
A Personalized Book Recommender System for Adults Based on Deep
Learning and Filtering
Yiu-Kai Ng
a
Computer Science Department, Brigham Young University, 3361 TMCB, Provo, Utah, U.S.A.
Keywords:
Book Recommender System, Deep Learning, Filtering.
Abstract:
Reading improves the reader’s vocabulary and knowledge of the world. It can open minds to different ideas
which may challenge the reader to view things in a different light. Reading books benefits both physical and
mental health of the reader, and those benefits can last a lifetime. It begins in early childhood and continue
through the senior years. A good book should make the reader curious to learn more, and excited to share
with others. For some readers, their reluctance to read is due to competing interests such as sports. For others,
it is because reading is difficult and they associate it with frustration and strain. A lack of imagination can
turn reading into a rather boring activity. In order to encourage adults to read, we propose an elegant book
recommender for adults based on a deep learning and filtering approaches that can infer the content and the
quality of books without utilizing the actual content, which are often unavailable due to the copyright con-
straint. Our book recommender filters books for adult readers simply based on user ratings, which are widely
available on social media, for making recommendations. Experimental results have verified the effectiveness
of our proposed book recommender system.
1 INTRODUCTION
Studies have shown that those who read for pleasure
have higher levels of self-esteem and a greater abil-
ity to cope with difficult situations (National Library,
2023). Reading for pleasure was also associated with
better sleeping patterns. Adults who read for just 30
minutes a week are 20% more likely to report greater
life satisfaction (Rayner et al., 2012). According to a
study from Pew Research from 2021 (Basmo, 2023),
75% of Americans have read a book on a yearly ba-
sis. A study by Delgado et al. (Delgado et al., 2018)
demonstrated that reading also improves written com-
prehension skills. Moreover, reading is good for a
person, since it improves his focus, memory, empathy,
and communication skills, besides reducing stress,
improving mental health, and learning new things to
help him succeed in his work and relationships (Nar-
vaez et al., 1999). Even though there are many ben-
efits on reading books, statistical data have indicated
that U.S. adults are reading roughly two or three fewer
books per year than they did between 2001 and 2016.
The decline is greater among subgroups that tended
to be more avid readers, particularly college gradu-
a
https://orcid.org/0000-0002-5680-2796
ates but also women and older Americans (Baron and
Mangen, 2021). This decline closely tracks the rise
of social media and iphones, since reading books is a
leisure activity that struggles to compete with the pop-
ular online platform. This is an alarming rate, since
ordinary people are not taking advantages of enrich-
ing themselves by reading and learning. We realize
that adult life is busy and even adults who want to
read sometimes just do not find the time. In order to
motivate adults to read, it is essential to recommend
books to them that are accessible and relevant in order
to achieve the goal.
Adult learners expect information they are learn-
ing to be useful and applicable to their lives or in-
terest. Assigning reading that is not just accessi-
ble, but is also relevant and enjoyable can make a
big difference in motivating adult learners. Choos-
ing books that relate directly to adult students’ lives
or careers and offering them the joy of reading can be
useful. In helping adults to find appropriate books to
read, we have developed BkRec, a personalized book
recommender for adults, which adopts the content-
based and collaborative filtering approaches to make
personalized book recommendations for adults. The
user-based and item-based collaborative filtering (CF)
approaches are popular techniques for generating per-
248
Ng, Y.
A Personalized Book Recommender System for Adults Based on Deep Learning and Filtering.
DOI: 10.5220/0012171600003598
In Proceedings of the 15th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2023) - Volume 1: KDIR, pages 248-256
ISBN: 978-989-758-671-2; ISSN: 2184-3228
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

sonalized recommendations. When the data spar-
sity becomes a problem for certain adult users, i.e.,
when there is not enough data to generate similar user
groups or similar item groups to use the CF methods,
the content-based filtering approach can be adopted to
make personalized recommendations for the users.
BkRec, which is a novel recommender that ex-
clusively targets adult readers, is a self-reliant rec-
ommender which, unlike others, does not rely on
book metadata, such as book reviews and Library of
Congress subject headings, that are either directly re-
trieved or inferred from the Web. BkRec is unique,
since it explicitly considers the ratings and content
descriptions on books rated by adults. In addition,
BkRec first adapts Recurrent Neural Networks (RNN)
for classifying books belonged to the categories that
users are interested in reading as candidate books to
be considered for making recommendations. Here-
after, content-based and collaborative filtering ap-
proaches are applying for ranking candidate books to
be suggested to adult readers. Conducted empirical
study have validated that the proposed book recom-
mender for adults is effective, since it accurately pred-
icates books preferred by adult readers.
2 RELATED WORK
There are a number of recent publications that are
closely related to our work. Saraswt and Srishti
(Saraswat and Srishti, 2022) apply RNN for classi-
fication books based on book plots and reviews and
make book recommendations based on book cate-
gories. Our BkRec, on the other hand, only adapts
RNN for classifying books into one of the 31 pre-
defined categories. Hereafter, BkRec relies on vari-
ous filtering approaches to classify books that are pre-
ferred by adult readers for making recommendations.
Mathew et al. (Mathew et al., 2016) also propose
a book recommender system based on content-based
and CF approaches. However, their content-based fil-
tering system relies on the entire content of each book
for making recommendation, which more often than
not are unavailable due to the copyright constraint,
as stated earlier. Moreover, they only consider the
item-based CF method, without using the user-based
approach, which is inadequate, since the latter often
compromises the former to provide accurate predic-
tion on user’s preference.
Devika et al. (Devika et al., 2016) extract infor-
mation from the users’ reviews and then score to each
book based on the users’ feedback. In reality, how-
ever, this approach is unreliable, since it is highly un-
likely that users provide reviews on books and offer
feedback on various books due to the time constraint
and commitment. Our book recommender system
simply consider book descriptions supplied by book
publishers and users’ ratings on books that are widely
available on social media.
Another book recommender system based on col-
laborative filtering is presented by Ramakrishnan et
al. (Ramakrishnan et al., 2020). The authors assign
explicit ratings to users solely based on the implicit
feedback given by users to specific books using var-
ious algorithms. This approach, however, involves
users in the feedback cycle, which is undesirable,
since it is explicitly relied on engagement, which is
not trustworthy due to the fact that users might not be
willing to offer their feedbacks on books, especially
with the ones that they are unfamiliar.
Fuli Zhang (Zhang, 2016) introduces a personal-
ized book recommender based on time-sequential col-
laborative filtering, which is combined with college
students’ learning trajectories. The author, who relies
on the availability of time sequence information of
borrowing books and the circulation times of books,
does not realize that these information are not widely
available to the general public, and thus the adoption
of their recommendation method is seriously hindered
due to the data constraint.
3 OUR BOOK RECOMMENDER
We first utilize a deep neural network model to clas-
sify a book B given by a user U who often makes
available a number of preferred books in his profile.
Based on the category of B, we filter books in a collec-
tion that are in the same category as B, called candi-
date books. Hereafter, we combine different filtering
approaches to recommend the top-ranked candidate
books to U.
3.1 The RNN Model
We employ a recurrent neural network (RNN) as our
classifier, since RNNs produce robust models for clas-
sification. Similar to other deep neural networks,
RNNs are both trained (optimized) by the backpropa-
gation of error and comprised of a series of layers: in-
put, hidden, and output. An input layer is a vector or
matrix representation of the data to be modeled, and
a few hidden layers of activation nodes are included.
Each of the hidden layer is designed to map its pre-
vious layer to a higher-order and higher-dimensional
representation of the features which aims to be more
useful in modeling the output than the original fea-
tures. An output layer produces the desired output for
A Personalized Book Recommender System for Adults Based on Deep Learning and Filtering
249

classification or regression tasks.
RNNs achieve the recurrent pattern matching
through its recurrent layer(s). A recurrent layer is
one which contains a single recurrent unit through
which each value of the input vector or matrix passes.
The recurrent unit maintains a state which can be
thought of as a “memory.” As each value in the in-
put iteratively passes through the unit at time step t,
the unit updates its state h
t
based on a function of
that input value x
t
and its own previous state h
t−1
as
h
t
= f (h
t−1
, x
t
), where f is any non-linear activation.
Recurrent layers are designed to “remember” the
most important features in sequenced data no matter
if the feature appears towards the beginning of the se-
quence or the end. In fact, one widely-used imple-
mentation of a recurrent unit is thus named “Long-
Short Term Memory”, or LSTM. The designed RNN
accurately classifies our data set of books solely based
on their sequential text properties.
3.1.1 Feature Representation
To utilize a RNN, we need to provide the network
with sequential data as input and a corresponding
ground-truth value as its target output. Each data en-
try has to first be transformed in order to be fed into
the RNN. Attributes of book entries were manipulated
as follows:
• Label. The label consists of the category of a book,
each of which is the top 31 categories pre-defined
by Thriftbooks
1
. Since RNN cannot accept strings
as an output target, each unique category string is
assigned a unique integer value, which is trans-
formed into a one-hot encoding
2
to be used later
as the network’s prediction target.
• Features. Features are extracted from the data
set S as the brief description of a book, which
is called a sentence of an entry, and is accessible
from the book-affiliated websites such as Amazon
3
.
Words in a brief description are transformed into
sequences, or ordered lists of tokens, i.e., unigrams
and special characters such as punctuation marks.
Each sequence is padded with an appropriate num-
ber of null tokens such that each sequence was of
uniform length. We have considered only the first
72 tokens in each sentence when representing the
features, since over 90% of sentences in S contain
1
https://www.thriftbooks.com/sitemap/
2
A one-hot encoding of an integer value i among n
unique values is a binarized representation of that integer as
an n-dimensional vector of all zeros except the i
th
element,
which is a one.
3
www.amazon.com
72 or fewer tokens. We considered the 6,500 most
commonly-occurring tokens in S.
• Text. While extracting features, we have chosen
not to remove stopwords, since we prefer not to
lose any important semantic meaning, e.g., ‘not’,
within term sequences nor punctuation, since many
abstracts include mathematical symbols, e.g., ‘|’,
which especially correlate to certain categories. We
did, however, convert all of the text in a sentence to
lowercase because the particular word embedding
which we used did not contain cased characters.
3.1.2 Network Structure
In this section, we discuss our RNN used for classi-
fying book categories. Table 1 summaries different
layers, dimensions, and parameters in our RNN.
The Embedding Layer. A design goal of our neu-
ral network is to capture relatedness between differ-
ent English words (or tokens) with similar seman-
tic meanings. Our neural network begins with an
embedding layer whose function is to learn a word
embedding for the tokens in the vocabulary of our
dataset. A word embedding maps tokens to respec-
tive n-dimensional real-valued vectors. Similarities
in semantic meanings between different tokens ought
to be captured in the word embedding by correspond-
ing vectors which are also similar either by Euclidean
distance, or by cosine similarity, or both.
The embedding layer contains 1,950,000 param-
eters, since there are 6,500 vectors, one for each to-
ken in the vocabulary, and each vector comes with
300 dimensions, and all of which could be trained.
Due to the large amount of time it would take to prop-
erly train the word embedding from scratch, we have
performed two different tasks: (i) we have loaded
into the embedding layer as weights an uncased, 300-
dimensional word embedding, GloVe, which has been
pre-trained on documents on the Web, and (ii) we
have decided to freeze, i.e., not train, the embedding
layer at all. The pre-trained vectors from GloVe suffi-
ciently capture semantic similarity between different
tokens for our task and they are not required to be fur-
ther optimized. Since the embedding layer was not
trained, it simply served to transform the input tokens
into a 300-dimensional space. Therefore, instead of
the 72-element vector which we started with, the em-
bedding layer outputs a 72 × 300 real-valued matrix.
The Bi-directional GRU Layer. Following the em-
bedding layer in our network is one type of recur-
rent layer – a bi-directional GRU, or Gated Recur-
rent Unit, layer. A GRU is a current state-of-the-
art recurrent unit which is able to ‘remember’ impor-
tant patterns within sequences and ‘forget’ the unim-
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
250
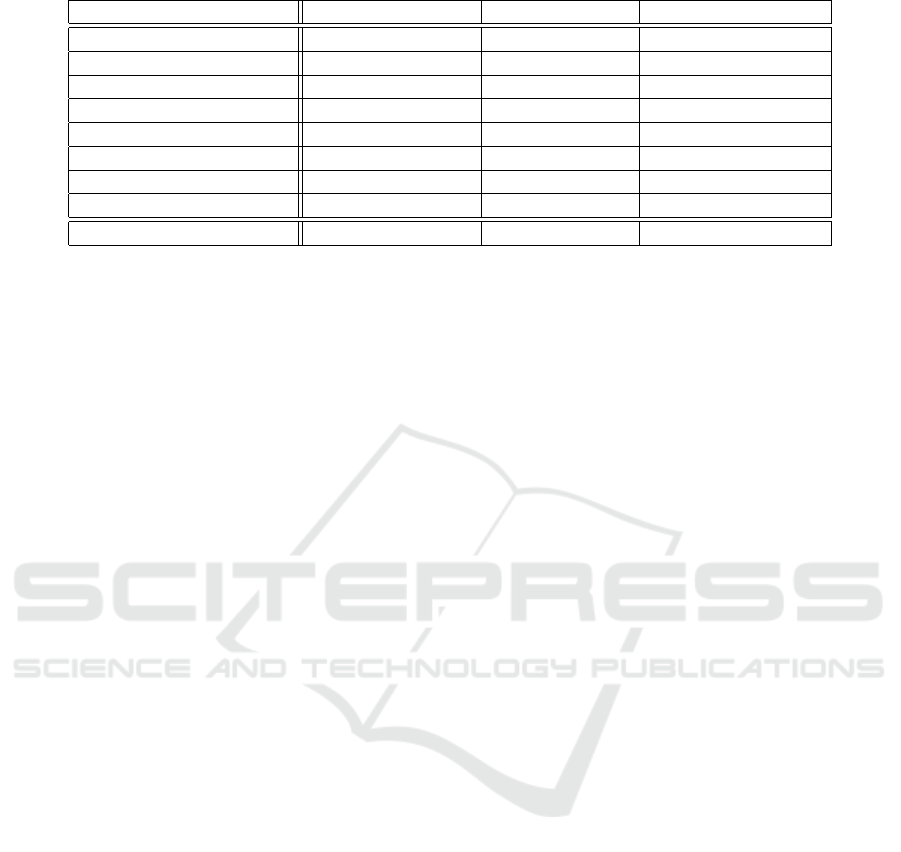
Table 1: Dimensions and number of parameters of layers in the RNN.
Layer Output Dimensions Total Parameters Trainable Parameters
Input 72 0 0
Embedding 72 × 300 1,950,000 0
Bi-directional GRU 72 × 128 140,160 140,160
Global Max Pooling (1D) 128 0 0
Dropout 1 128 0 0
Dense Hidden 64 8,256 8,256
Dropout 2 64 0 0
Dense Output 31 845 845
Total 2,099,261 149,261
portant ones. This layer effectively ‘reads’ the text,
or ‘learns’ higher-order properties within a sentence,
based on certain ordered sequences of tokens. The
number of trainable parameters in a single GRU layer
is 3 × (n
2
+ n(m + 1)), where n is the output dimen-
sion, or the number of time steps through which the
input values pass, and m is the input dimension. In
our case, n = 64, since we have chosen to pass each
input through 64 time steps, and m = 300 which is the
dimensionality of each word vector in the embedding
space. Since our layer is bi-directional, the number
of trainable parameters is twice that of a single layer,
i.e., 2 × 3 × (64
2
+ 64 × 301) = 140,160, the greatest
number of trainable parameters in our network.
The recurrent layer outputs a 72 × 128 matrix,
where 72 represents the number of tokens in a se-
quence, and 128 denotes the respective output values
of the GRU after each of 64 time steps in 2 directions.
The Global Max-Pooling Layer (1D). At this point
in the network, it is necessary to reduce the matrix
output from the GRU layer to a more manageable
vector which we eventually use to classify the token
sequence into one of the 31 categories. In order to
reduce the dimensionality of the output, we pass the
matrix through a global max-pooling layer. This layer
simply returns as output the maximum value of each
column in the matrix. Max-pooling is one of several
pooling functions, besides sum- or average-pooling,
used to reduce the dimensionality of its input. Since
pooling is a computable function, not a learnable one,
this layer cannot be optimized and contains no train-
able parameters. The output of the max-pooling layer
is a 128-dimensional vector.
The Dropout Layer 1. Our model includes at this
point a dropout layer. Dropout, a common technique
used in deep neural networks which helps to prevent
a model from overfitting, occurs when the output of
a percentage of nodes in a layer are suppressed. The
nodes which are chosen to be dropped out are prob-
abilistically determined at each pass of data through
the network. Since dropout does not change the di-
mensions of the input, this layer in our network also
outputs a 128-dimensional vector.
The Dense Hidden Layer. Our RNN model includes
a dense, or fully-connected, layer. A dense layer is
typical of nearly all neural networks and is used for
discovering hidden, or latent, features from the previ-
ous layers. It transforms a vector x with N elements
into a vector y with M inputs by multiplying x by a M
× N weight matrix W . Throughout training, weights
are optimized via backpropagation.
The Dropout Layer 2. Before classification, our
RNN model includes another dropout layer to again
avoid overfitting to the training sequences.
The Dense Output Layer. At last, our RNN model
includes a final dense layer which outputs 31 distinct
values, each value corresponding to the relative prob-
ability of the input belonging to one of the 31 unique
categories. Each instance is classified according to the
category corresponding to the highest of the 31 output
values.
3.2 Our Filtering Approaches
Our book recommender considers two different fil-
tering approaches in making book recommendations
for adult readers: the content-based and collaborative-
based filtering (CF) approaches. The content-based
approach suggest books similar in content to the ones
a given user has liked in the past, whereas recommen-
dations based on the user-based CF approach identi-
fies a group of users S whose preferences represented
by their ratings are similar to those of the given user
u and suggests books to u that are likely appealing to
u based on the ratings of S.
3.2.1 The Content-Based Filtering Method
The content-based filtering method analyzes the de-
scriptions of books rated by an adult u and construct a
profile of u based on the descriptions which are used
for predicting the ratings of books unknown to u. This
method does not require the ratings on books given
A Personalized Book Recommender System for Adults Based on Deep Learning and Filtering
251

by other users as in the CF approach to predict ratings
on unknown books to u. A user profile is a vector
representation of the corresponding user u’s interests,
which can be constructed using Equation 1.
X
u
= Σ
i∈τ
u
r
u,i
X
i
(1)
where τ
u
is the set of books rated by user u, r
u,i
de-
notes the rating provided by user u on book i, and X
i
is
the vector representation of the book description D on
i with the weight of each keyword k in D computed by
using the term frequency (TF) and inverse document
frequency (IDF) of k.
The Cosine Similarity, denoted CSIM, of the vec-
tor space model (VSM) is used to predict the rating
of a book B unknown to user u using the profile P of
u, denoted CSIM(P, B). The profile representation of
P is computed using Equation 1, whereas the vector
representation of the description of B is determined
similarly as X
i
in Equation 1, i.e., the weight of each
keyword k in the description of B is calculated by us-
ing the TF/IDF of k.
CSim(P, B) =
Σ
t
i=1
(P
i
× B
i
)
q
Σ
t
i=1
P
2
i
× Σ
t
i=1
B
2
i
(2)
where t is the dimension of the vector representation
of P and B.
3.2.2 The Collaborative Filtering Approaches
The collaborative filtering (CF) approaches rely on
the ratings of a user and other users. The predicted
rating of a user u on a book i is likely similar to the rat-
ing of user v on i if both users have rated other books
similarly. In this paper, we consider both the user-
based CF approach and the item-based CF approach.
The User-Based CF Approach. The user-based CF
approach determines the interest of a user u on a book
i using the ratings on i by other users, i.e., the neigh-
bors of u who have similar rating patterns. We ap-
ply the Cosine Similarity measure as defined in Equa-
tion 3 to calculate the similarity between two users u
and v and determine user pairs which have the lowest
rating difference among all the users. Equation 3 can
be applied to compute the similarity between a user
and each one of the other users to find out the similar-
ity group of each user. Two users who have the lowest
difference rating value between them means that they
are the closest neighbors.
USim(u, v) =
Σ
s∈S
u,v
(r
u,s
× r
v,s
)
q
Σ
s∈S
u,v
r
2
u,s
×
q
Σ
s∈S
u,v
r
2
v,s
(3)
where r
u,s
(r
v,s
, respectively) denotes the rating of user
u (user v, respectively) on item s, and S
u,v
denotes the
set of books rated by both users u and v.
Upon determining the K-nearest neighbors (i.e.,
KNN) of a user u using Equation 3, we compute the
predicted rating on a book s for u using Equation 4.
ˆr
u,s
= ¯r
u
+
Σ
v∈S
u,v
(r
v,s
− ¯r
u
) ×USim(u, v)
Σ
v∈S
u,v
USim(u, v)
(4)
where ˆr
u,s
stands for the predicted rating on book s for
user u, ¯r
u
is the average rating on books provided by
user u, S
u,v
is the group of closest neighbors of u, r
v,s
is the rating of user v on book s, and USim(u, v) is the
similarity measure between users u and v as computed
in Equation 3.
The Item-Based CF Approach. Contrast to the
user-based CF approach which relies on similar user
groups to recommend books, the item-based CF ap-
proach computes the similarity values among differ-
ent books and determine sets of books with similar
ratings provided by different users. The item-based
CF approach predicts the rating of a book i for a user u
based on the ratings of u on books similar to i. The ad-
justed cosine similarity matrix is applied to compute
the similarity values among different books and as-
sign books with similar ratings into the same similar-
item group as defined in Equation 5.
ISim(i, j) =
Σ
u∈U
(r
u,i
− ¯r
u
) × (r
u, j
− ¯r
u
)
p
Σ
u∈U
(r
u,i
− ¯r
u
)
2
×
p
Σ
u∈U
(r
u, j
− ¯r
u
)
2
(5)
where ISim(i, j) denotes the similarity value between
books i and j, r
u,i
(r
u, j
, respectively) denotes the rat-
ing of user u on book i ( j, respectively), ¯r
u
is the av-
erage rating for user i on all books u has rated, and U
is the set of books rated by u.
Equation 5 is used to compute the similarity be-
tween two books, whereas Equation 6 predicts the rat-
ing for user u on book i.
S
u,i
= ¯r
u
+
Σ
u
(r
u,i
− ¯r
u
)
u(i) + r
+
Σ
j∈I(u)
(r
u, j
−
Σ
u
(r
u, j
− ¯r
u
)
u( j)
)
ISim(i, j) + r
(6)
where S
u,i
denotes the predicted rating on book i for
user u, ¯r
u
denotes the average rating on all books u
has rated, r
u,i
(r
u, j
, respectively) is the rating on book i
( j, respectively) provided by u, I(u) is the set of books
u has rated, u(i) (u( j), respectively) is the number of
users who has rated i ( j, respectively), and r is the
book rating which is used to decrease the extremeness
when there are not enough ratings available.
The 1
st
component on the right-hand side of Equa-
tion 6 is called the global mean which is the average
rating on all the books u has rated. The 2
nd
compo-
nent is called the item offset which is the score for user
u on book i, whereas the 3
rd
component is called the
user offset, i.e., the user prediction on book i.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
252
(a) Errors using only 70% book descriptions. (b) Errors using 100% book descriptions.
Figure 1: Prediction errors of the content-based approach on the books in the BookCrossing dataset.
4 EXPERIMENTAL RESULTS
In this section, we first introduce the datasets used
for the empirical study conducted to assess the per-
formance of BkRec, our personalized book recom-
mender for adult readers. Hereafter, we present the
results of the empirical studies on BkRec.
4.1 Datasets
We have chosen a number of book records included in
the BookCrossing dataset to conduct the performance
evaluation of our recommender
4
. The BookCrossing
dataset was collected by Cai-Nicolas Ziegler between
August and September of 2004 with data extracted
from BookCrossing.com. It includes 278,858 users
who provide, on the scale of 1 to 10, 1,149,780 rat-
ings on 271,379 books. Each book record includes
a user ID, the ISBN of a book, and the rating pro-
vided by the user (identified by user ID) on the book.
We used Amazon.com AWS advisement API to ver-
ify that the ISBNs from the BookCrossing dataset
are valid. The 271,379 books in the BookCrossing
dataset is denoted BKC DS.
Besides using the books and their ratings in the
BookCrossing dataset, we extracted the book descrip-
tion of 30% of the BookCrossing books from Ama-
zon.com, since they were missing in the books and
needed for our content-based filtering approach. The
Amazon dataset yields the additional dataset used for
evaluating the performance of BkRec. Figure 1 shows
the differences in terms of prediction errors using only
70% versus 100% of book descriptions generated by
the content-based filtering approach.
4
Other datasets can be considered as long as they con-
tain user IDs, book ISBNs, and ratings.
4.2 Accuracy of Our RNN Classifier
Using a 80/10/10% training/validation/test split of the
data as mentioned in Section 4.1, we achieved 79%
classification accuracy on the book dataset. The ac-
curacy could not be higher likely because of the high
amounts of overlap between distinct keywords in the
brief description of books with different categories,
such as “Deep Learning Computing” and “Theory
of computation”. With 79% accuracy, we still suc-
cessfully classify 4 out of 5 book records, which
is way above the baseline “best-guesser” classifier.
Other bag-of-words modeling techniques with which
we have experimented, i.e., logistic regression, Sup-
port Vector Machine (SVM), and Multinomial Na
¨
ıve,
showed lower results.
4.3 Performance Evaluation of BkRec
In our empirical study, we considered the similar
user group size of ten users in the user-based CF ap-
proach, since LensKit
5
, which has implemented the
user-based CF method and has been cited in a num-
ber of published papers, has demonstrated that ten is
an ideal group size in predicting user ratings. We have
also chosen ten to be the group size of books used
in the content-based and item-based CF approaches,
since the prediction error rate using this group side
is the most ideal, in terms of size and accuracy, as
demonstrated in our empirical study and Figure 1.
To evaluate the performance of BkRec, we com-
puted the prediction error of CBRec for each user U
in CBC DS by taking the absolute value of the differ-
ence between the real and predicted ratings on each
book U has rated in the dataset. These prediction er-
rors were added up and divided by the total number of
5
http://lenskit.org/
A Personalized Book Recommender System for Adults Based on Deep Learning and Filtering
253

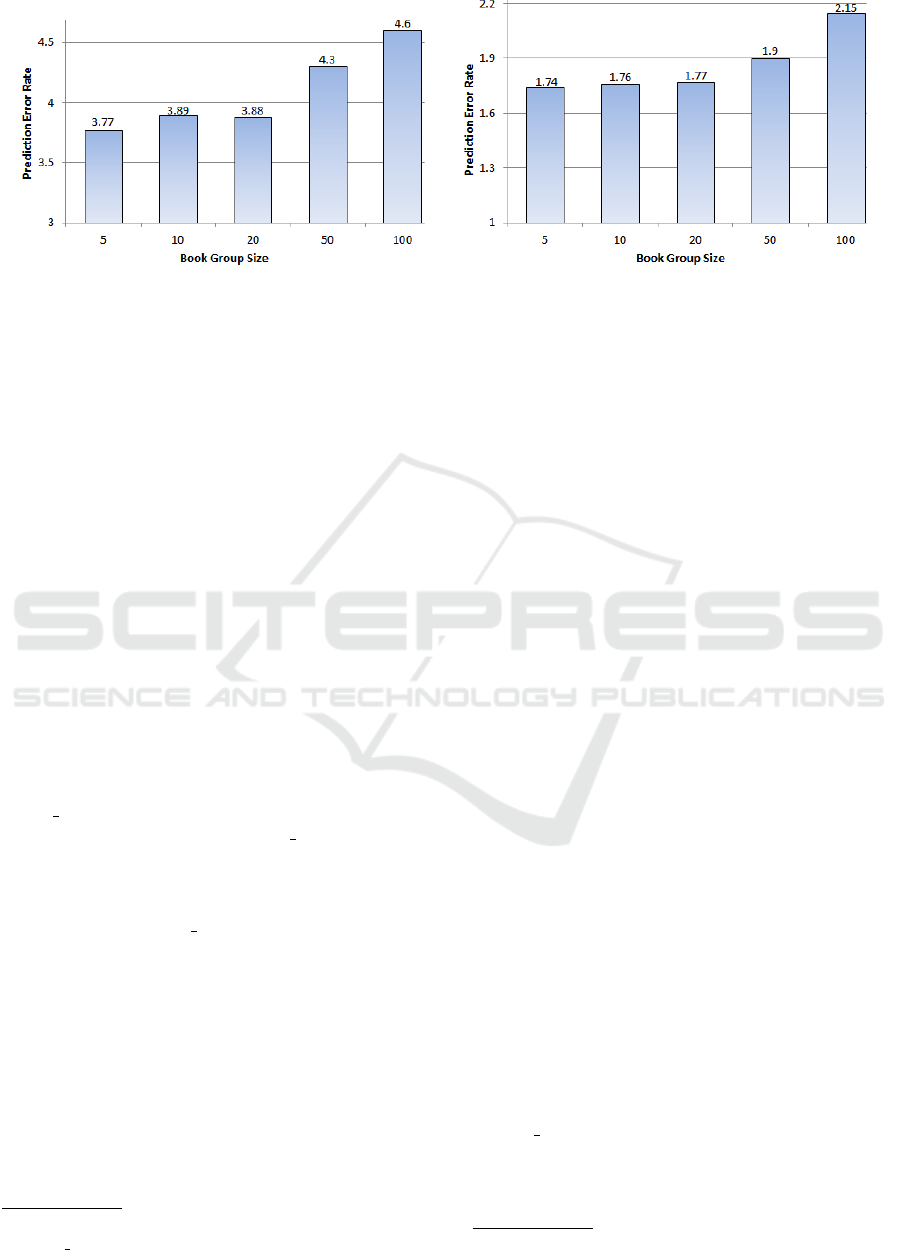
predictions. Figure 2 shows the prediction error rate
of each filtering approaches and their combinations.
As shown in Figure 2, the combined item-based,
content-based and user-based CF approach, denoted
ICU, outperforms individual and other combined
prediction models in terms of obtaining the lowest
prediction error rates among all the models. ICU
achieves the highest prediction accuracy, which is
only half a rating (out of 10) away from the actual
rating, since the item-based and content-based fil-
tering approach compensates the user-based CF ap-
proach when user ratings are sparse and vice versa.
The prediction error rate, i.e., accuracy ratio, achieved
by ICU is statistically significant (p < 0.04) over
the ones based on the combined content-based and
item-based CF approach and the combination of the
content-based and user-based approaches, the next
two models with prediction error rate lower than one,
which are determined using the Wilcoxon test signed-
ranked test. The experimental results have verified
that ICU is the most accurate recommendation tool
in predicting ratings on books for adults, which is the
most suitable choice for making book recommenda-
tions for adults based on the rating prediction.
4.4 Comparing Book Recommenders
We compared our recommender with exiting book
recommenders that achieve high accuracy in recom-
mendations on books based on their respective model.
• MF. Yu et al. (Yu et al., 2009) and Singh et
al. (Singh and Gordon, 2008) predict ratings
on books and movies based on matrix factor-
ization (MF), which can be adopted for solving
large-scale collaborative filtering problems. Yu et
al. develop a non-parametric matrix factorization
(NPMF) method, which exploits data sparsity ef-
fectively and achieves predicted rankings on items
comparable to or even superior than the perfor-
mance of the state-of-the-art low-rank matrix fac-
torization methods. Singh et al. introduce a col-
lective matrix factorization (CMF) approach based
on relational learning, which predicts user ratings
on items based on the items’ genres and role play-
ers, which are treated as unknown values of a rela-
tion between entities of a certain item using a given
database of entities and observed relations among
entities. Singh et al. propose different stochas-
tic optimization methods to handle and work effi-
ciently on large and sparse data sets with relational
schemes. They have demonstrated that their model
is practical to process relational domains with hun-
dreds of thousands of entities.
• ML. Besides the matrix factorization methods,
probabilistic frameworks have been introduced for
rating predictions. Shi et al. (Shi et al., 2010) pro-
pose a joint matrix factorization model for making
context-aware item recommendations
6
. Similar to
ours, the matrix factorization model developed by
Shi et al. relies not only on factorizing the user-item
rating matrix but also considers contextual informa-
tion of items. The model is capable of learning from
user-item matrix, as in conventional collaborative
filtering model, and simultaneously uses contex-
tual information during the recommendation pro-
cess. However, a significant difference between Shi
et al.’s matrix factorization model and ours is that
the contextual information of the former is based on
mood, whereas ours makes recommendations ac-
cording to the contextual information on books.
• MudRecS (Qumsiyeh and Ng, 2012) makes recom-
mendations on books, movies, music, and paintings
similar in content to other books, movies, music,
and paintings, respectively that a MudRecS user is
interested in. MudRecS does not rely on users’ ac-
cess patterns/histories, connection information ex-
tracted from social networking sites, collaborated
filtering methods, or user personal attributes (such
as gender and age) to perform the recommendation
task. It simply considers the users’ ratings, gen-
res, role players (authors or artists), and reviews of
different multimedia items. MudRecS predicts the
ratings of multimedia items that match the interests
of a user to make recommendations.
Figure 3 shows the Mean Absolute Error (MAE)
and Root Mean Square Error (RMSE) scores of our
and other recommender systems on the BKC DS
dataset. MAE and RMSE are two performance met-
rics widely-used for evaluating rating predictions on
multimedia data. Both MAE and RMSE measure the
average magnitude of error, i.e., the average predic-
tion error, on incorrectly assigned ratings. The er-
ror values computed by MAE are linear scores, i.e.,
the absolute values of individual differences in incor-
rect assignments are weighted equally in the average,
whereas the error rates of RMSE are squared before
they are summed and averaged, which yield a rela-
tively high weight to errors of large magnitude.
MAE=
1
n
n
∑
i=1
| f (x
i
)−y
i
|, RMSE=
r
∑
n
i=1
( f (x
i
) − y
i
)
2
n
(7)
where n is the number of items with ratings to be eval-
uated, f (x
i
) is the rating predicted by a system on item
6
The system was originally designed to predict rat-
ings on movies but was implemented by Qumsiyeh and Ng
(Qumsiyeh and Ng, 2012) for comparisons on books too.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
254
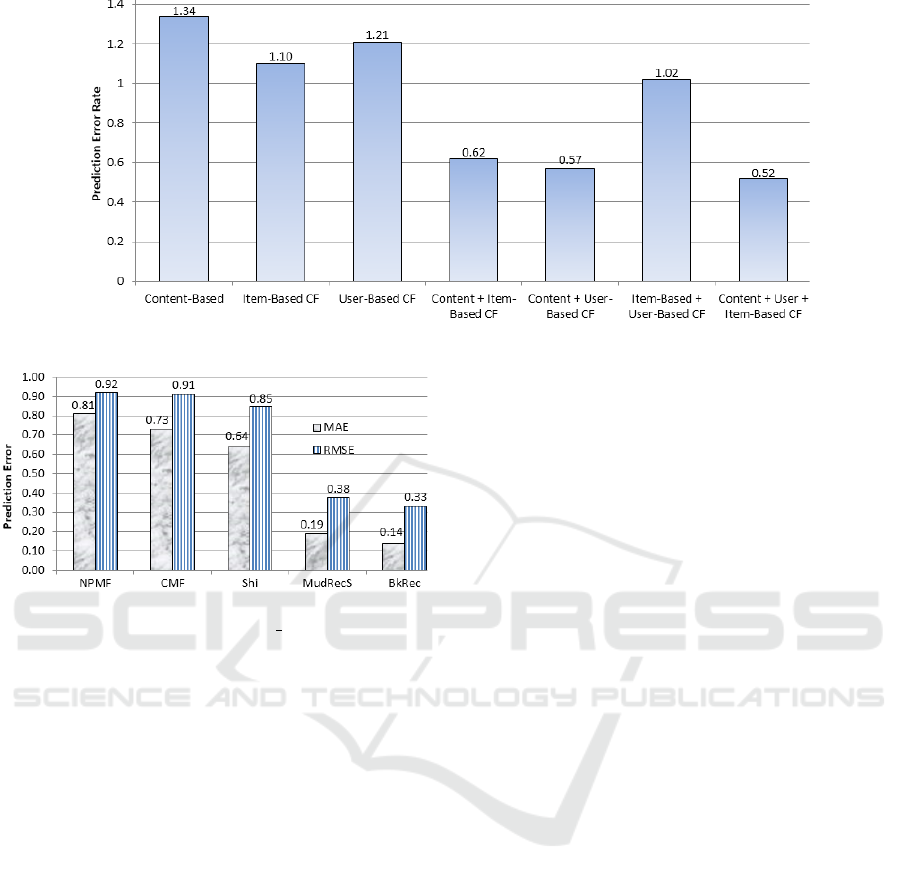
Figure 2: Prediction error rates of the various filtering approaches and their combinations.
Figure 3: The MAE and RMSE scores for various book rec-
ommendation systems based on BKC DS, the BookCross-
ing dataset.
x
i
(1 ≤ i ≤ n), and y
i
is an expert-assigned rating to x
i
.
As the MAE and RMSE scores shown in Fig-
ure 3, our book recommender significantly outper-
forms other book recommender systems on rating
predictions of the respective books based on the
Wilcoxon Signed-Ranks Test (p ≤ 0.05).
5 CONCLUSIONS
It is important to develop a book recommender sys-
tem for adults that lightens their burden to search for
desirable books to read for either educational or enter-
taining purpose, or both. Unlike many of the existing
book recommender systems, our proposed book rec-
ommender for adults, BkRec, simply relies solely on a
deep learning model and different filtering approaches
to make personalized book recommendations. BkRec
is simple and unique, since it relies only on user rat-
ings on books to determine books preferred by adults.
It is also easy to interpret any book recommended by
BkRec, which is simply based on the common inter-
ests of other users who share the same passion to a
particular adult. An empirical study demonstrates that
BkRec outperforms well-known book recommenders
for adults, and the results are statistically significant.
REFERENCES
Baron, N. and Mangen, A. (2021). Doing the Reading: the
Decline of Long Long-Form Reading in Higher Edu-
cation. Poetics Today, 42(2):253–279.
Basmo (2023). 15 Statistics About Reading Books
You Must Know in 2023. https://basmo.app/reading-
statistics/#:∼:text=Now%20that%20we%20know%20
that,couple%20of%20things%20in%20common.
Delgado, P., Vargas, C., Ackerman, R., and Salmeron, L.
(2018). Don’t Throw Away your Printed Books: A
Meta-Analysis on the Effects of Reading Media on
Reading Comprehension. ERR, 25:23–38.
Devika, P., Jisha, R., and Sajeev, G. (2016). A Novel Ap-
proach for Book Recommendation Systems. In Pro-
ceedings of ICCIC, pages 1–6. IEEE.
Mathew, P., Kuriakose, B., and Hegde, V. (2016). Book
Recommendation System through Content Based and
Collaborative Filtering Method. In Proceedings of
Data Mining & Advanced Computing, pages 47–52.
Narvaez, D., Van Den Broek, P., and Ruiz, A. (1999). The
Influence of Reading Purpose on Inference Generation
and Comprehension in Reading. Educational Psy-
chology, 91(3):488.
National Library (2023). Reading for Pleasure – a Door
to Success. https://natlib.govt.nz/schools/reading-eng
agement/understanding-reading-engagement/reading-
for-pleasure-a-door-to-success.
Qumsiyeh, R. and Ng, Y. (2012). Predicting the Ratings
of Multimedia Items for Making Personalized Recom-
mendations. In Proc. of ACM SIGIR, pages 475–484.
Ramakrishnan, G., Saicharan, V., Chandrasekaran, K.,
Rathnamma, M., and Ramana, V. (2020). Collabora-
tive Filtering for Book Recommendation System. In
SocProS, Volume 2, pages 325–338. Springer.
Rayner, K., Pollatsek, A., Ashby, J., and Clifton, C. (2012).
Psychology of Reading, 2nd Ed. Psychology Press.
A Personalized Book Recommender System for Adults Based on Deep Learning and Filtering
255

Saraswat, M. and Srishti (2022). Leveraging Genre Classi-
fication with RNN for Book Recommendation. Infor-
mation Technology, 14(7):3751–3756.
Shi, Y., Larson, M., and Hanjalic, A. (2010). Mining Mood-
Specific Movie Similarity with Matrix Factorization
for Context-Aware Recommendation. In Workshop on
CARS, pages 34–40.
Singh, A. and Gordon, G. (2008). Relational Learning via
Collective Matrix Factorization. In Proceedings of
ACM SIGKDD, pages 650–658.
Yu, K., Zhu, S., Lafferty, J., and Gong, Y. (2009).Fast Non-
parametric Matrix Factorization for Large-Scale Col-
laborative Filtering. InProc. of SIGIR, pages 211–218.
Zhang, F. (2016). A Personalized Time-Sequence-Based
Book Recommendation Algorithm for Digital Li-
braries. IEEE Access, 4:2714–2720.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
256
