Financial Services and Insurance (BFSI) in-
dustry, rely heavily on calculations for day-to-day
operations. BFSI software, the largest market for
Information Technology (IT) services (Arc, 2022),
contains numerous types and instances of such cal-
culations. These calculations represent the business
Datar, A., Zare, A., R, V. and A, A.
Towards Synthesis of Code for Calculations Using Their Specifications.
DOI: 10.5220/0011940900003464
In Proceedings of the 18th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2023), pages 497-504
ISBN: 978-989-758-647-7; ISSN: 2184-4895
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
497
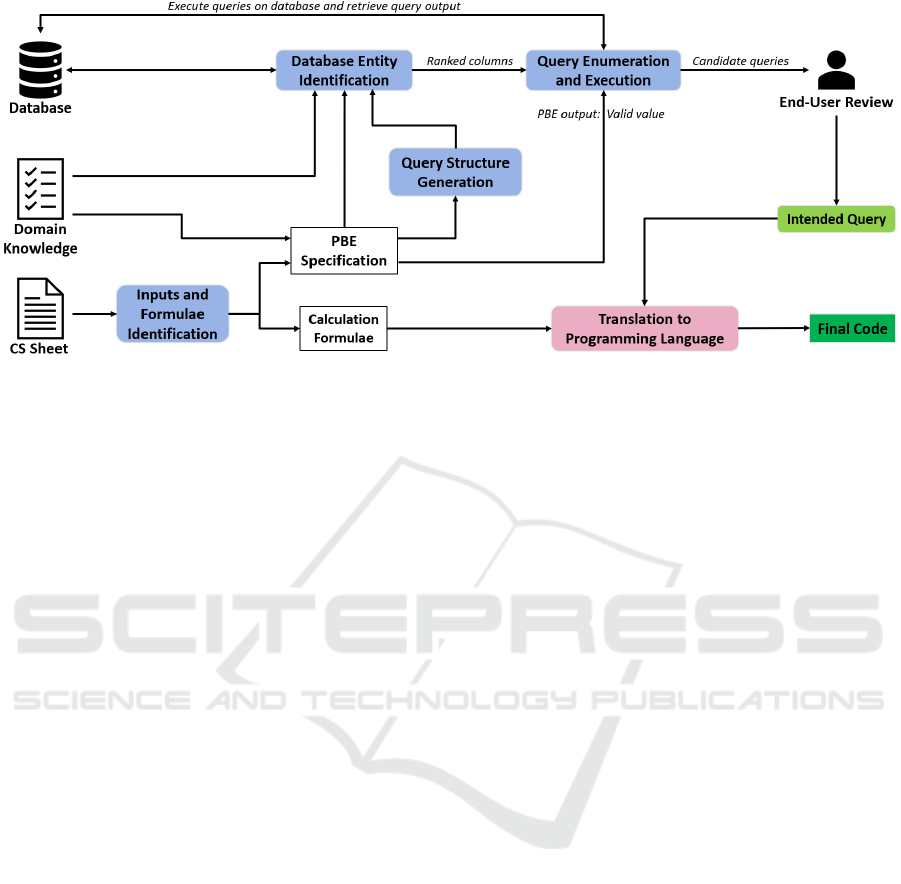
Figure 2: Overview of the proposed approach for code generation from Calculation Specifications (CS) sheet.
rules that are adhered to by BFSI organizations, and
they are developed by domain experts following rigor-
ous review. Such calculations are typically specified
in spreadsheets, known as Calculation Specification
(CS) sheets. Figure 1 shows a CS sheet from insur-
ance domain that specifies the calculation for com-
puting admin fee for a policy holder who may have
exceeded the limit for premium payments in a year.
As evident from the sample CS sheet, calculations
are formally specified in terms of calculation inputs
(cells A3-A8) and the business rules for computing
the value of calculation output Admin Fee (cell A11)
using the values of calculation inputs (cells B3-B8).
The business rules (cells B11, B14) are implemented
by domain experts in the form of mathematical and
logical formulae. For ease of understanding, an il-
lustration of the calculation is provided that contains
at least one valid value for each calculation input.
For example, the given CS sheet (Figure 1) illustrates
how the admin fee is calculated for policy ID 123456
by considering the valid values (cell B3-B8) for each
calculation input. Here, valid values are the output
of queries corresponding to the calculation input text
(A3-A11) for the policy ID 123456. As soon as val-
ues for calculation inputs (cells B3-B8) are entered in
the CS sheet, all formulae (cell B11, B14) are trig-
gered and the respective calculation output is com-
puted (cell B11).
In real-world scenarios from the BFSI domain,
manually implementing code corresponding to given
calculation specifications, such as CS sheets, is an
effort-intensive and tedious task, because:
• To trigger/execute such calculations in code, val-
ues of calculation inputs (cells B3-B8 in Figure 1)
need to be retrieved from the enterprise database.
This requires inferring database queries that incor-
porate the table relationships (primary/foreign keys
for joining tables) in the database schema. Real-
world enterprise databases contain hundreds of ta-
bles that are part of complicated database schema
and hence creating the intended query manually is
extremely difficult.
• These intended queries need to be written in a pa-
rameterized way to ensure data for multiple poli-
cies/users can be retrieved on demand.
• The business rules (cell B11, B14 in Figure 1),
referred henceforth as ‘business formulae’, in the
BFSI domain are complex and may contain long
sequence of mathematical and logical expressions
that refer to multiple calculation inputs. Hence, in
real-world scenarios, it is very difficult to manu-
ally translate such business formulae into the de-
sired programming language.
Incorporating all these factors while writing the
code manually is a challenge. Hence, there is a clear
need for automating code generation for such calcula-
tions as per their formal specifications i.e., CS sheets.
In this paper, we propose an idea to synthesize the
code corresponding to the calculation specifications
in CS sheets. Figure 2 shows the overview of the ap-
proach implementing our proposed idea. We believe
CS sheets are the perfect combination of text and busi-
ness formulae, and hence CS sheets offer a novel and
simple means of specifying user intent for synthesiz-
ing code for calculations. Unlike ambiguous natural
language specifications, the contents of CS sheets are
precise and machine-interpretable. Additionally, the
illustration of the underlying calculations, provided
along-with CS sheets, contains a valid value for each
calculation input. These valid values play a key role
in our proposed approach that is described as follows.
As a first step of our approach, we plan to parse
the input CS sheet to automatically identify all cells
ENASE 2023 - 18th International Conference on Evaluation of Novel Approaches to Software Engineering
498

containing calculation inputs and business formulae
(more details in Section 2.1). Next, we plan to for-
mulate a custom PBE specification for each calcula-
tion input. The PBE input will contain all available
textual information corresponding to the calculation
input and the PBE output will be its valid value men-
tioned in the illustration. We refer to PBE specifica-
tion as PBE spec henceforth.
As a next step, the PBE spec will be used to syn-
thesize database queries corresponding to each calcu-
lation input. Firstly, we will guess the query structure
and database entities needed in the various clauses
(SELECT, WHERE, etc.) of the intended query. This
will be done by applying Natural Language Process-
ing (NLP) techniques on the formulated PBE input.
Next, the guessed query structure and entities will be
traversed, as per the grammar and algorithm shown in
Section 2.3.3, to enumerate all possible queries and
these queries will then be executed on the underly-
ing database. The queries that return same value as
PBE output will then be presented for the end-user
review for marking the intended query. Once the in-
tended queries for all calculation inputs are synthe-
sized, these queries, along-with the specified busi-
ness formulae, will be translated to the programming
language desired by the end-user. Initially, we plan
to generate the final code in Python using available
open-source code translation tools (Richter, 2022;
C.W., 2022). However, our approach can be easily
extended to generate code in other programming lan-
guages through corresponding state-of-the-art code
translation techniques.
The key contributions of our paper are:
• A user-friendly format for specifying calculations
i.e. CS sheets.
• An end-to-end approach for synthesis of code cor-
responding to CS sheets.
• A novel PBE-based query synthesis technique.
2 PROPOSED APPROACH
Figure 2 shows the overview of our proposed ap-
proach. The key steps of the same are explained as
follows, using the example CS sheet in Figure 1.
2.1 Identification of Calculation Inputs
and Business Formulae
As a first step, we identify all calculation inputs and
business formulae by parsing the input CS sheet. For
this, the contents of all non-empty cells will be read
to identify referred cells. These are the cells that are
Figure 3: Cell References Graph (CRG) for the example CS
sheet shown in Figure 1.
used or referred in at least one other cell in the CS
sheet. For example, in Figure 1 cell B14 has a for-
mula, “=MAX(B3,(B4-B5))”, and hence B3, B4 and
B5 will be identified as referred cells for B14. The re-
lationship between a cell and it’s referred cell(s) will
be maintained in the form of a directed graph, termed
as Cell References Graph (CRG). Figure 3 shows the
CRG for the example CS sheet (Figure 1). In CRG,
each cell with references to other cells (e.g. B14 in
Figure 1) will be tagged as ‘destination node’ and an
edge will be drawn from each of it’s referred cells
(B3, B4, B5 in Figure 1) by tagging them as ‘source
nodes’. Once all non-empty cells are parsed, the fol-
lowing three artifacts will be identified though CRG:
• Cells that are never tagged as a ‘destination node’
but are tagged as a ‘source node’ at least once will
be marked as input cells. (Example: cells B3-B8 in
Figure 1)
• Each cell immediately to the left of each input cell
will be tagged as calculation input. (Example: cells
A3-A8 in Figure 1)
• All non-empty cells, apart from input cells, that are
part of CRG will be marked as business formulae
cells. (Example: cells B11-B14 in Figure 1)
2.2 Formulation of Programming by
Example (PBE) Specification
As a next step, a PBE spec will be formulated for each
identified calculation input. We formally define PBE
spec as:
Input Text [Supporting Information]
{Domain Keywords} = Value, where
• Input Text contains the name of the calculation in-
put. In the example CS sheet (Figure 1), contents of
calculation input cells A3 to A8 i.e. Policy value,
Total premium in current year etc. will be consid-
ered as Input Text for respective PBE spec.
• [Supporting Information] captures additional in-
formation, apart from the Input Text, that can be
Towards Synthesis of Code for Calculations Using Their Specifications
499

used in synthesizing queries for calculation inputs.
In the BFSI domain, this typically includes infor-
mation that is unique to each illustration, such as
policy ID, customer ID, etc. In the example CS
sheet (Figure 1), the illustrated values for all cal-
culation inputs are taken from the policy 123456.
Hence, Policy ID = 123456 will be considered as
Supporting Information in the PBE spec of each
calculation input.
• {Domain Keywords} is an optional field of PBE
spec that contains all domain-specific information
that denotes the context and/or the calculation type
in which the calculation input is being used. These
keywords are included in order to assist query syn-
thesis by narrowing down the search for relevant
database entities that are needed in query clauses.
The example CS sheet (Figure 1) belongs to insur-
ance domain and the calculation name, i.e. Admin
Fee, will be considered as Domain Keywords in the
PBE spec of each calculation input.
• Value contains the valid value(s) of the calculation
input that is(are) provided in the illustration. It is
determined by extracting the contents inside input
cells that are identified in Section 2.1. In the ex-
ample CS sheet (Figure 1), the input cells are B3
to B8 and hence, their contents i.e. 99000, 90000
etc. will be considered as Value for PBE spec for-
mulation. Please note that we use valid value i.e.
Value and PBE output interchangeably throughout
the paper.
Using the formal definition described above, the
PBE spec for each calculation input in the example
CS sheet (Figure 1) will be as follows.
1. Policy value [Policy ID = 123456] {Admin Fee} =
99000
2. Total premium in current year [Policy ID =
123456] {Admin Fee} = 90000
...................
Formulation of such a PBE spec from calculation
specifications (CS sheet) and using it to synthesize
queries is one of the novel contributions of our ap-
proach. To the best of our knowledge, none of the ex-
isting techniques create such a specification for syn-
thesis and/or make use of valid values i.e. PBE output
to synthesize the query.
2.3 Query Synthesis Based on PBE Spec
Once the PBE spec is formulated, a query synthe-
sis apparatus will be used to synthesize the desired
database query. The approach for the same is de-
scribed as follows.
Figure 4: Phrases and relationships for ‘Total premium in
current year’ from the CS sheet in Figure 1.
2.3.1 Generation of Query Structure
The structure of the desired query can be guessed
by parsing the Input Text using standard natural lan-
guage parser. Figure 4 shows the parsed phrases
and their relationships, identified through CoreNLP
parser(Manning et al., 2014), for Total premium in
current year. The query structure for this calculation
input will be constructed by a rule-based apparatus
on the basis of identified phrases and their relation-
ships. This will be accomplished by mapping related
phrases to respective query clauses using natural lan-
guage semantics, as explained below.
In Total premium in current year, the subject noun
is premium and hence it is considered in SELECT
clause. As per natural language semantics, the sub-
ject noun’s adjectival modifier is Total which indi-
cates addition or cumulative sum, and hence the SE-
LECT clause of the desired query should be updated
to include aggregate function i.e. SUM(premium).
Next, the main noun’s nominal modifier current year
(linked via preposition in) will be considered in
WHERE clause as it indicates the scope or condi-
tion of the desired query. As per natural language
semantics, the phrase current year is a named-entity
and intuitively indicates the ongoing year i.e. 2023,
and hence the WHERE clause should contain year =
2023. However, date-related information is generally
mentioned in columns with date data type, and hence
the phrase current year can also relate to a date on
or between 1-Jan-2023 and 31-Dec-2023. Therefore,
the WHERE clause will also contain 1-Jan-2023 <=
date <= 31-Dec-2023, leading to two query struc-
tures. Lastly, the Supporting Information in PBE spec
i.e., Policy ID = 123456 becomes part of the WHERE
clause by default as the given illustration contains val-
ues from policy ID 123456. Hence, based on the
aforementioned information for the calculation input
Total premium in current year, the identified query
structures are shown in Table 1.
2.3.2 Identification of Database Entities Needed
in the Query
Once the query structure is ready, the database en-
tities i.e., table and column names corresponding to
each query clause need to be identified. As shown
in Table 1, every query clause will contain either text
ENASE 2023 - 18th International Conference on Evaluation of Novel Approaches to Software Engineering
500

Figure 5: Database details corresponding to the example CS sheet in Figure 1.
Table 1: Query structures for ‘Total premium in current
year’ from the CS sheet in Figure 1.
Stru- Clause LHS Oper- RHS
cture Aggr- Variable ator Aggr- Variable
ID egate egate
1
SELECT SUM premium
WHERE 1 Policy ID = 123456
WHERE 2 Date >= 1-Jan-2023
WHERE 3 Date <= 31-Dec-2023
2
SELECT SUM premium
WHERE 1 Policy ID = 123456
WHERE 2 year = 2023
or a text-operator-value triplet. To infer the intended
column(s) for the query clause text, we will compare
it with all table and column names, and their descrip-
tion provided in the database schema. The identified
columns will then be assigned a text matching score
by using standard text matching utilities (Foundation,
2022) to quantify how similar these columns are to
the query clause text. In case a query clause also con-
tains a value and operator, a clause predicate will be
created.
For example, the clause predicate for clause
WHERE 2 belonging to query structure ID 2 in Table
1 will be ‘year = 2023’. Columns that contain at least
one value mentioned in such a clause predicate will
be considered as candidate columns for the respective
query clause. All such candidate columns will then be
given a representative value matching score, and later
they will be sorted based on their combined value
and text matching scores to get a ranked list of can-
didate columns. Table 2 shows the ranked list of can-
didate columns, as per database schema in Figure 5,
for the PBE spec shown in Table 1. We have observed
that the accuracy of identifying database columns im-
proves if value matching is done along with conven-
tional text matching.
Apart from the Input Text, the Domain Keywords
Table 2: Ranked columns for the query structures of ‘Total
premium in current year’ from the CS sheet in Figure 1.
Clause Rank Table Column Value Text
Score Score
SUM 1 POLICY PREM AMT 0 20
(premium) 2 PREM RECEIPT PREM 0 15
PAID DT
... ... ... ... ...
Policy ID 1 POLICY POLICY ID 25 25
= 123456 DETAILS
2 POLICY POLICY ID 25 20
PREM RECEIPT
... ... ... ... ...
included in PBE spec also play a vital role in
the identification of database entities for query
clauses. We explain this through the example of
the calculation input ‘Max Rate of Policy Value’
(cell A8 in Figure 1) for the database schema
in Figure 5. The SELECT clause for this cal-
culation input, as per the described query struc-
ture generation approach (refer Step 2.3.1), will
be ‘MAX(Rate)’. As a result, the columns ‘FI-
NAL RATE’ from PRODUCT DETAILS, ‘RATE’
from PROD ADMIN FEE, and ‘MAX RATE’ from
PROD SERVICE CHARGE DIM will get signifi-
cantly higher text matching score due to the sub-string
‘rate’ in their name. Assuming that all three columns
contain the value ’0.02’ or ‘2%’, the column ‘RATE’
from PROD ADMIN FEE will be ranked highest as
it’s table name is very similar to the provided Do-
main Keywords ‘Admin Fee’.
2.3.3 Query Enumeration and Execution
To generate possible queries, all identified informa-
tion i.e., ranked columns, query clauses and query
structures, will be traversed as per the algorithm de-
scribed in Algorithm 1. Firstly, high-scoring tables
will be identified by considering the sum of text and
Towards Synthesis of Code for Calculations Using Their Specifications
501

Algorithm 1: Generation of Candidate Queries.
Inputs: Database (DB), list of query structures
(Structs), ordered list of ranked columns (RC),
expected query output (Value).
Output: Ordered list of candidate queries
(CandQueries).
1: procedure GENCANDQUERIES(RC,Value)
2: CandQueries ← [..]
3: RT ← getRankedTables(RC)
4: for s ∈ Structs do
5: for i ← 1..MaxJoins do
6: // MaxJoins will be configurable
7: SelTabs ← P(RT [0..i − 1])
8: // P(A) indicates power set of set A
9: for {t} ∈ SelTabs do
10: q ← queryInSyntax(s, {t}, RC)
11: result ← executeQuery(q, DB)
12: if result == Value then
13: Add q to CandQueries
14: end if
15: end for
16: end for
17: end for
18: return CandQueries
19: end procedure
20: procedure GETRANKEDTABLES(RankedCols)
21: TabMap ← {..}
22: for c ∈ RankedCols do
23: tab ← table o f c
24: score ← text + value matching score o f c
25: TabMap[tab] ← TabMap[tab] + score
26: end for
27: sorted ← sort(TabMap, TabMap.values())
28: return sorted.keys()
29: end procedure
value matching scores (computed in Step 2.3.2) of
ranked columns from each table. Next, queries will
be enumerated as per the grammar shown in Figure
6. As evident from this grammar, we plan to focus
on the key constructs without loss of generality, and
hence we restrict our query synthesis approach to con-
sider only a subset of query language constructs. To
form a query through enumeration, ranked columns
will be picked, as per the order of aforementioned
high-scoring tables, and inserted in identified query
clauses as per the desired query language syntax. For
explanation purpose we have used SQL as the desired
query language (Figure 6), but our idea can easily be
extended to work for other query languages by simply
using corresponding grammar for query enumeration.
Once an enumerated query is ready, it will be ex-
ecuted on the input database and the value returned
Figure 6: Grammar used for enumeration of queries.
by the query will be compared with the PBE output
identified in Step 2.2. If the values match, the query
will be marked as a candidate query and added to
an ordered list of candidate queries CandQueries (as
shown in Algorithm 1). The order in which the can-
didate queries are added in CandQueries represents
their rank. Once all enumerated queries are executed
on the database, CandQueries will be presented to the
end-user for review and verdict of intended query.
2.3.4 Query Review by the End-User
We aim to provide only a few queries for end-user
review, hence we execute all enumerated queries on
the database to get a reduced set of candidate queries.
In case all enumerated queries are presented to the
end-user, then he/she may prefer spending time man-
ually writing the intended query, instead of reviewing
a large number of queries that may not even result in
the expected query output. Hence, only top N candi-
date queries will be given to the end-user to mark the
intended query. The value of N will be configurable
and will get fine-tuned after the end-user reviews.
There is a possibility that none of the candidate
queries is the end-user’s intended query, or our ap-
proach doesn’t generate even a single candidate query.
In such scenarios, we plan to ask the end-user to cre-
ate the intended query manually and use the query for
online learning (Hoi et al., 2021) to improve our ap-
proach to enable generation of queries for such sce-
narios in the future.
2.4 Translation to Target Programming
Language
Once the database queries are synthesized and final-
ized for all calculation inputs in the CS sheet, the code
ENASE 2023 - 18th International Conference on Evaluation of Novel Approaches to Software Engineering
502

corresponding to these queries and the business for-
mulae (identified in Section 2.1) will be generated in
the programming language desired by the end-user.
In the initial prototype of our approach, we gener-
ate the final code in Python using well-tested openly
available techniques (Richter, 2022; C.W., 2022).
These techniques automatically identify the partici-
pating formulae in the input CS sheet and convert
them into Python. Using these techniques, the final
code for the input CS sheet in Figure 1, as per the
CRG in Figure 3, will be as shown below:
import os, sys
# Function synthesized for Total premium in
current year
def getTotalPremium(policyID):
cursor = database.cursor()
cursor.execute("SELECT SUM(PREM_AMT)
FROM POLICY_PREM_RECEIPT WHERE ...")
result = cursor.fetchall()
return result
# Functions for V, W, B, T, R will be
synthesized similar to getTotalPremium
# Function synthesized for Admin Fee
def getAdminFee(policyID):
V = getPolicyValue(policyID)
P = getTotalPremium(policyID)
W = getTotalWithdrawals(policyID)
AFThresh = MAX(V,(P-W))
B = getAdminFeeBase(policyID)
T = getWaiverThreshold(policyID)
R = getMaxRatePolicyValue(policyID)
AF = B if AFThresh < T else V * R
return AF
The constructed CRG (Figure 3) plays a vital role
in generation of final code. The example CS sheet
(Figure 1) contains two business formulae in cells
B11, B14, but as evident in the CRG, the formula in
cell B14 needs to be executed before the formula in
cell B11. This sequential dependency in business for-
mulae is maintained by the directed edge from cell
B14 to B11 in CRG, and hence the code for the for-
mula in cell B14 appears before the same for cell B11.
3 RELATED WORK
The key challenge for program synthesis is the di-
versity of user intent and the inability to express the
intent precisely. Natural language descriptions (Li
and Jagadish, 2014; Desai et al., 2016) are the most
common way of stating user intent, but they are am-
biguous and result in incorrect programs. Specifying
user intent through input-output examples (Gulwani,
2016) works for a certain class of string manipulation
programs, but it hasn’t been used effectively in query
synthesis paradigm. State-of-the-art query synthesis
techniques either require the user to provide partial
queries (Bastani et al., 2019) or create large input-
output tables (Wang et al., 2017; Takenouchi et al.,
2020). Creating such complicated artifacts is as com-
plex and effort-intensive as writing the query manu-
ally. To address these drawbacks, we have proposed
a novel concise and precise way of specifying user
intent in the form of Calculation Specification (CS)
sheets. A CS sheet represents the mathematical and
logical relationship between the inputs and outputs
of a program. Furthermore, the end-users, who are
not programming experts, may find providing valid
value(s) of variables participating in the calculations
to be more approachable and natural as compared to
creating complicated input-output tables and partial
queries.
Another challenge for program synthesis is enu-
merating and searching programs in a large and
intractable program space. In query synthesis
paradigm, existing techniques (Desai et al., 2016;
Yaghmazadeh et al., 2017) haven’t overcome this
challenge of program space explosion. A few tech-
niques (Li and Jagadish, 2014; Wang et al., 2017;
Takenouchi et al., 2020) indeed reduce the search
space but require the end-user to provide additional
hints like the selection of aggregate function, con-
stants, etc., which can not be provided by the end-
users who typically don’t have technical knowledge
of query language and syntax. On the contrary, in our
proposed approach we plan to reduce the search space
by filtering the enumerated queries based on expected
query output and other heuristics described in detail
in Section 2.3. Hence, the end-user doesn’t need to
give technical guidance, like the selection of aggre-
gate functions, constants, conditions, etc., for reduc-
ing search space for queries.
4 CONCLUSION AND FUTURE
WORK
In this paper we have presented a novel idea to synthe-
size code corresponding to CS sheets. As described
in the paper, business rules can be easily expressed
in CS sheets through a combination of text and for-
mulae. This makes CS sheet a precise and machine-
interpretable way to specify calculations. We have
also proposed a novel query synthesis approach that
firstly formulates a custom PBE spec for each input
in CS sheet, and later uses text and value inference to
synthesize database query corresponding to each PBE
spec. Lastly, the synthesized database queries and the
business formulae specified in the CS sheet are trans-
Towards Synthesis of Code for Calculations Using Their Specifications
503

lated into the desired programming language.
Going ahead, we plan to improve our approach
by incorporating machine learning to ensure that the
user-intended query is inferred with a high rank. Our
goal is to develop a technique that is self-adaptive and
capable of continuously improving the underlying
steps, such as identifying query structures, database
entities, query enumeration etc., based on feedback
from the end-user.
REFERENCES
Arc, I. (2022). It bfsi market overview.
https://www.industryarc.com/Research/
It-Bfsi-Market-Research-500664. Accessed:
2023-01-26.
Bastani, O., Zhang, X., and Solar-Lezama, A. (2019). Syn-
thesizing queries via interactive sketching. arXiv
preprint arXiv:1912.12659.
C.W. (2022). pyexcel - lets you focus on data, instead of file
formats. https://docs.pyexcel.org/en/latest/. Accessed:
2023-01-26.
Desai, A., Gulwani, S., Hingorani, V., Jain, N., Karkare,
A., Marron, M., and Roy, S. (2016). Program syn-
thesis using natural language. In Proceedings of the
38th International Conference on Software Engineer-
ing, pages 345–356.
Foundation, P. S. (2022). difflib - helpers for computing
deltas. https://docs.python.org/3/library/difflib.html.
Accessed: 2023-01-26.
Gulwani, S. (2011). Automating string processing in
spreadsheets using input-output examples. ACM Sig-
plan Notices, 46(1):317–330.
Gulwani, S. (2016). Programming by examples. Depend-
able Software Systems Engineering, 45(137):3–15.
Gulwani, S., Polozov, O., Singh, R., et al. (2017). Program
synthesis. Foundations and Trends® in Programming
Languages, 4(1-2):1–119.
Hoi, S. C., Sahoo, D., Lu, J., and Zhao, P. (2021). Online
learning: A comprehensive survey. Neurocomputing,
459:249–289.
Li, F. and Jagadish, H. V. (2014). Nalir: an interac-
tive natural language interface for querying relational
databases. In Proceedings of the 2014 ACM SIG-
MOD international conference on Management of
data, pages 709–712.
Manning, C. D., Surdeanu, M., Bauer, J., Finkel, J. R.,
Bethard, S., and McClosky, D. (2014). The stanford
corenlp natural language processing toolkit. In Pro-
ceedings of 52nd annual meeting of the association
for computational linguistics: system demonstrations,
pages 55–60.
Richter, S. (2022). Xlcalculator: Ms excel formulas to
python. https://github.com/bradbase/xlcalculator. Ac-
cessed: 2023-01-26.
Takenouchi, K., Ishio, T., Okada, J., and Sakata, Y. (2020).
Patsql: efficient synthesis of sql queries from exam-
ple tables with quick inference of projected columns.
arXiv preprint arXiv:2010.05807.
Wang, C., Cheung, A., and Bodik, R. (2017). Synthesizing
highly expressive sql queries from input-output exam-
ples. In Proceedings of the 38th ACM SIGPLAN Con-
ference on Programming Language Design and Im-
plementation, pages 452–466.
Yaghmazadeh, N., Wang, Y., Dillig, I., and Dillig, T. (2017).
Sqlizer: query synthesis from natural language. Pro-
ceedings of the ACM on Programming Languages,
1(OOPSLA):1–26.
ENASE 2023 - 18th International Conference on Evaluation of Novel Approaches to Software Engineering
504
