
QUALITY-BASED IMPROVEMENT OF QUANTIZATION FOR
LIGHT FIELD COMPRESSION
Raphael Lerbour, Bruno Mercier, Daniel Meneveaux and Chaker Larabi
SIC Laboratory, University of Poitiers
Bat. SP2MI, Teleport 2, Bvd Marie et Pierre Curie, BP 30179 86962 Futuroscope Chasseneuil Cedex, France
Keywords: Image-based rendering, light field, compression, subjective assessment.
Abstract: In the last decade, many methods have been proposed for rendering image-based objects. However, the number
and the size of the images required are highly memory demanding. Based on the light field data structure, we
propose an improved compression scheme favoring visual appearance and fast random access. Our method
relies on vector quantization for preserving access in constant time. 2D Bounding boxes and masks are used to
reduce the number of vectors during quantization. Several light field images are used instead of blocks of 4D
samples, so that image similarities be exploited as much as possible. Psychophysical experiments performed
in a room designed according to ITU recommendations validate the quality metrics of our method.
1 INTRODUCTION
Image-based rendering methods offer an attractive
mean for realistically rendering and/or relighting real-
life objects, with potentially complex shape and re-
flectance properties. In many cases, modeling objects
from our real world is unpractical, not only because of
shape that is difficult to reproduce, but also due to re-
flectance properties that should also be modeled and
rendered, with subsurface scattering, anisotropy and
so on.
With image-based rendering methods, object
complexity is postponed to image complexity. Fur-
thermore, in some cases, rendering time is constant.
This is one important reason why this representation
has been a method of choice for several years.
However, these methods suffer from various draw-
backs such as the high number of images required, the
lack of precision when the observer is close to the ob-
ject, or the (blurred) discontinuities appearing on the
rendered images.
This paper addresses the problem of compression
for light fields (or lumigraphs) interactive rendering
(Levoy and Hanrahan, 1996; Gortler et al., 1996).
Even though compression is necessary for reducing
the size of data for generating images, both visual
quality and rendering time have to be taken into ac-
count (Figure 1).
Several methods have been applied for compress-
ing data related to light fields (Ramanathan et al.,
2003; Chang et al., 2003; Li et al., 2001; Magnor
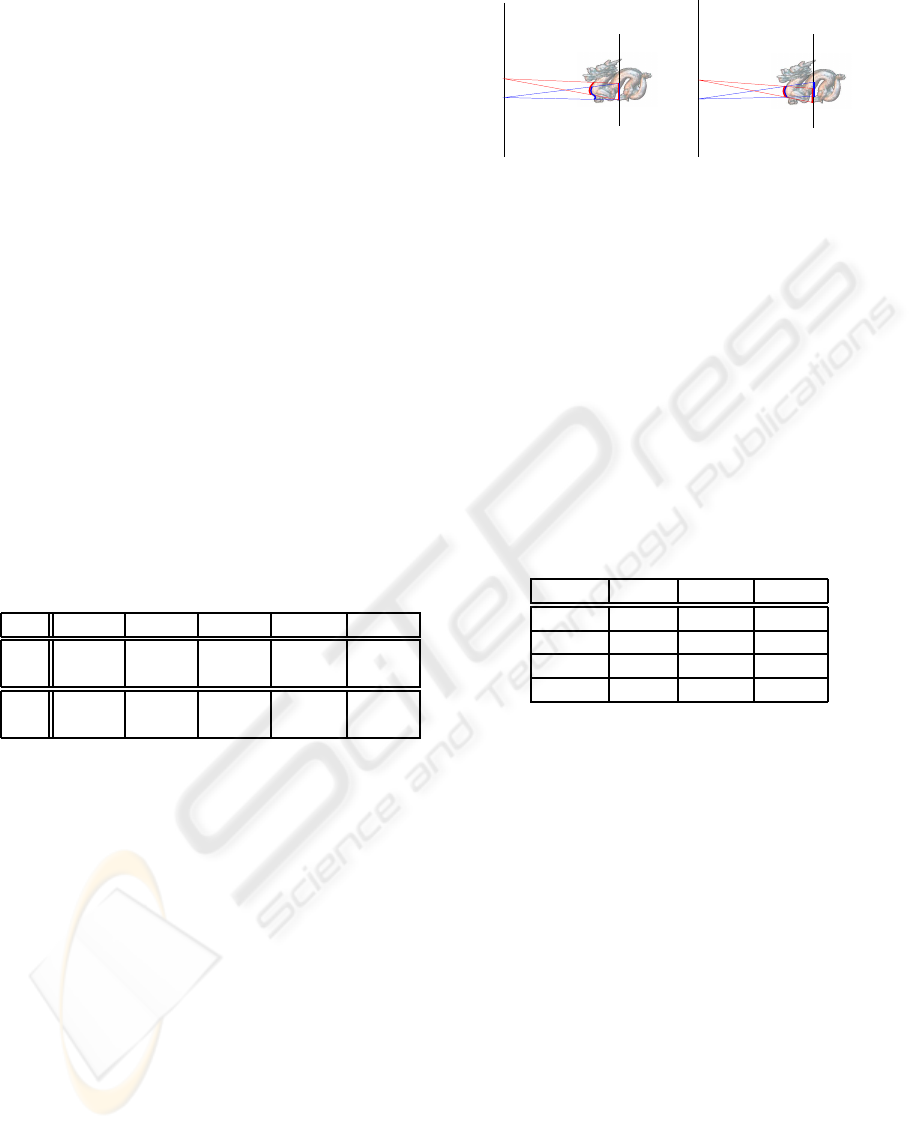
Figure 1: Images from compressed light fields. (a) ref-
erence image; (b) original 4D compression scheme from
(Levoy and Hanrahan, 1996); (c) our method. GPU imple-
mentation allows the rendering of 20 light fields at between
25 to 65 frames per second.
et al., 2003; Girod et al., 2003). The original work
described in (Levoy and Hanrahan, 1996) presents a
compression method based on the 4D structure. In
the literature, high compression rates can only be
achieved at the expense of image quality or with a
loss of random access. In addition, object contours
are subject to artifacts (see Figure 1.b).
In this paper, we propose to adapt vector quantiza-
tion for light field rendering so as to perform well in
235
Lerbour R., Mercier B., Meneveaux D. and Larabi C. (2007).
QUALITY-BASED IMPROVEMENT OF QUANTIZATION FOR LIGHT FIELD COMPRESSION.
In Proceedings of the Second International Conference on Computer Graphics Theory and Applications - GM/R, pages 235-243
DOI: 10.5220/0002078802350243
Copyright
c
SciTePress

every way of these. Our method relies in the 2D space
of images and highly benefits from inter-image simi-
larities when viewpoints are close. Our contributions
include: (i) the use of object masks for reducing the
compression areas and preserving the object contours;
(ii) the combination of images for improving vector
quantization in terms of visual appearance and com-
pression rates; (iii) the validation of our compression
scheme using a PSNR (Peak Signal to Noise Ratio)
metric validated by a psychophysical study quantify-
ing its correlation with human judgment.
This paper is organized as follows: Section 2
presents the work related to our paper; Section 3
presents the broad lines of our method; Section 4 sum-
marizes the vector quantization method we use; Sec-
tion 5 discusses light field compression using quanti-
zation; Section 6 shows how object silhouette can ef-
ficiently be used for improving quantization; Section
7 presents our quality assessment system; Section 8
gives implementation details; Section 9 provides re-
sults; Section 10 concludes and proposes future work.
2 RELATED WORK
2.1 Light Field Data Structure
Light fields (or lumigraphs) correspond to a 4D sam-
pling of the plenoptic function defined in (Adelson
and Bergen, 1991) by Adelson and Bergen. They are
defined by a set of slabs. Each slab is a pair of parallel
planes uv and st uniformly sampled (Levoy and Han-
rahan, 1996; Gortler et al., 1996). Figure 2 illustrates
the light field representation.
2.2 Light Field Compression
In the original work proposed in (Levoy and Han-
rahan, 1996), light field compression is achieved
through vector quantization. Instead of using 2D vec-
tors on the images, the authors compress 4D vectors
corresponding to 2D samples on the uv plane com-
bined with 2D samples on the st plane. The aim is to
benefit from the similarity existing between two close
viewpoints.
In (Tong and Gray, 2000), prediction is used for
recovering images and achieving high compression
rates. In (Zhang and Li, 2000), compression makes
use of prediction on intermediate images for concen-
tric mosaics. Principal component analysis (Lelescu
and Bossen, 2004), 2D shape encoding (Girod et al.,
2003) or wavelet coders (Wei, 1997; Li et al., 2001)
can also advantageously be exploited for increasing
compression rates.
Slab (s,t)
(a) Slab (u,v)
s
u
v
t
Real object
Real object
Slab (s,t)
(b) Slab (u,v)
Figure 2: Light field representation. (a) an image corre-
sponds to one uv sample associated with the whole st plane;
(b) conversely, one st sample associated with all the uv
directions provides radiance samples passing through the
point located in (s,t).
Several authors address perceptual image qual-
ity with image-based rendering compression meth-
ods without quantization (Ramanathan et al., 2001;
Magnor and Girod, 2000; Magnor et al., 2003;
Magnor and Girod, 1999; Zhang and Li, 2000). For
instance in (Magnor and Girod, 2000), the authors
propose two methods dedicated to light field com-
pression. The first one relies on DCT-based video
compression while the second one relies on disparity-
compensated image prediction. The compression
rates achieved are very high (from 100:1 to 2000:1).
Nevertheless, as pointed out in (Heidrich et al.,
1999; Levoy and Hanrahan, 1996) vector quantiza-
tion is more practical for graphics hardware imple-
mentation since decompression can be achieved by
the GPU.
Geometry has also been used for improving ob-
ject appearance and reducing the image-based infor-
mation size (Magnor et al., 2003; Chang et al., 2003).
However, some reconstruction process is required.
This paper rather addresses light fields compression
without geometry reconstruction.
3 WORK OVERVIEW
Our compression scheme is based on vector quantiza-
tion. Instead of using vectors in the 4D space of light
fields, we propose to exploit image similarities using
several images with 2D vectors. As shown in the re-
sults, the visual quality is greatly improved, with a
high compression rate.
GRAPP 2007 - International Conference on Computer Graphics Theory and Applications
236

Most light fields represent 3D objects in front of a
neutral background (uniformly black by convention).
In this paper, we focus on that type of light field and
take advantage of it: pixels corresponding to the back-
ground are ignored using 2D bounding boxes on the
images and a binary mask matching the object silhou-
ette. This is used for: (i) avoiding the compression
of groups of background pixels and (ii) providing a
better representation for PSNR computations.
In order to validate the use of PSNR which is often
considered as uncorrelated to human judgment, we
have designed and conducted a psychophysical exper-
iment. After a correlation study, we have been able to
link the PSNR to the MOS (Mean Opinion Score) so
as to extract a quality threshold.
We have applied our compression method on a set
of virtual and real objects, with various reflectances,
textures and sizes. Our method proves fast and effi-
cient for compressing light field images and render-
ing them in real-time directly from their compressed
form.
A LZ scheme can further reduce the light field
sizes on the disk (for instance when a light field has
to be transmitted though a computer network).
4 VECTOR QUANTIZATION
Even with loss, vector quantization is a method of
choice for reducing image sizes. However, visual ar-
tifacts should be unnoticeable for quality light field
rendering.
The aim of vector quantization is to replace a
(high) number of vectors by a set of indexes referenc-
ing a reduced set of representatives (the dictionary).
The size required for each index depends on the num-
ber of vectors contained in the dictionary.
Several methods have been proposed for the dic-
tionary construction. Most of them provide compa-
rable results in terms of compression rates. We have
chosen the LBG method (Linde et al., 1980) since the
dictionary size is a power of two. This is convenient
for storing data in the memory as explained in Sec-
tion 8. Moreover, the dictionary size can be automat-
ically chosen depending on a measured quality value
(the PSNR in our case). The dictionary refinement is
based on a generalized Lloyd iteration (Lloyd, 1982).
We have tried various color spaces (RGB, CIE
Luv, CIE Lab, LCh). In all the tests we made for light
field compression, the quadratic RGB distance associ-
ated with a PSNR quality measurement provided the
best results.
5 LIGHT FIELD COMPRESSION
Figure 3 and Table 1 present the light fields used in
this paper, including real and virtual objects. The Sun-
flower is a real object as well as the Clown. The Quad
is a virtual object, rendered with POV-ray. Buddha
and Dragon are provided by Stanford University.
Figure 3: Images of light fields used for our tests: (a) Sun-
flower, (b) Clown, (c) Quad, (d) Buddha, (e) Dragon.
Table 1: Light fields characteristics. Sl. is the number of
slabs; (u, v) and (s, t) represent the number of samples on
the uv and st planes; m.size corresponds to the memory re-
quired for storing the whole light field without compression
(given in MB).
LF Sl (u, v) (s,t) m.size
Sunflower 4 8× 8 256× 256 48
Clown 5 8× 8 256× 256 60
Quad 6 8× 8 256× 256 72
Buddha 1 32× 32 256× 256 192
Dragon 1 32× 32 256× 256 192
5.1 Images (2D Vectors)
On one hand, it is possible to compress every light
field image independently. Thus, one dictionary is
necessary for each image. However in this case, com-
pression rates do not benefit from images similarity
when viewpoints are close. Moreover, since dictio-
naries are separated, as many dictionaries as images
are necessary in the memory during rendering.
On the other hand, only one dictionary for all the
images of a light field is not more attractive since all
the viewpoints show various portions of the object,
QUALITY-BASED IMPROVEMENT OF QUANTIZATION FOR LIGHT FIELD COMPRESSION
237
with varying lighting conditions and potentially vary-
ing reflectance properties. Therefore, a single dictio-
nary clamps many important noticeable tints. This
method is thus inappropriate for coding shading re-
finements.
5.2 Uvst Blocks (4D Vectors)
Another solution consists in exploiting the whole light
field coherence. This is why the authors of (Levoy
and Hanrahan, 1996) propose a compression scheme
based on 4D uvst blocks. With this approach, a 2 ×
2× 2× 2 uvst vector corresponds to 4 blocks of 2× 2
pixels in 2× 2 uv sample images in the same slab.
Increasing the vector size also requires to increase
the dictionary size. Furthermore, the vectors in this
dictionary are also larger. This is why a single dictio-
nary should be used for the whole light field with 4D
vectors.
Table 2: Comparison of compression methods: 4D quanti-
zation vs. 2D quantization. Two light fields (LF) are used:
1- the Sunflower. and 2- the Buddha. v.type indicates the
type of vectors used for quantization; d.size is the dictio-
nary size; c.time provides the computing time; m.size is the
memory size (in KB) with compression. The given PSNR
corresponds to a mean over the compressed images.
LF v.type d.size c.time m.size PSNR
1 4D 16384 2h 1173 30.63
2D 256 40s 916 30.70
2 4D 16384 7h 2598 33.43
2D 256 3m 4104 32.72
The results provided in Table 2 show that larger
vectors and unique dictionary for all the slabs imply
higher compression time. As stated in (Levoy and
Hanrahan, 1996), the approach using 4D vectors re-
mains interesting only when the uv plane is densely
sampled. However, increasing the sampling density
also increases the light field size whatever the com-
pression scheme used. Both these affirmations can be
verified in this example (Buddha is 16 times denser
than Sunflower).
5.3 Slab Images
As shown in Figure 4.a, a block of pixels on the st
plane does generally not correspond to the same re-
gion of the object for 2×2 uv samples. This produces
artifacts when using 4D vectors. On the other hand,
2D st vectors can be associated with one region of
the object for more distant viewpoints, thus increas-
ing image quality with a smaller dictionary.
uv plane
st plane
st plane
uv plane
(a) (b)
Figure 4: (a) A 2× 2× 2× 2 block of uvst does not cover
the same region of the object; (b) With 2 × 2 blocks of st
samples, it is possible to associate pixels corresponding to
the same region of the object for several viewpoints.
This is the reason why we have associated one dic-
tionary for groups of several uv images in each slab.
This method better benefits from image similarities
for both uv and st planes.
Table 3: Comparison of number of dictionaries per slab for
the Sunflower. light field. d.size corresponds to the dictio-
nary size while m.size indicates the size required in memory
(in KB). The given PSNR (in dB) corresponds to a mean
on the compressed images (background pixels are not taken
into account).
# Dict. d.size m.size PSNR
64 128 1144 30.8
16 256 1060 31.8
4 512 1073 32.6
1 1024 1133 33.3
As shown in Table 3, reducing the number of dic-
tionaries for each slab allows to increase the dictio-
nary size (and thus the image quality) while keeping
a similar overall memory size. Nevertheless, we have
noticed that the loss in visual quality is not worth the
benefit in memory space when the number of dictio-
naries is too low (with fixed dictionary size). Addi-
tionally, we show in Section 9 that the number of dic-
tionaries should remain high enough for ensuring a
homogeneous quality over the whole light field. In
practice, the best compromise has generally been ob-
tained with 4 dictionaries per slab, corresponding to 4
regions of uv images subdividing the slab.
6 OBJECT SILHOUETTE
Background pixels in the images do not correspond to
any information. Quantifying these pixels increases
the computing time, the dictionary size and con-
tributes to the impairment of visual quality through
aliasing on the object contour. This is why we pro-
pose to only take into account pixels corresponding
GRAPP 2007 - International Conference on Computer Graphics Theory and Applications
238

to the object in our quantization method.
6.1 Silhouette Bounding Box
In most light fields, the st plane is placed so that the
object be located at the center of the images. We
first associate a 2D bounding box enclosing the object
with each image. All the pixels outside the box are not
considered during the quantization process; they are
not even stored in the memory. In practice, depend-
ing on light fields, between 40% and 80% of vectors
are ignored during encoding.
6.2 Silhouette Mask
Inside each bounding box (for each uv image), a bi-
nary mask indicates whether a pixel corresponds to
the object or to the background. It is RLE-encoded
on the disk, and stored uncompressed in the memory
for rendering performance reasons.
Table 4: Mask size in the memory for each light field and
benefit compared to compression without bounding boxes
nor masks. Dictionaries contain 256 vectors.
Light Field Mask size (KB) Benefit
Sunflower 430 67.1%
Clown 704 57.4%
Quad 1510 24.8%
Buddha 2031 62.6%
Dragon 4779 12.1%
As shown in Table 4, even though bounding boxes
and masks have to be stored in the memory, compres-
sion rates are higher than pure 2D compression with
equal PSNR. Last but not least, object silhouettes are
accurately preserved.
7 QUALITY ASSESSMENT
Quality assessment addresses several types of appli-
cations such as medical imaging, image and video
compression, etc. The assessment can be subjective
involving human judgment, objective implying the
use of mathematical tools, or both (Keelan, 2002).
Formal subjective testing has been used for many
years with a relatively stable set of standard methods
described in the ITU recommendation (ITU-R Rec-
ommendation BT.500-10, 2000).
Objective quality assessment offers several types
of measures or metrics. Simple metrics such as PSNR
are very easy to compute and are appropriate for real-
time assessment but they may not correlate with hu-
man judgment. Other measures are based on the Hu-
man Visual System (HVS) modeling which allows a
good correlation but are often difficult to implement.
Because subjective experiments are complicated
to manage and time consuming, they are difficult to
repeat. To ensure repeatability, the correlation exist-
ing between the opinion score (subjective) and the re-
sults of mathematical metrics (objective) is studied.
In the case of a good correlation (greater than 70%),
it is possible to use the metric and to extrapolate the
results for human judgement.
In existing light field works, compression bit-rate
(i.e. size of dictionaries) is chosen only with regards
to the used memory while the PSNR is used for final
quality assessment. In our approach, bit-rate is reg-
ulated by a quality criterion (see Section 8). During
quantization, the dictionary is iteratively constructed.
At every step, the quality associated to the dictionary
is measured and compared to a threshold. If it exceeds
the threshold, the algorithm stops. Otherwise, a new
step starts with an increased dictionary size.
7.1 Evaluations Conditions
In the framework of psychophysical assessment, we
have verified that the observer has a normal visual
acuity and no color blindness. Our psychophysical
test room conforms to ITU recommendations (ITU-R
Recommendation BT.500-10, 2000) (Figure 5.a):
• an adjustable and directional lighting with a tem-
perature between 5000K and 6500K delivering
25 lux on the display because of the black back-
ground;
• a calibrated display with a resolution of 800×600
pixels to display 256× 256 images;
• a non reflective wall painting;
• an adapted viewing distance: 75 cm.
7.2 Assessment Protocol
The duration of a subjective experiment is around 15
minutes. It should not exceed 30 min because of the
observer fatigue. The test protocol is composed of 5
different light fields where only 3 images have been
chosen for their specific content. 4 couples of suc-
cessive dictionary sizes are confronted for each view,
from 128 vs. 256 to 1024 vs. 2048, defining 60 tests
(5×3×4). The original image is displayed on the top
in order to have a reference of quality. A snapshot of
the protocol is given in Figure 5.b.
QUALITY-BASED IMPROVEMENT OF QUANTIZATION FOR LIGHT FIELD COMPRESSION
239
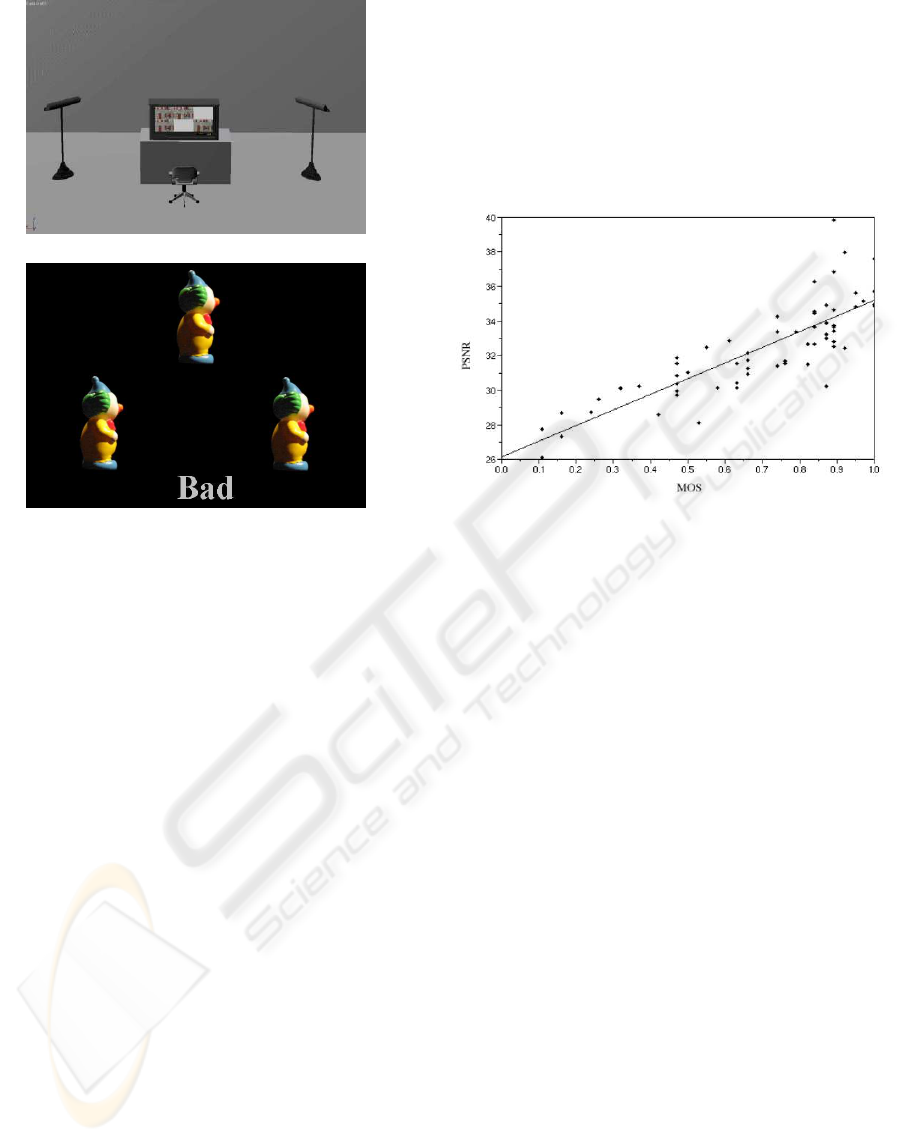
(a)
(b)
Figure 5: Psychophysical experiments: (a) Test room instal-
lation; (b) Snapshot of the proposed protocol using ”Presen-
tation” software from Neurobehavioral Systems.
In front of the configuration of Figure 5.b, the ob-
server has to make a choice. If one of the two com-
pressed images looks less impaired than the other, he
clicks on the best one. If no difference is perceptible,
the reference image or the ”Bad” button are clicked
respectively when both images seem similar to the
reference image or when they are strongly impaired.
When the result is validated, an intermediate black
screen is displayed during half a second for memo-
rization avoidance. Another test among the sixty is
proposed to the observer in a random way.
7.3 Assessment Results
Nineteen observers have participated to the subjective
experiment (a minimum of fifteen is recommended
for coherent statistics). The average score of each
image is computed for all the observers. This score
is called Mean Opinion Score (MOS) and its value
is between 0 (no observer chose it) and 1 (all the ob-
servers chose it). To reject the incoherent answers and
the observers that do not make the test seriously, the
kurtosis test is performed with the whole data.
The next step is to study the correlation between
the PSNR and the MOS (see Figure 6). For this pur-
pose, we use the Pearson correlation coefficient which
provides the link existing between two data sets. A
high correlation value means that the two measures
have a similar evolution. Furthermore, the behavior
of the first one could be extrapolated from the second
one. We thus obtain a value of 83.3% for the Pearson
coefficient which demonstrates that the PSNR and the
MOS are very correlated in the framework of our ap-
plication.
Figure 6: Correlation between PSNR and MOS.
The quality threshold implemented in the com-
pression stage is based on the definition of the straight
line drawn in Figure 6 obtained by linear regression.
The equation of this line is:
PSNR = 9.032× MOS + 26.168 (1)
For instance, the threshold value for MOS = 0.7
(agreement of 70% of the observers) is PSNR =
32.5dB. Equation 1 is integrated in the system for
the automatic dictionary size determination: the user
can specify a MOS value as the quality criterion.
8 IMPLEMENTATION
For constructing a dictionary as representative as pos-
sible, we have chosen to use all the uvst samples as a
learning set. Even though this choice implies longer
computing times, the final image quality is better dur-
ing rendering. Moreover, compression time only cor-
responds to a preprocessing step and is much shorter
than with 4D vectors.
The dictionary size is automatically fixed accord-
ing to the PSNR measured at each step of the LBG
algorithm. This method provides a dictionary size
equal to 2
n
, n being the number of steps of the al-
gorithm (each step doubles the dictionary size). With
such a representation, the size of each index is equal
to n bits, which allows to store efficiently the index
GRAPP 2007 - International Conference on Computer Graphics Theory and Applications
240
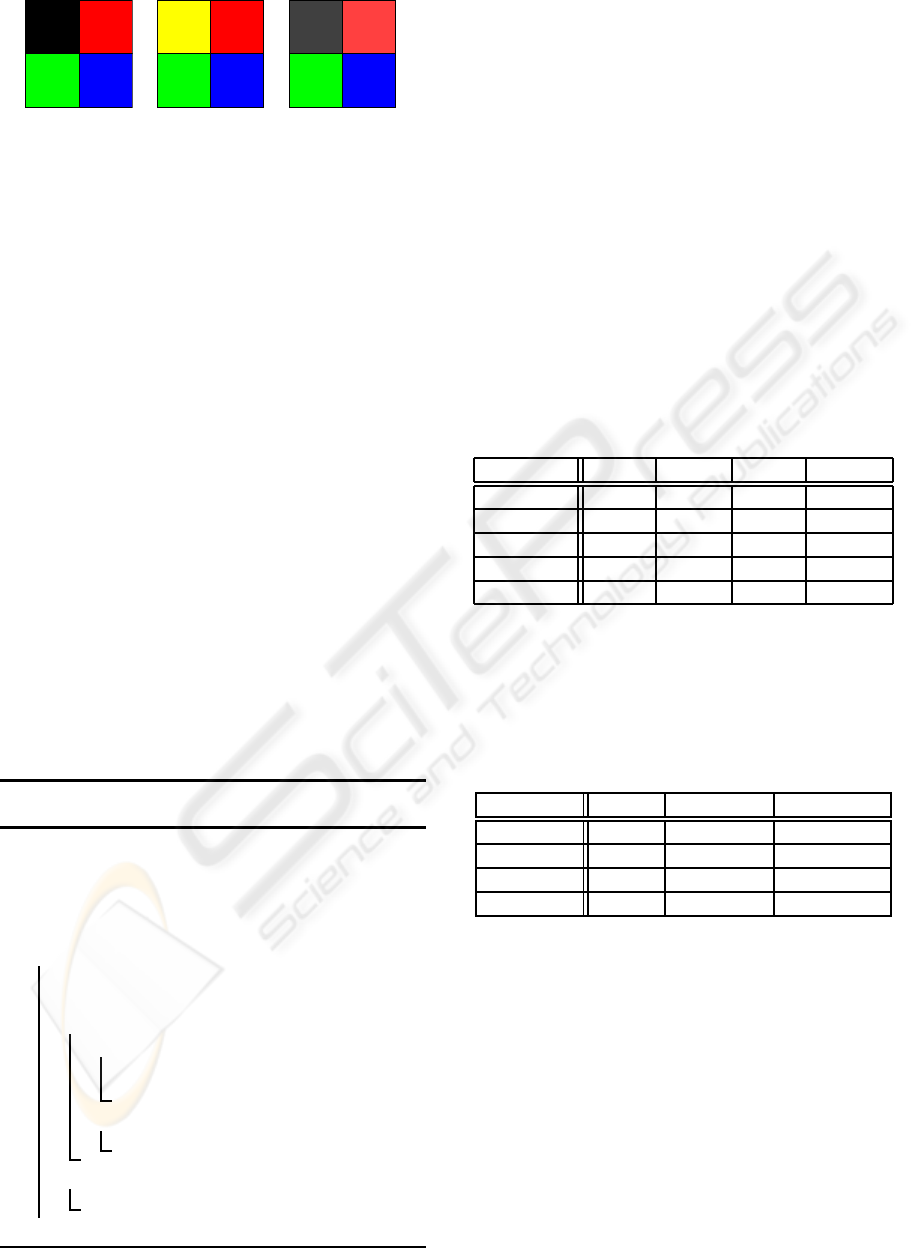
Black Red
Green
Blue
Red
Green
Blue
Yellow
Light red
Green
Blue
Dark grey
(a) (b) (c)
Figure 7: Block selection when not taking background
(black) pixels into account. The vector distance between
(a) and (b) is lower than between (a) and (c) since the black
pixel is not taken into account.
table and offers a random access to any value inside
this table.
The distance d
v
used between a pair of vectors V
1
and V
2
during quantization is computed as follows:
d
v
(V
1
,V
2
) =
n
∑
i=1
d
p
(V
1,i
,V
2,i
)
V
k,i
corresponds to the i
th
pixel of the vector V
k
. d
p
is the Euclidean distance between two pixels, using
their respectiveprimary componentsin the RGB color
space. This is the distance usually used for vector
quantization. As shown in Figure 7, background pix-
els are advantageously discarded during quantization
by always getting a minimal distance with other pix-
els. These background pixels are recovered during
rendering thanks to the binary masks.
Algorithm 1 provides the decompression method
for a (slab, u, v, s,t) sample.
Algorithm 1: R,G,B sample from u, v, s,t coordi-
nates and a compressed light field.
Data:
slab, u, v, s,t: light field direction;
LF
c
: compressed light field
Result:
r, g, b: light field sample (”color”);
begin
image = LF
c
.images(Slab, u, v);
codebook = LF
c
.codebooks(Slab, u, v);
if (s,t) ∈ image.bbox then
if (s,t) ∈ image.mask then
index = image.indexes(s,t);
(r, g, b) = codebook(index);
else
(r, g, b) = background;
else
(r, g, b) = background;
end
9 RESULTS
The PSNR values provided in this paper do not in-
clude background pixels since they disturb the actual
value. Using these pixels generally provides a much
higher PSNR value which is in practice unreliable be-
cause it depends on the number of such pixels in the
image. Tables 5 and 6 provide the results obtained for
the 5 test light fields.
The size selection is automatic and incremental,
based on the PSNR. A light field is compressed using
4 dictionaries per slab, each having its own size, such
that the PSNR is always greater than 32.5dB (MOS of
70%).
Table 5: Compression rates and PSNR for the test light
fields. PSNR. is given in dB, m.size corresponds to the
size required in memory after compression (in MB), c.rate
provides the compression rate, c.time indicates the time re-
quired for the compression process.
LF PSNR m.size c.rate c.time
Sunflower 33.0 1.52 31.6:1 4m14s
Clown 33.2 2.90 20.7:1 22m12s
Quad 33.4 4.47 16.1:1 5m14s
Buddha 33.1 6.09 31.5:1 9m52s
Dragon 32.9 15.25 12.6:1 36m04s
Table 6: Results obtained in terms of variation coefficient.
v.coeff. represents the variation coefficient in terms of
PSNR computed for all the images of the light field. Images
LT provide the percentage of images having a PSNR lower
than the given threshold. PSNR Min provides the minimum
value found for the PSNR of one image.
Light field v.coeff Images LT PSNR Min.
Sunflower 0.55 12.1% 31.4
Clown 0.53 5.6% 32.0
Quad 0.92 16.1% 31.0
Buddha 0.96 27.7% 30.4
We have implemented both GPU and CPU light
field rendering programs. The tests were run with a
Xeon 2.4 GHz processor with 2GB RAM. For more
information about rendering, please refer to (Levoy
and Hanrahan, 1996).
For CPU rendering, when using compressed in-
stead of uncompressed light fields, performance in
terms of frames per second decreases of about 10%
with the whole data in memory. The rate is between
30 and 52 frames per second for a single light field.
The difference is essentially due to access indirections
even though silhouette bounding boxes and masks
avoid searching the dictionary for pixels outside the
object.
QUALITY-BASED IMPROVEMENT OF QUANTIZATION FOR LIGHT FIELD COMPRESSION
241
The GPU used for our tests is a NVIDIA Quadro
FX 3450/4000 SDI with 256 MB of memory. De-
pending on the viewpoint, our GPU program gener-
ates between 25 and 65 images per second with 20
light fields together.
Table 7: PSNR comparison without background pixels for
the Dragon. object between the Light Field Rendering com-
pression scheme and our method. The size provided for our
method does not include the binary mask. PSNR vc cor-
responds to the PSNR variation coefficient. Note that this
coefficient is much lower with our method.
Dragon LF Rendering Our Method
PSNR vc 1.20 dB 0.25 dB 0.26 dB
PSNR min 30.0 dB 30.4 dB 32.3 dB
PSNR max 36.8 dB 31.6 dB 33.6 dB
PSNR avg 31.1 dB 30.8 dB 32.9 dB
MOS avg 55 % 51% 74 %
Mem. size 9.5 MB 9.6 MB 10.6 MB
Table 7 shows results obtained by our compres-
sion method and the approach proposed in (Levoy
and Hanrahan, 1996) with the original images of the
Dragon. With equivalent PSNR and without masks,
compression rates are equivalents though it is the
worst case for our compression scheme. However, the
variation coefficient is much lower with our method
(due to the use of several dictionaries), implying a
better visual quality during rendering. Using binary
masks increases further the object silhouette quality
as shown in Figure 1. Unfortunately, this parameter
is difficult to estimate in terms of PSNR. Another ad-
vantage of our method concerns the automatic choice
of compression rate that provides an average PSNR
greater than 32.5 dB. It generally increases the PSNR
of 2 dB at the expense of 10% on the the light field
size. In average, our method gives a PSNR high
enough to ensure that most observers do not notice
any loss in quality (MOS > 70%) while the previous
method does not.
10 CONCLUSION
This paper presents an improved compression method
relying on quantization dedicated to interactive qual-
ity rendering. Compression time and visual quality
have been improved with the help of object bounding
boxes and silhouette masks for each light field image.
The introduction of a PSNR threshold has allowed to
tune directly the visual quality of the compressed ob-
jects with regards to human judgment. As shown in
the results, our method provides efficient random ac-
cess to uvst samples during the rendering phase. We
wish to integrate depth to the binary masks so as to
reduce aliasing artifacts due to uv sampling, also val-
idated by visual experiments.
ACKNOWLEDGEMENTS
We wish to thank Stanford University for providing
the original and compressed Dragon images. We also
aknowledge James Cowley for the Quad model.
REFERENCES
Adelson, E. H. and Bergen, J. R. (1991). The Plenop-
tic Function and the Elements of Early Vision, chap-
ter 1. Computational Models of Visual Processing,
MIT Press.
Chang, C., Zhu, X., Ramanathan, P., and Girod, B. (2003).
Shape adaptation for light field compression. In IEEE
ICIP.
Girod, B., Chang, C., Ramanathan, P., and Zhu, X. (2003).
Light field compression using disparity-compensated
lifting. In IEEE ICASSP.
Gortler, S. J., Grzeszczuk, R., Szeliski, R., and Cohen, M. F.
(1996). The lumigraph. ACM Computer Graphics,
30(Annual Conference Series):43–54.
Heidrich, W., Lensch, H., Cohen, M., and Seidel, H. (1999).
Light field techniques for reflections and refractions.
In Eurographics Rendering Workshop 1999. Euro-
graphics.
ITU-R Recommendation BT.500-10 (2000). Methodology
for the subjective assessment of the quality of televi-
sion pictures. Technical report, ITU, Geneva.
Keelan, B. W. (2002). Handbook of Image Quality: Char-
acterization and Prediction. Marcel Dekker, New
York, NY.
Lelescu, D. and Bossen, F. (2004). Representation and cod-
ing of light field data. Graph. Models, 66(4):203–225.
Levoy, M. and Hanrahan, P. (1996). Lightfield render-
ing. ACM Computer Graphics, 30(Annual Conference
Series):31–42.
Li, J., Shum, H., and Zhang, Y. (2001). On the the com-
pression of image based rendering scene: A compar-
ison among block, reference and wavelet coders. In
Int. Journal of Image and Graphics, 1(1):45–61.
Linde, Y., Buzo, A., and Gray, R. (1980). An algorithm for
vector quantizer design. IEEE Trans. on Communica-
tions, 1:84–95.
Lloyd, S. P. (1982). Least squares quantization in
pcm. IEEE Transactions on Information Theory,
28(2):129–136.
GRAPP 2007 - International Conference on Computer Graphics Theory and Applications
242

Magnor, M. and Girod, B. (1999). Hierarchical coding of
light fields with disparity maps. In IEEE ICIP, Kobe,
Japan, pages 334–338.
Magnor, M. and Girod, B. (2000). Data compression for
light field rendering. IEEE Trans. Circuits and Sys-
tems for Video Technology, 10(3):338–343.
Magnor, M., Ramanathan, P., and Girod, B. (2003). Multi-
view coding for image-based rendering using 3-d
scene geometry. In IEEE Trans. Circuits and Systems
for Video Technology, 13(11):1092–1106.
Ramanathan, P., Flierl, M., and Girod, B. (2001). Multi-
hypothesis prediction for disparity-compensated light
field compression. In IEEE ICIP.
Ramanathan, P., Kalman, M., and Girod, B. (2003). Rate-
distortion optimized streaming of compressed light
fields. In IEEE ICIP, pages 277–280.
Tong, X. and Gray, R. (2000). Coding of multi-view im-
ages for immersive viewing. In IEEE ICASSP, Istan-
bul, Turkey, pp. 1879-1882.
Wei, L.-Y. (1997). Light field compression using wavelet
transform and vector quantization. Technical Report
EE372, University of Stanford.
Zhang, C. and Li, J. (2000). Compression of lumigraph with
multiple reference frame (MRF) prediction and just-
in-time rendering. In Data Compression Conference,
pages 253–262.
QUALITY-BASED IMPROVEMENT OF QUANTIZATION FOR LIGHT FIELD COMPRESSION
243
