
TEXT CATEGORIZATION USING EARTH MOVER’S DISTANCE AS
SIMILARITY MEASURE
Hidekazu Yanagimoto and Sigeru Omatu
Osaka Prefecture University, 1-1, Sakai, Osaka, Japan
Keywords:
Text Categorization, Earth Mover’s Distance.
Abstract:
We propose a text categorization system using Earth Mover’s Distance (EMD) as similarity measure between
documents. Many text categorization systems adopt the Vector Space Model and use cosine similarity as
similarity measure between documents. There is an assumption that each of words included in documents
is uncorrelated because of an orthogonal vector space. However, the assumption is not desirable when a
document includes a lot of synonyms and polysemic words. The EMD does not demand the assumption
because it is computed as a solution of a transportation problem. To compute the EMD in consideration of
dependency among words, we define the distance between words, which needs to compute the EMD, using
a co-occurrence frequency between the words. We evaluate the proposing method with ModApte split of
Reuters-21578 text categorization test collection and confirm that the proposing method improves a precision
rate for text categorization.
1 INTRODUCTION
Text categorization systems automatically categorize
informations using human-labeled documents. The
system uses the similarity measure between an un-
labeled document and the labeled documents. The
documents are represented as vectors with the Vec-
tor Space Model (VSM) and the cosine similarity is
used in text categorization. When the cosine similar-
ity is computed, we assume that the vector space is am
orthogonal vector space. However, this assumption
is not always fulfilled because a document includes
a lot of synonyms and polysemic words. Hence, we
need to propose new similarity measure without the
assumption that each of words is uncorrelated.
We propose a text categorization system using the
Earth Mover’s Distance (EMD) as a similarity mea-
sure between documents. The EMD needs no as-
sumption that each of words is uncorrelated. Alter-
natively, it demands a distance between the words.
We define the distance according to relationship be-
tween the words. To capture the relationship between
the words, we use the co-occurrence frequency of the
words. The co-occurrence is represented as the co-
occurrence probability and the distance is computed
according to the probability. To evaluate the propos-
ing method, we carry out an experiment that ModApte
split of Reuters-21578 text categorization test collec-
tion is categorized with the proposing method and a
conventional method. We confirm that the proposing
method is superior to a conventional method in the
view of a precision rate.
2 PREVIOUS WORK
Text categorization is the activity of labeling natural
language texts with predefined categories. To realize
the text categorization, various machine learning al-
gorithms are applied to it(Sebastiani, 2002). Expert
Network(Yang and Chute, 1994), which is one of the
text categorization systems using k-nearest neighbor-
hood(Mitchell, 1997), achieves high recall and pre-
cision. The Expert Network uses a cosine measure
between an input document and a labeled document.
Text categorization systemsusually deal with texts
represented as vectors by the Vector Space Model
(VSM)(Salton et al., 1975). In the VSM, documents
632
Yanagimoto H. and Omatu S. (2007).
TEXT CATEGORIZATION USING EARTH MOVER’S DISTANCE AS SIMILARITY MEASURE.
In Proceedings of the Ninth International Conference on Enterprise Information Systems - ISAS, pages 632-635
DOI: 10.5220/0002406606320635
Copyright
c
SciTePress

are represented as real-value vectors whose elements
are weights for indexing words. When a retrieval sys-
tem retrieves documents which relate to a query, a
similarity measure between a document and the query
is calculated by a cosine measure. In this case we
assume that the vector space consists of orthogonal
basis vectors. However, this assumption does not al-
ways fulfill because of synonyms, polysemic words,
co-occurrence of words. Dependency of words dis-
torts the similarity measure between a document.
Wan et al.(Wan and Peng, 2005) propose a simi-
larity measure regarding dependency between words.
They use the Earth Mover’s Distance (EMD)(Rubner
et al., 2000) to calculate the similarity measure be-
tween documents. They use the electronic lexical
database - WordNet(Miller et al., 1990) and define
the distance depending on semantical vicinity. How-
ever, it is difficult to digitize the semantical vicin-
ity since the vicinity is defined in linguistics. A
well-known problem with thesaurus-based method is
that general-purpose thesauri do not have sufficient
vocabulary coverage crossing different applications.
The thesaurus-based method cannot cover neologisms
since almost all thesauruses are often maintained with
man power. Hence, we tackle these problems by im-
provement of similarity measure.
3 TEXT CATEGORIZATION
USING EMD
3.1 Vector Space Model
In the VSM, all documents written with natural lan-
guages is represented as vectors to deal with them on
computers. An element of the document vector de-
notes a weight of an indexing word included in the
document. The weight for the indexing words is cal-
culated by tf*idf.
w
i
j
= tf
i
j
log
N
df
j
(1)
where w
i
j
is a weight of a term T
j
in a document Doc
i
,
tf
i
j
is a term frequency of T
j
in Doc
i
, df
j
is a document
frequency of T
j
and N is the total number of the doc-
uments. A document Doc
i
is represented as the doc-
ument vector d
i
= (w
i
1
, w
i
2
, ··· , w
i
V
) where V denotes
the number of vocabulary for the corpus.
The cosine measure is often used as a similarity
measure between documents. The cosine measure
sim
cos
(d
i
, d
j
) between between documents; Doc
i
and
Doc
j
, is calculated below.
sim
cos
(d
i
, d
j
) =
d
i
d
T
j
k d
i
k
2
k d
j
k
2
(2)
where T denotes transposition of a matrix and k d
i
k
2
denotes a quadratic norm of d
i
. Since we make the
norms of all documents be equal to 1 in an experi-
ment, Equation (2) is transformed into below.
sim
cos
(d
i
, d
j
) = d
i
d
T
j
(3)
3.2 Earth Mover’s Distance
The EMD is a method to evaluate similarity be-
tween two multi-dimensional distributions in a fea-
ture space where a distance between features can
be defined. The distributions are represented as
signatures which have feature vectors and weights
for the features. A multi-dimensional distribution
P which is represented as the signature is P =
{(p
1
, w
p
1
), (p
2
, w
p
2
), ··· , (p
m
, w
p
m
)} where p
i
is a
feature vector and w
p
i
is a weight for the feature vec-
tor. Now, let Q = {(q
1
, w
q
1
), (q
2
, w
q
2
), ··· , (q
n
, w
q
n
)}
be the second distribution.
A distance between the features is defined in the
feature space and is called a ground distance. Let
D = [d
ij
] be a ground distance matrix where d
ij
is the
ground distance between the features; p
i
and q
j
. Let
F = [ f
ij
] be a flow matrix where f
ij
is the flow be-
tween p
i
and q
j
. Here, we want to find an optimal
flow F
∗
where makes a following cost function be a
minimum.
WORK(P, Q, F) =
m
∑
i=1
n
∑
j=1
d
ij
f
ij
(4)
The cost function is minimized under the following
constraints:
f
ij
≥ 0 1 ≤ i ≤ m, 1 ≤ j ≤ n (5)
n
∑
j=1
f
ij
≤ w
p
i
1 ≤ i ≤ m (6)
m
∑
i=1
f
ij
≤ w
q
j
1 ≤ j ≤ n (7)
m
∑
i=1
n
∑
j=1
f
ij
= min(
m
∑
i=1
w
p
i
,
n
∑
j=1
w
q
j
) (8)
Using the optimal flow F
∗
, the earth mover’s dis-
tance EMD(P, Q) is defined.
EMD(P, Q) =
∑
m
i=1
∑
n
j=1
d
ij
f
ij
∗
∑
m
i=1
∑
n
j=1
f
ij
∗
(9)
Since the resulting work WORK(P, Q, F
∗
) depends on
the size of a signature, we need to normalize the re-
sulting work. If the resulting work is not normalized,
the smaller signature is favorable and this similarity
measure is not desirable.
TEXT CATEGORIZATION USING EARTH MOVER'S DISTANCE AS SIMILARITY MEASURE
633

3.3 Earth Mover’s Distance for Texts
Documents need to be represented as the signatures to
compute similarity between the documents using the
EMD. Let a feature vector p
i
be an indexing word and
let a weight for the feature be a weight for the index-
ing word. A document Doc
i
is represented as a signa-
ture D
i
= {(T
1
, w
i
1
), (T
2
, w
i
2
), ··· , (T
m
, w
i
m
)} which in-
cludes all indexing words in only the document Doc
i
.
We need to define the ground distance between
indexing words to compute the EMD. We define the
ground distance between the indexing words depend-
ing on relationship between the indexing words. The
relationship between the indexing words is defined
based on the co-occurrence of the indexing words.
Now let co-occurrence frequency of T
i
and T
j
be
occur(T
i
, T
j
). A conditional probability P(T
i
|T
i
)
which shows a probability that T
j
occurs in a sentence
including T
i
is defined below.
P(T
j
|T
i
) =
occur(T
i
, T
j
)
∑
j
occur(T
i
, T
j
))
(10)
The ground distance d
ij
from T
i
to T
j
is defined below
using the conditional probability P(T
i
|T
i
).
d
ij
= 1− P(T
j
|T
i
) (11)
Since the EMD is not similarity measure, the sim-
ilarity measure between the documents is computed
using the EMD. When the sum of the weights for the
indexing words in a signature is 1, the next formula
consists.
EMD(D
k
, D
l
) ≤ 1 (12)
if
∑
i
w
k
i
= 1 and
∑
i
w
l
i
= 1
We define the similarity measure sim
EMD
(D
k
, D
l
) be-
tween Doc
k
and Doc
l
.
sim
EMD
(D
k
, D
l
) = 1− EMD(D
k
, D
l
) (13)
3.4 Text Categorization
The proposing system uses architecture of the Expert
Network (ExpNet)(Yang and Chute, 1994). The Exp-
Net consists of two steps: a similarity computing step
and a category rank step. In the similarity computing
step, the ExpNet computes cosine measure between
an unlabeled document and a labeled document. It
selects top K cosine measure labeled documents and
uses them to decide a category for the unlabeled doc-
ument. Our system uses the EMD to select K labeled
documents.
In the category rank step, the ExpNet uses the K
labeled documents to decide a category for the unla-
beled document. In the ExpNetP(c
k
|d
i
) is defined as
Table 1: Content of Reuters-21578 using experiments.
documents unique words
Training 7,733 17,488
Test 3,008 10,731
a conditional probability of a category c
k
related to a
document Doc
i
judged by human previously. Given
the labeled documents, the conditional probability is
estimated as
P(c
k
|d
i
) =
frequency of category c
k
for d
i
frequency of d
i
in labeled documents
(14)
Relevance measure of each category rel(c
k
|d
i
) is de-
fined as a weighted sum of the cosine similarity.
rel
cos
(c
k
|x) =
K
∑
j=1
P(c
k
|d
j
)sim
cos
(x, d
j
) (15)
The x denotes a document vector of the unlabeled
document. Since our method uses the EMD, rel(c
k
|X)
is defined as
rel
EMD
(c
k
|X) =
K
∑
j=1
P(c
k
|D
j
)sim
EMD
(X, D
j
) (16)
where X denotes a signature for the unlabeled docu-
ment.
4 EXPRIMENTS
We carried out text categorization for Reuters-21578
text categorization test collection. We used ModAPte
split of the Reuters-21578. The ModApte split con-
sists of 9,603 training documents and 3,299 test docu-
ments. In the experiment we used 7,733 training doc-
uments and 3,008 test documents including more than
one indexing word after we removed SMART stop-
list and applied Porter algorithm(Porter, 1980). On
average a training document and a test document are
labeled with 1.2 categories. 115 different categories
exist in the training documents and 93 different cate-
gories exist in the test documents. And 3 categories
in the test documents do not exit in training docu-
ments. Table 1 shows the content of the training doc-
uments and the test documents. Since 3,407 indexing
words out of 10,731 unique words in the test docu-
ments was not included in the training documents, we
used only 7,324 words to compute the similarity be-
tween a training document and a test document.
The experiment was that a test documents was
labeled one category ˆc which has the maximum
rel
cos
(c
k
|x) or the maximum rel
EMD
(c
k
|X) although
ICEIS 2007 - International Conference on Enterprise Information Systems
634
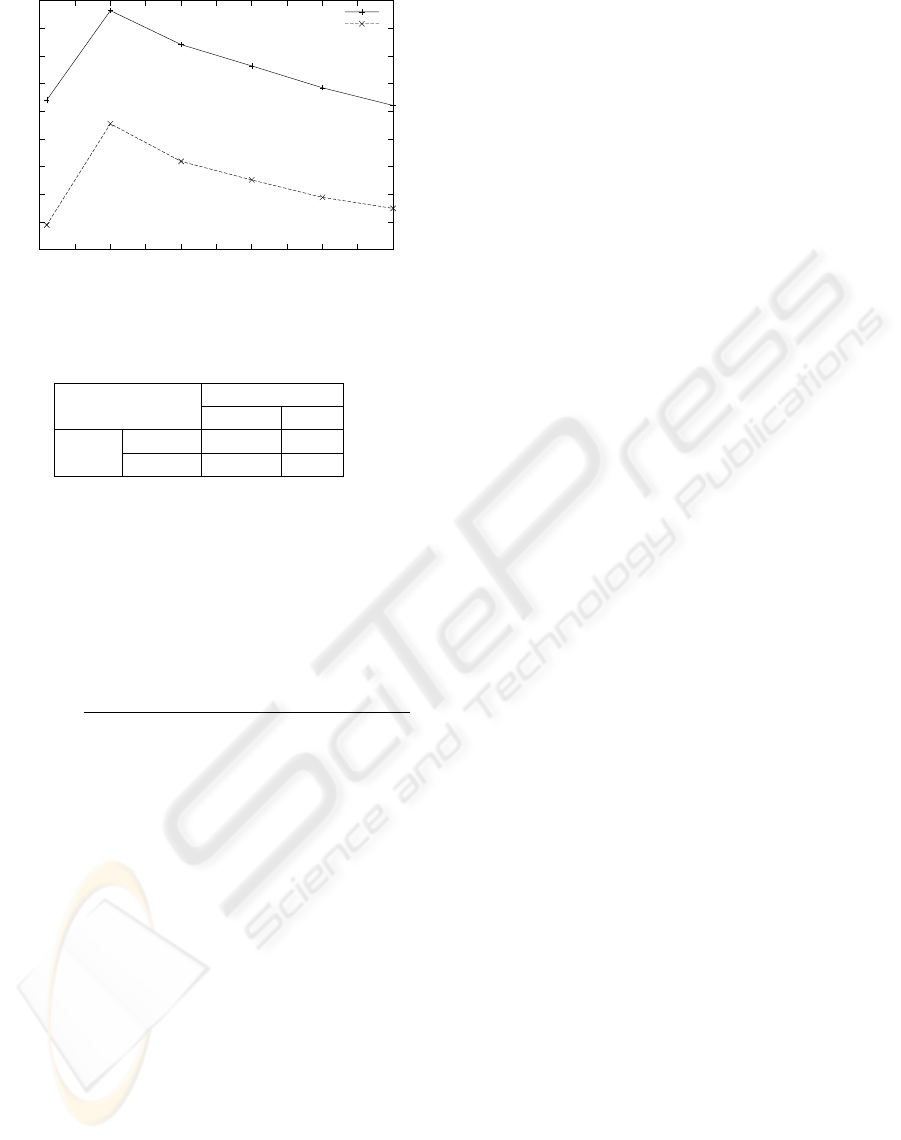
77
78
79
80
81
82
83
84
85
86
0 5 10 15 20 25 30 35 40 45 50
Precision
K
"EMD"
"VSM"
Figure 1: Precision rate on K=1, 10, 20, 30, 40, 50.
Table 2: The number of correct documents and error docu-
ments for VSM and EMD.
VSM
correct error
EMD correct 2,359 217
error 94 338
test documents were labeled with several categories.
Hence, when an estimated category ˆc is included in
categories labeled in a test document as correct cat-
egories, we consider that that the text categorization
algorithm can label the document correctly.
To evaluate each method based on previous idea
we used precision rate for the test documents.
precision=
the number of correct labeled documents
the number of all test documents
(17)
The precision rate depends on a value of K in
Equation (15) and Equation (16). Figure 1 shows
precision rates for cosine similarity (VSM) and our
proposing method (EMD) on K = 1, 10, 20, 30, 40, 50.
Our proposing method, EMD was superior to a con-
ventional method, VSM on every K-values. The pre-
cision rate on K = 10 was the maximum value for
VSM and EMD. The precision rate of VSM is 81.6%
and the one of EMD is 85.6%. Hence, the difference
of the precision rates is about 4.0%.
To discuss text categorization ability Table 2
shows the number of error documents and correct
documents for VSM and EMD. The error documents
for EMD was smaller than the one for VSM because
of improvement of the precision rate.
In figure 1 we confirmed that it could improve
the precision rate to regard the dependency of in-
dexing words. In table 2 we think that we can im-
prove our method. Our method makes a word related
to too many words or contextually unrelated words.
Hence, our method could not label the documents
which VSM could label correctly. To make a word
related to appropriate words increases the similarity
between documents which the VSM can not evaluate.
Hence, the number of error documents in VSM de-
creases. On the other hand, to make a word related to
too many words boosts the similarity between docu-
ments which are unrelated. This cause the number of
error documents, which can not exist in the VSM, to
increase. We need to discuss how to define the dis-
tance between the indexing words beside the condi-
tional probability P(T
i
|T
j
).
5 CONCLUSION
We proposed a text categorization method using Earth
Mover’s Distance as a similarity measure. We re-
alized to compute similarity between documents re-
garding the dependency of words using the Earth
Mover’s Distance. The distance between the words
is defined with the conditional probability that one
word occur with the other word in the same sentence.
We confirm that the proposing method is superior to
a conventional method using cosine similarity with
Reuters-21578 text categorization test collection.
We will discuss how to define the distance be-
tween words beside the conditional probability and
improve our proposing method.
REFERENCES
Miller, G. A., Beckwith, R., Fellbaum, C., Gross, D., and
Miller, K. J. (1990). Introduction to wordnet: An on-
line lexical database. International Journal of Lexi-
cography, 3(4):235–312.
Mitchell, T. M. (1997). Machine Learning. McGraw Hill,
New York, US.
Porter, M. (1980). An algorithm for suffix stripping. Pro-
gram, 14(3):130–137.
Rubner, Y., Tomasi, C., and Guibas, L. (2000). The earth
mover’s distance as a metric for image retrieval. Inter-
national Journal of Computer Vision, 40(2):99–121.
Salton, G., Wong, A., and Yang, C. S. (1975). A vector
space model for automatic indexing. Communications
of the ACM, 18(11):613–620.
Sebastiani, F. (2002). Machine learning in automated text
categorization. ACM Computing Surveys, 34(1):1–47.
Wan, X. and Peng, Y. (2005). The earth mover’s distance as
a semantic measure for document similarity. In the
14th ACM International Conference on Information
and Knowledge Management, pages 301–302. ACM
Press.
Yang, Y. and Chute, C. G. (1994). An example-
based mapping method for text categorization and re-
trieval. ACM Transactions on Information Systems,
12(3):252–277.
TEXT CATEGORIZATION USING EARTH MOVER'S DISTANCE AS SIMILARITY MEASURE
635
