
EFFICIENT OBJECT DETECTION USING PCA MODELING AND
REDUCED SET SVDD
Rudra N. Hota and Venkataramana Kini B.
Research and Technology Unit, Honeywell Technology Solutions Lab, Bangalore, India
Keywords:
Object Detection, PCA modeling and reduced set SVDD.
Abstract:
Object detection problem is traditionally tackled as two class problem. Wherein the non object classes are
not precisely defined. In this paper we propose cascade of principal component modeling with associated test
statistics and reduced set support vector data description for efficient object detection, both of which hinge
mainly on modeling of object class training data. The PCA modeling enables quick rejection of comparatively
obvious non object in initial stage of the cascade to gain computation advantage. The reduced set SVDD is
applied in latter stages of cascade to classify relatively difficult images. This combination of PCA modeling
and reduced set support vector data description leads to a good object detection with simple pixel features.
1 INTRODUCTION
The object detection is a process of isolating the ob-
ject of interest from it’s surroundings, e.g. detection
of people in an image snapshot. We human beings
can do this effortlessly but when it comes to doing the
same automatically by using machines we encounter
many problems, in terms of scales at which they are
present, orientation, illumination etc.
Traditionally in machine learning paradigm of ob-
ject detection problem is tackled using two class prob-
lem, i.e. by having positive and negative class (ob-
ject and non-object classes respectively) training data
sets. The training procedure strives to find a optimal
boundary between these two classes in the space of
features with the expectation of good generalization.
This kind of approach is followed successfully ((Vi-
ola and Jones, 2001), (Romdhani et al., 2001), (Row-
ley et al., 1997)) by the researchers by having variety
of object class data in terms of several thousands and
hundred thousands from non-object class. It is nat-
ural to include variety of data (by applying different
affine transformations such as orientation, scale and
with different illumination) for positive class, but for
negative class we can not define precisely what is va-
riety of data to collect. Hence, the negative class re-
mains ill defined. We could collect few hundreds of
thousands (or more) of negative class data, but it is
insufficient as negative class is of virtually infinite in
size.
Another framework for object detection problem
often used by the machine learning community is
of developing a model /data description (which de-
scribes structure in the data) only for the positive
class. The negative class data is used mostly for fine
tuning of the boundary around positive class. The
classification (detection in true sense) involves look-
ing for object features in given image. If such features
are found, then object is detected otherwise the image
is labeled as non-object.
The simple model for this kind of approach is
Principal Component Analysis(PCA). This appears to
be natural way of describing the objects. The PCA
features in the form of eigenfaces (Moghaddam and
Pentland, 1997) has been applied successfully for face
recognition and related tasks. In this paper we uti-
lize PCA features for describing the structure in tar-
get object class data. The test data is projected onto
this model represented by major principal directions.
These principal directions being few in number, lead-
ing to quick rejection of obvious negative samples.
We utilize the test statistics which are traditionally
used in fault detection (Venkatasubramanian et al.,
2003) (Yue and Qin, 2001) community. These statis-
tics provide thresholds which are effectively used to
discard non-object images. Here, it should be noted
that the PCA model is used as a coarse model for
object class data, the different directions might have
different discriminatory power (Sun et al., 2002), but
overallmodel for object class based on dominantprin-
222
N. Hota R. and Kini B. V. (2008).
EFFICIENT OBJECT DETECTION USING PCA MODELING AND REDUCED SET SVDD.
In Proceedings of the Third International Conference on Computer Vision Theory and Applications, pages 222-227
DOI: 10.5220/0001079402220227
Copyright
c
SciTePress

cipal directions gives an envelop around object class
data and provides strategy for quick rejection of non-
object class data.
The kernel methods have been proposed for the
task developing data based models as well. The
traditional data based modeling technique PCA is
extended to handle higher order correlations in the
data by mapping into higher dimensional feature
space - Kernel Principal Component Analysis(KPCA)
(Scholkopf et al., 1998). It is simple enough com-
pared to PCA in terms of just finding eigen value
decomposition. It finds the uncorrelated features in
higher dimensional space, explaining structure of pos-
itive class data. But in object detection problems as
we use many thousands of object class data for train-
ing of KPCA, the run-time computational complexity
blows up.
In this work, we applied cascaded structure for
object detection, in which the removal negative sam-
ples are taken care in different stages according to
their degree of closeness to positive class distribution.
Therefore, it it required to have strong classifiers in
the later stages for separating difficult negative sam-
ples from positive class. Hence, for discriminating
non-objects which are like objects, we need to resort
to strong classifiers (Heisele et al., 2003). Tradition-
ally artificial neural networks are developed as strong
classifier. However, neural networks demand lengthy
training, convergence of the training process is some-
times uncertain and choice of network architectures
remains somewhat of an art. In early 1990s, the kernel
methods (Vapnik, 1999) such as Support Vector Clas-
sifiers(SVC), regressors are developed for classifica-
tion and function approximation tasks. The advan-
tage of these methods over neural network methods is
that they implicitly solve the nonlinear problem. Also
they exhibit good generalization capability because of
their regularization properties.
Another data based modeling technique in ker-
nel feature space is Support Vector Data Description
(SVDD)(Tax and R.P.W, 2004). It tries to find a en-
closing sphere of minimal volume for positive class
data in high dimensional feature space unlike SVC,
which tries to find the hyperplane between positive
and negative class training data. This kind of model is
particularly suited for object detection problem (Seo
and Ko, 2004) (Tax and R.P.W, 2004). But, the daunt-
ing disadvantage with SVDD when applied to object
detection is the number of kernel computations in-
volved. The number of kernel computations involved
is order of the number of support vectors generated
during training procedure. In typical problems of ob-
ject detection (face detection and people detection)
that we are targeting, these support vectors are as high
as few thousands. Because of these high number of
Support Vectors (SVs) the computational cost may be
sometimes between half a minute to few minutes.
In this paper to tackle this computational cost, we
propose to “leverage the technique of reducing the
number of support vectors (Romdhani et al., 2001)
into SVDD”. The number of support vectors can
be reduced to few hundreds from thousands without
compromising much on accuracy.
The quick rejection of non-object data using lin-
ear PCA and associated test statistics, followed by
Reduced Set SVDD leads to a good balance between
speed and accuracy. Hence, we propose a efficient
(both in terms of speed and accuracy) method for the
problem of object detection by novel cascade of lin-
ear PCA modeling and series of Reduced Set SVDD
(RSSVDD) with increasing number of reduced set
SVs.
The outline of the paper is as follows. The method
for quick rejection based on PCA modeling is ex-
plained in next section. The RSSVDD is explained in
section 3. The overall approach of cascaded PCA and
RSVDDs is explained in section 4. Section 5 gives ex-
periments and results of object detection (specifically
on face data). In section 6 we draw some conclusions
of this work and plans for future work.
2 PCA MODELING OF OBJECT
CLASS AND THRESHOLDING
STATISTICS
PCA is a versatile data analysis tool. It can be consid-
ered as data modeling tool, the major principal com-
ponents capturing most of the variance in the covari-
ance matrix of data. The rest of the components are
assumed to represent noise in the data. The steps in-
volved in PCA modeling is summarized in below al-
gorithm. PCA based feature extraction has received
considerable attention in computer vision area. In
previous works (Moghaddam and Pentland, 1997) the
image is represented by features in a low dimensional
space spanned by the principal components. These
features are further utilized in classifier. PCA is pre-
dominantly used for extracting features and dimen-
sionality reduction, the modeling perspective is miss-
ing.
PCA is traditionally applied by Chemometrics with
modeling perspective for the purpose of fault detec-
tion. Fault detection using PCA models is normally
accomplished by applying two statistics. The squared
prediction error SPE , which indicates the amount by
which a sample deviates from the model, is defined
EFFICIENT OBJECT DETECTION USING PCA MODELING AND REDUCED SET SVDD
223

Table 1: Algorithm for PCA model training on Object class
data.
1. Given the data set X = x
1
. . .x
n
from object class find the mean vector
µ =
1
n
∑
n
1
x
i
,
2.Find the covariance matrix C =
1
n−1
∑
n
1
(x
i
− µ)(x
i
− µ)
′
3.Eigen value decompose the covariance matrix C = PΛP
4. Choose the principal components
ˆ
P corresponding dominant eigen
values and remaining eigen vectors
˜
P represent minor components.
by
SPE = x
′
˜
P
˜
P
′
x (1)
Hotellings T
2
statistic, which measures deviation of a
sample inside the model, takes the form
T
2
= x
′
ˆ
PΛ
−1
ˆ
P
′
x (2)
Both of these indices follow chi square distribution
under the normality assumption of object class data.
The δ
2
and τ
2
limits (for SPE and T
2
respectively)are
found for given confidence level. It is to be noted
that SPE departs from limits whenever the covariance
structure breaks down, where as T
2
violation happens
whenever the different contributors (PCA scores) go
out of range. For object detection problem, when-
ever any one of these indices crosses limits, we can
infer that image is from non-object class. Therefore it
makes sense to combine them. (Yue and Qin, 2001)
has proposed combination index defined as:
ρ = c
SPE
δ
2
+ (1− c)
T
2
τ
2
, c ∈ (0, 1) (3)
Since ρ is linear combination of T
2
and SPE the limits
can be found using chi square distribution.
3 REDUCED SET SVDD
First we introduce the notation by explaining SVDD
(Tax and R.P.W, 2004) in input space. Given the
positive class data-set, SVDD tries to find enclosing
sphere around data which has minimum volume. By
minimizing the sphere volume, SVDD minimizes the
detection error (i.e. the chance of accepting outlier
objects).
Given positive class data X = {x
1
. . . x
n
} the
SVDD attempts to find a hyper-sphere with center c
and radius R which encloses most of the data, i.e. the
volume of the hyper-sphere is minimized. That is to
minimizing the objective function:
F(R, c) = R
2
s.t.kx
i
− ck
2
≤ R
2
∀i (4)
The positive class data set might contain some out-
liers. To allow such possible outliers, introducing
slack variables ξ
i
into 4 leads to primal solution:
F(R, c) = R
2
+C
∑
i
ξ
i
s.t.kx
i
− ck
2
≤ R
2
+ ξ
i
ξ
i
≥ 0 ∀i (5)
The parameter C is a regularization parameter. In-
troducing Lagrange multipliers and setting the partial
derivatives w.r.t. R, c and ξ
i
leads to dual solution:
L =
∑
i
α
i
(x
i
· x
i
) −
∑
i, j
α
i
α
j
(x
i
· x
j
) (6)
When 0 < α
i
< C implies kx
i
− ck
2
= R
2
, i.e. these
data points lie on boundary of SVDD solution. For
any test data point x, label is decided to be belonging
to object class based on distance to center smaller or
equal than the radius:
kx− ck
2
= (x· x)− 2
∑
i
α
i
(x·x
i
) −
∑
i, j
α
i
α
j
(x
i
· x
j
) ≤ R
2
(7)
R
2
is found by substituting for x with any of the SVs.
For flexible data descriptions the dot products are
replaced by corresponding kernel dot products, i.e.
x 7→ Φ(x). Also the negative data objects can be uti-
lized in fine tuning the data description boundary of
SVDD (Tax and R.P.W, 2004).
As discussed in introduction, (section 1) the solu-
tion generated by SVDD involves large percentage of
data points as SVs, resulting in high run-time com-
plexity in object detection problems.
In this work, the methodology adopted to reduce
the number of SVs is derived from (Romdhani et al.,
2001). Let N
s
number of SVs obtained for SVDD
training. The sum of SVs weighted by non-zero α is
given by
Ψ =
N
s
∑
i=1
α
i
Φ(x
i
) (8)
By approximating the N
s
number of SVs by new N
rs
number of SVs we can reduce the computationalcom-
plexity. The approximation of Ψ is:
ˆ
Ψ =
N
rs
∑
i=1
β
i
Φ(ˆx
i
) (9)
Where, β ∈ ℜ and ˆx
i
are approximate SVs. We can
usually achieve N
rs
≪ N
s
with out loss of much ac-
curacy. To achieve this, (Romdhani et al., 2001) has
suggested to minimize the norm kΨ−
ˆ
Ψk
2
, which can
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
224
−10 −5 0 5
−10
−5
0
5
Feature 1
Feature 2
−10 −5 0 5
−10
−5
0
5
Feature 1
Feature 2
−10 −5 0 5
−10
−5
0
5
Feature 1
Feature 2
(a) (b) (c)
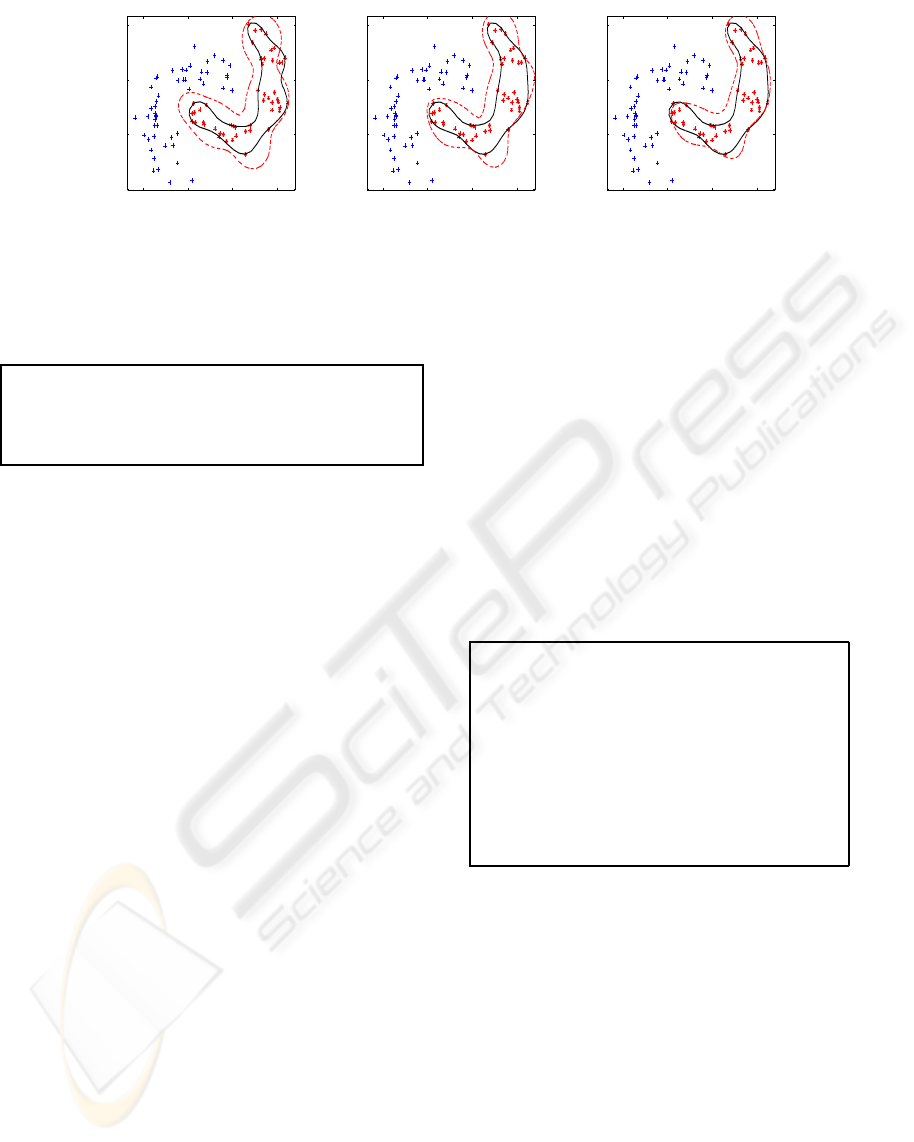
Figure 1: Dotted boundary represents (a) RSVDD with 30% SVs (b) RSVDD with 40% SVs (c) RSVDD with 60% SVs.
Table 2: Algorithm for RSSVDD training on Object class.
1. Given the data set X = x
1
. . . x
n
find find SVs using SVDD algorithm
2.Find the reduced set SVs by minimizing kΨ−
ˆ
Ψk
2
3. Choose the cascade of RSSVDDs starting from a minimum number
of reduced set SVs decided based on classification performance on
training data set
be rewritten in terms of only kernel dot products.
They also provide an iterative algorithm for finding
reduced SVs, starting from one SV. The Figure 1
shows a simple banana data example, wherein star
shaped positive class data is modeled using differ-
ent percentages of original SVs. The solid line en-
velop around positive class represents original SVDD
boundary. The algorithm for RSSVDD is summarized
in Table 2.
4 OUR APPROACH - EFFICIENT
CASCADE OF PCA AND SVDD
ALGORITHM FOR OBJECT
DETECTION
In object detection problems, such as face detection,
the object can occur at any position of the image and
in several scales. Under such cases the automated
object detection algorithm has to search the image
either with a fixed size of sub-window in a pyramidal
structure or by varying the scale of the search window
starting from a desired scale. For a standard size
image the percentage of sub-windows containing
target object is usually less than one percent of
windows to be scanned for the whole image. This
problem demands a coarse-to-fine cascade classifier
strategy to search the target object, i.e. in the initial
stage of the detector it should be able to remove as
many negative patterns as possible, retaining almost
all positive patterns. As the level increases the task of
separating the object like negative class objects from
the target object becomes tougher. Hence cas-
caded classifier with better accuracy at later stage
(where we can afford higher computational complex-
ity) of the detector is suitable. Our approach uses
cascade of linear PCA model followed by series of
one-class RSSVDD classifiers with increasing num-
ber of support vectors. There are many possible good
features for face detection, presented in literature.
For simplicity we consider only pixel values of the
image sub-window as feature vector. Our method can
also be applied with other sophisticated features
Table 3: Algorithm for Object detection using PCA and
RSVDD cascaded classifiers.
1. Training: Given target object class image data X = {x
1
. . .x
n
} perform
(1.a) PCA model training (Table 1) and find the threshold by using
equation (3)
(1.b) SVDD training and find Reduced set SVs (Table 2), decide
on minimum number of RSSV
2. Testing: Given the test image, form the sub-windows and for
each vector x representing sub-window
(2.a) Project x onto principal directions found in (1.a) and
if it crosses the threshold,
discard the sub-window as non-object and continue with
new sub-window,
else
Start with RSSVDD with least number of SVs in cascade, if
accepted by current RSVDD continue with next RSVDD in
cascade until final RSVDD is reached, label accordingly.
(Gabor, Haar wavelet, etc.) to improve the perfor-
mance. The overall approach (training and testing) is
explained in below algorithm.
5 EXPERIMENTS AND
DISCUSSION
Usually, in object detection problem the number neg-
ative sample is much more as compared to that of
positive samples. This is because the negative class
is always ill defined as we have discussed in ear-
lier section. To discard comparatively easier negative
samples we applied PCA modeling and more difficult
false alarms are handled by reduced set SVDD in cas-
EFFICIENT OBJECT DETECTION USING PCA MODELING AND REDUCED SET SVDD
225
0 0.5 1 1.5 2 2.5 3
0
50
100
150
200
250
300
350
400
450
Combined Test Statitic
Frequency
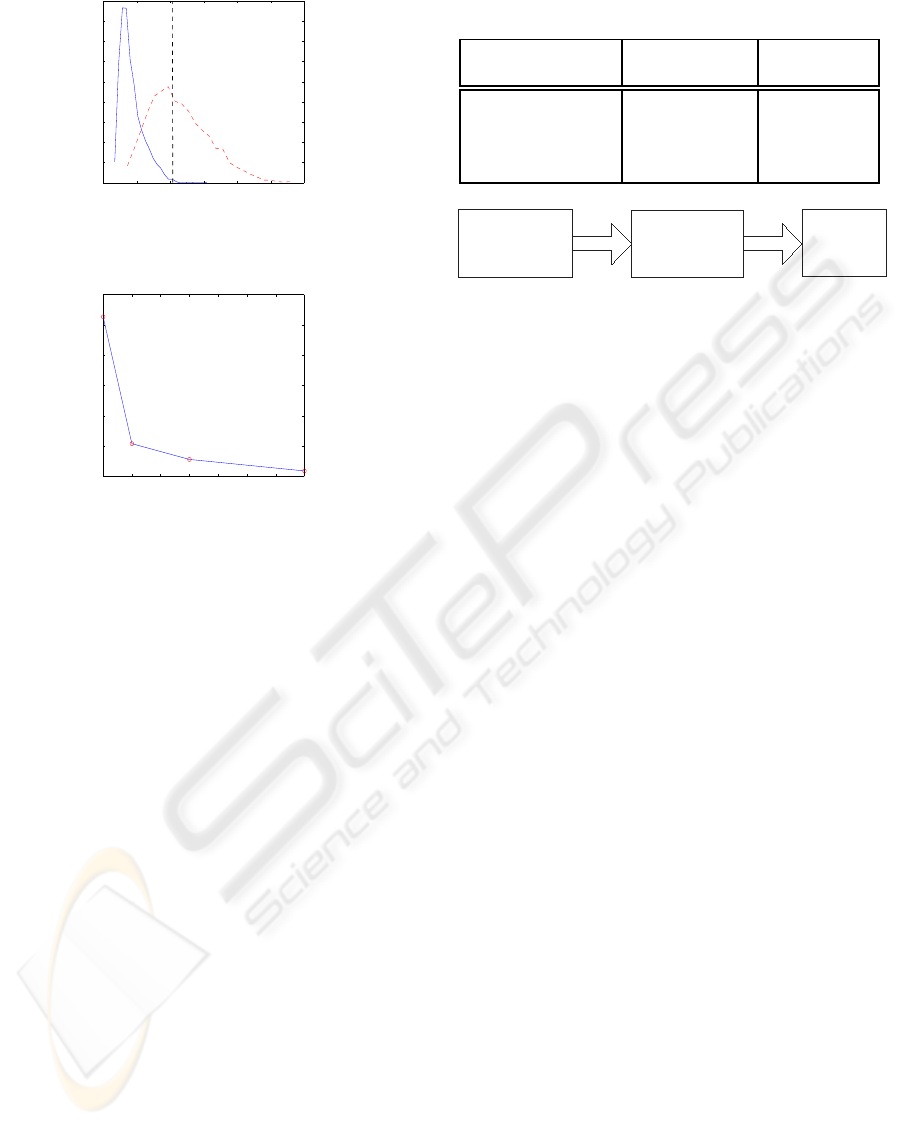
Figure 2: Quick rejection of non faces using PCA with test
statistics.
30 40 50 60 70 80 90 100
9.5
10
10.5
11
11.5
12
12.5
# of SVs
% of False alarm
Figure 3: Percentage of reduced SVs vs false alarm rate.
caded structure.
Data set: In our experiments of face
detection we used CBCL face data set
[http://www.ai.mit.edu/projects/cbcl/ software-
dataset/index.html], which contains 2429 faces and
4585 non face samples for training and 472 faces
and 23573 non face sample for testing. For our
experiment we have selected randomly 2000 each
from face and non-face samples from training set for
training purpose and rest of the samples are used for
testing.
After applying initial filtering by PCA model with
associated combined test statistics the negative pat-
terns which are difficult to classify are fed to SVDD.
The PCA model is able to discard more than 50%
of non-face class data, retaining almost all face class
data. The number of principal components retained
is equal to the components which captures 90% of
the variance (which is equal to 8 principal direc-
tions). The threshold based on chi square distribu-
tion is found to be equal to 1.08 (with c = 0.5 as
shown in Figure 2 by dashed vertical line. The two
frequency curves (solid and dashed respectively) rep-
resents frequency with which face class data and non-
face class data appears corresponding to combined
statistic. Here, randomly 2000 number face and non
face class data is utilized to show the quick rejection
capability of non-faces at the same retaining almost
all face class data. Out of these 2000 face class data
Table 4: Performance of RSSVDD on Face detection.
% of SV retained Detection rate False Alarm
(%) (%)
100 94 9.5
60 94 10
40 94 9.8
30 94 12
PCA Modeling
with
Test Statistics
Reduced Set
SVDD
(40% SVs)
SVDD
Figure 4: Cascade structure for face detection.
700 data points which have higher value of ρ (eqn 3)is
retained for SVDD training and non-face data which
have ρ less than 1.5 retained for fine tuning of SVDD
boundary in next stage of cascade. The detection rate
on test data the by applying PCA model is found to be
99.3% with false alarm rate of 58%.
With the data retained by PCA we analyzed the
performance of SVDD by increasing the number of
reduced support vectors (as explained in section 3).
By using 100% of the support vectors for the trained
SVDD we achieved 94% detection accuracy during
testing with 9.5% of false alarm. By reducing the
support vector to 30% (originally SVDD training pro-
duced 139 SVs from 700 face class training data) the
false alarm rate increases to near about 12% with re-
taining same accuracy of detection rate. With 40%
and 60% of SVs, the false alarm rate further reduces
to around 10% and 9.8% respectively. The plot of
percentage of support vectors vs false alarm rate is
depicted in Figure 3. Further increase in reduced set
of support vectors lead to better performance in terms
of lesser false alarm at the same level of detection
rate. This can be because of some generalization ca-
pability provided by approximate reduced SVs. When
we reduce the SVs by certain percentage, the runtime
computational complexity also reduced by approxi-
mately same percentage. Hence, we could reduce the
runtime computational complexity of SVDD with out
much compromising on the accuracy (false alarm in-
creased by just 0.3% when SVs reduced to 40% from
100% with same detection rate). Therefore, we pro-
pose a cascade structure shown in Figure 4 for face
detection problem. The combination of PCA model-
ing and RSSVDD drastically reduced overall compu-
tational complexity by about 80% as compared to a
single monolithic SVDD classifier.
It is to be noted that in (Seo and Ko, 2004) by us-
ing the color information in SVDD false alarm rate
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
226

was as low as 1% at same detection rate as that of
our experiments. Hence, by making use of color fea-
tures or other sophisticated features and preprocess-
ing techniques the false alarm rate can be reduced
substantially. However, in this work the goal was to
show the efficacy of the PCA and RSSVVD cascade
approach for the problem of face detection.
6 CONCLUSIONS AND FUTURE
WORK
In this paper we proposed cascade of PCA model-
ing with associated test statistic and reduced set sup-
port vector data description for efficient object detec-
tion. The PCA modeling enabled quick rejection up to
40− 50% of comparatively obvious non-faces to gain
computation advantage. The reduced set SVDD ap-
plied in later stage of cascade to classify relatively dif-
ficult images. This novel combination of PCA mod-
eling and RSSVDD lead to good face detection at re-
duced computational cost by using only simple pixel
features.
Motivated by these results, in future we plan to ap-
ply this approach to other object detection tasks such
as vehicle, people detection. Further in future we plan
to improve the performance of object detection using
more sophisticated feature set.
REFERENCES
Heisele, B., Serre, T., Prentice, S., and Poggio, T. (2003).
Hierarchial classification and feature reduction for fast
face detection with support vector machines. In Pat-
tern Recognition Society.
Moghaddam, B. and Pentland, A. (1997). Probabilistic vi-
sual learning for object representation. In IEEE Trans-
actions on Pattern Analysis and Machine Intelligence.
Romdhani, S., Torr, P., Scholkopf, B., and Blake, A. (2001).
Computationally efficient face detection. In 8th Int.
Conf on Computer vision.
Rowley, H. A., Baluja, S., and Kanade, T. (1997). Rota-
tion invariant neural network based face detection. In
Computer Science technical report CMU-CS-97-201.
Scholkopf, B., Smola, A., and Muller, K. (1998). Nonlinear
component analysis as a kernel eigenvalue problem.
In Neural Computation, 10(5):1299-1319.
Seo, J. and Ko, H. (2004). Face detection using support
vector domain description in color images. In ICASSP,
54, 4566,.
Sun, Z., Bebis, G., and Miller, R. (2002). Object detection
using feature subset selection. In Pattern Recognition,
37, 21652176.
Tax, D. and R.P.W, D. (2004). Support vector data descrip-
tion. In Machine Learning, 54, 4566,.
Vapnik, V. N. (1999). The Nature of Statistical Learning
Theory. Springer-Verlag, New York, 2nd edition.
Venkatasubramanian, V., Rengaswamy, R., Yin, K., and
Kavuri, S. N. (2003). A review of process fault de-
tection and diagnosis. In Part I:Quantitative model-
based methods. Comput. Chem.
Viola, P. and Jones, M. (2001). Rapid object detection us-
ing boosted cascaded of simple features. In Conf. on
Computer Vision and Pattern Recognition.
Yue, H. and Qin, S. J. (2001). Reconstruction based
fault identification using combined index. In I & EC
Reasearch, 40, 4403-4414.
EFFICIENT OBJECT DETECTION USING PCA MODELING AND REDUCED SET SVDD
227
