
IDENTIFYING AN OBSERVABLE PROCESS WITH ONE
OF SEVERAL SIMULATION MODELS VIA UMPI TEST
Nicholas A. Nechval, Konstantin N. Nechval, Edgars K. Vasermanis, Kristine Rozite
Department of Mathematical Statistics, University of Latvia, Raina Blvd 19, Riga LV-1019, Latvia
Keywords: Observable process, UMPI test, Identification
Abstract: In this paper, for identifying an observable process with one of several simulation models, a uniformly most
powerful invariant (UMPI) test is developed from the generalized maximum likelihood ratio (GMLR). This
test can be considered as a result of a new approach to solving the Behrens-Fisher problem when covariance
matrices of multivariate normal populations (compared with respect to their means) are different and
unknown. The test is based on invariant statistic whose distribution, under the null hypothesis, does not
depend on the unknown (nuisance) parameters.
1 INTRODUCTION
Computational modeling has become an important
tool for building and testing theories in Cognitive
Science during the last years. The area of its
applications includes, in particular, business process
simulation, resource management, knowledge
management systems, operations research,
economics, optimization, stochastic models, logic
programming, operation and production
management, supply chain management, work flow
management, total quality management, logistics,
risk analysis, scheduling, forecasting, cost benefit
analysis, economic revitalization, financial models,
accounting, policy issues, regulatory impact
analysis, etc. One of the most important steps in the
development of a simulation model is recognition of
the simulation model, which is an accurate
representation of the process being studied. This
procedure consists of two basic stages: (i)
establishing the form of an adequate simulation
model for the process under study and then (ii)
estimating precisely the values of its parameters.
In developing strategies for the design of
experiments for parameter estimation, it is
customarily assumed that the correct form of the
model is known. However, experimenters often do
not have just one model known to be correct but
have instead m>1 rival models to consider as
possible explanations of the process being
investigated. It is natural for model users to devise
rules so as to identify an observable process with
one of several distinct models, collected for
simulation, which accurately represents the process,
especially when decisions involving expensive
resources are made on the basis of the results of the
model.
Substantiation that a computerized model within
its domain of applicability possesses a satisfactory
range of accuracy consistent with the intended
application of the model is usually referred to as
model validation and is the definition used in this
paper.
Validation is defined in this paper following a
classic simulation textbook (Law and Kelton, 1991,
p. 299): “Validation is concerned with determining
whether the conceptual simulation model (as
opposed to the computer program) is an accurate
representation of the system under study”. Hence,
validation cannot result in a perfect model: the
perfect model would be the real system itself.
Instead, the model should be 'good enough', which
depends on the goals of the model. Validation is a
central aspect to the responsible application of
models to scientific and managerial problems. The
importance of validation to those who construct and
use models is well recognized. General discussions
on validation of simulation models can be found in
all textbooks on simulation. Examples are Banks and
Carson (1984), Law and Kelton (1991), and Pegden,
Shannon, and Sadowski (1990). A well-known
article is Sargent (1991). Recent survey article is
Kleijnen (1995), including 61 references.
Statistical hypothesis testing (Naylor and Finger,
1967), as distinguished from graphical or descriptive
techniques, offers a framework that is particularly
152
Nechval N., Nechval K., Vasermanis E. and Rozite K. (2004).
IDENTIFYING AN OBSERVABLE PROCESS WITH ONE OF SEVERAL SIMULATION MODELS VIA UMPI TEST.
In Proceedings of the First International Conference on Informatics in Control, Automation and Robotics, pages 152-159
DOI: 10.5220/0001133101520159
Copyright
c
SciTePress

attractive for model validation. A test would
compare a sample of observations taken from the
target population against a sample of predictions
taken from the model. Not surprisingly, a number of
statistical tools have been applied to validation
problems. For example, Freese (1960) introduced an
accuracy test based on the standard χ
2
tests.
Ottosson and Håkanson (1997) used R
2
and
compared with so-called highest-possible R
2
, which
are predictions from common units (parallel time-
compatible sets). Jans-Hammermeister and McGill
(1997) used an F-statistic-based lack of fit test.
Landsberg et al. (2003) used R
2
and relative mean
bias. Bartelink (1998) graphed field data and
predictions with confidence intervals. Finally,
Alewell and Manderscheid (1998) used R
2
and
normalized mean absolute error (NMAE).
In practice, simulations are usually validated by
considering not one but several output measures
(e.g., expected waiting time, expected queue length,
etc.). In this case, one could in principle validate the
simulation for each output measure individually, as
discussed previously. However, these output
measures will in general be dependent. In some
cases, it may be possible to model this dependence
explicitly – e.g., using a multivariate normal
distribution. The aim of this study was to develop
and use criteria, which permit an objective
comparison of different models to the observed field
data and to each other. A given model, which
describes a specific system significantly better, will
be declared the ‘valid’ model while the other will be
rejected. The term ‘valid’ is used here in a sense that
any model that could not be proven invalid would be
a valid model for the system.
Real plants are, in general, time-varying for
various reasons, such as plant operating point
changes, component aging, equipment wear, heat
and material transfer degradation effects.
In this paper, we propose an effective technique
for validation of simulation models (static or
dynamic), performing the UMPI test for comparison
of a real process data set and data sets of several
simulation models.
2 TESTING THE VALIDITY OF A
SIMULATION MODEL
Suppose that we desire to validate a kth multivariate
stationary response simulation model of an
observable process, which has p response variables.
Let x
ij
(k) and y
ij
be the ith observation of the jth
response variable of the kth model and the process
under study, respectively. It is assumed that all
observation vectors, x
i
(k)=(x
i1
(k), ..., x
ip
(k))′, y
i
=(y
i1
,
..., y
ip
)′, i=1(1)n, are independent of each other,
where n is a number of paired observations. Let
z
i
(k)=x
i
(k)−y
i
, i=1(1)n, be paired comparisons
leading to a series of vector differences. Thus, for
testing the validity of a simulation model of a real,
observable process, it can be obtained and used a
sample of n independent observation vectors
Z(k)=(z
1
(k), ... ,z
n
(k)). Each sample Z(k), k∈{1, …,
m}, is declared to be realization of a specific
stochastic process with unknown parameters.
In this paper, for testing the validity of the kth
simulation model of a real, observable process, we
propose a statistical approach that is based on the
generalized maximum likelihood ratio. In using
statistical hypothesis testing to test the validity of a
simulation model under a given experimental frame
and for an acceptable range of accuracy consistent
with the intended application of the model, we have
the following hypotheses:
H
0
(k): the kth model is valid for the acceptable
range of accuracy under a given experimental frame;
H
1
(k): the kth model is invalid for the acceptable
range of accuracy under a given experimental frame.
(1)
There are two possibilities for making a wrong
decision in statistical hypothesis testing. The first
one, type I error, is accepting the alternative
hypothesis H
1
(k) when the null hypothesis H
0
(k) is
actually true, and the second one, type II error, is
accepting the null hypothesis when the alternative
hypothesis is actually true. In model validation, the
first type of wrong decision corresponds to rejecting
the validity of the model when it is actually valid,
and the second type of wrong decision corresponds
to accepting the validity of the model when it is
actually invalid. The probability of making the first
type of wrong decision will be called model
builder’s risk (
α
(k)) and the probability of making
the second type of wrong decision will be called
model user’s risk (
β
(k)). Thus, for fixed n, the
problem is to construct a test, which consists of
testing the null hypothesis
H
0
(k): z
i
(k) ∼ N
p
(0,Q(k)), ∀i = 1(1)n, (2)
where Q(k) is a positive definite covariance matrix,
versus the alternative
H
1
(k): z
i
(k) ∼ N
p
(a(k),Q(k)), ∀i = 1(1)n, (3)
where a(k)=(a
1
(k), ... ,a
p
(k))′≠(0, ... ,0)′ is a mean
vector. The parameters Q(k) and a(k) are unknown.
It will be noted that the result of Theorem 1
given below can be used to obtain test for the
hypothesis of the form H
0
: z
i
(k) follows
IDENTIFYING AN OBSERVABLE PROCESS WITH ONE OF SEVERAL SIMULATION MODELS VIA UMPI TEST
153
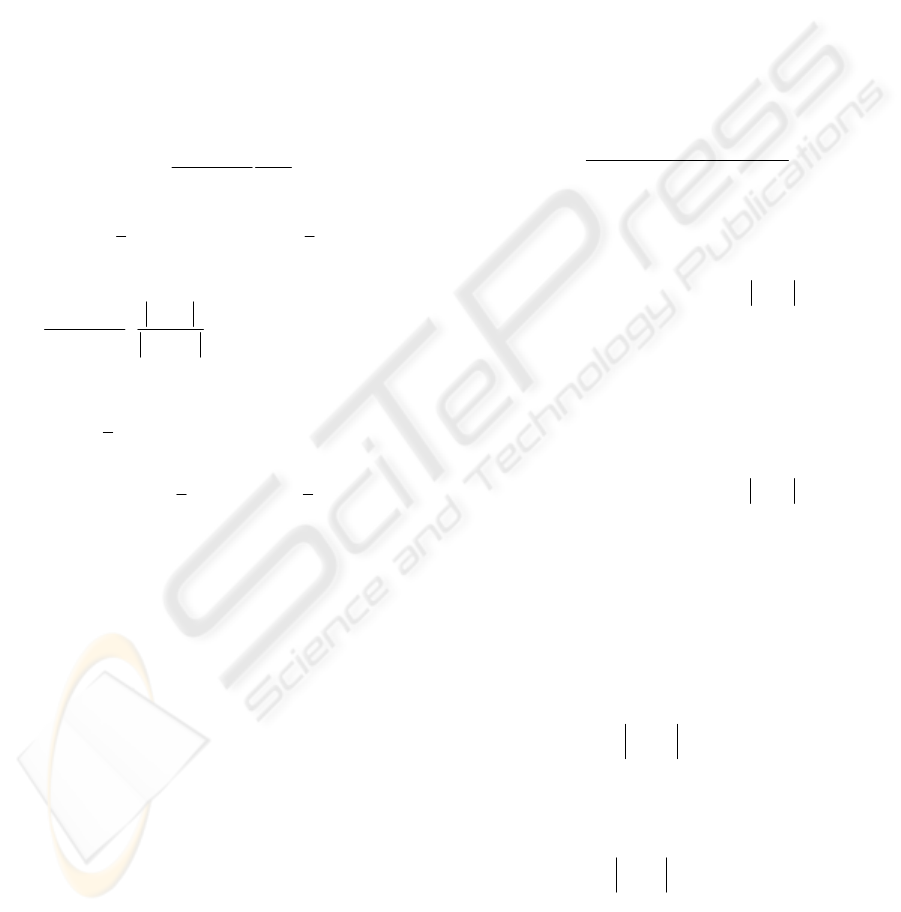
N
p
(a(k),Q(k)) versus H
a
: z
i
(k) does not follow
N
p
(a(k),Q(k)), ∀i=1(1)n. The general strategy is to
apply the probability integral transforms of w
k
,
∀k=p+2(1)n, to obtain a set of i.i.d. U(0,1) random
variables under H
0
(Nechval, 1998b). Under H
a
this
set of random variables will, in general, not be i.i.d.
U(0,1). Any statistic, which measures a distance
from uniformity in the transformed sample (say, a
Kolmogorov-Smirnov statistic), can be used as a test
statistic.
Theorem 1 (Characterization of the
Multivariate Normality). Let z
i
(k), i=1(1)n, be n
independent p-multivariate random variables
(n≥p+2) with common mean a(k) and covariance
matrix (positive definite) Q(k). Let w
r
(k), r=p+2, …,
n, be defined by
r
r
p
pr
kw
r
1)1(
)(
−+−
=
()()
)()()()()(
1
1
11
kkkkk
rrrrr −
−
−−
−
′
−× zzSzz
,, ... 2, ,1
)(
)(
)1(
1
npr
k
k
p
pr
r
r
+=
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
−
+−
=
−
S
S
(4)
where
,)1/()()(
1
1
1
∑
−
=
−
−=
r
i
ir
rkk zz (5)
,))()())(()()(
1
1
111
∑
−
=
−−−
′
−−=
r
i
ririr
kkkkk zzz(zS (6)
then the z
i
(k) (i=1, …, n) are N
p
(a(k),Q(k)) if and
only if w
p+2
(k), …, w
n
(k) are independently
distributed according to the central F distribution
with p and 1, 2, . . . , n−(p+1) degrees of freedom,
respectively.
Proof. The proof is similar to that of the
characterization theorems (Nechval et al., 1998a,
2000) and so it is omitted here.
3 GMLR STATISTIC
In order to distinguish the two hypotheses (H
0
(k) and
H
1
(k)), a generalized maximum likelihood ratio
(GMLR) statistic is used. The GMLR principle is
best described by a likelihood ratio defined on a
sample space
Z with a parameter set Θ, where the
probability density function of the sample data is
maximized over all unknown parameters, separately
for each of the two hypotheses. The maximizing
parameter values are, by definition, the maximum
likelihood estimators of these parameters; hence the
maximized probability functions are obtained by
replacing the unknown parameters by their
maximum likelihood estimators. Under H
0
(k), the
ratio of these maxima is a Q(k)-free statistic. This is
shown in the following.
Let the complete parameter space for
θ
(k)=(a(k),Q(k)) be Θ={(a(k),Q(k)): a(k)∈R
p
,
Q(k)∈
Q
p
}, where Q
p
is a set of positive definite
covariance matrices, and let the restricted parameter
space for
θ
(k), specified by the H
0
(k) hypothesis, be
Θ
0
={(a(k),Q(k)): a(k)=0, Q(k)∈Q
p
}. Then one
possible statistic for testing H
0
(k):
θ
(k)∈Θ
0
versus
H
1
(k):
θ
(k)∈Θ
1
, where Θ
1
=Θ−Θ
0
, is given by the
generalized maximum likelihood ratio
.
)()((L max
)()((L max
)(
0
0
)(
)(
1
1
)(
);
);
=
∈
∈
kk
kθk
LR
kH
k
kH
k
θ
θ
θ
Z
Z
Θ
Θ
(7)
Under H
0
(k), the joint likelihood for Z(k) is given by
/2
/2
)(
0
)()(2=))();((
n
np
kH
kkkL
−
−
QZ
πθ
.2/)()]()[(exp
1
1
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
′
−×
∑
=
−
n
i
ii
kkk zQz (8)
Under H
1
(k), the joint likelihood for Z(k) is given by
/2
/2
)(
1
)()(2=))();((
n
np
kH
kkkL
−
−
QZ
πθ
.))/2()(()]([))()((exp
1
1
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
−
′
−−×
∑
=
−
n
i
ii
kkkkk azQaz
(9)
It can be shown that
);
∈
)()(( max
)(
0
0
)(
kkL
kH
k
θ
θ
Z
Θ
)2/exp()(
ˆ
)(2
/2
0
/2
npk
n
np
−=
−
−
Q
π
(10)
and
);
∈
)()(( max
)(
1
1
)(
kkL
kH
k
θ
θ
Z
Θ
),2/exp()(
ˆ
)(2
/2
1
/2
npk
n
np
−=
−
−
Q
π
(11)
where
)(
ˆ
0
kQ = Z(k)Z′(k)/n, (12)
)(
ˆ
1
kQ = (Z(k)
−
$
a (k)u′)(Z(k)−
$
a(k)u′)′/n, (13)
ICINCO 2004 - SIGNAL PROCESSING, SYSTEMS MODELING AND CONTROL
154

and
a
ˆ
(k)=Z(k)u/u′u are the well-known maximum
likelihood estimators of the unknown parameters
Q(k) and a(k) under the hypotheses H
0
(k) and H
1
(k),
respectively, u=(1,...,1)′ is the n-dimensional column
vector of units. A substitution of (10) and (11) into
(7) yields
.)(
ˆ
)(
ˆ
2/
1
2/
0
nn
kkLR
−
= QQ (14)
Taking the (n/2)th root, this likelihood ratio is
evidently equivalent to
1
10
)(
ˆ
)(
ˆ
−
•
= kkLR QQ
./))()()(()()(/)()( uuuZuZZZZZ
′′
−
′′
= kkkkkk
(15)
Now the likelihood ratio in (15) can be considerably
simplified by factoring out the determinant of the p
× p matrix Z(k)Z′(k) in the denominator to obtain
this ratio in the form
•
LR
⎥
⎦
⎤
⎢
⎣
⎡
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
′
′′
−
′
′
=
−
uu
uZZZuZ
ZZ
ZZ
))((])()([))((
1)()(
)()(
1
kkkk
kk
kk
()
nkkkk /))((])()([))((11
1
uZZZuZ
−
′′
−=
. (16)
This equation follows from a well-known
determinant identity. Clearly (16) is equivalent
finally to the statistic
)1(
-
)( −
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
=
•
LR
p
pn
kv
n
),()]()[(
1
kkkn
p
pn
aTa
))
−
′
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
−
=
(17)
where )()(
1
knk QT
)
= . It is known that )(k),(k)( Ta
)
is a complete sufficient statistic for the parameter
θ
(k)=(a(k),Q(k)). Thus, the problem has been
reduced to consideration of the sufficient statistic
))(,)(( kk Ta
)
. It can be shown that under H
0
, v
n
(k) is
a Q(k)-free statistic which has the property that its
distribution does not depend on the actual
covariance matrix Q(k). This is given by the
following theorem.
Theorem 2 (PDF of the Statistic v
n
(k)). Under
H
1
(k), the statistic v
n
(k) is subject to a noncentral F-
distribution with p and n−p degrees of freedom, the
probability density function of which is
),);((
)(
1
qnkvf
nkH
1
2
2
1
)(
2
,
2
−
−
⎥
⎦
⎤
⎢
⎣
⎡
−
⎥
⎦
⎤
⎢
⎣
⎡
⎟
⎠
⎞
⎜
⎝
⎛
−
=
p
n
p
kv
pn
p
pnp
Β
2
)(1
n
n
kv
pn
p
−
⎥
⎦
⎤
⎢
⎣
⎡
−
+×
,
)(
1
2
)(
;
2
;
2
e
1
11
2/
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
⎥
⎦
⎤
⎢
⎣
⎡
−
+×
−
−
kpv
pnknqp
n
F
n
nq
0<v
n
(k)<∞. (18)
where
1
F
1
(b;c;x) is the confluent hypergeometric
function, q(k)=a′(k)[Q(k)]
−1
a(k) is a noncentrality
parameter. Under H
0
(k), when q(k)=0, (18) reduces
to a standard F-distribution with p and n−p degrees
of freedom,
1
)(
0
2
,
2
));((
−
⎥
⎦
⎤
⎢
⎣
⎡
⎟
⎠
⎞
⎜
⎝
⎛
−
=
pnp
nkvf
nkH
Β
,)(1 (k)
2
1
2
p
2
n
nn
p
kv
pn
p
v
pn
p
−
−
⎥
⎦
⎤
⎢
⎣
⎡
−
+
⎥
⎦
⎤
⎢
⎣
⎡
−
×
0<v
n
(k)<∞. (19)
Proof. The proof follows by applying Theorem 1
(Nechval, 1997a, 1999) and being straightforward is
omitted.
4 GMLR TEST
The GMLR test of H
0
(k) versus H
1
(k), based on
v
n
(k), is given by
⎪
⎩
⎪
⎨
⎧
<
≥
),( then ),(
),( then ),(
)(
0
1
kHkh
kHkh
kv
n
(20)
and can be written in the form
IDENTIFYING AN OBSERVABLE PROCESS WITH ONE OF SEVERAL SIMULATION MODELS VIA UMPI TEST
155

⎪
⎩
⎪
⎨
⎧
≥
=
)),(( )(<)( if ,0
)),(( )()( if 1,
))((
0
1
kHkhkv
kHkhkv
kvd
n
n
n
(21)
where h(k)>0 is a threshold of the test which is
uniquely determined for a prescribed level of
significance
α
(k) so that
{}
).())((sup
0
)(
kkvdE
n
k
α
θ
θ
=
∈Θ
(22)
When the parameter
θ
(k)=(a(k),Q(k)) is unknown, it
is well known that no the uniformly most powerful
(UMP) test exists for testing H
0
(k) versus H
1
(k)
(Nechval, 1997b). However, it can be shown that the
test (20) is UMPI for a natural group of
transformations on the space of observations. Here
the following theorem holds.
Theorem 3 (UMPI Test). For testing the
hypothesis H
0
(k) : q(k)=0 versus the alternative
H
1
(k): q(k)>0, the test given by (20) is UMPI.
Proof. The proof is similar to that of Nechval
(1997b) and so it is omitted here.
5 ROBUSTNESS PROPERTY
In what follows, as one more optimality of the v
n
-
test, a robustness property can be studied in the
following set-up. Let Z(k)=(z
1
(k), ..., z
n
(k))' be an n
× p random matrix with a PDF
ϕ
, let C
np
be the
class of PDF’s on R
np
with respect to Lebesque
measure dZ(k), and let
H be the set of nonincreasing
convex functions from [0,∞) into [0,∞). We assume
n
≥ p+1. For a(k)∈ R
p
and Q(k)∈ Q
p
, define a class
of PDF’s on R
np
as follows:
C
np
(a(k),Q(k))
.,))()(()]([))()((
)())()()((:
1
1
2/
⎪
⎪
⎪
⎪
⎭
⎪
⎪
⎪
⎪
⎬
⎫
⎪
⎪
⎪
⎪
⎩
⎪
⎪
⎪
⎪
⎨
⎧
∈
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
−
′
−×
=∈
=
∑
=
−
−
H
C
η
η
n
i
ii
n
np
kkkkk
kkkkff
azQaz
QQ,a;Z
(23)
In this model, it can be considered the following
testing problem:
pnp
kkkH QC ∈∈ )( ),)(,( :)(
0
QQ0
ϕ
(24)
versus
pnp
kkkkkH QC ∈≠
∈
)( ,)( ),)()(( :)(
1
Q0aQ,a
ϕ
,
(25)
and shown that v
n
-test is UMPI. Clearly if ( z
1
(k), ...,
z
n
(k)) is a random sample of z
i
(k)~N
p
(a(k),Q(k)),
i=1(1)n, or Z(k)~N
np
(ua′(k),I
n
⊗Q(k)), where u=(1,
..., 1)′∈ R
n
, the PDF
ϕ
of Z(k) belongs to
C
np
(a(k),Q(k)).
Further if f(Z(k);a(k),Q(k)) belongs
to
C
np
(a(k),Q(k)), then
∫
∞
∗
=
∗
0
)())(,)();(())()();(( rdGkrkkfkkkg QaZQaZ ,
(26)
also belongs to C
np
(a(k),Q(k)) where
∗
G
is a
distribution function on (0,∞), and so
C
np
(a(k),Q(k))
contains the (np-dimensional) multivariate t-
distribution, the multivariate Cauchy distribution,
the contaminated normal distribution, etc. Here the
following theorem holds.
Theorem 4
(Robustness Property). For the
problem (24)-(25), v
n
(k)-test is UMPI and the null
distribution of v
n
(k) is F-distribution with p and n-p
degrees of freedom.
Proof. The proof is similar to that of Nechval
[1997b] and so it is omitted here.
In other words, for any Q(k)∈
Q
p
and any
ϕ
∈C
np
(0,Q(k)), the null distribution of v
n
(k) is
exactly the same as that when Z(k)~N
np
(0,I
n
⊗Q(k)),
that is, the distribution of v
n
(k) under H
0
(k) is the F-
distribution with p and n−p degrees of freedom. In
this sense, the v
n
(k)-test is robust against departures
from normality.
6 RISK MINIMIZATION
For fixed n, in terms of the above probability density
functions in (18) and (19), the probability of making
the first type of wrong decision (model builder’s risk
(
α
(k)) is found by
∫
∞
=
)(
)(
0
)());((]);()[(
kh
nnkH
kdvnkvfnkhk
α
(27)
and the probability of making the second type of
wrong decision (model user’s risk (
β
(k)) by
.)())(,);(()](,);()[(
)(
0
)(
1
∫
=
kh
nnkH
kdvkqnkvfkqnkhk
β
(28)
ICINCO 2004 - SIGNAL PROCESSING, SYSTEMS MODELING AND CONTROL
156

This implies that the model is a perfect
representation of the process with respect to its mean
behavior. Any value of a(k) will result in a value for
q(k) that is greater than zero. As the value of a(k)
increases, the value of q(k) will also increase. Hence,
the noncentrality parameter q(k) is the validity
measure for the above test (20). Let us assume that
for the purpose for which the simulation model is
intended, the acceptable range of accuracy (or the
amount of agreement between the model and the
process) can be stated as 0≤q(k)≤q
•
(k), where q
•
(k) is
the largest permissible value. In the statistical
validation of simulation models, for preassigned
n=n
•
(n
•
>p) determined by a data collection budget,
if we let w
α
(k)
and w
β
(k)
be the unit weight (cost) of
the model builder’s risk (
α
(k)) and the model user’s
risk (
β
(k)), then the optimal threshold of test, h*(k),
can be found by solving the following optimization
problem:
Minimize:
]);()[()](,);([
)(
•••
= nkhkwkqnkhR
k
α
α
)](,);()[(
)(
kqnkhkw
k
••
+
β
β
(29)
Subject to:
),1,0()(
∈
kh (30)
where R[h(k);n
•
,q
•
(k)] is a risk representing the
weighted sum of the model builder’s risk and the
model user’s risk. It can be shown that h*(k)
satisfies the equation
));(*(
)(
0
)(
•
nkhfw
kHk
α
)).(,);(*(
)(
1
)(
kqnkhfw
kHk
••
=
β
(31)
In the statistical validation of simulation models, the
model user’s risk is more important that the model
builder’s risk, so that w
α
(k)
≤w
β
(k)
.
For instance, let us assume that p=10, n
•
=40,
q
•
(k)=0.5, and w
α
(k)
=w
β
(k)
=1. It follows from (31)
that the optimal threshold h*(k) is equal to 0.365.
If the sample size of observations, n, is not
bounded above, then the optimal value n* of n can
be defined as
:inf* nn =
,
)](,);([min arg=)(*
),()](,);(*[)( + ]);(*[)(
(0,1))(
⎟
⎟
⎟
⎟
⎟
⎠
⎞
⎜
⎜
⎜
⎜
⎜
⎝
⎛
≤
•
∈
••
kqnkhRkh
krkqnkhknkhk
kh
βα
(32)
where r
•
(k) is a preassigned value of the sum of the
kth model builder’s risk and the kth model user’s
risk.
7 PROCESS IDENTIFICATION
Let us assume that there is available a sample of
measurements of size n from each simulation model.
The elements of a sample from the kth model are
realizations of p-dimensional random variables
x
i
(k),
i=1(1)n, for each k∈{1, …, m}. We are investigating
an observable process on the basis of the
corresponding sample of size n of p-dimensional
measurements
y
i
=(y
i1
, ... ,y
ip
)′, i=1(1)n. We postulate
that this process can be identified with one of the m
simulation models but we do not know with which
one. The problem is to identify the observable
process with one of the m specified simulation
models. When there is the possibility that the
observable process cannot be identified with one of
the m specified simulation models, it is desirable to
recognize this case.
Let
y
i
and x
i
(k) be the ith observation of the
process and kth model variable, k∈{1, …, m},
respectively. It is assumed that all observation
vectors,
y
i
=(y
i1
, ..., y
ip
)′, x
i
(k)=(x
i1
(k), ..., x
ip
(k))′,
i=1(1)n, are independent of each other, where n is a
number of paired observations. Let
z
i
(k)=x
i
(k)−y
i
,
i=1(1)n, be paired comparisons leading to a series of
vector differences. Thus, for identifying the
observable process with one of the m specified
simulation models, it can be obtained and used
samples of n independent observation vectors
Z(k)=(z
1
(k), ... ,z
n
(k)), k=1(1)m. It is assumed that
under H
0
(k), z
i
(k)~N
p
(0,Q(k)), ∀i=1(1)n, where Q(k)
is a positive definite covariance matrix. Under H
1
(k),
z
i
(k)~N
p
(a(k),Q(k)), ∀i=1(1)n, where a(k)=(a
1
(k), ...,
a
p
(k))′≠(0, ... ,0)′ is a mean vector. The parameters
a(k) and Q(k), ∀k=1(1)m, are unknown. For fixed n,
the problem is to identify the observable process
with one of the m specified simulation models. If the
observable process cannot be identified with one of
the m specified simulation models, it is desirable to
recognize this case.
The test of H
0
(k) versus H
1
(k), based on the
GMLR statistic v
n
(k), is given by (20). Thus, if
IDENTIFYING AN OBSERVABLE PROCESS WITH ONE OF SEVERAL SIMULATION MODELS VIA UMPI TEST
157

v
n
(k)≥h(k) then the kth simulation model is
eliminated from further consideration.
If (m−1) simulation models are so eliminated,
then the remaining model (say, kth) is the one with
which the observable process may be identified.
If all simulation models are eliminated from
further consideration, we decide that the observable
process cannot be identified with one of the m
specified simulation models.
If the set of simulation models not yet eliminated
has more than one element, then we declare that the
observable process may be identified with
simulation model k* if
)),()(( max arg* kvkhk
n
Dk
−=
∈
(33)
where D is the set of simulation models not yet
eliminated by the above test.
8 APPLICATION OF THE TEST
This section discusses an application of the above
test to the following problem. An airline company
operates more than one route. It has available more
than one type of airplanes. Each type has its relevant
capacity and costs of operation. The demand on each
route is known only in the form of the sample data,
and the question asked is: which aircraft should be
allocated to which route in order to minimize the
total cost (performance index) of operation? This
latter involves two kinds of costs: the costs
connected with running and servicing an airplane,
and the costs incurred whenever a passenger is
denied transportation because of lack of seating
capacity. (This latter cost is “opportunity” cost.) We
define and illustrate the use of the loss function, the
cost structure of which is piecewise linear. Within
the context of this performance index, we assume
that a distribution function of the passenger demand
on each route is known. Thus, we develop our
discussion of the allocation problem in the presence
of completely specified demand distributions. We
formulate this problem in a probabilistic setting.
Let A
1
, ..., A
g
be the set of airplanes which
company utilize to satisfy the passenger demand for
transportation en routes 1, ..., h. It is assumed that
the company operates m routes which are of
different lengths, and consequently, different
profitabilities. Let
)(
)(
sf
k
ij
represent the probability
density function of the passenger demand S for
transportation en route j (j=1, ..., h) at the ith stage
(i∈1, …, n) for the kth simulation model (k∈{1, …,
m}). It is required to minimize the expected total
cost of operation (the performance index)
∑∑
∫
==
∞
⎥
⎥
⎦
⎤
⎢
⎢
⎣
⎡
−
h
j
g
r
Q
k
ijijjrijrijii
ij
dssfQscuwJ
11
)(
)()( + =)(U
(34)
subject to
∑
=
≤
h
j
ririj
grau
1
, ..., 1,= ,
(35)
where
∑
=
=
g
r
rjrijij
hjquQ
1
, , ... 1,= , (36)
U
i
={u
rij
} is the g × h matrix, u
rij
is the number of
units of airplane A
r
allocated to the jth route at the
ith stage, w
rij
is the operation costs of airplane A
r
for
the jth route at the ith stage, c
j
is the price of a one-
way ticket for air travel en jth route, q
rj
is the limited
seating capacity of airplane A
r
for the jth route, a
ri
is
available the number of units of airplane A
r
at the ith
stage.
Let us assume that
}{
∗∗
=
riji
uU is the optimal
solution of the above-stated programming problem.
Since information about the passenger demand is not
known precisely, this result provides only
approximate solution to a real airline system. To
depict the real, observable airline system more
accurately, the test proposed in this paper, might be
employed to validate the results derived from the
analytical model (34)-(36). In this case
},..., {1, ,1(1) ,)()( nihjYkXkZ
ijijij
∈∀
=
−
=
(37)
where
,)( + )( =)(
0
)()(
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎣
⎡
∫
∫
∗
∗
∞
∗
ij
ij
Q
Q
k
ijij
k
ijjij
dssfQdsssfckX
(38)
is the expected gain (ensured by the service of a
passenger demand on the jth route at the ith stage)
derived from the analytical model (34)-(36),
∑
=
∗∗
=
g
r
rjrijij
hjquQ
1
,, ... 1,= , (39)
Y
ij
is the real gain ensured by the service of a
passenger demand on the jth route at the ith stage
ICINCO 2004 - SIGNAL PROCESSING, SYSTEMS MODELING AND CONTROL
158

(an observation of the airline system response
variable).
Thus, the methodology proposed in this paper
allows one to determine whether the analytical
model (34)-(36) is appropriate for minimizing the
total cost of airline operation.
9 CONCLUSIONS
The main idea of this paper is to find a test statistic
whose distribution, under the null hypothesis, does
not depend on unknown (nuisance) parameters. This
allows one to eliminate the unknown parameters
from the problem.
The authors hope that this work will stimulate
further investigation using the approach on specific
applications to see whether obtained results with it
are feasible for realistic applications.
ACKNOWLEDGMENTS
This research was supported in part by Grant No.
02.0918 and Grant No. 01.0031 from the Latvian
Council of Science and the National Institute of
Mathematics and Informatics of Latvia.
REFERENCES
Alewell, C. and Manderscheid, B., 1998. Use of objective
criteria for the assessment of biogeochemical
ecosystem models. Ecol. Modelling, 105, 113–124.
Banks, J. and Carson, J.S., 1984. Discrete-event System
Simulation. NJ : Prentice-Hall, Englewood Cliffs.
Bartelink, H.H., 1998. Radiation interception by forest
trees: a simulation study on effects of stand density
and foliage clustering on absorption and transmission.
Ecol. Modelling, 105, 213–225.
Freese, F., 1960. Testing accuracy. Forest Sci., 6, 139–
145.
Jans-Hammermeister, D.C. and McGill, W.B., 1997.
Evaluation of three simulation models used to describe
plant residue decomposition in soil. Ecol. Modelling,
104, 1–13.
Kleijnen, J.P.C., 1995. Verification and validation of
simulation models. European Journal of Operational
Research, 82, 145-162.
Law, A.M. and W.D. Kelton, W.D., 1991. Simulation
Modeling and Analysis. New York: McGraw-Hill.
Naylor, T.H. and Finger, J.M., 1967. Verification of
computer simulation models. Management Science,
14, 92-101.
Nechval, N.A., 1997a. Adaptive CFAR tests for detection
of a signal in noise and deflection criterion. In: Digital
Signal Processing for Communication Systems, T.
Wysocki, H. Razavi, & B. Honary, eds. Kluwer
Academic Publishers, 177-186.
Nechval, N.A., 1997b. UMPI test for adaptive signal
detection. In: Proc. SPIE 3068: Signal Processing,
Sensor Fusion, and Target Recognition VI, I. Kadar,
ed. Orlando, Florida USA, Paper No. 3068-73, 12
pages.
Nechval, N.A. and Nechval, K.N., 1998a. Characterization
theorems for selecting the type of underlying
distribution. In: Abstracts of Communications of the
7th Vilnius Conference on Probability Theory and
Mathematical Statistics & the 22nd European Meeting
of Statisticians (Vilnius, Lithuania, August 12-18).
TEV, 352-353.
Nechval, N.A., 1988b. A general method for constructing
automated procedures for testing quickest detection of
a change in quality control. Computers in Industry, 10,
1988, 177-183.
Nechval, N.A. and Nechval, K.N., 1999. CFAR test for
moving window detection of a signal in noise. In:
Proceedings of the 5th International Symposium on
DSP for Communication Systems (Perth-Scarborough,
Australia, February 1-4). IEEE, 134-141.
Nechval, N.A., Nechval, K.N., and Vasermanis, E.K.,
2000. Technique of testing for two-phase regressions.
In: Proceedings of the Second International
Conference on Simulation, Gaming, Training and
Business Process Reengineering in Operations, (Riga,
Latvia, September 21-23). RTU, 129-133.
Ottosson, F. and Håkanson, L., 1997. Presentation and
analysis of a model simulating the pH response of lake
liming. Ecol. Modelling, 104, 89–111.
Pegden, C.P., Shannon, R.E., and Sadowski, R.P., 1990.
Introduction to Simulation using SIMAN. New York:
McGraw-Hill.
Sargent, R.G., 1991. Simulation model verification and
validation. In: Proceedings of the 1991 Winter
Simulation Conference, 37-47.
IDENTIFYING AN OBSERVABLE PROCESS WITH ONE OF SEVERAL SIMULATION MODELS VIA UMPI TEST
159
