
EFFICIENT OBJECT DETECTION ROBUST TO RST WITH
MINIMAL SET OF EXAMPLES
Sebastien Onis, Henri Sanson, Christophe Garcia
France Telecom RD, 4 rue du clos courtel, Rennes, France
Jean-Luc Dugelay
Eurecom, Sophia Antipolis, France
Keywords:
Object detection, correlation, affine deformation.
Abstract:
In this paper, we present an object detection approach based on a similarity measure combining cross-
correlation and affine deformation. Current object detection systems provide good results, at the expense
of requiring a large training database. The use of correlation anables object detection with very small training
set but is not robust to the luminosity change and RST (Rotation, Scale, translation) transformation. This paper
presents a detection system that first searches the likely positions and scales of the object using image prepro-
cessing and cross-correlation method and secondly, uses a similarity measure based on affine deformation to
confirm or not the predetection. We apply our system to face detection and show the improvement in results
due to the images preprocessing and the affine deformation.
1 INTRODUCTION
Object detection is a classical research topic. Most
of the current object detection systems use machine
learning like Gaussian Mixture Model, Neural Net-
works or Support Vector Machine. In (Viola and
Jones, 2001) the system performs fast object detection
using a cascade of classifiers associated with Haar de-
scriptors. In (Santiago-Mozos et al., 1999) the detec-
tion system extracts features using PCA and a clas-
sifier based on SVM method to detect objects in in-
frared images. (Garcia and Delakis, 2004) perform
face detections using a convolutional neural network
and in (Sung and Poggio, 1998) face detection is done
using GMM to extract face descriptors and a percep-
tron to perform classification. These systems cur-
rently provide the best detection rate, however the fea-
tures used are dependent on the object to detect. Addi-
tionally, they need a large training database, manually
annotated to initialize the detection system, which
represents long and tiresome work. Thus for each ob-
ject to detect, it is necessary to choose or learn good
features and to build a training database.
Correlation is a well-known shape detection
method which has many advantages; easy to imple-
ment, fast, easily adapable to a broad variety of shapes
and not requiring complex feature extractors, or a
large training database. This method however, is not
robust to illumination change, scale variations or ro-
tation.
We describe in this paper an object detection sys-
tem based on cross-correlation, robust to illumina-
tion changes and affine deformations. (MacLean and
Tsotsos, 2007) performs shape detection, using nor-
malized cross-correlation for various object scales us-
ing a pyramid of images. The use of deformation
models for object detection produced interesting re-
sults. (Edwards et al., 1999) performs face detection
using Active Appearance Model deforming the faces
textures in order to maximise the similarity between
the images to compare. (Wakahara et al., 2001) shows
that affine deformation increases the robustness in ro-
tation and scale changes of a character recognition
system based on cross-correlation measures. Our sys-
tem performs a predetection using normalized cross-
correlation on a pyramid of images. We then use sim-
ilarity measure based on affine deformation and cen-
tered normalized cross-correlation to valid or not the
predetection.
Section II describes the predetection system based
on the normalized cross-correlation applied to a fil-
tered pyramid of images. Section III is about the de-
179
Onis S., Sanson H., Garcia C. and Dugelay J. (2008).
EFFICIENT OBJECT DETECTION ROBUST TO RST WITH MINIMAL SET OF EXAMPLES.
In Proceedings of the Third International Conference on Computer Vision Theory and Applications, pages 179-185
DOI: 10.5220/0001083601790185
Copyright
c
SciTePress

cision process which consists of determining whether
a predetection is valid or not. Finally in section IV we
apply our system to face detection and analyse the in-
fluence of the image filters and the affine deformation
compensation upon the detection rate.
2 PREDETECTION
The first step of our system consists of detecting the
likely positions and scales of the searched object. The
system is based on the normalized cross-correlation
between each example image of the object to detect
and a pyramid of filtered images.
2.1 Normalized Cross-Correlation
This section introduces the well-known normalized
cross-correlation method used for object predetection.
We denote the reference image F and the test image
G. We represent F and G by grey level functions f (r)
and g(r). r denotes a 2D loci vector (u, v).
An object is predetected at position p = (i, j) in
G if this point is a local maximum of the normalized
cross-correlation function C(p) and if this maximum
is greater than a given threshold.
σ
f
=
r
∑
r∈Dom
F
f (r)
2
σ
g
=
r
∑
r∈Dom
F
g(p + r)
2
C(p) =
1
σ
f
σ
g
∑
r∈Dom
F
f (r)g(p + r) (1)
Interestingly enough, we can easily show that the
similarity measure based on the normalized cross-
correlation and the L2 distance between two normal-
ized images F
0
and G
0
respectively represented by the
grey level functions
f (r)
σ
f
and
g(r)
σ
g
are equivalent. In-
deed, if D(p) is the L2 distance between the images
G
0
and F
0
at position p in G
0
D(p) =
∑
r∈Dom
F
f (r)
σ
f
−
g(p +r)
σ
g
2
=
=1
z }| {
∑
r∈Dom
F
f (r)
σ
f
2
+
=1
z }| {
∑
r∈Dom
F
g(p +r)
σ
g
2
−
2
σ
f
σ
g
∑
r∈Dom
F
f (r)g(p + r) (2)
Then D(p) = 2(1 − C(p)) only depends on the nor-
malized cross-correlation.
2.2 Image Processing for Predetection
The defined similarity measure applied to grey-scale
images gives results of poor precision (Fig. 5). In or-
der to increase the robustness of the predetection sys-
tem to illumination variations, we apply a high pass
filter inspired from the Nagano method to the images
F and G. This filter extracts the edges of the images.
Thus, the predetection system becomes a measure of
the edges similarity. If all the edges are perfectly su-
perposed, the normalized cross-correlation score is 1
and the less the edges are superposed, the closer to 0
the similarity score approaches.
v
1
, v
2
, v
3
and v
4
corresponding to the 4 following ma-
trix:
1 1 0 −1 −1
1 1 0 −1 −1
1 1 0 −1 −1
1 1 1
1 1 1
0 0 0
−1 −1 −1
−1 −1 −1
1 1 0 0 0
1 1 1 0 0
0 1 0 −1 0
0 0 −1 −1 −1
0 0 0 −1 −1
0 0 0 1 1
0 0 1 1 1
0 −1 0 1 0
−1 −1 −1 0 0
−1 −1 0 0 0
f
1
= max (
|
f ⊗ v
1
|
,
|
f ⊗ v
2
|
,
|
f ⊗ v
3
|
,
|
f ⊗ v
4
|
)
Filter f
1
convolutes the image F represented by
the function f (r) with 4 filters represented by the ma-
trix (v
1
, v
2
, v
3
, v
4
). Each filter is an edge detector in
a given direction. The final image represented by the
function f
1
(r) is the maximum of the four edges val-
ues of F detected using the filters (v
1
, v
2
, v
3
, v
4
).
Figure 1: Predetection filter applied to a face image.
2.3 Implementation Using the Pyramid
of Images
In order to create a predetection system able to de-
tect objects of different sizes, the test images are re-
peatedly down-sampled by a factor of 1.2, resulting
in a pyramid of images (Fig. 2). Each image of the
pyramid is filtered using the predetection filter. Then
we apply the normalized cross-correlation detection
method to each image of the pyramid and each filtered
reference image. The predetection system searchs the
likely positions and scales of the researched object
with recall close to 1 (number of good detections di-
vided by the number of elements to detect). The next
step consists of refining and verifying the predetec-
tion information in order to increase the precision of
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
180

the system (number of good detections divided by the
number of detections).
Figure 2: Example of a Pyramid of images used for prede-
tection. According to the image of the pyramid where an
object is predetected, we know the dimension of the prede-
tected object compared to the reference one.
3 DECISION
Once the predetection phase has been carried out, we
apply the decision system to each predetected object.
The decision system uses a similarity measure based
on centered normalized cross-correlation and affine
deformation compensation. Each predetected object
is deformed in order to maximize the similarity be-
tween the deformed test image and the corresponding
reference image of the object. Then, the images of the
objects to compare are preprocessed via a histogram
equalization, a high pass filter and image normaliza-
tions. Finally we apply the centered cross-correlation
to obtain a similarity score between the two images
deformed and preprocessed to compare.
3.1 Affine Deformation Compensation
This section describes the computational model
used for optimal affine deformation determination.
The key idea is to find the maximum similarity
measure for the affine deformation parameters. We
first describe the chosen similarity measure and the
corresponding function Ψ to maximize. We then
explain the Gauss Newton optimization method used
to find a maximum of function Ψ.
3.1.1 Formulation of the Affine Deformation
Method
Affine deformation is the first-order approximation of
the image deformation resulting from the perspective
projection of a rigid plane object which undergoes a
displacement and a rotation. Affine deformation con-
sists in translating, tilting and changing the vertical
and horizontal scale of an image.
If G
∗
=
{
g
∗
(r)
}
is the result of an affine transfor-
mation of a grey-scale image G =
{
g(r)
}
. The coor-
dinates (0, 0) being the image centre, we can write:
g
∗
(r) = g(r +d
r
)
r =
u
v
d
r
=
d
u
d
v
=
a
0
u + a
1
v + a
2
a
3
u + a
4
v + a
5
The 6 parameters (a
0
, ..., a
5
) define the affine de-
formation. a
2
and a
5
are the translation parameters,
a
0
, a
1
, a
2
and a
3
determine the image tilt and scale.
The criterion usually used to determine the best
affine deformation is the minimization of the L2 dis-
tance between the images requiring matching. In or-
der to ensure robustness versus illumination, we in-
troduce here the criterion of maximizing the centered
normalized cross-correlation of the deformed refer-
ence image and the test image, namely: find the pa-
rameters (a
0
, ..., a
5
) which maximize the following
objective function Ψ.
Ψ =
∑
r∈Dom
F
f
n
z }| {
f (r) − m
f
σ
f
g(p + r +d
r
) − m
g
σ
g
| {z }
g
n
(3)
F =
{
f (r)
}
and G =
{
g(r)
}
are respectively the refer-
ence and the test image, p the coordinate of G where
the object have been predetected.
m
f
and m
g
are the means of the functions f (r) and
g
∗
(p + r), r ∈ Dom
F
:
m
f
=
∑
r∈Dom
F
f (r)
m
g
=
∑
r∈Dom
F
g(p + r +d
r
)
σ
f
and σ
g
are the standard deviations of the functions
f (r) and g
∗
(p + r), r ∈ Dom
F
:
σ
f
=
r
∑
r∈Dom
F
( f (r) − m
f
)
2
σ
g
=
r
∑
r∈Dom
F
(g(p + r +d
r
) − m
g
)
2
We notice that only the functions g, m
g
and σ
g
depend on the affine deformation parameters.
3.1.2 Optimal Affine Deformation
Determination
We describe in this section the computational model
used to determine the affine deformation parameters.
First of all, following the necessary condition of Ψ
maximization yields to a set of six equations
EFFICIENT OBJECT DETECTION ROBUST TO RST WITH MINIMAL SET OF EXAMPLES
181

∂Ψ
∂a
i
= 0 i ∈ [0, 5] (4)
These equations cannot be solved analytically.
Since the problem has a low dimension, it seems ap-
propriate to determine the affine deformation param-
eters using non linear optimisation. (Dugelay and
Sanson, 1995) shows that the Gauss Newton iterative
method enables a robust and fast convergence solu-
tion for affine deformation optimization.
This method uses two approximations to perform
the optimization:
• The function Ψ to optimize is locally a second-
order polynomial function.
• The second derivative of the function g is 0 (the
Hessian matrix of g(r), H
g
= 0). Namely, that
the luminance variation of the image G is locally
linear.
We denote A
k
=
a
0
a
1
a
2
a
3
a
4
a
5
t
the
value of the affine deformation parameters to the k
th
iteration.
Using the approximation Ψ is locally a second-
order polynomial function, the updating parameter
vector is given by:
A
k+1
= A
k
− H
−1
A
G
A
(5)
Where H
A
is the Hessian of the cost function Ψ
and G
A
its gradient.
G
A
=
∂Ψ
∂a
i
.
.
.
!
H
A
=
∂
2
Ψ
∂a
i
∂a
j
. . .
.
.
.
.
.
.
To simplify, henceforth we will use:
g
p
⇔ g(p + r + d
r
)
g
r
⇔ ∇
r
(g
p
) d
i
r
⇔
∂d
r
∂a
i
m
i
g
⇔
∂m
g
∂a
i
σ
i
g
⇔
∂σ
g
∂a
i
• g
p
value of g at point (p + r + d
r
).
• g
r
the gradient value of g at point (p + r + d
r
).
• d
i
r
the derivative function of d
r
with respect to a
i
.
• m
i
g
the derivative function of the mean of g(p +
r + d
r
), r ∈ Dom
F
.
• σ
i
g
the derivative function of the standard devia-
tion of g(p + r +d
r
), r ∈ Dom
F
In order to determine A
k+1
, we have to compute each
iteration the matrix G
A
and H
A
. The assumption of the
local linear variation of g(r) allows us to determine
G
A
and H
A
using only the known functions f (r) and
g(p +r + d
r
), the gradient of g(r) (easily computable
using bilinear approximation), and d
i
r
.
Indeed, G
A
is given by:
∂Ψ
∂a
i
=
∑
r∈Dom
F
f (r) − m
f
σ
f
∂
∂a
i
g
p
− m
g
σ
g
=
∑
r∈Dom
F
f
n
∂g
n
∂a
i
(6)
=
∑
r∈Dom
F
f
n
d
i
r
t
g
r
− m
i
g
σ
g
− (g
p
− m
g
)σ
i
g
σ
2
g
With :
m
i
g
=
∑
r∈Dom
F
d
i
r
t
g
r
(7)
If we denote V
i
g
=
∂V
g
∂a
i
the derivative function of the
variance V
g
of g(p + r +d
r
):
σ
2
g
= V
g
=
∑
r∈Dom
F
(g
p
− m
g
)
2
V
i
g
=
∑
r∈Dom
F
2
d
i
r
t
g
r
− m
i
g
(g
p
− m
g
)
σ
i
g
=
V
i
g
2V
1
2
g
(8)
Similarly, noticing that ∀(i, j),
∂d
i
r
∂a
j
= 0, the Hessian
matrix H
A
is determined as follows:
∂
2
Ψ
∂a
i
∂a
j
=
∑
r∈Dom
F
f
n
∂
2
g
n
∂a
i
∂a
j
(9)
σ
4
g
∂
2
g
n
∂a
i
∂a
j
= (10)
2(g
p
− m
g
)σ
g
σ
i
g
σ
j
g
−
d
j
r
t
g
r
− m
j
g
σ
i
g
σ
2
g
−
(g
p
− m
g
)σ
i j
g
σ
2
g
−
d
i
r
t
g
r
− m
i
g
σ
j
g
σ
2
g
σ
i j
g
=
∂
2
σ
g
∂a
i
∂a
j
is the second derivative function of σ
g
.
σ
i j
g
=
∂
∂a
j
1
2
V
i
g
V
−1
2
g
=
1
2V
g
V
i j
g
σ
g
−
V
i
g
V
j
g
2σ
g
!
(11)
With V
i j
g
=
∂V
i
g
∂a
j
the second derivative function of the
variance V
g
:
V
i j
g
=
∑
r∈Dom
F
2
d
i
r
t
g
r
− m
i
g
d
j
r
t
g
r
− m
j
g
(12)
After the computation of G
A
and H
A
, for the k
th
iteration, we compute H
−1
A
. In practice this inversion
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
182

does not raise any problems. Finally using (5), the
affine deformation system converges towards solution
in less than 10 iterations.
3.2 Image Preprocessing for Decision
In order to reduce the sensitivity of the decision sys-
tem to variations of illumination, we apply the fol-
lowing image preprocessing to the deformed object
images to compare.
The image preprocessing is performed in 3 steps:
• Histogram equalization:
Histogram equalization is a contrast enhancement
technique with the objective to obtain a new image
with uniform histogram. This method usually in-
creases the local contrast of an image, and reduces
the variability of the grey-scale images represent-
ing the object we have to detect.
• High Pass Filter:
Image low frequency information are usually not
pertinent for the detection using cross-correlation,
that is why we substract from both images to
compare their corresponding blurred images. If
we denote G
1
= g
1
(r) the image G = g(r) filtered
by the high pass filter.
g
1
(r) = g(r) −Blur (g(r))
Blur (g(r)) = g(r) ⊗ w(r, n)
With w(r, n) =
1
4n
if
k
r
k
∞
< n else w(r, n) = 0.
• Sigmoid normalization:
The sigmoid normalization maximises the low
gray scale values, minimises the high ones and
thus standardizes the distribution of grey scale
values of the image, thus increasing the precision
of our detection system (Fig. 5). If G
2
= g
2
(r) is
the normalized image, then:
g
2
(r) = Sig(g
1
(r))
Sig(x) = 1 −
2
1 + e
−ax
The value of a is about 20 in our detection system.
Figure 3: Decision Preprocessing applied to a face image.
From the left to the right, grey-scale face image, histogram
equalization, high pass filter and finally, sigmoid normaliza-
tion.
4 EXPERIMENTAL RESULTS
In this section, we first present results that confirm ro-
bustness in rotation and scale changes of the similar-
ity measure based on affine deformation compensa-
tion and normalized centered cross-correlation. Then
we apply the detection system to faces, using a test
database containing 450 faces and show the improve-
ment brought by the proposed method.
4.1 Affine Deformation Evaluation
The purpose of the affine deformation compensation
is to bring robustness versus rotation, scale changes
and translation to the centered normalized cross-
correlation similarity measure. This section shows
two quantitative results obtained by applying our
affine deformation method to a 35 × 41 pixel face im-
age with a wide variety of pure rotation, and scale
change.
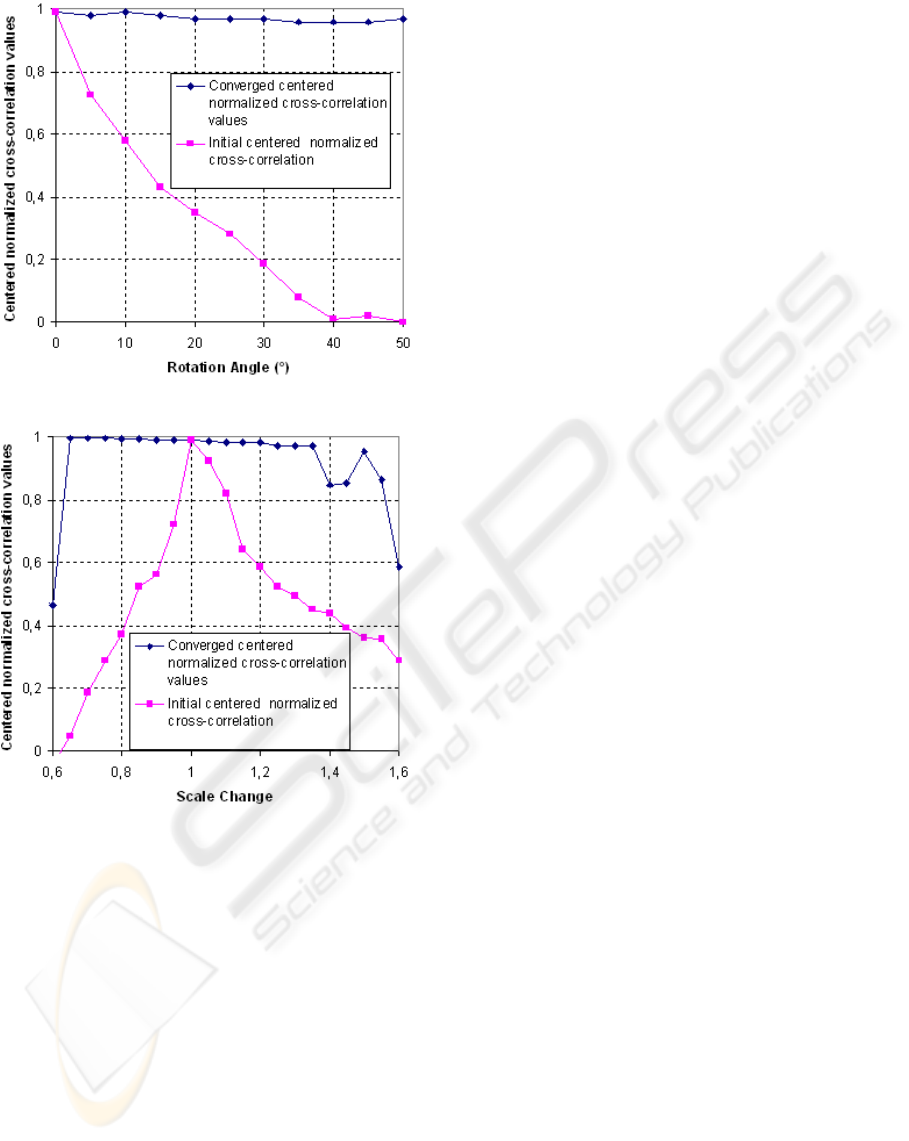
Fig. 4(a) shows centered normalized cross-
correlation score between an input grey-scale face im-
age and the corresponding artificially generated im-
age applying pure rotation. It is clear that until a rota-
tion of about 50
◦
, the affine deformation method con-
verges and the similarity measure is almost invariant
to rotation.
We reproduce the same experiment applying pure
scale change to the artificially generated image. We
can see on Fig. 4(b) that if the affine deformation con-
verges to the optimal solution, the centered normal-
ized cross-correlation value is about 1. The values of
the converged centered normalized cross-correlation
lower than 0.9 are due to local maximum convergence
of the affine deformation optimization algorithm.
4.2 Detection Evaluation
In order to evaluate our system, we apply it to face
detection using a test base containing 450 faces. The
reference database consists of 15 faces Fig. (6), se-
lected in order to obtain a good representation of the
faces space with a minimal set of examples. Fig. 5
shows the relation between the precision (number of
good detections divided by the number of detections)
and the recall (number of good detections divided by
the number of elements to detect). Thus, the better
a detector is, the closer the corresponding roc-curve
is to the upper right corner. We notice the predetec-
tion system is able to detect most of the test database
faces but with poor precision. The decision system
using centered normalized cross-correlation on grey
scale images clearly increases the detection precision.
We notice the relevance of the decision system images
EFFICIENT OBJECT DETECTION ROBUST TO RST WITH MINIMAL SET OF EXAMPLES
183
(a) Relation between the mean normalized cross-
correlation values and the rotation.
(b) Relation between the mean normalized cross-
correlation values and scale change.
Figure 4: Affine deformation experimental results.
preprocessing and the affine deformation. The preci-
sion of our detection system for a recall of 0.9 without
image preprocessing and affine deformation compen-
sation is 0.28, the image preprocessing increases the
precision to 0.55 and the affine deformation to 0.79.
This system introduces promising methods to per-
form efficient detection with very small training set.
However, it should be noted that we are not able to
obtain good detection rates from complex face detec-
tion databases like CMU , where lots of faces are oc-
cluded and very badly contrasted. Our future works is
to produce a detection system using reduced training
sets able to reach detection rates close to state-of-the-
art.
5 CONCLUSIONS
The object detection system based on the cross-
correlation method is sensitive to illumination
changes, rotations, translations and scale changes. To
solve this problem, we introduce a detection process
divided in a predetection and a decision system. The
two parts of the detection system use different image
preprocessing which increases the detection speed
and rates. This method has shown good results on
face detection. Additionally, we introduce a new sim-
ilarity measure based on cross-correlation and affine
deformation. The affine deformation system based on
the mean normalized cross-correlation optimization
we have developed is very promising, and shows good
convergence for complex grey-scale images. Thus the
measure we use for decision is robust to RST and in-
creases the precision of our detection system.
REFERENCES
Dugelay, J. L. and Sanson, H. (1995). Differential methods
for the identification of 2d and 3d motion models in
image sequences. In Signal Processing: Image Com-
munication 7.
Edwards, G. J., Cootes, T. F., and Taylor, C. J. (1999). Ad-
vances in active appearance models. In Computer Vi-
sion, 1999. INSTICC Press.
Garcia, C. and Delakis, M. (2004). Convolutional face
finder, a neural architecture for fast and robust face
detection. In IEEE Transactions on pattern analysis
and machine intelligence, Vol.26, NO.11.
MacLean, W. J. and Tsotsos, J. K. (2007). Fast pattern
recognition using normalized grey-scale correlation in
a pyramid image representation. In Machine Vision &
Applications.
Santiago-Mozos, R., Leiva-Murillo, J., Perez-Cruz, F., and
Artes-Rodriguez, A. (1999). Supervised-pca and svm
classifiers for object detection in infrared images.
In IEEE Conference on Advanced Video and Signal
Based Surveillance.
Sung, K. K. and Poggio, T. (1998). Example-based learning
for view based human face detection. In IEEE Trans-
actions on pattern analysis and machine intelligence,
Vol.22, NO.1.
Viola, P. and Jones, M. (2001). Robust real-time object de-
tection. In Second International Workshop on Statisti-
cal and Computational Theories of Vision - Modeling,
Learning and Sampling.
Wakahara, T., Kimura, Y., and Tomono, A. (2001). Affine-
invariant recognition of gray-scale characters using
global affine transformation correlation. In IEEE
Transactions on pattern analysis and machine intel-
ligence, Vol.23, NO.4.
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
184
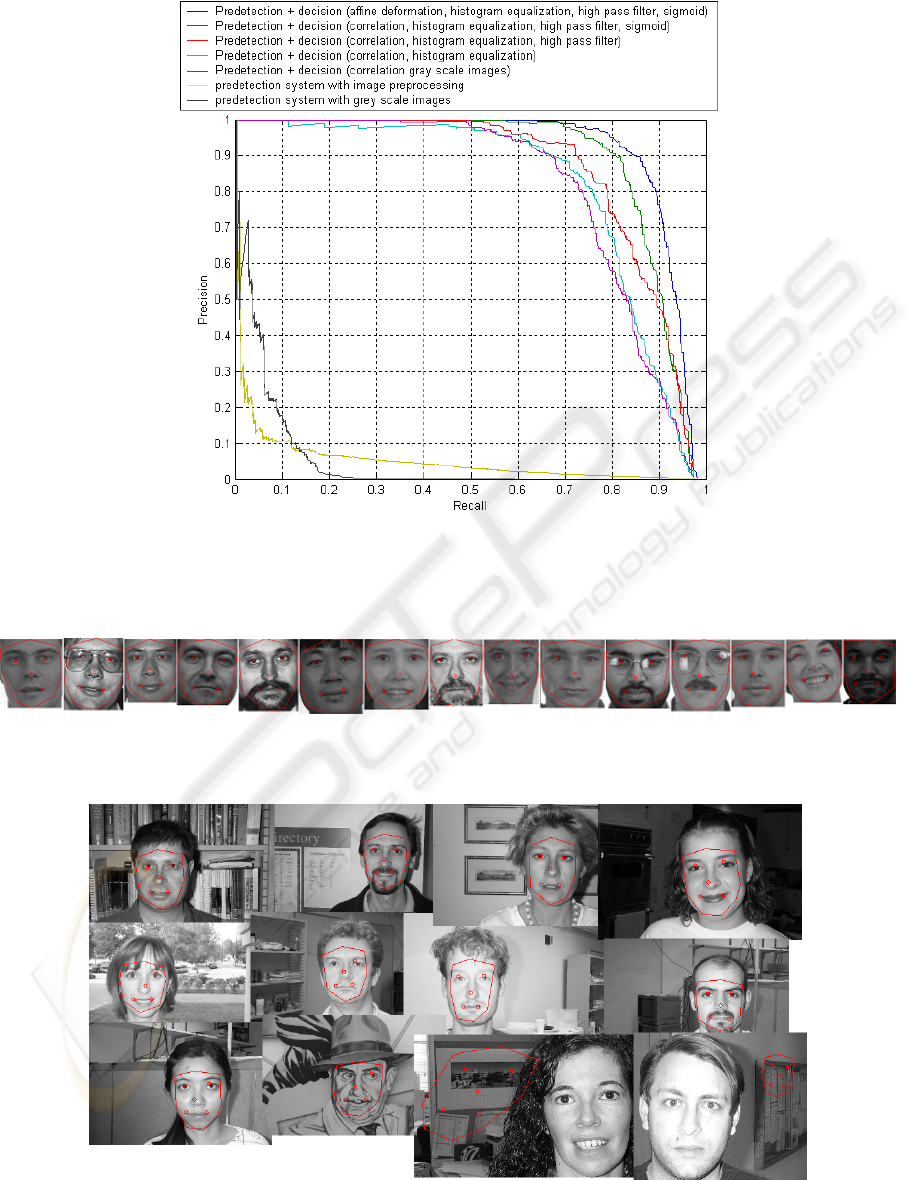
Figure 5: Relation between the precision and the recall values for differents versions of our system detection. We start from
the simple predetection system, then we add the decision system using a simple grey-scale correlation, we progressively apply
the different image processing to decision and finally the affine deformation method.
Figure 6: Reference images used for the system evaluation.
Figure 7: Some results obtained on the Faces 1999 database.
EFFICIENT OBJECT DETECTION ROBUST TO RST WITH MINIMAL SET OF EXAMPLES
185
