
USER INTERFACE DESIGN FOR VOICE CONTROL SYSTEMS
Wolfgang Tschirk
Siemens AG Austria, Speech Recognition Resort
Erdberger Lände 26, A-1031 Wien, Austria
Keywords:
Voice control systems, speech recognition, user interfaces, man-machine interfaces.
Abstract:
A voice control system converts spoken commands into control actions, a process which is always imperfect
due to errors of the speech recognizer. Most speech recognition research is focused on decreasing the recogniz-
ers’ error rates; comparatively little effort was spent to find interface designs that optimize the overall system,
given a fixed speech recognizer performance. In order to evaluate such designs prior to their implementation
and test, three components are required: 1) an appropriate set of performance figures of the speech recognizer,
2) suitable performance criteria for the user interface, and 3) a mathematical framework for estimating the
interface performance from that of the speech recognizer. In this paper, we will identify four basic interface
designs and propose an analytical approach for predicting their respective performance.
1 INTRODUCTION
James Glass et al. point out that "developing conver-
sational interfaces is a classic chicken and egg prob-
lem. In order to develop system capabilities, one
needs to have a large corpus of data [...]. In order to
collect data that reflect actual usage, one needs to have
a system that users can speak to." (Glass et al., 2000).
Compared to the vast literature on traditional speech
recognition aspects like signal analysis, feature ex-
traction, pattern comparison techniques, and search
strategies, for which excellent reports are available in
(Rabiner and Juang, 1993), (IEEE, 1994), and (IEEE,
2002), little work was devoted to the development of
analytical methods for user interface design. How-
ever, analytical approaches can considerably shorten
trial and error loops in system development and raise
robustness and user-friendlyness of voice control sys-
tems in a way hardly achievable by classical speech
recognizer improvements.
A mathematical approach for dialogue control is
proposed in (Niimi and Nishimoto, 1999), where
the authors derive relations between speech recog-
nizer performance and dialogue efficiency, and com-
pare four strategies of confirming user inputs. They
focus on keyword confusion and leave the prob-
lem most severe in real world voice control systems,
namely to balance the acceptance of non-keywords
with its counterpart, the keyword rejection, as fu-
ture work. The computer-aided design and develop-
ment approach for spoken dialogue systems given in
(Lin and Lee, 2001) estimates performance figures by
quantitative simulations, comparing different strate-
gies of query and confirmation on a finite state ma-
chine model of the user interface.
In our paper, we consider all possible user inter-
face errors for four basic interface designs. We show
analytically how the error rates observed on the user
interface depend on those of the speech recognizer,
and how the former can be minimized while the latter
remain unchanged. As an auxiliary result, we express
the error rates for different vocabulary sizes in terms
of the rates for a single vocabulary of arbitrary (how-
ever reasonable) size, an achievement which greatly
reduces test effort. Throughout this paper, we con-
centrate on isolated word recognition, which is the
dominant technology for a wide range of voice control
systems. We take into account that, typically, users
of such systems are not pleased with a period of un-
certainty after having entered a command; therefore,
we do not allow delayed decisions, although they are
found to improve the performance of spoken dialogue
systems (Souvignier et al., 2000).
Another crucial aspect of voice control system de-
sign lies beyond the scope of our paper: the question
of selecting appropriate commands for a given set of
21
Tschirk W. (2004).
USER INTERFACE DESIGN FOR VOICE CONTROL SYSTEMS.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 21-26
DOI: 10.5220/0002602100210026
Copyright
c
SciTePress

control functions − words that are easily recognized
automatically and, at the same time, correspond to the
intuitive choice of most users.
2 SPEECH RECOGNIZER
ERRORS
2.1 Error Types
In a speech recognizer’s front end, the incoming audio
signal is converted into parameters, commonly called
features, that carry information relevant for the recog-
nition act. The result is a pattern of features, which
may be a vector composed of energy values over time
and frequency or of other appropriate measures (Ra-
biner and Juang, 1993). Since here we do not deal
with the feature extraction, we consider the pattern
rather than the audio signal as the input to the speech
recognizer.
Then, within the context of isolated word recogni-
tion, a speech recognizer is an algorithm that assigns
one of N + 1 classes W
i
, 0 ≤ i ≤ N , to a pattern p.
We denote W
0
the garbage class, i.e. the class which
shall be assigned to all patterns derived from back-
ground noise. The set of classes {W
i
, 0 ≤ i ≤ N }
is the recognizer’s vocabulary; N, the number of non-
garbage classes, is the vocabulary size.
For classifying an incoming pattern p, the recog-
nizer calculates a score s
i
for each class W
i
. The
higher s
i
, the better p matches W
i
, such that finally
the class with the highest score is assigned to p. (For
recognizers that deliver a low score as an indicator for
a good match, we reverse the sign of the score). The
scores shall only depend on p; we envisage a func-
tional split where the recognizer is context-free and
any context-dependency is located in an extra compo-
nent of the user interface.
When a pattern is classified as garbage, we say that
it is rejected; otherwise we say that it is accepted.
Each recognition error falls into one of the following
three categories: confusion (a non-garbage pattern is
assigned the wrong non-garbage class), false rejec-
tion (a non-garbage pattern is classified as garbage),
and false acceptance (a garbage pattern is assigned a
non-garbage class).
A recognizer’s performance can be described in
terms of rates c of confusions, r of false rejections,
and a of false acceptances. Such rates are usually es-
timated by feeding a set of patterns which were not
used for training (the test set) into the recognizer and
counting the incorrect outcomes appropriately. If the
test set represents the patterns expected during oper-
ation, the rates measured can be viewed as a good
guess for the underlying probabilities.
2.2 Error Rates and Vocabulary Size
In Section 6, we give an algorithm for predicting the
error rates observable on the user interface. It in-
volves the estimation of the speech recognizer’s error
rates on different vocabulary sizes. Ideally, they are
obtained from testing; however, this might require an
enormous test effort and the availability of sufficient
data. As an alternative, we now derive a formalism
for predicting the error rates c
M
, r
M
, and a
M
on a
vocabulary of size M from the rates estimated on a
vocabulary of size N. It is particularly helpful in the
design of voice control systems featuring large num-
bers of commands when data are available for only
a small number of words, and relies on assumptions
reasonable in the absence of other evidence:
If the recognizer receives a non-garbage pattern p
of class W
k
, we assume that 1) the probability that
p is rejected rather than accepted as W
k
does not de-
pend on the presence of classes other than W
0
and
W
k
, and 2) the probability that p is classified as W
i
rather than W
k
is equal for all i 6∈ {k, 0} and inde-
pendent of the presence of classes other than W
i
and
W
k
. If the recognizer receives a garbage pattern, we
assume that 3) the probability that p is classified as
W
i
rather than garbage is equal for all i 6= 0 and in-
dependent of the presence of classes other than W
i
and W
0
.
With these assumptions and the trivial figure
c
1
= 0, we obtain (see Appendix) for M, N > 0:
c
M
=
(M − 1)c
N
(N − 1) + (M − N )c
N
, (1)
r
M
=
(N − 1)r
N
(N − 1) + (M − N )c
N
, (2)
a
M
=
Ma
N
N + (M − N)a
N
. (3)
3 USER INTERFACE ERRORS
Also on the user interface, we observe confusions,
false rejections, and false acceptances. How the rates
of these errors derive from the speech recognizer’s er-
ror rates, depends on the particular user interface de-
sign. For a number of design alternatives, we will give
these relationships in the following sections.
In general, no design will be optimum with respect
to all three types of errors. Therefore, each voice con-
trol system calls for its own optimization criterion.
Some authors propose to use weighed sums of the er-
ror rates (Villarrubia and Acero, 1993) and to set the
weights according to the requirements of the particu-
lar application. Others measure dialogue efficiency in
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
22

terms of the average number of exchanges taken (Ni-
imi and Nishimoto, 1999) or the percentage of satis-
fied users (Lin and Lee, 2001).
In our performance estimations, we will stick to the
rates of confusions, false rejections, and false accep-
tances, and, from the first two of them, which relate
to incorrect system reactions on correct user inputs,
we will estimate a lower bound for the rate of failed
command sequences (a command sequence is a con-
catenation of keyword utterances required to make the
voice control system perform a certain action; e.g. a
command sequence consisting of light and switch on
may cause the voice control switch on the light).
4 SUBVOCABULARY TYPES
4.1 Embedded Subvocabulary
In a voice control system designed to control a light,
a heater, and a telephone, the word warmer makes
sense in the context of the heater control but not when
the light menu or the telephone menu are selected; the
commands switch on and switch off may be allowed
for both the light and the heater. In such a way, at each
time instant only a subset of the speech recognizer’s
vocabulary is active, and these subvocabularies may
have words in common.
If the system considers all classes, whether they be-
long to the active subvocabulary or not, we call the
subvocabulary embedded. First, we analyze this strat-
egy in its simplest form: an observable confusion oc-
curs, if the recognizer commits a confusion and the
result belongs to the active subvocabulary; an observ-
able false rejection occurs, if 1) the recognizer com-
mits a false rejection, or 2) the recognizer commits a
confusion and the result does not belong to the ac-
tive subvocabulary; an observable false acceptance
occurs, if the recognizer commits a false acceptance
and the result belongs to the active subvocabulary.
In the absence of user errors, which we assume
throughout this analysis, a correct non-garbage result
always belongs to the active subvocabulary. A wrong
non-garbage result is assumed to fall into each of the
remaining classes with equal probability. From this,
we find the rates C
S
N
of confusions, R
S
N
of false re-
jections, and A
S
N
of false acceptances observable on
the user interface for an embedded subvocabulary of
size S > 0 out of a total vocabulary of size N ≥ S as
follows:
C
S
N
=
S − 1
N − 1
c
N
, (4)
R
S
N
= r
N
+
N − S
N − 1
c
N
, (5)
A
S
N
=
S
N
a
N
. (6)
For large N with small S, a more sophisticated
approach is favourable: if a non-garbage result falls
out of the active subvocabulary, then the class which
scored next is taken as a new hypothesis, and this pro-
cess is repeated until either a hypothesis is garbage
or falls into the active subvocabulary, or a predefined
number H of hypotheses were examined. This strat-
egy is implemented in the voice control devices de-
scribed in (Tschirk, 2001). For 2 ≤ H ≤ N − S, the
observable error rates are given by:
C
S,H
N
= C
S
N
+
H
X
i=2
S − 1
N − i
c
N−i+1
.
i−1
Y
j=1
N − S − j + 1
N − j
c
N−j+1
,
(7)
R
S,H
N
= R
S
N
+
H
Y
i=2
N − S − i + 1
N − i
c
N−i+1
+
H
X
i=2
r
N−i+1
i−1
Y
j=1
N − S − j + 1
N − j
c
N−j+1
,
(8)
A
S,H
N
= A
S
N
+
H
X
i=2
S
N − i + 1
a
N−i+1
.
i−1
Y
j=1
N − S − j + 1
N − j + 1
a
N−j+1
.
(9)
In Section 7, we mainly refer to the usage of em-
bedded subvocabularies as given by Equations (4) to
(6). The power of examining more than one hypothe-
sis is shown in Section 7.4.
4.2 Separated Subvocabulary
If the system evaluates each incoming pattern with re-
spect to only those classes represented in the active
subvocabulary, disregarding the other ones, we call
the subvocabulary separated. The observable error
rates on a separated subvocabulary of size S are de-
rived from Equations (4) to (6) by setting N = S.
5 MENU ARRANGEMENTS
5.1 Hierarchical Menus
On an voice interface featuring menus, the user has to
select the appropriate menu prior to submitting a con-
trol command. In our example of Section 7.2, each
controllable device has its own menu. We can place
a device selection menu on the top level of the user
interface, such that switching on the light requires ei-
ther a sequence of 3 commands: select to go to the
USER INTERFACE DESIGN FOR VOICE CONTROL SYSTEMS
23

selection menu, light to select the light, and switch on
to switch it on, or, if the light menu was the last one
selected, a sequence of length 1: switch on. We call
this menu arrangement hierarchical.
5.2 Connected Menus
In order to support direct switching between menus,
we include each device identifier into each of the
device menus, thus eliminating the selection menu.
Switching on the light requires either a command se-
quence of length 2: light and switch on, or of length 1:
switch on, depending on the recently selected menu.
We call this arrangement connected. Compared to the
hierarchical one, the connected arrangement requires
fewer steps on larger subvocabularies.
5.3 Command Sequence Behaviour
The error rates defined so far apply to single-pattern
reception. Now we define a command sequence fail-
ure rate. A command sequence is considered success-
ful, if each command is recognized correctly, other-
wise it is considered failed. For the purpose of sim-
plicity, we assume that command sequences are not
interrupted by garbage reception. Consequently, the
command sequence failure rate below gives a lower
bound for the actual figure, and the false acceptance
rate has no impact on the command sequence perfor-
mance and is kept as an extra figure. Assuming in-
dependent recognition errors, the failure rate F
L
of a
command sequence of length L is given by
F
L
= 1 −
L
Y
i=1
³
1 − (C
S
i
N
i
+ R
S
i
N
i
)
´
, (10)
where N
i
and S
i
are the recognizer’s vocabulary and
subvocabulary size, respectively, in the user interface
state corresponding to the reception of the i-th com-
mand. Equation (10) holds for all menu arrangements
and all subvocabulary types.
6 BASIC INTERFACE DESIGNS
Combining the alternatives given in Sections 4 and 5,
we identify four basic user interface designs:
design HE: hierarchical menu arrangement, em-
bedded subvocabularies,
design HS: hierarchical menu arrangement, sepa-
rated subvocabularies,
design CE: connected menu arrangement, embed-
ded subvocabularies,
design CS: connected menu arrangement, separated
subvocabularies.
In Section 7, we will evaluate, for three example
systems, these four designs, in order to point out the
advantages and drawbacks of each approach under the
conditions stated.
The evaluation of a design consists of four steps:
step 1: estimate the vocabulary and subvocabulary
sizes corresponding to each menu,
step 2: estimate the necessary speech recognizer
error rates via testing or by using Equations (1) to (3)
with appropriate test figures as inputs,
step 3: calculate the observable error rates for each
menu, using Equations (4) to (6) or (7) to (9),
step 4: for each command sequence type, calculate
the failure rate according to Equation (10).
7 EXAMPLE SYSTEMS
7.1 Example Speech Recognizer
Suppose a speech recognizer with the error rates:
c
10
= 0.005, r
10
= 0.03, and a
10
= 0.20 for a vocab-
ulary of size 10, on which the voice control systems
of Sections 7.2 to 7.4 shall be based. We do not con-
sider modifications of the recognizer itself. Instead,
we ask for the optimum user interface design for the
respective task, given the recognizer as it is.
7.2 Light, Heater, and Telephone
Control
Our first example system shall control a light with
the commands switch on, switch off, brighter, and
darker, a heater with switch on, switch off, warmer,
and cooler, and a hands-free telephone with connect,
disconnect, louder, and softer. The device selectors
are light, heater, and telephone. For the hierarchi-
cal arrangement, select shall be used to enter the de-
vice selection menu. Note that each device has the
same number of control commands, which facilitates
our analysis; in real world systems, different devices
will, in general, have control command sets of differ-
ent sizes. We analyze the system following Section 6,
using Equations (1) to (3) together with the recognizer
figures of Section 7.1 in step 2. The results are shown
in Table 1; there, the select-and-control failure rate
corresponds to command sequences required to select
a device and invoke a control action on it, whereas the
control failure rate corresponds to commands invok-
ing a control action on an already selected device.
In this example, the lowest select-and-control fail-
ure rate is achieved by employing the connected menu
arrangement together with separated subvocabularies;
however, it is paid with the highest false acceptance
rate.
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
24
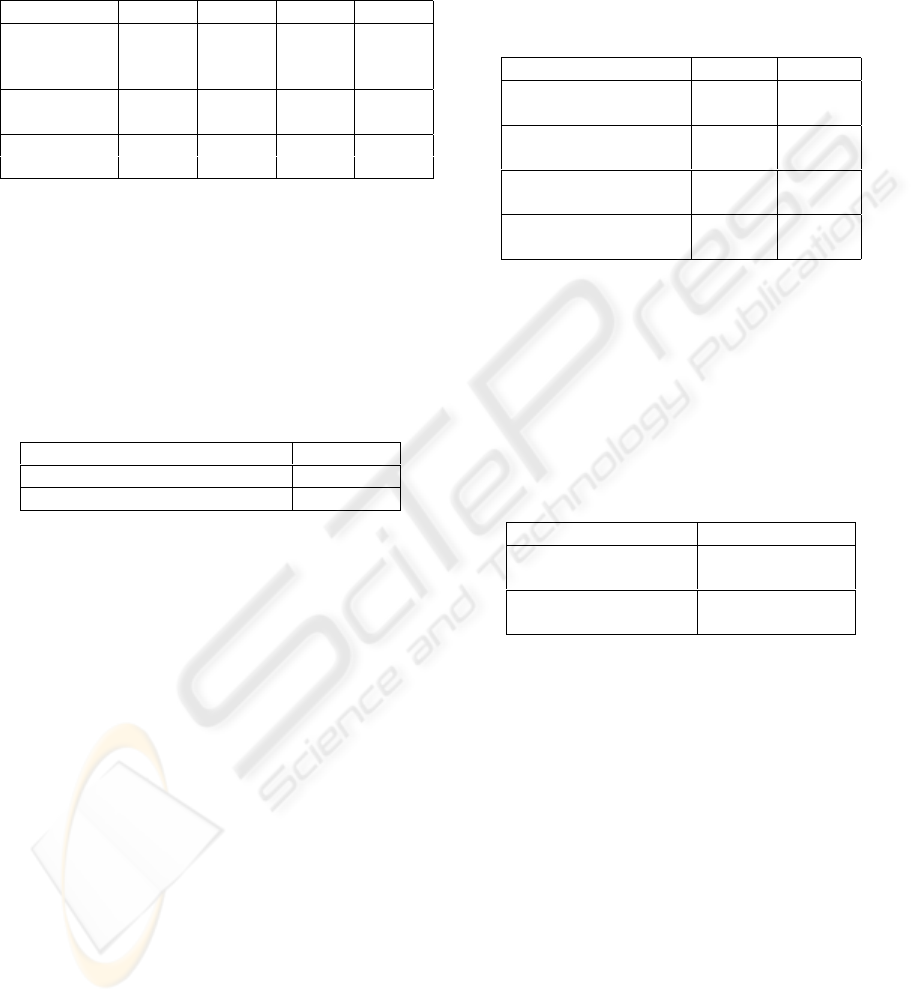
Table 1: Performance figures for different user interface de-
signs of a voice control system featuring device menus. In
the hierarchical designs, the false acceptance rate is taken
from the device menus, since voice control systems assume
that state most of the time (in the connected designs, the
false acceptance rate is equal for all menus).
HE HS CE CS
select-and-
control
failure rate 0.1073 0.0928 0.0719 0.0657
control
failure rate 0.0371 0.0323 0.0366 0.0334
false accep-
tance rate 0.0926 0.1111 0.1321 0.1489
7.3 Single–Device Control
The second example relates to a single 50-commands
control menu without subvocabularies. All designs
are identical, each command sequence is of length 1.
The performance is given in Table 2.
Table 2: Performance figures for a large single device con-
trol menu.
all designs
command sequence failure rate 0.0560
false acceptance rate 0.5556
Here, the exorbitant false acceptance rate is likely
to cause permanent unintentional activation of the
system. This undesired behaviour is a consequence of
the large number of commands allowed at each time
instant without any context.
7.4 Keyword Activation
As a third example, we modify the interface of Sec-
tion 7.3. We reduce the number of false acceptances
by introducing a sleep mode, in which the system ac-
cepts nothing but a certain wake up keyword. After
having been activated with wake up, it accepts each
one of its 50 commands and an extra sleep keyword,
which brings it back into the sleep mode.
The results of the analysis are shown in Table 3.
The wake-up-and-control failure rate corresponds to
command sequences required to get the voice control
system out of its sleep mode and invoke a control ac-
tion, whereas the control-or-sleep failure rate corre-
sponds to commanding an already active system or
bringing it back into the sleep mode. Since there are
only two menus, hierarchical and connected arrange-
ment are identical. In the active mode (first and sec-
ond row), the interface behaves very similar to the one
of Section 7.3. In the sleep mode, false acceptances
are almost suppressed (last row), and we find that the
technique of embedded subvocabularies yields a false
acceptance behaviour far better than that of separated
subvocabularies, at moderate cost with respect to the
wake-up-and-control failure rate (third row).
Table 3: Performance figures for different user interface de-
signs of a voice control system with keyword activation.
HE, CE HS, CS
control-or-sleep
failure rate 0.0570 0.0565
active mode
false acceptance rate 0.5543 0.5604
wake-up-and-control
failure rate 0.1108 0.0849
sleep mode
false acceptance rate 0.0109 0.0244
If, in case of an out-of-subvocabulary rejection in
the sleep mode, we examine a second hypothesis ac-
cording to Equations (7) to (9), we can lower the sleep
mode false acceptance rate almost without raising the
wake-up-and-control failure rate compared to the sep-
arated subvocabulary design:
Table 4: Performance figures for a voice control system
with keyword activation, examining a second hypothesis in
case of an out-of-subvocabulary rejection in the sleep mode.
HE, CE (H = 2)
wake-up-and-control
failure rate 0.0861
sleep mode
false acceptance rate 0.0170
8 CONCLUSION
We presented an analytical approach for estimating
the performance of voice control user interfaces, ap-
plicable to systems based on isolated word recogni-
tion and featuring menus. It allows for deriving de-
sign guidelines and focuses on user interface opti-
mization, given the speech recognizer’s performance.
In order to make such estimation feasible even if suf-
ficient test data are not available, we derived a formal-
ism for predicting a speech recognizer’s error rates on
different vocabulary sizes from the rates obtained on
a single vocabulary of arbitrary (however reasonable)
size.
We illustrated the approach by comparing four ba-
sic user interface designs. Mechanisms for improving
voice interfaces which were left out of the study, such
as the weighing of errors according to their relative
USER INTERFACE DESIGN FOR VOICE CONTROL SYSTEMS
25

importance or the minimization of overall error rates
by taking into account the a priori probability of com-
mands, can easily be integrated into the formalism.
The framework given here can also be used to se-
lect the best recognizer for a particular task, which
may be characterized by non-negotiable parameters
such as the number of menus and the menu sizes.
The methods presented were developed in the
course of the design of voice remote control sys-
tems for physically disabled people (Tschirk, 2001).
They were found useful for early detection of design
strengths and weaknesses. Clearly, they cannot elim-
inate the need for exhaustive real world testing.
APPENDIX
We view the recognition of a non-garbage pattern of
class W
k
as an experiment (Papoulis, 1984); its out-
comes are the class indices j ∈ {0, . . . , N}. To each
outcome j, we assign a probability p(j), which is ei-
ther p
1
(N): the probability of correct recognition, or
p
2
(N): the probability of confusion into a specific
class, or p
3
(N): the probability of rejection.
p(k) = p
1
(N),
p(i, i 6∈ {k, 0}) = p
2
(N),
p(0) = p
3
(N),
with
p
1
(N) + (N − 1)p
2
(N) + p
3
(N) = 1. (11)
Confusion rate and false rejection rate are given by
c
N
= (N − 1)p
2
(N), (12)
r
N
= p
3
(N). (13)
From assumption (1) of Section 2.2 follows that
p
3
(N)/(p
1
(N)+p
3
(N)) does not depend on N; from
assumption (2) follows that p
2
(N)/(p
1
(N) +p
2
(N))
does not depend on N. Thus, both expressions are
constant, and there exist constant u = p
1
(N)/p
3
(N)
and v = p
2
(N)/p
3
(N), such that we can rewrite
Equations (11) to (13) to
c
N
=
(N − 1)v
u + (N − 1)v + 1
,
r
N
=
1
u + (N − 1)v + 1
.
Since this holds for all N > 1, we obtain Equa-
tions (1) and (2).
Now we view the recognition of a garbage pattern
as an experiment and assign to each outcome either
q
1
(N): the probability of rejection, or q
2
(N): the
probability of acceptance with respect to a specific
class.
p(0) = q
1
(N),
p(i, i 6= 0) = q
2
(N),
with
q
1
(N) + Nq
2
(N) = 1. (14)
The false acceptance rate is given by
a
N
= Nq
2
(N). (15)
From assumption (3) of Section 2.2 follows that
q
2
(N)/(q
1
(N) + q
2
(N)) does not depend on N .
Thus, there exists a constant w = q
1
(N)/q
2
(N), such
that we can rewrite Equations (14) and (15) to
a
N
=
N
w + N
.
Since this holds for all N > 0, we obtain Equa-
tion (3).
REFERENCES
Glass, J., Polifroni, J., Seneff, S., and Zue, V. (2000). Data
collection and performance evaluation of spoken dia-
logue systems: The MIT experience. Massachusetts
Institute of Technology.
IEEE (1994). Special section on robust speech recognition.
In IEEE Transactions on Speech and Audio Process-
ing vol. 2, no. 4, pp. 549-643, October 1994.
IEEE (2002). Special issue on automatic speech recognition
for mobile and portable devices. In IEEE Transactions
on Speech and Audio Processing vol. 10, no. 8, pp.
529-658, November 2002.
Lin, B.-S. and Lee, L.-S. (2001). Computer-aided anal-
ysis and design for spoken dialogue systems based
on quantitative simulations. In IEEE Transactions on
Speech and Audio Processing vol. 9, no. 5, pp. 534-
548, July 2001.
Niimi, Y. and Nishimoto, T. (1999). Mathematical analy-
sis of dialogue control strategies. In Proceedings of
EUROSPEECH 99 vol. 3, pp. 1403-1406.
Papoulis, A. (1984). Probability, Random Variables, and
Stochastic Processes. McGraw-Hill, New York.
Rabiner, L. and Juang, B.-H. (1993). Fundamentals of
Speech Recognition. Prentice-Hall, Englewood Cliffs,
NJ.
Souvignier, B., Kellner, A., Rueber, B., Schramm, H., and
Seide, F. (2000). The thoughtful elephant: Strategies
for spoken dialog systems. In IEEE Transactions on
Speech and Audio Processing vol. 8, no. 1, pp. 51-62,
January 2000.
Tschirk, W. (2001). Neural net speech recognizers. Voice
remote control devices for disabled people. In
e & i Artificial Intelligence 7/8/2001, pp. 367-370.
Springer.
Villarrubia, L. and Acero, A. (1993). Rejection techniques
for digit recognition in telecommunication applica-
tions. In Proc. IEEE Int. Conf. Acoustics, Speech, and
Signal Processing 1993, pp. 455-458.
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
26
