
AN IMPROVED MODEL FOR SECURE CRYPTOGRAPHIC
INTEGRITY VERIFICATION OF LOCAL CODE
Christian Payne
School of Information Technology, Murdoch University, Perth, Western Australia
Keywords:
Code integrity verification, malicious code, one-way hash functions.
Abstract:
Trusted fingerprinting is a new model for cryptographic integrity verification of executables and related objects
to protect users against illicit modifications to system programs and attacks by malicious code. In addition
to a number of other novel features, trusted fingerprinting improves upon previous designs by managing the
privileges assigned to processes based upon their verification status. It also provides greater flexibility as, in
addition to globally verified programs, each user can independently flag for verification software relevant to
their individual security requirements. Trusted fingerprinting also allows for automatic updates to fingerprints
of objects where these modifications are made by trusted code.
1 INTRODUCTION
Numerous vulnerabilities in software (Dowd et al.,
2007; US-CERT, 2006) and a proliferation of mali-
cious code (Gordon et al., 2006; Kalafut et al., 2006)
mean that compromise of computer systems is be-
coming increasingly difficult to prevent. One ap-
proach to mitigating these risks is the use of crypto-
graphic techniques such as one-way hash functions or
digital signatures to support verification of code in-
tegrity so that these intrusions may be detected and
subsequently repelled. While code signing is used ex-
tensively for remote and distributed code (Gong et al.,
1997; Microsoft Corporation, 2006), local code veri-
fication is far less common. Existing schemes have
both practical and architectural limitations and have
failed to recognize that code verification is only one
piece of the puzzle. While verification can detect
naive modifications, there are a number of ways that
attackers can bypass these security checks. Prevent-
ing this requires that the privileges assigned to a pro-
gram be determined based upon its verification status.
This paper presents a new model for integrity ver-
ification of local system code. Like some previous
approaches it uses one-way hash functions to gener-
ate hash values or ‘fingerprints’ for security-related
system objects. However, it improves upon previous
designs by also considering the files a program inter-
acts with at runtime and whether the program’s in-
tegrity has been verified or not. Based upon this a trust
level is assigned to the process and its privileges are
controlled by integrating the code verification model
with a secure access control scheme. This allows
trusted, verified code to be granted higher privileges
than programs that have not been authenticated and
therefore defends against more sophisticated redirec-
tion attacks. It also resolves practical issues such as
verification of non-native executables (such as scripts)
and allows the automatic updating of fingerprints be-
longing to data objects where these modifications are
made by trusted code.
2 PREVIOUS APPROACHES
Use of cryptography to verify code integrity has long
been identified as a means for detecting substitution
or modification of system programs. The Tripwire
software generates one-way hashes of important sys-
tem files and is then run on a regular basis to re-
calculate these hashes and detect if these files have
changed (Kim and Spafford, 1994a; Kim and Spaf-
ford, 1994b). However, Tripwire is a passive detec-
tion mechanism and its high detection latency means
that there is typically a considerable window of vul-
nerability between a compromise occurring and the
administrator being alerted to this event.
Consequently mechanisms which actively prevent
the execution of compromised code have since been
developed. CryptoMark involves embedding signa-
tures in the ELF binary header with the kernel veri-
fying this signature and potentially denying execution
80
Payne C. (2007).
AN IMPROVED MODEL FOR SECURE CRYPTOGRAPHIC INTEGRITY VERIFICATION OF LOCAL CODE.
In Proceedings of the Second International Conference on Security and Cryptography, pages 80-84
DOI: 10.5220/0002124300800084
Copyright
c
SciTePress

if this fails (Beattie et al., 2000). The I
3
FS scheme
uses a stacked filesystem that incorporates the storage
of hash values for data objects with verification oc-
curring upon access (Patil et al., 2004). Yet another
approach utilises the code verification features of the
TPM chip found in TCG-compliant computer systems
to cache known-good ‘measurements’ of system ob-
jects and verify these upon access (Sailer et al., 2004).
Each of these designs suffers from one or more
serious limitations. For example, the TCG-based in-
tegrity verification scheme has no convenient way for
users to update hash values when legitimate changes
are made to the corresponding file object. This is
problematic from a security perspective as it means
objects that may change frequently are likely to be
omitted from verification. This creates scope for a
verified program to be subverted by malicious modifi-
cations to the data file inputs that control its behaviour
such as configuration files.
A similar problem affects CryptoMark as its de-
pendence upon storing signatures inside the ELF bi-
nary executables themselves does not allow for ver-
ification of data files. This also precludes verifica-
tion of non-natively executable scripts. Its designers
suggest that a solution to this is the use of a separate
table specifying signed objects and their signatures.
However, the table then becomes the target of attack
and leads to the more general problem of determining
which system objects require verification and which
do not. This needs to be reliable and immutable in
the face of an attacker with superuser privileges oth-
erwise the system can be tricked into mis-identifying
a maliciously modified object as one that does not re-
quire verification. If this is not the case then an at-
tacker can either insert new malicious code or redi-
rect users to unwittingly execute code other than the
intended trusted program. This problem is illustrated
in the I
3
FS design where a Unix inode value rather
than a path is used to identify each file. This allows
a privileged attacker to create a new program of the
same name as one that is cryptographically verified
but with a different inode number. A user executing
this program will believe they are running a trusted,
verified program but as the inode numbers will not
match, the redirection will not be detected.
This issue can be resolved by requiring all objects
(both code and data) to be verified but this is imprac-
tical (Reid and Caelli, 2005). Not only does it im-
pose an unnecessary performance penalty but dealing
with modified or newly created objects becomes prob-
lematic. An underlying cause of these limitations and
weaknesses is that all programs execute with the same
level of privilege, regardless of whether they have
been verified or not. A novel solution is therefore to
link the privilege with which a program executes with
its verification status. This effectively limits the im-
pact of insertion or redirection attacks by constrain-
ing the privileges of non-verified code. A new model
for local code integrity verification that uses this tech-
nique will now be described.
3 OVERVIEW OF TRUSTED
FINGERPRINTING
3.1 The Vaults Security Model
Vaults is an operating system security model that pro-
vides a key management infrastructure and a crypto-
graphic locks and keys based access control scheme
(Payne, 2003; Payne, 2004), in addition to the in-
tegrity verification mechanism described here. The
access control model applies cryptographically-based
read and write protection to selected files which are
then accessed through tokens called ‘tickets’. Users
can also grant others access to their files by generat-
ing additional tickets for them. Note that these access
controls apply in addition to existing discretionary ac-
cess control lists or permissions. The model also fa-
cilitates the storage of a variety of items in secure
repositories known as ‘vaults’. Each user has their
own vault which they are responsible for administer-
ing using specially designated software. However,
there are also system vaults maintained by the ker-
nel and security administrator. Of these, the one most
relevant to trusted fingerprinting is the Global Public
vault which can be read by all users but only modified
by the security administrator.
The items stored in these various vaults include
tickets and file encryption keys but users can also
store secret values such as passwords that are asso-
ciated with specific applications. These applications
can then request access to the keys that are bound to
them in a manner that is transparent to the user. Each
user’s vault is stored in encrypted form on the disk and
loaded into memory when the corresponding decryp-
tion key is supplied. Access to this vault is restricted
to trusted programs executed subsequent to vault de-
cryption.
Trusted fingerprinting has been designed to in-
tegrate with the Vaults model and leverage the fea-
tures it provides. For example, the fingerprints gen-
erated from system objects can be stored securely in
the appropriate vault. As access to a vault is crypto-
graphically controlled, this ensures the integrity of the
fingerprint values. Fingerprints can then be verified
when the corresponding program or file is accessed.
AN IMPROVED MODEL FOR SECURE CRYPTOGRAPHIC INTEGRITY VERIFICATION OF LOCAL CODE
81

Additionally, the cryptographic access control archi-
tecture provides a convenient means for managing
process privilege and confinement. However, trusted
fingerprinting also improves the security of the Vaults
model since it allows applications to be authenticated
before keys are released to them.
3.2 Local and Global Dependencies
The existence of both the Global Public vault and
individual user vaults gives trusted fingerprinting a
unique two-tier design. The security administrator
can specify programs with system-wide security sig-
nificance to have their fingerprints verified upon ex-
ecution by all system users. These fingerprints are
stored in the Global Public vault and are readable
by all. However, in addition to this each user can
also store fingerprints in their own vault for programs
relevant to them and their specific security require-
ments. This provides superior flexibility compared
with previous approaches and recognizes that security
requirements differ from user to user. Furthermore, it
reduces the workload of the administrator as individ-
ual users can flag programs for verification without
requiring administrative intervention.
Trusted fingerprinting also recognizes both that
not all system objects require verification and that de-
pendency relationships exist between those that do.
For example, a program’s secure behaviour at runtime
may depend upon shared libraries, data files and even
other programs. These dependency relationships are
modelled using interconnected digraph structures that
reflect the shared dependencies of different programs.
This enables efficient and secure runtime verification
of objects.
3.3 Process Trust Levels
Programs are assigned a trust level which is stored
as part of their fingerprint record and determines the
level of privilege that the process will normally have
when executed. Four hierarchical levels of trust are
defined and these are designated Level 0 to 3 (L0–
3), with higher numbers indicating greater privileges.
Unverified code is classified as L0 and cannot access
a user’s vault. The effect of this is that L0 processes
cannot utilise any access tickets that the user pos-
sesses and are therefore unable to access cryptograph-
ically protected files where a ticket is required. Forc-
ing all unverified programs to be unprivileged limits
the damage from malicious code in the event of a suc-
cessful redirection or insertion attack. This resolves a
significant limitation of previous schemes.
Beyond this, verified code can still run with lim-
ited privilege by being designated L1 which results in
the program being confined to a limited set of specif-
ically identified file access tickets. This allows pro-
grams to execute with the minimum amount of priv-
ilege required and is particularly applicable to pro-
grams such as web browsers and e-mail clients that
are exposed to large amounts of untrusted code and
data. Applications labelled as L2 are considered to be
fully trusted and have access to all of the user’s tickets
while the L3 designation is reserved for the software
used to administer vault contents.
3.3.1 Determining Trust Levels
The trust level of a process at runtime depends pri-
marily upon the value assigned by the user and this is
the highest trust level it may hold. However, its trust
level can vary depending on other factors. Specifi-
cally the trust level of a new child process is instanti-
ated as the minimum of that program’s user-specified
trust level and its parent’s current trust level
1
. With-
out this the secure operation of a trusted program
could be subverted if it were executed by malicious
code and supplied with dangerous parameters or in-
puts. This therefore prevents a malicious, untrusted
program from misusing a trusted one. As a result
it is not necessary to analyse the behaviour of each
individual program in response to all possible inputs
when assigning trust levels.
The manner in which the trust level of a program is
decided is designed to reflect both applicable security
semantics and the practical requirements of program
operation. For example, L0 applications are unable
to access cryptographically protected files where this
requires a ticket. However, where discretionary con-
trols allow, they may still access files that are only
protected with the opposite mode to that requested;
e.g., where read access is requested to a file that is
only write protected. This effectively minimises the
privileges of an L0 program by isolating it from any
sensitive data while not limiting its privileges to such
a degree that the user is forced to elevate its trust level
in order for the program to operate correctly. There-
fore, users need only increase an L0 program’s trust
level if there is a set of specific cryptographically pro-
tected objects that they wish the program to be able
to access. Furthermore, even in this scenario, unless
the program requires general access to cryptograph-
ically protected files, the user can set the trust level
1
The only exception to this rule is the special case where
an L3 program is executed and these can only be spawned
from L2 processes. Because of this, L3 programs must be
designed to prevent any subversion of their behaviour by
parameters or other external inputs.
SECRYPT 2007 - International Conference on Security and Cryptography
82
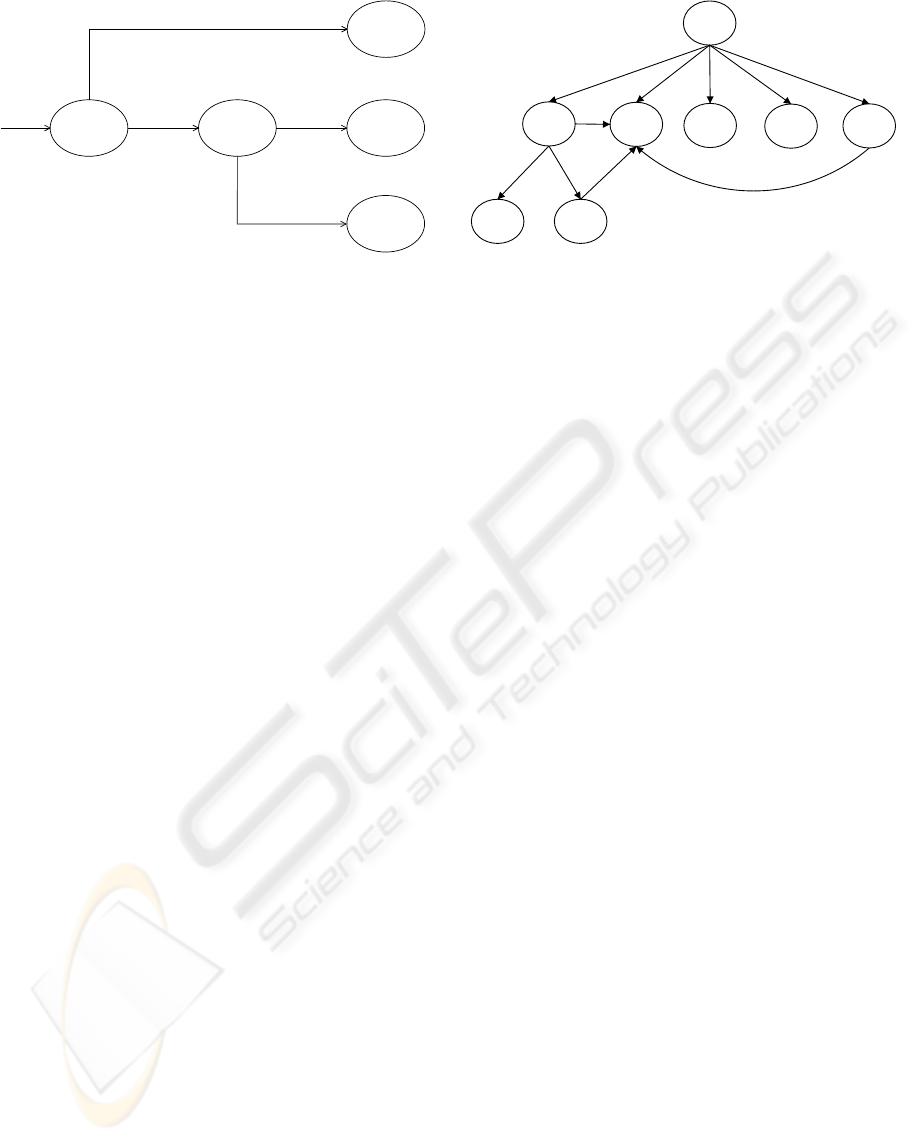
Attempt Match
Verify
Fingerprint
Execution
Initiated
Match Failed
Match
Succeeded
Fingerprint Valid
Fingerprint
Invalid
Deny
Execution
Execute
Trusted
Execute
Untrusted
Figure 1: Overview of process execution, matching and ver-
ification.
to L1, thereby confining the program to these specifi-
cally selected objects.
3.4 Matching, Verification and
Execution of Programs
An overview of the process that occurs when a pro-
gram is executed is given in Figure 1. When a pro-
gram’s execution is initiated, a matching process oc-
curs where the user’s vault and Global Public vault are
searched for a fingerprint entry corresponding to the
path of the file being executed. If no match is found
then the program will execute as untrusted (L0), oth-
erwise, if verification is successful, the trust level is
set based upon the value in the matched fingerprint
record and according to the rules described in the pre-
vious section. This ensures that the default behaviour
is to minimise the privileges assigned to a program
and this significantly mitigates the risks due to inser-
tion or redirection attacks.
The local and global dependency digraphs identi-
fied through the matching process are then merged to
construct a ‘runtime digraph’ for that program. This
is maintained for the lifetime of the process and is
used to identify and verify the relevant objects when
accessed. An abstracted example of a hypothetical
runtime digraph is given in Figure 2. In this exam-
ple, the program is linked with two different shared
libraries, which in turn have their own dependency ar-
rangements as shown by the direction of the arrows.
The program has both global and local (per-user) con-
figuration files, both of which are identified in the run-
time digraph as a result of the merging process. The
program also has a helper application that it executes
at runtime.
Once matching is complete and the runtime di-
graph constructed, the program binary and the shared
libraries it depends upon are verified by calculating
Prog
Lib 1 Lib 2
Lib 3
Lib 4
Prog 2
(Helper)
Config
(Local)
Config
(Global)
Figure 2: Example runtime digraph.
one-way hashes and comparing these against the fin-
gerprint values in the runtime digraph. The pro-
gram and shared library images are cached in mem-
ory between verification and execution. This excludes
race condition-based attacks involving a privileged at-
tacker modifying a trusted object in the time between
verification and use.
3.5 Data File Dependencies and
Automatic Updating
Non-executable data objects accessed by a trusted
program at runtime are checked against the runtime
digraph. If these are specified as a dependency for
that program then these are also loaded into memory
and verified. This allows for the files used by an ap-
plication which impact on security to be specifically
marked for verification without the performance im-
pact of requiring all accessed files to be verified. This
design also facilitates verification of non-natively ex-
ecutable programs such as scripts by specifying the
script source code as a dependency of the natively
executable interpreter or runtime environment. Trust
levels can also be assigned to individual scripts and
the effective trust level of the interpreter process is
modified to be the minimum of its current level and
that assigned to the data file dependency. This enables
interpreted scripts and other non-natively executable
programs to have different and independent trust lev-
els to that of their interpreter.
As is the case with programs and libraries, data
file dependencies are also cached at runtime. Be-
cause of this, modifications to these data objects by a
trusted process are captured by the system and used
to automatically update the user’s fingerprint value
for that object. This is a convenient and secure ap-
proach to dealing with modifications to trusted data
that does not involve the level of administrative over-
head required in previous file integrity verification
AN IMPROVED MODEL FOR SECURE CRYPTOGRAPHIC INTEGRITY VERIFICATION OF LOCAL CODE
83

schemes. Automatic fingerprint updating can only be
performed by a program which is a parent of the data
file dependency in the program’s runtime digraph. In
this way the runtime digraph clearly defines the trust
relationships between a program and the libraries and
data files it depends on. However, users can also man-
ually update fingerprint values in their vault using a
specifically designated L3 application.
4 CONCLUSION
Trusted fingerprinting is a new model for local code
verification which leverages the cryptographic infras-
tructure provided by the Vaults architecture. It re-
solves the weaknesses of previous approaches in that
it actively prevents execution of maliciously modi-
fied objects, supports the verification of non-natively
executable scripts, allows the automatic updating of
fingerprints when modifications are made by trusted
code and limits the privileges assigned to unverified
processes. Other unique features include the use of
digraphs to represent the relationships between pro-
grams and the objects they depend upon for their se-
curity and a two-tier approach where users can inde-
pendently specify programs to be verified consistent
with their individual security requirements in addi-
tion to global defaults. This recognizes the need for
greater flexibility in local code verification architec-
tures in order to avoid administrative overheads that
otherwise represent a significant impediment to their
adoption. Therefore, the adoption of the trusted fin-
gerprinting code verification technique, in conjunc-
tion with the other features of the Vaults model, has
the potential to significantly mitigate the effects of
widespread malicious code and intrusion.
REFERENCES
Beattie, S. M., Black, A. P., Cowan, C., Pu, C., and Yang,
L. P. (2000). CryptoMark: Locking the stable door
ahead of the Trojan horse. White paper, WireX Com-
munications Inc.
Dowd, M., McDonald, J., and Schuh, J. (2007). The Art of
Software Security Assessment. Addison-Wesley.
Gong, L., Mueller, M., Prafullchandra, H., and Schemers,
R. (1997). Going beyond the sandbox: An overview of
the new security architecture in the Java Development
Kit 1.2. In Proceedings of the USENIX Symposium on
Internet Technologies and Systems.
Gordon, L. A., Loeb, M. P., Lucyshyn, W., and Richardson,
R. (2006). Eleventh annual CSI/FBI computer crime
and security survey. Technical report, Computer Se-
curity Institute (CSI).
http://GoCSI.com
.
Kalafut, A., Acharya, A., and Gupta, M. (2006). A study
of malware in peer-to-peer networks. In Proceedings
of the 6th ACM SIGCOMM on Internet Measurement.
ACM Press.
Kim, G. H. and Spafford, E. H. (1994a). The design and
implementation of Tripwire: A file system integrity
checker. In Proceedings of the 2nd ACM Conference
on Computers and Communication Security.
Kim, G. H. and Spafford, E. H. (1994b). Experiences with
Tripwire: Using integrity checkers for intrusion de-
tection. Technical Report CSD-TR-93-071, COAST
Laboratory, Purdue University, West Lafayette, IN
47907-1398.
Microsoft Corporation (2006). Introduction to code signing.
Online:
http://msdn.microsoft.com/workshop/
security/authcode/intro_authenticode.asp
.
Patil, S., Kashyap, A., Sivathanu, G., and Zadok, E.
(2004). I
3
FS: An in-kernel integrity checker and in-
trusion detection file system. In Proceedings of the
18th USENIX Large Installation System Administra-
tion Conference (LISA 2004).
Payne, C. (2003). Cryptographic protection for operating
systems. Research Working Paper Series IT/03/03,
School of Information Technology, Murdoch Univer-
sity, Perth, Western Australia.
Payne, C. (2004). Enhanced security models for operat-
ing systems: A cryptographic approach. In Proceed-
ings of the 28th Annual International Computer Soft-
ware and Applications Conference: COMPSAC 2004,
pages 230–235. IEEE Computer Society.
Reid, J. F. and Caelli, W. J. (2005). DRM, trusted comput-
ing and operating system architecture. In Proceedings
of the 2005 Australasian Workshop on Grid Comput-
ing and e-research, volume 44, pages 127–136.
Sailer, R., Zhang, X., Jaeger, T., and van Doorn, L. (2004).
Design and implementation of a TCG-based integrity
measurement architecture. In Proceedings of the 13th
USENIX Security Symposium, pages 223–238.
US-CERT (2006). Quarterly trends and analysis report,
volume 1, issue 2. Technical report, United States
Computer Emergency Readiness Team.
http://www.
us-cert.gov
.
SECRYPT 2007 - International Conference on Security and Cryptography
84
