
Deep Reinforcement Agent for
Efficient Instant Search
Ravneet Singh Arora
1
, Sreejith Menon
2
, Ayush Jain
1
and Nehil Jain
1
1
Bloomberg, U.S.A.
2
Google, U.S.A.
Keywords:
Instant Search, Deep Learning, Reinforcement Learning, Information Retrieval, Search.
Abstract:
Instant Search is a paradigm where a search system retrieves answers on the fly while typing. The na
¨
ıve
implementation of an Instant Search system would hit the search back-end for results each time a user types
a key, imposing a very high load on the underlying search system. In this paper, we propose to address the
load issue by identifying tokens that are semantically more salient toward retrieving relevant documents and
utilizing this knowledge to trigger an instant search selectively. We train a reinforcement agent that interacts
directly with the search engine and learns to predict the word’s importance in relation to the search engine.
Our proposed method treats the search system as a black box and is more universally applicable to diverse
architectures. To further support our work, a novel evaluation framework is presented to study the trade-off
between the number of triggered searches and the system’s performance. We utilize the framework to evaluate
and compare the proposed reinforcement method with other baselines. Experimental results demonstrate the
efficacy of the proposed method in achieving a superior trade-off.
1 INTRODUCTION
Interactivity in search engines has substantially grown
in popularity in recent years. To further enrich the
user experience, most modern search engines such as
Google and Bing provide instant search capabilities
(Venkataraman et al., 2016b). Instant search retrieves
results on the fly at every keystroke compared to con-
ventional search engines that trigger search at the end
of the query. Analyses of query-logs performed by
(Cetindil et al., 2012) have shown that the instant
search improves user experience by reducing the over-
all time and effort to retrieve the relevant results and
helps users find information when they are not sure of
the exact query. This feature is very relevant to mo-
bile applications. Recently, these systems have also
become extremely popular in Social Networking web-
sites such as Linkedin (Venkataraman et al., 2016a).
Instant Answers is another variation of this paradigm,
which is very common in search engines these days.
Instant answers allows users to view answers instantly
while typing questions such as “how is weather to-
day?” This feature is also handy in open-domain
question answering where user needs are ambiguous.
The implementation of instant search systems
faces a significant challenge in the form of immense
load on the back-end search engine. The instant
search leads to an increase of tens or up to hun-
dreds of more queries for a single search session.
This becomes more severe in the case of longer nat-
ural language queries. Managing such load becomes
problematic for several reasons: the software or the
hardware might not be able to cope with high query
throughput during spikes of requests, or it might cause
high energy consumption by the servers, or just con-
sume computational resources needed by other pro-
cesses like indexing.
Several approaches have been proposed to im-
prove the performance and scalability of instant
search. Many of these studies are based on design-
ing more efficient index data structures for faster re-
trieval of results (Bast and Weber, 2006; Fafalios and
Tzitzikas, 2011; Li et al., 2012; Ji et al., 2009; Li
et al., 2011; Wang et al., 2010). These data struc-
tures are examined together with the techniques such
as caching (Fafalios et al., 2012) for their ability to
improve the search engine query throughput. Caching
has been further extensively applied for large-scale
traditional search systems in various studies such as
(Markatos, 2001; Saraiva et al., 2001; Dean, 2009;
Gan and Suel, 2009; Fagni et al., 2006; Long and
Suel, 2006). New index data-structures and file sys-
Arora, R., Menon, S., Jain, A. and Jain, N.
Deep Reinforcement Agent for Efficient Instant Search.
DOI: 10.5220/0012178300003598
In Proceedings of the 15th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2023) - Volume 1: KDIR, pages 281-288
ISBN: 978-989-758-671-2; ISSN: 2184-3228
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
281

Figure 1: Behaviors of Traditional, Instant and proposed Instant search system for the query Flight service from New York
to Barcelona Spain. Searches are triggered at tokens marked green. The whole prefix is forwarded to the search engine as a
query.
tem formats for boosting the overall speed of search
engines have also been explored (Brin and Page,
1998; Dean, 2009).
In this paper, we propose a new method to solve
the instant search paradigm’s scalability challenges.
Our approach stems from the idea that a subset of to-
kens heavily influences the retrieval of the most rele-
vant results. This subset generally includes keywords
that are either topical or tokens that can alter the se-
mantic meaning of the query. We have applied this
idea towards training a reinforcement agent that pre-
dicts if a typed token is salient and selectively trig-
gers search only for such tokens. This is illustrated
in Figure 1. Searches are triggered at tokens marked
green. A traditional search system would wait till the
last token before issuing the search; an instant search
system, on the other hand, queries at every new to-
ken. Our proposed approach, in addition to common
stopwords, decides to skip the search at word New as
it is very common and needs more context (York in
this case) to retrieve the correct answer. Also, since
there is only one Barcelona city present in Spain, the
word Spain does not influence the results returned
and hence is skipped. The new approach treats the
underlying retrieval engine as a black box and is de-
coupled from the internal implementation. During the
training, the agent updates weights based on the feed-
back received during its interaction with the search
system. This methodology has the following advan-
tages: a) More universal application to a diverse set
of modern architectures; b) No need to scale up in-
dividual components of complicated search and QA
pipelines such as (Yang et al., 2019); c) Easy integra-
tion with the existing techniques such as caching.
Reinforcement learning provides the framework
to integrate and experiment with different reward
functions. Furthermore, there can be a lot of differ-
ent states based on the decision taken by the algo-
rithm and it is not easy to calculate exact true labels
for a pure supervised setting. Recently, reinforcement
learning has been successfully applied to an iden-
tical problem in the field of Simultaneous Machine
Translation (SMT) (Grissom II et al., 2014; Satija and
Pineau, 2016; Gu et al., 2016). SMT is defined as the
task of producing a real-time translation of a sentence
while typing. The goal here is to achieve a good trade-
off between the quality and delay of the translation.
We further evaluate the loss in the quality of in-
stant search due to introducing the proposed rein-
forcement agent. Instant search quality is measured
based on the studies that have compared the instant
search system with a traditional one (Cetindil et al.,
2012; Chandar et al., 2019). Instant search query logs
have been analyzed by (Cetindil et al., 2012) to un-
derstand the properties of instant search that lead to
a better user experience. Recently (Chandar et al.,
2019) combined user-query interaction logs with user
interviews and proposed new metrics that can eval-
uate user satisfaction for an instant search system.
Both the studies have proposed results-quality and
user-effort as the two primary metrics to measure
user experience improvement. Quality measures how
relevant the search system results are to the user
query, whereas Effort captures how quickly the rel-
evant results are retrievable using a search engine.
We use these metrics to estimate how well the pro-
posed methods can reduce the overall system load
while preserving the performance. Experiments are
performed on three different combinations of datasets
with two retrieval systems. Our experiments show
that the proposed model achieves a superior trade-off
by achieving near-optimal performance while reduc-
ing the number of triggered searches by 50%.
2 BASELINES
This section introduces the baselines that are evalu-
ated and compared with the proposed model.
Search at Every Token: SET issues search for every
new token. This method represents the true instant
search paradigm.
Search at Last Token: SLT waits for the entire query
and triggers a single search request at the end. This
baseline mimics the behavior of a regular retrieval en-
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
282

gine.
Skip Stop-Words: SS simply issues a search at every
token except the stop-words.
Similarity Matching Pre-Trained Model: SM pre-
trained model issues a query only when the query’s
semantic meaning has changed by more than a cer-
tain threshold. We utilize the pre-trained Universal
Sentence Encoder model (Cer et al., 2018) to gener-
ate an embedding for the query at every new token and
compare the similarity with the embedding of the pre-
viously searched sub-query. We use CosineDistance
between sentence embedding vector pairs to measure
the similarity. A sentence pair S
1
, S
2
is considered
to be semantically different if CosineDistance(S
1
, S
2
)
≥ threshold (Gomaa et al., 2013). We treat the
threshold as a hyper-parameter, and the actual value
is later stated in Section 4. Algorithm 1 describes this
approach in more detail.
Q ← Query ;
N ← Number of tokens in query Q ;
D ← Set of Retrieved Documents ;
q
searched
← Sequence of tokens previously
searched ;
V
searched
← Embedding Vector of q
searched
;
q
current
← Current sequence of tokens ;
V
current
← Embedding Vector of q
current
;
for i ← 1 to N do
q
current
← Q[1, i];
V
current
← GetEmbedding(q
current
);
if CosineDistance (V
searched
,
V
current
) ≥ threshold then
q
searched
← q
current
;
V
searched
← V
current
;
D ← RetrieveDocuments(q
current
);
end
end
Algorithm 1: Inference using Similarity Matching pre-
trained model Method.
3 REINFORCEMENT AGENT
Deep Q Networks: In Q-learning (Watkins and
Dayan, 1992), the environment is formulated as a se-
quence of state transitions (s
t
, a
t
, r
t
, s
t+1
) of a Markov
Decision Process (MDP). At a given time-step t for
state s
t
, the agent takes an action a
t
and in response re-
ceives the reward r
t
. As a result, the environment tran-
sitions into state s
t+1
. The agent chooses action a
t
for
the state s
t
by referring a state-action value function
Q(s
t
, a
t
), which measures the action’s expected long-
term reward. The algorithm updates the Q-function
by interacting with the environment and obtaining re-
wards. In large environments, it is impractical to
maintain a Q function for a substantially large num-
ber of states. DQN (Mnih et al., 2013) solves this
problem by approximating Q(s, a) using a deep neu-
ral network, which takes state s as input and calculates
value for every state/action pair.
Environment: The environment yields new words
for the agent and also interacts with the underlying
search engine. For a given query, the agent receives a
new word x
t
from the environment at every time-step t
and, in response, takes action a
t
. Based on the action,
the environment requests the underlying retrieval en-
gine, and the agent is provided feedback in the form
of reward r
t
. An episode terminates at the last token
x
T
of the query.
State: The state represents the portion of the query
that is already observed by the Agent. For a given
query q, let us assume that the agent has received to-
kens x
1
, ··· , x
t
denoted by partial query q
0
. The envi-
ronment maintains two sequences of tokens for every
q
0
:
• q
0
1
: the list of tokens x
1
, ··· , x
t
0
used in the last
search query submitted to the system.
• q
0
2
: the list of tokens x
t
0
+1
··· , x
t
the system has
seen since it last submitted a search query.
This state formulation allows the agent to learn
the overall importance of q
0
conditioned on already
searched sequence q
0
1
. At every time-step t, the agent
receives a new token x
t
which is then appended to
the unseached sub-sequence q
0
2
: q
0
2
= q
0
2
∪ x
t
. After
a search is triggered, q
0
2
is appended to the searched
sub-sequence q
0
1
and q
0
2
is cleared back to empty.
Actions: For every new token x
t
, the agent chooses
one of the following actions:
• WAIT: Instant search is not triggered, and the
agent waits for the next token.
• SEARCH: Typed query q
0
is issued to the under-
lying search system, and new results are retrieved.
SEARCH action results in following state transi-
tion: q
0
1
= q
0
1
∪ q
0
2
; q
0
2
=
/
0
Reward: During training, at every time-step t, the
agent receives reward r
t
based on (s
t
, a
t
). The re-
ward function is designed to encourage the agent to
improve the search result’s quality while keeping the
number of searches issued to the underlying retrieval
engine low. The agent receives a positive reward if
a SEARCH (S) action leads to an improvement in
Mean Average Precision (MAP) by more than a fixed
threshold R
th
. Otherwise, a constant penalty of -1
is imposed. The positive reward is directly propor-
tional to the improvement in map: ∆
MAP
. We treat
the threshold R
th
as a hyper-parameter and the actual
value is later stated in Section 4. Since the WAIT (W)
Deep Reinforcement Agent for Efficient Instant Search
283

Figure 2: The Bi-LSTM Siamese DQN network for calcu-
lating rewards for both WAIT and SEARCH actions. The
numbers represent the dimension of outputs generated by
each layer.
action does not affect the Quality and Total Searches,
the reward is set as 0. The following equation sum-
marizes the reward function:
R =
0, action = W
1 + ∆ MAP, action = S and ∆
MAP
≥ R
th
-1, action = S and ∆
MAP
< R
th
Bi-LSTM Deep Q Network: This section describes
the base network architecture, as shown in Figure 2
that calculates rewards for a given state. Input to
the model is the state, formulated as a pair of sub-
queries (q
1
, q
2
). Input tokens for each sub-query
are represented using pre-trained GloVe (Penning-
ton et al., 2014) word-embeddings, that are then
passed to a Bi-Directional Long Short-Term Mem-
ory (LSTM) (Hochreiter and Schmidhuber, 1997)
Siamese Encoder. Since both the sequences have
originated from the same query, it is intuitive to ap-
ply a Siamese Network that allows the sharing of Bi-
LSTM weights. The output vectors for both the sub-
queries are concatenated, and the final single feature
vector is fed to a fully-connected layer that generates
a two-dimensional vector representing the rewards for
both the actions. The whole network can be summa-
rized using the below equation:
u
1
= f
Bi-LST M
(q
1
);u
2
= f
Bi-LST M
(q
2
)
v
1
= relu(W
1
·u
1
+ b
1
);v
2
= relu(W
1
·u
2
+ b
1
)
H = [v
1
⊕ v
2
];R = W
2
·H + b
2
Inference: For every typed token during an instant
search session, a state is prepared as a pair of sub-
queries: prefix of the already searched query and suf-
fix that still needs to be searched. The state is passed
as an input to the trained model described in Figure 2.
The base model generates rewards for both WAIT and
SEARCH actions. The agent picks the action with the
best reward, and based on that, the search to the un-
derlying system is either skipped or triggered using
the query entered so far. The state for the agent is
updated accordingly, and the agent waits for the next
token. An episode terminates at the end of the query
session.
4 METRICS AND
EXPERIMENTAL SETUP
Metrics: We utilize the following metrics to evaluate
the performance of the proposed methods.
Average Number of Triggered Searches (TS) - System
Load: This metric represents the load on the search
system and is measured as the average number of re-
quests made to the search system during an instant
search session.
Average Effort: Studies (Cetindil et al., 2012; Chan-
dar et al., 2019) have found the Effort to be a very
crucial factor that differentiates an instant search user-
experience from a traditional search system. Effort
is defined as the minimum number of tokens that a
user would have to type to retrieve the best possible
ranking of results. Ranking quality is measured using
Mean Average Precision (MAP) and the best ranking
achieves the maximum MAP. Let N
q
be the number of
tokens in a given query q. n
q
is the minimum number
of tokens needed to retrieve the best possible ranking
for query q. Metric e f f ort is the average effort across
all queries in the dataset and is computed as follows:
e f f ort =
∑
n
q
≤ N
q
|
Q
|
∀q ∈ Q
Quality: We use MAP to capture the quality of the
results. MAP is calculated using the open source
PyTREC-Eval (Van Gysel and de Rijke, 2018) library.
Evaluation Procedure: To measure the TS vs. Ef-
fort trade-off, we simulate an action function in a real
instant search session for every query and keep track
of both the metrics. The action function returns an
action(WAIT and SEARCH) at every new token based
on the decision taken by the method being evaluated.
For instance, the SET(subsection 2) method would re-
turn SEARCH for every token in the query. TS is in-
cremented, and results get updated at every search.
For every query, we invoke the action function un-
til the retrieval has achieved the best possible MAP or
has reached the last token. The total number of tokens
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
284

used to achieve the best MAP is added to the Effort at
the end of the query session. For Quality, we keep
track of the MAP achieved at every token position for
all the queries.
Datasets: We have evaluated the methods on three IR
datasets: MS Marco passage ranking(Nguyen et al.,
2016), Wiki IR(Frej et al., 2019) 59k version and
InsuranceQA (Feng et al., 2015). InsuranceQA is
adapted to a pure Document Retrieval task using
(Tran and Niedere
´
ee, 2018). InsuranceQA is used in
order to test how well methods generalize to differ-
ent domains. To ensure that the underlying search
engine can retrieve relevant documents in top 1000
for enough queries, we have reduced the total number
of documents to 400k and 500k for MS Marco and
Wiki IR, respectively by random sampling. For In-
suranceQA, we use the full set of 27,413 documents.
The evaluation sets of size 1000 queries are kept un-
seen for all three datasets.
Retrievers: We conduct experiments using both the
BM25(Robertson and Zaragoza, 2009) and semantic-
based matching retrieval systems. For semantic re-
trieval, we use a transformer-based pre-trained sen-
tence encoding model known as Universal Sentence
Encoder (USE) (Cer et al., 2018) for representing the
queries and documents with embeddings and further
use cosine similarity to rank results.
Hyper-Parameters: For SM, we set a threshold of
0.1. For the proposed DQN agent, we trained the
model with following settings: future reward γ =
0.05, ε = 1, ε
decay
= 0.995, learning rate α = 0.01 and
ε
min
= 0.7. Furthermore, weights are learned using
Adam optimizer(Kingma and Ba, 2014) with a batch
size of 32. Reward threshold R
th
mentioned in the re-
ward section for determining the action is set to 0 for
MS Marco and Wiki IR and 0.0001 for Insurance QA.
5 RESULTS
TS vs. Effort: Table 1 shows the drop in Average
Number of Triggered Searches achieved by different
methods and compares it with extra Average Effort
introduced in the system. The top two rows high-
light the absolute values achieved by two basic search
systems: SLT, which mimics a traditional search en-
gine, and SET, representing a true instant search sys-
tem. These systems set the upper and lower bounds
respectively on Effort and TS. The bottom three rows
list down the percentage change in the metrics intro-
duced by the proposed methods with respect to a true
instant search system(SET).
Skip Stop-words method manages to achieve op-
timum Effort. This can be attributed to the fact that
generally, stop-words are not deemed salient in com-
mon language usage, allowing SS not to miss a search
for any salient words. On the other hand, since SS in-
fluences only a limited and fixed set of tokens, the
achieved TS is not up to the optimal. Also, the overall
performance of SM is quite comparable to SS. Results
also show that that the pre-trained model is unable to
transfer its knowledge to this new task.
While all the methods are able to retain the Ef-
fort within 5% of the SET, the proposed DQN method
manages to reduce the overall TS on average by more
than 20% across all the datasets compared to other
baselines. Compared to a pure instant search system,
DQN reduces the overall load by more than 50%. The
performance of DQN agent is directly proportional to
the training size of the dataset and hence is highest for
MS Marco.
Impact on Quality: We have captured the loss of
quality in results at every token position by plotting
the average MAP over all the queries at every token
position for the proposed DQN method and further
comparing it with the ideal SET instant search. Fig-
ure 3 plots the average MAP(y-axis) at every time-
step t(x-axis) for both SET and DQN. The plot shows
that the MAP achieved by DQN is very close to that
of SET at all the token positions, and hence the loss
in quality introduced is minimal.
Subjective Analysis: Lastly, we subjectively ana-
lyzed the predictions made on the unseen queries by
the learned model. Figure 4 lists queries with tokens
at which the search triggered is marked green. We
also report the incremental difference in MAP intro-
duced by the triggered search(highlighted as blue) to
capture the search action quality.
For MS Marco, besides stop-words, the agent
waits for the words “cost” , “install” and “purpose”.
MS Marco is a large QA dataset with verbose pas-
sages. It is difficult for a basic BM25 algorithm to re-
trieve a good ranking without additional context early
in the query; thus the model decides to wait. For the
first InsuranceQA query, the agent decides to execute
the search for the token “a” as in insurance jargon,
“vest a retirement plan” is a common phrase, and a
semantic model such as Universal Sentence Encoder
does not ignore this as a stop-word. The same is
not true for the second sentence where the search is
skipped for the same token. For WikiIR’s first query,
the phrase “chief justice” is often present as a whole
in documents, and any improvement in ranking con-
tributed by the phrase itself is already captured by the
first word “chief”. In the second example, the name
“juan carlos” is unique enough to retrieve relevant
documents; therefore, the token “i” is skipped.
Deep Reinforcement Agent for Efficient Instant Search
285
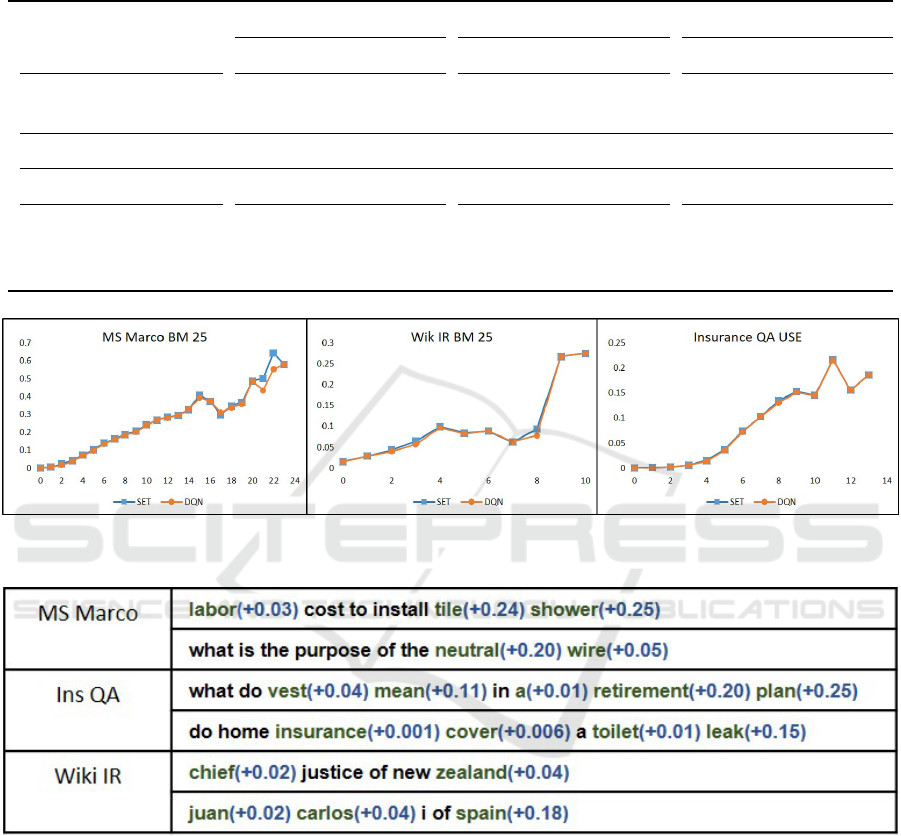
Table 1: Metrics achieved by different methods. Effort and TS metrics are averaged over all the queries. The top two rows
are the absolute values achieved by two base search systems. The bottom three rows list down the % change in the metrics
introduced by methods with respect to a true instant search system.
*
Statistical significance is tested using a two-tailed paired
t-test. We mark significant improvements when p < 0.01.
MS Marco - BM25 Wiki IR - BM25 Insurance QA - USE
Methods Effort TS Effort TS Effort TS
SLT (Regular Search) 10.76 1 5.83 1 8.25 1
SET (Instant Search) 8.24 8.24 4.74 4.74 7.70 7.70
Percentage change in metrics with respect to SET(Pure Instant Search)
∆Effort(%) ∆TS(%) ∆Effort(%) ∆TS(%) ∆Effort(%) ∆TS(%)
SS (Baseline) 0 -49.75 0 -22.62 0.59 -39.25
SM (Baseline) 4.00 -45.43 3.24 -26.88 1.50 -40.42
DQN (Proposed) 4.00 -74.15
*
3.94 -44.88
*
1.37 -55.47
*
Figure 3: Average MAP achieved by DQN vs. SET at every token position. X-axis is token index and Y-axis is MAP averaged
over all the queries.
Figure 4: Predictions of DQN Network on unseen queries.
6 CONCLUSION
This paper has introduced a Reinforcement Agent that
relieves the load on the back-end search system in
an instant search paradigm. Proposed agent achieves
the goal by learning word importance based on the
search system behavior and utilizes this knowledge
towards judiciously issuing searches to the underly-
ing retrieval system. We further evaluated the trade-
off between system load and performance. Experi-
ments demonstrate the ability of the proposed agent
to achieve near-optimal trade-off.
REFERENCES
Bast, H. and Weber, I. (2006). Type less, find more: fast
autocompletion search with a succinct index. In Pro-
ceedings of the 29th annual international ACM SIGIR
conference on Research and development in informa-
tion retrieval, pages 364–371.
Brin, S. and Page, L. (1998). The anatomy of a large-scale
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
286

hypertextual web search engine.
Cer, D., Yang, Y., Kong, S.-y., Hua, N., Limtiaco, N., John,
R. S., Constant, N., Guajardo-Cespedes, M., Yuan,
S., Tar, C., et al. (2018). Universal sentence encoder.
arXiv preprint arXiv:1803.11175.
Cetindil, I., Esmaelnezhad, J., Li, C., and Newman, D.
(2012). Analysis of instant search query logs. In
WebDB, pages 7–12. Citeseer.
Chandar, P., Garcia-Gathright, J., Hosey, C., St. Thomas,
B., and Thom, J. (2019). Developing evaluation met-
rics for instant search using mixed methods methods.
In Proceedings of the 42nd International ACM SIGIR
Conference on Research and Development in Informa-
tion Retrieval, pages 925–928.
Dean, J. (2009). Challenges in building large-scale informa-
tion retrieval systems. In Keynote of the 2nd ACM In-
ternational Conference on Web Search and Data Min-
ing (WSDM), volume 10.
Fafalios, P., Kitsos, I., and Tzitzikas, Y. (2012). Scal-
able, flexible and generic instant overview search. In
Proceedings of the 21st International Conference on
World Wide Web, pages 333–336.
Fafalios, P. and Tzitzikas, Y. (2011). Exploiting available
memory and disk for scalable instant overview search.
In International Conference on Web Information Sys-
tems Engineering, pages 101–115. Springer.
Fagni, T., Perego, R., Silvestri, F., and Orlando, S. (2006).
Boosting the performance of web search engines:
Caching and prefetching query results by exploiting
historical usage data. ACM Transactions on Informa-
tion Systems (TOIS), 24(1):51–78.
Feng, M., Xiang, B., Glass, M. R., Wang, L., and Zhou, B.
(2015). Applying deep learning to answer selection:
A study and an open task. In 2015 IEEE Workshop
on Automatic Speech Recognition and Understanding
(ASRU), pages 813–820. IEEE.
Frej, J., Schwab, D., and Chevallet, J.-P. (2019). Wikir:
A python toolkit for building a large-scale wikipedia-
based english information retrieval dataset. arXiv
preprint arXiv:1912.01901.
Gan, Q. and Suel, T. (2009). Improved techniques for re-
sult caching in web search engines. In Proceedings of
the 18th international conference on World wide web,
pages 431–440.
Gomaa, W. H., Fahmy, A. A., et al. (2013). A survey of
text similarity approaches. International Journal of
Computer Applications, 68(13):13–18.
Grissom II, A., He, H., Boyd-Graber, J., Morgan, J., and
Daum
´
e III, H. (2014). Don’t until the final verb
wait: Reinforcement learning for simultaneous ma-
chine translation. In Proceedings of the 2014 Confer-
ence on empirical methods in natural language pro-
cessing (EMNLP), pages 1342–1352.
Gu, J., Neubig, G., Cho, K., and Li, V. O. (2016). Learning
to translate in real-time with neural machine transla-
tion. arXiv preprint arXiv:1610.00388.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term
memory. Neural computation, 9(8):1735–1780.
Ji, S., Li, G., Li, C., and Feng, J. (2009). Efficient interac-
tive fuzzy keyword search. In Proceedings of the 18th
international conference on World wide web, pages
371–380.
Kingma, D. P. and Ba, J. (2014). Adam: A
method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Li, G., Ji, S., Li, C., and Feng, J. (2011). Efficient
fuzzy full-text type-ahead search. The VLDB Journal,
20(4):617–640.
Li, G., Wang, J., Li, C., and Feng, J. (2012). Supporting
efficient top-k queries in type-ahead search. In Pro-
ceedings of the 35th international ACM SIGIR con-
ference on Research and development in information
retrieval, pages 355–364.
Long, X. and Suel, T. (2006). Three-level caching for ef-
ficient query processing in large web search engines.
World Wide Web, 9(4):369–395.
Markatos, E. P. (2001). On caching search engine query
results. Computer Communications, 24(2):137–143.
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A.,
Antonoglou, I., Wierstra, D., and Riedmiller, M.
(2013). Playing atari with deep reinforcement learn-
ing. arXiv preprint arXiv:1312.5602.
Nguyen, T., Rosenberg, M., Song, X., Gao, J., Tiwary,
S., Majumder, R., and Deng, L. (2016). Ms marco:
A human-generated machine reading comprehension
dataset.
Pennington, J., Socher, R., and Manning, C. D. (2014).
Glove: Global vectors for word representation. In
Proceedings of the 2014 conference on empirical
methods in natural language processing (EMNLP),
pages 1532–1543.
Robertson, S. and Zaragoza, H. (2009). The probabilistic
relevance framework: BM25 and beyond. Now Pub-
lishers Inc.
Saraiva, P. C., Silva de Moura, E., Ziviani, N., Meira, W.,
Fonseca, R., and Ribeiro-Neto, B. (2001). Rank-
preserving two-level caching for scalable search en-
gines. In Proceedings of the 24th annual international
ACM SIGIR conference on Research and development
in information retrieval, pages 51–58.
Satija, H. and Pineau, J. (2016). Simultaneous machine
translation using deep reinforcement learning. In
ICML 2016 Workshop on Abstraction in Reinforce-
ment Learning.
Tran, N. K. and Niedere
´
ee, C. (2018). Multihop attention
networks for question answer matching. In The 41st
International ACM SIGIR Conference on Research
& Development in Information Retrieval, pages 325–
334.
Van Gysel, C. and de Rijke, M. (2018). Pytrec eval: An ex-
tremely fast python interface to trec eval. In The 41st
International ACM SIGIR Conference on Research
& Development in Information Retrieval, pages 873–
876.
Venkataraman, G., Lad, A., Guo, L., and Sinha, S. (2016a).
Fast, lenient and accurate: Building personalized in-
stant search experience at linkedin. In 2016 IEEE In-
ternational Conference on Big Data (Big Data), pages
1502–1511. IEEE.
Deep Reinforcement Agent for Efficient Instant Search
287

Venkataraman, G., Lad, A., Ha-Thuc, V., and Arya, D.
(2016b). Instant search: A hands-on tutorial. In Pro-
ceedings of the 39th International ACM SIGIR con-
ference on Research and Development in Information
Retrieval, pages 1211–1214.
Wang, J., Cetindil, I., Ji, S., Li, C., Xie, X., Li, G., and Feng,
J. (2010). Interactive and fuzzy search: a dynamic way
to explore medline. Bioinformatics, 26(18):2321–
2327.
Watkins, C. J. and Dayan, P. (1992). Q-learning. Machine
learning, 8(3-4):279–292.
Yang, W., Xie, Y., Lin, A., Li, X., Tan, L., Xiong, K.,
Li, M., and Lin, J. (2019). End-to-end open-domain
question answering with bertserini. arXiv preprint
arXiv:1902.01718.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
288
