
PhotoRestorer: Restoration of Old or Damaged Portraits with Deep
Learning
Christopher Mendoza-D
´
avila, David Porta-Montes and Willy Ugarte
a
Department of Computer Science, Universidad Peruana de Ciencias Aplicadas, Lima, Peru
Keywords:
Photo Restoration, GAN, Image Inpainting, CNN, Image Classification, Deep Learning, Machine Learning
Models.
Abstract:
Several studies have proposed different image restoration techniques, however most of them focus on restoring
a single type of damage or, if they restore different types of damage, their results are not very good or have
a long execution time, since they have a large margin for improvement. Therefore, we propose the creation
of a convolutional neural network (CNN) to classify the type of damage of an image and, accordingly, use
pretrained models to restore that type of damage. For the classifier we use the transfer learning technique
using the Inception V3 model as the basis of our architecture. To train our classifier, we used the FFHQ
dataset, which is a dataset of people’s faces, and using masks and functions, added different types of damage
to the images. The results show that using a classifier to identify the type of damage in images is a good
pre-restore option to reduce execution times and improve restored image results.
1 INTRODUCTION
Photography as we know it today has its beginnings
in the late 1830s in France, where Joseph Nic
´
ephore
Ni
´
epe using a portable camera obscura made the first
photograph that did not fade rapidly. Thus, thanks to
the camera, different historical moments of human-
ity could be retained in time. However, despite the
fact that the photographs can last several years, this
does not imply that they may suffer damage from
other sources such as exposure to the environment or
poor conservation practices. InstaRestoration
1
men-
tions that there are different types of damage caused
by these sources, such as scratches and cracks, bro-
ken parts, missing parts, changes in colors and dis-
coloration. Because of this, today there are countless
old, historical or family photos damaged by these bad
conservation practices.
While there are different methods of restoring
photos today, these methods are not accessible to ev-
eryone. Whether for money or lack of knowledge due
to, most of the people who own this damaged pho-
tographs are non-digital, and the existent methods can
be very cumbersome for many people (Ullah et al.,
a
https://orcid.org/0000-0002-7510-618X
1
“How to assess the damage of an old photograph” - In-
staRestoration - https://www.instarestoration.com/blog/ho
w-to-assess-the-damage-of-an-old-photograph
2019; Zhang et al., 2020a; Luo et al., 2021; Jiao et al.,
2022; Sun et al., 2022). Consequently, currently there
are not many accessible tools that can be used by any-
one to restore old photos, which means that many of
these photos cannot be restored and are lost over time
causing cultural and historical losses.
Among the most used techniques for restoring
photographs we have, on the one hand, digital restora-
tion, which consists of digitally scanning the photo to
be restored and then using tools such as Adobe Photo-
shop to restore the photo. This method of restoration
requires time and technical knowledge in this type
of tools. Thus, the result of the restoration will de-
pend on who is responsible for it. On the other hand,
we have restoration using Machine Learning models.
These models are trained with thousands of photos
to be able to restore a photograph. Although the pro-
cess of training a model also requires time and knowl-
edge in this field, today there is a wide variety of pre-
trained models available for everything from improv-
ing quality to restoring cracks and giving color to old
photos (Shen et al., 2019; Wan et al., 2023). There are
even pre-trained models that are capable of regenerat-
ing images of scientific interest, even written charac-
ters (Ferreira et al., 2022; Furat et al., 2022; Su et al.,
2022; su Jo et al., 2021).
As mentioned, there are different models of restor-
ing images. For example, in (Rao et al., 2023) pro-
104
Mendoza-Dávila, C., Porta-Montes, D. and Ugarte, W.
PhotoRestorer: Restoration of Old or Damaged Portraits with Deep Learning.
DOI: 10.5220/0012190000003584
In Proceedings of the 19th International Conference on Web Information Systems and Technologies (WEBIST 2023), pages 104-112
ISBN: 978-989-758-672-9; ISSN: 2184-3252
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

pose a regressive model called MS-GAN to recon-
struct images, which is based on a Generative Ad-
versarial Network (GAN) and consists of two phases:
The first phase consists of reconstructing the im-
age from the edges and domains of color. The sec-
ond phase is responsible for improving the qual-
ity of the reconstructed image. This technique can
achieve high-quality reconstructed images using only
the edges and color domains of the image as input.
However, there are some negative results with images
that contain a lot of details, in this case the difficulty
of the reconstruction will increase and therefore the
quality of the image will decrease. On the other hand
in (Nogales et al., 2021) propose a model called ARQ-
GAN to restore images of ancient architectural struc-
tures, which is a neural network that locates the parts
of the image where information is missing in order
to later complete it, adding the missing elements ac-
cording to their architectural style and the distribution
denoting the ruins. The model is capable of restoring
these ancient structures contained in the images, how-
ever, as in the previous case, it is not capable of accu-
rately restoring parts where the structure is very de-
tailed. Likewise, by not knowing exactly what these
ancient structures that are being restored looked like
and only basing ourselves on the opinion of experts, it
is difficult to know exactly if the restoration is correct.
For those reasons, in our project, we are using ma-
chine learning models and different frameworks like
Flask and React Native to create a free and easy to
use mobile app for photo restoration. One of the tech-
niques to be used are Generative adversarial networks
(GAN), a type of algorithm used for unsupervised
learning. It consists of the combination of two neu-
ral networks in which there is a generator and a dis-
criminator, where, based on a series of samples, the
generator tries to create images that make the discrim-
inator believe that they are real (Cheng et al., 2020).
With this technique, certain parts of the photographs
that have lost quality or are damaged can be recon-
structed. On the other hand, if we want to reconstruct
missing parts or cracks in the photograph, there is Im-
age Inpainting, which according to (Qin et al., 2021),
defines it as the process that is applied to images in
order to fill in holes or missing parts (such as cracks)
through the analysis of the edges of the missing part.
In this project, we are creating an image classificator
to detect what process should be applied to the im-
age given by the user and restore that image with just
one button, however, internet access will always be
needed.
We propose a new approach to restore old or dam-
aged portraits. On one hand, we create a classifica-
tion model based on a Convolutional Neural Network
(CNN) to detect if the photograph either has cracks or
is blurred, or both. Thus, according to the classifica-
tion, different pre-trained and specialized models will
be called to restore the type of damage found. Fur-
thermore, to carry out this classifier, it was also nec-
essary to create a dataset of 12,000 images of people’s
faces, based on the FFHQ dataset, using masks and a
Gaussian filter, to simulate damage on the portraits.
In addition, a mobile application was built with the
models, so people can use them to restore their most
precious photos.
To summarize, our main contributions are as fol-
lows:
• Implementing a CNN model to classify different
types of damage from a portrait.
• A pipeline structure to restore a damaged portrait.
• Building a large dataset of face images with dif-
ferent types of damage.
The rest of this paper is structured as follows. Sec-
tion 2 presents some related works for image restora-
tion. Section 3 presents the methodology to develop
our proposed method. Section 4 shows the experi-
ments and results of the proposed method. Finally,
section 5 closes with conclusions and perspectives.
2 RELATED WORKS
In this section, we will see five projects where the au-
thors use some techniques that are going to be used
in this paper like GANs and Image Inpainting, these
investigations are useful because they work as an in-
spiration in the development of our project. Thus, in
order to reduce the damage not only in photos but
in images in general, several recent scientific articles
have focused their attention on GANs as a technique
to solve this problem.
In (Rao et al., 2023) the authors proposed a novel
progressive model for the image reconstruction task,
called MS-GAN, which uses an enhanced U-net as
a generator. The MS-GAN can achieve high qual-
ity and refined reconstructed images using the input
of binary sparse edges and color domains. The MS-
GAN training process consists of two phases: the gen-
eration phase and the refinement phase. The gener-
ation phase is to use binary sparse edges and color
domains to generate the preliminary images. The re-
finement phase is to further improve the quality of
the preliminary images. The results of the MS-GAN
shows that it can achieve high-quality reconstructed
images using only the input of binary sparse edges
and color domains. However, since every method is
not absolute, some representative negative results are
PhotoRestorer: Restoration of Old or Damaged Portraits with Deep Learning
105

presented. For example, when the images to be re-
constructed contain many rich details, the difficulty
of image reconstruction will increase rapidly and the
quality of these reconstructed images will decrease.
This approach is similar in one of the cases of our
project, which is to improve the image quality. Since
our project is the restoration of old or damaged pho-
tos, this is an important aspect for us, but it does not
cover the full scope of our project.
In (Cao et al., 2020), an attempt is made to restore
Chinese Ancient Murals that were damaged by the
passage of time and now have some fissures or cracks
that do not allow the correct appreciation that it de-
serves due to its religious, cultural and artistic impor-
tance. The authors propose the use of a GAN with
improved consistency to repair the missing parts of
the mural. In addition, the first layers of the network
apply convolutions to extract the characteristics of the
mural. As a result, they had a high SSIM score (0.85
in average) compared to other studies, this metric in-
dicates the similarity between the original image and
the one generated by the network where a higher score
means better quality. Comparing this paper to ours,
we have a small similarity in the process, we pretend
that the user will take a picture or upload a damaged
imaged, and we are going to restore it, but centering
in facial restoration instead of murals. Another impor-
tant difference with our project is that their architec-
ture uses only GANs to restore the mural, and we are
proposing a classifier that can determine if an image
might need image inpainting and GAN to be applied.
In (Shen et al., 2019), they propose a multitask model,
which, unlike a single task model, is capable of opti-
mizing more than one task in parallel learning. This
consists of an end-to-end Convolutional Neural Net-
work (CNN) to learn effective features of the blurred
face images and then estimate a latent one. Likewise,
the different tasks are capable of sharing the weight
of the image to be processed for a better result. Talk-
ing about metrics, they used the CelebA and Helen
dataset to compare it with other state-of-the-art mod-
els, the results show that the multitasking model has a
higher average PSNR and SSIM than the others (24
and 0.87 respectively), this demonstrates both high
quality and similarity of the generated image and the
original. Therefore, this model presents an alternative
to our project; although it focuses on facial restora-
tion, it is limited to deblurring and does not cover the
reconstruction of missing parts as ours. One impor-
tant difference in architecture is that they have a CNN
combined with a GAN to guarantee the deblurr, we
propose an image classifier capable of determining if
an image should use image inpainting or GAN for fa-
cial restoration.
In (Nogales et al., 2021), the contribution of the au-
thors is the ARQGAN network that locates the parts
of the image where information is missing in order
to later complete it, adding the missing elements ac-
cording to their architectural style and the distribution
denoted by the ruins. The process of this solution is
based on two different ways of restoring. In the first,
images of the ruins are used to rebuild Greek tem-
ples, being the baseline. In the second, a segmented
image is used as additional information for the re-
construction of a temple. After applying filters when
combining both methods to form the image of a tem-
ple, it would be evaluated by the discriminator model,
causing the generator to learn from its mistakes. In
both cases, the same conclusion was reached: the
segmented training was more efficient than the direct
one. Although this does not mean that the system is
perfect, it still needs to improve in terms of restoring
more precise parts of architectural constructions. Al-
though this proposal uses a GAN for restoration, it
differs quite a bit from our project, since it is aimed
at restoring images of old structures while our project
focuses on restoring portraits. Even so, the use of a
segmented image to improve the restoration is a very
interesting technique that could be used for a possible
improvement in our solution.
In (Yuan et al., 2019), the authors propose a frame-
work for image completion based on Patch-GAN that
is a type of discriminator for GANs which only pe-
nalizes structure at the scale of local image patches.
It is composed of a generator, multi-scale discrimi-
nators, and an edge processing function, which can
extract holistic and structured features from damaged
images. Compared to existing methods that only use
holistic features, the proposed method learns more de-
tails from the given image and achieves more realis-
tic results, especially in restoration of human faces.
The process generally consists of three steps. First,
one must go through the architecture of the model
that aims to receive the masked image and generate
the missing context that is consistent with its sur-
roundings while maintaining a high level of realism.
They then go through the loss functions, where the
reconstruction loss and global guidance loss provide
the holistic information of the damaged images to the
generator, and the local guidance and edge loss moti-
vate the model to obtain the information of the image
structure. Finally, they go through the optimization
phase where the goal is to find the best encoding of
the masked input, that is, the generator produces the
closest image to the one that was originally inserted.
The authors conclude that the model is suitable for
different types of datasets and obtains the best perfor-
mance in the restoration of human faces. As a result,
WEBIST 2023 - 19th International Conference on Web Information Systems and Technologies
106
the PSNR and SSIM stand out, where they obtained
favorable ratings on a wide variety of datasets. This
approach is similar to ours for the part of restoring
cracks and missing parts of an image. However, we
also focus on improving the quality of the images of
the user, that is why we use more than one model to
restore the portraits.
3 MAIN CONTRIBUTION
3.1 Context
Before we start, it is important to have some def-
initions in mind. In this section, we will see what
we mean when we refer to a Convolutional Neural
Network (CNN) that we are going to use as our
classifier, Image Inpainting method and Generative
Adversarial Network (GAN).
Definition 1 (CNN (Fu, 2021; Wang, 2022)). Is
mainly used for image classification methods because
it can extract information and features from images
and learn from these patterns in order to perform
classification tasks based on these found patterns.
Example 1. In Figure 1 shows the basic structure of
a convolutional neural network (CNN).
Figure 1: CNN structure by (Tropea and Fedele, 2019).
Definition 2 (Image Inpainting (Yuan et al., 2019;
Liang et al., 2021; Fanfani et al., 2021; Chen et al.,
2021)). Is an algorithm that receives a damaged
image with a missing part as input, then analyzes
the edges of the missing part (nearest neighbors)
and tries to reconstruct it based on all the analysis
performed. This technique has multiple cultural
applications, since it can help to reconstruct ancient
murals or even images of high historical value
(Poornapushpakala et al., 2022; Liu, 2022; Zeng
et al., 2020; Cao et al., 2020). In this paper, we
will make use of image inpainting to be able to
reconstruct cracks or even missing parts of an image,
always giving priority to facial restoration.
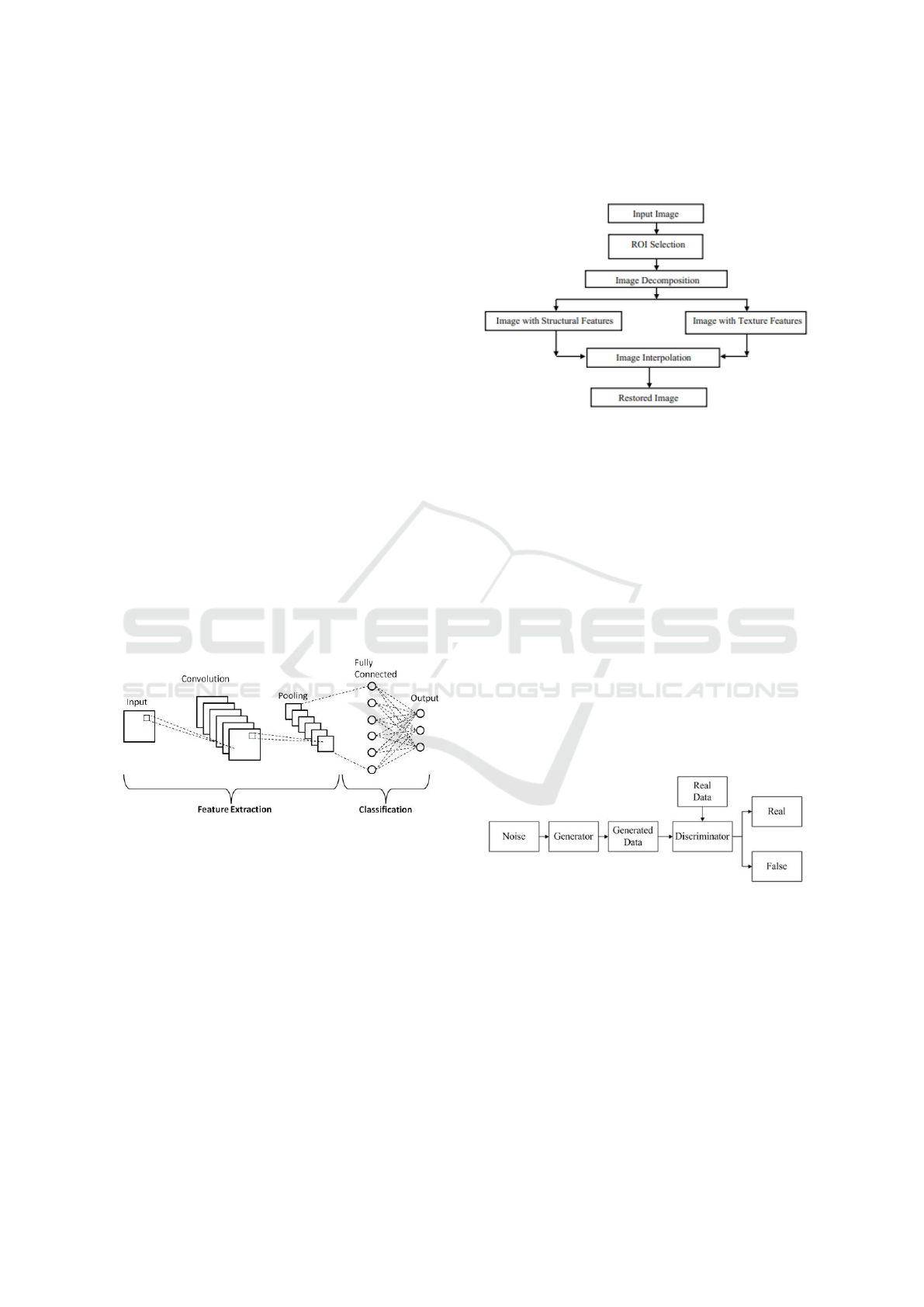
Example 2. In Figure 2 a flowchart about the image
inpainting technique is shown.
Figure 2: Flowchart of Inpainting technique by (Poorna-
pushpakala et al., 2022).
Definition 3 (GAN (Cao et al., 2020; Fu, 2021; Zhang
et al., 2020b)). Is a type of unsupervised neural net-
work that is composed of two networks. The first is
a generating network, which is in charge of generat-
ing the image from random noise. The second is a
discriminator network, which is in charge of evaluat-
ing whether the generated image is a real image or a
generated one. To do this, the discriminator receives
as input data the generated image and the real image
and evaluate if the two images are similar or not. The
idea here is that the generating network is capable
of generating images capable of making the discrimi-
nating network believe that the generated image is the
real one.
Example 3. In Figure 3 shows the basic structure of
a generative adversarial network (GAN).
Figure 3: GAN structure by (Cao et al., 2020).
3.2 Method
In this section, the main contributions proposed in
this project will be detailed, including the use of pre-
trained models and the integration with the mobile
app.
3.2.1 Classifier Architecture
The main contribution of this research is the classifi-
cation model. This classifier is in charge of detecting
PhotoRestorer: Restoration of Old or Damaged Portraits with Deep Learning
107

Figure 4: Dataset separation for classifier training.
the type of damage that the input image has, then clas-
sifies it into three classes: Blurred, Cracked and both
cases. According to the class detected, the application
will call the API of a pre-trained model that special-
izes in restoring that type of damage.
To create our classifier, we used Transfer Learning, a
method that allows transferring acquired knowledge
from one network to another. The base architecture
we used was Inception V3, a type of Convolutional
Neural Network (CNN), with pre-trained weights that
are useful for image analysis and object detection as
shown in Figure 1. We added an input layer to receive
a 512x512 image, finally, as an output layer, we have
a 1x1x3 value representing the type of damage. This
model was exported with the ’h5’ extension, so it can
be deployed in our backend.
3.2.2 Dataset Building
In order to train a model to classify the type of dam-
age, we developed our own dataset based on an ex-
isting one. The Flickr Faces HQ (FFHQ) Dataset
consists of 70,000 high-quality PNG images, we ran-
domly selected 12,000 images and separated it in 3
groups. In Figure 4 shows the group separation used
to train the image classifier, it should be noted that
each group had 4,000 images.
• First group: a Gaussian noise filter was applied to
add blur to the image.
• Second group: we applied masks that simulated
the cracks and damage
• Third group: a combination of both to simulate a
totally damaged image
3.2.3 Model Architecture
In Figure 5, we can see the main process when the
user submits an image through the application.
• Upload Image: From the application, the user
sends an input image, which can be in PNG or
JPG format. This image is sent to our server
(backend) and it can be taken from your smart-
phone camera or can be uploaded from your
gallery.
Figure 5: Architecture flow.
• Classifier: The image is classified according to the
type of damage found by the classification model.
The types of damage can be: Blurred, Cracked
and both cases.
• API Call: According to the type of damage found
by the classifier, the application will call the API
of a trained model specialized in restoring this
type of damage. In case is blurred, the app will
call the GFP-GAN model, in case is cracked, the
app will call the Image Inpainting model and, if
the image has both types of damage, the app will
call first Image Inpainting and second GFP-GAN.
• Download and Share: After restoring the image,
the application allows you to download the image
to your smartphone or share it on your social net-
works.
3.2.4 Architecture of the Application:
Backend-Frontend Integration
As we can see in Figure 6, we decided to separate the
restoration models with the image classifier (backend)
of the application (frontend).
The backend consists of an API that receives an im-
age which will be sent by the user, then it is recog-
nized by the classifier that identifies the type of dam-
age and, depending on the result, it is sent to one or
both restoration models. As a result, a JSON object is
sent to the frontend with the link of the restored image
and the type of damage identified by the classifier.
For the deployment, we used a free plan from Python
Anywhere, inside this server we have all our python
scripts and the H5 model of the classifier, this server
is running all day, every day, for 3 months, the con-
nection with the frontend (app) is through an API call.
The frontend consists of the development of the
application, here we have different files using React
Native with Expo, the connection with the backend
was made with an API call, we choose the Expo SDK
because it provides different tools with native An-
droid functionalities such as its camera, gallery and
file sharing.
To summarize, we deployed the restoration models
and image classifier in a backend server that is con-
nected to the Android application through an API.
WEBIST 2023 - 19th International Conference on Web Information Systems and Technologies
108

Figure 6: Architecture of the application.
4 EXPERIMENTS
4.1 Experimental Protocol
To develop our project, we divided the development
into 4 pieces, the backend where we have the restora-
tion functionality, the server where we deployed our
backend, the frontend to create the app and a mobile
phone where we put all together.
• Backend: The Python programming language was
used in its version 3.10.7, the Flask libraries used
for the development of the API server were Pillow
for image manipulation, Dotenv for the creation of
hidden variables, Keras for the use of our classi-
fier in ’h5’ format and Replicate to be able to use
the pre-trained models of GFP-GAN and Image
Painting.
• Server Deployment: We use the free plan offered
by the Python Anywhere website, this platform
offers a free plan for up to 3 months; however,
this plan does not allow the use of a GPU, so all
the processes carried out by the classifier run on
the CPU provided by the website; likewise, the
platform support team had to be contacted to be
able to add the Replicate API to its ’White List’
and thus be able to send the links in JSON format
to the frontend.
• Frontend: We use React Native 0.71 and Re-
act 18.2, this accompanied by the Expo 48 SDK
which allows us to use native Android function-
alities. Most of the libraries used belong to de
Expo SDK and an extra library is Feather to use
some vector icons. To export the application, we
used the Expo Application Services (EAS), which
Figure 7: Accuracy of the classification model.
through command lines is capable of gathering all
the files used in the frontend and generating an in-
staller (APK).
• Mobile phone: To test all the functionalities, we
used an OnePlus 7 pro with Android 10, to install
the APK you have to download the file from our
Google Drive Folder or Github because it is not
deployed on the Play Store. Having the APK the
installation is simple and some permissions to ac-
cess the files and camera will be asked in order
to use the app. It is important to know that this
application will run in all Android devices with
Android 5 or more.
4.2 Results
4.2.1 Classifier Accuracy
To measure the performance of our model, we use the
cross-validation technique, which is a technique that
helps us compare the accuracy of the model with re-
spect to the training data and the validation data. Fig-
ure 7 shows the accuracy of the model throughout the
ten training epochs. Thus, it can be seen that the accu-
racy of the validation data started with a value of 0.99,
which is quite a high value. This is mainly because
the Transfer Learning technique was used to train the
model, this technique uses the structure of a network
with already trained weights and is used as the basis
for the creation of our own convolutional network. At
the end of the training, it is observed that the accu-
racy had a value of more than 0.995, which indicates
a very good performance of the model.
4.2.2 Classifier Labels
It is important that our classifier works correctly, since
in this way the application will know which restora-
tion model to call according to the type of damage.
PhotoRestorer: Restoration of Old or Damaged Portraits with Deep Learning
109

Figure 8: Classification of portraits.
This will help reduce the restore wait time signifi-
cantly. Thus, in figure 8 some examples of the differ-
ent classes of our classifier are shown. For a portrait
with cracks, our model classifies it as “Cracked Im-
age”, for a blurred one it classifies as “Blurred Image”
and for one with both types of damage it classifies as
“Blurred and Cracked Image”.
4.2.3 Execution Time
Regarding the execution time of the restoration mod-
els, we have measured both models and the results can
be seen in table 1. Thus, it is observed that the GFP-
GAN model, which restores blurred images, has an
average execution time of 2.59 seconds, a minimum
time of 1 second and a maximum time of 8.4 seconds.
On the other hand, the Image Inpainting model used
to restore cracked images has an average execution
time of 55.38 seconds, a minimum time of 32 sec-
onds, and a maximum time of 67.4 seconds.
Table 1: Execution time of restoration models.
Min Average Max
Image Inpainting 32.000 55.380 67.400
GFP-GAN 1.000 2.591 8.400
4.2.4 Quantitative Results
If the image to be restored is classified with both types
of damage, the application will call both models for
its restoration, that is, both the GFP-GAN model and
the Image Inpainting model. In order to know which
of the models to use first and obtain the best result,
Table 2: Execution time of restoration models.
PSNR
Image Inpainting + GFP-GAN 24.016
GFP-GAN + Image Inpainting 23.162
both cases were evaluated using the Peak Signal-to-
Noise Ratio (PSNR) metric, which evaluates the de-
gree of distortion or noise of the generated image with
respect to the real image. Thus, the higher the PSNR
value, the higher the quality of the generated or re-
constructed image. Table 2 shows that if we first use
the GFP-GAN model and then the Image Inpainting
model, a PSNR of 23.16 is obtained, while if we first
use the Image Inpainting model and then the GFP-
GAN model, a PSNR of 24.02 is obtained.
4.3 Discussion
According to the results obtained in figure 7, we can
affirm that using the transfer learning technique for
image classification is very convenient, since a high
accuracy is obtained, which indicates a good result in
image classification. This is thanks to the fact that,
by using the structure of a model with already trained
weights as the base of our model, it is not necessary
to train these weights again from scratch. Thus, the
amount of time required for training and the amount
of data required for this training are also reduced.
The use of the classifier also helps to reduce the time
needed for restoration, since according to the classi-
fication of the image, the application will only call
the required model to restore that particular type of
damage. Observing figure 1, we can conclude that
the Image Inpainting model, which is responsible for
restoring cracks, is the one that has a longer execu-
tion time with respect to the GFP-GAN model, which
is responsible for restoring the blurred images. Like-
wise, it can be concluded that, if the image has both
types of damage, this will be the one that will require
a longer execution time for the restoration. In addi-
tion to the longer time required to restore an image
with both types of damage, it was necessary to know
which model to use first to get the best possible re-
sults. From the data seen in Figure 2, it can be con-
cluded that the best way to restore an image with both
types of damage is to use the Image Inpainting model
first and then the GFP-GAN model, since this combi-
nation has a higher PSNR. than the opposite combi-
nation.
WEBIST 2023 - 19th International Conference on Web Information Systems and Technologies
110

5 CONCLUSIONS AND
PERSPECTIVES
In conclusion, the use of a classifier to identify the
type of damage of an image and, consequently, calling
pre-trained models to restore the damage type found
in the image, shows very good results. Knowing what
kind of damage the image has avoids having to call
overly complex and time-consuming models to re-
store minor damage to an image. Therefore, it is nec-
essary to train a very good classifier model. Thus, the
use of the transfer learning technique has been shown
to have very good results in the creation of image clas-
sifiers, in addition, requiring less training time and
data for it. Since generative models are applied to
more domains (Pautrat-Lertora et al., 2022).
Furthermore, it has been shown that when an im-
age has several types of damage, it is necessary to
know in what order to use the different models re-
sponsible for restoring the different types of damage,
since the incorrect order of the use of these models
leads to a lower quality in the restored image. Thus,
to know which model to use first in case the image has
several types of damage, the PSNR and SSIM metrics
can be used.
While a classifier is a good first choice for restor-
ing an image based on the type of damage, our clas-
sifier only classifies if an image is blurry, has cracks,
or both types of damage. Therefore, as future work,
more types of damage could be established for the
classifier, such as lack of color, missing parts of an
image, water damage, among others. Also, you could
create a restore model that is capable of restoring all
kinds of damage from an image, although this might
cause a very high execution time, which might not
be very convenient if you plan to use the model in
some application for people’s daily use, similar to
(Ysique-Neciosup et al., 2022; Castillo-Arredondo
et al., 2023).
REFERENCES
Cao, J., Zhang, Z., Zhao, A., Cui, H., and Zhang, Q. (2020).
Ancient mural restoration based on a modified gener-
ative adversarial network. Heritage Science, 8(1):7.
Castillo-Arredondo, G., Moreno-Carhuacusma, D., and
Ugarte, W. (2023). Photohandler: Manipulation of
portrait images with stylegans using text. In ICSBT,
pages 73–82. SCITEPRESS.
Chen, Y., Liu, L., Tao, J., Xia, R., Zhang, Q., Yang, K.,
Xiong, J., and Chen, X. (2021). The improved image
inpainting algorithm via encoder and similarity con-
straint. Vis. Comput., 37(7):1691–1705.
Cheng, J., Yang, Y., Tang, X., Xiong, N., Zhang, Y.,
and Lei, F. (2020). Generative adversarial networks:
A literature review. KSII Trans. Internet Inf. Syst.,
14(12):4625–4647.
Fanfani, M., Colombo, C., and Bellavia, F. (2021). Restora-
tion and enhancement of historical stereo photos. J.
Imaging, 7(7):103.
Ferreira, I., Ochoa, L., and Koeshidayatullah, A. (2022).
On the generation of realistic synthetic petrographic
datasets using a style-based GAN. Scientific Reports,
12(1).
Fu, X. (2021). Research and application of ancient chinese
pattern restoration based on deep convolutional neural
network. Comput. Intell. Neurosci., 2021:2691346:1–
2691346:15.
Furat, O., Finegan, D. P., Yang, Z., Kirstein, T., Smith, K.,
and Schmidt, V. (2022). Super-resolving microscopy
images of li-ion electrodes for fine-feature quantifica-
tion using generative adversarial networks. npj Com-
putational Materials, 8(1).
Jiao, Q., Zhong, J., Liu, C., Wu, S., and Wong, H.
(2022). Perturbation-insensitive cross-domain image
enhancement for low-quality face verification. Inf.
Sci., 608:1183–1201.
Liang, B., Jia, X., and Lu, Y. (2021). Application of adap-
tive image restoration algorithm based on sparsity of
block structure in environmental art design. Complex.,
2021:9035163:1–9035163:16.
Liu, L. (2022). Computer-aided mural digital restoration
under generalized regression neural network. Mathe-
matical Problems in Engineering, 2022:1–8.
Luo, X., Zhang, X. C., Yoo, P., Martin-Brualla, R.,
Lawrence, J., and Seitz, S. M. (2021). Time-travel
rephotography. ACM Trans. Graph., 40(6):213:1–
213:12.
Nogales, A., Delgado-Martos, E., Melchor,
´
A., and Garc
´
ıa-
Tejedor,
´
A. J. (2021). ARQGAN: an evaluation of
generative adversarial network approaches for auto-
matic virtual inpainting restoration of greek temples.
Expert Syst. Appl., 180:115092.
Pautrat-Lertora, A., Perez-Lozano, R., and Ugarte, W.
(2022). EGAN: generatives adversarial networks for
text generation with sentiments. In KDIR, pages 249–
256. SCITEPRESS.
Poornapushpakala, S., Barani, S., Subramoniam, M., and
Vijayashree, T. (2022). Restoration of tanjore paint-
ings using segmentation and in-painting techniques.
Heritage Science, 10(1).
Qin, Z., Zeng, Q., Zong, Y., and Xu, F. (2021). Image in-
painting based on deep learning: A review. Displays,
69:102028.
Rao, J., Ke, A., Liu, G., and Ming, Y. (2023). MS-GAN:
multi-scale GAN with parallel class activation maps
for image reconstruction. Vis. Comput., 39(5):2111–
2126.
Shen, Z., Xu, T., Zhang, J., Guo, J., and Jiang, S. (2019). A
multi-task approach to face deblurring. EURASIP J.
Wirel. Commun. Netw., 2019:23.
Su, B., Liu, X., Gao, W., Yang, Y., and Chen, S. (2022).
A restoration method using dual generate adversarial
PhotoRestorer: Restoration of Old or Damaged Portraits with Deep Learning
111

networks for chinese ancient characters. Vis. Infor-
matics, 6(1):26–34.
su Jo, I., bin Choi, D., and Park, Y. B. (2021). Chinese
character image completion using a generative latent
variable model. Applied Sciences, 11(2):624.
Sun, Q., Guo, J., and Liu, Y. (2022). Face image synthesis
from facial parts. EURASIP J. Image Video Process.,
2022(1):7.
Tropea, M. and Fedele, G. (2019). Classifiers compari-
son for convolutional neural networks (cnns) in image
classification. In DS-RT, pages 1–4. IEEE.
Ullah, A., Wang, J., Anwar, M. S., Ahmad, U., Saeed,
U., and Fei, Z. (2019). Facial expression recognition
of nonlinear facial variations using deep locality de-
expression residue learning in the wild. Electronics,
8(12):1487.
Wan, Z., Zhang, B., Chen, D., Zhang, P., Chen, D., Wen,
F., and Liao, J. (2023). Old photo restoration via deep
latent space translation. IEEE Trans. Pattern Anal.
Mach. Intell., 45(2):2071–2087.
Wang, R. (2022). An old photo image restoration process-
ing based on deep neural network structure. Wireless
Communications and Mobile Computing, 2022:1–12.
Ysique-Neciosup, J., Chavez, N. M., and Ugarte, W. (2022).
Deephistory: A convolutional neural network for au-
tomatic animation of museum paintings. Comput. An-
imat. Virtual Worlds, 33(5).
Yuan, L., Ruan, C., Hu, H., and Chen, D. (2019). Image in-
painting based on patch-gans. IEEE Access, 7:46411–
46421.
Zeng, Y., Gong, Y., and Zeng, X. (2020). Controllable digi-
tal restoration of ancient paintings using convolutional
neural network and nearest neighbor. Pattern Recog-
nit. Lett., 133:158–164.
Zhang, S., He, F., and Ren, W. (2020a). Photo-realistic de-
hazing via contextual generative adversarial networks.
Mach. Vis. Appl., 31(5):33.
Zhang, S., Wang, L., Zhang, J., Gu, L., Jiang, X., Zhai,
X., Sha, X., and Chang, S. (2020b). Consecutive con-
text perceive generative adversarial networks for serial
sections inpainting. IEEE Access, 8:190417–190430.
WEBIST 2023 - 19th International Conference on Web Information Systems and Technologies
112
