
CABA
2
L A BLISS PREDICTIVE COMPOSITION ASSISTANT FOR
AAC COMMUNICATION SOFTWARE
Nicola Gatti
Dipartimento di Elettronica e Informazione, Politecnico di Milano
Piazza Leonardo da Vinci 32, I-20133, Milano, Italy
Matteo Matteucci
Dipartimento di Elettronica e Informazione, Politecnico di Milano
Piazza Leonardo da Vinci 32, I-20133, Milano, Italy
Keywords:
AAC languages, accessibility to disabled users, hidden Markov model, intelligent user interface, symbolic
prediction.
Abstract:
In order to support the residual communication capabilities of verbal impaired peoples softwares allowing
Augmentative and Alternative Communication (AAC) have been developed. AAC communication software
aids provide verbal disables with an electronic table of AAC languages (i.e. Bliss, PCS, PIC, etc.) symbols in
order to compose messages, exchange them via email, or vocally synthetize them, and so on. A current open
issue, in thins kind of software, regards human-computer interaction in verbal impaired people suffering motor
disorders. They can adopt only ad-hoc input device, such as buttons or switches, which require an intelligent
automatic scansion of the AAC symbols table in order to compose messages. In such perspective we have
developed CA BA
2
L an innovative composition assistant exploiting an user linguistic behavior model adopting
a semantic/probabilistic approach for predictive Bliss symbols scansion. CABA
2
L is based on an original
discrete implementation of auto-regressive hidden Markov model called DAR-HMM and it is able to predict
a list of symbols as the most probable ones according to both the previous selected symbol and the semantic
categories associated to the symbols. We have implemented the composition assistant as a component of
BLISS 2003 an AAC communication software centered on Bliss language and experimentally validated it with
both synthetic and real data.
1 INTRODUCTION
Nowadays, millions of verbal impaired people live
in the world (Bloomberg and Johnson, 1990); their
communication capabilities are permanently or tem-
porarily corrupted and, for this reason, most of them
suffer a condition of social exclusion. Verbal im-
paired people can not adopt canonic communicative
media (Fodor, 1983), such as natural language, and,
as the clinical experience evidences, their primary
need is to try alternative ways, according to their
residual capabilities, to communicate. In 1983 the
International Society for Augmentative and Alterna-
tive Communication (ISAAC, 1983) has been estab-
lished in USA with the aim to develop alternative in-
struments to allow verbal impaired people to com-
municate. ISAAC has been involved in developing
both languages, namely, Augmentative and Alterna-
tive Communication languages (AAC) (Shane, 1981),
and aids in order to support residual communicative
capabilities in verbal disables. AAC languages are
usually based on symbols and exploit peculiar com-
position rules simple enough to be learnt and used by
verbal disables. Among the AAC languages we can
cite: Bliss, PCS, PIC, PICSYMB, CORE, and Rebus.
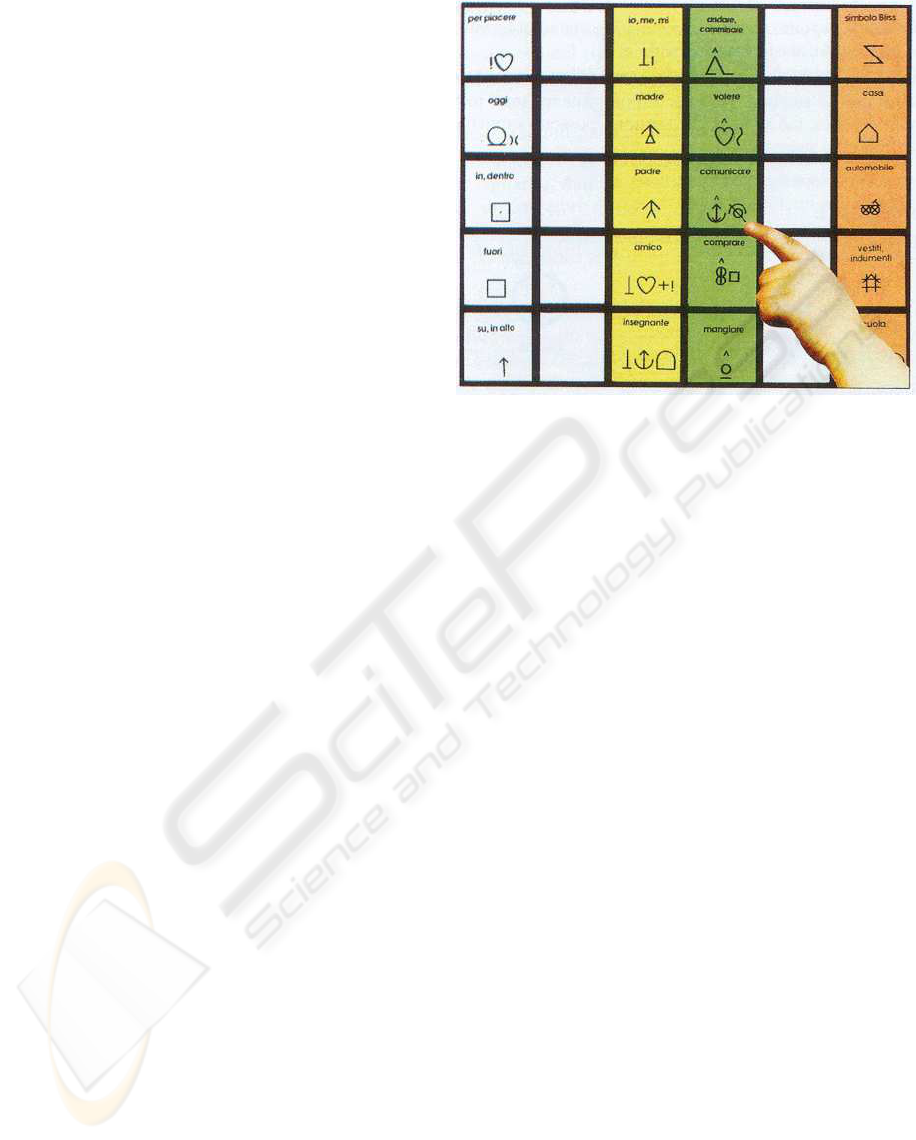
Currently, disables adopt paper tables (see Fig-
ure 1) containing their most used AAC symbols and
point in such tables the symbols related to what they
want to communicate. In the AAC field other AAC
aids exist, such as VOCAs (i.e. smart tablets that
associate vocal inputs to specific symbols), but they
evidence severe limitation with respect to effective
verbal disables needs since they present a limited set
di predefined sentences. Given this scenario, infor-
mation technology plays a relevant role by providing
the verbal disabled people with aids, such as AAC
software applications, to support their communica-
tion. In fat, AAC software applications provide ver-
bal impaired people with an electronic table of sym-
bols where they can select AAC symbols to compose
messages adopting canonical or ad-hoc AAC devices
(e.g. joystick, tablet, switch, etc.). In addition, they
offer other features, such as email message exchange
and vocal synthesis.
89
Gatti N. and Matteucci M. (2004).
CABA2 L A BLISS PREDICTIVE COMPOSITION ASSISTANT FOR AAC COMMUNICATION SOFTWARE.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 89-96
DOI: 10.5220/0002606600890096
Copyright
c
SciTePress
A current open issue concerning AAC communi-
cation software aids regards human-computer inter-
action in disables with motor disorders (Lee et al.,
2001), that represent about the 60% of verbal im-
paired people. Motor disordered people are not able
to use canonical input devices, such as keybord and
mouse, but they can use only ad-hoc devices, such as
buttons or switches according to their residual motor
capabilities. Such devices operate providing the AAC
software aid with an on/off input, so, in order to select
AAC symbols from a table, it is required an automatic
scansion of such table underlining the symbols they
can select. The intelligent scansion mechanisms cur-
rently adopted in AAC software do not assure a rele-
vant reduction of the time spent by verbal disables to
compose messages: in fact person evidencing motor
disorders can spend few minutes to compose a sim-
ple sentece. In such perspective we have developed
CA BA
2
L (Composition Assistant for Bliss Augmen-
tative Alternative Language) an innovative composi-
tion assistant that performs a predictive scansion of
Bliss symbols and reduces up to 60% the time re-
quired to compose a message. CABA
2
L is based on
a discrete implementation of auto-regressive hidden
Markov model (Rabiner, 1989) called DAR-HMM
and it predicts a list of symbols as the most prob-
able according to both the last selected symbol and
the semantic categories associated to symbols. More-
over, the predictive model embedded in C ABA
2
L can
be adapted to the specific disable user to better match
his/her peculiar linguistic behavior.
The paper is structured as follows. In Section 2, we
introduce current scansion mechanisms for verbal dis-
ables and underline prediction issues. Section 3 intro-
duces Bliss symbolic prediction issues and probabilis-
tic prediction techniques. Section 4 describes DAR-
HMM and its implementation. Section 5 reports the
experimental results we have obtained. Finally, Sec-
tion 6 concludes the paper.
2 SENTENCE COMPOSITION IN
PEOPLE WITH MOTOR
DISORDERS
Currently some AAC software aids provide people
suffering motor disorders with an automatic scansion
of the symbol table (see Figure 1). A generic scan-
sion mechanism can be described as follows: an high-
light moves autonomously on an AAC symbol table
according to a specific strategy, when the requested
symbol is highlighted the user can select such symbol
activating the device, then the highlight starts to move
again. Each scansion mechanism is characterized by a
specific ad-hoc input device and the scansion strategy.
Ad-hoc input devices allow the verbal disable to
Figure 1: An AAC symbols table
start the scansion, select symbols, close the sentence,
and activate features such as vocal synthesis. Each
user adopts the device that best matches with his/her
residual motor capabilities. The alternative/residual
motor capabilities used are usually: blowing with the
mouth, closing the eyes, pushing big buttons.
The scansion strategy determines what is the next
symbol to highlight. In literature several automatic
scansion strategies for AAC communication aids can
be retrieved (Higginbotham et al., 1998) and each one
of them exhibits advantages and drawbacks. Such
strategies can be classified in (Swiffin et al., 1987):
• linear scansion: the symbols are presented sequen-
tially from the first symbol of the table to the last
one;
• row-column scansion: at first the rows are scanned,
once the disable has selected a row, its columns
are scanned (or vice versa) (Simpson and Koester,
1999);
• scansion at subgroups: the symbols are presented
in groups fewer and fewer up to only one symbol;
• predictive scansion: it predicts the most probable
symbols the user will use to continue the sentence
according to a model of the user, and it presents the
most probable ones.
The choice of the most adequate scansion strategy
for the peculiar user depends on several factors, such
as the mental and motor residual capabilities, the
adopted AAC language and the size of the user sym-
bols table. With respect to the user mental capa-
bilities, both scansion at subgroups and row-column
scansion require the user to remember exactly the
place of the desired symbol, so they can not be used
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
90

by disables evidencing severe mental impairments.
With respect to the size of the symbol table linear
scansion, row-column scansion and scansion at sub-
groups do not offer good performance if the number
of symbols is elevate (50 symbols and more). Hence,
current non predictive scansion strategies do not allow
to verbal disables suffering motor disorders a relevant
reduction in the time spent to compose sentences (Lee
et al., 2001).
Although predictive scansion strategies could as-
sure better performance (Koester and Levine, 1994),
they are currently adopted in a small number of AAC
assistitive technology aids. In particular symbolic pre-
diction is currently adopted only in VOCAs, but it evi-
dences severe limitations: it predicts symbols accord-
ing to a strict set of sentences previously registered
and do not exploit a linguistic behavior model of the
user. In such a way such prediction system allows the
user to compose a fixed number of messages and it
is not able to generalize allowing the composition of
new messages (Higginbotham et al., 1998). In litera-
ture numerous predictive techniques have been devel-
oped, but they have been applied mainly in alphabet-
ical prediction. In such context the main prediction
techniques (Aliprandi et al., 2003) employ a statisti-
cal approach (based on hidden Markov models and
Bayesian networks), a syntactic and strong syntac-
tic approach (based on linguistic models), a semantic
approach (based on semantic networks), and hybrid
approaches. To the best of our knowledge, currently
symbolic predictive models do not exist.
The main issue with alphabetical predictive tech-
niques, that prevents their use for symbolic predic-
tion, is related to the size of the dictionary of items
to be predicted and their composition rules. In fact,
alphabetical prediction operates on a limited num-
ber (about 20) of items, the alphabetic signs, that
can be organized in words known a priori. Con-
versely, symbolic prediction operates on a set of sym-
bols variable in number that can be organized in dif-
ferent sequences according to the peculiar user lin-
guistic capabilities. In addition alphabetical predic-
tion techniques do not match with the symbolic pre-
diction issue. On the other side, a pure statistical ap-
proach does not keep into account the peculiar AAC
language structure, in fact each verbal impaired user
adopts/develops an own syntactic model according to
his/her residual mental capacities. This is also the rea-
son for which the utilization of a pure syntactic ap-
proach for any user can not be achieved, and a pure
semantic approach does not address the variability re-
lated to the residual user capacities.
We consider an ad-hoc hybrid approach as the right
choice in this context; in the following sections of the
paper we focus on the description of this prediction
model since it represents the most original part of our
work.
3 BLISS SYMBOLS PREDICTION
AND GRAPHICAL MODELS
In our work we focus on the Bliss language (Bliss,
1966), since it is the most adopted and expressive
among AAC languages. In the design of a composi-
tion assistant to predicts Bliss symbols, a set of pecu-
liar requirements regarding both the human-computer
interface and the prediction model can be established.
The composition assistant should suggest a lim-
ited number of symbols (around 4-5) not to confuse
the disable user (Koester and Levine, 1994), the pre-
diction must be accomplished in real time, and the
scansion rate must be adaptable with the user needs
(Cronk and Schubert, 1987). This last aspect ad-
dresses issues due to the high variability of residual
mental and motor capabilities, in fact the composition
assistant should be able to adapt the scansion rate ac-
cording to the time required by the specific disable
to read and select the highlighted symbol. With re-
spect to the prediction model, a verbal impaired user
can adopt all the Bliss symbols (about 2000), even
if he/she usually adopts only a part of them (usually
from 6-7 to 200), and it should be taken into account
that the symbol to be predicted depends in some ex-
tents on the symbols selected previously.
We have adopted a semantic/probabilistic approach
to model the user language behavior and we use this
model in order to predict the most probable symbols
to be suggested by an automatic scansion system. We
have used the semantic approach to take advantage of
a Bliss symbols categorization and the probabilistic
approach both to take into account for uncertainties
in the user language model and to give a reasonable
estimate of the reliability of the proposed prediction.
In CABA
2
L we have used a graphical model based
on a variation of a classical Hidden Markov Models
(HMM). Classical HMMs involve states and symbols,
in particular they relate the probability that a particu-
lar symbol is emitted to the probability that the system
is in particular state. Moreover they use a stochas-
tic process to define the transition from a state to the
other (see Figure 2).
In HMM a particular sequence of observation (i.e.
observed symbols) is generated by choosing at time
t = 0 the initial state s
i
∈ S according to an ini-
tial probability distribution π(0), a symbol v
k
is gen-
erated from a multinomial probability distribution b
i
k
associated to state s
i
, and the system move from the
present state s
i
to the next state s
i
0
of the sequence
according to a transition probability a
ii
0
to generate
the next symbol. States in this model are not directly
observable; symbols represent the only information
that can be observed, and this is the reason for the
term hidden in the model name. Notice that classical
HMMs consider symbols as independent from each
CABA2L A BLISS PREDICTIVE COMPOSITION ASSISTANT FOR AAC COMMUNICATION SOFTWARE
91
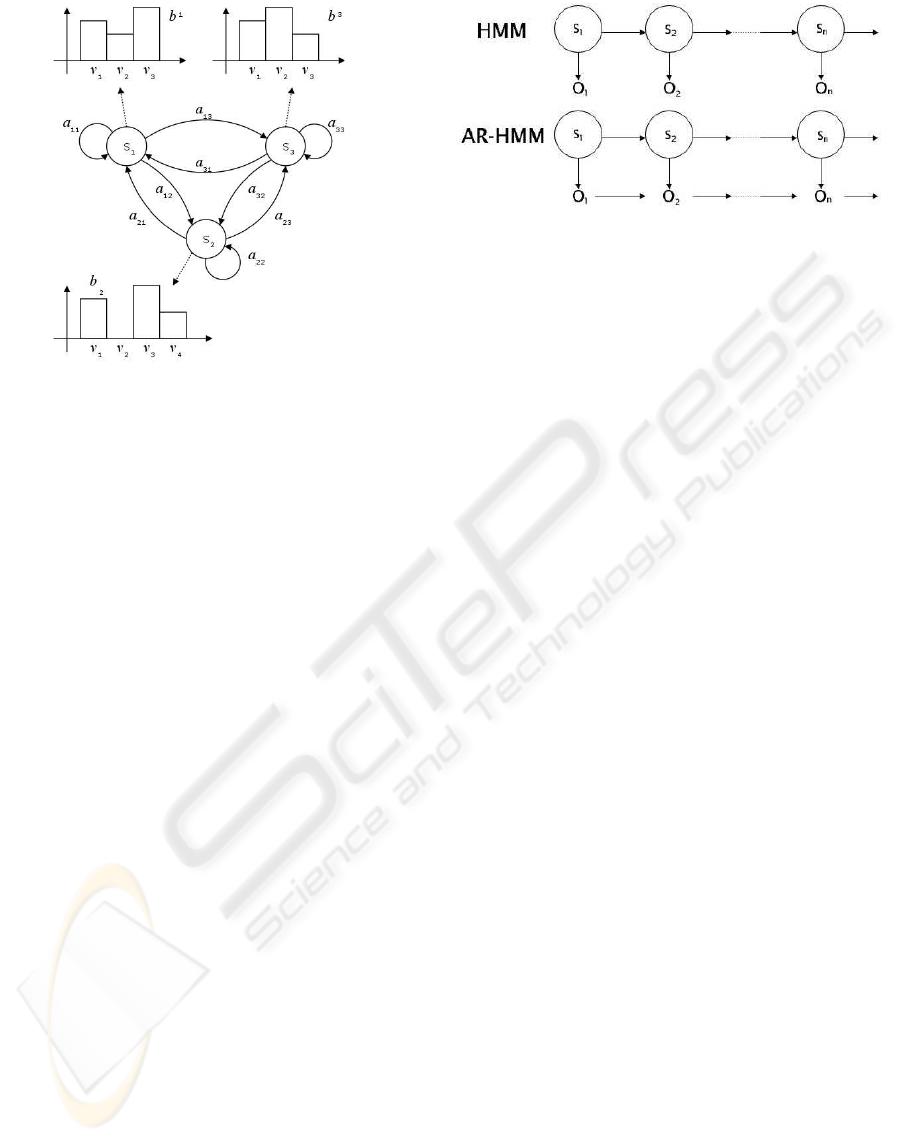
Figure 2: An example of Hidden Markov Model
other given the present state; thus probability of ob-
serving symbol v
k
at time t in a sequence of sym-
bols does not depend on the symbol observed at time
t − 1, but it depends only on the present state s
i
and,
implicitly, the previous one s
i
0
through the transition
probability a
ii
0
(Ghahramani, 2001).
HMMs could be adopted to implement a predictive
models for Bliss symbols if we could assume that a
symbol is predictable given the corresponding Bliss
symbol category as the hidden state. However, this
approach oversimplify the user language model de-
scribed previously: it does not relate the emission of a
symbol with the symbol previously emitted due to the
independence assumption in HMMs. To face this is-
sues we have adopted a particular extension of HMM,
called AR-HMM (Auto-Regressive Hidden Markov
Model) that relate the emitted symbol both to the ac-
tual state (as canonical HMM) and to the previous
emitted symbol (Figure 3 illustrates the differences
between canonical HMM and AR-HMM). In such a
way we have a model that keeps into account the pre-
vious emission and it is still computationally tractable
as described further on.
In order to identify the possible hidden states of
an ad-hoc AR-HMM for the Bliss language, sym-
bols have been divided into six categories according
to their grammatic role, and, later, each category has
been divided into a number of subcategories adopt-
ing the semantic networks formalism (Quillian, 1968)
to keep into account the semantic of the symbols and
the logic connection among two subcategories. This
subcategories identification process has been accom-
plished in collaboration with experts in verbal reha-
bilitation to obtain subcategories not excessively spe-
cific that would have complicated the model without
any reason (e.g., we have a substantive subcategory
Figure 3: Comparison between HMM and AR-HMM
‘food’ because it connects the verb subcategory ‘feed-
ing’, we have not a substantive subcategory ‘animal’
because it does not connect a specific category). We
report such subcategories and the number of symbols
assigned to each subcategory (note that a symbol can
belong more than one category).
• Verbs: people movement (23), objects movement
(15), body care (16), description (3), everyday (10),
servile (7), emotional (7), feeding (33), other (180).
• Adverbs: time (67), exclamatory (12), place (28),
quantity (17), holidays (12), color (23), other (20).
• Adjectives: opinion (29), character (18), physical
description (33), food description (17), quantity
(13), feeling (29), other (52).
• Substantives: food (141), cloth (38), body (47), ev-
eryday (26), people place (110), things place (22),
other (600).
• People: possession (16), relation (47), job (38),
other (51).
• Punctuation: question (13), other (36).
4 DISCRETE
AUTO-REGRESSIVE HIDDEN
MARKOV MODEL
AR-HMMs are commonly used in literature for pre-
diction in continuous systems and they usually de-
scribe the emission probability of an symbol/value
according to a Gaussian distribution; the emission of
Bliss symbol, however, is a discrete event that can be
described adopting a multinomial probability distri-
bution. In CABA
2
L, to overcome this problem, we
have implemented a Discrete Auto-Regressive Hid-
den Markov Model (DAR-HMM) where the emis-
sion probability for a symbol is described using a bi-
variated multinomial distribution. In fact, we intro-
duced the DAR-HMM as a first order extension of a
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
92
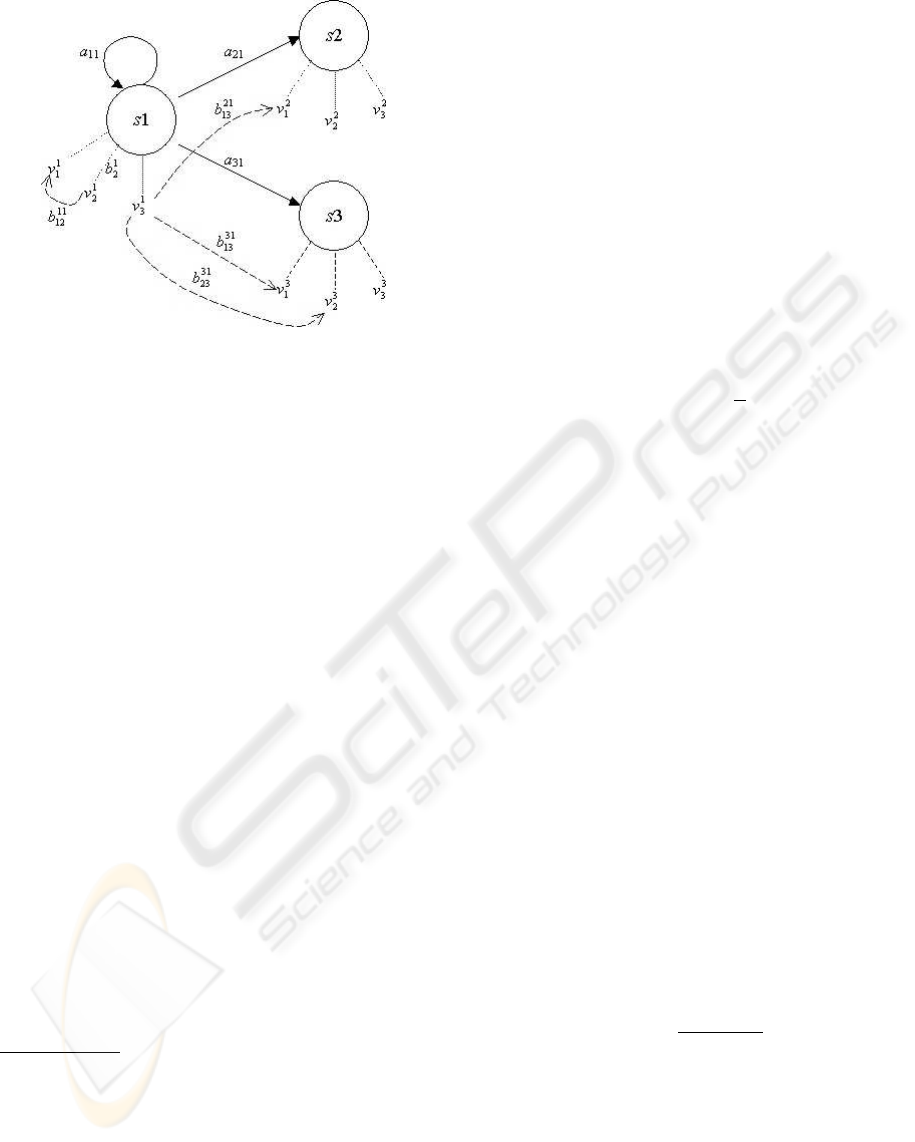
Figure 4: Symbols emission in DAR-HMM; s
i
is the state
(symbol subcategory), v
j
are the observed symbol
classical HMM where the symbol emission probabil-
ity depends on the present state and the last observed
symbol as depicted in Figure 4.
DAR-HMM for symbolic prediction can be de-
scribed using a parameter vector λ =< Π
0
, A, B >,
where Π
0
[N] is the vector of inital subcategory prob-
ability π
i
(0), A[N][N ] is the matrix with subcategory
transition probabilities a
ii
0
, and B[N ][M ][M + 1] is
the emission matrix
1
with symbol probabilities b
ii
0
kk
0
and b
i
k
(see Appendix A for details). In CABA
2
L,
this λ vector has been estimated using a dataset of
Bliss sentences. To do that, we have adopted a
variation of the Baum-Welch algorithm, an iterative
algorithm based on the Expectation-Maximization
method (Bilmes, 1998; Dempster et al., 1977), adapt-
ing this technique to the specific case of DAR-HMM
(see Figure 5).
Since the Baum-Welch algorithm is a greedy algo-
rithm that can be trapped in local minima, the ini-
tialization estimate of λ parameter vector is a fun-
damental aspect. In literature a theoretical solution
that addresses such issue does not exist; in practice,
the adoption of a random or uniform distributed ini-
tialization for A and Π
0
has been verified to be ad-
equate. In particular we adopt an uniform distribu-
tion as initial estimate for Π
0
, and a distribution based
on the knowledge about the phenomenon for A. Only
1
From an implementation point of view matrix B could
represent the main issue of this model (i.e., with N = 30
subcategories and M ' 2000 symbols the cells number
amount is of the order of 10
8
, about 400MBytes). How-
ever B can be considered a sparse matrix since from each
subcategories only a part of symbols can be emitted, so the
cells number is, approximately, lower than 10
4
and ad-hoc
data structure such as heap or priority queue and optimized
algorithms can be used to overcame memory occupancy and
speed access issues.
arcs connecting subcategories in the semantic model
of the language (see Section 3) should have a proba-
bility a
ii
0
6= 0. However, we have assigned to the arcs
between symbols and states that are not connected in
the semantic network a very low probability, not to
preclude the training algorithm to eventually discover
unforeseen correlations.
The initial estimation for the B matrix is more crit-
ical so we have used the Segmental k-Means (Juang
and Rabiner, 1990; Juang et al., 1986) technique
to obtain a more confidential estimate. Such pro-
cess considers a sub set of sentences composing the
dataset, and, for each one, it looks for the best se-
quence of subcategories using the Viterbi algorithm
to upgrades the symbols emission probabilities.
Given the initial values λ
0
for the model param-
eters, we use a modified Baum-Welch algorithm to
estimate, from a real dataset, the model parameters
through a sequence of temporary
λ model parameters.
As in any learning algorithm, the main issue is avoid-
ing the overfitting phenomenon (Caruana et al., 2001),
so we would like to stop the training phase according
to the generalization error (i.e., the error on new sam-
ples) and not just observing the training error (i.e., the
error on the training set). To do this, we have used
the K-fold cross-validation technique (Amari et al.,
1995); it consists in dividing the whole set of sen-
tences into K similar subsets to use at each iteration
K − 1 subsets for parameter estimation and the re-
maining validation set is used to valuate the conver-
gence of model generalization error. In other words,
we calculate the errors of the model in predicting the
sentences of the validation set it has never seen, and
we analyze the validation error function during train-
ing iterations of the Baum-Welch algorithm until it
reaches its minimum.
In order to terminate the iteration at which the error
function reaches its minimum, several practical tech-
niques can be adopted, but none of them assures the
achieving the global minimum. We have chosen to
adopt a termination criterion based the generalization
loss method (Prechelt, 1996). Given:
Err
Opt
(t) = min
t
0
≤t
Err
V al
(t
0
)
the minimum error is obtained at time t; consider
GL(t) , 100
³
Err
V al
(t)
Err
Opt
(t)
− 1
´
which represents the last increment in comparison
with the minimum. The training phase is stopped
whenever the generalization loss GL becomes bigger
than a given threshold τ :
GL(t) > τ.
In this approach, the error function could stabilize af-
ter a local minimum, without GL(t) rising the thresh-
old. In order to face such issue we have added to
CABA2L A BLISS PREDICTIVE COMPOSITION ASSISTANT FOR AAC COMMUNICATION SOFTWARE
93
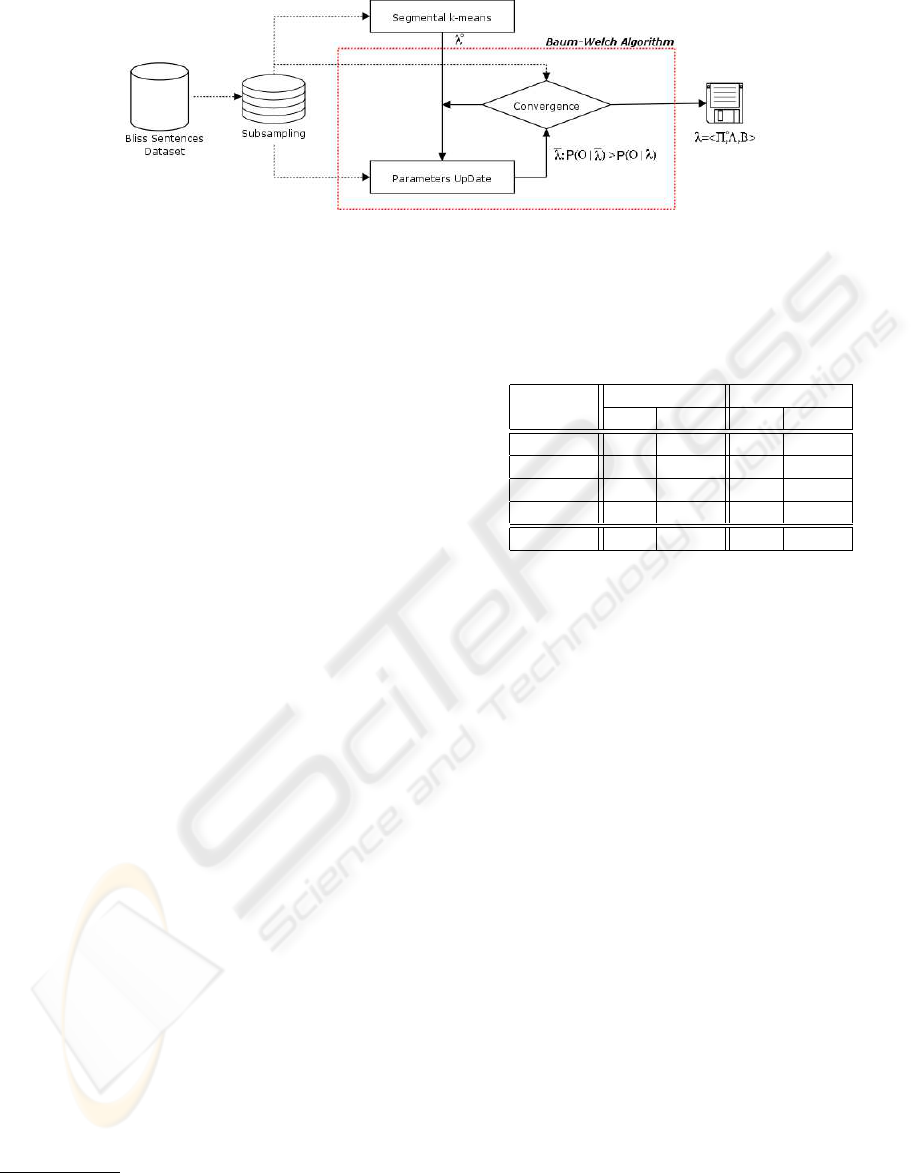
Figure 5: The training process
the stop criterion two condition relating the maximum
number of iterations and the minimum improvement
during learning.
5 EXPERIMENTAL RESULTS
DAR-HMM has been implemented in CABA
2
L and,
finally, integrated in BLISS2003, a communication
software centered on Bliss language. CA BA
2
L re-
ceives from BL IS S2003 the last selected symbol, cal-
culates the most probable four symbols according to
the established requirements, and scans them in an ad-
hoc panel in the graphical interface before scanning
the full table.
In order to validate DAR-HMM, we are interested
in giving an estimated training error and general-
ization error in several user scenarios characterized
by symbols, symbols subcategories, user residual lin-
guistic capabilities, and user needs; we are also inter-
ested in evaluating the time required both for learning
and prediction process. To accomplishing this val-
idation, we have strictly collaborated with two Ital-
ian clinics for verbal impairments (PoloH and SNPI
of Crema
2
) evaluating the prediction performance in
different scenarios; in this paper we report just two
scenarios as the most significant ones:
1. a dataset of 20 sentences with 4 sub-categories and
7 symbols representing a verbal impaired person
unskilled in Bliss utilization or suffering deep men-
tal deficiency;
2. a dataset of 80 sentences with 18 sub-categories
and 120 symbols representing a verbal impaired
person skilled in Bliss use and without deep mental
deficiency.
We have shuffled the sentences of each dataset in or-
der to achieve a homogeneous dataset not affected by
2
PoloH is a information technology center that support
AAC aids adoption. SNPI is the neuropsychiatric adoles-
cent and infancy local service associated to the hospital of
Crema, Italy.
Table 1: Training error: probability that the requested sym-
bol is in the first four predicted symbols according to the
datasets adopted to train the DAR-HMM
Predictions Scenario 1 Scenario 2
Mean Std. Dev. Mean Std. Dev.
1 symbol 0.343 0.055 0.250 0.017
2 symbols 0.563 0.074 0.299 0.028
3 symbols 0.778 0.067 0.319 0.033
4 symbols 0.908 0.056 0.345 0.042
not suggested 0.092 0.056 0.655 0.042
time correlation. In addition we have divided each
dataset into two parts, respectively 80% of sentences
in the first part and 20% of sentences in the second
one. We have adopted the first part to training the
model computing the training error. We have adopted
the second one to evaluate the generalization error.
The training error expresses the effectiveness of the
learning and it is obtained comparing the suggestion
proposed by CA BA
2
L during the composition of sen-
tences it has learnt. To estimate the correct predic-
tion’s probability, we have carried out over 800 simu-
lations where we compare the suggested symbols and
the one chosen by the user. In Table 1 mean and stan-
dard deviation for both the two scenarios are showed,
they evidence a training error of about 9.2% for the
first scenario and 65.5% for the second one taking into
account a number of proposed symbols equals to 4 as
suggested by therapist and according to the require-
ments from Section 3.
The generalization error expresses the effectiveness
of the prediction system, and it is obtained compar-
ing the suggestions proposed by CABA
2
L during the
composition of sentences that exhibit the same prob-
ability distribution with respect to the sentences it has
learnt, but were not presented to the system during
the training phase. To estimate the correct predic-
tion’s probability, we have carried out over 200 simu-
lations where we compare the suggested symbols and
the one chosen by the user. In Table 2 mean and stan-
dard deviation for both the two scenarios are showed,
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
94

they evidence a generalization error of about 11.3%
for the first scenario and 64.3% for the second one
taking again into account a number of proposed sym-
bols equals to 4 before. The values of mean and stan-
dard deviation evaluated in generalization error are
very close to the values evaluated in training error,
thus DAR-HMM evidences high generalization abil-
ity. Although the training and generalization errors
are in the second scenario high we are confident to
get better result just having a bigger dataset.
Time spent by verbal disables that collabo-
rated with us in order to compose messages using
BL IS S2003 with respect to the time spent with adop-
tion of a traditional scansion system has been reduced
up to 60%. Tests have evidenced that the training
phase requires few minutes depending on the size of
the dataset and the number of symbols and subcat-
egories, but this does not affect BLISS2003 perfor-
mance, because it can be run on background. Con-
versely, these tests have proved that the symbols pre-
diction is immediate (<1 second) and can be per-
formed in real time.
6 CONCLUSIONS
In this paper we have analyzed the AAC symbols
scansion issues for motor disordered persons estab-
lishing requirements according to literature and the
experiences of several clinics for verbal disables that
have collaborated with us. In particular we described
prediction models currently adopted in AAC context
and we designed an ad-hoc prediction model (DAR-
HMM). We described DAR-HMM peculiarities: its
formalism, ad-hoc emission rules, parameters initial-
ization, training processes, stopping criterion, and im-
plementation issues. We have applied DAR-HMM to
the case of Bliss language introducing semantic cate-
gories for Bliss symbols. In addition, we integrated
CA BA
2
L into BLISS2003 an AAC communication
software based on Bliss, and experimentally validated
it with real data in collaboration with two Italian clin-
ical centers for verbal impaired people proving its ef-
fectiveness for reduction of the time spent to compose
Bliss messages.
In future the performance of the prediction will be
improved refining the prediction model. Moreover we
would like to achieve on-line adaptation of the DAR-
HMM to the linguistic behavior of the user and to take
into account the evolution of the user linguistic capa-
bilities, and to support other AAC languages with re-
spect to Bliss, particularly PCS. Finally we will ana-
lyze the learnt semantic/probabilistic model of the lin-
guistic behavior of the user in order to study relation-
ships between disabilities and verbal impairments.
Table 2: Estimated generalization error: probability that
the requested symbol is in the first four predicted symbols
according to the datasets not adopted to train the DAR-
HMM
Predictions Scenario 1 Scenario 2
Mean Std. Dev. Mean Std. Dev.
1 symbol 0.202 0.082 0.185 0.089
2 symbols 0.438 0.146 0.252 0.073
3 symbols 0.666 0.181 0.304 0.070
4 symbols 0.887 0.067 0.357 0.077
not suggested 0.113 0.067 0.643 0.077
REFERENCES
Aliprandi, C., Barsocchi, D., Fanciulli, F., Mancarella, P.,
Pupillo, D., Raffaelli, R., and Scudellari, C. (2003).
AWE, an innovative writing prediction environment.
In Proc. of the Int. Human Computer Conf., Crete,
Greece.
Amari, S., Finke, M., Muller, K. R., Murata, N., and Yang,
H. (1995). Asymptotic statistical theory of overtrain-
ing and cross-validation. Technical Report METR
95-06, Dep. of Math. Eng. and Inf., Physics, Uni. of
Tokyo, Tokyo.
Bilmes, J. (1998). A gentle tutorial of the EM Algorithm
and its application to parameter estimation for Gaus-
sian Mixture and Hidden Markov Models. Technical
report, Dep. of Electrical Eng. and Comp. Sci. at Uni.
of California, Berkeley.
Bliss, C. K. (1966). Semantography. Semantography Blis-
symbolic Communication, Sidney, Australia.
Bloomberg, K. and Johnson, H. (1990). A statewide demo-
graphic survey of people with severe communication
impairments. Augmentative and Alternative Commu-
nication, 6:50–60.
Caruana, R., Lawrence, S., and Giles, C. L. (2001). Overfit-
ting in neural networks: Backpropagation, conjugate
gradient, and early stopping. In Advances in Neural
Information Processing Systems, Denver, Colorado.
Cronk, S. and Schubert, R. (1987). Development of a real
time expert system for automatic adaptation of scan-
ning rates. In Proc. of the Conf. on Rehabilitation
Technology, RESNA, volume 7, pages 109–111, Wash-
ington, DC, USA.
Dempster, A., Laird, N., and Rubin, D. (1977). Maxi-
mum likelihood from incomplete data via the EM al-
gorithm. Journal of Royal Statistical Society B, 39:1–
38.
Fodor, J. (1983). The modularity of mind. MIT Press, Cam-
bridge, USA.
Ghahramani, Z. (2001). An introduction to hidden markov
models and bayesian networks. International Journal
of Pattern Recognition and Artificial Intelligence, 1:9–
42.
CABA2L A BLISS PREDICTIVE COMPOSITION ASSISTANT FOR AAC COMMUNICATION SOFTWARE
95

Higginbotham, D. J., Lesher, G. W., and Moulton, B. J.
(1998). Techniques for augmenting scanning commu-
nication. Augmentative and Alternative Communica-
tion, 14:81–101.
ISAAC (1983). Int. Soc. for Augmentative and Alterna-
tive Communication, Internet site. http://www.isaac-
online.org. Last accessed October 1th, 2003.
Juang, B. and Rabiner, L. (1990). The segmental k-means
algorithm for estimating parameters of hidden markov
models. In IEEE Trans. on Acoustics Speech and
Signal processing, ASSP-38, pages 1639–1641. IEEE
Computer Society Press.
Juang, B., Rabiner, L., and Wilpon, G. (1986). A segmental
k-means training procedure for connected word recog-
nition. AT&T Technical Journal, 65:21–31.
Koester, H. and Levine, S. (1994). Learning and perfor-
mance of ablebodied individuals using scanning sys-
tems with and without word prediction. Assistive
Technology, page 42.
Lee, H.-Y., Yeh, C.-K., Wu, C.-M., and Tsuang, M.-F.
(2001). Wireless communication for speech impaired
subjects via portable augmentative and alternative sys-
tem. In Proc. of the Int. Conf. of the IEEE on Eng.
in Med. and Bio. Soc., volume 4, pages 3777–3779,
Washington, DC, USA.
Prechelt, L. (1996). Early stopping-but when? In Neural
Networks: Tricks of the Trade, pages 55–69.
Quillian, M. (1968). Semantic memory. In Minsky ed.
Semantic Information Processing. MIT Press, Cam-
bridge.
Rabiner, L. (1989). A tutorial on hidden markov models and
selected applications in speech recognition. In Proc. of
the IEEE, 77, pages 257–286. IEEE Computer Society
Press.
Shane, B. (1981). Augmentative Communication: an intro-
duction. Blackstone, Toronto, Canada.
Simpson, R. C. and Koester, H. H. (1999). Adaptive one-
switch row-column scanning. IEEE Trans. on Reha-
bilitation Engineering, 7:464–473.
Swiffin, A. L., Pickering, J. A., and Newell, A. F. (1987).
Adaptive and predictive techniques in a cammunica-
tion prosthesis. Augmentative and Alternative Com-
munication, 3:181–191.
APPENDIX A
In this appendix, we briefly describe the DAR-HMM ac-
cording to the formalism adopted by Rabiner in (Rabiner,
1989) to specify classical hidden Markov models:
• S , {s
i
}, subcategories set with N = |S|;
• V , {v
j
}, predictable symbols set with M = |V |;
• V
(i)
= {v
(i)
k
}, set of symbols predictable in subcategory
i with M
(i)
= |V
(i)
| and V =
S
i
V
(i)
;
• O(t) ∈ V , observed symbol at time t;
• Q(t) ∈ S, state at time t;
• π
i
(t) = P (Q(t) = s
i
), probability that s
i
is the actual
subcategory at time t;
• a
ii
0
= P (Q(t + 1) = s
i
|Q(t) = s
i
0
), transition proba-
bility from s
i
0
to s
i
;
• b
i
k
= P (O(0) = v
(i)
k
|Q(0) = s
i
), probability of ob-
serving v
(i)
k
from subcategory s
i
at t = 0;
• b
ii
0
kk
0
= P (O(t) = v
(i)
k
|Q(t) = s
i
, O(t − 1) = v
(i
0
)
k
0
),
probability of observing v
(i)
k
from the subcategory s
i
having just observed v
(i
0
)
k
0
.
DAR-HMM for symbolic prediction can thus be described
using a parameter vector λ =< Π
0
, A, B >, where
Π
0
[N] is the vector of inital subcategory probability π
i
(0),
A[N][N] is the matrix with subcategory transition probabil-
ities a
ii
0
, and B[N][M ][M + 1] is the emission matrix with
symbol probabilities b
ii
0
kk
0
and b
i
k
. Given λ the vector of pa-
rameters describing a specific language behavior model, we
can predict the first observed symbol as the most probable
one at time t = 0:
ˆ
O(0) = arg max
v
(i)
k
³
P (O(0) = v
(i)
k
|λ)
´
= arg max
v
(i)
k
(P (O (0) |Q (0) , λ) P (Q(0)))
= arg max
v
(i)
k
³
b
i
k
· π
i
(0)
´
.
Then mimicking the DAR-HMM generative model, to pre-
dict the t
th
symbol of a sentence we want to maximize the
symbol probability in the present (hidden) state given the
last observed symbol:
P
³
O(t) = v
(i)
k
, Q(t) = s
i
|O(t − 1) = v
(i
0
)
k
0
, λ
´
.
Recalling that we can compute the probability of the current
(hidden) state as:
P (Q(t)) =
N
X
P (Q(t)|Q(t − 1)) P (Q(t − 1)) =
=
N
X
i
0
=1
π
i
0
(t − 1)a
ii
0
= π
i
(t),
we obtain a recursive form for symbol prediction at time t:
ˆ
O(t) = arg max
v
(i)
k
Ã
b
ii
0
kk
0
·
N
X
i
0
=1
π
i
0
(t − 1)a
ii
0
!
.
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
96
