XRM: AN XML-BASED LANGUAGE FOR RULE MINING SYSTEMS
B. Bouchou
1
, A. Cheriat
1
, M. Halfeld Ferrari Alves
1
, T. Jen
1
, D. Laurent
2
1
Universit
´
e Franc¸ois Rabelais Blois-Tours-Chinon,
Antenne Universitaire de Blois, 3, Place Jean Jaur
`
es 41000 Blois - France
2
Universit
´
e de Cergy-Pontoise,
2, avenue A. Chauvin - BP 222 95302 Cergy-Pontoise Cedex - France
Keywords:
XML, XML Schema, association rule, data mining tools, logic formula.
Abstract:
We present XRM, an XML-based language capable of promoting the collaboration among data mining sys-
tems. XRM is a general framework to express any system results and/or data as logic formulas. In this way,
XRM offers flexibility to represent data, constraints and patterns, and allows mining systems to present their
results in an exchangeable format. In this work, we concentrate on the use of XRM to represent different
forms of association rules. XRM is built on XML Schema.
1 INTRODUCTION
We present XRM, an XML-based language capable
of assuring the exchange of information among data
mining systems. XRM allows the representation of
first order formulas and, thus, is an efficient tool to
represent data, constraints and patterns. In this paper,
we focus on association rule mining systems. How-
ever, XRM can be used with every mining system
whose data and results can be expressed by first or-
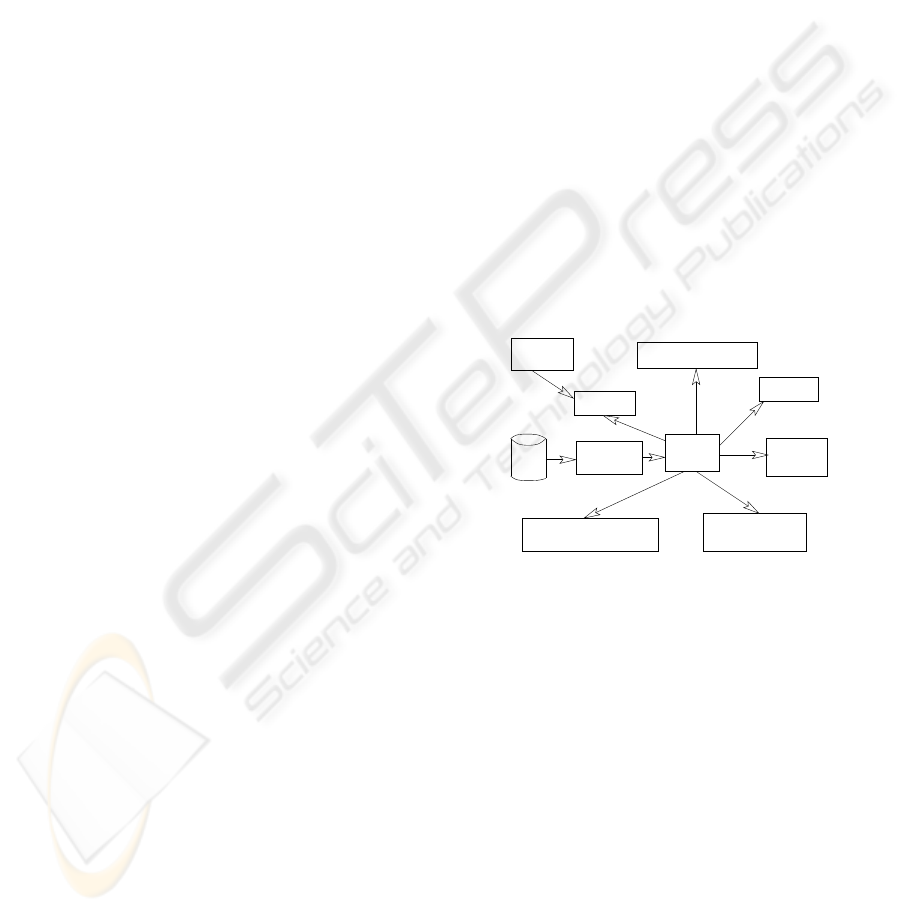
der formulas. Figure 1 shows a rule extraction pro-
cess whose result is presented as an XRM document.
It illustrates that, in this context, a lot of different ap-
plications can interact with the rule mining system.
The aim of data mining systems is to efficiently ex-
tract knowledge from large data collections in order to
identify relevant trends. Mining results are presented
through different kinds of patterns (association rules,
classification, clusters, etc). To improve the knowl-
edge discovery process it is essential to define a model
that allows (i) the integration of results coming from
different data mining systems and (ii) the use by an
application (from any different domain) of the results
coming from a previous execution of a mining extrac-
tion task. The motivation for XRM comes from firstly
the possibility of integrating results obtained by min-
ing systems that use, in fact, a subset of logic formulas
(such as association rules, conjunctive queries and so
on) to express the extracted knowledge. We propose
a standard exchange format among systems.
Association rules are undoubtedly one of the most
documents
source
Association rule
extraction algo
Query, filtering
(XQuery, XSLT, ...etc)
applications
Web
Integration
XRM
XML /XRM
document
tools
Visualization
Data mining models
(classification, clustring, ...etc)
Association rule extration tools
Data
Figure 1: Utilization of XRM Model.
popular type of patterns. The most famous application
example of association rule mining is the market bas-
ket analysis: mine items sold together and then com-
pute the association rules that indicate the probability
of one set of items being in the basket given that an-
other set is in. Association rule mining has evolved
giving rise to more sophisticate approaches that pro-
pose to mine queries (Dehaspe and Toivenen, 1999;
Diop et al., 2002). The problem of iterative query an-
swering is becoming more and more important. The
motivation of these methods comes from the observa-
tion that a first extraction can accelerate further ones:
results already obtained during the extraction task of
one user can improve the mining task of subsequent
users (Diop et al., 2002).
XML allows the representation of data by using
tags that indicate the semantic structure of the data.
Groups sharing data with similar meaning can agree
441
Bouchou B., Cheriat A., Halfeld Ferrari Alves M., Jen T. and Laurent D. (2004).
XRM: AN XML-BASED LANGUAGE FOR RULE MINING SYSTEMS.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 441-446
DOI: 10.5220/0002614504410446
Copyright
c
SciTePress

on different sets of tags and a schema for represent-
ing different kinds of data. In this way XML can be
adopted as a framework for exchanging knowledge
information among data mining systems.
Although some work have already been proposed
in this context such as PMML (Data Mining Group,
2003), our approach is a contribution since we con-
centrate on the representation of logic formulas. In
doing this, we allow the user working on data mining
to express data (i.e., facts over a database schema),
database constraints (such as functional dependency)
and extended association rules (i.e., patterns more so-
phisticate than those allowed by the association rule
module of PMML). Moreover, as XRM is built over
XML Schema it can ensure a certain level of correct-
ness of the data and patterns by defining integrity con-
straints. The following example shows that XRM can
simplify the task of describing sophisticate associa-
tion rules.
Example 1.1 Consider the association rule R1: 80% of
the customers who buy bread and butter, also buy milk
(i.e., confidence=0.80). Moreover, this holds in 20% of
the transactions (i.e., support=0.20). Rule R1 can be
easily represented in PMML. Now consider the associ-
ation rule R2, with confidence=0.50 and support=0.25:
Customers buying dairy products in June are professors
doing local shopping. The representation of R2 in PMML
is extremely complicate, artificial and time consuming,
since we need firstly to combine several tables into a
universal table, then to transfer it to a binary table. The
reason for this is that the DTD proposed by PMML
cannot express predicates, variables or quantifiers. To
express R2 we need a tool capable of expressing the
logic formula (∀x, ∃p, ∃v
1
, ∃y
1
, ∃s
1
, ∃v
2
, ∃y
2
, ∃s
2
)
(Cust(x, p, v
1
) ∧ Sale(x, y
1
, s
1
, ”June”) ∧
P rod(y
1
, ”dairy”) ⇒ (Cust(x, ”professor”, v
2
) ∧
Sale(x, y
2
, s
2
, ”June”) ∧ Store(s
2
, v
2
)). ¤
The main contributions of this paper are:
• The introduction of an XML-based language to rep-
resent logic formulas. This language allows the repre-
sentation of data, constraints and patterns (as logical
formulas). Thus, XRM offers a flexibility for systems
that extend the association rule mining by considering
not only simple rules over a unique database relation
but also queries involving base relations and views. It
is a general framework to express any system on logic
formulas (not only association rules).
• The possibility given to the mining systems to
present their results in an exchangeable format, mak-
ing it easy for other tools to work on them. In fact,
different tasks can be accomplished over the results
of a mining process: their integration to the results
coming from other mining systems, their use in other
mining process, their graphical representation, their
manipulation by XML query languages, etc.
• The use of XML Schema (W3C, 2001) in the defini-
tion of XRM that ensures a certain level of correctness
of data to be mined and allows the automatic verifica-
tion of patterns produced by mining systems.
This paper is organized as follows. Section 2 dis-
cuss some related work. Section 3 recalls the data
mining concepts to be represented in our language. In
Section 4, XRM is presented by a general schema and
we discuss some of its details. Section 5 concludes
with some further work.
2 RELATED WORK
The Predictive Model Markup Language (PMML)
proposed by (Data Mining Group, 2003) is a format
to exchange patterns among systems. It is an XML-
based language, built over a DTD, for describing data
mining models. Part of this DTD concerns rule mod-
els and focus on association rules. This specification
is however restricted to relatively simple rule mod-
els, since only transactions with a single attribute can
be represented. Variables, negation, quantifiers, con-
nectives or multi-dimensional association rules can-
not be expressed by PMML. The model Rule Model
proposed by (Wettschereck and M
¨
uller, 2001) modi-
fies the DTD of PMML for association rules. In this
way, it can describe multi-relational association rules.
In that approach, an association rule consists of a set
of literals but quantifiers and connectives cannot be
represented.
Contrary to the above approaches, XRM is built
over XML Schema. Thus, XRM can impose con-
straints that are not possible to express when dealing
with a DTD. Moreover, as XRM allows the represen-
tation of logic formulas, sophisticate multi-relational
association rules can be treated.
XDM (Meo and Psaila, 2003) uses XML as a unify-
ing framework for inductive databases (Imielinski and
Mannila., 1996) and, more generally, for knowledge
discovery systems. It is devised to capture the KDD
process and allows the storage of the derivation pro-
cess (described by statements). In fact, XRM can be
seen as a complement for XDM: as XDM is indepen-
dent of a specific format for data and pattern, one can
consider that data and patterns represented by XRM
documents might be stored in an inductive database
based on XDM.
3 MINING DATABASES
We assume that the reader is familiar with the bases
of relational databases and first order logic. We just
recall some definitions and notations used in this pa-
per. A relation schema is a relation name R and a
database schema is a nonempty finite set R of re-
lational schemas. In the named perspective, names
of attributes are considered and a tuple u (with sort
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
442

U = {A
1
, . . . , A
n
}) is defined as a function and rep-
resented by u = hA
1
: v
1
, . . . , A
n
: v
n
i, where
A
1
, . . . , A
n
are attributes and each v
i
is a constant
in the underlying domain. In the unnamed perspec-
tive the order is important, and a tuple is seen as an
element of the Cartesian product. A tuple u (with ar-
ity n) is denoted by u = hv
1
, . . . , v
n
i. In this paper
we use the logic programming perspective and repre-
sent a relation instance over R as a set of facts over
R. A fact is denoted by R(A
1
: v
1
, . . . , A
n
: v
n
) or
by R(v
1
, . . . , v
n
). A database instance over R is the
union of relation instances over R, for all R ∈ R.
Terms are built in the usual way from constants,
variables and function symbols. An atom is either
true, false or an expression of the form R(t
1
, . . . , t
n
)
where R is a n-ary predicate and t
1
, . . . , t
n
are terms.
(Well-formed first order) formulas (over R) are de-
fined recursively starting with atoms, using boolean
connectives and the quantifiers (∀ and ∃). Given a
first order formula φ, we denote by free(φ) the set of
of free variables in φ.
A datalog rule has the form l : a
0
← a
1
, . . . , a
n
,
where the head a
0
is an atom and the body, a
1
, . . . , a
n
is composed by atoms or negated atoms. Each dat-
alog rule is associated to a first order formula φ :
(¬a
1
∨ . . . ∨ ¬a
n
∨ a
0
) (quantifiers omitted).
We recall the notations and terminologies presented
in (Diop et al., 2002), which will be used in the
rest of this article. We start with the notion of ref-
erential that is defined as a view r over a database
schema R. Intuitively, r gives the ”individuals” for
which the support and the confidence of a rule are
computed. For instance, the following referential r
defines the customers that bought products in June:
r(x) ← Cust(x, p, v) ∧ Sale(x, y, s, ”June”).
Now, a mining query is an expression of the form:
(∃Y )(r ∧ φ), such that Y = free(φ) \ f ree(r)
and φ is a logical formula. An association rule
is an expression of the form: (∀K)(Q
1
⇒ Q
2
),
where K = free(r) and Q
1
and Q
2
are two mining
queries containing the same referential r. For exam-
ple, consider the two queries Q
1
and Q
2
. Q
1
indi-
cates customers buying dairy product in June: Q
1
:
(∃y)(r(x) ∧ Sale(x, y, s, D) ∧ Store(s, ”dairy”))
and Q
2
indicates professors doing local shopping in
June: Q
2
: (∃v)(r(x) ∧ Cust(x, ”P rofessor”, v) ∧
Sale(x, y, s, D) ∧ Store(s, v)). Now, L
2
:
(∀x)(Q
1
⇒ Q
2
) is an example of an association rule.
Given a logic formula φ (expressing a query or a
view) and a database instance I over database schema
R, the expression φ(I) represents the relation result-
ing from the evaluation of φ over I and |φ(I)| is the
number of tuples in this resulting relation. Now, for
every instance I of R, we have:
• The support of Q relatively to I and a referential r,
denoted by sup(Q/r, I) is the ratio Sup(Q/r, I) =
|Q(I)|
|r(I)|
. A frequent query is a mining query Q for
which Sup(Q/r, I) ≥ minsup, where minsup is a
support threshold.
• The support of an association rule L : (∀K)(Q
1
⇒
Q
2
) relatively to r and I, denoted by Sup(L/r, I) is
the ratio Sup(L/r, I) =
|(Q
1
∧Q
2
)(I)|
|r(I)|
.
• The confidence of an association rule L :
(∀K)(Q
1
⇒ Q
2
) relatively to r and I, denoted
by Conf(L/r, I) is the ratio: Conf (L/r, I) =
|(Q
1
∧Q
2
)(I)|
|Q
1
(I)|
. We can also define the confidence of an
association rule by the expression: Conf(L/r, I) =
Sup(L/r,I)
Sup(Q
1
/r,I)
.
• An association rule L is interest-
ing iff: Sup(L/r, I)≥minsup and
Conf (L/r, I)≥minconf , where minconf and
minsup are thresholds.
4 XRM
XRM specification is available in (Bouchou et al.,
2004). This specification is built with XML Schema
since it allows the implementation of integrity con-
straints over the model and the use of name spaces.
The concept of name space brings the possibility of
including in an XML document the reference of a
schema previously defined. In other words, a docu-
ment has an element <xmlns> having as attribute an
URL that specifies the schema (or the content type) of
the document. In this paper, this schema corresponds
to the specification of XRM, designed to make pos-
sible the communication among data mining applica-
tions.
DTDs also allow the specification of schemas but
they are less powerful than XML Schema. Indeed, a
DTD offers very limited data types, it does not allow
the use of XML name spaces and it does not support
the concept of inheritance. Moreover, it is more dif-
ficult to extend a DTD than a schema proposed with
XML Schema.
In this section we present the language XRM. We
explain features concerning XML Schema when nec-
essary. Figure 2 summarizes the elements specified
by XRM. The specification of these elements takes
into account the hierarchy of XML documents - trees
where each node has a position, a label and a type
(element or attribute). Most of XRM elements corre-
spond to the concepts seen in Section 3. In order to
give them a global scope (to be able to reference them
anywhere), all components are listed under the root.
In what follows we first present the basic elements
of XRM and then, we show how they can be used to
describe association rules.
XRM: AN XML-BASED LANGUAGE FOR RULE MINING SYSTEMS
443

Frequent−Query
XRM
0
0
term
00 0
00000
0 0
0
FD
minconf
Rule
Association−
0
constant variable function
attribute
QueryFormulaatom predicate
ViewConstraint
Referential minsup
Figure 2: Components of XRM model.
4.1 Basic elements of XRM
The basic elements of XRM concern the presentation
of first order formula. We show in Figure 3 how our
model defines a constant (line 1), a variable (line 2)
and a function (lines 3-16) . We recall that simple
types and complex types are defined in XML Schema.
Simple types are built by imposing some restrictions
over predefined types (strings, positive integer, etc) or
other simple types. Complex types are composed by a
set of elements or attributes. From Figure 3, we notice
that the elements constant and variable have prede-
fined types, while function is a complex type element.
Indeed, the complex type that defines a function has
the following features: (i) two attributes: the first one
specifying the function symbol (line 13) and the sec-
ond one its arity (line 14); (ii) some sub-elements:
represented by a list of constants, variables or func-
tions (lines 5-12). These sub-elements represent the
function parameters. Notice that we can refer to previ-
ously declared components, using the XML Schema
option ref (lines 8-10).
XML Schema proposes different choices to de-
fine sub-elements. In Figure 3 we notice the use of
sequence (line 5) and choice (line 6). The option
sequence defines an ordered list of sub-elements,
while choice specifies possible choices of sub-
elements. We can also precise the minimum and max-
imum number of occurrences of each sub-element,
with options minOccurs and maxOccurs (when
these options are not specified they are considered to
be 1). Thus, in our case, a function can have a se-
quence of 1 or n (due to the unbounded on line 5) pa-
rameters. Parameters
1
can be chosen to be constants,
variables or functions.
The definition of a term uses the same XML
Schema options mentioned above. Recall that a term
is either a constant, a variable or a function. The set of
attribute names that can be used in a XRM document
is specified by the basic element attribute.
In the definition of a predicate (Figure 4) XRM
gives the user the option of using the named (line 6)
or the unnamed (line 7) perspective (Section 3).
1
Notice that in the declaration of function, predicate, etc.
XRM includes the notion of their parameters.
1) <xrm:element name="constant" type="xrm:string"/>
2) <xrm:element name="variable" type="xrm:string"/>
3) <xrm:element name="function">
4) <xrm:complexType>
5) <xrm:sequence maxOccurs="unbounded">
7) <xrm:choice>
8) <xrm:element ref="constant"/>
9) <xrm:element ref="variable"/>
10) <xrm:element ref="function"/>
11) </xrm:choice>
12) </xrm:sequence>
13) <xrm:attribute name="symbol" type="xrm:string"/>
14) <xrm:attribute name="arity" type="xrm:positiveInteger"/>
15) </xrm:complexType>
16) </xrm:element>
Figure 3: Constant, Variable and Function declarations.
1) <xrm:element name="predicate">
2) <xrm:complexType>
3) <xrm:sequence>
4) <xrm:element name="symbol" type="xrm:string"/>
5) <xrm:choice>
6) <xrm:element name="attribute-name"
type="xrm:string" maxOccurs="unbounded"/>
7) <xrm:element name="arity" type="xrm:string"/>
8) </xrm:choice>
9) </xrm:sequence>
10) </xrm:complexType>
11) </xrm:element>
Figure 4: Specification of a predicate in XRM.
In the description of a mining rule, we want the
names of predicates to be unique. To this end, we use
the notion of key provided by XML Schema, which is
defined in two steps. In the first step we identify a set
of context positions from the root on which the key is
being defined. In the second step, we specify the set of
values that distinguish each context position. Indeed,
this notion of key corresponds to the absolute key
presented in (Buneman et al., 2001). We use a sub-
set of XPath expressions to specify context positions
and to obtain the values that compose keys. In Fig-
ure 5, the key constraint ”predicate-PK” is presented.
The first XPath expression (xpath=”XRM/predicate”)
specifies the path to context positions (in this case, po-
sitions labeled predicate). The second Xpath expres-
sion (xpath=”symbol”) specifies that, in this context,
the sub-element ”symbol” is the key.
1) <xrm:key name="predicate-PK">
2) <xrm:selector xpath="XRM/predicate"/>
3) <xrm:field xpath="symbol"/>
4) </xrm:key>
Figure 5: Key constraint for predicates.
An atomic formula (or an atom) is either true, false
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
444

or composed by a predicate symbol and terms. We
want to constraint predicate symbols composing an
atom to those already defined. To this end, we use
the notion of foreign key (keyref). Similarly to the
key definition, we use XPath expressions to specify
foreign keys (lines 2-3 of Figure 6). We recall that
foreign keys are always associated to a key. Now, to
indicate the key constraint to which the foreign key
is associated to, we add refer, as illustrated in Fig-
ure 6 (line 1). In this figure, we present the foreign
key ”atom-ref-RK”. This foreign key indicates that
the element ”symbol”, specified by Xpath expressions
xpath=”.//atom” and xpath=”symbol”, refers to a key
defined by the key constraint predicate-PK (defined
in Figure 5). Notice that we also use the notion of
foreign key to assure that attribute-name (line 6 Fig-
ure 4) corresponds to an existing attribute.
1) <xrm:keyref name="atom-ref-RK" refer="predicate-PK">
2) <xrm:selector xpath=".//atom"/>
3) <xrm:field xpath="symbol"/>
4) </xrm:keyref>
Figure 6: Foreign key constraint for atoms.
In Figure 7 we show the recursive definition of
a formula. In the option choice we present four
ways of building a formula. The first choice corre-
sponds to the atomic formula (line 4) while the second
one defines negative formulas (lines 5-10). The third
choice introduces quantified formula: a list of quan-
tified variables precedes a formula (lines 11-19). The
fourth choice builds a compound formula by using bi-
nary connectives (lines 20-26). Notice that TQuanti-
fier (line 14) and TBConnective (line 23) are simple
types corresponding to the quantifiers (∃ and ∀) and
to the binary connectives, respectively.
The next step consists in defining queries and
views. In XRM, these definitions are done by refer-
ring to types previously defined: a query refers to a
formula and a view refers to a query.
4.2 Association rules in XRM
In this part we specify association rules with the basic
elements introduced in the previous section. Firstly,
the specification of a referential is done just by re-
ferring to a view defined over a database schema. The
thresholds minsup and minconf are specified by a sim-
ple type called ”Prob-number”, which represents val-
ues between 0 and 1.
To define a frequent query we use the concept of
inheritance, implemented by the option extension
in XML Schema. In Figure 8 (line 4), a Frequent-
Query inherits all the properties of a query (due to
the declaration <xrm:extension base= ”TQuery”>).
Besides, it has its own properties: an element called
”ref-referential” (line 6) and two attributes (lines 8-9).
1) <xrm:element name="Formula">
2) <xrm:complexType>
3) <xrm:choice>
4) <xrm:element ref="atom"/>
5) <xrm:sequence>
6) <xrm:element name="unary-connective"
type="xrm:string" fixed="not"/>
7) <xrm:element name="open-parenthesis"
type="xrm:string" fixed="("/>
8) <xrm:element ref="Formula"/>
9) <xrm:element name="close-parenthesis"
type="xrm:string" fixed=")"/>
10) </xrm:sequence>
11) <xrm:sequence>
12) <xrm:element name="open-parenthesis"
type="xrm:string" fixed="("/>
13) <xrm:sequence maxOccurs="unbounded">
14) <xrm:element name="quantifier"
type="TQuantifier" default="Exist"/>
15) <xrm:element name="variable" type="xrm:string"/>
16) </xrm:sequence>
17) <xrm:element name="close-parenthesis"
type="xrm:string" fixed=")"/>
18) <xrm:element ref="Formula"/>
19) </xrm:sequence>
20) <xrm:sequence>
21) <xrm:element name="open-parenthesis"
type="xrm:string" fixed="("/>
22) <xrm:element ref="Formula"/>
23) <xrm:element name="binary-connective"
type="TBConnective"/>
24) <xrm:element ref="Formula"/>
25) <xrm:element name="close-parenthesis"
type="xrm:string" fixed=")"/>
26) </xrm:sequence>
27) </xrm:choice>
28) </xrm:complexType>
29) </xrm:element>
Figure 7: Specification of a well-formed formula.
A frequent query is associated to the key constraint
”Frequent-Query-PK” (line 13-16) and we define a
foreign key constraint over ”ref-referential” since we
want this element to be an association to a referential.
In Figure 9 we show the declaration of this foreign
key constraint. Notice that the associated key con-
straint, denoted by “Referential-PK”, is defined over
a referential (the declarations of referential and its key
constraint are not shown here).
Finally, XRM defines an Association-Rule as an el-
ement composed by the following features:
(i) A list of quantified variables. (ii) Elements cor-
responding to the antecedent and the consequent of
an association rule. We define foreign key constraints
over these elements, since they should be references
to frequent queries. (iii) Attributes “support” and
“confidence” of type Prob-number. We refer to (Bou-
chou et al., 2004) for an example of an XRM docu-
ment that represents an association rule.
XRM: AN XML-BASED LANGUAGE FOR RULE MINING SYSTEMS
445

1) <xrm:element name="Frequent-Query">
2) <xrm:complexType>
3) <xrm:complexContent>
4) <xrm:extension base="TQuery">
5) <xrm:sequence>
6) <xrm:element name="ref-referential"/>
7) </xrm:sequence>
8) <xrm:attribute name="id" type="xrm:string"/>
9) <xrm:attribute name="support" type="Prob-number"/>
10) </xrm:extension>
11) </xrm:complexContent>
12) </xrm:complexType>
13) <xrm:key name="Frequent-Query-PK">
14) <xrm:selector xpath="XLogic/Frequent-Query"/>
15) <xrm:field xpath="@id"/>
16) </xrm:key>
Figure 8: Specification of a frequent query and its associ-
ated key constraint.
1) <xrm:keyref name="Frequent-referential-RK"
refer="Referential-PK">
2) <xrm:selector xpath="XRM/Frequent-Query"/>
3) <xrm:field xpath="ref-referential"/>
4) </xrm:keyref>
Figure 9: Foreign key constraint for frequent queries.
From the above presentation, we can notice that the
use of XML Schema helps a lot in the specification of
XRM. Key and foreign keys constraints are extremely
useful to guarantee the consistency of XRM docu-
ments (avoiding, for instance, association rules that
use frequent queries that do not exist). The inheri-
tance property helps in generalizing some concepts.
Moreover, XRM offers a natural way of describing
patterns since, for instance, it keeps track of the mean-
ing of each element in an association rule (i.e., a rule
is composed by quantified variables, frequent queries,
and so on). The verbose aspect (an XML inheritance)
of this approach is an advantage, since the aim here
is to propose a tool that allows the communication
among different types of application programs. No-
tice from Figure 2 that XRM also specifies functional
dependencies (FD) and constraints (not discussed in
this paper).
5 CONCLUSION
In this paper we present XRM, an XML-based lan-
guage that allows the representation of first order for-
mulas and, thus, is an efficient tool to represent data,
constraints and patterns. Although in this paper we
concentrate on association rule mining systems, XRM
can be used with every mining system whose data and
results can be expressed by first order formulas.
We are interested in the following directions for
further research. First, the application of our ap-
proach to other data mining tasks, such as classifica-
tion and clustering in first order logic, as introduced
in (D
ˇ
zeroski and Lavra
ˇ
c, 2001). Second, the speci-
fication of a general framework to exploit data min-
ing results. To this end, we should firstly extend the
tree automata validation process presented in (Bou-
chou and Halfeld Ferrari Alves, 2003) to deal with
XML Schema instead of DTDs. Our goal is to de-
velop an update language allowing changes on valid
XRM documents by preserving validity (we intend to
adapt the method proposed in (Bouchou et al., 2003)
to XRM).
REFERENCES
Bouchou, B., Cheriat, A., Halfeld Ferrari Alves, M., Jen,
T., and Laurent, D. (2004). An XML approach for
rule mining systems. Technical Report (To appear),
LI, Universit
´
e de Tours.
Bouchou, B., Duarte, D., Halfeld Ferrari Alves, M., and
Laurent, D. (2003). Extending tree automata to model
XML validation under element and attribute con-
straints. In ICEIS.
Bouchou, B. and Halfeld Ferrari Alves, M. (2003). Up-
dates and incremental validation of XML documents.
In DBPL. LNCS 2921, Springer Verlag.
Buneman, P., Davidson, S., Fan, W., Hara, C., and Tan,
W. C. (2001). Keys for XML. In World Wide Web,
pages 201–210.
Data Mining Group (2003). PMML. Technical report,
http://www.dmg.org/pmml-v2-0.htm.
Dehaspe, L. and Toivenen, H. (1999). Discovery of frequent
datalog patterns. Data mining and knowledge discov-
ery. Kluwer Academic Publishers, 3:7–36.
Diop, C., Giacometti, A., Laurent, D., and Spyratos, N.
(2002). Composition of mining contexts for efficient
extraction of association rules. In EDBT. LNCS 2287,
Springer Verlag.
D
ˇ
zeroski, S. and Lavra
ˇ
c, N., editors (2001). Relational
Data Mining, chapter 6, 9. Springer-Verlag.
Imielinski, T. and Mannila., H. (1996). A database perspec-
tive on knowledge discovery. Communication of the
ACM, 39:58–64.
Meo, R. and Psaila, G. (2003). An XML-Based definition of
a database for knowledge discovery. Technical Report
RT74-2003-04, Dipartimento di Informatica, Univer-
sit di Torino.
W3C (2001). XML Schema Part 1: Structures. Technical
report, http://www.w3.org/TR/xmlschema-1/.
Wettschereck, D. and M
¨
uller, S. (2001). Exchanging data
mining models with the predictive modelling markup
language. In Proc. of the ECML/PKDD-01 Workshop
on Integration Aspects of Data Mining, Decision Sup-
port and Meta-Learning, pages 55–66.
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
446
