
Enhancing Gesture Recognition for Sign Language Interpretation in
Challenging Environment Conditions: A Deep Lea rning Approach
Domenico Amalfitano
a
, Vincenzo D’Angelo, Antonio M. Rinaldi
b
, Cristiano Rus so
c
and Cristian Tommasino
d
Department of Electrical Engineering and Information Technology University of Naples Federico II,
Via Claudio, 21, Naples 80125, Italy
cristiano.russo@unina.it, cristian.tommasino@unina.it
Keywords:
Gesture Recognition, Sign Language, D eep Learning, Real-Time Translation, Accessibility.
Abstract:
Gesture recognition systems have gained popularity as an effective means of communication, leveraging the
simplicity and effectiveness of gestures. With the absence of a universal sign language due to r egional varia-
tions and limited dissemination in schools and media, there is a need for real-time translation systems to bridge
the communication gap. The proposed system aims to translate American Sign Language (AS L), the predomi-
nant sign language used by deaf communities in real-time in North America, West Africa, and Southeast Asia.
The system utilizes SSD Mobilenet FPN architecture, known for its real-time performance on low-power de-
vices, and leverages transfer learning techniques for efficient training. Data augmentation and preprocessing
procedures are applied to improve the quality of training data. The system’s detection capability is enhanced
by adapting color space conversions, such as RGB to YCbCr and HSV, to improve the segmentation for vary-
ing lighting conditions. Experimental results demonstrate t he system’s Accessibility and non-invasiveness,
achieving high accuracy in recognizing ASL signs.
1 INTRODUCTION
Sign lang uage is a crucial mode of communication for
the deaf and hard-of-hearing community. It enables
these individuals to exp ress their thoughts and engage
in fruitful interactions, giving a complete knowledge
representation system. However, there are signifi-
cant challenges to effective communication between
sign language users and those who do not under stand
sign language (Wadhawan and Kumar, 2021; Rast-
goo et al., 2021). Gesture recognition technology,
an essential field within compu te r vision and machine
learning, has the potential to bridge this gap. It can
achieve this by precisely interpreting sign language
gestures in real-time. Gesture recognition in sign lan-
guage involves developing sophisticated systems that
can analyze and compr ehend complex hand move-
ments, facial expressions, and body postures that con-
stitute sign language. These systems use cuttin g-edge
a
https://orcid.org/0000-0002-4761-4443
b
https://orcid.org/0000-0001-7003-4781
c
https://orcid.org/0000-0002-8732-1733
d
https://orcid.org/0000-0001-9763-8745
algorithm s and machine learning techniques to recog-
nize and interpret the rich visual cues in sign language
gestures. Gesture recognition technology c a n facili-
tate seamless communication between sign language
users and the broader community by accurately cap-
turing and understanding these gestures (Mitra and
Acharya, 2007; Khan and I braheem, 2012).
However, precise recognition of sign la nguage
gestures can pose significant challenge s, especially
under varied lighting and exp osure conditions. Varia-
tions in lighting, such as harsh sunlight or dim envi-
ronments, can impact the qu ality and visibility of the
gestures. This makes it difficult for recognition sys-
tems to interpret them accu rately. Furthermore, dif-
fering exposure levels, such as overexposed or under-
exposed images, can add c omplexity to the recogni-
tion process, leading to possible errors o r misinterpre-
tations. It is crucia l to address the impact of lighting
and exposure conditions on sign language recognition
to develop robust and reliable gesture recognition sys-
tems. Ackn owledging these challenges will allow r e-
searchers and practitioners to create algorithms an d
techniques resilient to varying lighting conditions and
exposure levels. T his will ensure accurate recognition
Amalfitano, D., D’Angelo, V., Rinaldi, A., Russo, C. and Tommasino, C.
Enhancing Gesture Recognition for Sign Language Interpretation in Challenging Environment Conditions: A Deep Learning Approach.
DOI: 10.5220/0012209700003598
In Proceedings of the 15th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2023) - Volume 1: KDIR, pages 395-402
ISBN: 978-989-758-671-2; ISSN: 2184-3228
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
395

regardless of the environmental constraints (Suarez
and Murphy, 2012). Furthermore, variations in ex-
posure and lighting conditions can significantly affect
the contrast, color, and textur e of sign language ges-
tures. Shadows, reflection s, and uneven illum ination
can introduce noise and distortions, making the ex-
traction of meaningful features from the visual data
challengin g. These variations m ay also affect the
recogn ition of subtle nuances and fine-grained move-
ments that are essential for the accurate inte rpreta-
tion of sign language (Su arez and Murp hy, 2012).
In orde r to tackle the challenge s presented by var-
ied lighting and exposure conditions, ou r solution fo-
cuses on examining different color spaces to enhance
the accuracy of the gesture recognition system. Tradi-
tional color spaces, such as RGB (Red-G reen-Blue),
may not be robust enough to handle variations in
lighting conditions effectively. As a result, we p ro-
pose investigating alternative color spac e s, such as
HSV (Hue-Saturation-Value) or YCbCr (L uminance-
Blue Chrominance-Red Chrominanc e ), which offer
distinct advantages in separating color information
from variations in illu mination. By utilizing alterna-
tive color spaces, w e aim to boost the system’s ability
to differentiate between sign language gestures and
their backgrounds under different lighting conditions.
These color spa ce transformations can help mitigate
the effects of lighting variations, en abling more accu-
rate feature extraction and gesture recognition. Addi-
tionally, by exploring multiple color spaces, we can
tailor the system to different environments and lig ht-
ing scenarios, ensuring robust perfo rmance across di-
verse re al-world settings. In our experim e ntal eval-
uation, we will co mpare the performance of the ges-
ture recognition system using different color spaces
under varied exposure and lighting conditions. We
will assess m e trics such as recognition accuracy, ro-
bustness to lighting variations, and computational ef-
ficiency. By thor oughly investigating the impact of
color space transformations, we aim to provide in-
sights into the most effective co lor spa c e choices for
improving gesture recognition accuracy in different
environments. Through our research, we want to con -
tribute to advancing gesture recognition systems for
sign language. We specifically aim to tackle the chal-
lenges posed by varied exposure and lighting con-
ditions. By investigating different color spaces, we
hope to enhan c e the system’s accur acy, enabling ef -
fective communication between sign language users
and non-sign users across a variety of real-world sce-
narios. This research has the potential to significan tly
improve Acce ssibility and inclusivity for the deaf and
hard-of-hearing co mmunity, empowering them to en-
gage more seamlessly in a wide range of environ-
ments and lighting conditions. The remainder of the
paper is organiz ed as follows: Section 2 p rovides an
overview of the related works, Section 3 introduces
our proposed approac h, Section 4 presen ts the results
obtained from our experiments, and finally, Section 5
provides con clusions and discusses future works.
2 RELATED WORKS
Gesture recognition, particularly in the context of sign
languag e, has been extensively re searched in com-
puter vision and machine learning. Researchers have
explored various app roaches an d techniques to inter-
pret sign language gestures accur ately. This section
provides an overview of the related works in ges-
ture r e cognition f or sign language, highlighting sig-
nificant contributions and advancements in the field.
One a pproach focuses on utilizing 3D models for ges-
ture recognition, which provides precise re sults but
can be c omputationally expensive and less efficient
for real-time systems. For example, in video surveil-
lance, facial recognition based on 3D face model-
ing has shown a 40% improvement in performanc e
when reconstructing 3D facial models from non-
frontal frames (Park and Jain, 2007). However, the
computational c omplexity of 3D modeling techniques
makes them less suitable for real-time applications.
Simplified versions of volumetric models rely on the
representation of the human skeleton, analyzing the
position and orientatio n of its constituent segments.
These skeleton-based systems focus on key parame-
ters, resulting in faster p rocessing times while main-
taining satisfactory recognition performance. Such
approa c hes have found practical applications in var-
ious human-computer interaction interfaces. Bidi-
mensional models, on the other han d, extra ct low-
level features such as color, shape, and contour di-
rectly from images, making them suitable for ges-
ture classification systems. Researchers have exten-
sively employed these mod els to classify and inte r-
pret sign language ge stu res accurately. Another ap-
proach to gesture recognition involves electromyogra-
phy (EMG)-based models, which classify gestures by
analyzing the ele ctrical impulses generated by mu s-
cles. This technique allows for a broader range of mo-
tion, enabling more natur al and expressive gestures.
Segmentation is a crucial step in the gestu re recog -
nition pipelin e , involving dividing images into rele-
vant parts for analysis. Various metho dologies have
been proposed to address this process. Region -based
segmentation methods have been explored, including
region growing a nd region sp littin g. Region grow-
ing involves selecting seed p ixels representing dis-
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
396

tinct areas and expanding th e m until the entire im a ge
is covered, verifying the homogeneity of each sec-
tion. Region splitting adopts a top-down approach,
recursively dividing the image into sub-images un-
til only homogeneous regions remain. Thresholding,
a commonly used technique, categorizes pixels into
“object” or “background” based on a predetermined
threshold value, resulting in a binary image. Ad-
vanced thresho lding techniques handle noise and im-
prove segmentation accuracy under challenging light-
ing conditions. Clustering techniques have also been
applied to g esture recognition, which groups elements
with similar characteristics within an image. The
level of similarity is determined through distance cal-
culations. Shape descriptors play a vital r ole in r ecog-
nizing objects, including gesture recognition. These
descriptors offer a collection of features that de scribe
a specific shape and can be u tilized for efficient im-
age retrieval and comparison, even in the presence of
transformations such as scaling, rotation, or transla-
tion. Various methodologies for shape description and
representation, such as region-based or contou r-based
approa c hes, have been proposed. Edge direction his-
tograms are essential tools for detecting objects when
color information is unavailable, describing an im-
age’s texture. The input image is divided into blo cks,
and variables representing vertical, horizontal, diago-
nal, or isotropic edge n ature are associated with each
block. The Harris corner detector, an operator for
corner detec tion, identifies important points for ob-
ject description and can reduce the amount of data
used in processing. H owever, its sensitivity to scale
changes limits its applicability to image s of different
sizes. The Scale-Invariant Feature Transform (SIFT)
descriptor extracts and describes many features f rom
images, minimizin g the influence of local variations
on object detection. The angular partitioning-based
approa c h (ARP) is conducted on grayscale images,
where circular sections surround the edge to ensure
scale invariance, and angles generated are measured
for information extraction. Despite progress in ges-
ture recognition technologies, limitations persist, par-
ticularly related to the equipment used and image
noise. Factors such as camera distan c e, resolution,
and lighting conditions can affect the quality of ge s-
ture detection. Additionally, user fatigue, kn own as
“gorilla arm” fatigue, has been obser ved , particularly
in mid-air gestures, where users experience arm fa-
tigue when per forming gestures over extended peri-
ods.
Gesture recognition has witnessed significant ad-
vancements with the application of artificial neu-
ral networks, which are computational models in-
spired by biological systems (Abiodun et al., 2018).
Machine-based feature extraction has proven effective
in several doma ins (Russo et al., 2020; Rinaldi a nd
Russo, 2020; Rinaldi et al., 2021). In fact, different
types of architectures and purposes exist in the field
of neural networks, each c atering to specific re quire-
ments. Convolutional neural networks (CNNs) have
been widely used for image and patter n recognition
tasks (Madani et al., 2023; Rinaldi et al., 2020). T heir
architecture c omprises convolutiona l layers, pooling
layers to reduce input parameters, a nd fully connected
layers for classification based on information derived
from previous la yers. Object detection algorithms can
be categorized b a sed on the approach employed (Gir-
shick et al., 2014). Models like R-CNN and Fast
R-CNN adopt a two-stage approach: the first stage
identifies possible regions of interest, and the second
stage employs CNNs to detect objects within those
regions. Conversely, models like YOLO an d SSD uti-
lize a fully convolutiona l approach , enabling single-
pass detection . The former achieves higher accuracy,
while the latter exhibits superio r spe e d, making it
more suitable f or real-time applications. Given the
need for prompt response in gesture recognition sys-
tems, single-stage appro aches are favored in their im-
plementation. Region-based convolutional networks
excel in object detection tasks, distingu ish ing fore-
ground ob je c ts from the background based on a re-
gion of interest. These networks aim to produce
bounding boxes containing objects an d specify their
categories. Earlier models utilized selective search
algorithm s to extract regions of interest (ROIs) and
subsequen t convolutional operations to cla ssify ob-
jects within the identified regions, f ollowed by sup-
port vector machines (SVMs) for object region clas-
sification and linear regressors for bounding box re-
finement. However, these architectures suffered from
time-consuming training due to the large number o f
regions identified. Subsequent advancements in ob-
ject detection h ave led to the evolution of these mod-
els, resulting in more efficient techniques. The Fast
R-CNN architectur e (Girshick, 2015) directly gen-
erates feature maps from the input image, eliminat-
ing the need for region proposal stages and improv-
ing speed. Faster R-CNN (Ren et al., 2015)intro-
duces a Region Proposal Network (RPN) that effi-
ciently and accurately identifies r egions of interest,
sharing convolutional features with downstream de-
tection networks. Region- based Fully Convolutional
Networks (R-FCN) (Dai et al., 2016) f urther enhances
detection speed by sharin g computations for all re-
gion proposals. Mask R-CNN (He et al. , 2017) effi-
ciently de tects objects w hile simultaneously generat-
ing segmen tation mask s for each instance. This ap-
proach replaces RoIPooling with RoIAlig n for more
Enhancing Gesture Recognition for Sign Language Interpretation in Challenging Environment Conditions: A Deep Learning Approach
397

accurate pixel-level segmentation. Single Shot Multi-
Box Detector (SSD) combines object classification
and bounding box prediction in a single pass, utiliz-
ing predefined bounding boxes of varying sizes. By
evaluating object categories and adapting the boxes
to their shape, SSD handle s objects of different scales
effectively. MobileNet SSD v2 (Sandler et al., 2018),
designed for real-time applications on mobile devices,
achieves high-speed processing. YOLO (You Only
Look Once) (Redmon et al. , 2016) proposes a novel
object detection approach by recognizing im age re-
gions with high probabilities of containing objects,
enabling single-pass evalua tion. YOLO is a globa l
reasoning network that reasons abo ut the entire im -
age and all objects within it, dividing the input image
into an S×S grid. Each grid c ell is r esponsible for
detecting an object if its center falls with in that cell.
The approach is extremely fast, capable of processing
45 frames per second, w ith a faster version r eaching
155 frames per second. However, YOLO may exhibit
more localization errors compared to other de tection
systems. YOLOv7 (Wang et al., 2022), introduc ed in
2022, outperforms previous detection models in terms
both spe e d and accur acy. It requires significantly
less expensive hardware compared to oth er n eural net-
works and is trained solely on the MS COCO dataset
without the use of pre-trained models. The cited
study (Bha rati and Pramanik, 2020), conduc te d in
2020, provides a detailed performance comparison
of various object detection models. It is imp ortant
to note that performance depen ds on factors such as
input image resolution, dataset, and training config-
urations. Model acc uracy is measured using mean
average prec ision (mAP). From the reported data, it
can be inferred that SSD and R-FCN are among the
fastest mode ls but do no t match the precision and ac-
curacy of Faster R-CNN. While SSD is less affected
by the choice of feature extractors, it is less accurate
in detecting small objects. YOLO rem ains the fastest
architecture , with a speed of appr oximately 21-155
frames per second, while Mask R-CNN exhibits the
highest accur a cy, with an average p recision of 47.3.
3 SIGN LA N GUAGE
TRANSLATION SYSTEM
Our approach targets developing a real-time Ameri-
can Sign Language (ASL) translation system. ASL
stands as the principal sign language for deaf commu-
nities in America, Canada, and various countries in
West Afric a and Southeast Asia. The system captures
visual input from a camera, executes g esture detection
and recogn ition, and then exhibits the corresponding
textual translation along with a reliability score.
Figure 1 showcases the architecture of our system,
which is com posed of the following key modu le s:
• Capture Module: This m odule represents the
eyes of the system. It uses the webcam to cap-
ture a video fr ame, which becomes the initial raw
data for the entire tra nslation pr ocess. The ability
to effectively capture frames in different lighting
conditions a nd at varying distances underpins its
functionality.
• Preprocessing Module: This module transforms
the raw vid eo frame into a format that the system
can more e fficiently analyze. This includes im-
age transformations like gamma correction, wh ich
can adjust the brigh tness of the image and im-
prove visibility. Noise reduction and normaliza-
tion might also occur at this stage to improve
the accuracy of subsequent detection and clas-
sification tasks. Additionally, the prepossessing
pipeline also app lies image resizing to dimensions
of 320x320.
• Detection Module: Th is is where the actual sign
detection happens. This module analyzes the pr e-
processed frame and identifies the presence of any
signs. The output of this module is a set of regions
in the frame where a sign is likely present, o ften
represented by boundin g boxes.
• Classification Module: The identified signs are
then fed into this module. Here, a class is assigned
to each detecte d sign based on the trained model.
The Classification Module’s role is to translate the
identified signs into their equivalent meanings in
spoken or written language.
• Visualizat ion Module: Th e final module takes
the classified signs and presents them to the user
in an easy-to-understand format. This involves
displaying the corresponding textual translation
and the screen’s reliability score. This mod-
ule provides critical feedbac k to users, allowing
them to understand how the system interprets their
signs.
Each module plays a critical role in the system, con-
tributing to the overall goal of effective and efficient
real-time ASL translation.
3.1 Sign Detection Implementation
We implemented our system using Python 3. 8, draw-
ing from the power of the TensorFlow 2 Object Detec -
tion API and the OpenCV library. The training pro-
cess embraces a supervised learning approach, lever-
aging labeled data that we created with the op en-
source software LabelImg . Once we load the trained
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
398
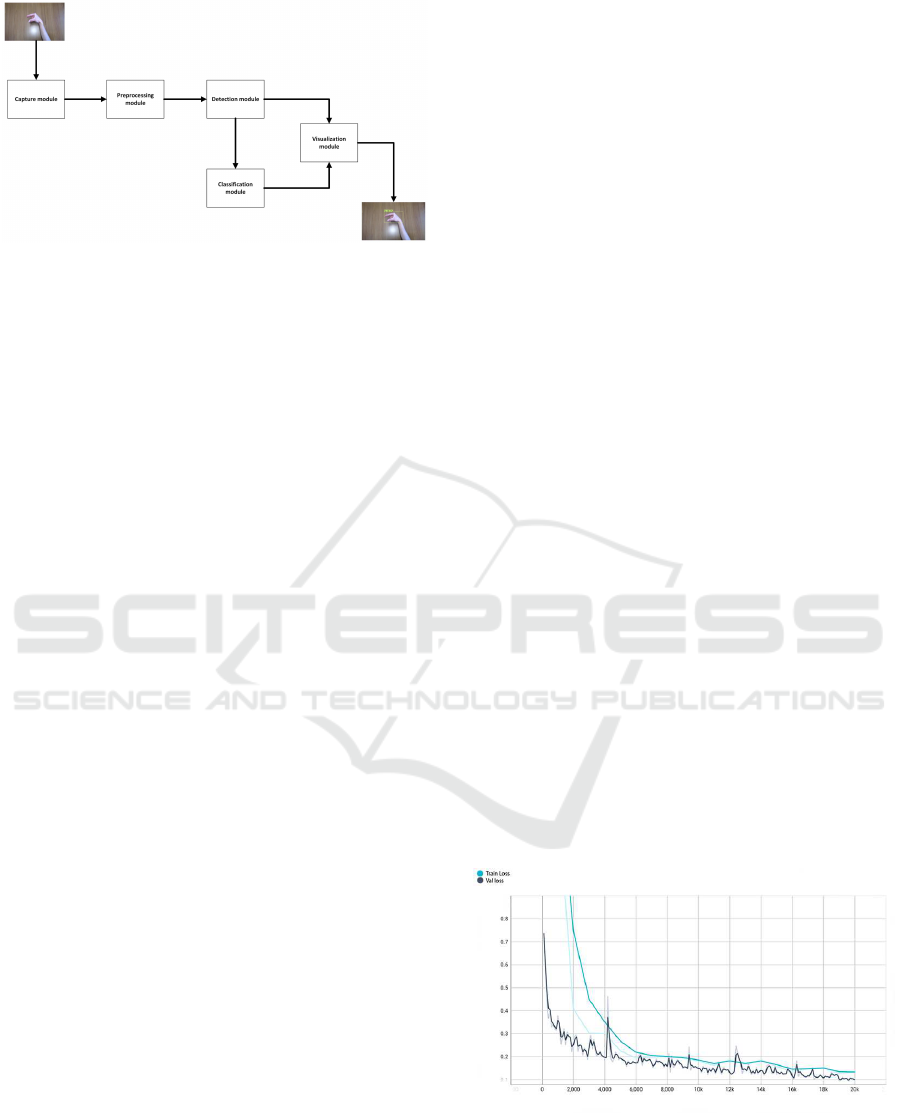
Figure 1: System A r chitecture.
model, we start the detection proc ess. The system
captures the video stream from the webcam with the
help of the OpenCV library and starts displaying real-
time detections on the screen. Each detection comes
defined with bounding boxes, class labels, and con-
fidence scores. We have set up the system to dis-
play a maximum of two detections simultaneously.
We have established a confidence threshold that dic-
tates the minimum score for reliable predictions. This
threshold essentially f unctions as a filter, discarding
results that lack sufficient confidenc e . Experiments in
different visual conditions have set the value of the
threshold. To ensure robust performan c e, we put the
system through rigo rous testing using a variety of we-
bcams, each with different resolutions. We experi-
mented with several color spaces and altered the po-
sitioning distance between the webcam and the tar-
get objects. We ran these tests under an array of
lighting conditions and with both simple and com-
plex backgro unds to mimic real-world scenarios. In
the forthcoming section, we will delve into the results
of these tests. Capitalizing on the trained model and
real-time vid eo input, o ur system strives to accurately
detect and identify the specified signs across a multi-
tude of situations. The bounding boxes and class la-
bels serve as intuitive visual feedback, giving user s in-
sights into how the system interprets their signs. Con-
fidence scores, on the other hand, offer a measure of
the system’s prediction certain ty. These scores em-
power users to evaluate the reliability of the sign in-
terpretations.
4 EXPERIMENTAL RESULTS
In this section, we present our experimental strategy,
report the results, and go into deep related discus-
sions.
To evaluate our approach, we constructed ou r
dataset, recognizing that the phase of dataset creation
plays a crucial role in achieving pleasing results. In
this stud y, we selected a restricted set of signs. Such
a strategy initially allows the mode l to learn essen-
tial sign recog nition before gradually expanding the
training set. This approach can be useful when deal-
ing with com plex sign language systems, providing
a stepping stone to incorporate more signs into the
model progressively.
After all, the quality and volume of input data
directly steer the detector’s accuracy. We harnessed
four different webcam models to capture images for
each sign. To boost system robustness, we por trayed
each sign with slight variations in ha nd poses and in-
terchang eably used hands in each image.
Following the data collection, we annotated each
image using the LabelImg software (Tzutalin, 2015).
During this annotation process, we matched each sign
with its appropriate lab el and highlighted the region of
interest with a bounding box. Consequen tly, we ge n-
erated an XML file specifying the image inf ormation,
the assigned label, and the bounding box coordinates.
Constructing the dataset required us to engage in
careful labeling to depict the nuances in sign expres-
sions accurately. This variation in the dataset helps
ensure that our model learns to recogniz e and gener-
alize different instances of the same sign effectively.
Additionally, we optimized the size of the dataset,
striking a balance between the r equiremen t for am ple
samples and the practical limitations of data collec-
tion.
We use the annota te d dataset to train the sign lan-
guage translation model. By exposing the model to a
wide array of sign variations, we aim to enhance its
generalization capabilities and its accur acy in recog-
nizing signs in rea l-world scenarios. By constructing
an effective dataset, we set the stag e for training a re-
silient and de pendable sign language translatio n sys-
tem.
Figure 2: Loss trend over epochs.
Enhancing Gesture Recognition for Sign Language Interpretation in Challenging Environment Conditions: A Deep Learning Approach
399

4.1 Training
To augment the efficiency of the training proced ure,
we leveraged the well-established technique of tra ns-
fer learning (Cook et al., 2013). This approach
enables adapting a pre -trained ar tificial intelligenc e
model to a task distinct from its initial training objec-
tive. Specifically, we extracted the lower layers from
the pre-trained network for reuse within our newly
designed network to recognize a set of five distinct
signs.
We elected to use the SSD MobileNet V2 FPN
Lite model, with an input size of 320x320 p ixels pre-
trained on the COCO 201 7 dataset (Lin et al., 201 4).
The ration ale for this selection is the neural network’s
impressive pro c essing speed o f 22ms and a COCO
mAP of 22.2. These performa nce metrics, coupled
with the simplicity of the network’s architecture that
facilitates its operation even on low-power devices,
deemed it an apt choice for our app lication.
In the train ing phase, we employed aug mentation
techniques, specifically random cropping and hori-
zontal flipping, to enhance th e network’s gener aliza-
tion capabilities. The mo del’s training leverages a
momentum optimizer (Ruder, 2016), featuring a co-
sine decay learning rate strategy (Loshchilov and Hut-
ter, 2016 ). This optimizer initiates with a base learn-
ing rate of 0.08, diminish ing gr a dually per a c osine
decay schedule, thereby promotin g smoother conver-
gence and limiting the risk of overshooting. A warm-
up phase within the initial 1000 steps grad ually es-
calates the learning rate from 0.026, a measure that
mitigates the risk of prem ature divergence. A momen-
tum optimizer value of 0.9 encoura ges the op timizer’s
acceleration in the correct directio n and da mpens os-
cillations, proving beneficial in complex optimization
landscapes. We employ a loss function that is a line ar
combination of localization and classification losses,
represented in Equation 1.
L = w
1
· L
loc
+ w
2
· L
class
(1)
In our configuratio n, we d eemed it appropriate to as-
sign equivalent importance to both components lo-
calization lo ss (L
loc
) and classification loss (L
class
),
thus setting w
1
= w
2
= 1.0. We specifically utilize
Smooth-L1 as the localization loss, wher eas Focal
Loss, with a gamma of 2 and alpha o f 0.25, serves
as our classification loss. We conducted the trainin g
phase over 20,000 epochs.
As illustrated in Figur e 2, both the training and
validation data exhibit a decrease in loss functions,
signaling the system’s excellent adaptation to the new
data.
4.2 Evaluation
One of the goals of this study is to obtain a sy stem for
sign recognition that gives r obust predictions under
different environmen tal conditions, such as br ightness
variations and backgro und c omplexity. In low-light
conditions, HSV (Hue, Saturation, Value) color space
is often considered more advantageous compared to
YCbCr (Luma, Chroma Blue, Chroma Red) color
space due to the distinct characteristics of their re-
spective components. The Value component in HSV
directly r epresents the brigh tness or inten sity of a
color, making it particularly suitable for object de tec-
tion in low-light e nvironments. Despite reduced over-
all illumination, the Value co mponen t still exhibits
distinguishab le variations in brightness, enabling ef-
fective differentiation of objects. Conversely, YCbCr
separates the color information from the brightness
informa tion, with the Luma component representing
the brigh tness. However, the Luma component may
not provide sufficient contrast for robust object dete c-
tion in low-light cond itions. This discrepan cy arises
from the fact that the Luma component is less sensi-
tive to variations in brightness under low-light con-
ditions, potentially leading to decreased detection ac-
curacy. Consequently, HSV, emphasizing the Value
component, is generally favored over YCbCr for im-
proved object detectio n performance in low-light con-
ditions. We observed that predicted classes were cor-
rect during tests conducted in non-optimal environ-
mental conditions for RGB in put fra mes. However,
their probability scores were not predominant con-
cerning other classes. For these reasons, we compared
RGB against HSV under b right environment condi-
tions an d RGB against YCbCr under low-light envi-
ronment condition s.
The results of tests conducted for each sign are
presented in Table 1 and Table 2 and summarized
graphica lly in Figure 3 and Fig ure 4.
For example, in tests carried out in brightly lit en-
vironm ents, an improvement in confidence scores was
observed when converting to the HSV color space,
as demonstrated in the examples shown in Figure 5
where the confide nce score for the “Hello” sign in-
creases from 56. 08% to 99.24 %. Similarly, in tests
condu c te d in low-light conditions, detection quality
was improved by using the YCbCr color spac e, as
shown in Figure 6 w here it can be observed that the
confidence score increases from 51.45% to 93.29%
for the “No” sign.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
400
Table 1: C omparison of P r obability Scores for RGB and
HSV in low-light environments.
Sign RGB (%) HSV (%)
“Yes” 46.46 99.39
“No” 50.01 96.02
“Hello” 54.05 99.42
“I Love You” 49.89 96.72
“Thank You” 68.39 97.14
Table 2: C omparison of P r obability Scores for RGB and
YCbCr in bright environments.
Sign RGB (%) YCbCr (%)
“Yes” 52.09 92.95
“No” 58.30 95.9
“Hello” 50.43 99.81
“I Love You” 56.70 99.01
“Thank You” 59.92 99.03
Figure 3: Accuracy comparison between each sign’s RGB
and HSV color spaces.
Figure 4: Accuracy comparison between each sign’s RGB
and HSV color spaces.
Figure 5: Sign recognition comparison between RGB and
HSV color spaces in a bright environment. HSV outper-
forms RGB in this condition.
Figure 6: Sign recognition comparison between RGB and
YCbCr color spaces i n low-light environment. YCbCr out-
performs RGB in this condition.
5 CONCLUSIONS
Gestures provide a simple and effective method of
communication, which is why gestu re recognition
systems are gaining pop ularity. Depending on the
application domain, it is important to consider the
choice of technologies and training architectu res care-
fully. While more sophisticated sensors can pr ovide
more accu rate detections, they are often less afford-
able and accessible.
Our propo sed system is capable of real-time trans-
lation of five sym bols from American Sign Language
(ASL), whic h is the pr edominan t language a mong
deaf com munities in America, Canada, West Africa,
and Southeast Asia. By analyzing the data stream
from the webcam, the system displays the dete c tion
on the screen, providing bounding bo xes, classes,
and c onfidence scores. It is based on the SSD M o-
bilenet architecture, designed to delive r real-time per-
formance on low-power devices while achieving high
levels of accuracy under optimal co nditions. In chal-
lenging lighting c onditions, the detection quality has
been significantly improved through color space con-
versions, ena bling better image segmentation. The
implemented technology demonstrates Accessibility
and non-invasiveness.
Overall, this resear c h contributes to advancing
gesture recognition systems, particular ly for sign lan-
guages, by leveraging De ep Lea rning techniques. The
proposed system shows promise in real-time trans-
lation and has the potential to facilitate communica-
tion betwee n deaf individuals and the wider commu-
nity. Future work may focus on expanding the vocab-
ulary using other knowledge sources (Caldarola et al.,
2015; Muscetti et a l., 2022) and improving the sys-
tem’s robustness under various environme ntal condi-
tions, ultimately aiming to make gestur e reco gnition
more accurate, efficient, and inclusive.
Enhancing Gesture Recognition for Sign Language Interpretation in Challenging Environment Conditions: A Deep Learning Approach
401

ACKNOW LED GM EN TS
We acknowledge financial suppor t from the p roject
PNRR MUR project PE0000013-FAIR.
REFERENCES
Abiodun, O. I., Jantan, A., Omolara, A., Dada, K. V., Mo-
hamed, N. A., and Arshad, H. (2018). State-of-the-
art in artificial neural network applications: A survey.
Heliyon, 4(11):e00938.
Bharati, P. and Pramanik, A. (2020). Deep learning
techniques—r-cnn to mask r-cnn: a survey. In Com-
putational Intelligence in Pattern Recognition: Pro-
ceedings of CIPR 2019, pages 657–668.
Caldarola, E. G., Picariello, A., and Rinaldi, A. M. (2015).
Big graph-based data visualization experiences: The
wordnet case study. In IC3K 2015 - Proceedings of the
7th International Joint Conference on Knowledge Dis-
covery, Knowledge Engineering and Knowledge Man-
agement, page 104 – 115.
Cook, D., Feuz, K. D., and Krishnan, N. C. (2013). Trans-
fer learning for activity recognition: A survey. Knowl-
edge and information systems, 36:537–556.
Dai, J., Li, Y., He, K., and Sun, J. (2016). R-fcn: Object de-
tection via region-based f ull y convolutional networks.
In Advances in neural information processing sys-
tems, volume 29.
Girshick, R. (2015). Fast r-cnn. I n Proceedings of the IEEE
international conference on computer vision, pages
1440–1448.
Girshick, R., Donahue, J., Darrell, T., and Malik, J. (2014).
Rich feature hierarchies for accurate object detec-
tion and semantic segmentation. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 580–587.
He, K., Gkioxari, G. , Doll´ar, P., and Girshick, R. (2017).
Mask r-cnn. In Proceedings of the IEEE international
conference on computer vision, pages 2961–2969.
Khan, R. Z . and Ibraheem, N. A. (2012). Hand gesture
recognition: a literature review. International journal
of artificial Intelligence & Applications, 3(4):161.
Lin, T.-Y., Maire, M., Belongie, S., Hays, J. , P erona, P.,
Ramanan, D., ..., and Zitnick, C . L. (2014). Mi-
crosoft coco: Common objects in context. In Com-
puter Vision–ECCV 2014: 13th European Confer-
ence, Zurich, Switzerland, September 6-12, 2014, Pro-
ceedings, Part V 13, pages 740–755. Springer Interna-
tional Publishing.
Loshchilov, I. and Hutter, F. (2016). Sgdr: Stochastic
gradient descent with warm restarts. arXiv preprint
arXiv:1608.03983.
Madani, K., Rinaldi, A. M., Russo, C., and Tommasino,
C. (2023). A combined approach for improving
humanoid robots autonomous cognitive capabilities.
Knowledge and Information Systems, 65(8):3197–
3221.
Mitra, S. and Acharya, T. (2007). Gesture recognition:
A survey. IEEE Transactions on Systems, Man,
and Cybernetics, Part C (Applications and Reviews),
37(3):311–324.
Muscetti, M., Rinaldi, A. M., Russo, C., and Tommasino, C.
(2022). Multimedia ontology population through se-
mantic analysis and hierarchical deep features extrac-
tion techniques. Knowledge and Information Systems,
64(5):1283–1303.
Park, U. and Jain, A. K. (2007). 3d model-based face recog-
nition in video. In Advances in Biometrics: Interna-
tional Conference, ICB 2007, Seoul, Korea, August
27-29, 2007. Proceedings, pages 1085–1094. Springer
Berlin Heidelberg.
Rastgoo, R., Kiani, K., and Escalera, S. (2021). Sign lan-
guage recognition: A deep survey. Expert Systems
with Applications, 164:113794.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A.
(2016). You only look once: Unified, real-time object
detection. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 779–
788.
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster
r-cnn: Towards real-time object detection with r egion
proposal networks. In Advances in neural information
processing systems, volume 28.
Rinaldi, A. M. and Russo, C. (2020). A content based im-
age retrieval approach based on multiple multimedia
features descriptors in e-health environment. In 2020
IEEE International Symposium on Medical Measure-
ments and Applications (MeMeA), pages 1–6. IEEE.
Rinaldi, A. M., Russo, C., and Tommasino, C. (2020). A
knowledge-driven multimedia retrieval system based
on semantics and deep features. Future Internet,
12(11):183.
Rinaldi, A. M., Russo, C., and Tommasino, C. (2021). Vi-
sual query posing in multimedia web document re-
trieval. In 2021 IEEE 15th International Confer-
ence on Semantic Computing (ICSC), pages 415–420.
IEEE.
Ruder, S. (2016). An overview of gradient de-
scent optimization algorithms. arXiv preprint
arXiv:1609.04747.
Russo, C., Madani, K., and Rinaldi, A. M. (2020). An unsu-
pervised approach for knowledge construction applied
to personal robots. IEEE Transactions on Cognitive
and Developmental Systems, 13(1):6–15.
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and
Chen, L.-C. (2018). Mobilenetv2: Inverted residu-
als and linear bottlenecks. I n Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion, pages 4510–4520.
Suarez, J. and Murphy, R. R. (2012). Hand gesture recog-
nition with depth images: A review. In 2012 I EEE
RO-MAN: t he 21st IEEE international symposium on
robot and human interactive communication, pages
411–417. IEEE.
Tzutalin (2015). Labelimg. https://github.com/tzutalin/
labelImg.
Wadhawan, A. and Kumar, P. (2021). S ign language recog-
nition systems: A decade systematic literature review.
Archives of Computational Methods in Engineering,
28:785–813.
Wang, C.-Y., Bochkovskiy, A., and Liao, H.-Y. M. (2022).
Yolov7: Trainable bag-of-freebies sets new state-of-
the-art for real-time object detectors. arXiv preprint
harXiv:2207.02696.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
402
