
Face Recognition in Different Subspaces:
A Comparative Study
Borut Batagelj and Franc Solina
University of Ljubljana, Faculty of Computer and Information Science,
Tr
ˇ
za
ˇ
ska 25, SI-1000 Ljubljana, Slovenia
Abstract. Face recognition is one of the most successful applications of image
analysis and understanding and has gained much attention in recent years. Among
many approaches to the problem of face recognition, appearance-based subspace
analysis still gives the most promising results. In this paper we study the three
most popular appearance-based face recognition projection methods (PCA, LDA
and ICA). All methods are tested in equal working conditions regarding pre-
processing and algorithm implementation on the FERET data set with its stan-
dard tests. We also compare the ICA method with its whitening preprocess and
find out that there is no significant difference between them. When we compare
different projection with different metrics we found out that the LDA+COS com-
bination is the most promising for all tasks. The L1 metric gives the best results in
combination with PCA and ICA1, and COS is superior to any other metric when
used with LDA and ICA2. Our results are compared to other studies and some
discrepancies are pointed out.
1 Introduction
As one of the most successful applications of image analysis and understanding, face
recognition has recently received significant attention, especially during the past few
years. The problem of machine recognition of human faces continues to attract re-
searchers from disciplines such as image processing, pattern recognition, neural net-
works, computer vision, computer graphics, computer art [2], and psychology. The
strong need for user-friendly systems that can secure our assets and protect our privacy
without losing our identity in dozens of passwords and PINs is obvious. One of the
advantages of the personal identification system based on analysis of frontal images of
the face regard on other biometric analysis is that it is effective without the participant’s
cooperation or knowledge. A general statement of the problem of machine recognition
of faces can be formulated as follows: given still or video images of a scene, identify
or verify one or more persons in the scene using a stored database of faces. A survey of
face recognition techniques is given in [1].
In general we can divide the face recognition techniques into two groups: geometric
feature-based approach and appearance-based approach. The geometric feature-based
approach uses properties of facial features such as eyes, nose, mouth, chin and there re-
lations for face recognition descriptors. Advantages of this approach include economy
Batagelj B. and Solina F. (2006).
Face Recognition in Different Subspaces: A Comparative Study.
In 6th International Workshop on Pattern Recognition in Information Systems, pages 71-80
DOI: 10.5220/0002500200710080
Copyright
c
SciTePress

and efficiency when achieving data reduction and insensitivity to variations in illumi-
nation and viewpoint. However, facial feature detection and measurements techniques
developed to date are not reliable enough for geometric feature-based recognition. Such
geometric properties alone are inadequate for face recognition because rich information
contained in the facial texture or appearance is discarded. This problem tries to achieve
local appearance-based feature approaches.
On the other hand, the appearance-based approach, such as PCA, LDA and ICA
based methods, has significantly advanced face recognition techniques. Such an ap-
proach generally operates directly on an image-based representation. It extracts features
into a subspace derived from training images. In addition those linear methods can be
extended using nonlinear kernel techniques to deal with nonlinearity in face recogni-
tion. Although the kernel methods may achieve good performance on the training data,
it may not be so for unseen data owing this to their higher flexibility than linear methods
and a possibility of overfitting therefore.
Subspace analysis is done by projecting an image into a lower dimensional space
and after that recognition is performed by measuring the distances between known im-
ages and the image to be recognized. The most challenging part of such a system is
finding an adequate subspace. In the paper three most popular appearance-based sub-
space projection methods will be presented: Principal Component Analysis (PCA), Lin-
ear Discriminant Analysis (LDA), and Independent Component Analysis (ICA). Using
PCA [3], a face subspace is constructed to represent “optimally” only the face object.
Using LDA [4], a discriminant subspace is constructed to distinguish “optimally” faces
of different persons. In comparison with PCA which takes into account only second or-
der statistics to find a subspace, ICA [5] captures both second and higher-order statistics
and projects the input data onto the basis vectors that are as statistically independent as
possible. We made a comparison of those three methods with three different distance
metrics: City block (L1), Euclidean (L2) and Cosine (COS) distance.
For consistency with other studies we used the FERET data set [9], with its stan-
dard gallery images and probe sets for testing. Even though a lot of studies were done
with some of those methods it is very difficult to compare the results with each other
because of different preprocessing, normalization, different metrics and even databases.
Although the researcher used the same database they chose different training sets. We
also noticed that the results of other research groups are often contradictory. In most
cases the results are given only for one or two projection-metric combinations for a
specific projection method, and in some cases researchers are using nonstandard data-
bases or some hybrid test sets derived from standard database. Bartlett et al. [5] and Liu
et al. [10] claim that ICA outperforms PCA, while Beak et al. [11] claim that PCA is bet-
ter. Moghaddam [12] states that there is no significant difference. Beveridge et al. [13]
claim that in their test LDA performed uniformly worse than PCA, Martinez [14] states
that LDA is better for some tasks, and Navarrete et al. [15] claim that LDA outperforms
PCA on all tasks in their tests.
The rest of the paper is organized as follows: Section 2 gives brief description of
the algorithm to be compared, Section 3 reports the details of methodology, Section 4
presents the results and compares our results to results of other research groups and
Section 5 concludes the paper.
72

2 Algorithms
For face recognition and comparison we used well known appearance-based methods:
PCA, LDA and ICA. All three methods reduce the high dimension image space to
smaller dimension subspace which is more appropriate for presentation of the face im-
ages. A two dimensional image X with m rows and n columns can be viewed as a vector
in ℜ
N=m×n
dimensional space. Image comparison is very difficult in such high di-
mension space. Therefore, the methods try to reduce the dimension to lower one while
retaining as much information from the original images as possible. In our case, where
the normalized image of the face has N = 60 × 50 pixels, the image space dimen-
sionality is ℜ
50×60=3000
. With subspace analysis method we reduce this image space
to ℜ
m=403
.
Reduced image space is much lower than original image space (m ≪ N), in spite
of that we retained 98.54% of original information.
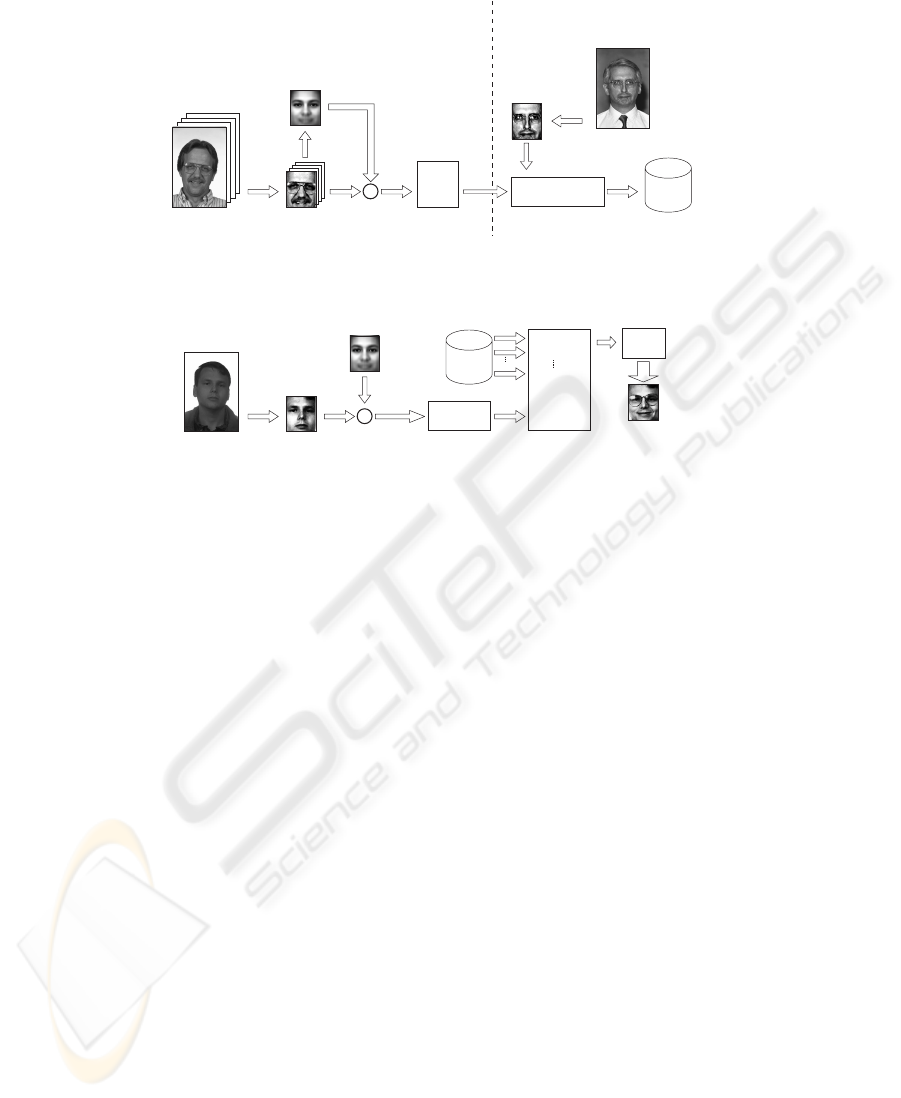
Figure 1a presents a general appearance-based system for face recognition. In the
left part of the figure is the training of the subspace system and in the right is the proce-
dure for projecting gallery images onto subspace with the projection matrix W
T
. Matrix
X containing the images as vectors in its columns, vector x
mean
presenting mean im-
age, matrix
˜
X containing mean-subtracted images in its columns, vector x
g
presenting
image from gallery. During the training phase, the projection matrix W
T
is calculated
which contains the basis vectors of the subspaces. Than the gallery images of known
persons are projected onto subspace. At the end, such presented images are stored in the
database. Later, in the matching phase (Fig. 1b), normalized and mean-subtracted probe
image is projected onto the same subspace as the gallery image was and its projection
is then compared to stored gallery projection. For comparison the nearest neighbor is
determined by calculating the distance from a probe image projection to all gallery im-
ages projections and then choosing the minimal distance as similarity measure. The
most similar gallery image is then chosen to be the result of the recognition and the
unknown probe image is identified.
2.1 Principal Component Analysis (PCA)
The PCA method [3] tends to find such s subspace whose basis vectors correspond to
the maximum variance direction in the original image space. New basis vectors define
a subspace of face images called face space. All images of known faces are projected
onto the face space to find sets of weights that describe the contribution of each vector.
For identification an unknown person, the normalized image of person is first projected
onto face space to obtain its set of weights. Than we compare these weights to sets of
weights of known people from gallery. If the image elements are considered as random
variables, the PCA basis vectors are defined as eigenvectors of scatter matrix S
T
:
S
T
=
M
X
i=1
(x
i
− µ) · (x
i
− µ)
T
, (1)
where µ is the mean of all images in the training set (the mean face, Fig. 1), x
i
is
the i-th image with its columns concatenated in a vector and M is the number of all
73
Training
images
Normalization
Meanimage
-
X
x
mean
X X
~
PCA
LDA
ICA
W
T
TRAININGPHASE
GALLERY PROJECTION
Normalization
galleryimage#1
P =W
x
T
(x-x )
g mean
P
x
x
g
MATCHING HASEP
Probeimage Normalization
-
XX X
~
Meanimage
x
mean
P
x
P
1
P
2
P
G
P =W
x
T
X
~
Distance
calculation
d( ,P)P
x 1
d( ,P)P
x 2
d( ,P )P
x G
d
min( )d
Recognition
result
b)
a)
Stored
gallery
images
DB
Stored
gallery
images
DB
Fig.1. A general subspace appearance-based face recognition system. a) Training images is deter-
mined a subspace and gallery images are projected and stored as prototypes. b) Probe images are
projected to the known subspace and the identification is determined based on minimal distance.
training images. The projection matrix W
P CA
is composed of m eigenvectors corre-
sponding to m eigenvalues of scatter matrix S
T
, thus creating a m-dimensional face
space. Since these eigenvectors (PCA basis vectors) look like some ghostly faces they
were conveniently named eigenfaces.
2.2 Linear Discriminant Analysis (LDA)
LDA method [4] finds the vectors in the underlying space that best discriminate among
classes. For all samples of all classes it defined two matrix: between-class scatter matrix
S
B
and the within-class scatter matrix S
W
. S
B
represents the scatter of features around
the overall mean µ for all face classes and S
W
represents the scatter of features around
the mean of each face class:
S
B
=
c
X
i=1
M
i
· (µ
i
− µ) · (µ
i
− µ)
T
(2)
S
W
=
c
X
i=1
X
x
k
∈X
i
(x
k
− µ
i
) · (x
k
− µ
i
)
T
(3)
where M
i
is the number of training samples in class i, c is the number of dis-
tinct classes, µ
i
is the mean vector of samples belonging to class i and X
i
represents
74

the set of samples belonging to class i with x
k
being the k-th image of that class.
The goal is to maximize S
B
while minimizing S
W
, in other word, maximize the ra-
tio det|S
B
|/det|S
W
|. This ratio is maximized when the column vectors of projection
matrix (W
LDA
) are the eigenvectors of S
−1
W
· S
B
.
To prevent singularity of the matrix S
W
, PCA is used as preprocessing step and the
final transformation is W
opt
= W
P CA
W
LDA
.
2.3 Independent Component Analysis (ICA)
PCA considered image elements as random variables with Gaussian distribution and
minimized second-order statistics. Clearly, for any non-Gaussian distribution, largest
variances would not correspond to PCA basis vectors. ICA [5] minimizes both second-
order and higher-order dependencies in the input data and attempts to find the basis
along which the projected data are statistically independent. For the face recognition
task were proposed two different architectures: Architecture I - has statistically inde-
pendent basis images (ICA I) and Architecture II assumes that the sources are indepen-
dent coefficients (ICA II). These coefficients give the factorial code representation. A
number of algorithm exist; most notable are Jade, InfoMax, and FastICA. Our imple-
mentation of ICA uses the FastICA package [7] for its good performances.
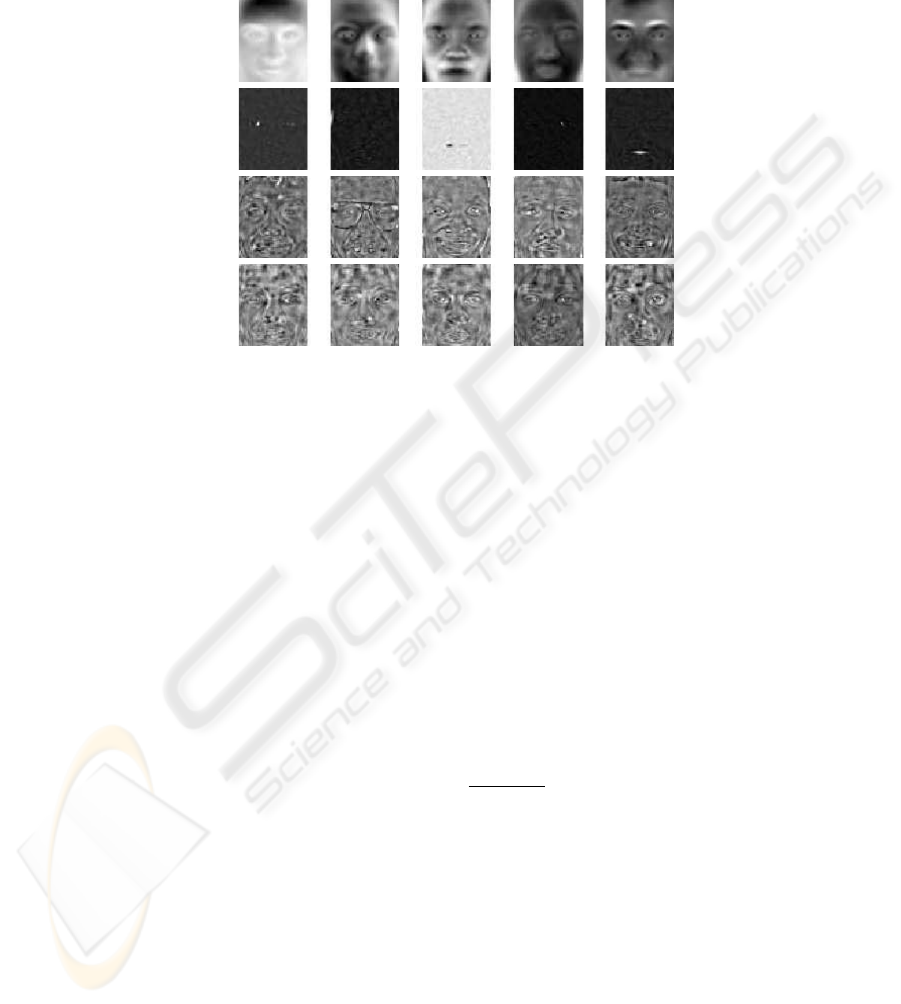
The Architecture I provides a more localized representation for faces, while ICA
Architecture II, like PCA in a sense, provides a more holistic representation (Fig. 2).
ICA I produces spatially localized features that are only influenced by small parts of
an image, thus isolating particular parts of faces. For this reason ICA I is optimal for
recognizing facial actions and suboptimal for recognizing temporal changes in faces
or images taken under different conditions. Preprocessing steps of the methods ICA in-
volves a PCA process by vertically centering (for ICA I), and whitened PCA process by
horizontally centering (for ICA II). So, it is reasonable to use these two PCA algorithms
to revaluate the ICA-based methods [8].
ICA Architecture I includes a PCA by vertically centering (PCA I):
P
v
= X
v
V
T
Λ
−1/2
(4)
where X
v
is the vertically-centered training image column data matrix. Symbols Λ and
V correspond to largest eigenvalues and eigenvectors of S
T
matrix respectively:
S
T
=
M
X
i=1
(x
i
− µ
v
) · (x
i
− µ
v
)
T
, µ
v
=
1
N
N
X
j=1
x
i
(5)
In contrast to standard PCA, PCA I removes the mean of each image while standard
PCA removes the mean image of all training samples.
ICA Architecture II includes a whitened PCA by horizontally centering (PCA II):
P
w
= P
h
· (
1
M
Λ)
−1/2
=
√
MX
h
V Λ
−1
, (6)
where P
h
is the projection matrix of standard PCA method:
P
h
= X
h
V Λ
−1/2
. (7)
75
Matrix X
h
contains in rows horizontally-centered training images. PCA II is actu-
ally the whiten version of standard PCA.
PCA
ICA1
ICA2
LDA
Fig.2. Face representations found by PCA, ICA I, ICA II and LDA methods.
Figure 2 shows first five eigenfaces of PCA, ICA and LDA methods. These images
look like ghostly faces are basis vectors produced by projection methods, reshaped to a
matrix form of the same size as original image.
2.4 Distance Measures
To measure the distance between unknown probe image and gallery images stored
in database (Fig. 1b) three different distance measures will be used. Manhattan (L1),
Euclidean (L2) and Cosine (COS) distance. Generally, for two vectors, x and y dis-
tance measures are defined as:
d
L1
(x, y) = |x − y| (8)
d
L2
(x, y) = kx − yk (9)
d
COS
(x, y) = 1 −
x
T
· y
kxk · kyk
, (10)
where the L2-norm of the vector is denoted as k· k and the L1-norm as | · |.
3 Methodology
3.1 Face Database
For consistency with other studies, we used the standard FERET data set. The FERET
database includes the data partitions (subsets) for recognition tests, as described in [9].
76

The gallery consists of 1196 images, one image per subject and there are four sets
of probe images (fb, fc, dup1 and dup2) that are compared to the gallery images in
recognition stage. The fb probe set contains 1195 images of subjects taken at the same
time as gallery images with different facial expression. The fc probe set contains 194
images of subjects under different illumination conditions. The dup1 set contains 722
images taken anywhere between one minute and 1031 days after the gallery image was
taken, and dup2 set is a subset of dup1 containing 234 images taken at last 18 months
after the gallery image was taken. All images in the data set are size 384×256 and
grayscale.
3.2 Normalization
All algorithms and all image preprocessing were done with Matlab. The standard im-
rotate function was used with bilinear interpolation parameter to get the eyes at fixed
points. Transformation is based upon a ground truth file of eye coordinates supplied
with the original FERET data. All images were than cropped the same way to eliminate
as much background as possible. No masking was done since it turned out that cropping
eliminated enough background. After cropping, images were additionally resized to be
the size of 60×50 using standard imresize function with bilinear interpolation. Finally,
image pixel values were histogram equalized to the range of values from 0 to 255 using
the standard histeq function.
3.3 Training
To train the PCA algorithm we used M =1007 FERET images of c=403 classes (differ-
ent persons). Each class contains a different number of persons. These numbers vary
from 1 to 10. Out of 1007 images in training set, 396 of images are taken from the
gallery (39% of all training images) and 99 images are take from dup1 probe set (10%
of all training images). The remaining 512 are not in any set used for recognition. The
training set and gallery overlap on about 33% and with dup1 probe set on about 14%.
PCA derived, in accordance with theory, M − 1 = 1006 meaningful eigenvectors.
We adopted the FERET recommendation and kept the top 40% of those, resulting in
403-dimensional PCA subspace. In such way 98.54% of original information (energy)
was retained in those 403 eigenvectors. This subspace was used for recognition as PCA
face space and as input to LDA and ICA (PCA was the preprocessing dimensionality
reduction step). For ICA representation we also try to use more eigenvectors but the
performance was worse. We also confirm the findings in [8] that recognition perfor-
mance is not different if we use only preprocessing step of ICA method. In our case
where the dimensionality of ICA representation is the same as the dimensionality of
PCA the performance is the same for L2 and COS metrics and for the L1 metrics the
performance is not much different. Besides of using time consuming ICA methods we
can use only preprocessing whitening step (PCA I instead of ICA I and PCA II instead
of ICA II). Although LDA can produce a maximum of c −1 basis vectors we kept only
403 to make fair comparisons with PCA and ICA methods. After all the subspaces have
been derived, all images from data sets were projected onto subspace and recognition
using neighbor classification with various distance measures was conducted.
77
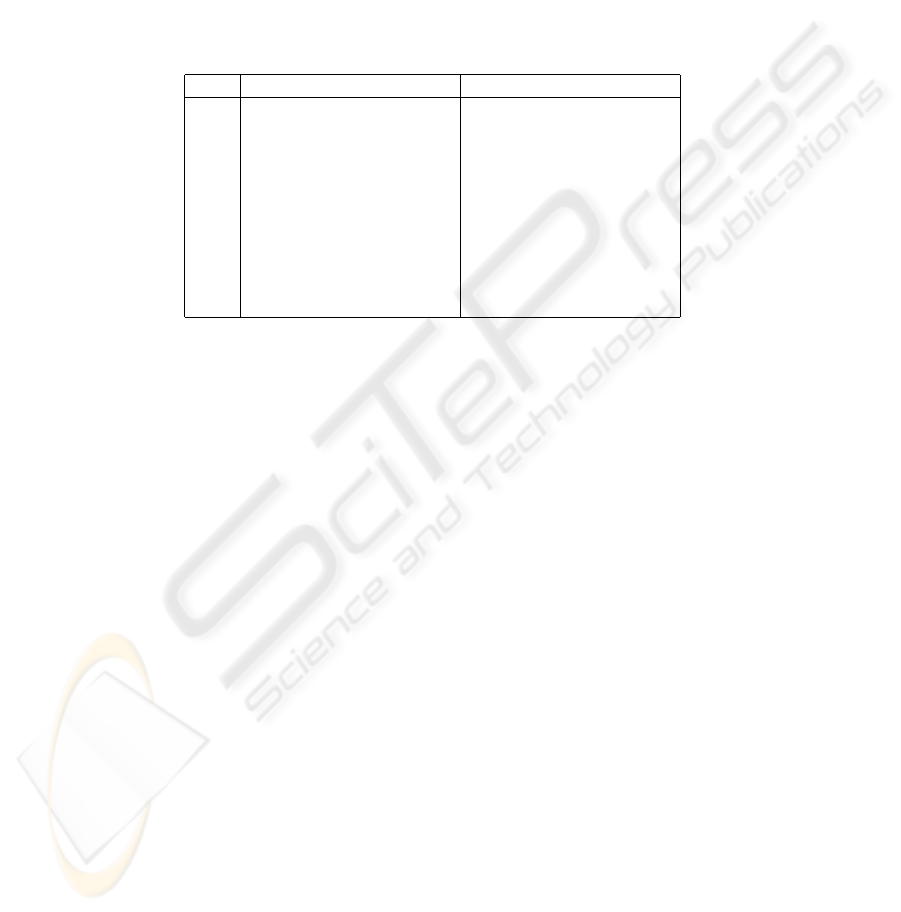
4 Results
Results of our experiment can be seen in Table 1. We test all the projection-metric
combinations. Since we implemented four projection methods (PCA, LDA, ICA1 and
ICA2) and three distance measures (L1, L2 and COS) it can be concluded that we com-
pared 12 different algorithms. The best performance on each data set for each method
is bolded.
Table 1. Performance across four projection methods and three metrics. The best projection-
metric combinations are in bold.
L1 L2 COS L1 L2 COS
fc probe set fb probe set
PCA 88.87% 87.70% 86.78% 54.64% 14.95% 16.49%
LDA 81.42% 83.35% 91.46% 53.61% 54.12% 79.38%
ICA1 91.97% 87.70% 87.36% 23.20% 14.95% 14.43%
ICA2 71.30% 79.00% 89.04% 34.02% 51.03% 78.87%
dup1 probe set dup2 probe set
PCA 42.52% 37.26% 37.95% 20.51% 13.68% 14.10%
LDA 43.21% 47.09% 64.13% 27.35% 35.04% 47.01%
ICA1 41.55% 37.26% 37.53% 15.81% 13.68% 13.68%
ICA2 20.50% 33.52% 47.92% 10.26% 22.65% 30.77%
On the fb (the different expression task) probe set the best combination is ICA1+L1,
but it can be stated that the remaining three projection-metric combinations (LDA+COS,
ICA2+COS and PCA+L1) produce similar results and no straightforward conclusion
can be drawn regarding which is the best for specific task. ICA1 performance was com-
parable to LDA and this confirms the theoretical property of ICA1 that it is optimal for
recognizing facial actions.
On the fc (the different illumination task) probe set LDA+COS and ICA2+COS
win. ICA1 is the worst choice, which is not surprising since ICA1 tends to isolate the
face parts and is therefore not appropriate for recognizing images taken under different
illumination conditions.
On the dup1 and dup2 (the temporal change tasks) probe sets, again LDA+COS
wins and ICA1 is the worst, especially for the dup2 data set. ICA2+COS also did very
good on such difficult tasks.
If we compare the metrics the L1 gives the best results in combination with PCA
and ICA1. It can be concluded that COS is superior to any other metric when used
with LDA and ICA2. We found it surprising that L2 is not the best choice in any of the
combinations, but in the past research it was the most frequently used metric.
Fb probe set was found to be the easiest (highest recognition rates) and dup2 the
most demanding (lower recognition rates), which is consistent with [9], but in contra-
diction with Beak at al. [11] who stated that fc is the most demanding probe set. Also
consistent with [9] is that LDA+COS outperforms all others. Both [9] and [6], when
comparing PCA and ICA, claim that ICA2 outperforms ICA+L2 and this is what we
78

also found. As stated in [5], we also found that ICA2 gives best result when combined
with COS. We also agree with Navarrete et al. [15] that LDA+COS works better than
PCA. We agree with Moghaddam et al. [12] and with Yang et al. [8] who stated that
there is no significant difference between PCA and ICA. We also confirm the result
in [8] that there is no significant performance difference between ICA and preprocess-
ing whitening PCA step.
5 Conclusion
This paper presented an independent, comparative study of three most popular appear-
ance based face recognition projection methods (PCA, LDA and LDA) and their ac-
companied three distance metrics (City block, Euclidean and Cosine) in equal working
conditions. This experimental setup yielded 12 different algorithms to be compared.
From our independent comparative research we can derive that the L2 metric is the
most promising combination for all tasks. Although ICA1+L1 seems to be promising,
except for the illumination changes task where LDA+COS and ICA2+COS outperforms
PCA and ICA1. For all probe sets the COS seems to be the best choice of metric for
LDA and ICA2 and L1 for PCA and ICA1. LDA+COS combination turned out to be the
best choice for temporal changes task. In spite of the fact that L2 metric produced lower
results it is surprising that it was used so often in the past. We also tested only whitened
PCA preprocessing step of ICA method and it confirms that there is no performance
difference between ICA and preprocessing PCA.
References
1. Zhao, W., Chellappa, R., Phillips, P.J., Rosenfeld, A.: Face Recognition: A Literature Survey,
ACM Computing Surveys, (2003) 399–458
2. Solina, F.,Peer, P., Batagelj, B., Juvan, S., Kova
ˇ
c, J.: Color-Based Face Detection in the ”15
Seconds of Fame” Art Installation, International Conference on Computer Vision / Computer
Graphics Collaboration for Model-based Imaging, Rendering, image Analysis and Graphical
special Effects MIRAGE’03, (2003) 38–47
3. Turk, M., Pentland, A.: Eigenfaces for Recognition, Journal of Cognitive Neurosicence, 3(1),
1991, 71–86
4. Zhao, W., Chellappa, R., Krishnaswamy, A.: Discriminant Analysis of Principal Components
for Face Recognition, Proc. of the 3rd IEEE International Conference on Face and Gesture
Recognition, FG’98, (1998) 336
5. Bartlett, M.S., Movellan, J.R., Sejnowski, T.J.: Face Recognition by Independent Component
Analysis, IEEE Trans. on Neural Networks, 13(6), (2002) 1450–1464
6. Draper, B., Baek, K., Bartlett, M.S., Beveridge, J.R.: Recognizing Faces with PCA and ICA,
Computer Vision and Image Understanding (Spacial Issue on Face Recognition), 91(1-2),
(2003) 115–137
7. Hyv
¨
arinen, A., Oja, E.: Independent component analysis: algorithms and aplications. Neural
Networks. 13(4-5) (2000) 411–430
8. Yang, J., Zhang, D., Yang, J.Y.: Is ICA Significantly Better than PCA for Face Recognition?
ICCV. (2005) 198–203
79

9. Phillips, P.J., Moon, H., Rizvi, S.A., Rauss, P.J.: The FERET Evaluation Methodology for
Face-Recognition Algorithms, IEEE Trans. on Pattern Recognition and Machince Intelli-
gence, 22(10), (2000) 1090–1104
10. Liu, C., Wechsler, H.: Comparative Assessment of Independent Component Analysis (ICA)
for Face Rcognition, Second International Conference on Audio- and Video-based Biometric
Person Authentication, (1999) 22–23
11. Baek, K., Draper, B., Beveridge, J.R., She, K.: PCA vs. ICA: A Comparison on the FERET
Data Set, Proc. of the Fourth International Conference on Computer Vision, Pattern Recog-
nition and Image Processing, (8-14), (2002) 824–827
12. Moghaddam, B.: Principal Manifolds and Probabilistic Subspaces for Visual Recognition,
IEEE Trans. on Pattern Analysis and Machine Inteligence, 24(6), 2002 780–788
13. Beveridge, J.R., She, K., Draper, B., Givens, G.H.: A Nonparametric Statistical Comparison
of Principal Component and Linear Discriminant Subspaces for Face Recognition, Proc. of
the IEEE Conference on Computer Vision and Pattern Recognition, (2001) 535–542
14. Martinez, A., Kak, A.: PCA versus LDA, IEEE Trans. on Pattern Analysis and Machine
Inteligence, 23(2), 2001 228–233
15. Navarrete, P., Ruiz-del-Solar, J.: Analysis and Comparison of Eigenspace-Based Face
Recognition Approaches, International Journal of Pattern Recognition and Artificial Intel-
ligence, 16(7), 2002 817–830
80
