
Design a Recommendation System in Real Estate Investment Based
on Context Approach
Tinh T. Nguyen
1,2
, Sang Vu
1,2,*
, Truc Nguyen
1,2
, Vuong T. Pham
2,3,4
and Hien D. Nguyen
1,2 a
1
University of Information Technology, Ho Chi Minh City, Vietnam
2
Vietnam National University, Ho Chi Minh City, Vietnam
3
University of Science, Ho Chi Minh City, Vietnam
4
Institute of Data Science and Artificial Intelligence, Sai Gon University, Ho Chi Minh City, Vietnam
Keywords: Recommendation System, Consultation, Many-Cold-Start-Users, Nearest-Neighbors Approach, Intelligent
System.
Abstract: The real estate investment industry has experienced a significant increase in user participation over the years,
with individuals keen on registering concurrent interests in both recent and prior projects. This growing trend
necessitates the development of an approach that can recommend real estate items in a simultaneous manner.
However, the presence of unrequired memberships and stop-by behaviors has introduced several challenges,
resulting in numerous cold-start scenarios for new users. This study proposes a recommendation system
tailored specifically for real estate, designed to offer warm-start item recommendations of cold-start users
using a content-based approach and a session-based recommendation system. Herein, a system for real estate
recommendation with acceptable warm-start item recommendations is proposed in the many-cold-start-users
scenario. The session-based recommendation system is adapted and made use of pre-existing methods to
effectively handle sequential and contextual data for the encoded attribute prediction of the next-interacted
item. Then, the nearest-neighbors method is employed weighted cosine similarity to identify conforming
candidates. The results demonstrate the effectiveness of efficiently integrating the information and the
difficulty in performing well in item recommendations simultaneously.
1 INTRODUCTION
Among the crucial challenges in any e-commerce is
maintaining the existing users while attracting new
ones and recommendation systems play a crucial role
in enhancing the user experience and improving the
overall functionality of a real estate investment
platform. The common recommendation system uses
historical records as prior knowledge to choose
candidates and performs most effectively with
adequate records (Roy and Duta, 2022, Nguyen et al,
2020). However, the recommendation task becomes
complex due to no clear data of new users which
inevitably leads to more problems for the
recommendation/consultation system. Therefore,
addressing this cold-start problem is essential for
enhancing the overall functionality and usability of
real estate investment platforms.
* Corresponding author.
a
https://orcid.org/0000-0002-8527-0602
The item cold-start problem occurs when a
recommendation system cannot recommend new items
due to record deficiencies and new listing omissions.
Cold-start items are new items with few or no
interactions (Wei et al., 2017), whereas the rest of the
items are warm-start items. As new items are added
continuously in practical applications, this problem can
cause missed opportunities for recommendations,
particularly in real estate recommendations wherein
users can register a concurrent interest in recent and
prior projects. Specific attributes of real estate, such as
location, developer brand, and living space, can
influence user behavior when searching and buying
properties (Chia et al, 2016). Thus, a recommendation
approach using these attributes to real-estate items
simultaneously must be determined.
Context information is useful for
recommendation tasks (Adomavicius and Tuzhilin,
Nguyen, T., Vu, S., Nguyen, T., Pham, V. and Nguyen, H.
Design a Recommendation System in Real Estate Investment Based on Context Approach.
DOI: 10.5220/0012210800003598
In Proceedings of the 15th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2023) - Volume 2: KEOD, pages 255-263
ISBN: 978-989-758-671-2; ISSN: 2184-3228
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
255

2011). This information is also significant for real
estate recommendation because user interests can
vary according to the context. For example, users
searching from urban areas may be more interested in
condominiums than users searching from rural areas.
Using context information is an approach to achieve
better real estate recommendations. The context
information is also represented by ontology (Bouihi
and Bahaj, 2018, Nguyen et al., 2021) and graph
information (Yan et al., 2019, Nguyen et al., 2023).
Deep learning techniques can be used to learn
item attributes and predict the representation of real-
estate items for the corresponding factorization
machine (Wei et al., 2017). Meta-learning can also be
applied (Vartak et al., 2017). However, these
approaches utilize the factorization machine, which
interprets the engagement or rating prediction to the
recommendation task. This requires user identifiers
and sufficient records for efficiency. Hence, this
characteristic is also observed in other real estate
search engines and e-commerce systems with
unrequired membership, which encourages the use of
a content-based approach and session-based
recommendation system.
A session-based recommendation system (Hidasi
et al., 2016) uses sequential behavior without relying
on user identifiers. This paper proposes a real estate
recommendation approach for solving the item cold-
start problem with acceptable warm-start item
recommendations in the cold-start-users scenario. It
modifies a session-based recommendation system
and employs existing mechanisms to efficiently deal
with sequential and context information for the next-
interacted item’s encoded attribute prediction. The
nearest-neighbors approach is also used with
weighted cosine similarity to determine conforming
candidates. The experimental results show that the
proposed method is not only among different applied
mechanisms but also against baselines using the top-
n recommendation with the real estate dataset.
2 PREMILARIES
2.1 Content-Based Recommendation
System
Content refers to the attributes of an item; this can
take the form of different data types, such as metadata
and text description. The content-based
recommendation system comprises a profile learner
and a filtering component when working with
structured item representations (Lops et al., 2011).
The profile learner predicts the user profile from
interacted item attributes in a similar representation
to the item profile, after which the filtering
component determines the relevant items using the
matching algorithm. As it relies only on item
attributes, it can constantly recommend cold-start
items. This study tends to use the nearest-neighbors
approach with weighted cosine similarity as a
filtering component. Weighted cosine similarity is
selected as the similarity function owing to its
efficiency and flexibility with our user and item
profiles, which are high-dimensional vectors.
Weighted cosine similarity is defined as follows:
22
(1)
iii
i
ii ii
ii
wuv
Similarity
wu wv
=
where u
i
and v
i
are components of vector u and v,
resp., w
i
is the weight for both components.
2.2 Recurrent Recommendation
System Without User Identifiers
Without a user identifier, the task of recommendation
is underappreciated owing to the sparsity of training
data (Zhang et al., 2019). This sparsity leads the
recommendation system to learn from sequential
interactions without using user identifiers. Many
previous works (Li et al., 2017, Liu et al., 2018) relied
only on the sequence of interactions in each session.
Such a system is known as a session-based
recommendation system and uses RNN (Recurrent
Neural Network) as a core layer of the model owing
to its capability for capturing sequential patterns. The
system operates by receiving the click sequence of the
session, [𝑒
, 𝑒
, . . . , 𝑒
, 𝑒
] and predicting the next
click 𝑒
where 𝑒
is the i
th
event of the session. The
output of the system lists the scores for each item,
after which the system recommends only the top-n
highest-scored items to the user. The profile learner
utilizes this structure to predict the user profile from
the sequential patterns.
The process of splitting the click sequence into
training sequences working with the corresponding
structure is proposed in (Hidasi, 2016). Each training
sequence contains the input sequences and ground
truths. Input sequences use every possible prefix
within the training sequence and subsequent clicks as
ground truths (Figure 1). This generates an adequate
number of training sequences for deep learning.
2.3 Attention Mechanism in the
Current Recommendation System
A click sequence used in a recurrent recommendation
system is implicit feedback. It is indirect feedback
KEOD 2023 - 15th International Conference on Knowledge Engineering and Ontology Development
256

Figure 1: An example of splitting the click sequence into
training sequences.
implied from the user behavior and requires careful
consideration due to its characteristics of being very
noisy and providing no negative feedback (Hu et al.,
2008). It is impossible to determine whether the users
like or dislike the item on which they clicked, nor
whether a click is a miss click. The profile learner
uses the attention mechanism to deal with noise and
capture the purpose of the sequence, giving
precedence to each click differently.
Li et al. (2017) proposed the encoder portion of
the neural attentive recommendation machine
(NARM). NARM is an encoder-decoder session-
based recommendation system with an attention
mechanism. Its encoder portion incorporates two
encoders, the global encoder, and the local encoder.
The former represents the entirety of user behavior in
the click sequence, i.e., the last hidden state of the
RNN as follows:
= (2)
gt
ch
where, c
g
is the output of the global encoder and h
t
is the last hidden state of RNN. The local encoder
represents the main purpose of the click sequence,
defined as the sum of weighted hidden states from
every time step as follows (3):
1
= . (3)
n
ljj
j
cah
=
where, c
l
is the output of the local encoder, h
j
is the
hidden state of RNN at time step j and a
j
is the
weighted factor, which is defined as:
(, )
(, )
1
(4)
tj
tk
score h h
j
n
score h h
k
e
a
e
=
=
()
31 2
( , ) (5)
tj t j
score h h A A h A h
σ
=+
where, σ is an activation function, A
3
is a weighting
vector, and A
1
and A
2
are the learned weights of h
t
and
h
j
, respectively. As a result, both outputs from the
global and local encoders are concatenated and used
in the computation of the subsequent layers.
2.4 Application of Context Information
in the Recurrent Recommendation
System
Context information, such as the time and location of
the requested service, is useful when applied to the
recommendation task (Adomavicius and Tuzhilin,
2011). The profile learner uses the LC technique
(Beutel et al., 2018) to efficiently incorporate context
features, thereby overcoming difficulties inherent in
increasing the dimension of inputs that entail more
hidden units in the model. It works by determining
the elements-wise product of all embedded context
features in hidden states as follows:
()
1 * (6)
jjj
hwh=+
where h
j
is the hidden state of RNN at time step j and
w
j
is the embedded context feature.
The embedding layer of each context feature is
initialized by a 0-mean Gaussian distribution to
ensure that the multiplicative term has a mean of 1.
This initialization causes the multiplicative term to
act like an attention mechanism in the hidden state.
The element-wise product is performed both before
and after passing through the RNN. These
multiplications are considered as prefusion and post
fusion, consecutively.
3 CONTENT-BASED APPROACH
FOR RECOMMENDATION
SYSTEM IN REAL ESTATE
Using the content-based approach having a profile
learner and a filtering component, the item cold-start
problem has been solved. The profile learner is a
modified session-based recommendation system with
an attention mechanism to predict user profiles using
sequential and context information. The filtering
component uses the nearest-neighbors approach to
determine the most relevant items.
3.1 Profile Learner
The profile learner predicts a user profile composed of
the encoded attributes of the next-interacted item. It
utilizes the click sequence and context information.
Let [e
1
, e
2
, …, e
n
] denote a click sequence wherein 𝑒
Design a Recommendation System in Real Estate Investment Based on Context Approach
257

is the i th event of the sequence and [c
1
, c
2
, …, c
n
, e
n+1
]
are context features where 𝑐
corresponds to 𝑒
. The
profile learner predicts [f
1
, f
2
, …, f
m-1
, f
m
] where f
i
is the
i
th
encoded feature of 𝑒
determined from the click
sequence and context features. The encoded feature is
either one-hot or binary encoding depending on the
possible number of classes. Each f
i
prediction is either
a multiclass or binary classification depending on
ground truth encoding. For example, real estate
projects have the number of bedrooms as a feature.
This is reflected by one possible class among three:
one, two, or three bedrooms. Therefore, predicting this
feature is a multiclass classification problem.
Furthermore, it is a multilabel classification problem
when grouping such predictions as a feature
prediction. Particularly, we predict the possibilities of
all classes for each feature of the next-interacted item
used them as a user profile.
The structure of the session-based
recommendation system is modifed its task to the
objectives. Furthermore, the attention mechanism of
the encoder portion of NARM is used and adopted the
LC in the profile learner to efficiently deal with
sequential and context information, consecutively.
Thus, this efficiency should provide better user profile
prediction results and both warm-start and cold-start
item recommendations. Our profile learner received
an embedded item identifier, numerical features,
embedded categorical features, and the embedded
context features of a click sequence as inputs and then
predicted the user profile (Figure 2).
In the attention layer, global and local encoders are
used similar to the encoder portion of NARM but
using postfusion products instead of the original
hidden states. This replacement includes the effect of
context information when calculating the attention
score. The output of the attention layer is a
concatenated vector from the local and the global
encoders, which is used by the fully connected layers
to calculate the scores of the classes of all features.
Each fully connected layer is responsible for only one
encoded feature prediction; thus, its number of units is
equal to the number of corresponding classes. Its
activation function is either the softmax or sigmoid
function for multiclass and binary classification.
3.2 Filtering Components
The filtering component is responsible for
determining the candidates conforming to the
predicted user profile through the matching algorithm.
Herein, we used the nearest-neighbors approach to
gather top-n related items by calculating the scores of
all items using weighted cosine similarity, which
considers the numerical values of every possibility in
the user profile. It is also suitable for high-dimensional
vectors, which are similar to both our user and item
profiles. The representation of the item and user
profiles must be the same to compute the similarity
score. Thus, the concatenated vector of all encoded
features is used. Regarding these profiles, multiclass
and multilabel encoded features have different
influences on the similarity score calculation owing to
the different sum of values within the vector. To deal
with this, we selected weighted cosine similarity over
cosine similarity because it is flexible to assign
different weights to each component. Each 𝑤
for (1)
is defined as follows:
1/
(7)
1
i
n
w
=
Where, n is the number of classes of the
corresponding multilabel feature. The structure of our
filtering component is shown in Figure 3. It was used
to calculate the similarity score between all item
profiles and the predicted user profile using (1) and (7)
together as the similarity function. This study designs
a method recommending the top-n items with the
highest similarity score to the user
.
3.3 Real-Estate Pricing System
A real estate pricing system is a tool or model used to
estimate the value or price of properties in the real
estate market. It utilizes various factors and data
points to provide insights into property valuation,
helping buyers, sellers, and real estate professionals
make informed decisions. A typical real estate pricing
system includes:
Data collection: A real estate pricing system
collects a wide range of data related to the properties
being analyzed. The system may also consider
additional data sources such as demographic
information, economic indicators, and infrastructure
development plans.
Feature selection: Once the data is collected, the
pricing system identifies the most relevant features
that significantly impact property prices. This process
involves statistical analysis and machine learning
techniques to determine which variables have the
strongest correlation with property values.
Model development: The pricing system utilizes
various statistical and machine learning models to
build a prediction model. Commonly used models
include multiple linear regression, random forests, or
neural networks. The choice of model depends on the
complexity of the data and the accuracy required for
price estimation.
KEOD 2023 - 15th International Conference on Knowledge Engineering and Ontology Development
258

3.4 Regression Tree
A regression tree is a machine learning algorithm used
for solving regression problems. It is a type of decision
tree where each internal node performs a feature or an
attribute, and each leaf node represents a prediction or
an estimated value for the target variable.
Tthe process of building the regression tree involves
recursively partitioning the feature space based on the
values of different input features. The goal is to create
homogeneous regions or subsets of the data that share
similar characteristics in terms of the target variable.
This partitioning is done by selecting the feature and
the corresponding threshold that results in the best
split, often measured using metrics like mean squared
error (MSE) or mean absolute error (MAE).
3.5 Linear Regression
For the dataset of house prices and their corresponding
sizes, a linear regression model is built to predict the
price of a house based on its size, number of bed-
rooms, number of toilets, number of floors as Table 1.
Table 1: Some information of a house.
Orde
r
Price Area Bedrooms Toilets Floors
1 10 126 2 2 1
2 15 152 2 3 1
3 17 116 1 2 3
4 11 133 3 2 1
The linear relationship between the area, number
of bedrooms/toilets/floors of the house (variables 𝑥
,
𝑥
,𝑥
,𝑥
) and its price (dependent variable y) was
found. It can be represented by the equation:
y’ = f(x) = w
1
x
1
+ w
2
x
2
+ w
3
x
3
+ w
4
x
4
+ c (8)
where, w = {w
1
, w
2
, w
3
, w
4
} is the slope (regression
coefficient) and c is the intercept (y-intercept).
The linear regression model provides a linear
approximation of the relationship between house size
and price. It assumes a constant slope, indicating that
the price increases linearly with the size of the house.
However, it's important to note that linear regression
may not capture complex nonlinear relationships or
interactions between variables.
Figure 2: The structure of the proposed profile leaner.
Figure 3: The structure of the proposed filtering component.
Design a Recommendation System in Real Estate Investment Based on Context Approach
259

4 EXPERIMENTAL RESULTS
This section details the dataset and data preparation. It
also explains how the experiment was conducted and
evaluated to compare the performance of the proposed
approach and selected baselines.
4.1 Dataset and Data Preparation
The dataset used herein comprised one year of website
records captured in 2020 obtained from website
batdongsan.com.vn
2
, a popular real estate search
engine website, which included 13,425,274
interactions between 305,019 users and 6,849 items. It
contains 6,917 items with metadata that were used as
candidates; these metadata were consequently
processed as the item profile for each corresponding
item. It means each interaction has its context features.
First, the item profiles from its metadata are
provided the ground truth of the user profile prediction
and the participant in the similarity score calculation.
These metadata comprised 38 features, some of which
have missing and unique values. Features, which have
many unique values or missing values of more than
half, are removed. Those are not effective to interpret.
Besides, performing data imputation to fill the
remaining missing values based on other feature
values: the type of real estate, location, price level, etc.
Thereafter, all values are assigned into classes
depending on their corresponding feature
characteristic. Each value is assigned into a class with
an upper bound for discrete numerical features.
Values greater than or equal to this upper bound were
categorized equally. For example, the number of
bedrooms is a discrete numerical feature with five
classes: one, two, three, four, and five or more
bedrooms. This approach entailed the limitation of the
number of classes by grouping several sample classes.
After performing classifications, using either one-
hot or binary encoding encodes assigned class for one
possible class and many possible classes, respectively.
As a result, we generated item profiles composed of
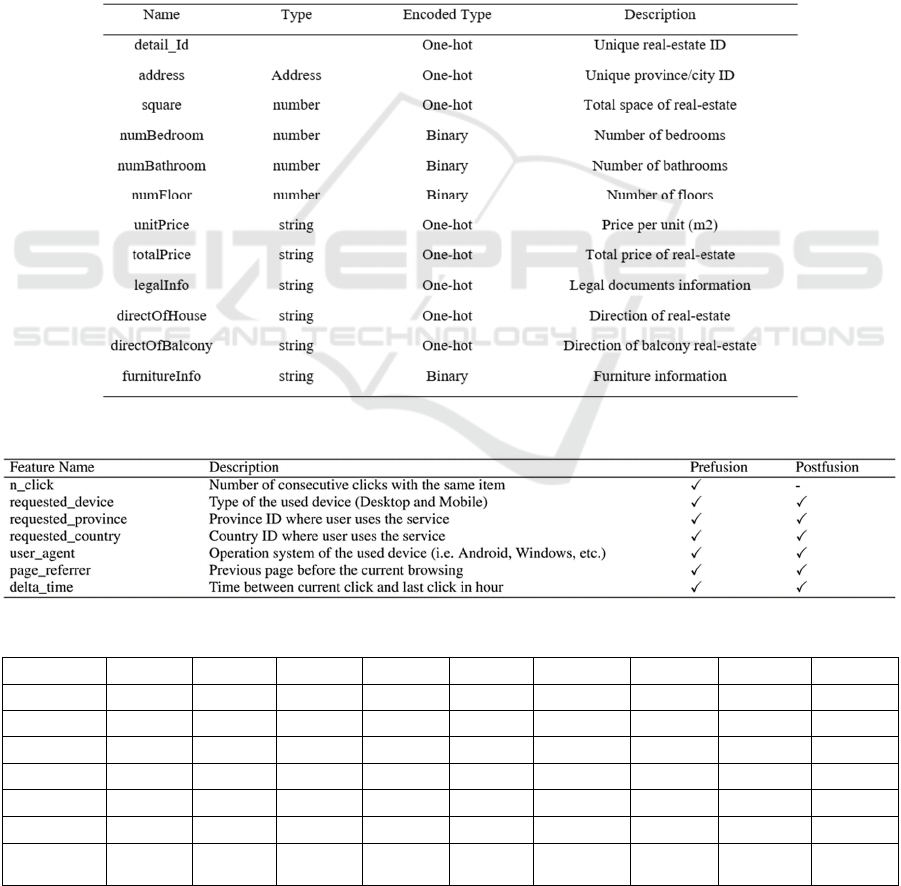
15 encoded features for 6,917 items, the information
relating to which is shown in Table 2.
Finally, sets of sequences of context features is
divided into the training and testing sets. These
included context features for the prefusion. Seven
context features were used: n_click, requested device,
requested province, requested country, user agent,
page reference, and delta time. These features and
outline their participation are described in Table 3.
2
https://batdongsan.com.vn/
4.2 Evaluation
The top-n recommendation task is used for evaluation
because it is practical for real usage. This task
evaluates performance based on the recommendation
list provided by the system and the actual click of the
user. The appropriate metrics are Recall@K and
Mean Reciprocal Rank@K (MRR@K), where K is
the number of items in the recommendation list.
Recall@K measures the model performance whether
the actual click is on the K-items recommendation list.
𝑅𝑒𝑐𝑎𝑙𝑙@𝐾
(9)
where, n
hit
is the number of cases having the actual
click and N is the number of all cases.
MRR@K measures the ranking performance of the
model as an average of reciprocal ranks of the actual
click within the recommendation list as follows:
𝑀𝑅𝑅@𝐾
∑
∈
(10)
where, c is the actual click, C is a set of cases
having the actual click, N is the number of all cases.
The model performance is evaluated in terms of
two aspects: warm-start and cold-start item
recommendations. We assigned test cases to each
perspective using the type of their actual click item.
We defined new items appearing only in the testing set
and the top 100 most recently introduced items in the
training set.
Figure 4 is the results of items ranking in real-
estate dataset by their price for inputted requirements.
Figure 4: The results for ranking of items by their price.
4.3 Comparison Against Other
Methods
Baselines were categorized by their strengths in terms
of two aspects: warm-start and cold-start item
recommendations. There are warm-start item
baselines:
KEOD 2023 - 15th International Conference on Knowledge Engineering and Ontology Development
260
• S-Pop: A sequence popularity predictor that
recommends items ranked by their number of
interactions in the current sequence.
• Item-KNN (Sarwar et al., 2001): It uses the
nearest-neighbors approach with cosine
similarity between the recently interacted item
vector in the current sequence and other item
vectors to obtain the most relevant items.
• NARM (Li et al., 2017): An encoder-decoder
GRU-based session-based recommendation
system with an attention mechanism.
• STAMP (Liu et al, 2018): An MLP-based
session-based recommendation system with an
attention mechanism. It creates a
recommendation list based on sequential clicks.
The content-based approach (Lops e al., 2011)
with different profile learners and similar filtering
components for the cold-start item baselines. They
were as follows:
• CB (S-Pop): A sequence popularity predictor
that predicts the user profile using the item
profile of the most interacted item in the current
sequence.
• CB (Mean): A model that predicts the user
profile from the meaning of the item profiles in
the current sequence.
Table 2: Description, type, and post-processed information of the encoded attributes within the item profiles.
Table 3: Description and participation of context features in prefusion and postfusion.
Table 4: Comparison with warm-item test cases.
Method Recall@1 Recall@5 MRR@5 Recall@10 MRR@10 Recall@15 MRR@15 Recall@20 MRR@20
S-Pop 6.49 18.35 11.07 21.02 11.44 21.88 11.51 22.43 11.54
Item – KNN 8.95 25.64 14.8 36.56 16.25 43.49 16.8 48.49 17.08
NARM 13.75 32.79 20.62 43.39 21.93 49.91 22.45 54.59 22.71
STAMP 14.09 33.14 20.88 43.55 22.27 49.98 22.78 54.62 23.04
CB (S-Pop) 6.49 13.96 9.12 18.83 9.76 22.16 10.02 24.77 10.17
CB (Mean) 6.03 19.85 11.14 26.81 12.06 31.45 12.43 35.05 12.63
Proposed
approach
11.97 24.21 16.29 31.90 17.31 37.13 17.72 41.23 17.95
Design a Recommendation System in Real Estate Investment Based on Context Approach
261

Table 4 is the results of warm-start item
recommendation through 12,066 test cases.
Moreover, to identify conforming candidates, the
nearest-neighbors method is also combined with
weighted cosine similarity.
In terms of Recall@K, the proposed approach is
mostly fourth following Item-KNN, NARM, and
STAMP, respectively. The only exception in terms of
Recall@1 is that our approach is at the third place by
outperforming Item-KNN. In terms of MRR@K, our
approach is at the third place behind NARM and
STAMP, consecutively. Meanwhile, our approach
yields better performance in both terms compared to
cold-start item baselines.
These results are better in terms of ranking and
one-item recommendation. The proposed approach
cannot beat Item-KNN, NARM, and STAMP in
overall warm-start item recommendation owing to
two causes. The first is having more candidates.
There are 6,917 considered items when calculating
the similarity score, out of which not all participate in
the interaction logs. Conversely, these three baselines
consider only 6,105 items found in the training set.
The second is the disadvantage of using the only item
attributes to determine the candidates. This results in
retrieving only items like to the predicted user profile
while users can register their interests with different
attributes.
After weighing every feature equally when
computing the similarity score, this might not match
with user’s attributes priority. There could be user
specific requirements when searching for real estate.
Hence, making this approach more personalized by
incorporating different weights for each feature can
improve the recommendation performance.
5 CONCLUSION
In this paper, an approach for building a
recommendation system in real-estate is proposed. In
the case of numerous cold-start customers, this
method resolves the item cold-start problem with
respectable warm-start item recommendations. It
adapts a session-based recommendation system and
makes use of already in place methods to effectively
handle sequential and contextual data for the encoded
attribute prediction of the next interacted item. The
experimental results demonstrate that this method is
superior to baselines utilizing the top-n
recommendation with the dataset from the real estate
search engine as well as to other used methods.
Based on the idea, people in the same group
should react similarly to similar items, the
recommendation approach improves search results by
using customer demographic data (Matuszelański and
Kopczewska, 2022). In the future, the proposed
method will be combine the knowledge base of real-
estate investment (Nguyen et al., 2022) for
recommending more accuracy based on customers’
behaviors, which will be aimed at the demographic
profile of customer.
ACKNOWLEDGMENT
This research was supported by The VNUHCM-
University of Information Technology’s Scientific
Research Support Fund.
REFERENCES
Adomavicius, G., Tuzhilin, A. 2011. Context-aware
recommender systems. In Recommender Systems
Handbook. Ricci, F. et al. (Eds). Springer.
Beutel, A., Covington, P., Jain, S., et al. 2018. Latent cross:
Making use of context in recurrent recommender
systems. In WSDM 2018, 11th Int. Conf. Web Search
Data Mining, 2018, pp. 46–54. ACM.
Bouihi, B., Bahaj, M. 2018. Ontology and rule-based
recommender system for e-learning
applications. International Journal of Emerging
Technologies in Learning, 14(15), 4.
Chia, J., Harun, A., Kassim, A., 2016. Understanding
factors that influence house purchase intention among
consumers in kota kinabalu: An application of buyer
behavior model theory. J. Technol. Manage. Bus. 3(2).
Hidasi, B., et al. 2016. Session-based recommendations
with recurrent neural networks. In ICLR 2016, 4th
International Conference on Learning Representations,
May 2016.
Hu, Y., Koren, Y., Volinsky, C. 2008. Collaborative
filtering for implicit feedback datasets. In ICDM 2008,
8th IEEE Int. Conf. Data Mining, Dec. 2008, pp. 263–
272. IEEE.
Li, J., Ren, P., Chen, Z., et al. 2017. Neural attentive
session-based recommendation. In Proc. ACM Conf.
Inf. Knowl. Manage., Nov. 2017. ACM
Liu, Q., Zeng, Y., Mokhosi, R., et al. 2018. STAMP: Short-
term attention/memory priority model for session-based
recommendation. In SIGKDD 2018, 24th Int. Conf.
Knowl. Discovery Data Mining, Jul. 2018, pp. 1831–
1839. ACM.
Lops, P., Gemmis, M., Semeraro, G. 2011. Content-based
recommender systems: State of the art and trends. In
Recommender Systems Handbook. Ricci, F. et al. (Eds).
Springer.
Matuszelański, K., Kopczewska, K. 2022. Customer Churn
in Retail E-Commerce Business: Spatial and Machine
Learning Approach. Journal of Theoretical and
KEOD 2023 - 15th International Conference on Knowledge Engineering and Ontology Development
262

Applied Electronic Commerce Research 17(1), 165-
198.
Nguyen, H., Tran, D., Do, H., et al. 2020. Design an
intelligent system to automatically tutor the method for
solving problems. International Journal of Integrated
Engineering, 12(7), 211-223.
Nguyen, H. D., Tran, T. V., Pham, X. T., et al. 2021.
Ontology-based integration of knowledge base for
building an intelligent searching chatbot. Sensors &
Materials, 33(9), 3101 – 3123.
Nguyen, H. T., Nguyen, H. D., Do, N. V., et al. 2022.
Knowledge Representation of Expert System in Real-
Estate Investment Combining Collected Data. In New
Trends in Intelligent Software Methodologies, Tools
and Techniques (pp. 571-583). IOS Press.
Nguyen, H. D., Truong, D., Vu, S., et al. 2023. Knowledge
Management for Information Querying System in
Education via the Combination of Rela-Ops Model and
Knowledge Graph. Journal of Cases on Information
Technology (JCIT), 25(1), 1-17.
Roy, D., Dutta, M. 2022. A systematic review and research
perspective on recommender systems. Journal of Big
Data, 9(1), 59.
Sarwar, B., Karypis, G., Konstan, et al. 2001. Item-based
collaborative filtering recommendation algorithms. In
WWW 2001, 10th Int. Conf. World Wide Web, 2001, pp.
285–295.
Vartak, M., Thiagarajan, A., Miranda, C., et al. 2017. A
meta-learning perspective on cold-start
recommendations for items. In NIPS 2017, 31
st
Annual
Conference on Neural Information Processing Systems,
pp. 6904–6914, Dec. 2017.
Wei, J., He, J., Chen, K. et al., 2017. Collaborative filtering
and deep learning based recommendation system for
cold start items. Expert Syst. Appl. 69, 29–39.
Yan, Y., Zhang, Q., Ni, B., et al. 2019. Learning context
graph for person search. In CVPR 2019, the IEEE/CVF
conference on computer vision and pattern recognition,
pp. 2158-2167. IEEE.
Zhang, S., Yao, L., Sun, A., Tay, Y. 2019. Deep learning
based recommender system: A survey and new
perspectives. ACM Comput. Surv. 52(1), 5
Design a Recommendation System in Real Estate Investment Based on Context Approach
263
