
Proposal of a New Approach Using Deep Learning for QR Code
Embedding
Kanaru Kumabuchi
a
and Hiroyuki Kobayashi
b
Osaka Institute of Technology University, Osaka, Japan
Keywords:
Deep Learning, Image Hiding, Image Processing.
Abstract:
The purpose of this research is to enhance the technique of embedding QR codes into arbitrary images using
deep learning. Previous approaches faced the issue of compromising the quality when embedding QR codes
into arbitrary images. We address this problem by proposing a deep learning model and learning method
that can improve the quality of embedded images and accurately recover QR codes. Specifically, we design
a new model using deep learning that embeds QR codes into images while minimizing the degradation of
image quality. The effectiveness of the proposed model and learning method is validated through experiments,
demonstrating the enhancement of image quality in the embedded images and accurate QR code recovery.
1 INTRODUCTION
In recent years, with the widespread use of the inter-
net, exchanging information and communication has
become convenient. However, on the other hand, the
leakage of personal information and organizational
assets has become a significant problem. As a coun-
termeasure, there is a technique called steganography.
Steganography is the art of concealing one piece of
digital data (audio, images) within another piece of
digital data.
In a previous research(Kumabuchi and Kobayashi,
2022), two models were created using deep learning:
one to embed QR codes into images and the other to
restore QR codes from images with embedded QR
codes. However, there was a significant issue with
embedding QR codes into images, as it substantially
compromised the quality of the original images. In
this research, similar to the previous study, we aim
to create new Encoder and Decoder models to embed
QR codes into images and restore them without com-
promising the quality of the original images. We pro-
pose and evaluate a model capable of achieving this
goal
In a previous research, we referred to the model
proposed by Simon J
´
egou(J
´
egou et al., 2017). for
semantic segmentation, which improved upon the
Unet(Ronneberger et al., 2015) model, and used it as
a
https://orcid.org/0009-0004-0181-4185
b
https://orcid.org/0000-0002-4110-3570
a basis for our work. In this study, we further re-
fined that model to devise a method for embedding
QR codes while preserving their distinctive features.
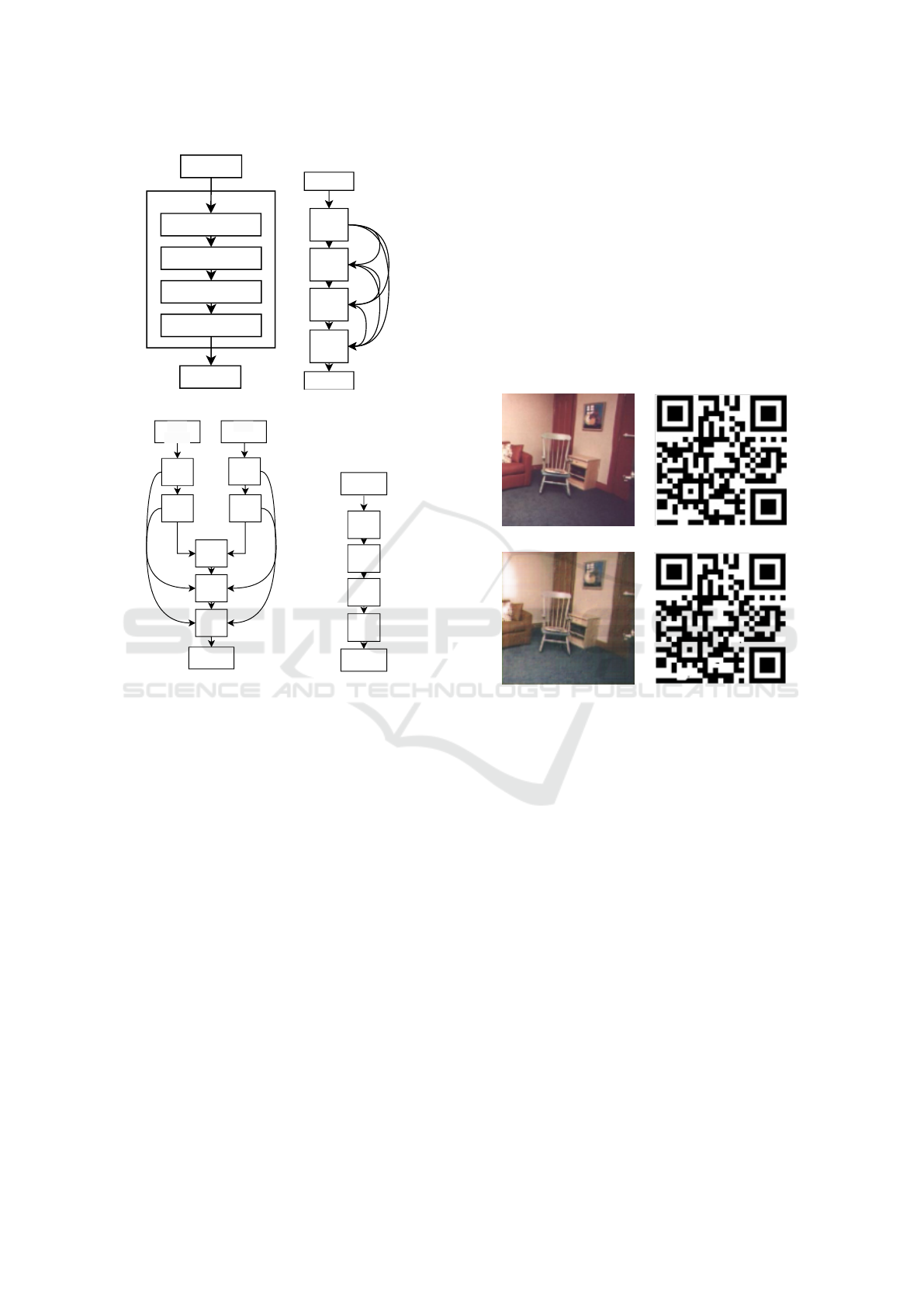
2 PRINCIPLE
In this PRINCIPLE, the embedding and restoration
procedures of the QR code are explained with the aid
of Figure1, along with the learning steps.
1. Input a three-channel image and a one-channel
QR code into two separate models.
2. Concatenate the two output feature maps at an in-
termediate layer and input them into the Conca-
tImageModel.
3. In the QR code embedding model, train with the
three-channel image as the ground truth.
4. Pseudo-image and normalize it before inputting it
into the Restoration Model.
5. Train the Restoration Model using the output im-
age as input and the one-channel QR code image
as the ground truth.
6. Next, compute the loss for both models using the
Mean Squared Error (MSE) from the following
equation (1), and then calculate the weighted loss
using the following equation (2).
7. Use the computed loss values to update the
weights of both models.
342
Kumabuchi, K. and Kobayashi, H.
Proposal of a New Approach Using Deep Learning for QR Code Embedding.
DOI: 10.5220/0012238900003543
In Proceedings of the 20th International Conference on Informatics in Control, Automation and Robotics (ICINCO 2023) - Volume 1, pages 342-345
ISBN: 978-989-758-670-5; ISSN: 2184-2809
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

Figure 1: Overall Structure.
Loss = mse =
1
M
1
· M
2
M
1
∑
n=1
M
2
∑
n=1
{y(i, j) − x(i, j)}
2
(1)
loss = α · Loss
Encoder
+ β ·Loss
Decoder
(2)
3 MODEL CREATION
3.1 Datasets
The dataset used in this research consists of indoor
images shown in Figure 2 and images generated us-
ing Python’s QR code library as depicted in Figure 3.
For the training process, 8000 images and QR codes
were utilized for each category, and an additional set
of 1000 images was reserved for testing purposes.
Figure 2: Indoor image.
3.2 Conventional Model
In this research, we aimed to enhance the perfor-
mance by utilizing an improved model compared to
the conventional approach. Before explaining the
model used in this study, let’s first describe the con-
ventional model. The conventional model combines
Figure 3: QR Image.
a 3-channel image with a QR code and inputs them
together into a single Encoder-Decoder model. How-
ever, in our model, we take a different approach by
performing dimensionality reduction separately for
the QR code and the 3-channel image using distinct
models. This enables us to embed the QR code into
the 3-channel image while preserving its distinctive
features. +
Input Image Input Image
Figure 4: Conventional Model.
3.3 Model Structure
The overall structure of this research is as shown
in Figure 1, comprising two models. The Encoder
Model in the figure serves as a model for embedding
QR codes. On the other hand, the Decoder Model is
used for recovering QR codes embedded in images.
In the following subsections, I will provide a detailed
explanation of the structure of each model.
3.3.1 Encoder Model
The structure of the Encoder model is an Encoder-
Decoder architecture. In this architecture, both three-
channel images and QR codes are input into the same
Encoder shown in Figure 5c. Dimensional compres-
Proposal of a New Approach Using Deep Learning for QR Code Embedding
343
Conv2D
Batch Norm
Relu
Dropout
Input
Output
(a) Dence parts.
Dence
Parts
Dence
Parts
Dence
Parts
Dence
Parts
Input
Output
(b) Dence block.
Input
Image
Input
QR
Dence
Parts
Dence
Parts
Dence
Parts
Dence
Parts
Concat
Image
Dence
Parts
Dence
Parts
Embedded
Image
(c) Encoder Model.
Dence
Parts
Dence
Parts
Dence
Parts
Dence
Parts
Embedded
Image
Restoration
Image
(d) Decoder model.
Figure 5: Detail Structure.
sion is performed, and the intermediate layers are con-
catenated before decoding is done. The model struc-
ture consists of Dense Blocks, as depicted in Figure
5b. Inside the Dense Block, there are convolutional
layers, batch normalization layers, ReLU layers, and
Dropout layers as shown in Figure 5a. The use of skip
connections for all layers prevents the vanishing gra-
dient problem
3.3.2 Decoder Model
The Decoder model aims to restore a QR code from
an image containing an embedded QR code. The De-
coder model has a simple structure, consisting of four
connected Dense blocks as shown in the Figure 5d.
4 EXPERIMENTAL
In this EXPERIMENTAL, we conducted a 200-epoch
training using the learning procedure described in the
principles and the model illustrated in Figure1. Sub-
sequently, we utilized the trained model to compare
the output results with those obtained from the con-
ventional model, thus examining the differences be-
tween them
4.1 Results of Conventional Models
After training the model using the architecture shown
in Figure 5, we obtained the results for the test im-
ages, as shown in Figure 7. However, it is evident
that while the conventional model can restore the QR
code, the images with embedded QR codes result in a
loss of image quality in the input images
(a) Input Image. (b) Input QRcode.
(c) Embedded Image. (d) Restoration QRcode.
Figure 6: Conventional model result.
4.2 Results of this Research Model
After training the model using the procedure shown in
Figure 1, we obtained results for test images as shown
in Figures 8 and 9. In comparison to the results of the
conventional model depicted in Figure 6, it was con-
firmed that not only can QR codes be restored, but
they can also be embedded more clearly into the im-
ages. Furthermore, the presence of areas in Figure
8 where embedding is not complete is believed to be
due to high brightness values.
5 CONCLUSION
In this research, we developed new Encoder and De-
coder models to improve the performance of both im-
age embedding and QR code restoration. As a result,
we were able to obtain output images with embed-
ded QR codes that closely resembled the input im-
ICINCO 2023 - 20th International Conference on Informatics in Control, Automation and Robotics
344

(a) Input Image. (b) Input QRcode.
(c) Embedded Image. (d) Restoration QRcode.
Figure 7: This research model result.
(a) Input Image. (b) Input QRcode.
(c) Embedded Image. (d) Restoration QRcode.
Figure 8: This research model result.
ages, and the restored QR codes were in a readable
state.
REFERENCES
J
´
egou, S., Drozdzal, M., Vazquez, D., Romero, A., and Ben-
gio, Y. (2017). The one hundred layers tiramisu: Fully
convolutional densenets for semantic segmentation. In
Proceedings of the IEEE conference on computer vi-
sion and pattern recognition workshops, pages 11–19.
Kumabuchi, K. and Kobayashi, H. (2022). Improving the
performance of qr code embedding in arbitrary images
using deep learning. volume 2022, pages 1P1–Q08.
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-
net: Convolutional networks for biomedical image
segmentation. In Medical Image Computing and
Computer-Assisted Intervention–MICCAI 2015: 18th
International Conference, Munich, Germany, October
5-9, 2015, Proceedings, Part III 18, pages 234–241.
Springer.
Proposal of a New Approach Using Deep Learning for QR Code Embedding
345
