
EMOTION SYNTHESIS IN VIRTUAL ENVIRONMENTS
Amaryllis Raouzaiou, Kostas Karpouzis and Stefanos Kollias
Image, Video and multimedia Systems Laboratory, National Technical University of Athens,
9, Heroon Politechniou street, 15773, Zographou, Athens, Greece
Keywords: MPEG-4 facial animation, facial expressions, emotion synthesis
Abstract: Man-Machine Interaction (MMI) systems that utilize multimodal information about users' current emotional
state are presently at the forefront of interest of the computer vision and artificial intelligence communities.
Interfaces with human faces expressing emotions may help users feel at home when interacting with a com-
puter because they are accepted as the most expressive means for communicating and recognizing emotions.
Thus, emotion synthesis can enhance the atmosphere of a virtual environment and communicate messages
far more vividly than any textual or speech information. In this paper, we present an abstract means of de-
scription of facial expressions, by utilizing concepts included in the MPEG-4 standard to synthesize expres-
sions using a reduced representation, suitable for networked and lightweight applications.
1 INTRODUCTION
Current information processing and visualization
systems are capable of offering advanced and intui-
tive means of receiving input and communicating
output to their users. As a result, Man-Machine In-
teraction (MMI) systems that utilize multimodal
information about their users' current emotional state
are presently at the forefront of interest of the com-
puter vision and artificial intelligence communities.
Such interfaces give the opportunity to less technol-
ogy-aware individuals, as well as handicapped peo-
ple, to use computers more efficiently and thus over-
come related fears and preconceptions.
Despite the progress in related research, our in-
tuition of what a human expression or emotion actu-
ally represents is still based on trying to mimic the
way the human mind works while making an effort
to recognize such an emotion. This means that even
though image or video input are necessary to this
task, this process cannot come to robust results
without taking into account features like speech,
hand gestures or body pose. These features provide
means to convey messages in a much more expres-
sive and definite manner than wording, which can be
misleading or ambiguous. While a lot of effort has
been invested in examining individually these as-
pects of human expression, recent research (Cowie,
Douglas-Cowie, Tsapatsoulis, Votsis, Kollias, Fel-
lenz & Taylor, 2001) has shown that even this ap-
proach can benefit from taking into account multi-
modal information.
Multiuser environments are an obvious testbed
of emotionally rich MMI systems that utilize results
from both analysis and synthesis notions. Simple
chat applications can be transformed into powerful
chat rooms, where different users interact, with or
without the presence of avatars that take part in this
process, taking into account the perceived expres-
sions of the users. The adoption of token-based ani-
mation in the MPEG-4 framework benefits such
networked applications, since the communication of
simple, symbolic parameters is, in this context,
enough to analyze, as well as synthesize facial ex-
pression, hand gestures and body motion. While
current applications take little advantage from this
technology, research results show that its powerful
features will reach the consumer level in a short pe-
riod of time.
The real world actions of a human can be trans-
ferred into a virtual environment through a represen-
tative (avatar), while the virtual world perceives
these actions and corresponds through respective
system avatars who can express their emotions using
human-like expressions and gestures.
In this paper we describe an approach to synthe-
size expressions via the tools provided in the
MPEG-4 standard (Preda & Preteux, 2002) based on
real measurements and on universally accepted as-
sumptions of their meaning. These assumptions are
44
Raouzaiou A., Karpouzis K. and Kollias S. (2004).
EMOTION SYNTHESIS IN VIRTUAL ENVIRONMENTS.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 44-52
DOI: 10.5220/0002639200440052
Copyright
c
SciTePress

based on established psychological studies, as well
as empirical analysis of actual video footage from
human-computer interaction sessions and human-to-
human dialogues. The results of the synthesis proc-
ess can then be applied to avatars, so as to convey
the communicated messages more vividly than plain
textual information or simply to make interaction
more lifelike.
2 MPEG-4 REPRESENTATION
In the framework of MPEG-4 standard, parameters
have been specified for Face and Body Animation
(FBA) by defining specific Face and Body nodes in
the scene graph. The goal of FBA definition is the
animation of both realistic and cartoonist characters.
Thus, MPEG-4 has defined a large set of parameters
and the user can select subsets of these parameters
according to the application, especially for the body,
for which the animation is much more complex. The
FBA part can be also combined with multimodal
input (e.g. linguistic and paralinguistic speech analy-
sis).
2.1 Facial Animation
MPEG-4 specifies 84 feature points on the neutral
face, which provide spatial reference for FAPs defi-
nition. The FAP set contains two high-level parame-
ters, visemes and expressions. In particular, the Fa-
cial Definition Parameter (FDP) and the Facial Ani-
mation Parameter (FAP) set were designed in the
MPEG-4 framework to allow the definition of a fa-
cial shape and texture, eliminating the need for
specifying the topology of the underlying geometry,
through FDPs, and the animation of faces reproduc-
ing expressions, emotions and speech pronunciation,
through FAPs. By monitoring facial gestures corre-
sponding to FDP and/or FAP movements over time,
it is possible to derive cues about user’s expressions
and emotions. Various results have been presented
regarding classification of archetypal expressions of
faces, mainly based on features or points mainly
extracted from the mouth and eyes areas of the
faces. These results indicate that facial expressions,
possibly combined with gestures and speech, when
the latter is available, provide cues that can be used
to perceive a person’s emotional state.
The second version of the standard, following
the same procedure with the facial definition and
animation (through FDPs and FAPs), describes the
anatomy of the human body with groups of distinct
tokens, eliminating the need to specify the topology
of the underlying geometry. These tokens can then
be mapped to automatically detected measurements
and indications of motion on a video sequence, thus,
they can help to estimate a real motion conveyed by
the subject and, if required, approximate it by means
of a synthetic one.
2.2 Body Animation
In general, an MPEG body is a collection of
nodes. The Body Definition Parameter (BDP) set
provides information about body surface, body
dimensions and texture, while Body Animation
Parameters (BAPs) transform the posture of the
body. BAPs describe the topology of the human
skeleton, taking into consideration joints’ limita-
tions and independent degrees of freedom in the
skeleton model of the different body parts.
2.2.1 BBA (Bone Based Animation)
The MPEG-4 BBA offers a standardized interchange
format extending the MPEG-4 FBA (Preda &
Preteux, 2002). In BBA the skeleton is a hierarchical
structure made of bones. In this hierarchy every
bone has one parent and can have as children other
bones, muscles or 3D objects. For the movement of
every bone we have to define the influence of this
movement to the skin of our model, the movement
of its children and the related inverse kinematics.
3 EMOTION REPRESENTATION
The obvious goal for emotion analysis applications
is to assign category labels that identify emotional
states. However, labels as such are very poor de-
scriptions, especially since humans use a daunting
number of labels to describe emotion. Therefore we
need to incorporate a more transparent, as well as
continuous representation, that matches closely our
conception of what emotions are or, at least, how
they are expressed and perceived.
Activation-emotion space (Whissel, 1989) is a
representation that is both simple and capable of
capturing a wide range of significant issues in emo-
tion. It rests on a simplified treatment of two key
themes:
• Valence: The clearest common element of emo-
tional states is that the person is materially in-
fluenced by feelings that are ‘valenced’, i.e.
they are centrally concerned with positive or
negative evaluations of people or things or
events. The link between emotion and valencing
is widely agreed
• Activation level: Research has recognised that
emotional states involve dispositions to act in
certain ways. A basic way of reflecting that
EMOTION SYNTHESIS IN VIRTUAL ENVIRONMENTS
45
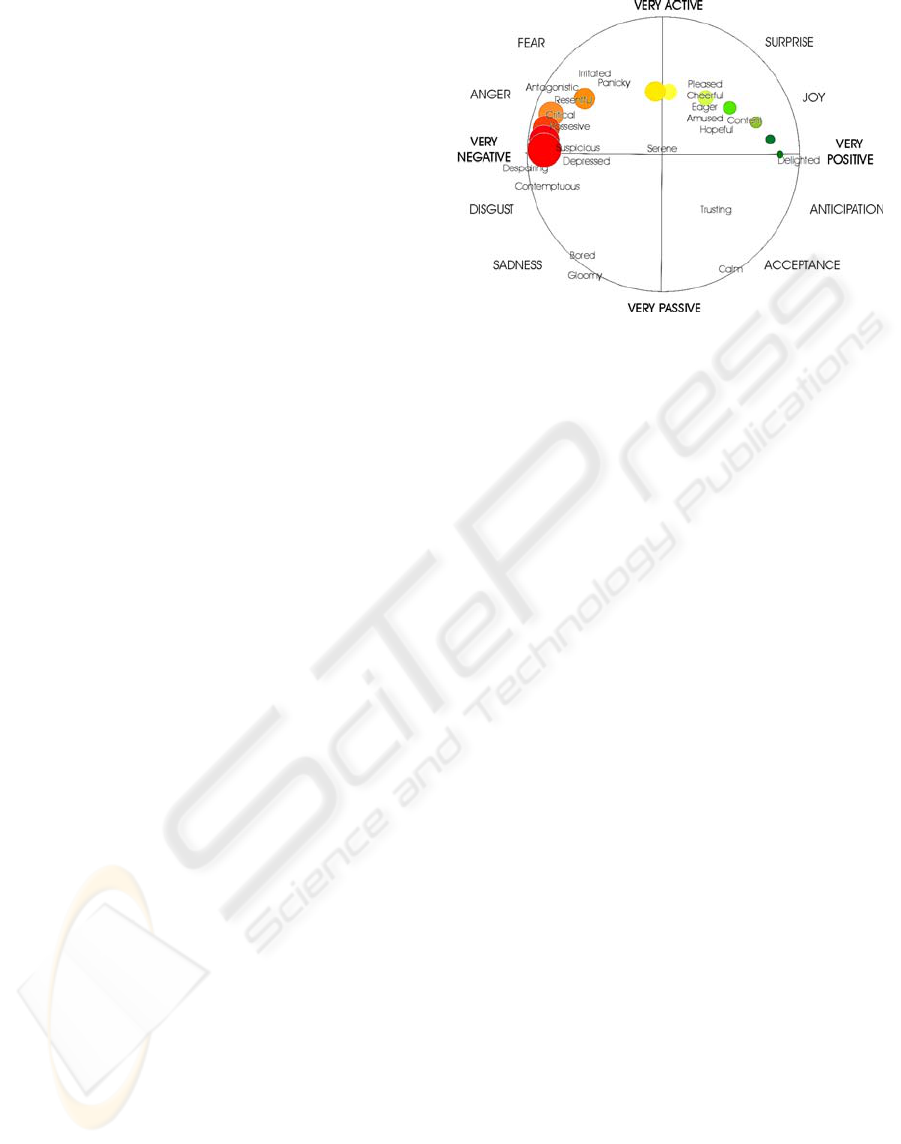
theme turns out to be surprisingly useful. States
are simply rated in terms of the associated acti-
vation level, i.e. the strength of the person’s
disposition to take some action rather than none.
The axes of the activation-evaluation space re-
flect those themes. The vertical axis shows activa-
tion level, the horizontal axis evaluation. A basic
attraction of that arrangement is that it provides a
way of describing emotional states which is more
tractable than using words, but which can be trans-
lated into and out of verbal descriptions. Translation
is possible because emotion-related words can be
understood, at least to a first approximation, as refer-
ring to positions in activation-emotion space. Vari-
ous techniques lead to that conclusion, including
factor analysis, direct scaling, and others (Whissel,
1989).
A surprising amount of emotional discourse can
be captured in terms of activation-emotion space.
Perceived fullblown emotions are not evenly distrib-
uted in activation-emotion space; instead they tend
to form a roughly circular pattern. From that and
related evidence, (Plutchik, 1980) shows that there is
a circular structure inherent in emotionality. In this
framework, identifying the center as a natural origin
has several implications. Emotional strength can be
measured as the distance from the origin to a given
point in activation-evaluation space. The concept of
a full-blown emotion can then be translated roughly
as a state where emotional strength has passed a cer-
tain limit. An interesting implication is that strong
emotions are more sharply distinct from each other
than weaker emotions with the same emotional ori-
entation. A related extension is to think of primary
or basic emotions as cardinal points on the periphery
of an emotion circle. Plutchik has offered a useful
formulation of that idea, the ‘emotion wheel’ (see
Figure 1).
Activation-evaluation space is a surprisingly
powerful device, and it has been increasingly used
in computationally oriented research. However, it
has to be emphasized that representations of that
kind depend on collapsing the structured, high-
dimensional space of possible emotional states
into a homogeneous space of two dimensions.
There is inevitably loss of information; and worse
still, different ways of making the collapse lead to
substantially different results. That is well illus-
trated in the fact that fear and anger are at oppo-
site extremes in Plutchik’s emotion wheel, but
close together in Whissell’s activation/emotion
space. Extreme care is, thus, needed to ensure that
collapsed representations are used consistently.
Figure 1: The Activation-emotion space
4 FACIAL EXPRESSIONS
There is a long history of interest in the problem of
recognizing emotion from facial expressions (Ekman
& Friesen, 1978), and extensive studies on face per-
ception during the last twenty years (Davis & Col-
lege, 1975). The salient issues in emotion recogni-
tion from faces are parallel in some respects to the
issues associated with voices, but divergent in oth-
ers.
As in speech, a long established tradition at-
tempts to define the facial expression of emotion in
terms of qualitative targets, i.e. static positions capa-
ble of being displayed in a still photograph. The still
image usually captures the apex of the expression,
i.e. the instant at which the indicators of emotion are
most marked. More recently emphasis, has switched
towards descriptions that emphasize gestures, i.e.
significant movements of facial features.
In the context of faces, the task has almost al-
ways been to classify examples of archetypal emo-
tions. That may well reflect the influence of Ekman
and his colleagues, who have argued robustly that
the facial expression of emotion is inherently cate-
gorical. More recently, morphing techniques have
been used to probe states that are intermediate be-
tween archetypal expressions. They do reveal effects
that are consistent with a degree of categorical struc-
ture in the domain of facial expression, but they are
not particularly large, and there may be alternative
ways of explaining them – notably by considering
how category terms and facial parameters map onto
activation-evaluation space (Karpouzis, Tsapatsoulis
& Kollias, 2000).
Facial features can be viewed (Cowie et al.,
2001) as either static (such as skin color), or slowly
varying (such as permanent wrinkles), or rapidly
varying (such as raising the eyebrows) with respect
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
46

to time evolution. Detection of the position and
shape of the mouth, eyes, particularly eyelids, wrin-
kles and extraction of features related to them are the
targets of techniques applied to still images of hu-
mans. It has, however, been shown (Bassili, 1979),
that facial expressions can be more accurately rec-
ognized from image sequences, than from a single
still image. His experiments used point-light condi-
tions, i.e. subjects viewed image sequences in which
only white dots on a darkened surface of the face
were visible. Expressions were recognized at above
chance levels when based on image sequences,
whereas only happiness and sadness were recog-
nized at above chance levels when based on still
images. Techniques which attempt to identify facial
gestures for emotional expression characterization
face the problems of locating or extracting the facial
regions or features, computing the spatio-temporal
motion of the face through optical flow estimation,
and introducing geometric or physical muscle mod-
els describing the facial structure or gestures.
In general, facial expressions and emotions are
described by a set of measurements and transforma-
tions that can be considered atomic with respect to
the MPEG-4 standard; in this way, one can describe
both the anatomy of a human face –basically
through FDPs, as well as animation parameters, with
groups of distinct tokens, eliminating the need for
specifying the topology of the underlying geometry.
These tokens can then be mapped to automatically
detected measurements and indications of motion on
a video sequence and, thus, help to approximate a
real expression conveyed by the subject by means of
a synthetic one.
5 GESTURES AND POSTURES
The detection and interpretation of hand gestures has
become an important part of human computer inter-
action (MMI) in recent years (Wu & Huang, 2001).
Sometimes, a simple hand action, such as placing
one’s hands over their ears, can pass on the message
that he has had enough of what he is hearing; this is
conveyed more expressively than with any other
spoken phrase. To benefit from the use of gestures in
MMI it is necessary to provide the means by which
they can be interpreted by computers. The MMI in-
terpretation of gestures requires that dynamic and/or
static configurations of the human hand, arm, and
even other parts of the human body, be measurable
by the machine. First attempts to address this prob-
lem resulted in mechanical devices that directly
measure hand and/or arm joint angles and spatial
position. The so-called glove-based devices best
represent this solutions’ group.
Human hand motion is highly articulate, because
the hand consists of many connected parts that lead
to complex kinematics. At the same time, hand mo-
tion is also highly constrained, which makes it diffi-
cult to model. Usually, the hand can be modeled in
several aspects such as shape (Kuch & Huang,
1995), kinematical structure (Lin, Wu & Huang,
200), dynamics (Quek, 1996), (Wilson & Bobick,
1998) and semantics.
Gesture analysis research follows two different
approaches that work in parallel. The first approach
treats a hand gesture as a two- or three dimensional
signal that is communicated via hand movement
from the part of the user; as a result, the whole
analysis process merely tries to locate and track that
movement, so as to recreate it on an avatar or trans-
late it to specific, predefined input interface, e.g.
raising hands to draw attention or indicate presence
in a virtual classroom.
The low level results of the approach can be ex-
tended, taking into account that hand gestures are a
powerful expressive means. The expected result is to
understand gestural interaction as a higher-level fea-
ture and encapsulate it into an original modal, com-
plementing speech and image analysis in an affec-
tive MMI system (Wexelblat, 1995). This transfor-
mation of a gesture from a time-varying signal into a
symbolic level helps overcome problems such as the
proliferation of available gesture representations or
failure to notice common features in them. In gen-
eral, one can classify hand movements with respect
to their function as:
• Semiotic: these gestures are used to communi-
cate meaningful information or indications
• Ergotic: manipulative gestures that are usually
associated with a particular instrument or job
and
• Epistemic: again related to specific objects, but
also to the reception of tactile feedback.
Semiotic hand gestures are considered to be con-
nected, or even complementary, to speech in order to
convey a concept or emotion. Especially two major
subcategories, namely deictic gestures and beats, i.e.
gestures that consist of two discrete phases, are usu-
ally semantically related to the spoken content and
used to emphasize or clarify it. This relation is also
taken into account in (Kendon, 1988) and provides a
positioning of gestures along a continuous space.
EMOTION SYNTHESIS IN VIRTUAL ENVIRONMENTS
47

6 FROM FEATURES TO
SYMBOLS
6.1 Face
In order to estimate the users' emotional state in a
MMI context, we must first describe the six arche-
typal expressions (joy, sadness, anger, fear, disgust,
surprise) in a symbolic manner, using easily and
robustly estimated tokens. FAPs and BAPs or BBA
representations make good candidates for describing
quantitative facial and hand motion features. The use
of these parameters serves several purposes such as
compatibility of created synthetic sequences with the
MPEG-4 standard and increase of the range of the
described emotions – archetypal expressions occur
rather infrequently and in most cases emotions are
expressed through variation of a few discrete facial
features related with particular FAPs.
Based on elements from psychological studies
(Ekman, 1993), (Parke, 1996), (Faigin, 1990), we
have described the six archetypal expressions using
MPEG-4 FAPs, which is illustrated in Table 1. In
general, these expressions can be uniformly recog-
nized across cultures and are therefore invaluable in
trying to analyze the users' emotional state.
Table 1: FAPs vocabulary for archetypal expression de-
scription
Joy
open_jaw(F
3
), lower_t_midlip(F
4
),
raise_b_midlip(F
5
), stretch_l_cornerlip(F
6
),
stretch_r_cornerlip(F
7
), raise_l_cornerlip(F
12
),
raise_r_cornerlip(F
13
),close_t_l_eyelid(F
19
),
close_t_r_eyelid(F
20
), close_b_l_eyelid(F
21
),
close_b_r_eyelid(F
22
), raise_l_m_eyebrow (F
33
),
raise_r_m_eyebrow(F
34
), lift_l_cheek (F
41
),
lift_r_cheek(F
42
), stretch_l_cornerlip_o (F
53
),
stretch_r_cornerlip_o(F
54
)
Sadness
close_t_l_eyelid(F
19
), close_t_r_eyelid(F
20
),
close_b_l_eyelid(F
21
),close_b_r_eyelid(F
22
),
raise_l_i_eyebrow(F
31
), raise_r_i_eyebrow (F
32
),
raise_l_m_eyebrow(F
33
),
raise_r_m_eyebrow(F
34
), raise_l_o_eyebrow
(F
35
), raise_r_o_eyebrow(F
36
)
Anger
lower_t_midlip(F
4
), raise_b_midlip(F
5
),
p
ush_b_lip(
F
16
), depress_chin(F
18
),
close_t_l_eyelid(F
19
), close_t_r_eyelid(F
20
),
close_b_l_eyelid(F
21
),close_b_r_eyelid(F
22
),
raise_l_i_eyebrow(F
31
), raise_r_i_eyebrow (F
32
),
raise_l_m_eyebrow(F
33
),
raise_r_m_eyebrow(F
34
),raise_l_o_eyebrow
(F
35
), raise_r_o_eyebrow(F
36
),
squeeze_l_eyebrow(F
37
), squeeze_r_eyebrow
(F
38
)
Fear
open_jaw(F
3
), lower_t_midlip(F
4
),
raise_b_midlip(F
5
), lower_t_lip_lm(F
8
),
lower_t_lip_rm(F
9
), raise_b_lip_lm (F
10
),
raise_b_lip_rm(F
11
), close_t_l_eyelid (F
19
),
close_t_r_eyelid(F
20
), close_b_l_eyelid (F
21
),
close_b_r_eyelid(F
22
), raise_l_i_eyebrow (F
31
),
raise_r_i_eyebrow(F
32
),
raise_l_m_eyebrow(F
33
), raise_r_m_eyebrow
(F
34
), raise_l_o_eyebrow(F
35
),
raise_r_o_eyebrow (F
36
), squeeze_l_eyebrow
(F
37
), squeeze_r_eyebrow (F
38
)
Disgust
open_jaw (F
3
), lower_t_midlip (F
4
),
raise_b_midlip (F
5
), lower_t_lip_lm (F
8
),
lower_t_lip_rm (F
9
), raise_b_lip_lm (F
10
),
raise_b_lip_rm (F
11
), close_t_l_eyelid (F
19
),
close_t_r_eyelid (F
20
), close_b_l_eyelid (F
21
),
close_b_r_eyelid(F
22
), raise_l_m_eyebrow (F
33
),
raise_r_m_eyebrow(F
34
), lower_t_lip_lm_o
(F
55
), lower_t_lip_rm_o (F
56
), raise_b_lip_lm_o
(F
57
), raise_b_lip_rm_o (F
58
),
raise_l_cornerlip_o (F
59
), raise_r_cornerlip_o
(F
60
)
Surprise
open_jaw (F
3
), raise_b_midlip (F
5
),
stretch_l_cornerlip (F
6
) , stretch_r_cornerlip
(F
7
), raise_b_lip_lm(F
10
),raise_b_lip_rm(F
11
),
close_t_l_eyelid (F
19
), close_t_r_eyelid (F
20
),
close_b_l_eyelid (F
21
), close_b_r_eyelid (F
22
),
raise_l_i_eyebrow(F
31
), raise_r_i_eyebrow (F
32
),
raise_l_m_eyebrow (F
33
), raise_r_m_eyebrow
(F
34
), raise_l_o_eyebrow (F
35
),
raise_r_o_eyebrow (F
36
), squeeze_l_eyebrow
(F
37
), squeeze_r_eyebrow (F
38
),
stretch_l_cornerlip_o (F
53
),
stretch_r_cornerlip_o (F
54
)
Although FAPs provide all the necessary ele-
ments for MPEG-4 compatible animation, we cannot
use them for the analysis of expressions from video
scenes, due to the absence of a clear quantitative
definition. In order to measure FAPs in real image
sequences, we define a mapping between them and
the movement of specific FDP feature points (FPs),
which correspond to salient points on the human
face. This quantitative description of FAPs provides
the means of bridging the gap between expression
analysis and synthesis. In the expression analysis
case, the non-additive property of the FAPs can be
addressed by a fuzzy rule system.
Quantitative modeling of FAPs is implemented
using the features labeled as f
i
(i=1..15) in Table 2
(Karpouzis, Tsapatsoulis & Kollias, 2000). The fea-
ture set employs feature points that lie in the facial
area and, in the controlled environment of MMI ap-
plications, can be automatically detected and
tracked. It consists of distances, noted as s(x,y),
where x and y correspond to Feature Points (Tekalp
& Ostermann, 2000), between these protuberant
points, some of which are constant during expres-
sions and are used as reference points; distances
between these reference points are used for normali-
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
48

zation purposes (Raouzaiou, Tsapatsoulis, Karpouzis
& Kollias, 2002). The units for f
i
are identical to
those corresponding to FAPs, even in cases where
no one-to-one relation exists.
Table 2: Quantitative FAPs modeling: (1) s(x,y) is the
Euclidean distance between the FPs, (2) D
i-NEUTRAL
refers
to the distance D
i
when the face is its in neutral position
FAP name
Feature for
the descrip-
tion
Utilized feature
Squeeze_l_eyebrow
(F
37
)
D
1
=s(4.5,3.11)
f
1=
D
1-
NEUTRAL
–D
1
Squeeze_r_eyebrow
(F
38
)
D
2
=s(4.6,3.8)
f
2=
D
2-
NEUTRAL
–D
2
L
ower_t_midlip (
F
4
)
D
3
=s(9.3,8.1)
f
3=
D
3
-D
3-
NEUTRAL
R
aise_b_midlip (
F
5
)
D
4
=s(9.3,8.2)
f
4=
D
4-
NEUTRAL
–D
4
R
aise_l_i_eyebrow
(F
31
)
D
5
=s(4.1,3.11)
f
5=
D
5
–D
5-
NEUTRAL
R
aise_r_i_eyebrow
(F
32
)
D
6
=s(4.2,3.8)
f
6=
D
6
–D
6-
NEUTRAL
R
aise_l_o_eyebrow
(F
35
)
D
7
=s(4.5,3.7)
f
7=
D
7
–D
7-
NEUTRAL
R
aise_r_o_eyebrow
(F
36
)
D
8
=s(4.6,3.12)
f
8=
D
8
–D
8-
NEUTRAL
R
aise_l_m_eyebrow
(F
33
)
D
9
=s(4.3,3.7)
f
9=
D
9
–D
9-
NEUTRAL
R
aise_r_m_eyebrow
(F
34
)
D
10
=s(4.4,3.12)
f
10=
D
10
–D
10-
NEUTRAL
Open_jaw (F
3
)
D
11
=s(8.1,8.2)
f
11=
D
11
–D
11-
NEUTRAL
close_t_l_eyelid (F
19
)
–
close_b_l_eyelid
(F
21
)
D
12
=s(3.1,3.3)
f
12=
D
12
–D
12-
NEUTRAL
close_t_r_eyelid
(F
20
) –
close_b_r_eyelid
(F
22
)
D
13
=s(3.2,3.4)
f
13=
D
13
–D
13-
NEUTRAL
stretch_l_cornerlip
(F
6
)
(stretch_l_cornerlip_
o)(F
53
) –
stretch_r_cornerlip
(F
7
)
(stretch_r_cornerlip_
o)(F
54
)
D
14
=s(8.4,8.3)
f
14=
D
14
–D
14-
NEUTRAL
squeeze_l_eyebrow
(F
37
) AND
squeeze_r_eyebrow
(F
38
)
D
15
=s(4.6,4.5)
f
15=
D
15-
NEUTRAL
-D
15
For our experiments on setting the archetypal
expression profiles, we used the face model devel-
oped by the European Project ACTS MoMuSys, be-
ing freely available at the website
http://www.iso.ch/ittf. Table 3 shows examples of
profiles of the archetypal expression fear
(Raouzaiou, Tsapatsoulis, Karpouzis & Kollias,
2002).
Figure 2 shows some examples of animated pro-
files. Fig. 2(a) shows a particular profile for the ar-
chetypal expression anger, while Fig. 2(b) and (c)
show alternative profiles of the same expression.
The difference between them is due to FAP intensi-
ties. Difference in FAP intensities is also shown in
Figures 2(d) and (e), both illustrating the same pro-
file of expression surprise. Finally Figure 2(f) shows
an example of a profile of the expression joy.
Table 3: Profiles for the Archetypal Expression Fear
Profiles FAPs and Range of Variation
Fear (P
F
(0)
)
F
3
∈
[102,480],F
5
∈ [83,353],F
19
∈ [118,37
0], F
20
∈
[121,377],F
21
∈ [118,370],
F
22
∈
[121,377],
F
31
∈
[35,173],F
32
∈ [39,183],
F
33
∈
[14,130], F
34
∈ [15,135]
P
F
(1)
F
3
∈
[400,560],F
5
∈ [333,373],F
19
∈ [-400,-
340],F
20
∈
[-407,-347],F
21
∈ [-400,-
340],F
22
∈
[-407,-347]
P
F
(2)
F
3
∈
[400,560],F
5
∈ [-240,-160],F
19
∈ [-
630,-570],F
20
∈
[-630,-570],F
21
∈ [-630,-
570],F
22
∈
[-630,-
570],F
31
∈
[260,340],F
32
∈ [260,340],F
33
∈
[160,240],F
34
∈
[160,240],F
35
∈ [60,140],F
36
∈
[60,140]
(a) (b) (c)
(d) (e) (f)
Figure 2: Examples of animated profile: (a)-(c) Anger, (d)-
(e) Surprise, (f) Joy
6.1.1 Creating Profiles for Expressions Be-
longing to the Same Universal Emotion
Category
As a general rule, one can define six general catego-
ries, each characterized by an archetypal emotion;
within each of these categories, intermediate expres-
EMOTION SYNTHESIS IN VIRTUAL ENVIRONMENTS
49

sions are described by different emotional intensi-
ties, as well as minor variation in expression details.
From the synthetic point of view, emotions belong-
ing to the same category can be rendered by animat-
ing the same FAPs using different intensities. In the
case of expression profiles, this affect the range of
variation of the corresponding FAPs which is appro-
priately translated; the fuzziness introduced by the
varying scale of FAP intensities provides mildly
differentiated output in similar situations. This en-
sures that the synthesis will not render “robot-like”
animation, but drastically more realistic results.
For example, the emotion group fear also contains
worry and terror (Raouzaiou et al., 2002), synthe-
sized by reducing or increasing the intensities of the
employed FAPs, respectively.
We have created several profiles for the arche-
typal expressions. Every expression profile has been
created by the selection of a set of FAPs coupled
with the appropriate ranges of variation and its ani-
mation produces the selected emotion.
In order to define exact profiles for the arche-
typal expressions, we combine the following steps:
(a) Definition of subsets of candidate FAPs for an
archetypal expression, by translating the facial
features formations proposed by psychological
studies to FAPs,
(b) Fortification of the above definition using varia-
tions in real sequences and,
(c) Animation of the produced profiles to verify
appropriateness of derived representations.
The initial range of variation for the FAPs has
been computed as follows: Let m
i,j
and σ
i,j
be the
mean value and standard deviation of FAP F
j
for the
archetypal expression i (where i={1ÆAnger,
2ÆSadness, 3ÆJoy, 4ÆDisgust, 5ÆFear,
6ÆSurprise}), as estimated in (Raouzaiou et al.,
2002) . The initial range of variation X
i,j
of FAP F
j
for the expression i is defined as:
X
i,j
=[m
i,j
-σ
i,j
, m
i,j
+ σ
i,j
]. (1)
for bi-directional, and
X
i,j
=[max(0, m
i,j
-σ
i,j
), m
i,j
+σ
i,j
] or
Χ
i,j
=[ m
i,j
-σ
i,j
,
min(0, m
i,j
+σ
i,j
)].
(2)
for unidirectional FAPs.
For example, the emotion group fear also con-
tains worry and terror (Raouzaiou et al., 2002)
which can be synthesized by reducing or increasing
the intensities of the employed FAPs, respectively.
Table 4: Created profiles for the emotions terror and worry
Emotion
term
Profile
A
fraid
F
3
∈
[400,560], F
5
∈
[-240,-160], F
19
∈
[-630,-
570], F
20
∈
[-630,-570], F
21
∈[-630,-570],
F
22
∈
[-630,-570],F
31
∈[260,340],
F
32
∈
[260,340], F
33
∈
[160,240],
F
34
∈
[160,240], F
35
∈[60,140], F
36
∈[60,140]
Terrified
F
3
∈
[520,730], F
5
∈
[-310,-210], F
19
∈
[-820,-
740], F
20
∈
[-820,-740], F
21
∈[-820,-740],
F
22
∈
[-820,-740], F
31
∈[340,440],
F
32
∈
[340,440], F
33
∈
[210,310],
F
34
∈
[210,310], F
35
∈[80,180], F
36
∈[80,180]
Worried
F
3
∈
[320,450], F
5
∈
[-190,-130], F
19
∈
[-500,-
450], F
20
∈
[-500,-450], F
21
∈[-500,-450],
F
22
∈
[-500,-450], F
31
∈[210,270],
F
32
∈
[210,270], F
33
∈
[130,190],
F
34
∈
[130,190], F
35
∈[50,110], F
36
∈[50,110]
Table 4 and Figures 3(a)-(c) show the resulting
profiles for the terms terrified and worried emerged
by the one of the profiles of afraid. The FAP values
that we used are the median ones of the correspond-
ing ranges of variation.
(a) (b) (c)
Figure 3: Animated profiles for (a) afraid, (b) terrified (c)
worried
6.2 Gesture Classification
Gestures are utilized to support the outcome of the
facial expression analysis subsystem, since in most
cases they are too ambiguous to indicate a particular
emotion. However, in a given context of interaction,
some gestures are obviously associated with a par-
ticular expression –e.g. hand clapping of high fre-
quency expresses joy, satisfaction- while others can
provide indications for the kind of the emotion ex-
pressed by the user. In particular, quantitative fea-
tures derived from hand tracking, like speed and
amplitude of motion, fortify the position of an ob-
served emotion; for example, satisfaction turns to
joy or even to exhilaration, as the speed and ampli-
tude of clapping increases.
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
50
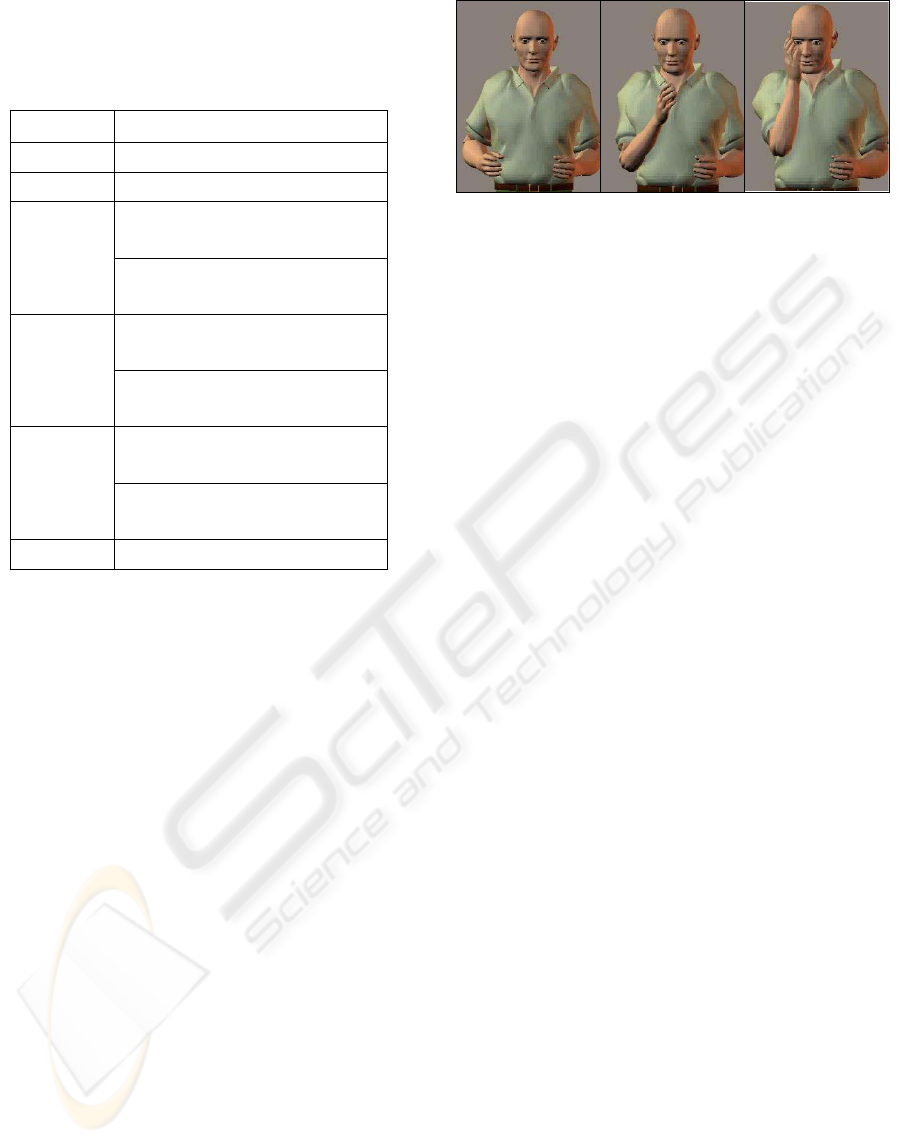
Table 5 shows the correlation between some detect-
able gestures with the six archetypal expressions.
Table 5: Correlation between gestures and emotional
states
Emotion Gesture Class
Joy hand clapping-high frequency
Sadness hands over the head-posture
lift of the hand- high speed
Anger
italianate gestures
hands over the head-gesture
Fear
italianate gestures
lift of the hand- low speed
Disgust
hand clapping-low frequency
Surprise hands over the head-gesture
Given a particular context of interaction, gesture
classes corresponding to the same emotional are
combined in a “logical OR” form. Table 1 shows
that a particular gesture may correspond to more
than one gesture classes carrying different affective
meaning. For example, if the examined gesture is
clapping, detection of high frequency indicates joy,
but a clapping of low frequency may express irony
and can reinforce a possible detection of the facial
expression disgust.
Animation of gestures is realized using the 3D
model of the software package Poser, edition 4 of
CuriousLabs Company. This model has separate
parts for each moving part of the body. The Poser
model interacts with the controls in Poser and has
joints that move realistically, as in real person. Poser
adds joint parameters to each body part. This allows
us to manipulate the figure based on those parame-
ters. We can control the arm, the head, the hand of
the model by filling the appropriate parameters; to
do this a mapping from BAPs to Poser parameters is
necessary. We did this mapping mainly experimen-
tally; the relationship between BAPs and Poser pa-
rameters is more or less straightforward.
Figure 4 shows some frames of the animation
created using the Poser software package for the
gesture “lift of the hand” in the variation which ex-
presses sadness.
(a) (b) (c)
Figure 4: Frames from the animation of the gesture “lift of
the hand”
7 CONCLUSIONS
Expression synthesis is a great means of improving
HCI applications, since it provides a powerful and
universal means of expression and interaction. In
this paper we presented a method of synthesizing
realistic expressions using lightweight representa-
tions. This method employs concepts included in
established standards, such as MPEG-4, which are
widely supported in modern computers and stand-
alone devices.
REFERENCES
Kendon, A, 1988. How gestures can become like words.
In Crosscultural perspectives in nonverbal communi-
cation. Potyatos, F. (ed.). Hogrefe, Toronto, Canada.
Wexelblat, A., 1995. An approach to natural gesture in
virtual environments. In ACM Transactions on Com-
puter-Human Interaction, Vol. 2, iss. 3.
Parke, F., Waters, K., 1996. Computer Facial Animation.
A K Peters.
Quek, F., 1996. Unencumbered gesture interaction. In
IEEE Multimedia, Vol. 3. no. 3.
Faigin, G., 1990. The Artist's Complete Guide to Facial
Expressions. Watson-Guptill, New York.
Lin, J., Wu, Y., Huang, T.S., 2000. Modeling human hand
constraints. In Proc. Workshop on Human Motion.
Bassili, J. N., 1979. Emotion recognition: The role of fa-
cial movement and the relative importance of upper
and lower areas of the face. Journal of Personality and
Social Psychology, 37.
Kuch, J. J., Huang, T. S., 1995. Vision-based hand model-
ing and tracking for virtual teleconferencing and tele-
collaboration. In Proc. IEEE Int. Conf. Computer Vi-
sion.
Karpouzis, K., Tsapatsoulis, N., Kollias, S., 2000. Moving
to Continuous Facial Expression Space using the
MPEG-4 Facial Definition Parameter (FDP) Set. In
EMOTION SYNTHESIS IN VIRTUAL ENVIRONMENTS
51

Electronic Imaging 2000 Conference of SPIE. San
Jose, CA, USA.
Davis, M., College, H., 1975. Recognition of Facial Ex-
pressions. Arno Press, New York.
Preda, M., Prêteux, F., 2002. Advanced animation frame-
work for virtual characters within the MPEG-4 stan-
dard. In Proc. of the International Conference on Im-
age Processing. Rochester, NY.
Tekalp, M., Ostermann, J., 2000. Face and 2-D mesh ani-
mation in MPEG-4.In Image Communication Journal,
Vol.15, Nos. 4-5.
Ekman, P., Friesen, W., 1978. The Facial Action Coding
System. In Consulting Psychologists Press. San Fran-
cisco, CA.
Ekman, P., 1993. Facial expression and Emotion. In Am.
Psychologist, Vol. 48.
Cowie, R., Douglas-Cowie, E., Tsapatsoulis, N., Votsis,
G., Kollias, S., Fellenz, W., Taylor, J., 2001. Emotion
Recognition in Human-Computer Interaction. In IEEE
Signal Processing Magazine.
Plutchik, R., 1980. Emotion: A psychoevolutionary synthe-
sis. Harper and Row New York.
Whissel, C.M., 1989. The dictionary of affect in language.
In Emotion: Theory, research and experience: Vol 4,
The measurement of emotions. Plutchnik, R., Keller-
man, H. (eds). Academic Press, New York.
Wilson, A., Bobick, A., 1998. Recognition and interpreta-
tion of parametric gesture. In Proc. IEEE Int. Conf.
Computer Vision.
Wu, Y., Huang, T.S., 2001.Hand modeling, analysis, and
recognition for vision-based human computer interac-
tion. In IEEE Signal Processing Magazine. Vol. 18,
iss. 3.
Raouzaiou, A., Tsapatsoulis, N., Karpouzis, K., Kollias,
S., 2002. Parameterized facial expression synthesis
based on MPEG-4. In EURASIP Journal on Applied
Signal Processing. Vol. 2002, No. 10. Hindawi Pub-
lishing Corporation.
ICEIS 2004 - HUMAN-COMPUTER INTERACTION
52
