
A CASE STUDY ON THE APPLICATION OF THE MAAEM
METHODOLOGY FOR THE SPECIFICATION MODELING OF
RECOMMENDER SYSTEMS IN THE LEGAL DOMAIN
Lucas Drumond, Rosario Girardi and Adriana Leite
Department of Computer Science, Federal University of Maranhão, Avenida Dos Portugueses, São Luís, Brazil
Keywords: Recommender Systems, Information Filtering, Semantic Web, Multi-Agent Systems.
Abstract: Recommender systems have been target of continuous research over the last years, being used as an
approach to the information overload problem. The Semantic Web is a new generation of the Web which
aims at improving the effectiveness of information access on the Web by structuring its content in a
machine readable way. Agents have been also object of active research on the software engineering field
considering the high level of abstraction for software development provided by the multi-agent paradigm.
This paper describes the modeling of Infonorma, a multi-agent recommender system for the legal domain
developed under the guidelines of MAAEM, a methodology for multi-agent application development, which
is also evaluated here.
1 INTRODUCTION
Recommender systems (Adomavicius and Tuzhilin,
2005) (Ziegler, 2004) are a particular type of
filtering applications. They help users to deal with
the problem of information overload. In content-
based approaches (Adomavicius and Tuzhilin, 2005)
(Balabanovic and Shoham, 1997) they provide the
users with recommendations of items that are similar
to the ones that they preferred in the past. This is
achieved by measuring the similarity between
information items representation and user profiles.
Most of the content-based filtering algorithms
use statistical-based methods to measure similarity
between user models and information item
representations (Adomavicius and Tuzhilin, 2005).
Those methods do not consider any kind of semantic
processing, which is the reason why ambiguity
problems are faced by content-based filtering
systems.
The Semantic Web (Antoniou and Van
Harmelen, 2004) is a new generation of the Web in
which data is structured in such a way that it can be
machine readable and exhibited in a user-friendly
way. This is done with the use of ontologies
(Gruber, 1995) and standard technologies defined by
the World Wide Web Consortium (W3C). With a
semantically structured representation of Web data,
recommender systems can use semantic-based
similarity measures in order to improve their
effectiveness.
Agent-oriented Software Engineering approaches
the increasing complexity of computing systems that
must operate in open and quickly changing
environments by improving our ability to model,
design and implement complex systems (Jennings,
2000).
MAAEM (“Multi-agent Application Engineering
Methodology”) (Lindoso and Girardi 2006) is a
software development methodology for multi-agent
application engineering based on the reuse of
software artifacts developed in a Domain
Engineering process guided by the MADEM
(“Multi-agent Domain Engineering Methodology”)
methodology (Girardi and Marinho, 2007).
Infonorma (Drumond, Girardi, Lindoso and
Marinho, 2006) is a multi-agent recommender
system for the legal domain that recommends legal
normative instruments to users according to their
particular interests. The information items of
Infonorma are represented as instances of the
ONTOJURIS ontology, which is written in OWL
according to the W3C recommendations. The system
was modelled under the guidelines of the MAAEM
methodology and this experience has contributed for
its evaluation.
155
Drumond L., Girardi R. and Leite A. (2007).
A CASE STUDY ON THE APPLICATION OF THE MAAEM METHODOLOGY FOR THE SPECIFICATION MODELING OF RECOMMENDER SYSTEMS
IN THE LEGAL DOMAIN.
In Proceedings of the Ninth International Conference on Enterprise Information Systems - SAIC, pages 155-160
DOI: 10.5220/0002389201550160
Copyright
c
SciTePress

This paper focuses on the requirements
specification of Infonorma and the Application
Analysis phase of the MAAEM methodology. The
description of the architectural and detailed design
as well as the implementation of Infonorma is not
provided here due to space restrictions.
This paper is organized as follows. Section 2
introduces the main modeling concepts of MAAEM
and briefly describes its tasks and products in the
context of a multi-agent application engineering
process. Section 3 provides an overview of the
system specification, describing the tasks carried out
and their respective products. Section 4 analyzes
related work on multi-agent and Semantic Web
recommender systems. Finally, Section 5 concludes
this paper with some remarks on further work being
conducted.
2 AN OVERVIEW OF THE
MAAEM METHODOLOGY
Multi-agent Application Engineering (MaAE)
(Jennings, 2000) is a process for the development of
specific applications through the reuse of software
artifacts produced in Multi-agent Domain
Engineering (MaDE) (Girardi and Marinho, 2007), a
complementary and interdependent process.
MAAEM is a methodology for analysis, design and
implementation of multi-agent applications through
the reuse of software artifacts such as domain
models, multi-agent frameworks, pattern systems
and software agents. MAAEM also supports the
development of applications from scratch, without
reuse, as is the case of the development of
Infonorma.
The ONTORMAS (“ONTOlogy driven tool for
the Reuse of Multi-Agent Software”) ontology
works as a modeling tool and a storage repository
for products constructed on the Multi-agent Domain
Engineering and Multi-agent Application
Engineering processes. MAAEM products are
represented as instances of ONTORMAS ontology.
For the specification of an application, MAAEM
focuses on modeling goals, roles, activities and
interactions of entities of an organization. Entities
have knowledge and use it to exhibit autonomous
behavior. An organization is composed of entities
with general and specific goals that establish what
the organization intends to reach. The achievement
of specific goals allows reaching the general goal of
the organization. Specific goals are reached through
the performance of responsibilities that entities have
by playing roles with a certain degree of autonomy.
Entities playing roles have skills on one or a set
of techniques that support the execution of
responsibilities in an effective way. Pre-conditions
and post-conditions may need to be satisfied
for/after the execution of an activity. Knowledge can
be consumed and produced through the execution of
an activity.
For the specification of a design solution, roles
are assigned to agents structured and organized into
a particular multi-agent architectural solution
according to non-functional requirements.
Table 1 summarizes modeling phases, respective
tasks and modeling products of MAAEM.
Application analysis is performed through the
following modeling tasks: concept modeling, goal
modeling, role modeling and role interaction
modeling. An Application Specification is the
product of this phase and it is composed of each one
of these task products: concept model, goal model,
role model and role interactions model, respectively.
The concept modeling task aims at performing a
brainstorming of concepts involved in the
application and their relationships, representing
them in a concept model. These concepts can also be
selected for reuse from a domain model, if one is
available. This starts from an informal analysis of
the application requirements. These concepts are
refined in the subsequent modeling tasks.
Table 1: Modeling phases, tasks and products o
f
MAAEM methodology.
ICEIS 2007 - International Conference on Enterprise Information Systems
156
The purpose of the goal modeling task is to
identify the goals of the system, the external entities
which it cooperates with and the responsibilities
needed to achieve them.
In the role modeling task, the responsibilities
identified in the goal model, are assigned to roles as
well as the used and produced knowledge, imposed
pre-conditions, post-conditions and required skills.
Once the roles present in the application are
selected, adapted and composed, it is needed to
establish how the internal entities playing the roles
interact with each other and with external entities,
which is done in the role interactions modeling task.
The product of this task is a set of role interaction
models, one for each specific goal.
The user interface prototyping task is developed
in parallel with the goal modeling, role modeling
and the role interactions modeling tasks. Its product
is a set of user interface prototypes.
The design phase, supported by the ADEMAS
technique, approaches the architectural and detailed
design, defining a solution to the requirements
specified in the analysis phase.
Application implementation approaches the
mapping of design models to agents, behaviours and
communication acts, concepts involved in the JADE
framework, which is the adopted implementation
platform.
3 APPLICATION
SPECIFICATION
3.1 Concept Modeling
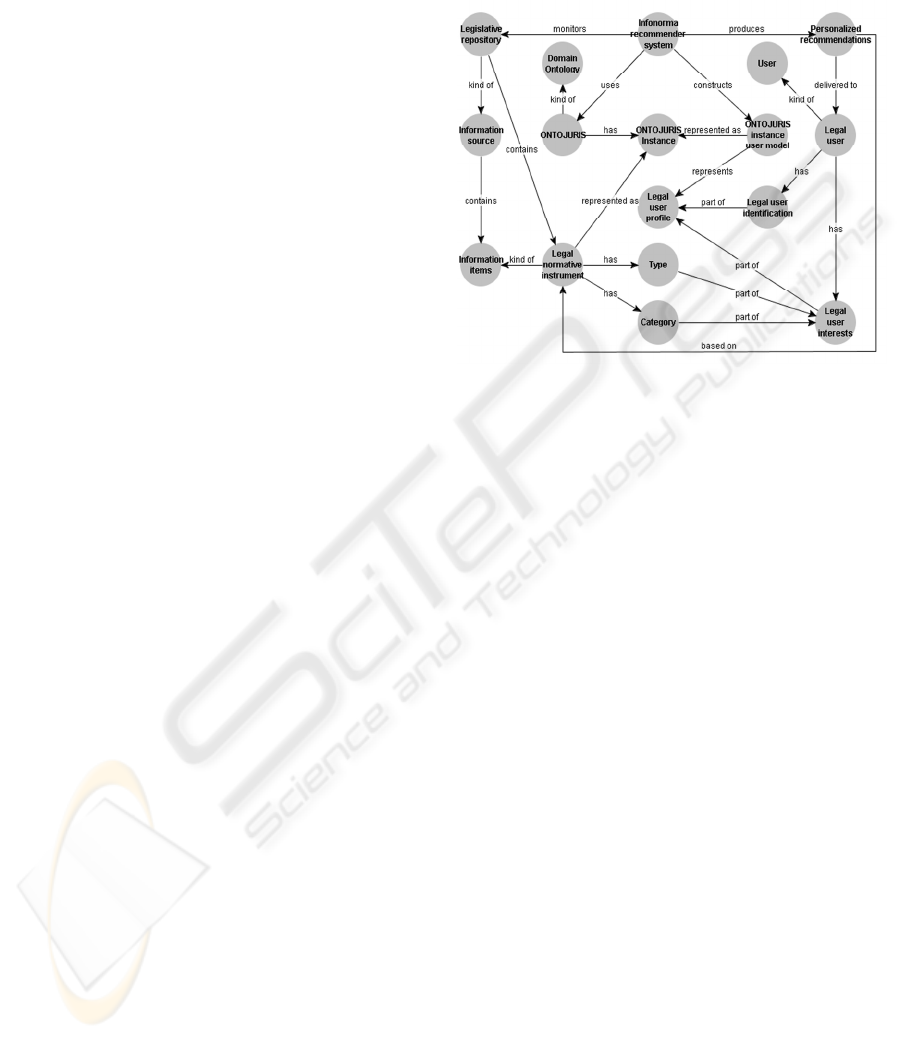
Infonorma is a system that provides its users with
personalized recommendations of legal normative
instruments. Each legal user has a profile composed
by his/her own interests and identification. This
profile is represented by a user model as an instance
of the ONTOJURIS domain ontology.
Recommendations are based on legal normative
instruments, the information items. Each one of
these instruments has two main characteristics: the
type and the category or legal branch in which it is
classified. These characteristics are also part of the
interests of legal users. The system monitors a
legislative repository, a kind of information source
composed by normative instruments.
Each legal normative instrument, as well as each
legal user model, is represented as an instance of the
ONTOJURIS ontology. ONTOJURIS is a domain
ontology used to represent the structure of legal
normative instruments. This internal representation
is compared to the interests of the users in order to
generate the recommendations.
All those concepts are represented in the Concept
Model shown in Figure 1.
3.2 Goal Modeling
After applying the guidelines of MAAEM regarding
the definition and representation of goal models in
multi-agent systems to the area of content-based
filtering, particularly for the legal domain, the
following goals are captured:
General Goal
Provide personalized legal-normative
recommendations
Specific Goals
Model legal users
Content-based filter of new legal
information
Deliver recommendations
The complete goal model of the system is
depicted in Figure 2. It is possible to realize that the
general goal of the system is achieved by three
specific goals, and, as requirements for the
fulfilment of the specific goals, there is a set of
responsibilities which need to be exercised in order
to achieve the specific goals. Besides that, there are
also external entities to the system: a Legislative
repository and a Legal user. The legal information
for content-based filtering users is obtained from a
Legislative repository and the external entities
representing legal users receives filtered items and
provide some explicit information about their
interests.
The fulfilment of the specific goal model legal
users requires the exercise of explicit user profile
Figure 1: Concept model of Infonorma.
A CASE STUDY ON THE APPLICATION OF THE MAAEM METHODOLOGY FOR THE SPECIFICATION
MODELING OF RECOMMENDER SYSTEMS IN THE LEGAL DOMAIN
157
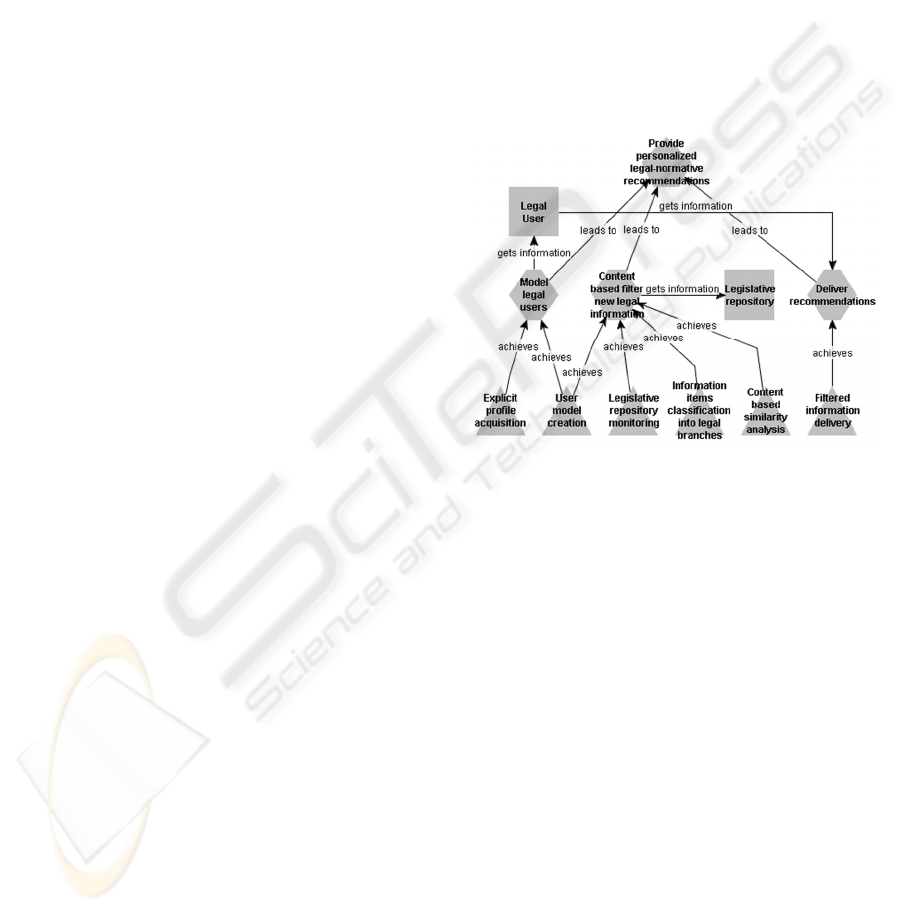
acquisition and the user model creation
responsibilities. Similarly, in order to achieve the
content-based filter new legal information specific
goal it is necessary performing the responsibilities
user model creation and legislative repository
monitoring. The type of the normative instruments is
explicitly specified in the ontology, but their
categories are not.
Because of that, whenever new legal information
items are identified, the system must find out in
which legal branches they can be classified
(information items classification into legal branches
responsibility) so the content-based similarity
analysis responsibility can be carried out. At last it is
necessary to exercise the filtered information
delivery responsibility.
The Legal user external entity represents the
users of Infonorma. Such users are expected to be
people interested in Law, more specifically in legal
normative instruments, such as lawyers and judges.
Such users are interested in certain legal branches
and types of legal normative instruments which are
more closely related to their work.
Originally, Infonorma used a Brazilian
government website as information source. The lack
of semantic markup of this source, entirely written in
HTML, shortened the efficiency of the system. To
overcome this problem a Legislative repository was
built in OWL, according to Semantic Web standards,
and an auxiliary application, using JENA framework
(McBride, 2002), that converts the data of normative
documents into an instance of ONTOJURIS in OWL
format was developed.
This Legislative repository contains the
normative instruments which are recommended to
the users. It is important to state that the external
entity is composed only by the instances of the legal
normative instruments. The instances of user models
are created and maintained internally by the system.
The goal of ONTOJURIS is to represent legal
normative instruments in the form of Semantic Web
documents. It also represents various legal branches
organized into a hierarchy so that the normative
instruments can be classified according to it.
A legal branch is defined by a class that has four
attributes: a name, which identifies it, a set of
weighted keywords, the specializes and the
generalizes attributes. The weighted keywords are
terms that are semantically related to the branch. For
example, Crime and Penalty are keywords for the
legal branch Penal Law. They were determined with
the aid of a domain specialist and are used to
classify a given normative instrument. The first one
(specializes) indicates the superclass (es) of a legal
branch and the second one (generalizes), the
subclass (es). Both of them have multiple
cardinality, so multiple inheritance is allowed.
The Legal Normative Instrument class has the
following attributes representing the structure of a
normative instrument: the preliminary part, which
identifies it; the normative part, in which the norms
are found; and final part with some additional
information about the normative instrument.
The User class has three main attributes. Each
user is identified by its name. The recommendations
are delivered through email messages, so it is
important to annotate the email address. And,
finally, the user interests, represented by a set of
instances of legal branches.
3.3 Role Modeling
Each one of the responsibilities identified in the
Goal Model is assigned to an internal entity playing
a role. This is expressed in a Role Model, which, due
to space limitations, is not shown here. Each role
requires, during its development, the usage and
production of certain knowledge, the fulfilment of
pre-conditions and post-conditions and specific
skills. Each skill is detailed with a brief description
and most relevant bibliographical references
describing it.
The Input Interface role is in charge of the
explicit profile acquisition responsibility. This
responsibility uses the user identification and
interests knowledge, to acquire the Legal user
profile. The profile acquisition is made explicitly
since there are not enough interactions of the user
with the system to acquire his/her profile implicitly.
On the top of that Infonorma is designed for users
who know what they want but the desired
information is not available in the moment, so it is
Figure 2: Goal model of Infonorma.
ICEIS 2007 - International Conference on Enterprise Information Systems
158

reasonable to have the users specify their interests.
The specification of a new user profile is a pre-
condition for the explicit profile acquisition that
acquires a valid user profile.
The user modeler role is in charge of the user
model creation responsibility. When a valid user
profile is available, it creates an ONTOJURIS
instance user model by instantiating the class “User
Model” of ONTOJURIS with the information
available in the Legal user profile produced by the
first responsibility and the User model attributes
acquired from the ONTOJURIS ontology.
The Source Monitor is the role responsible for
the legislative repository monitoring, which uses the
skill information source update detection to perceive
changes in the Legislative repository to discover new
legal information items.
The information items classification
responsibility is assigned to the Classifier role that
classifies the normative instruments into one or more
legal branches assigning to each item the level of
similarity with each legal branch. This is done by
counting the keywords in the instrument and
comparing them to the keywords of each legal
branch.
The fifth responsibility is the Content-based
similarity analysis one. The Information Filter role
is in charge of it. The matching is performed by
comparing the type of the new information items
with the types each user is interested in. Once the
information items are classified into legal branches
the similarity analysis is performed by computing
the distance between the legal branches the user is
interested in and the legal branches the information
item is classified in.
The last responsibility is the filtered information
delivery one, assigned to the Output Interface role.
Once the information items are filtered (pre-
condition), the Output Interface produces the
personalized recommendations knowledge. They are
delivered to the user using the Electronic mail
message sending skill.
3.4 Role Interactions Modeling
Each one of the Role Interactions Model shows the
interactions related to each specific goal. The
interactions are numbered according to their
sequencing.
In the first role interaction model, related with
the model legal users specific goal, the explicit
profile acquisition, the user specifies his/her
identification and interests to the Input Interface role
that sends to the User Modeler the Legal user profile
so it can get the User model attributes from
ONTOJURIS and create the user models.
The second role interaction model is related to
the content based filter new legal information
specific goal. When any information source change
occurs, the Source Monitor informs the Classifier
about the new legal information items so that it can
perform the information items classification into
legal branches responsibility.
In order to perform the classification, the
classifier must get the ONTOJURIS legal branches.
Once the items are classified, they are sent to the
entity playing the Information Filter role that
performs the Content-based similarity analysis
responsibility. When the Information Filter role
receives those items, it requests the user models to
the User Modeler one and the ONTOJURIS legal
branches to the ONTOJURIS external entity.
At last, in order to deliver the recommendations,
the Information Filter sends to the Output Interface
the filtered information items which are sent to the
Legal User as personalized recommendations.
3.5 User Interface Prototypes
According to the goal, role, and role interactions
models, legal users interact with Infonorma for
specifying their profiles (explicit profile acquisition
responsibility). This interaction is supported by a
Web form in which the user specifies his/her
identification (login, email and password) and the
types and categories he/she is interested in.
On the other hand, Infonorma provides legal
users with personalized recommendations through
the filtered information delivery responsibility. This
can be considered as the output of the system and
takes place when the filtered information is
delivered to the user through email messages.
4 RELATED WORK
The state of art of the techniques used in
recommender systems has been moving forward in
the last years, improving considerably the
effectiveness of these systems (Adomavicius and
Tuzhilin, 2005).
A new research area, that has appeared recently,
aims at improving the effectiveness of recommender
systems using, as information source, semantically
structured documents using technologies of the
Semantic Web (Ziegler, 2004). Ontologies are the
knowledge representation structures used by
Semantic Web technologies. Work on the usage of
A CASE STUDY ON THE APPLICATION OF THE MAAEM METHODOLOGY FOR THE SPECIFICATION
MODELING OF RECOMMENDER SYSTEMS IN THE LEGAL DOMAIN
159

ontologies in user modeling and similarity analysis
in recommender systems has already been developed
(Middleton, Shadbolt, and De Roure, 2004).
A survey of current machine learning techniques
for automatic text classification that can be used to
classify information items into categories of the
taxonomy is provided in (Sebastiani, 2002).
The agent paradigm can be exploited in the
development of information filtering systems such
as recommender systems. Experiences in this area
are described in (Sheth and P. Maes, 1993).
There has been much work done in the domain
of Artificial Intelligence and Law. The development
and usage of legal ontologies to represent and access
legal information has been addressed in (Tiscornia,
2001) and (Valente, 1995). (Benjamins, Casanovas,
Breuker and Gangemi, 2005) provide an overview of
the application of Semantic Web technologies to the
legal domain.
5 CONCLUSIONS
This work described the requirements analysis of
Infonorma multi-agent system. A solution to the
requirements specified here was designed and
implemented also under the guidelines of MAAEM
methodology, although it is not described in this
paper. The next step is to carry out tests with real
legal users and define criteria for measuring the
quality of recommendations.
In the current version of Infonorma users have to
explicitly specify their interests by filling a form.
This is used to create and update the user model and
no feedback is obtained from the user. One research
issue to be addressed in the future is to combine web
usage mining techniques (Girardi and Marinho,
2007) with Semantic Web technologies to support
the implicit acquisition of user profiles and their
dynamic update through user feedback.
The case study described in this article also
contributed for the evaluation of the MAAEM
methodology application analysis phase.
Both MAAEM and ONTORMAS have proved
their usefulness for capturing and specifying
requirements of a specific application through
appropriate guidelines and representation and
decomposition mechanisms.
ACKNOWLEDGEMENTS
This work is supported by CNPq.
REFERENCES
Adomavicius, G., Tuzhilin, A., 2005. Toward the next
generation of recommender systems: A survey of the
state-of-the-art and possible extensions. IEEE Trans.
Knowledge and Data Engineering, v. 17, n. 6, 734-
749.
Antoniou G., Van Harmelen, F., 2004. A Semantic Web
Primer, MIT Press.
Balabanovic, M., Shoham, Y., 1997. Fab: Content-Based,
Collaborative Recommendation Comm. ACM, v. 40, n.
3, 66-72.
Benjamins, V. R., Casanovas, P., Breuker, J., Gangemi,
A., 2005. Law and the Semantic Web, an Introduction.
In Lecture Notes in Computer Science, v. 3369, 1–17.
Drumond L., Girardi. R., Lindoso, A., Marinho, L.,
2006. A Semantic Web Based Recommender System
for the Legal Domain. In Proc. of the European
Conference on Artificial Intelligence (ECAI 2006)
Workshop on Recommender Systems, Riva del Garda,
Italy, pp. 81-83.
Girardi. R., Marinho, L., 2007. A Domain Model of Web
Recommender Systems based on Usage Mining and
Collaborative Filtering, Requirements Engineering
Journal, London, Springer-Verlag Press, v. 12, n. 1,
pp. 23-40.
Gruber, T., 1995. Toward Principles for the Design of
Ontologies used for Knowledge Sharing. International
Journal of Human-Computer Studies, n. 43, 907-928.
Jennings, N., 2000. On Agent-based Software
Engineering. Artificial Intelligence, v. 117, n. 2, 277-
296.
Lindoso, A., Girardi, R., 2006. The SRAMO Technique
for Analysis and Reuse of Requirements in Multi-
agent Application Engineering. IX Workshop on
Requirements Engineering, Cadernos do IME, UERJ
Press, v. 20, 41-50. Rio de Janeiro.
McBride, B., 2002. Jena: a Semantic Web Toolkit.
Internet Computing IEEE, 6, pp. 55-59.
Middleton, S., Shadbolt, N., De Roure, D., 2004.
Ontological User Profiling in Recommender Systems.
ACM Transactions on Information Systems, 22, 54-88.
Sebastiani, F., 2002. Machine learning in automated text
categorization. ACM Computing Surveys.
Sheth, B., Maes, P., 1993. Evolving Agents for
Personalized Information Filtering. In Proc. Ninth
IEEE Conf. Artificial Intelligence for Applications,
345-352.
Tiscornia, D., 2001. Ontology-Driven Access to Legal
Information. DEXA 12th International Workshop on
Database and Expert Systems Applications, p. 792.
Valente, A., 1995. Legal Knowledge Engineering: a
Modeling Approach. IOS Press, Amsterdam, The
Netherlands.
Ziegler, C., 2004, Semantic Web Recommender Systems.
Proc. Joint ICDE/EDBT Ph.D. Workshop,
78-89.
ICEIS 2007 - International Conference on Enterprise Information Systems
160
