
IMPROVING ICA ALGORITHMS APPLIED TO PREDICTING
STOCK RETURNS
J. M. G
´
orriz
University of C
´
adiz
Avda Ram
´
on Puyol E 11202 s/n Algeciras
C. G. Puntonet
University of Granada
Daniel Saucedo E 18071 s/n
R. Mart
´
ın-Clemente
University of Seville
Avda. Descubrimientos s/n
Keywords:
Independent Component Analysis, On-line Support Vector Machines, Regularization Theory, Preprocessing
Techniques.
Abstract:
In this paper we improve a well known signal processing technique such as independent component analysis
(ICA) or blind source separation applied to predicting multivariate financial such as portfolio of stock returns
using the Vapnik-Chervonenkis theory. The key idea in ICA algorithms is to linearly map the input space
series (stock returns) into a new space which contains statistically independent components. There´s a wide
class of ICA algorithms however they usually fail due to their high convergence rates or their limited ability
of local search, as the number of observed signals increases.
1 INTRODUCTION
ICA algorithms have been applied successfully to sev-
eral fields such as biomedicine, speech, sonar and
radar, signal processing, etc. and more recently also
to time series forecasting (G
´
orriz et al., 2003), i.e. us-
ing stock data (Back and Weigend, 1997), and they
have faced the problem of blind source separation
(BSS) (Bell and Sejnowski, 1995). In the latter ap-
plication the mixing process of multiple sensors is
based on linear transformation making the following
assumptions:
1. the original (unobservable) sources are statistically
independent which are related to social-economic
events.
2. the number of sensors (stock series) is equal to that
of sources.
3. the Darmois-Skitovick conditions are satisfied
(Cao and Liu, 1996).
In this work we apply Genetic Algorithms to ICA in
the search of the separation matrix, in order to im-
prove the performance of endogenous learning sup-
port vector machines (SVMs) in real time series fore-
casting speeding up convergence rates (scenarios with
the BSS problem in higher dimension). Thus we are
using ICA as preprocessing technique in order to ex-
tract interesting structure in the stock.
SVMs are learning algorithms based on the struc-
tural risk minimization principle (Vapnik, 1999)
(SRM) characterized by the use of the expansion of
SV “admissible” kernels and the sparsity of the solu-
tion. They have been proposed as a technique in time
series forecasting (Muller et al., 1999) and have faced
the overfitting problem, presented in classical neural
networks, thanks to their high capacity for general-
ization. The solution for SVM prediction is achieved
solving the constrained quadratic programming prob-
lem thus SV machines are nonparametric techniques,
i.e. the number of basis functions are unknown before
hand. The solution of this complex problem in real-
time applications can be extremely uncomfortable be-
cause of high computational time demand. Moreover
the low rates of ICA algorithms can cause a design
fault in real time applications.
We organize the essay as follows. SV-ICA algo-
rithm for financial time series prediction will be pre-
sented in section 3. In section we show a guided GA
to improve convergence rates in ICA algorithms. Fi-
nally we diplay results and state some conclusions in
section 5.
351
M. Górriz J., G. Puntonet C. and Martín-Clemente R. (2004).
IMPROVING ICA ALGORITHMS APPLIED TO PREDICTING STOCK RETURNS.
In Proceedings of the First International Conference on E-Business and Telecommunication Networks, pages 351-355
DOI: 10.5220/0001399803510355
Copyright
c
SciTePress
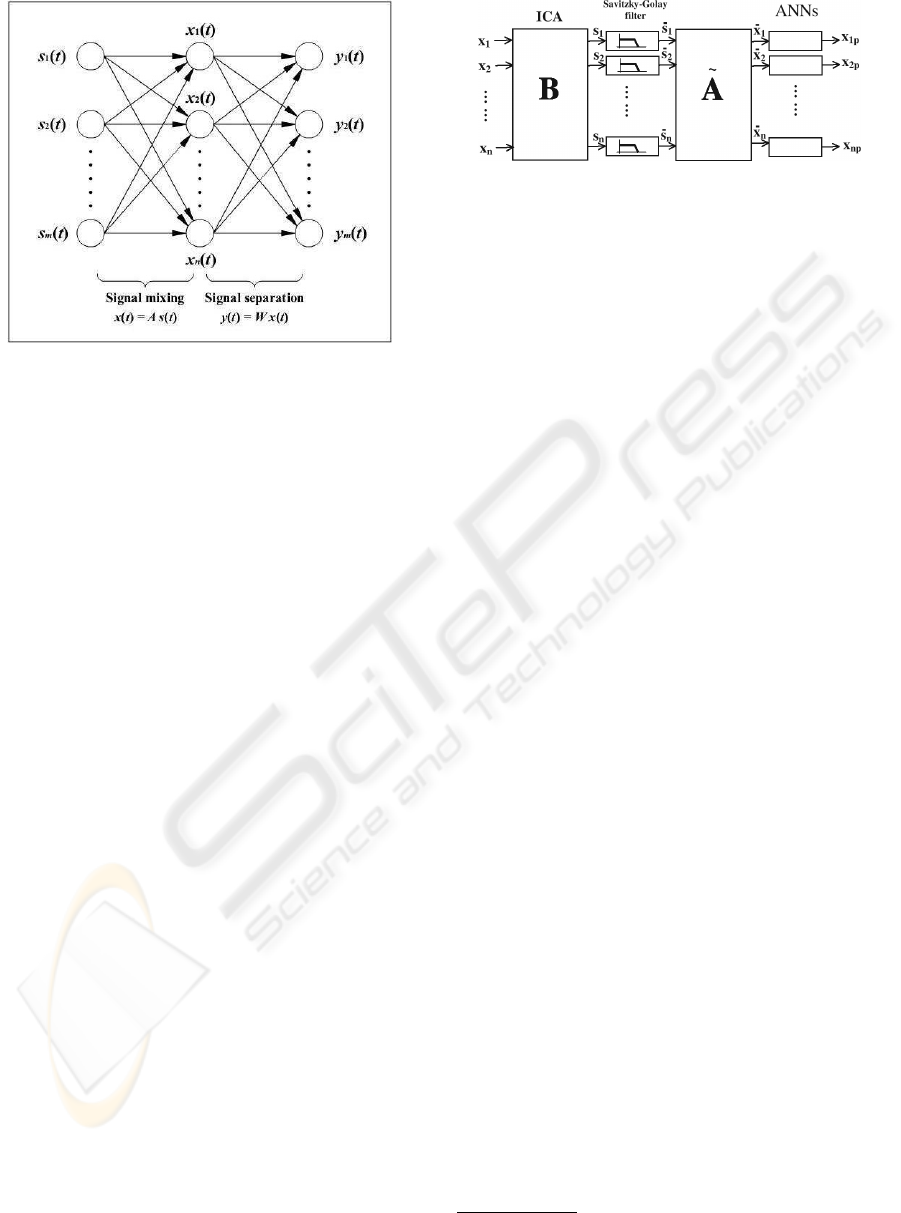
Figure 1: Independent Component Analysis and BSS prob-
lem. We suppose in financial ICA that the observed signal
are linearly generated by some underlying independent fac-
tors.
2 INTRODUCTION TO ICA
ICA has been used as a solution of the blind source
separation problem (Bell and Sejnowski, 1995) denot-
ing the process of taking a set of measured signal in a
vector, x, and extracting from them a new set of sta-
tistically independent components (ICs) in a vector y.
In the basic ICA each component of the vector x is
a linear instantaneous mixture of independent source
signals in a vector s with some unknown deterministic
mixing coefficients:
x
i
=
N
i=1
a
ij
s
j
(1)
Due to the nature of the mixing model we are able
to estimate the original sources ˜s
i
and the de-mixing
weights b
ij
applying i.e. ICA algorithms based on
higher order statistics like cumulants.
˜s
i
=
N
i=1
b
ij
x
j
(2)
Using vector-matrix notation and defining a time
series vector x =(x
1
,...,x
n
)
T
, s,
˜
s and the matrix
A = {a
ij
} and B = {b
ij
} we can write the overall
process as:
˜
s = Bx = BAs = Gs (3)
where we define G as the overall transfer matrix. The
estimated original sources will be, under some con-
ditions included in Darmois-Skitovich theorem (Cao
and Liu, 1996), a permuted and scaled version of the
original ones. Thus, in general, it is only possible to
Figure 2: Schematic representation of the ICA preprocess-
ing step.
find G such that G = PD where P is a permutation
matrix and D is a diagonal scaling matrix.
3 SVM-ICA ALGORITHM
SVM are essentially Regularization Networks (RN)
with the kernels being Green´s function of the cor-
responding regularization operators (Smola et al., ).
Using this connection, with a clever choice of regu-
larization operator (based on SVM philosophy), we
should obtain a parametric model being very resistant
to the overfitting problem. Our parametric model is
a Resource allocating Network (Platt, 1991) charac-
terized by the control of neural resources and by the
use of matrix decompositions, i.e. Singular Value De-
composition (SVD) and QR Decomposition to input
selection and neural pruning (G
´
orriz et al., 2004).
The on-line RN based on “Resource Allocating
Network” algorithms (RAN)
1
(Platt, 1991) which
consist of a network using RBFs, a strategy for
• Allocating new units (RBFs), using two part nov-
elty condition (Platt, 1991)
• Input space selection and neural pruning using ma-
trix decompositions such as SVD and QR with piv-
oting (Salmer
´
on-Campos, 2001).
and a learning rule based on the Structural Risk Min-
imization principle as discuss in (G
´
orriz et al., 2004).
4 GA APPLIED TO THE
SEPARATION MATRIX IN ICA
PROCEDURE.
A GA can be modelled by means of a time inhomo-
geneous Markov chain obtaining interesting proper-
ties related with weak and strong ergodicity, conver-
gence and the distribution probability of the process.
A canonical GA is constituted by operations of pa-
rameter encoding, population initialization, crossover
1
The principal feature of these algorithms is sequential
adaptation of neural resources.
ICETE 2004 - WIRELESS COMMUNICATION SYSTEMS AND NETWORKS
352

, mutation, mate selection, population replacement,
fitness scaling, etc. proving that with these simple op-
erators a GA does not converge to a population con-
taining only optimal members. However, there are
GAs that converge to the optimum, The Elitist GA and
those which introduce Reduction Operators (Eiben
et al., 1991). Our GA combines the two balancing
goals: exploiting the blindly search like a canoni-
cal GA and using statistical properties like a standard
ICA algorithm. In order to include statistical infor-
mation into the algorithm (it would be a nonsense to
ignore it!) we define the hybrid statistical genetic op-
erator based on reduction operators as follows:
q, M
n
G
p =
1
ℵ(T
n
)
exp
||q − S
n
· p||
2
T
n
; p, q ∈ ℘
N
(4)
where ℵ(T
n
) is the normalization constant depending
on temperature T
n
, n is the iteration and S
n
is the step
matrix which contains statistical properties, i.e based
on cumulants it can be expressed using quasi-Newton
algorithms as (Hyv
¨
arinen and Oja, ):
S
n
=(I − µ
n
(C
1,β
y,y
S
β
y
− I)); p
i
∈ C (5)
where C
1,β
y,y
is the cross-cumulant matrix whose ele-
ments are [C
α,β
y,y
]
ij
=
Cum(y
i
,...,y
i
α
,y
j
,...,y
j
β
) and S
β
y
is the sign matrix
of the output cumulants.
Finally the guided GA (GGA) is modelled, at each
step, as the stochastic matrix product acting on prob-
ability distributions over populations:
G
n
= P
n
R
· F
n
· C
k
P
n
c
· M
(P
m
,G)
n
(6)
where F
n
is the selection operator, P
n
R
a reduc-
tion operator, C
k
P
n
c
is the cross-over operator and
M
(P
m
,G)
n
are the mutation and guided operators.
The GA used applies local search (using the se-
lected mutation and crossover operators) around the
values (or individuals) found to be optimal (elite) the
last time. The computational time depends on the
encoding length, number of individuals and genes.
Because of the probabilistic nature of the GA-based
method, the proposed method almost converges to a
global optimal solution on average. In our simulation
nonconvergent case was found.
5 SIMULATIONS AND
CONCLUSIONS
To check the performance of the proposed hybrid al-
gorithm, 50 computer simulations were conducted to
test the GGA vs. the GA method (without guide)
and the most relevant ICA algorithm to date, Fas-
tICA (Hyv
¨
arinen and Oja, ). In this paper we neglect
the evaluation of the computational complexity of the
current methods, described in detail in several refer-
ences such as (Tan and Wang, 2001). The main rea-
son lies in the fact that we are using a 8 nodes Cluster
Pentium II 332MHz 512Kb Cache, thus the compu-
tational requirements of the algorithms (fitness func-
tions, encoding, etc.) are generally negligible com-
pared with the cluster capacity. Logically GA-based
BSS approaches suffer from a higher computational
complexity.
Consider the mixing cases from 2 to 20 indepen-
dent random super-gaussian input signals. We focuss
our attention on the evolution of the crosstalk vs. the
number of iterations using a mixing matrix randomly
chosen in the interval [−1, +1]. The number of indi-
viduals chosen in the GA methods were N
p
=30in
the 50 (randomly mixing matrices) simulations for a
number of input sources from 2 (standard BSS prob-
lem) to 20 (BSS in biomedicine or finances). The
standard deviation of the parameters of the separation
over the 50 runs never exceeded 1% of their mean
values while using the FASTICA method we found
large deviations from different mixing matrices due
to its limited capacity of local search as dimension in-
creases. The results for the crosstalk are displayed in
Table 5. It can be seen from the simulation results
that the FASTICA convergence rate decreases as di-
mension increases whereas GA approaches work effi-
ciently.
A GGA-based BSS method has been developed to
solve BSS problem from the linear mixtures of inde-
pendent sources. The proposed method obtain a good
performance overcoming the local minima problem
over multidimensional domains (see table 5). Exten-
sive simulation results prove the ability of the pro-
posed method. This is particular useful in some
medical applications where input space dimension in-
creases and in real time applications where reaching
fast convergence rates is the major objective.
Minimizing the regularizated risk functional, using
an operator the enforce flatness in feature space, we
build a hybrid model that achieves high prediction
performance (G
´
orriz et al., 2003), comparing with the
previous on-line algorithms for time series forecast-
ing. This performance is similar to the one achieve
by SVM but with lower computational time demand,
essential feature in real-time systems. The benefits
of SVM for regression choice consist in solving a
-uniquely solvable- quadratic optimization problem,
unlike the general RBF networks, which requires suit-
able non-linear optimization with danger of getting
stuck in local minima. Nevertheless the RBF net-
works used in this paper, with the help of various
techniques obtain high performance, even under ex-
tremely volatile conditions, since the level of noise
and the change of delay operation mode applied to
the chaotic dynamics was rather high.
IMPROVING ICA ALGORITHMS APPLIED TO PREDICTING STOCK RETURNS
353
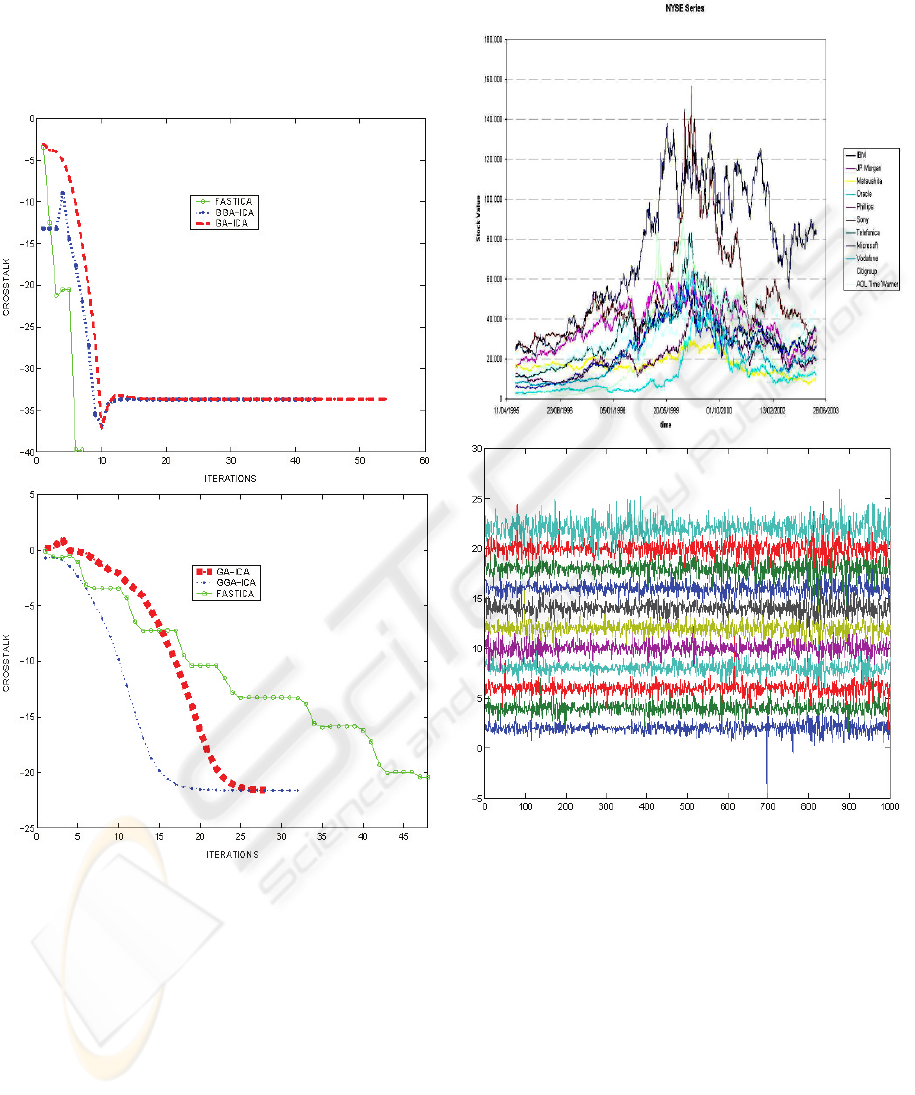
Table 1: Figures: 1) Mean Crosstalk (50 runs) vs. iterations
to reach the convergence for num. sources equal to 2 using
Ga approach and FASTICA (Hyv
¨
arinen and Oja, ). 2) Mean
Crosstalk (50 runs) vs. iterations to reach the convergence
for num. sources equal to 20 3) Set of Series used. 4) Set
of ICs.
ICETE 2004 - WIRELESS COMMUNICATION SYSTEMS AND NETWORKS
354

REFERENCES
Back, A. and Weigend, A. (1997). A first application of in-
dependent component analysis to extracting structure
from stock returns. International Journal of Neural
Systems, vol. 8(5).
Bell, A. and Sejnowski, T. (1995). An information-
maximization approach to blind separation and blind
deconvolution. Neural Computation, vol. 7:1129–
1159.
Cao, X. and Liu, W. (1996). General approach to blind
source separation. In IEEE Transactions on signal
Processing, volume vol. 44,3, pages 562–571.
Eiben, A., Aarts, E., and Hee, K. V. (1991). Global conver-
gence of genetic algorithms:a markov chain analysis.
Parallel Problem Solving from Nature, Lecture Notes
in Computer Science, vol. 496:4–12.
G
´
orriz, J. M., Puntonet, C. G., Salmer
´
on, M., and Ortega,
J. (June 2003). New method for filtered ica signals
applied to volatile time series. Lecture Notes in Com-
puter Science, LNCS, vol. 2687:433–440,ISSN 0302–
9743.
G
´
orriz, J., Puntonet, C., and Salmer
´
on, M. (2004). On line
algorithm for time series prediction based on support
vector machine philosophy. In The International Con-
ference on Computational Science. Lecture notes on
Computer Science. ICCS 2004, Krakow, Poland USA.
Hyv
¨
arinen, A. and Oja, E. A fast fixed point algorithm for
independent component analysis. Neural Computa-
tion, 9:1483–1492.
Muller, K., Smola, A., Ratsch, G., Scholkopf, B., and
Kohlmorgen, J. (1999). Using support vector ma-
chines for time series prediction. Advances in kernel
Methods-Support Vector Learning, MIT Press, pages
243–254.
Platt, J. (1991). A resource-allocating network for function
interpolation. Neural Computation, 3:213–225.
Salmer
´
on-Campos, M. (2001). Predicci
´
on de Series Tem-
porales con Rede Neuronales de Funciones Radiales
yT
´
ecnicas de Descomposici
´
on Matricial. Phd thesis,
University of Granada, Departamento de Arquitectura
y Tecnolog
´
ıa de Computadores.
Smola, A., Scholkopf, B., and Muller, K. The connection
between regularization operators and support vector
kernels. Neural Networks, 11:637–649.
Tan, Y. and Wang, J. (2001). Nonlinear blind source sepa-
ration using higher order statistics and a genetic algo-
rithm. IEEE Transactions on Evolutionary Computa-
tion, vol. 5(6).
Vapnik, V. (1999). The Nature of Statistical Learning The-
ory. Springer, 2nd edition edition.
IMPROVING ICA ALGORITHMS APPLIED TO PREDICTING STOCK RETURNS
355
