
FINDING SUITABLE KEYWORDS FOR A WEB PAGE FROM
CACHES BASED ON SIMILARITY AND FREQUENCY
Yasuhiro Tajima and Yoshiyuki Kotani
Department of Computer and Communication Sciences, Tokyo University of Agriculture and Technology
Naka-chou 2-24-16, Koganei, Tokyo, Japan
Keywords:
Metadata, Bayesian inference, Keyword generation.
Abstract:
Meta data are most important entry in a web page for summarization, indexing, and so on. Unfortunately,
there are many kind of matadata item but there are few guidelines for construct the metadata for a web page.
We propose an metadata finding method for a web page by searching the internet caches and selecting suitable
items for the target page. Our method is based on a bayesian method which is used in the area of text retrieval.
We evaluate this method by an experiment to find a set of suitable keywords for a source web page. Compare-
ing the original metatagged keywords and the system output, we obtain 74% precision and 76% recall. We
can conclude that this method finds the tendency of metadata which is annotated to the pages similar to the
target page.
1 INTRODUCTION
Metadata for a web page is important information and
which is used for summarization, indexing or infor-
mation retrieval. There have been suggested some
guidelines for writing metadata, such as Dublin Core.
These guidelines usually rule the entry types of meta-
data but does not define the content of data and de-
scription manner. In addition, Search Engine Opti-
mization (SEO for short) makes confusion for smart
use of metadata. Thus it tends to be a hard work that
generating useful metadata for a human.
Automatic generation of metadata is one of
the most expected study in the area of seman-
tic web and some studies are exist for metadata
retrieval(Jane Greenberg, 2005)(Jihie Kim, 2006).
In (J¨urgen Belizki, 2006), a metadata assignment
method which is based on usage is proposed. In
(Heiner Stuckenschmidt, 2001), a definition of a
structure of metadata and its generation process is
shown. There are also an application of such auto-
matic metadata generation system(Paynter, 2005) and
a specialized method for the area of image process-
ing(Solomon Atnafu, 2002). However, these stud-
ies are usually based on an extraction method which
takes metadata from the contents of the target file.
Now, a set of keywords for a web page is significant
for indexing and summarizing. But, it is also diffi-
cult because keywords may not be included in the tar-
get web page, thus we can not extract keywords only
from one page data. For keywords metadata, we must
find the suitable one with some background knowl-
edge, because a set of keywords should contain an
abstract word for the subject of the target web page
and also contain a characteristic word to show a dif-
ference from other pages. It should need some in-
ference mechanism from the background knowledge
to make a suitable keywords for a web page. Thus,
finding suitable keywords for a web page is also an
important problem for semantic web.
In this paper, we show a metadata (especially for
keywords)finding method for a web page by selecting
suitable item from cached pages. In our method, the
metadata added in the page which is similar to the
target page will be selected. For an item of metadata,
the probability whether the item is selected or not is
decided by Bayesian method.
We evaluate this method by an experiment to find
a set of suitable keywords for a source web page.
Comparing the original meta tagged keywordsand the
system output, we obtain 74% precision and 76% re-
call. We can conclude that this method finds the ten-
474
Tajima Y. and Kotani Y. (2007).
FINDING SUITABLE KEYWORDS FOR A WEB PAGE FROM CACHES BASED ON SIMILARITY AND FREQUENCY.
In Proceedings of the Third International Conference on Web Information Systems and Technologies - Web Interfaces and Applications, pages 474-477
DOI: 10.5220/0001289204740477
Copyright
c
SciTePress
dency of metadata which is added in the cache pages
which are similar to the target page.
2 OUR METHOD
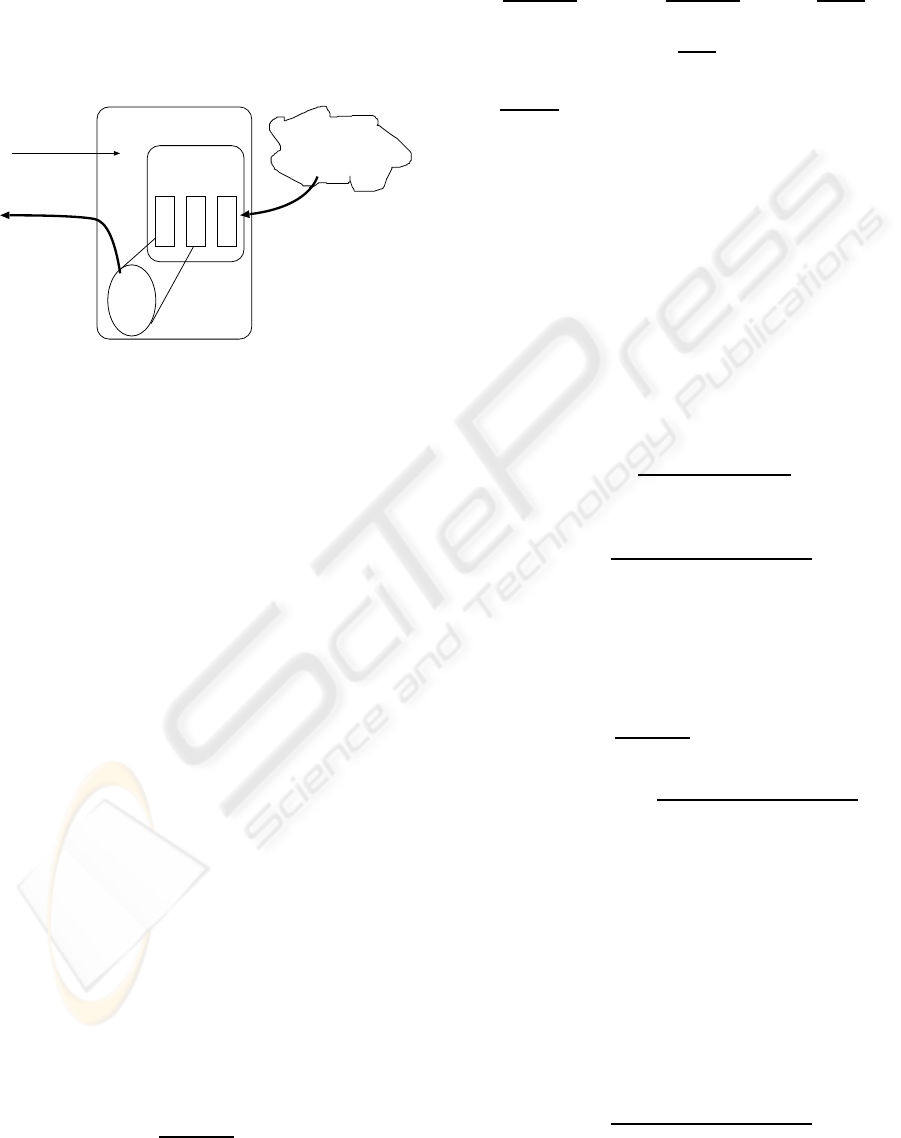
2.1 System Overview
target page
web cache
files
sets of keywords
(WWW)
The Internet
Our system
output (=candidate
of keywords)
w1
w2
.....
c1 c2 c3
gathering pages
randomly with
keywords
¡˚Input¡¸
Figure 1: The overview of our system.
We have made a metadata finding system with our
method. In Fig.1, we show the overview of our sys-
tem. Our system consists of the following elements.
• s is the input target page file. This is the page
which has no metadata and for which our system
selects suitable metadata.
• C is a set of cache pages collected from WWW.
This set C is contains only text data. Images and
other format data will be omitted in our system.
• c ∈ C is a page in the cache.
• K
c
is the set of keywords annotated in the page c.
• W
c
is the set of words which is contained in the
page c.
With these items, metadata for the target page s is
generated by the following steps.
1. Find similarity between the source page s and ev-
ery cache page c ∈ C.
2. Select metadata of c ∈ C based on the similarity.
3. Output the metadata for s.
In the following sections, we describe details of
similarity calculation and selection algorithm.
2.2 Keyword Inference
Assume that W is a candidate set of keywords and let
Z be the event that W is a set of keywords for s. Let
¯
Z be the event that W is not a set of keywords for s.
Now, we consider the following value:
P (Z|W )
P (
¯
Z|W )
. (1)
If we can find a set of words W which maximize (1),
then W is suitable for a set of keywords for s. From
Bayes theorem, we have
log
P (Z|W )
P (
¯
Z|W )
= log
P (W |Z)
P (W |
¯
Z)
+log
P (Z)
P (
¯
Z)
.
Here, the second term log
P (Z)
P (
¯
Z)
has the same value
for any W , thus we only consider the first term
log
P (W |Z)
P (W |
¯
Z)
.
Suppose that the occurrence probability of any
word is identical each other. Then,
P (W |Z) =
Y
u∈W
P (u|Z)
and
P (W |
¯
Z) =
Y
u∈W
P (u|
¯
Z).
Now, the value P (u|Z) can be approximated by the
probability that u is used as a keyword in cache pages
which are similar to s. In addition, P (u|
¯
Z) can be ap-
proximated by the probability that u is not a keyword
but it is contained in the page body of c ∈ C. Then,
P (u|Z) and P (u|
¯
Z) can be written as
P (u|Z) =
P
c∈C,u∈K
c
δ(s, c)
P
c∈C
δ(s, c)
(2)
and
P (u|
¯
Z) =
P
c∈C,u∈W
c
,u6∈K
c
δ(s, c)
P
c∈C
δ(s, c)
. (3)
Here, δ(s, c) is the similarity between the target page
s and a cache page c ∈ C. In this paper, we use the
cos based similarity between s and c.
From these approximation, we can define the
score S(W ) of a word set W as
S(W ) = log
P (W |Z)
P (W |
¯
Z
=
X
u∈W
log
P
c∈C,u∈K
c
δ(s, c)
P
c∈C,u∈W
c
,u6∈K
c
δ(s, c)
!
In Fig.2, we show an example of the above proba-
bility.
2.3 Yet Another Approximation
In equations (2) and (3), we have shown an example
of approximation for P (u|Z) and P (u|
¯
Z). If P (u |
¯
Z)
is approximated by the probability that u is not a key-
word but u is used in the page body among cache
pages each of them contains u, then we can consider
another approximation such that
P (u|
¯
Z) =
P
c∈C,u∈W
c
,u6∈K
c
δ(s, c)
P
c∈C,u∈W
c
δ(s, c)
. (4)
FINDING SUITABLE KEYWORDS FOR A WEB PAGE FROM CACHES BASED ON SIMILARITY AND
FREQUENCY
475

The target page
cache 1
cache 2
cache 3
W
u1
u2
u1
u1
u2
u1
δ1
δ2
δ3
similarity
similarity
similarity
P(u | Z) =
δ1+δ2+δ3
δ1+δ2
δ1 +δ2 + δ3
keywords
keywords
keywords
P(u | Z) =
δ3
Figure 2: The overview of our system.
3 EXPERIMENT
We evaluate our method by an experiment as follows.
cache page number 1886 pages.
Every page in this set can be reachable from
http://www.ipsj.or.jp by following the links. Also,
every page in this set has metadata named
“keywords”. Thus, the crawler for our ex-
periment searches all link paths from the page
http://www.ipsj.or.jp, and takes keyword assigned
pages into the cache set.
test page number 178 pages(set1) and 100
pages(set2).
From this set of pages, a target page is given to the
system as input. The selection of these test set is
random but we take care of variety of sites in the
test set.
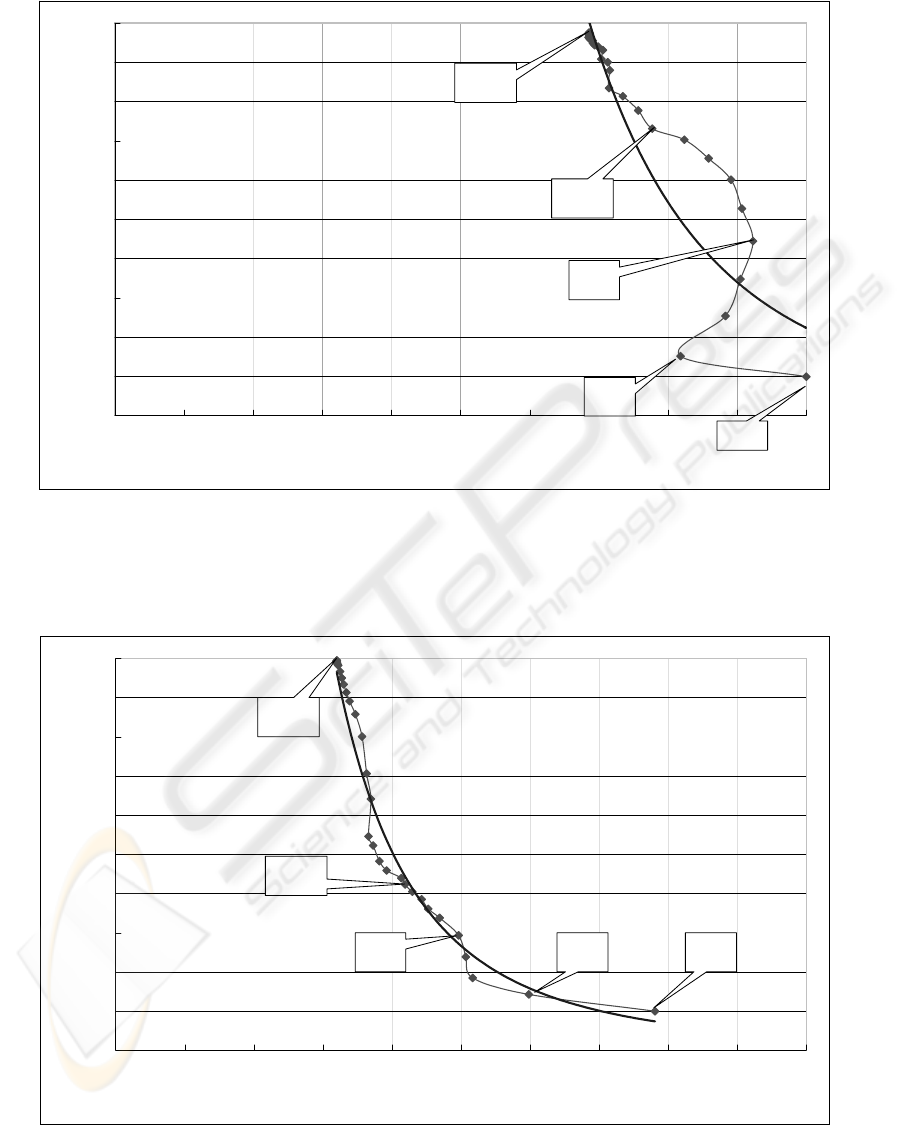
In Fig.3, we show the result of experiment of our
method for the test data (set1). Here, n in these fig-
ures represents the size of words of keyword candi-
date. When n = 1, i.e. the output of our system
contains just one word, then the precision is 1 and the
recall is 0 .1 for this test data. For the test data (set2),
we have obtained that the precision is 0.8 and the re-
call is 0.08 with just one candidate.
The average number of keywords in the set of
cache pages is 10.5 for the test data (set1). When
n = 10, we can see that the precision is 0.78 and
the recall is 0.72 for the test data (set1). On the other
hand, for the test data (set2), we haveobtained that the
precision is 0.21 and the recall is 0.20 when n = 10.
In Fig.4, we showthe result of experiment with the
approximation in equation (4). From these graphs, we
can read that if n = 5, i.e. the output of our system
contains five words, then precision is 0.5 and recall
is 0.3 for test data (set1). For the test data (set2), we
have obtained that the precision is 0.2 and the recall
is 0.1 when n = 5.
In both data set, (set1) or (set2), we can read that
the approximation in the equation (4) is worse than
another approximation.
4 CONCLUSIONS
We have shown a metadata finding method for a web
page by selecting suitable item from web cache. In
the evaluation, the result is 74% precision and 76%
recall with data (set1) and n = 10.
For future works, inference of other metadata
item, “subject” for example, is an interesting prob-
lem.
REFERENCES
Heiner Stuckenschmidt, F. v. H. (2001). Ontology-based
metadata generation from semi-structured informa-
tion. In Proceedings of the First Conference on
Knowledge Capture (K-CAP’01), pages 440–444.
Jane Greenberg, Kristina Spurgin, A. C. (2005). Final re-
port for the amega (automatic metadata generation ap-
plications) project. In University of North Carolina at
Chapel Hill.
Jihie Kim, Yolanda Gil, V. R. (2006). Semantic metadata
generation for large scientific workflows. In Proceed-
ings of the 5th International Semantic Web Conference
2006 (ISWC2006), pages 357–370.
J¨urgen Belizki, Stefania Costache, W. N. (2006). Appli-
cation independent metadata generation. In Proceed-
ings of the 1st international workshop on Contextu-
alized attention metadata: collecting, managing and
exploiting of rich usage information(CAMA06), pages
33–36.
Paynter, G. W. (2005). Developing practical automatic
metadata assignment and evaluation tools for internet
resources. In Proceedings of the 5th ACM/IEEE-CS
joint conference on Digital libraries, pages 291–300.
Solomon Atnafu, Richard Chbeir, L. B. (2002). Effi-
cient content-based and metadata retrieval in image
database. In Journal of Universal Computer Science,
volume 8, pages 613–622.
WEBIST 2007 - International Conference on Web Information Systems and Technologies
476
㫐㩷㪔㩷㪇㪅㪉㪉㪊㪉㫏
㪄㪊㪅㪐㪏㪐㪋
㪩
㪉
㩷㪔㩷㪇㪅㪍㪌㪐㪋
㪇
㪇㪅㪈
㪇㪅㪉
㪇㪅㪊
㪇㪅㪋
㪇㪅㪌
㪇㪅㪍
㪇㪅㪎
㪇㪅㪏
㪇㪅㪐
㪈
㪇 㪇㪅㪈 㪇㪅㪉 㪇㪅㪊 㪇㪅㪋 㪇㪅㪌 㪇㪅㪍 㪇㪅㪎 㪇㪅㪏 㪇㪅㪐 㪈
㫇㫉㪼㪺㫀㫊㫀㫆㫅
㫉㪼㪺㪸㫃㫃
㫅㪔㪈
㫅㪔㪉
㫅㪔㪌
㫅㪔㪈㪇
㫅㪔㪊㪇
Figure 3: The result of experiment with (set1).
㫐㩷㪔㩷㪇㪅㪇㪊㪍㪈㫏
㪄㪉㪅㪏㪏㪊㪐
㪩
㪉
㩷㪔㩷㪇㪅㪐㪍㪎㪐
㪇
㪇㪅㪈
㪇㪅㪉
㪇㪅㪊
㪇㪅㪋
㪇㪅㪌
㪇㪅㪍
㪇㪅㪎
㪇㪅㪏
㪇㪅㪐
㪈
㪇 㪇㪅㪈 㪇㪅㪉 㪇㪅㪊 㪇㪅㪋 㪇㪅㪌 㪇㪅㪍 㪇㪅㪎 㪇㪅㪏 㪇㪅㪐 㪈
㫇㫉㪼㪺㫀㫊㫀㫆㫅
㫉㪼㪺㪸㫃㫃
㫅㪔㪈㫅㪔㪉㫅㪔㪌
㫅㪔㪈㪇
㫅㪔㪊㪇
Figure 4: The result of (set1), another approximation.
FINDING SUITABLE KEYWORDS FOR A WEB PAGE FROM CACHES BASED ON SIMILARITY AND
FREQUENCY
477
