
Rigor in Applied Data Science Research Based on DSR:
A Literature Review
Daniel Szafarski
a
, Tobias Schmieg
b
, Laslo Welz
c
and Thomas Sch
¨
affer
d
Institute of Information Systems, University of Applied Sciences Heilbronn,
Max-Planck-Str. 39, 74081 Heilbronn, Germany
Keywords:
Design Science Research, Data Science, Rigor, Concept Matrix, Literature Review.
Abstract:
Design Science Research (DSR) enjoys increasing popularity in the field of information systems due to its
practical relevance and focus on design. A study from 2012 shows that DSR publications in general have a
weak rigor in connection with the selection and use of research methods. At the same time, there has also
been a recent increase in Data Science publications based on the paradigm of DSR. Therefore, this study
analyzes the rigor and the specific characteristics of the application of DSR based on 62 publications from
this field. Major deficits are observed in a large part of the sample regarding the rigorous documentation of
the scientific process as well as the selection and citation of adequate research methods. Overall 77.4% of
the analyzed publications were therefore characterized as weak in regard to their rigor. One explanation is the
novel combination of DSR and Data Science together with the speed at which new findings are obtained and
published.
1 INTRODUCTION
As a result of the digital transformation, Data Science
has developed into a trending topic that has recently
become important and is discussed in both, theory
and practice (Jordan and Mitchell, 2015). Due to the
increasing volume of available data and the easy ap-
plicability of machine learning algorithms in various
areas, this technology is key to the digital transfor-
mation of a company. This leads to major productiv-
ity increases through automation (Goes, 2014; Abbasi
et al., 2016). Moreover, researchers emphasize the fo-
cus on IT artifacts and their analysis, which is partic-
ularly relevant for business and society (Benbasat and
Zmud, 2003; Saar-Tsechansky, 2015; Abdel-Karim
et al., 2021).
Considering the research focus of information sys-
tems in the field of Data Science Research, it is not
surprising that numerous publications in this context
select Design Science Research (DSR) as their re-
search paradigm. DSR has become an established re-
search paradigm in the field of information systems in
a
https://orcid.org/0009-0008-8992-5152
b
https://orcid.org/0009-0006-9735-0788
c
https://orcid.org/0009-0006-6061-1921
d
https://orcid.org/0000-0001-8097-286X
general and gained in popularity (Alturki et al., 2012).
A major cornerstone for this development was laid by
the authors Hevner et al. (2004), in which they po-
sition DSR as an alternative to traditional behavioral
science research (Samuel-Ojo et al., 2010; Gregor and
Hevner, 2013; Pascal and Renaud, 2020). The nu-
merous parallels to Data Science research lead Saar-
Tsechansky (2015) to conclude that the guidelines de-
fined by Hevner et al. (2004) for conducting DSR re-
search also apply to publications in the field of Data
Science Research. However, due to the novelty of
DSR in the field of Data Science Research and the in-
terdisciplinary nature of this research area, there are
potential ambiguities in adapting the guidelines de-
fined by Hevner et al. (2004). For instance, the guide-
lines refer to practical relevance. Further, Elragal and
Klischewski (2017) argue that Data Science publi-
cations often lack such practical relevance. Instead
of relevant problems usually use cases with a large
number of existing datasets are preferred. The rigor-
ousness of these Big Data datasets is questioned by
researchers as well, due to the unclear rigorous col-
lection of data as well as unknown hypotheses be-
hind (Elragal and Klischewski, 2017). In addition,
Big Data creates new needs in terms of evaluating ar-
tifacts and demonstrating knowledge gain and prob-
lem solving (Elragal and Haddara, 2019).
126
Szafarski, D., Schmieg, T., Welz, L. and SchÃd’ffer, T.
Rigor in Applied Data Science Research Based on DSR: A Literature Review.
DOI: 10.5220/0012122300003541
In Proceedings of the 12th International Conference on Data Science, Technology and Applications (DATA 2023), pages 126-135
ISBN: 978-989-758-664-4; ISSN: 2184-285X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

Consequently, it is important to pay attention
to both the practical applicability and the scientific
grounding of the Data Science publications. Even be-
fore the multitude of ambiguities presented in con-
nection with Data Science, Arnott and Pervan (2012)
identified in a study that two-thirds of the publica-
tions show weak rigor in connection with the selec-
tion and use of research methods. It is currently un-
known whether, and if so, how, Data Science publi-
cations rigorously apply DSR to meet the demands of
a scientific community and the guidelines of Hevner
et al. (2004). Therefore, the following research ques-
tion (RQ) arises:
RQ: How is the rigor of DSR addressed in Data
Science research?
The aim of this literature review is to analyze Data
Science publications from the past three years claim-
ing the DSR approach and examining their rigor.
To achieve the objective, the following chapter
lays the necessary theoretical foundations. Building
upon this, the methodology as well as the selection
criteria for the research data will be explained in more
detail. Subsequently, the data will be analyzed on the
basis of the previously defined schema in order to de-
rive statements about the rigor. The findings of this
research are summarized in a respective overview at
the end of this research work. In the end, after a short
summary of the results, the limitations and implica-
tions of this paper are pointed out.
2 THEORETICAL BACKGROUND
In this chapter, the terms ”Data Science Research”,
”DSR” and ”Rigor” are explicitly presented and ex-
plained to provide an overview of the theoretical foun-
dation of this paper.
2.1 Data Science Research
Data Science is an established interdisciplinary field
that combines scientific methods, systems, and pro-
cesses from statistics, information science, and com-
puter science to gain insight into phenomena about
structured or unstructured data (Zhu and Xiong,
2015). According to van der Aalst (2016), Data Sci-
ence is used to assign business value to data. Ethical,
social, and legal aspects also play a role when consid-
ering the resulting insights (van der Aalst, 2016).
Nowadays, several process models can help re-
searchers to execute data science projects (Baijens
et al., 2020). Well-known reference models are the
CRoss Industry Standard Process for Data Mining
(CRISP-DM) as well as the Knowledge Discovery
in Databases (KDD). Based on them, several addi-
tional process models emerged over time (Mart
´
ınez-
Plumed et al., 2021). Taking CRISP-DM as an ex-
ample the typical process activities are arranged se-
quentially and consist of six different phases that can
optionally be iterated several times. These are (1)
Business Understanding, (2) Data Understanding, (3)
Data Preparation, (4) Modeling, (5) Evaluation, and
(6) Deployment (Chapman et al., 2000).
2.2 Design Science Research (DSR)
A well-known methodological framework in informa-
tion science that brings both practice and theory to
the solution approach is DSR (Hevner et al., 2004).
DSR is a problem-oriented approach that attempts
to gain a profound understanding of how novel so-
lutions, called artifacts, can be designed in the field
of information science. An artifact reflects the re-
search object under consideration and can be repre-
sented as a construct, model, method, or instantiation.
The knowledge from the generated artifacts can be
used for future research or for practical implementa-
tion (Hevner et al., 2004). Knowledge about the de-
sign problem can be generated through constructing
and applying artifacts. In principle, the DSR frame-
work according to Hevner (2007) is presented as a
DSR cycle model with three different research cycles.
These are the relevance cycle, rigor cycle and design
cycle.
The cycles shown can also be abstracted as a se-
quential process that represents a single iteration stage
after each run. Peffers et al. (2006) divided the De-
sign Science Research Process Model into six distinct
phases: problem identification, objective of solution,
design and development, demonstration, evaluation,
and communication. This process model also allows
iterating by going back to previous phases or starting
at different entry points (Peffers et al., 2006). Over
time several additional process models or advance-
ments of the presented models are made (Gregor and
Jones, 2007; Vaishnavi and Kuechler, 2004; Sonnen-
berg and Brocke, 2012).
2.3 Rigor
Primarily due to its practical orientation, the DSR
approach has been repeatedly criticized since its es-
tablishment for not meeting the demands of rigorous
research (Kuechler and Vaishnavi, 2011). ”In both
design-science and behavioral-science research, rigor
is derived from the effective use of the knowledge
base - theoretical foundations and research method-
Rigor in Applied Data Science Research Based on DSR: A Literature Review
127

ologies”.(p. 88) (Hevner et al., 2004) Thus, Hevner
et al. (2004) set up seven guidelines ((1) design as an
artifact, (2) problem relevance, (3) design evaluation,
(4) research contribution, (5) research rigor, (6) de-
sign as a search process, and (7) communication of re-
search) for constructing and applying artifacts. These
guidelines are based on the fundamental principle that
DSR is a problem-solving process. Within Hevner
(2007) DSR cycle model, rigor is ensured in the form
of a separate cycle. According to Peffers et al. (2007),
rigor must be ensured in both development and evalu-
ation. This can be ensured through the thoughtful se-
lection and application of existing research methods
and reference models (Hevner et al., 2004).
While Arnott and Pervan (2012) subdivided rigor
into the theoretical foundation and the selection and
use of appropriate research methods. This paper fo-
cuses mainly on applied research methods. The rea-
son for this focus is that the original study (Arnott
and Pervan, 2012) already identified a high level of
theoretical rigor but a low level of rigor in relation to
research methods. Several publications present possi-
ble methods that are well suited for DSR (Sonnenberg
and Brocke, 2012; Peffers et al., 2012).
3 METHODOLOGY
Fig. 1 illustrates our research approach. In the first
step, we conducted a literature review to identify rel-
evant publications. For this, we followed the guide-
lines of vom Brocke et al. (2009) to meet the require-
ments for rigor in this work. Initially, the criteria for
the selection of suitable literature are determined. The
selection first focused on the three literature databases
IEEE, ScienceDirect, and SpringerLink. Using the
keyword search, relevant publications were searched
with the following search string. “Data Science”
AND (“Design Science*” OR “DSR”).
Applying this, 82 publications are identified and
examined for duplicates. Their suitability in terms of
content is assessed on the basis of the abstracts and
the respective methodological sections. Here, a publi-
cation is only classified as suitable if it actively states
that it proceeds according to DSR. In addition, data
science has to play at least a thematic role. Accord-
ingly, the number of relevant publications is reduced
to a final number of 62, which are subsequently ana-
lyzed in depth.
The second step is to analyze the characteristics
of publications. Therefore, qualitative content anal-
ysis according to Mayring (2000) is used. The pub-
lications are systematically analyzed on the basis of
previously developed coding guidelines. Through an
inductive category development process, two new di-
mensions are identified. These are extended by two
further dimensions that are deductively derived
1. The use of research process models. Both in the
area of DSR and Data Science. In the context of
the analysis, only those sources were taken into
account where the authors state that they follow a
DSR approach.
2. The role of Data Science in the publications. Here
it is inductively identified on the basis of the liter-
ature examined that Data Science
(a) appears as an enabler and is only considered
from a meta-perspective. No implementation or
detailed explanation of Data Science concepts
follows.
(b) appears as an demonstrator within the frame-
work. For example, as a prototype in the
demonstration while the actual main artifact is
a framework.
(c) appears as an artifact itself and is thus the main
component of the publication. Here, for exam-
ple, a prediction model is developed for a prob-
lem and its performance is subsequently vali-
dated.
3. The type of artifact developed according to the
classification of Hevner et al. (2004).
4. The research methods used or cited are classified
according to Sonnenberg and Brocke (2012).
If such a concept is identified in a publication, this
is indicated by an X in the concept matrix. A finer
distinction is made for the research methods in order
to assess the rigor of Data Science Research as men-
tioned in section 2.3. If the use of a research method is
only mentioned, a blank circle is filled in. If a suitable
publication is referenced and justified, a full circle is
used as a symbol instead.
In the third step, an assessment based on the pub-
lication by Arnott and Pervan (2012) is made. For
this purpose, the classification is broken down into
the areas Weak, Adequate, and Strong. As the orig-
inal paper did not provide a comprehensive definition
of the assessment categories, the following guidelines
are made for the purpose of this paper.
• Weak: The rigor of a publication is classified
as Weak if it (1) does not mention any research
methods (2) mentions research methods but does
not give any references and justifications for the
choice of methods or (3) appropriately references
and justifies less than 50 % of the chosen research
methods.
• Adequate: The rigor of a publication is classi-
fied as Adequate if (1) it uses at least one research
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
128
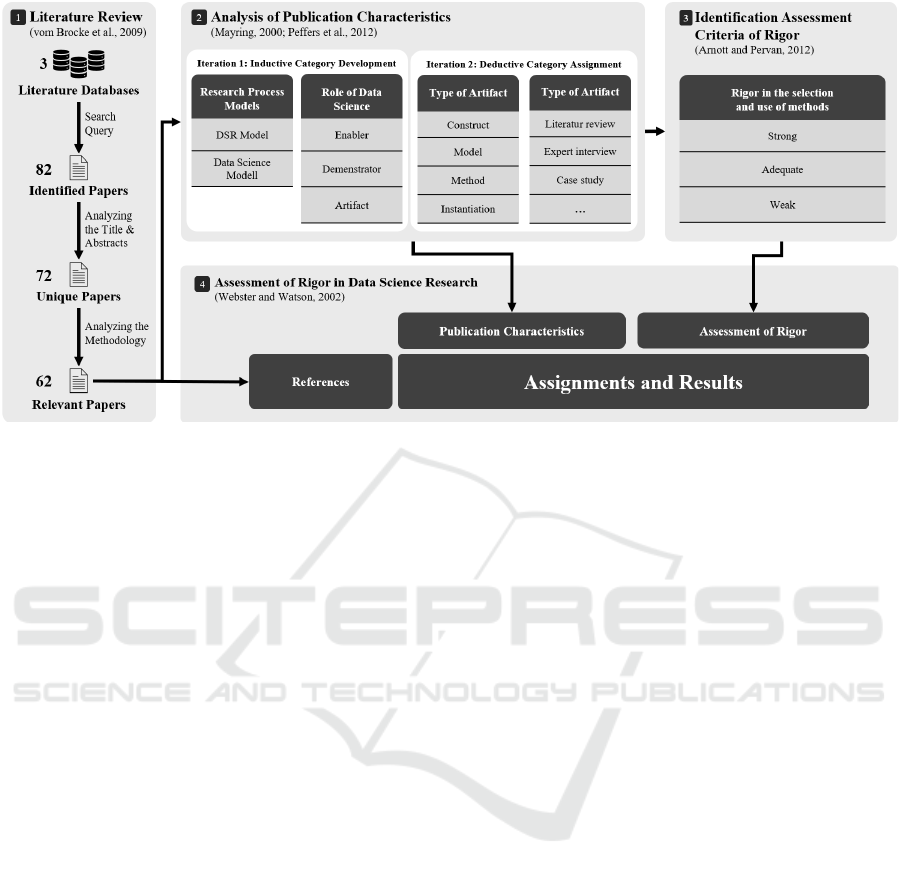
Figure 1: Overview of the Research Approach.
method and (2) justifies and supports the choice
of research methods with appropriate references
in 50 % or more of the cases.
• Strong: The rigor of a publication is classified
as Strong if it justifies and references each chosen
research method, in contrast to Adequate.
According to Peffers et al. (2012), a four- or multi-
eye principle is applied. In this way, an appropriate
and consistent assessment is attempted. In a fourth
step, the identified dimensions are presented in a con-
cept matrix according to the approach of Webster and
Watson (2002), based on the presented assessment
rules. The findings can be derived from the matrix
and will be presented in the following chapter.
4 FINDINGS
The rigor assessment of the 62 publications accord-
ing to the procedure already described yields differ-
ent findings. These are mapped in the concept matrix
below and then subsequently explained. For this pur-
pose, this section is subdivided according to dimen-
sions in the concept matrix.
4.1 Assessment
Looking at the assessment of the entire sample of this
study, three (4.8 %) publications are in the category
strong, eleven publications (17.7 %) are adequate and
48 (77.4 %) are weak. According to the study con-
ducted by Arnott and Pervan (2012) about 10 years
ago, 3.3 % were Strong, 22.1 % were Adequate, and
74.6 % were Weak. Thus, it can be seen that within
this sample the ratio of publications seems to remain
the same. In the context of data science publications,
therefore, the weak rigor with regard to the selec-
tion, justification, and citation of appropriate research
methods continues to be clearly evident.
4.2 Research Methods
During the analysis numerous research methods could
be identified. A detailed overview of all methods as
well as which publications use specific methods can
be found in the concept matrix 1. Upon closer exam-
ination of the research methods used, the most com-
mon one is literature analysis followed by expert in-
terviews. Although they are used in 33 and 24 cases
respectively, the concrete application is seldom ex-
plained and supported by research method references.
A distinct portion of the sample did not mention
any applied research method in the context of DSR.
In eight cases, it was not possible to observe any re-
search method. Consequently, these cases completely
omit the mention of adequate research methods. They
limit themselves to the naming of DSR in general. In
addition to this, eight further cases only mentioned
a single research method for their research approach.
In both of those cases, this automatically resulted in
classification as weak.
There are publications that merely mention the use
of research methods without referencing them. This
applies to 41 cases (66.1 %) after classification. This
percentage does not allow for a general conclusion
on the mention of methods since publications in this
group also mention using more than four methods.
Rigor in Applied Data Science Research Based on DSR: A Literature Review
129

Table 1: Overview of Publication Characteristics and Assessment Results.
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
130

Nevertheless, according to the rules of rigor defined
before, all these publications are rated as weak. The
delta of these cases to all weak cases is represented by
publications that make references in less than half of
the cases.
4.3 IT-Artifact and Role of Data Science
A dedicated examination of rigor considering the
Data Science role within this publication did not re-
veal any relation. The same applies to the differenti-
ation per artifact type. However, independent of the
research question, the distribution of the individual
classes is nevertheless interesting.
4.4 Process Model
Since the sample was selected based on the use of
DSR, it is not surprising that each publication men-
tions a process model. A corresponding reference is
always given as well. Overall, a variety of sources
is used. Sometimes publications referenced several
sources for the used methodology. However, when
considering data science process models, only three
models mention CRISP-DM. In this sample other
Data Science process models are not applied. The ex-
tended concept matrix showing all process models is
available from the authors upon request.
5 DISCUSSION
The study reveals significant weaknesses in connec-
tion with the selection and citation of suitable re-
search methods. As a result, over 77 % of publica-
tions are rated as weak in regard to the rigorous se-
lection and application of research methods. When
publications lack rigor, it can lead to results that are
not replicable by other researchers, unreliable, or even
incorrect. This can lead to incorrect conclusions be-
ing drawn which can have implications for further re-
search and practice. Although each publication spec-
ifies a DSR methodology and provides evidence of
it through widely used references, this still does not
infer a fundamental rigor in the approach. Peffers
et al. (2007), indicated by 29 publications (46.7 %),
also confirmed that the citation of research methods
contributes to better understanding, increased validity
and generalizability of the results. A possible expla-
nation might be that the researchers work conscien-
tiously and structured in the background, but do not
document it in the paper. Moreover, researchers may
be unaware of the actual use of the research methods
(e.g. experiment, survey, case study) and the need to
explicitly validate the results from them.
Furthermore, it can be seen in the concept matrix
that only in three cases name a Data Science process
model. The referenced CRISP-DM, which is popular
in knowledge and practice, has fundamental similar-
ities to DSR. Both approaches focus on the develop-
ment and validation of solutions to practical problems
using similar phases and methods. This could be a
reason for the low number of Data Science process
models while the number of DSR models is high.
Especially in publications in which the role of
Data Science is a demonstrator or artifact, metrics
such as accuracy are often used. One explanation for
the omission of specific justifications and references
could be that for many metrics in the field of Data Sci-
ence no foundation papers are available. Furthermore,
authors could assume that the methods used are gen-
erally known and therefore refrain from citing them.
Moreover, mathematical constructs such as an ac-
curacy score are often used for evaluation in the field
of Data Science. While Sonnenberg and Brocke
(2012) argue that logical reasoning and mathemati-
cal proofs can also be a method for evaluating, this
was not considered as a research method itself in this
work. These metrics usually have a practical origin
and are generally known in the community. Neverthe-
less, a reference to the work that justifies the selection
and describes the metrics is usually omitted. Further-
more, the results still can be considered valid, because
this does not excuse the absence of referencing cho-
sen research methods or the absence of research meth-
ods in other phases of DSR at all. In addition, these
metrics are only used for quantitative evaluations. A
qualitative perspective is therefore completely miss-
ing if no other evaluation method is conducted. For
this reason, the procedure can generally be regarded
as well-suited to answer the research question.
6 CONCLUSION
Based on the findings of Arnott and Pervan (2012),
many publications have a shortcoming in rigorously
describing the selection, application, and justification
of appropriate research methods. This motivates this
study to re-validate these findings after ten years. For
this purpose, the focus lies on the increasingly popu-
lar field of Data Science. Other publications have al-
ready shown that DSR is a suitable methodology for
Data Science publications. According to the search
criteria, 62 publications in the investigated time pe-
riod were based on a DSR approach.
Rigor in Applied Data Science Research Based on DSR: A Literature Review
131

6.1 Summary
This paper examined the rigorous use of research
methods and systematically maps them through a con-
cept matrix 1 to answer the research question. Based
on the research methods mentioned in each case, as
well as on the corresponding references provided, an
assessment of rigor is made. In summary, 77.4 % of
these publications were categorized as weak in terms
of rigor. Consequently, the ratio remains nearly simi-
lar to the data from the 2012 study of Arnott and Per-
van (2012). Looking at the analysis of Data Science
Research, 66.1 % do not reference or justify the re-
search methods with appropriate literature references
at all. At the same time, eight publications com-
pletely abstained from mentioning further research
methods. Only three publications could be identified
as strongly rigorous. The main reason for this assess-
ment is the consistent use of research methods for all
activities within the various phases of DSR. In each
case, references are cited that prove that it is an es-
tablished research method whose success can be ex-
pected. Hereby it can be concluded that after using
the methods in a comprehensible and promising way
in many contexts, the results are also valid for this
publication.
6.2 Limitations
We need to acknowledge some limitations to our re-
search. First, it must be taken into account that during
the data collection and classification, despite main-
taining a dual control principle, the absence of errors
cannot be guaranteed. Due to the diversity of this re-
search area and the missing separation precision pro-
vided by the search string used, it cannot be guaran-
teed that all publications matching the topic could be
determined. In Addition, the differentiation by con-
cepts and role of Data Science did not lead to any find-
ings due to the small sub-sample size in some cases.
In addition, the rigor applied by researchers can only
be assessed based on what was written in the publica-
tions. This means that only explicitly mentioned re-
search methods can be considered. Researchers may
omit (intentionally) details or steps for different rea-
sons. It is important to acknowledge the limitations in
assessing the rigor based solely on the written docu-
mentation in form of publications.
6.3 Future Work
To validate this work as well as for further analysis, a
replication of the study with additional Data Science
publications, even if they may not explicitly state that
they proceed according to DSR, would be useful. In
future studies, an exploration of DSR in the domain
of Data Science may benefit from adopting a quali-
tative methodology. By analyzing Data Science re-
search more in-depth the rigor can be assessed beyond
the applied research methods described in the corre-
sponding publications. Another possibility for further
work would be to develop a DSR process model, tai-
lored to the specific needs of Data Science research.
In order to take into account the characteristics of
Data Science Research, the authors propose future
work about the integration of a Data Science process
model like CRISP-DM into DSR.
REFERENCES
Abbasi, A., Sarker, S., and Chiang, R. H. (2016). Big data
research in information systems: Toward an inclusive
research agenda. JAIS, 17:1–32.
Abdel-Karim, B. M., Pfeuffer, N., and Hinz, O. (2021).
Machine learning in information systems - a biblio-
graphic review and open research issues. Electronic
Markets, 31:643–670.
Abkenar, S. P., Vanani, I. R., Sohrabi, B., and Manian, A.
(2022). Social commerce mobile application enhance-
ment: a hybrid text clustering - topic modeling busi-
ness model analysis. Electronic Commerce Research.
Alturki, A., Bandara, W., and Gable, G. G. (2012). Design
science research and the core of information systems.
LNCS, 7286:309–327.
Andrews, R., van Dun, C. G., Wynn, M. T., Kratsch, W.,
R
¨
oglinger, M. K., and ter Hofstede, A. H. (2020).
Quality-informed semi-automated event log genera-
tion for process mining. Decision Support Systems,
132.
Arnott, D. and Pervan, G. (2012). Design science in deci-
sion support systems research: An assessment using
the hevner, march, park, and ram guidelines. JAIS,
13:923–949.
Assarandarban, M., Bhowmik, T., Do, A. Q., Chekuri, S.,
Wang, W., and Niu, N. (2021). Foraging-theoretic tool
composition: An empirical study on vulnerability dis-
covery. Proceedings of IRI 2021, pages 139–146.
Baijens, J., Helms, R., and Iren, D. (2020). Applying scrum
in data science projects. Proceedings of CBI 2020,
1:30–38.
Benbasat, I. and Zmud, R. W. (2003). The identity crisis
within the is discipline: Defining and communicating
the discipline’s core properties. MIS Quarter, 27:183–
194.
Bokolo, A. J. (2022). Exploring interoperability of dis-
tributed ledger and decentralized technology adoption
in virtual enterprises. ISeB.
Brunk, J., Stierle, M., Papke, L., Revoredo, K., Matzner,
M., and Becker, J. (2021). Cause vs. effect in context-
sensitive prediction of business process instances. In-
formation Systems, 95.
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
132

Bunnell, L., Osei-Bryson, K. M., and Yoon, V. Y. (2020).
Finpathlight: Framework for an multiagent recom-
mender system designed to increase consumer finan-
cial capability. Decision Support Systems, 134.
Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz,
T. P., Shearer, C., and Wirth, R. (2000). Crisp-dm 1.0:
Step-by-step data mining guide.
Chasupa, T. L. and Paireekreng, W. (2021). The framework
of extracting unstructured usage for big data platform.
pages 90–94. IEEE.
Clapham, B., Bender, M., Lausen, J., and Gomber, P.
(2022). Policy making in the financial industry: A
framework for regulatory impact analysis using tex-
tual analysis. Journal of Business Economics.
Elragal, A. and Haddara, M. (2019). Design science re-
search: Evaluation in the lens of big data analytics.
Systems, 7:1–8.
Elragal, A. and Klischewski, R. (2017). Theory-driven
or process-driven prediction? epistemological chal-
lenges of big data analytics. Journal of Big Data, 4:1–
20.
Fabian, B., Bender, B., Hesseldieck, B., Haupt, J., and Less-
mann, S. (2021). Enterprise-grade protection against
e-mail tracking. Information Systems, 97.
Fatima, S., Desouza, K. C., Buck, C., and Fielt, E. (2022).
Public ai canvas for ai-enabled public value: A design
science approach. GIQ, 39.
Feio, I. C. L. and dos Santos, V. D. (2022). A strategic
model and framework for intelligent process automa-
tion. volume 2022-June, pages 22–25.
Ferro, D. B., Brailsford, S., Bravo, C., and Smith, H. (2020).
Improving healthcare access management by predict-
ing patient no-show behaviour. Decision Support Sys-
tems, 138.
Filipiak, D., We¸cel, K., Str
´
o
˙
zyna, M., Michalak, M., and
Abramowicz, W. (2020). Extracting maritime traffic
networks from ais data using evolutionary algorithm.
BISE, 62:435–450.
Fischer, D. A., Goel, K., Andrews, R., van Dun, C.
G. J., Wynn, M. T., and R
¨
oglinger, M. (2020). En-
hancing event log quality: Detecting and quantify-
ing timestamp imperfections. volume 12168 LNCS,
pages 309–326. Springer Science and Business Media
Deutschland GmbH.
Fussl, A. and Nissen, V. (2022). Interpretability of knowl-
edge graph-based explainable process analysis. pages
9–17.
F
¨
orster, M., Bansemir, B., and Roth, A. (2021). Innova-
tion von datengetriebenen gesch
¨
aftsmodellen. HMD
Praxis der Wirtschaftsinformatik, 58:595–610.
Goes, P. B. (2014). Big data and is research [editor’s com-
ments]. MIS Quarterly, 38:iii–viii.
Graafmans, T., Turetken, O., Poppelaars, H., and Fahland,
D. (2021). Process mining for six sigma: A guideline
and tool support. BISE, 63:277–300.
Gregor, S. and Hevner, A. R. (2013). Positioning and pre-
senting design science research for maximum impact.
MIS Quarterly: Management Information Systems,
37:337–355.
Gregor, S. and Jones, D. (2007). The anatomy of a design
theory. JAIS, 8:312–335.
G
´
ortowski, S. and Lewa
´
nska, E. (2020). Incremental mod-
eling method of supply chain for decision-making
support. volume 394, pages 34–44. Springer Science
and Business Media Deutschland GmbH.
Hacker, J. and Riemer, K. (2021). Identification of user
roles in enterprise social networks: Method develop-
ment and application. BISE, 63:367–387.
Hevner, A. (2007). A three cycle view of design science
research. SJIS, 19:87–92.
Hevner, A. R., March, S. T., Park, J., and Ram, S. (2004).
Design science in information systems research. MIS
Quarterly: Management Information Systems, 28:75–
105.
Huang, G. and Buss, M. (2020). Decision-making in ma-
chine learning. Proceedings of AEECA 2020, pages
256–260.
Hunke, F., Seebacher, S., and Thomsen, H. (2020). Please
tell me what to do – towards a guided orchestration
of key activities in data-rich service systems. volume
12388 LNCS, pages 426–437. Springer Science and
Business Media Deutschland GmbH.
Johnson, M., Albizri, A., Harfouche, A., and Fosso-Wamba,
S. (2022). Integrating human knowledge into artificial
intelligence for complex and ill-structured problems:
Informed artificial intelligence. IJIM, 64.
Jordan, M. I. and Mitchell, T. M. (2015). Machine learn-
ing: Trends, perspectives, and prospects. Science,
349:255–260.
Joubert, A., Murawski, M., and Bick, M. (2021). Measuring
the big data readiness of developing countries – index
development and its application to africa. Information
Systems Frontiers.
Kaymakci, C., Wenninger, S., and Sauer, A. (2021). A
holistic framework for ai systems in industrial appli-
cations. volume 47, pages 78–93. Springer Science
and Business Media Deutschland GmbH.
Khalil, M. and Rambech, M. (2022). Eduino: A telegram
learning-based platform and chatbot in higher educa-
tion. volume 13329 LNCS, pages 188–204. Springer
Science and Business Media Deutschland GmbH.
Kortmann, F., Fassmeyer, P., Funk, B., and Drews, P.
(2022). Watch out, pothole! featuring road dam-
age detection in an end-to-end system for autonomous
driving. DKE, 142.
Krasikov, P., Legner, C., and Eurich, M. (2021). Sourc-
ing the right open data: A design science research
approach for the enterprise context. volume 12807
LNCS, pages 313–327. Springer Science and Busi-
ness Media Deutschland GmbH.
Kratsch, W., K
¨
onig, F., and R
¨
oglinger, M. (2022). Shed-
ding light on blind spots – developing a reference ar-
chitecture to leverage video data for process mining.
Decision Support Systems, 158.
Kregel, I., Stemann, D., Koch, J., and Coners, A. (2021).
Process mining for six sigma: Utilising digital traces.
CAIE, 153.
Rigor in Applied Data Science Research Based on DSR: A Literature Review
133

Kuechler, B. and Vaishnavi, V. (2011). Promoting relevance
in is research: An informing system for design science
research. InformingSciJ, 14:125–138.
L
¨
ohr, B., Brennig, K., Bartelheimer, C., Beverungen, D.,
and M
¨
uller, O. (2022). Process mining of knowledge-
intensive processes: An action design research study
in manufacturing. pages 251–267.
Maheswaran, S., Indhumathi, N., Dhanalakshmi, S., Nan-
dita, S., Shafiq, I. M., and Rithka, P. (2022). Iden-
tification and classification of groundnut leaf disease
using convolutional neural network. pages 251–270.
Mar-Raave, J. R. D., Bahs¸i, H., Mr
ˇ
si
´
c, L., and Hausknecht,
K. (2021). A machine learning-based forensic tool
for image classification - a design science approach.
Forensic Science International: Digital Investigation,
38.
Martin, D., K
¨
uhl, N., von Bischhoffshausen, J. K., and
Satzger, G. (2020). System-wide learning in cyber-
physical service systems: A research agenda. volume
12388 LNCS, pages 457–468. Springer Science and
Business Media Deutschland GmbH.
Mart
´
ınez-Plumed, F., Contreras-Ochando, L., Ferri, C.,
Hern
´
andez-Orallo, J., Kull, M., Lachiche, N.,
Ram
´
ırez-Quintana, M. J., and Flach, P. (2021). Crisp-
dm twenty years later: From data mining processes
to data science trajectories. IEEE Transactions on
Knowledge and Data Engineering, 33(8):3048–3061.
Mayring, P. (2000). Pensionierung als krise oder
gl
¨
ucksgewinn?–ergebnisse aus einer quantitativ-
qualitativen l
¨
angsschnittuntersuchung. Zeitschrift f
¨
ur
Gerontologie und Geriatrie, 33:124–133.
Miah, S. J., Solomonides, I., and Gammack, J. G. (2020). A
design-based research approach for developing data-
focussed business curricula. Education and Informa-
tion Technologies, 25:553–581.
Molnar, E., Molnar, R., and Gregus, M. (2020). Business
schools and ris3 – enterprise architecture perspective.
Mombini, H., Tulu, B., Strong, D., Agu, E., Nguyen, H.,
Lindsay, C., Loretz, L., Pedersen, P., and Dunn, R.
(2020). Design of a machine learning system for pre-
diction of chronic wound management decisions. vol-
ume 12388 LNCS, pages 15–27. Springer Science and
Business Media Deutschland GmbH.
Monteiro, J., Barata, J., Veloso, M., Veloso, L., and Nunes,
J. (2022). A scalable digital twin for vertical farming.
JAIHC.
Odu, N. B., Prasad, R., Onime, C., and Sharma, B. K.
(2022). How to implement a decision support for dig-
ital health: Insights from design science perspective
for action research in tuberculosis detection. IJIM, 2.
Pan, Y. and Zhang, L. (2021). A bim-data mining integrated
digital twin framework for advanced project manage-
ment. Automation in Construction, 124.
Panzner, M., von Enzberg, S., Meyer, M., and Dumitrescu,
R. (2022). Characterization of usage data with the
help of data classifications. Journal of the Knowledge
Economy.
Pascal, A. and Renaud, A. (2020). 15 years of informa-
tion systems design science research: A bibliographic
analysis. Proceedings of HICSS 2020, pages 5016–
5025.
Peffers, K., Rothenberger, M., Tuunanen, T., and Vaezi, R.
(2012). Design science research evaluation. volume
7286, pages 398–410.
Peffers, K., Tuunanen, T., Gengler, C. E., Rossi, M., Hui,
W., Virtanen, V., and Bragge, J. (2006). The design
science research process: A model for producing and
presenting information systems research. pages 83–
106.
Peffers, K., Tuunanen, T., Rothenberger, M. A., and Chat-
terjee, S. (2007). A design science research method-
ology for information systems research. JMIS, 24:45–
77.
Peixoto, D., Faria, M., Macedo, R., Peixoto, H., Lopes,
J., Barbosa, A., Guimar
˜
aes, T., and Santos, M. F.
(2022). Determining internal medicine length of stay
by means of predictive analytics. volume 13566
LNAI, pages 171–182.
Pohl, M., Staegemann, D. G., and Turowski, K. (2022).
The performance benefit of data analytics applica-
tions. volume 201, pages 679–683. Elsevier B.V.
Romanov, D., Molokanov, V., Kazantsev, N., and Jha,
A. K. (2022). Removing order effects from human-
classified datasets: A machine learning method to im-
prove decision making systems. Decision Support
Systems.
Saar-Tsechansky, M. (2015). The business of business data
science in is journals. MIS Quarterly: Management
Information Systems, 39:iii–vi.
Samuel-Ojo, O., Shimabukuro, D., Chatterjee, S., Muthui,
M., Babineau, T., Prasertsilp, P., Ewais, S., and
Young, M. (2010). Meta-analysis of design science
research within the is community: Trends, patterns,
and outcomes. Global Perspectives on Design Science
Research, pages 124–138.
Schuster, T., Waidelich, L., and Volz, R. (2021). Matu-
rity models for the assessment of artificial intelligence
in small and medium-sized enterprises. volume 429
LNBIP, pages 22–36. Springer Science and Business
Media Deutschland GmbH.
Schwade, F. (2021). Social collaboration analytics frame-
work: A framework for providing business intelli-
gence on collaboration in the digital workplace. Deci-
sion Support Systems, 148.
Schwaiger, J., Hammerl, T., Florian, J., and Leist, S. (2021).
Ur: Smart–a tool for analyzing social media content.
ISeB, 19:1275–1320.
Schweiger, L., Barth, L., and Meierhofer, J. (2020). Data
resources to create digital twins. Proceedings of SDS
2020, pages 55–56.
Simonofski, A., Fink, J., and Burnay, C. (2021). Supporting
policy-making with social media and e-participation
platforms data: A policy analytics framework. GIQ,
38.
Soares, C. M. (2022). Crowdsourced data to improve mu-
nicipalities governance : Sesimbra’s case. pages 22–
25.
Sonnenberg, C. and Brocke, J. V. (2012). Lncs 7286 - eval-
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
134

uations in the science of the artificial – reconsidering
the build-evaluate pattern in design science research.
Spanaki, K., Karafili, E., and Despoudi, S. (2021). Ai ap-
plications of data sharing in agriculture 4.0: A frame-
work for role-based data access control. IJIM, 59.
Truong, T. M., L
ˆ
e, L. S., Paja, E., and Giorgini, P. (2021).
A data-driven, goal-oriented framework for process-
focused enterprise re-engineering. ISeB, 19:683–747.
Unhelkar, B. and Askren, J. (2020). Development and initial
validation of the big data framework for agile busi-
ness: Transformational innovation initiative. LNNS,
69:952–960.
Vaishnavi, V. and Kuechler, W. (2004). Design research in
information systems, volume 1.
van der Aalst, W. (2016). Data science in action.
van Dun, C., Moder, L., Kratsch, W., and R
¨
oglinger, M.
(2022). Processgan: Supporting the creation of busi-
ness process improvement ideas through generative
machine learning. Decision Support Systems.
Venkata, H. B. A., Calazacon, A., Mahmoud, T., and Hanne,
T. (2022). A technology recommender system based
on web crawling and natural language processing.
Proceedings of AIC 2022, pages 623–631.
Vereno, D., Polanec, K., and Neureiter, C. (2022). Evalu-
ating and improving model-based assessment of con-
textual data quality in smart grids. ISGT NA.
Volk, M., Staegemann, D., Trifonova, I., Bosse, S., and Tur-
owski, K. (2020). Identifying similarities of big data
projects-a use case driven approach. IEEE Access,
8:186599–186619.
vom Brocke, J., Simons, A., Niehaves, B., Niehaves, B.,
Reimer, K., Plattfaut, R., and Cleven, A. (2009). Re-
constructing the giant: On the importance of rigour in
documenting the literature search process.
V
¨
ossing, M., K
¨
uhl, N., Lind, M., and Satzger, G. (2022).
Designing transparency for effective human-ai collab-
oration. Information Systems Frontiers.
Warsinsky, S., Schmidt-Kraepelin, M., Thiebes, S., Wagner,
M., and Sunyaev, A. (2022). Gamified expert annota-
tion systems: Meta-requirements and tentative design.
volume 13229 LNCS, pages 154–166. Springer Sci-
ence and Business Media Deutschland GmbH.
Webster, J. and Watson, R. T. (2002). Analyzing the past
to prepare for the future: Writing a literature review.
MIS Quarterly, 26:xiii–xxiii.
Xia, L. (2022). Historical profile will tell? a deep learning-
based multi-level embedding framework for adverse
drug event detection and extraction. Decision Support
Systems, 160.
Yang, K. L., Hsu, S. C., and Hsu, H. M. (2020). Enriching
design thinking with data science: Using the taiwan
moving industry as a case. volume 1189 CCIS, pages
185–202. Springer.
Zhu, Y. and Xiong, Y. (2015). Defining data science. CoRR,
abs/1501.0:1–6.
Zschech, P., Horn, R., H
¨
oschele, D., Janiesch, C., and Hein-
rich, K. (2020). Intelligent user assistance for auto-
mated data mining method selection. BISE, 62:227–
247.
Rigor in Applied Data Science Research Based on DSR: A Literature Review
135
