
Algorithm for Selecting Words to Compose Phonological Assessments
Jo
˜
ao V
´
ıctor B. Marques
1 a
, Jo
˜
ao Carlos D. Lima
1 b
, M
´
arcia Keske-Soares
2 c
, Cristiano C. Rocha
3
,
Fabr
´
ıcio Andr
´
e Rubin
4
and Raphael Vieira Miollo
1
1
Centro de Tecnologia, Universidade Federal de Santa Maria, Santa Maria, Brazil
2
Centro de Ci
ˆ
encias da Sa
´
ude, Universidade Federal de Santa Maria, Santa Maria, Brazil
3
Xebia Data, Eindhoven, Netherlands
4
Petroleo Brasileiro S.A., Rio de Janeiro, Brazil
Keywords:
Speech Therapy, Phonological Processes, Graphs and Phonological Assessments.
Abstract:
The phonological assessment is one of the main resources that speech-language therapist has to identify phono-
logical disorders in children. For this, it is necessary to be composed of a words set that have a variety of
phonemes in different positions of the syllable and the word, in order to obtain a representative sample of
the phonological system. Thus, the present work aimed to analyze a set of 84 words from a phonological as-
sessment instrument, with the objective of identifying and removing words with over-represented phonemes.
Aiming to facilitate the phonological evaluation by making it more succinct with the reduction of the number
of words, the present work describes a judicious method organized in three steps, which was implemented in
Javascript and obtained a subset of 55 words, which have at least two occurrences of the same phonemes in
the proper positions in which they appeared in the initial set, representing a 35% reduction in the number of
words without losing quality.
1 INTRODUCTION
A thorough and comprehensive phonological assess-
ment is one of the main tools for the speech therapist
(Savoldi, 2012), as it helps in the identification and
diagnosis of speech disorders. To compose a phono-
logical assessment tool, it is necessary to select words
that represent figures known to children, and that are
inserted in their basic vocabulary and social context
(Gomes et al., 2013).
In southern Brazil, the Child Phonological Assess-
ment (CPA) (Yavas et al., 2001) is one of the evalua-
tions used by speech therapists, and according to the
authors, 125 words were chosen, which represent the
vocabulary of children aged 3 with a balanced sam-
ple of the adult phonological system, and present, at
least, three possibilities of occurrence for each conso-
nant sound, in all possible syllable positions.
In this sense, in order to represent the adult phono-
logical system, it is important that the set of words is
a
https://orcid.org/0009-0007-3206-725X
b
https://orcid.org/0000-0001-9719-3205
c
https://orcid.org/0000-0002-5678-8429
comprehensive in relation to the variety of phonemes
and, also, that they are evaluated more than once
in different syllable and word positions (Pagliarin,
2009). Thus, it is also possible to evaluate and iden-
tify the phonemes present in the child’s phonetic in-
ventory, that is, those that he can reproduce sponta-
neously (Stoel-Gammon, 1985).
The selection of the best words to compose a
phonological assessment has been the subject of stud-
ies such as (Savoldi et al., 2013), where 116 words
were selected from an initial set of 722, after valida-
tion with experts in the field. This number was re-
duced to 84 in the study of (Ceron et al., 2020), when
obtaining a balanced sample of words in an attempt to
avoid the over-representation of one phoneme or the
under-representation of another. However, it is ob-
served that many phonemes in this set still repeat in
the same position, with a frequency greater than the
minimum necessary for a quick and effective assess-
ment.
It was then sought to develop a method to eval-
uate a set of words through their phonetic transcrip-
tions, in order to determine the smallest sub-set that
contains a minimum number of occurrences for each
80
Marques, J., Lima, J., Keske-Soares, M., Rocha, C., Rubin, F. and Miollo, R.
Algorithm for Selecting Words to Compose Phonological Assessments.
DOI: 10.5220/0011990500003467
In Proceedings of the 25th International Conference on Enterprise Information Systems (ICEIS 2023) - Volume 1 , pages 80-88
ISBN: 978-989-758-648-4; ISSN: 2184-4992
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
phoneme in the different positions of the syllable and
the word, respecting the due restrictions that make a
reliable phonological assessment instrument.
The work is organized as follows. In the next sec-
tion, the basic concepts and related works that served
as the basis for this research will be presented. In
Section 3, the logic behind the choice of words that
make up a phonological assessment instrument will
be presented, and then the algorithm will be detailed.
In Section 4, the results obtained by this work will
be presented and discussed. Finally, in Section 5, the
conclusion is presented, and in the appendix all the
words of the initial set are found, and the crossed-out
words signal that these have been removed from the
final set.
2 BACKGROUND AND RELATED
WORK
In this section, some theoretical concepts that underlie
the use of structures such as graphs in this study will
be addressed, as well as concepts from speech therapy
such as Phonological Processes (PPs) and how they
are connected to the present work.
2.1 Important Concepts
The reader will be briefly introduced to some terms
from speech therapy, that are important for under-
standing the present work. In cases of phonologi-
cal disorders, only consonant phonemes are observed
(Shriberg et al., 1997). In addition, they can appear
in different positions in the syllable and word (begin-
ning, middle, and end), and the production of each
phoneme in a pronunciation must necessarily be in
one of these positions seen below.
• (OI) Onset Initial: beginning of syllable, word be-
ginning - ca.sa [house];
• (OM) Onset Medial: beginning of syllable, mid-
dle of the word - ca.va.lo [horse];
• (CM) Coda Medial: end of syllable, middle of the
word - ca.dar.c¸o [shoelace];
• (CF) Coda Final: end of syllable, end of the word
- a.mor [love];
• (OCI) Onset Complex Initial: beginning of sylla-
ble, beginning of word - Bra.sil [Brasil];
• (OCM) Onset Complex Medial: beginning of syl-
lable, middle of the word - bi.blio.te.ca [library].
2.2 Graphs
A graph G = (V, E) is a structure in which V is a
finite and non-empty set of n vertices, and a set E
of m edges, which are pairs of vertices of V. They
are classified according to the nature of the connec-
tion between their vertices, being able to be “undi-
rected” when their weights do not have direction, or
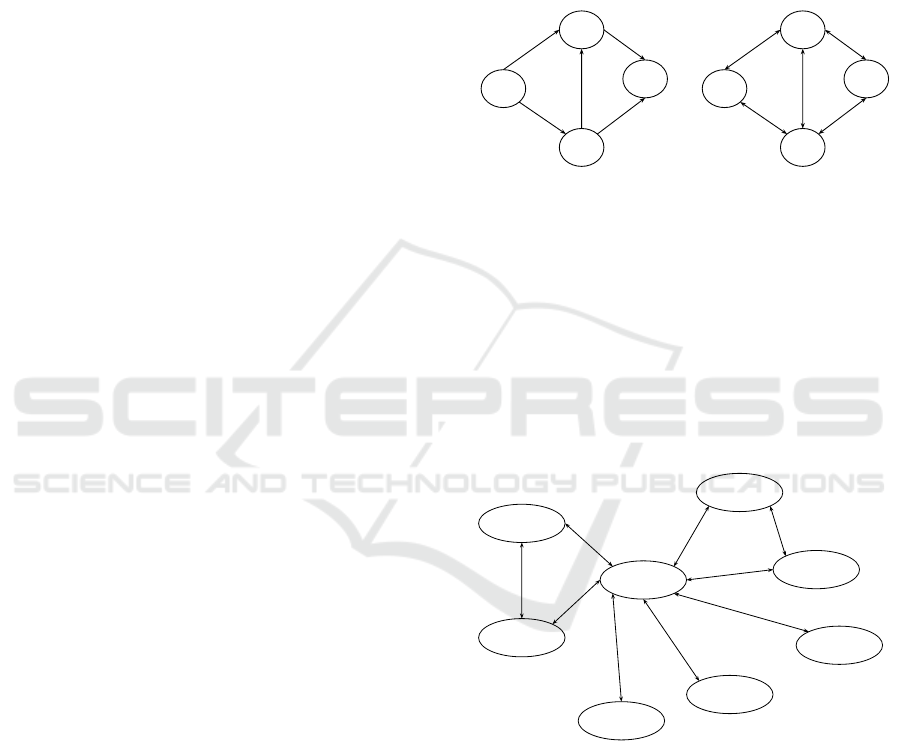
“directed”, as seen in Figure 1.
v1
v4
v3
v2
e1
e5
e3
e2
e4
(a) Directed
v1
v4
v3
v2
e1:E1
e5:E5
e3:E3
e2:E2
e4:E4
(b) Double Directed
Figure 1: Types of Graphs.
In this work, a Double Directed Graph structure
was used, where each edge has, necessarily, two
weights: one for each direction. By analyzing the ex-
ample of Figure 2, we can notice that, given the vertex
p(OI) the edge that connects it to the vertex t(OM) has
different weights depending on the choice of the cen-
tral vertex, highlighting the importance of centrality
in graphs to determine the influence of one vertex on
another.
d(OCM)
p(OI)
ɾ(OCM)
s(CM)
ɾ(CM)
t(OM)
ɾ(OM)
s(OM)
2:4
2:13
4:10
4:6
6:10
4:15
4:3
13:4
4:6
Figure 2: Partial mapping of the entry data.
The weights of each vertex are determined ac-
cording to the number of words in the set in which
a phoneme can occur in a certain position. It is also
worth of notice that words which have more than one
phoneme influence the weight of more than one ver-
tex. Therefore, when removing or adding words to
a vertex, the weights of its edges will be updated as
well.
Algorithm for Selecting Words to Compose Phonological Assessments
81

2.3 Graph Centrality
Introduced by (Bavelas, 1948) while studying the
communication of individuals and influence in small
social groups, the concept of centrality in graphs is as-
sociated with the degree of importance and influence
that each vertex has on another in the graph, and what
bottlenecks may exist in their connections. (Freeman,
1978) also works with the same concepts of central-
ity in social networks, investigating the quantitative
measures capable of defining the importance of each
vertex.
In this context, this work seeks to identify the im-
portance that each phoneme has in the set of analyzed
words, considering possible phonetic transcriptions
where a phoneme can appear in more than one po-
sition of the syllable and the word. In this way, it is
possible to identify the most influential phonemes in
the set, that is, those that are over-represented, and
make them less important by removing some of their
words, making the set more balanced.
Each vertex has a list of words in which a
phoneme occurred in a certain position. With that, it is
possible to identify the importance that each word has
in the vertices, in order to list which could or could not
be removed from the graph without the same ending
with under-represented phonemes.
2.4 Phonological Processes
In the context of speech therapy, phonological pro-
cesses have a great influence on a child’s language
acquisition process. It is expected that during this
stage, she applies several phonological processes,
such as replacing one phoneme with another or omit-
ting them. Such substitutions and omissions are con-
sidered in speech therapy as Phonological Processes
(PP), and some examples are presented in Table 1.
However, if a PP persists for a long time, it can
become a phonological disorder and remain in the
child’s speech, accompanying her in school during
her literacy process, bringing harm to her social life
(Goulart and Chiari, 2014). Therefore, some works
are dedicated to identifying possible phonological
disorders through voice recognition in phonological
evaluations (Franciscatto et al., 2019), so that the di-
agnosis and treatment is given early.
In the work of (Franciscatto et al., 2019), Ma-
chine Learning (ML) techniques were used to classify
the pronunciations of 84 words as correct or incor-
rect and to recognize phonological processes through
them. In (Franciscatto. et al., 2018), a case-based
method, commonly used in the health field and in ML
techniques (Tavana et al., 2022), is developed and is
able to have good learning while allowing new cases
to be stored in a database without complications (Hu-
sain and Pheng, 2010). The method works as an ex-
tra validation layer after the pronunciation classifica-
tion by ML, registering new cases and validating them
with an expert.
However, despite studies using Artificial Intelli-
gence (AI) techniques (Iliya and Neri, 2016) and ML
(Franciscatto et al., 2019) in speech therapy, they are
only used to identify phonological processes and clas-
sify (correct/incorrect) the pronunciation of spoken
words in phonological evaluation. But, before that,
a set of words must be chosen by a specialist to be
pronounced by the children, and such a set must an-
alyze all the phonemes of the language in different
positions of the word. Thus, the choice of words in
the set must follow specific criteria, addressed in Sec-
tion 3.1, because in a phonological evaluation, for ex-
ample, all phonemes must be analyzed at least twice
(Stoel-Gammon, 1985). So, to define the smallest
subset of words that meets the same criteria as the ini-
tial set, it is a matter of quantifying the “least effort”,
discussed in Section 3, rather than learning from er-
rors and successes.
3 DEVELOPMENT
In this section, the operation of the algorithm will be
presented and detailed, from the basic input structures
to the final result.
The set of 84 words from (Ceron et al., 2020) was
used as the database. Additionally, all the words in
the set should be phonetically decomposed in order to
detail in which positions the phonemes that compose
them appear. For this, the JSON structure, developed
in the work of (Marques, 2022), was used, which is
synthesized in Figure 3.
Figure 3: Example of the word “cavalo [horse]” [horse] de-
composed in consonant phonemes.
The main idea of the algorithm is to avoid as much
as possible that the same phoneme is over-represented
in the set of words, being analyzed in the same posi-
tion with a frequency equal to or greater than the min-
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
82

Table 1: Phonological processes in Portuguese acquisition. (Yavas et al., 2001).
Phonological Process (PP) Definition Example
Cluster reduction Reduction of a consonant within the same syllable. bruxa (witch) [br
´
usa]→[b
´
usa]
Final fricative deletion Deletion of phoneme /s/ in both syllable and word final positions l
´
apis (pencil) [l
´
apis]→[
´
api]
Liquid substitution Substitution of one liquid for another. zero (zero) [zeru]→[selu]
Plosivation Substitution of a fricative consonant for a plosive vaca (cow) [vaka]→[baka]
Intervocalic liquid nasalization Substitution of a liquid by a nasal in intervocalic position carro (car) [k
´
aχ u]→[k
´
amu]
imum necessary, avoiding the under-representation as
well.
In order for a phonological assessment to be reli-
able and the obtained set can be used, it is necessary
to follow some rules of speech therapy, which will be
discussed in Section 3.1.
3.1 Phonological Assessment Rules
In order for an assessment to be reliable and compre-
hensive, phonemes need to be analyzed in different
positions of the syllable and word with a defined min-
imum frequency, in order to contain a balanced sam-
ple of the adult phonological system (Savoldi, 2012).
Also, to determine the presence or absence of the
sound in the phonetic inventory, a minimum of two
occurrences of the segment can be considered, re-
gardless of the position in the word (Stoel-Gammon,
1985). Studies such as (Yavas et al., 2001) consider,
for phonological assessment, a minimum of three pos-
sibilities of occurrence for each consonant phoneme
in all possible syllable positions. In this work, a min-
imum of two occurrences of the same phoneme eval-
uated in a certain position was considered, according
with (Stoel-Gammon, 1985). Aiming at the flexibil-
ity of the algorithm for its applicability in different
scenarios from this research, the minimum number of
occurrences is one of the inputs provided by the user.
It should be noted that not all phonemes appear
in all allowed positions, due to a limitation of the
language itself (Savoldi, 2012). In the input data, it
was observed that the phoneme *n always appears in
word productions in the diminutive form in OM and
therefore should not have an impact on the proposed
method, as it would not occur in words in their natural
form.
In short, the method introduced by this work must
follow the criteria:
C.1 The phoneme /η/ evaluated in OM is disregarded
— words in diminutives;
C.2 Each phoneme must continue to occur at least
2 times in the same position after deleting any
word.
Next, in Section 3.2 the first step of the algorithm
will be detailed.
3.2 Phoneme Mapping and Graph
As a first step, the words that have a certain phoneme
in a certain position are counted on a map. The pair
“phoneme (position)” will be the key of each entry in
the map, which will point to a list of words in which
the phoneme appears in the right position. As a result,
a graph structure is obtained, shown in Figure 4.
p(OI)
passarinho [bird]
pastel [pastry]
pedra [rock]
porta [door]
s(OM)
passarinho [bird]
bolsa [handbag]
(+4)
ɾ(OM)
passarinho [bird]
fogo [fire]
(+8)
t(OM)
porta [door]
pastel [pastry]
(+13)
d(OCM)
pedra [rock]
vidro [glass]
ɾ(OCM)
chifre [horn]
pedra [rock]
(+11)
ɾ(CM)
garfo [fork]
jornal [newspaper]
porta [door]
13
2
3
4
6
10
15
s(CM)
plástico [plastic]
pastel [pastry]
(+4)
6
Figure 4: Sample of the graph generated after phoneme
mapping.
The algorithm must receive a set of words bro-
ken down into their consonant phonemes, as shown
in Figure 3. In this study, the abstract set from the
work of (Marques, 2022) was used as input, which
decomposed the 84 words proposed by (Ceron et al.,
2020) into consonant phonemes with the validation of
experts in the field.
From the analysis of Figure 4, we observe that
some phonemes (/t/) occur in the same position in a
greater number of words (15) than the minimum nec-
essary established by criterion C.1. Therefore, since
the phoneme repeats a lot in the set, it is thought
that some words can be excluded from the evaluation,
since they would be generating a super-representation
of the phoneme.
Algorithm for Selecting Words to Compose Phonological Assessments
83

But which ones could be excluded? It is noted
that the phoneme /s/ occurs in Onset Medial (OM)
in 6 words. According to the minimum value of oc-
currences criterion, 4 of these words could be disre-
garded, but it is not that simple. Before removing a
word from the evaluation, it is necessary to remember
that it is composed of other phonemes that are evalu-
ated in different positions. And, if the word that we
are willing to exclude is one of the few that evaluates
some other phoneme in a certain position? All these
issues are considered by the algorithm proposed by
this work.
3.3 Word Analysis
As a second step, through the graph shown in Fig-
ure 4, we will analyze each node and the words con-
tained in it. As we visit each node, we can remove
words, as long as the graph remains valid according
to the criteria established in Section 3.1.
Given a node of the graph, we need to determine
if the phoneme is over-represented in a certain posi-
tion or not. As an example, we will work with the
node highlighted in Figure 4, where the phoneme /p/
appears in OI in 4 different words. Thus, it can be
said that this pair is over-represented, since it occurs
in more words than the minimum necessary.
Now, we need to check if it is possible to remove
any of the words, without compromising the final set
with under-represented phonemes. We do this by an-
alyzing each word of the visited node separately, as
shown in Figure 5.
p(OI)
passarinho [bird]
pastel [pastry]
pedra [rock]
porta [door]
s(OM)
ɾ(OM)
t(OM)
d(OCM)
ɾ(OCM)
ɾ(CM)
13
2
3
4
6
10
15
s(CM)
6
Weight of the Edges
of Each Word
s(OM) 6
ɾ(OM) 10
s(CM) 6
t(OM) 15
d(OCM) 2
ɾ(OCM) 13
ɾ(CM) 3
t(OM) 15
Importance
Ordering the Words
according to their Weights
2 pedra [rock]
3 porta [door]
6 passarinho [bird]
6 pastel [pastry]
10 passarinho [bird]
13 pedra [rock]
15 pastel [pastry]
15 porta [door]
passarinho
[bird]
pastel
[pastry]
pedra
[rock]
porta
[door]
Figure 5: Analysis and ordering of each word of the visited
node.
The calculation of the weights of each word is
done through the counting of the weight of each node
in the remaining graph in which it appears. In Fig-
ure 4, the word “passarinho [bird]” appears in the
nodes “s(OM)” and “l(OM)”, which have weights
of 6 and 10, respectively. With the ordering of the
weights, we can evaluate the importance of each word
in that node, and it would be enough to keep the
first two and exclude the others, while still keeping
the graph valid. However, when removing words,
it is important to be careful not to exclude any that
have a weight lower than the established minimum,
as we will impact other nodes, and these may become
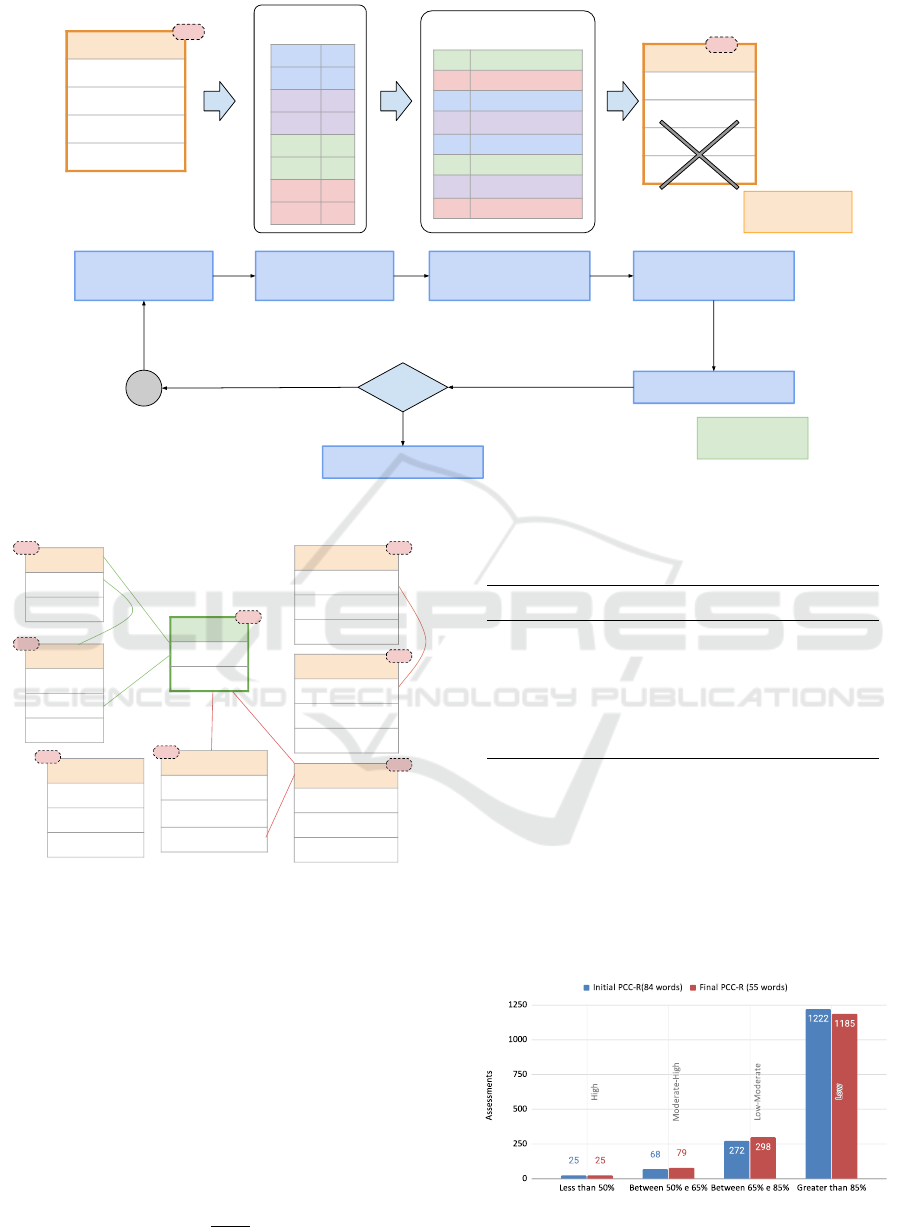
under-represented. Figure 6 shows the steps followed
so far, with the removal of words and subsequent up-
dating of the graph, finishing the first cycle of the al-
gorithm.
To better visualize the impact that the first cycle of
exclusion had on the graph, we can check in Figure 7
the updated weight of each node after the removal of
words.
However, the algorithm does not have a rule for
choosing the next node to be visited, being chosen
by order of insertion into the graph’s data structure.
In each visited node, words can be removed and the
graph must be updated, making the algorithm possi-
bly reproduce different results depending on the or-
dering of the graph.
4 RESULTS AND VALIDATION
All the stages of the algorithm described in Section 3
were implemented in the Javascript language. As in-
put for the method, a set of correct phonetic transcrip-
tions in JSON of the 84 words proposed by (Ceron
et al., 2020) was used. After all the data in the set
were analyzed by the algorithm, a reduction of 29
words was obtained, resulting in a subset of 55 words,
which satisfies the criteria established in Section 3.1.
However, to validate how the reduction of words
proposed by this work would behave in a real sce-
nario, data from 1611 phonological evaluations ap-
plied to 1357 children from April/2013 to Jan-
uary/2017 were analyzed. Some evaluations were in-
complete in the database used, so that some words
were not spoken in certain evaluations. For this rea-
son, it was decided to consider only evaluations with
42 or more words spoken by the children, which rep-
resent half of the initial set of words, resulting finally
in 1587 evaluations as a base for validation.
The PCC-R index (Percent of Consonants
Correct-Revised), developed by (Shriberg et al.,
1997), was used as a metric to validate the new
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
84
Choose Node
not Visited
Weights of the
Words in Node
Ordering the Words
by their Weights
Reorganize the Node
according with weights
Remove most
repeated words
p(OI)
passarinho [bird]
pastel [pastry]
pedra [rock]
porta [door]
4
Weight of the Edges of
Each Word
s(OM) 6
ɾ(OM) 10
s(CM) 6
t(OM) 15
d(OCM) 2
ɾ(OCM) 13
ɾ(CM) 3
t(OM) 15
Ordering the Words
according to their Weights
2 pedra [rock]
3 porta [door]
6 passarinho [bird]
6 pastel [pastry]
10 passarinho [bird]
13 pedra [rock]
15 pastel [pastry]
15 porta [door]
p(OI)
pedra [rock]
porta [door]
passarinho [bird]
pastel [pastry]
4
Update graph
End
Have all nodes been visited?
No
Yes
Set the current
node as Visited
Figure 6: Flowchart of the analysis of each phoneme represented in the graph.
p(OI)
pedra [rock]
porta [door]
s(OM)
travesseiro [pillow]
bolsa [handbag]
(+3)
ɾ(OM)
travesseiro [pillow]
fogo [fire]
(+7)
t(OM)
porta [door]
batom [lipstick]
(+12)
d(OCM)
pedra [rock]
vidro [glass]
ɾ(OCM)
chifre [horn]
pedra [rock]
(+11)
ɾ(CM)
garfo [fork]
jornal [newspaper]
porta [door]
13
2
3
4
5
9
14
s(CM)
plástico [plastic]
floresta [forest]
(+3)
5
Figure 7: Graph sample after removing two words from the
visited node.
dataset. This index is also used as a basis for recom-
mending therapeutic activities in the system proposed
by (Franciscatto et al., 2021). The PCC-R value is
calculated using Equation 1, based on the number of
correct consonants (CC) produced by the child and
the total expected productions (TEP). This allows us
to determine the severity of the phonological disor-
der, as shown in Table 2. Additionally, it is directly
related to the presence of phonological processes in
the child’s speech, as found in the study by (Ghisleni
et al., 2010).
PCC-R =
CC
T EP
× 100 (1)
Table 2: Indication of speech disorder according with PCC-
R value (Shriberg et al., 1997).
PCC-R Value Indication of Disorder
Less than 50% High
Between 51% e 65% Moderate-High
Between 66% e 85% Low-Moderate
Greater than 85% Low
Thus, the PCC-R of each assessment was calcu-
lated by first considering all 84 words of the initial
set. Then, another PCC-R was calculated in the same
way, but this time considering only the 55 words of
the new proposed set. The goal was to determine if
the degree of disorder associated with the first PCC-R
remained in the second case. The result of this calcu-
lation can be seen in the graph of Figure 8.
Figure 8: Comparative of PCC-R Classifications.
Algorithm for Selecting Words to Compose Phonological Assessments
85
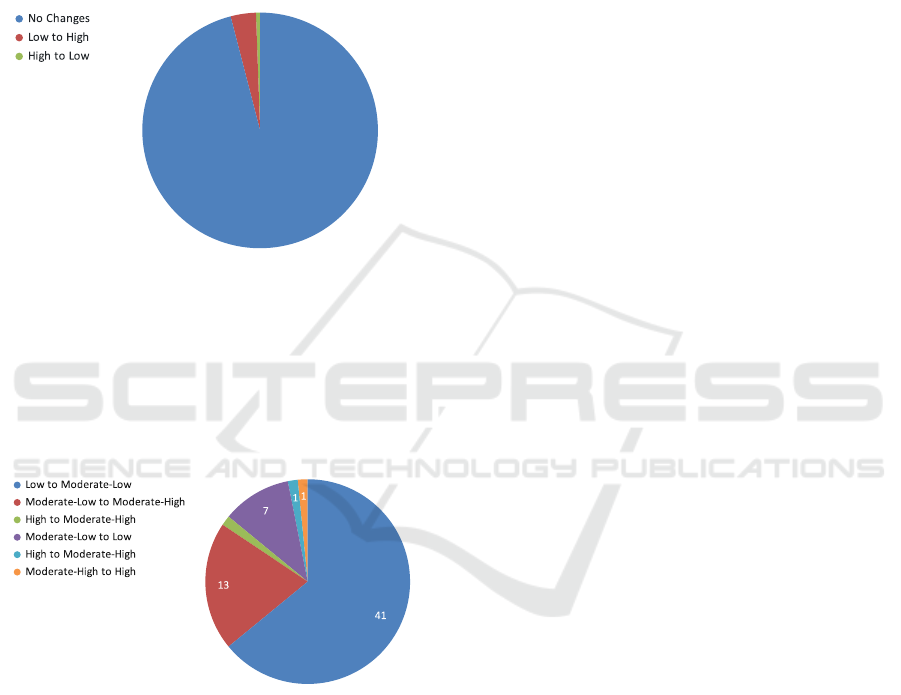
However, in order to identify if there were changes
in the disorder classification of an assessment when
only the 55 words of the proposed subset were con-
sidered, the two PCC-R results in each assessment
were compared, and each change was calculated. Af-
ter that, we arrived at the graph shown in Figure 9,
where it is possible to identify that 96% of the as-
sessments had no change in the Degree of Disorder
associated with the PCC-R when the new subset was
considered.
96,0%
Figure 9: Changes in Indication of Speech Disorder when
only the 55 selected words were considered.
Nevertheless, 64 evaluations, which represent 4%
of the evaluations analysed, had changes in the clas-
sification of the Degree of Disorder. Such changes
are mapped in the graph of Figure 10, in which it is
possible to identify that the changes are mainly con-
centrated in lower degrees.
Figure 10: Changes in Classification of 64 assessments.
5 CONCLUSION
This work aimed to perform a computational analy-
sis of the 84 words proposed by the work of (Ceron
et al., 2020) to compose a phonological assessment
tool. The analysis focused on identifying words that
generate a super-representation of their phonemes in
the set and to perform a critical removal of them. To
do this, it was necessary to establish rules for the val-
idation of removals, in order to not generate under-
represented phonemes in the set.
The method was described in stages in Section 3,
and the algorithm was implemented in Javascript and
validated with the use of real data in Section 4. The al-
gorithm was efficient in reducing the number of words
used by speech therapists in phonological evaluations
of children, also representing a reduction in the spent
time applying the evaluations. In addition, the reduc-
tion of the words did not bring negative impacts to the
quality of the evaluation, since the algorithm was im-
plemented following pre-established criteria in Sec-
tion 3.1. The validation was done using the PCC-R
value of (Shriberg et al., 1997), which indicates the
degree of phonological disorder based on the number
of correct consonants produced in the evaluation.
The set proposed by (Ceron et al., 2020) was used
as input for the algorithm, and at the end of the anal-
ysis of the 84 initial words, it was identified that 55
of them would already be sufficient to analyze the
same phonemes in the same positions that the ini-
tial set evaluated, with at least 2 occurrences for each
phoneme in each position, representing a reduction of
35% in the set size. Therefore, this work proposes
a method that can be followed manually or imple-
mented in any programming language to analyze the
words that compose a phonological assessment tool,
with the aim of making it more succinct without los-
ing quality.
REFERENCES
Bavelas, A. (1948). A mathematical model of group struc-
tures. Human Organization, 7:16–30.
Ceron, M. I., Gubiani, M. B., Oliveira, C. R. d., and Keske-
Soares, M. (2020). Phonological assessment instru-
ment (infono): A pilot study. CoDAS, 32(4).
Franciscatto, M. H., Del Fabro, M. D., Damasceno Lima,
J. C., Trois, C., Moro, A., Maran, V., and Keske-
Soares, M. (2021). Towards a speech therapy support
system based on phonological processes early detec-
tion. Computer Speech & Language, 65:101130.
Franciscatto, M. H., Lima, J. a. C. D., Trois, C., Maran,
V., Soares, M. K., and Rocha, C. C. d. (2019). Ap-
plying situation-awareness for recommending phono-
logical processes in the children’s speech. SAC ’19,
page 739–746, New York, NY, USA. Association for
Computing Machinery.
Franciscatto., M. H., Lima., J. C. D., Moro., A., Maran.,
V., Augustin., I., Keske Soares., M., and Cortez da
Rocha., C. (2018). A case-based system architecture
based on situation-awareness for speech therapy. In
Proceedings of the 20th International Conference on
Enterprise Information Systems - Volume 1: ICEIS,,
pages 461–468. INSTICC, SciTePress.
Freeman, L. C. (1978). Centrality in social networks con-
ceptual clarification. Social Networks, 1(3):215–239.
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
86

Ghisleni, M. R. L., Keske-Soares, M., and Mezzomo, C. L.
(2010). The use of repair strategies considering the
severity of the evolutional phonological disorder. Re-
vista CEFAC: Atualizac¸
˜
ao Cient
´
ıfica em Fonoaudiolo-
gia e Educac¸
˜
ao, 12(5):766–771.
Gomes, A. M., Feltin, T. D., Savoldi, A., and Keske-Soares,
M. (2013). Phonological assessments: analysis of the
most frequent words considering the vocabulary and
sound class. Dist
´
urbios da Comunicac¸
˜
ao, 25(1).
Goulart, B. N. G. d. and Chiari, B. M. (2014). Speech
disorders and grade retention in elementary. Revista
CEFAC: Atualizac¸
˜
ao Cient
´
ıfica em Fonoaudiologia e
Educac¸
˜
ao, 16(3).
Husain, W. and Pheng, L. T. (2010). The development of
personalized wellness therapy recommender system
using hybrid case-based reasoning. In 2010 2nd In-
ternational Conference on Computer Technology and
Development, pages 85–89.
Iliya, S. and Neri, F. (2016). Towards artificial speech
therapy: A neural system for impaired speech seg-
mentation. International Journal of Neural Systems,
26(06):1650023. PMID: 27354188.
Marques, J. V. B. (2022). M
´
odulo de an
´
alise contrastiva
para avaliac¸
˜
oes fonol
´
ogicas de e-fono.
Pagliarin, K. C. (2009). A abordagem contrastiva na ter-
apia fonol
´
ogica em diferentes gravidades do desvio
fonol
´
ogico. Mestrado em dist
´
urbios da comunicac¸
˜
ao
humana, Universidade Federal de Santa Maria, Santa
Maria.
Savoldi, A. (2012). Instrumento de avaliac¸
˜
ao fonol
´
ogica:
validac¸
˜
ao de conte
´
udo. Mestrado em dist
´
urbios da
comunicac¸
˜
ao humana, Universidade Federal de Santa
Maria, Santa Maria.
Savoldi, A., Ceron, M. I., and Keske-Soares, M. (2013).
What are the best words to compose an evaluation
phonological instrument? Audiology-Communication
Research, 18(3):194–202.
Shriberg, L. D. et al. (1997). The speech disorders classi-
fication system (sdcs). Journal of Speech, Language
and Hearing Research, 40(4):723–740.
Stoel-Gammon, C. (1985). Phonetic inventories, 15-24
months: a longitudinal study. Journal of Speech and
Hearing Research, 28:505–512.
Tavana, M., Nazari-Shirkouhi, S., Mashayekhi, A., and
Mousakhani, S. (2022). An integrated data mining
framework for organizational resilience assessment
and quality management optimization in trauma cen-
ters. SN Operations Research Forum, 3:17.
Yavas, M., Hernandorena, C., and Lamprecht, R. (2001).
Avaliac¸
˜
ao fonol
´
ogica da crianc¸a: reeducac¸
˜
ao e ter-
apia. Biblioteca Artmed. Fonoaudiologia. Artmed Ed-
itora.
Algorithm for Selecting Words to Compose Phonological Assessments
87

APPENDIX
Table 3: Phonemes and words in which it occurs in a certain position in the initial set. Scratched words are not in the new set.
ICEIS 2023 - 25th International Conference on Enterprise Information Systems
88
