
ROBUST SPOKEN DOCUMENT RETRIEVAL BASED ON
MULTILINGUAL SUBPHONETIC SEGMENT RECOGNITION
Shi-wook Lee, Kazuyo Tanaka
National Institute of Advanced Industrial Science and Technology, JAPAN
AIST Central # 2, Umezono 1-1-1, Tsukuba, 305-8568, Japan
Yoshiaki Itoh
Iwate Prefectural University, JAPAN
Sugo, 152-52, Takizawa, IWATE, 020-0193, Japan
Keywords:
Spoken document retrieval, Multi-lingual, Open-vocabulary Speech Recognition, Subphonetic unit.
Abstract:
This paper describes the development and application of a subphonetic segment recognition system for spoken
document retrieval. Following from the development of an open-vocabulary spoken document retrieval sys-
tem, where the retrieval process is accomplished in the symbolic domain by measuring the distance between
the parts of subphonetic segment results from pattern recognition in the acoustic domain, the system proposed
here performs matching based on subphonetic segment as more basic unit than the semantic unit. As such,
the system is not constrained by vocabulary or grammar, and can be readily extended to multilingual tasks.
This paper presents the proposed spoken document retrieval system including the proposed subphonetic seg-
ment recognition scheme, and evaluates the performance and feasibility of the system through experimental
application to multilingual retrieval tasks.
1 INTRODUCTION
Recently, information retrieval techniques have been
widely adopted for text databases to identify docu-
ments that are likely to be relevant to text queries. The
aim of spoken document retrieval (SDR) is to provide
similar functionality for databases of spoken docu-
ments. Such spoken documents, stored in the form of
audio signals, may be collected from many different
sources, such as news broadcasts on radio and televi-
sion, voice/video e-mail, and multimedia material on
the Web. Furthermore, as the volume of such acces-
sible multimedia databases continues to grow, the de-
mand for user-friendly methods to access, process and
retrieve the data has become increasingly important.
Therefore, it has become indispensable to be able to
retrieve such documents in response to speech queries
as well as text queries.
Overall, subword-based retrieval is not as effec-
tive as word-based retrieval, but is helpful when the
word-based speech recognition output is prone to er-
ror or undesirable, as may occur in out-of-vocabulary
(OOV) problems and multilingual tasks. With current
technology, there is a practical limit on the size of the
vocabulary. When new speech queries that are not in
the pronunciation dictionary (lexicon) are input, the
system undesirably replaces the query with the most
probable word. If the system is more sophisticated, it
regards the input query as unknown, and fails to of-
fer a result, without providing further details. The
system can never output a string of subwords that
is not listed in the pronunciation dictionary. Large-
vocabulary continuous speech recognition (LVCSR)
systems cannot deal with articulation at the subword
level unless subword units are used as the fundamen-
tal units. The video mail retrieval project is address-
ing this requirement by developing systems to retrieve
stored video material using the spoken audio sound
track(Jones, 1996).
In the task of cross-language retrieval, non-native
pronunciation characteristics (i.e., foreign accents) in
foreign language speech lead to extremely poor per-
formance in SDR. For example, English uttered by
a Japanese speaker will retain many Japanese speech
characteristics (Japanese-English). Therefore, it is de-
sirable that the system can deal with those speech
queries with foreign accents. As the prevalence of
multimedia material on the Web continues to grow,
the demand for multilingual SDR systems is rapidly
strengthening. The development of multilingual SDR
systems will therefore be of significant benefit for
multilingual task, and will parallel the development
of retrieval in these systems.
To accomplish cross-media tasks, for example text
134
Lee S., Tanaka K. and Itoh Y. (2004).
ROBUST SPOKEN DOCUMENT RETRIEVAL BASED ON MULTILINGUAL SUBPHONETIC SEGMENT RECOGNITION.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 134-139
DOI: 10.5220/0002636201340139
Copyright
c
SciTePress
queries of spoken documents and speech queries of
text documents, the choice of suitable subword units
for multimedia retrieval is important. The advantage
of subword units is that the transcript is readable by
humans and can be used to translate text queries into
subword sequences so as to be acceptable in SDR.
The present authors have been developing an SDR
system in which retrieval is conducted by calcu-
lating the distance between the parts of a subpho-
netic segment(SPS) sequence extracted from under-
lying speech recognition. As the system is based
on matching SPS sequences directly, the system is
not constrained in terms of vocabulary or grammar,
and is robust with respect to recognition error(Tanaka,
2001)(Lee, 2002). Most existing SDR systems are
based on matching text, and speech recognition sys-
tems usually employ the integration of likelihood val-
ues of acoustic phoneme sequences given from a top-
down hypotheses. Thus, it should be possible to
merge both acoustic and symbolic processing simul-
taneously. In this work, the feasibility of subpho-
netic units for retrieval in an SDR system is investi-
gated. The effect of varying the distance measure is
also examined in an attempt to improve the perfor-
mance of the shift continuous dynamic programming
(Shift-CDP) matching based on SPS sequences. Fi-
nally, SDR experiments are conducted to evaluate the
performance of the proposed system in both monolin-
gual and multilingual tasks.
2 SPOKEN DOCUMENT
RETRIEVAL SYSTEM
A spoken document database containing a signifi-
cantly high proportion of OOV words is assumed,
such as names and places. Such words will be suscep-
tible to poor retrieval performance due to misrecogni-
tion. Speech retrieval is similar to text retrieval, ex-
cept for a number of difficulties in actual application
such as accurate detection of word boundaries, recog-
nition errors, and acoustic mismatching. For this rea-
son, existing SDR systems perform retrieval using a
text-based database linked to multimedia material in
the speech-based database. The SDR system pro-
posed here aims to retrieve speech keyphrases directly
from the object multimedia database. In the system,
if the object multimedia database has parts similar to
those included in the input queries, the relevant data
can be retrieved using only the accumulated distance
between arbitrary durations of SPS sequences. Such
a scheme is suitable for an open-vocabulary system.
This function can be performed by applying Shift-
CDP for optimal matching between SPS sequences.
This is an essential difference from the conventional
speech processing methods. In the proposed system,
the input utterance is first encoded in terms of acous-
tic features. Then, the SPS extracted by a recognizer
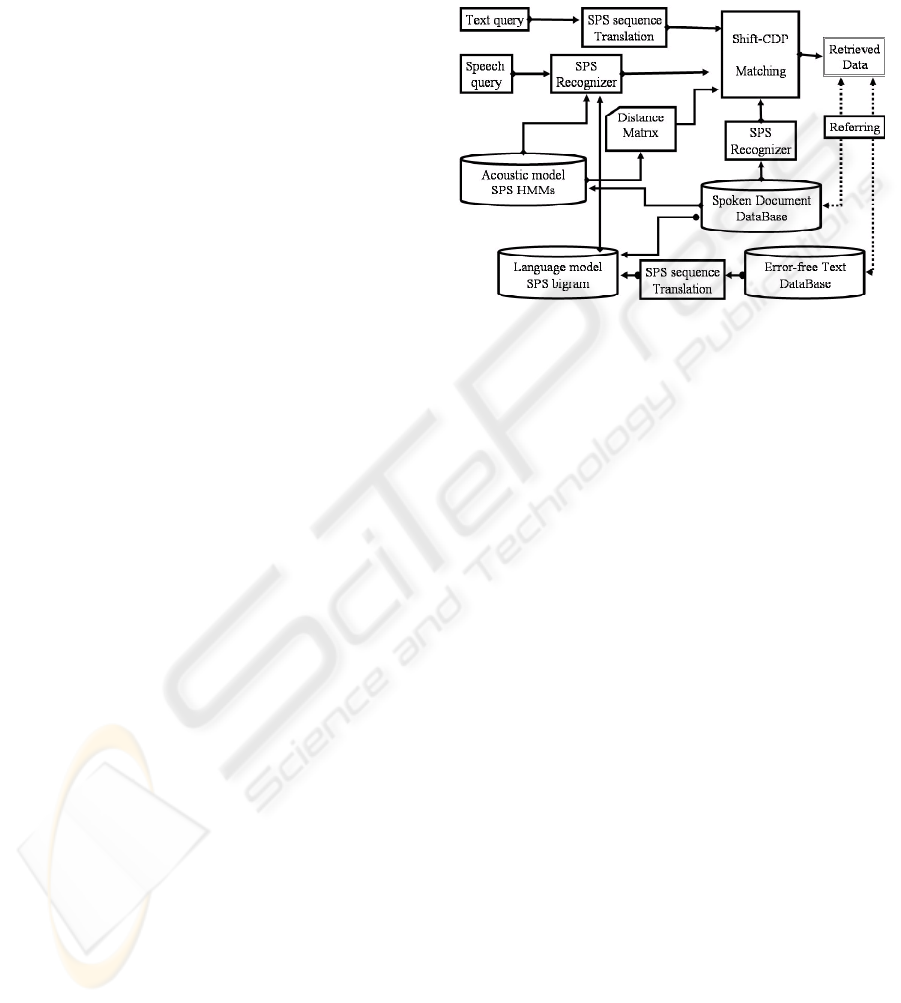
is transferred to Shift-CDP(Tanaka, 2001). Figure 1
shows the overall block diagram of the proposed SDR
system.
Figure 1: Block diagram of proposed SDR system based on
subphonetic segments
3 SUBWORD UNITS
In order to allow user-friendly queries of a multi-
media database, speech signals are converted into
words, phonemes, or other subword units, using
a speech recognition system. This work focuses
on a SPS-based approach, where spoken documents
are recognized as SPS sequences and the retrieval
process is carried out based on matching the dy-
namic programming scores of these transcriptions.
Although word-based approaches have consistently
outperformed phoneme approaches(Voorhees, 1998),
there are several compelling reasons for using SPS, as
mentioned above.
The present authors have been developing an ar-
chitecture for speech processing systems based on the
universal phonetic code (UPC)(Tanaka, 2001). All
of the speech data in the systems are once encoded
into UPC sequences, and then the speech process-
ing systems, such as recognition, retrieval, and diges-
tion, are constructed in the UPC domain. The inter-
national phonetic alphabet (IPA) or extended speech
assessment methods phonetic alphabe (XSAMPA) is
the candidate set for the UPC set. Here SAMPA is a
machine-readable phonetic alphabet. The SPS is de-
rived from XSAMPA and is refined under the consid-
eration of acoustic-articulatory effects. For example,
the XSAMPA (i.e., IPA) contains partly extra-detailed
categorization to be modeled in an engineering sense.
Therefore, only primary IPA symbols are adopted,
ROBUST SPOKEN DOCUMENT RETRIEVAL BASED ON MULTILINGUAL SUBPHONETIC SEGMENT
RECOGNITION
135
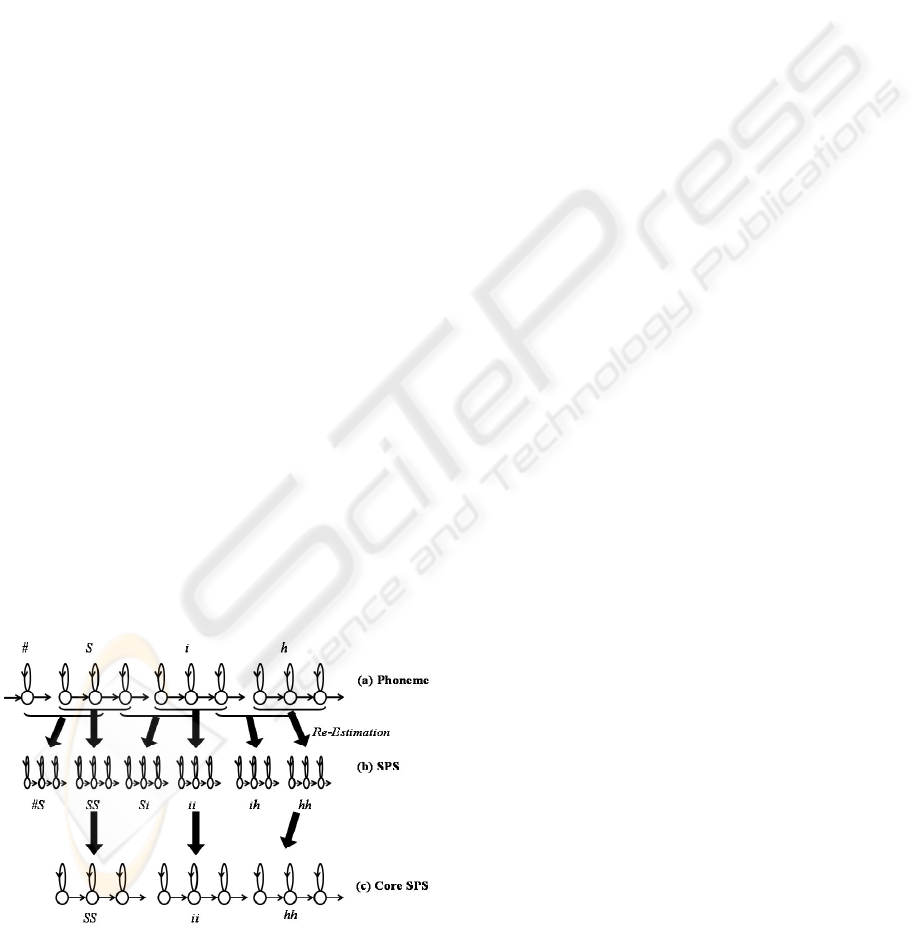
and minor phonetic variations are represented by sta-
tistical distributions in the acoustic domain. A sim-
ple example of an SPS converted from XSAMPA se-
quences consisting of stationary and non-stationary
segments in the speech stream is given below. The ad-
vantage of training SPS models is that pronunciation
variation is trained directly into the acoustic model,
and does not need to be modeled separately in the dic-
tionary.
• Speech: She had your dark · · ·
• XSAMPA-Phoneme: # S i h E dcl dZ @ r dcl d A
kcl k · · ·
• SPS: # #S SS Si ii ih hh hE EE EdZ dcl dZdZ dz@
@@ @r rr rd dcl dd dA AA Ak kcl kk · · ·
• Core SPS: # SS ii hh EE dZdZ @@ rr dd AA kk· · ·
where # denotes a pause or silence interval.
A total of 429 SPSs are extracted from the 43
phonemes for Japanese (including 3 silence types),
and 1352 SPSs are extracted from the 42 phonemes
of English (including 3 silence types). Theoret-
ically, 1610 SPSs can be extracted from the 42
English phonemes,however, some concatenations of
phonemes do not exist in real language. The remark-
ably fewer Japanese SPSs is due to the fact that most
Japanese syllables consist of 1 consonant and 1 vowel
(C+V). Therefore, concatenations of consonants are
very rare in Japanese, resulting in a lesser degree of
acoustic-articulation than in English. Acoustic mod-
els of English and Japanese are simply represented by
a left-to-right hidden Markov model (HMM) with 3
states, each with a single mixture diagonal distribu-
tion for simplicity.
Figure 2: Acoustic models of subword units: phoneme,
SPS, core SPS
4 SHIFT CONTINUOUS
DYNAMIC PROGRAMMING
When subword sequences are recognized directly,
with higher error rates than for words, selection of a
good matching approach becomes much more impor-
tant. Shift-CDP is an algorithm that identifies simi-
lar parts between a reference pattern R
N
and the in-
put pattern sequence I
T
synchronously. The pre-fixed
part of the reference pattern, called the unit reference
pattern (URP), is shifted from the start point of the
reference pattern to the end by a certain number of
frames. The matching results for each URP in the
reference pattern are then compared and integrated.
Shift-CDP is an improved version of the reference
interval-free CDP (RIFCDP), and performs matching
between arbitrary parts of the database and arbitray
parts of the query input(Itoh, 2001).
R
N
= {R
0
, · · · , R
τ
, · · · , R
τ +r
, · · · , R
N−1
} (1)
I
T
= {I
0
, · · · , I
t
, · · · , I
t+i
, · · · , I
T −1
} (2)
The first URP is taken from R
0
in the reference pat-
tern R
N
. The next URP is then composed of the same
number of N
URP
frames from the (N
shift
+ 1)
th
frame. In the same way, the k
th
URP is composed
of N
URP
frames from the k × (N
shift
+ 1)
th
frame.
Thus, the number of URPs becomes [N/N
shift
] + 1,
where [] indicates any integer that does not exceed the
enclosed value. Shift-CDP is then performed for all
URPs in the reference R
N
. It is not necessary to nor-
malize each cumulative distance at the end frame of
a URP because all URPs are of the same length. Ac-
tually, Shift-CDP is a very simple and flat algorithm
that performs CDP for each URP and integrates the
results.(Itoh, 2001)
5 DISTANCE MEASURE
In the Shift-CDP algorithm, the DP matching score
is calculated using a pre-measured SPS distance ma-
trix. Therefore, the system is directly influenced by
the distance measure, and selecting a proper measure
is important for the performance. Distance measures
have been widely applied in a number of speech tech-
nologies. For speech coding, distance measures are
used in the design scheme for vector quantization al-
gorithms and as objective measures of speech qual-
ity. In speech and speaker recognition, the spectral
difference between two speech patterns is measured
to compare patterns and make similarity decisions.
Motivated by these speech recognition techniques,
some unit-selection algorithms for speech synthesis
and optimal-joining algorithms now use the distance
measure between feature vectors. Here, the distance
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
136

measures D
AB
between two multivariate Gaussian
distributions, N(µ
A
, Σ
A
) and N(µ
B
, Σ
B
), are con-
sidered. The Bhattacharyya distance D
BHAT
, which
is covered in many texts on statistical pattern recog-
nition(Fukunaga, 1990), is a separability measure be-
tween two Gaussian distributions:
D
BHAT
=
1
N
N
X
n=1
(µ
An
− µ
Bn
)
2
8
·
Σ
An
+ Σ
Bn
2
¸
−1
+
1
2
ln
|
Σ
An
+Σ
Bn
2
|
p
|Σ
An
||Σ
Bn
|
(3)
where N is the number of HMM states and N = 3
states is used throughout this work. The first term
of Eq. (3) provides the class separability from the
difference between class means, while the second
term gives the class separability from the difference
between class covariance matrices. Here, consider-
ing the insufficiency of training data, the distance
measure derived directly from the difference between
class mean is adopted, that is, the first term of Eq. (3),
as formulated below. This distance is very close to the
weighted Mahalanobis distance.
D
AB
=
1
N
N
X
n=1
µ
(µ
An
− µ
Bn
)
2
Σ
An
+ Σ
Bn
2
¶
−1
(4)
Figure 3 shows the phonetic distance matrix be-
tween English and Japanese phonemes measured by
Eq. (4). The radius of the spots is linearly pro-
portional to the distance between the English and
Japanese phoneme HMMs. Thus, a larger spot area
indicates a longer distance.
6 EXPERIMENTAL EVALUATION
6.1 Multilingual Corpus and Models
For research into the underlying speech recognition
and information retrieval technologies based on sub-
word units, it was necessary to prepare a sufficient
corpus of spoken documents. The observation vec-
tor consists of 12th-order mel-cepstra, their delta,
power, and its derivative. Thus, a 26-dimensional
feature vector is extracted from each 5 ms analy-
sis frame. HMMs for English and Japanese are
estimated separately on language-dependent native-
speaker speech data as in typical monolingual speech
recognition. The phoneme models used here were 42
monophones (including 3 silence types) for English,
Figure 3: Phonetic distance matrix between English (# 39)
and Japanese (# 40) phonemes calculated by Eq.(4). The 3
silence models are not presented here.
and 43 monophones (including 3 silence types) for
Japanese. The English phoneme models were first es-
timated from TIMIT phonetically labeled data. The
acoustic models for the 1352 English SPSs were es-
timated using Wall Street Journal data (WSJ0). In
the case of Japanese acoustic models, Japanese news-
paper articles sentences (JNAS) were used to ob-
tain phonemes and the 429 SPSs. For all training
utterances, phoneme and SPS sequences were gen-
erated from the text transcription and a dictionary.
The Carnegie Mellon University (CMU) pronunci-
ation dictionary (120,000 words) was used for En-
glish, and the IPA pronunciation dictionary (60,000
words)(Kawahara, 1998) was used for Japanese to
translate all English and Japanese spoken documents
into phoneme/SPS sequences for forced-alignment in
training acoustic models and subword n-gram lan-
guage models. English acoustic phoneme models
were primarily built using the TIMIT 61 label set. In
order to use the CMU pronunciation dictionary (39
phonemes) to estimate English SPS models, the En-
glish phoneme models were collapsed down to the
39 labels. To increase underlying subword recogni-
tion accuracy, phoneme/SPS bigram language mod-
els were also estimated from the same corpus used to
train the acoustic models. The training material used
for acoustic and language models is summarized in
Table 1.
6.2 Experimental Results
A set of 10 short keyphrase queries were prepared for
SDR experiments. Each query had 9 relevant docu-
ments in each language-dependent target database of
2000 sentences. The input queries and target database
for experimental evaluation are detailed in Table 2.
The underlying recognition system for decoding
ROBUST SPOKEN DOCUMENT RETRIEVAL BASED ON MULTILINGUAL SUBPHONETIC SEGMENT
RECOGNITION
137

Table 1: Training material used for acoustic and language
models
Language English Japanese
# Sentences 29150 13786
Length 55.68 h 25.62 h
# Phonemes 42 43
# SPSs 1352 429
Table 2: Analysis of test material for monolingual and mul-
tilingual SDR tasks
Speaker Japanese Japanese English
Speech Japanese English English
Ave. length 1.19 s 2.00 s 1.01 s
# Phonemes 12.4 7.9 8.4
# SPSs 26.0 19.1 19.4
# Core SPSs 11.3 8.7 9.0
# Relevant 9 9 9
Target DB Japanese English
# Sentences 2000 2000
Length 3.29 h 1.87 hr
subwords was a single-pass beam search decoder
based on the JULIUS system(Kawahara, 1998). Ta-
ble 3 summaries the error rates for each language and
subword unit.
Table 3: Subword error rates (%) for each language and
subword unit
English Japanese
Phonemes 42.97 45.76
SPSs 50.90 46.21
Core SPSs 41.66 35.66
Figures 4 and 5 show the language-dependent
monolingual SDR performance for English and
Japanese according to subword units. The speech
of input queries and target DBs were uttered by na-
tive speakers. Both in English and Japanese SDR
experiments, the SPS-based SDR outperformed the
phoneme-based and core SPS-based schemes remark-
ably. Longer subword units can capture word or
phrase information, while shorter units can only
model word fragments. The trade-off is that the
shorter units are more robust to error and word vari-
ants than the longer units. There were no significant
differences between the performance of SDR based
on phonemes and core SPSs. As seen in Tables 2
and 3, although the error rates when using core SPSs
are lower than for the use of phonemes, the SDR
performance is heavily dependent on the number of
subwords per unit time. This also demonstrates that
the amount of information per unit time is an essen-
tial consideration in subword-based SDR. The per-
formance of SDR for English is worse than that for
Japanese, due to the extremely large number of vari-
ant pronunciations in English, and the larger amount
of information per unit time in Japanese. The former
cause can be counteracted to some extent by prepar-
ing various pronunciations in a dictionary, however,
cross-word coarticulation cannot be predicted.
0
20
40
60
80
100
0 20 40 60 80 100
Precision Rate [%]
Recall Rate [%]
SPS
SPScore
PHONE
Figure 4: Performance of Japanese SDR according to sub-
word units, phoneme(PHONE), subphonetic segment(SPS),
and core SPS(SPScore)
0
20
40
60
80
100
0 20 40 60 80 100
Precision Rate [%]
Recall Rate [%]
SPS
PHONE
SPScore
Figure 5: Performance of English SDR according to sub-
word units
The two HMM sets, Japanese and English, are
used together in English SDR tasks for Japanese-
English, labeled as EJ.model in Figure 6. The acous-
tic EJmodel contains 1778 SPS HMMs from the
1352 English HMMs, and 429 Japanese HMMs. The
3 silence models are chosen from the English mod-
els. Despite the simple method for combining the two
acoustic models, the performance is improved consid-
erably for Japanese-English tasks. This result demon-
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
138
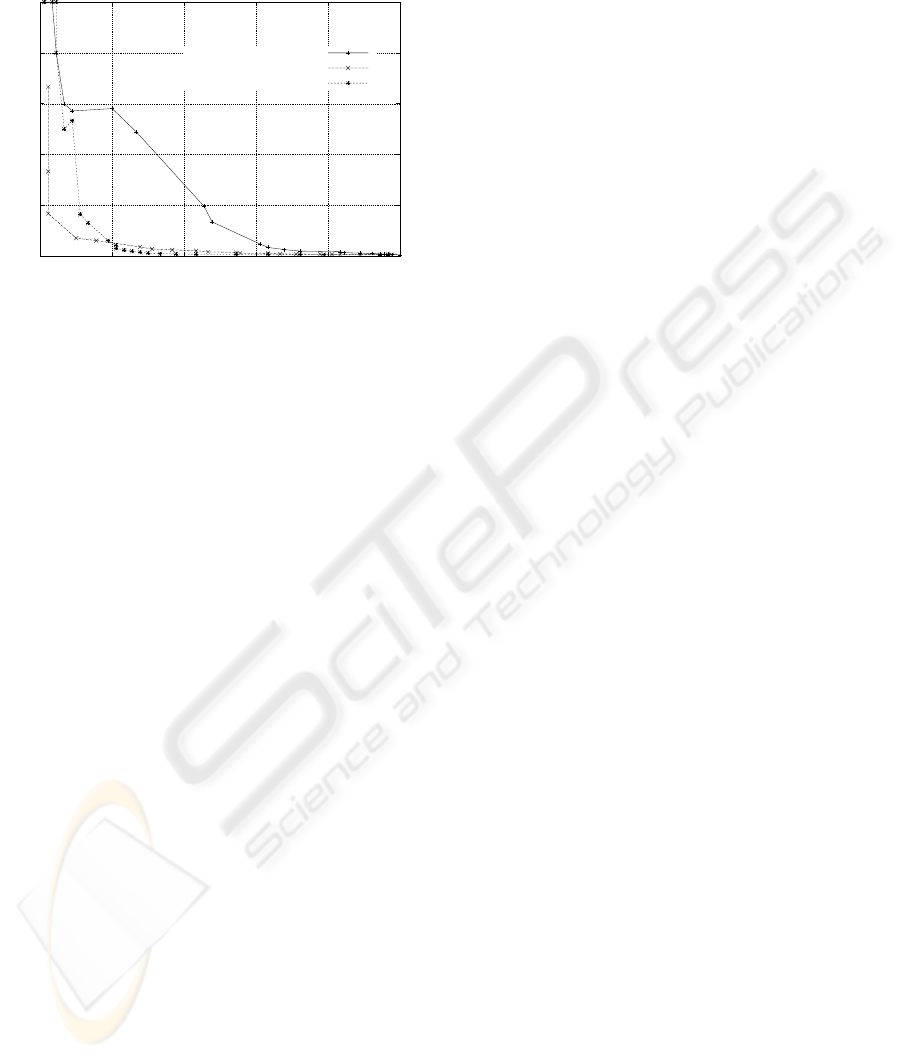
strates that this approach is a feasible means of han-
dling foreign accents in multilanguage SDR.
0
20
40
60
80
100
0 20 40 60 80 100
Precision Rate [%]
Recall Rate [%]
Espk - E.model
Jspk - E.model
Jspk-EJ.model
Figure 6: Performance of SPS-based English SDR accord-
ing to speaker type and acoustic model. Native English
speaker (Espk) and Japanese speaker (Jspk), English acous-
tic model (E.model), and Multi-lingual acoustic model
(EJ.model)
7 CONCLUSIONS
This paper presented the development of an open-
vocabulary SDR system and the use of SPSs as a new
subword unit. Experimental evaluation demonstrated
that the SPS-based approach significantly improves
the performance of both monolingual and multilin-
gual SDR. Future work will concentrate on extending
the system to other languages, as well as coupling the
scheme with LVCSR-based systems.
REFERENCES
E. Voorhees and D. Harman (1998). “Overview of the Sev-
enth Text REtrieval Conference” In Proc. of the 7th
Text Retrieval Conference (TREC-7) pp. 1–24 .
K. Ng (2000). “Subword-based approaches for Spoken
Document Retrieval” In Ph.D. thesis, Massachusetts
Institute of Technology, Cambridge, MA .
M. A. Siegler, et al. (1997). “Automatic Segmentation,
Classification and Clustering of Broadcast News Au-
dio” In ARPA Speech Recognition Workshop pp. 97–
99.
K. Sp
¨
arck Jones, G. J. F. Jones, J. T. Foote and S. J. Young
(1996). “Experiments in spoken document retrieval”
In Information Processing and Management 32(4):pp.
399-417.
K. Tanaka, et al. (2001). “Speech data retrieval system
constructed on a universal phonetic code domain” In
Proc. of ASRU2001 pp. 1–4.
S. Lee, et al. (2002). “Evaluation of speech data retrieval
system using sub-phonetic sequence” In Proc. of Au-
tumn Meeting of the Acoustical Society of Japan pp.
159–160.
Y. Itoh and K. Tanaka (2001). “Automatic Labeling and Di-
gesting for Lecture Speech Utilizing Repeated Speech
by Shift CDP” In Proc. of EUROSPEECH-2001 pp.
1805-1808.
K. Fukunaga (1990). “Introduction to Statistical Pattern
Recognition” Academic Press
T. Kawahara, et al. (1998). “Sharable software reposi-
tory for Japanese large vocabulary continuous speech
recognition” In Proc. of ICSLP’98 pp. 3527–3260.
The CMU Pronouncing Dictionary (v. 0.6), In
http://www.speech.cs.cmu.edu/cgi-bin/cmudict.
ROBUST SPOKEN DOCUMENT RETRIEVAL BASED ON MULTILINGUAL SUBPHONETIC SEGMENT
RECOGNITION
139
