
COMPARATIVE STUDIES OF SOCIAL CLASSIFICATION
SYSTEMS USING RSS FEEDS
Steffen Oldenburg
Chair for Information and Communication Services, Department of Computer Science, University of Rostock
Albert-Einstein-Strasse 21, D-18059 Rostock, Germany
Keywords:
Social Classification, Efficient Personal and Collaborative Tagging, Processing and Analysis of Heterogeneous
Tag Spaces, Tagging Automation, Tag Space Integration.
Abstract:
This paper presents the results of practical studies comparing five well established social classification services
for tagging of bookmarks (del.icio.us, BibSonomy bookmarks) and publications (BibSonomy publications,
CiteULike, Connotea) in the context of service interoperability and integration. Contrary to most of current
research we exclusively focus on the usage of RSS feeds for retrieval of tag-related data. Here we exploit
”recent” feeds, as this method of data retrieval corresponds directly to the way users can retrieve data from
these services, e.g. for tag suggestions. We motivate the preferred usage of feeds compared to full site
grabbing, and present analysis results of feed data from a period of one month concerning feature distribution,
growth, stability and convergence aspects. Furthermore we compare tag spaces and their intersections for
potential interoperability and integration of these services, and reveal that tags in practice are not really as
freely chosen as often promised.
1 INTRODUCTION
The emerging trend to public sharing of information
and knowledge implies a growing demand in light-
weight classification with low participation barriers
for users. This trend to collaboratively attach any the-
oretically unrestricted, free-form key words to content
- called tagging - has produced a tremendously rising
number of non-integrated tag spaces, tagged hetero-
geneous resources, and isolated tagging services.
However, recent quantitative research raises con-
cern that this growth trend complicates for individual
users to efficiently benefit from (resource discovery)
and contribute to (resource annotation) social classi-
fication over time. This represents a tough challenge
in the context of exploring best fitting vocabulary for
individual or public resources.
Getting operational with bootstrapping tag spaces
by retrieving best fitting tag vocabulary, staying oper-
ational over time by evolving best fitting vocabulary
as well as staying independent and interoperable by
importing and exporting service-specific tag vocabu-
lary and tagged content are essential requirements for
long-term user acceptance as well as efficient partici-
pation in different-scale social classification systems.
However, focusing on single folksonomies and
isolated tagged resources as not being inter-related so
far, only little research has been done on these topics.
1.1 Overview and Context
This paper presents work in progress of a PhD thesis
in the context of interoperable and integrated social
classification systems. As key requirement we deter-
mine a transparently extensible, integrative and inter-
operable tagging service - supporting efficient boot-
strapping of tag-related information from heteroge-
neous social classification systems with different the-
matic focuses, local or restricted user resources, as
well as a dynamic evolution of user-centric tag spaces
in an integrated context. Here we present results of
comparative studies with well-established classifica-
tion services over a time span of one month from
August 01, 2007 - September 01, 2007, exclusively
based on RSS feeds (Really Simple Syndication). Ad-
ditionally, we compare our results with publicly avail-
able full dumps regarding data until Sept. 01, 2007.
Our mid-term target is to analyse requirements to
establish a uniform, extensible architecture for a so-
cial classification analysis framework and interactive
evaluation platform for efficient and integrated per-
sonal tagging, deriving relevant tagging features, e.g.
394
Oldenburg S. (2008).
COMPARATIVE STUDIES OF SOCIAL CLASSIFICATION SYSTEMS USING RSS FEEDS.
In Proceedings of the Fourth International Conference on Web Information Systems and Technologies, pages 394-403
DOI: 10.5220/0001523803940403
Copyright
c
SciTePress

tag suggestions, from a dynamically evolving individ-
ual tag space (assisted tagging).
Our long-term focus is placed on efficient
(semi)automated tagging and tag suggestions based
on that integrative, interoperable approach, and on
analysis and application of the resulting tag spaces
for optimized navigability abstracting from the spe-
cific tagging services in background. Users should be
enabled to work with one consistent, virtual tag space,
and not depend on service-specific restrictions.
2 RELATED WORKS
This paper covers specific topics related to compara-
bility, integration and interoperability of social clas-
sification and tagging, and analyses leading tagging
services with different scales of popularity, growth as
well as thematic focuses. For a general overview and
research motivationrefer to community discussions in
(Mathes, 2004), (Shirky, 2005). For recent research of
tagging motivations read (Ames and Naaman, 2007)
or (Zollers, 2007). Associated quantitative evalua-
tions of static and dynamic features as well as emerg-
ing structures in tag spaces are presented in (Cattuto
et al., 2006), (Cattuto, 2007), (Golder and Huberman,
2005), or (Lambiotte and Ausloos, 2006). (Zhang
et al., 2006) compare the motivations, advantages
and drawbacks of traditional top-down and emerging
bottom-up semantics concerning Web resources and
present results from del.icio.us analysis. A BibSon-
omy overview is given in (Hotho et al., 2006).
Comparison, Integration and Interoperability
Studies. (Gruber, 2005) proposes an approach for
defining an ontology that would enable the exchange
of tag data and the construction of tagging systems
that can compositionally interact with other systems.
(Veres, 2006) evaluates semantic intersections and
interoperable features between different tagging ser-
vices (flickr, del.icio.us), but lacks profound quan-
titative evaluation. The relation between texts from
blog posts and tags associated with them are analysed
in (Berendt and Hanser, 2007). Inter-relations be-
tween different tag spaces are not considered. (Bhagat
et al., 2007) analyse how different information net-
works (e.g. web, chat, email, blog, instant messenger)
interact with each other, e.g. correlations between
blog - blog, blog - web or blog - messenger. (Schmitz
et al., 2007) analyse and compare co-occurrence net-
work properties of del.icio.us data (actual as of 2004-
2005) and BibSonomy data (as of July 2006).
Distribution, Growth, and Stability. Feed based
analysis using del.icio.us data is exploited in (Shaw,
2005), (Begelman et al., 2006), or on deli.ckoma
1
web site. The last one presents actual statistics de-
rived from recent RSS feeds, and evaluates data re-
trieval coverage and error probability. (Halpin et al.,
2007) analyse whether coherent and stable categoriza-
tion schemes can emerge from unsupervised tagging,
and they evaluate its dynamics over time, including
corresponding power-laws in del.icio.us tag distribu-
tions for resources with different popularity scale. A
brief CiteULike analysis including power-lawis given
in (Capocci and Caldarelli, 2007).
Tag Space Navigability and Efficiency. (Chi and
Mytkowicz, 2007) analyse early data (actual as of
2004-2005) from large-scale del.icio.us with (condi-
tional) entropy concerning efficient navigability, and
reveal that efficiency is decreasing over time. Effi-
ciency analysis using entropy measure is also used in
(Zhang et al., 2006) and (Li et al., 2007). (Santos-
Neto et al., 2007) analyse CiteULike and BibSonomy
whether usage patterns can be exploited to improve
the navigability in a growing tagsonomy. They anal-
yse the smaller scale services BibSonomy and CiteU-
Like to reveal tagging activity distribution, and de-
fine metrics to uncover similarities in user interests.
(Brooks and Montanez, 2006) analyse the effective-
ness of tags to describe blog contents (technorati
2
,
REST API). The authors suggest that tags are more
useful to assign blogs to broad category clusters than
to indicate particular resource content. Hence, they
exploit text contents to automatically extract relevant
keywords (TF-IDF) for tag usage and compare differ-
ent combinations of these approaches.
Review of the State of the Art. Existing research
approaches introduce metrics and measures for tag
related similarities, growth, stability, and efficiency.
They apply them on basically comparable data sets
- mostly the popular broad folksonomy del.icio.us,
in some cases the less frequently used services Ci-
teULike or BibSonomy. However, results from these
different research publications cannot be effectively
compared due to different time scopes, evaluation tar-
gets, amounts of data, data retrieval concepts, and a
missing comprehensive analysis architecture follow-
ing an integrative approach. Thus, chances to evalu-
ate, compare and rank tag or resource spaces, e.g. for
efficienttag suggestions, and to deduce conclusionsto
optimize tagging processes are hard to identify. There
is need for an evaluation approach on comparable ac-
tual data sets from the same time span, based on uni-
form data retrieval which is in the scope of this paper.
1
http://deli.ckoma.net/stats
2
http://www.technorati.com/
COMPARATIVE STUDIES OF SOCIAL CLASSIFICATION SYSTEMS USING RSS FEEDS
395

3 RSS FEEDS AS SOURCE FOR
TAG SPACE BOOTSTRAPPING
RSS feeds are offered by many leading social classifi-
cation services, at least for recent data, in general also
for specific tags, users, and resources. This promises
a more consistent retrieval of heterogeneous tag data
than site-depending methods, e.g. full or random site
grabs using Web spiders like wget.
<item rdf:about=”http://code.google.com/”>
<title>Google Code − Developer Network</title>
<link>http://code.google.com/</link>
<description></description>
<dc:creator>lhc1111</dc:creator>
<dc:date>2007−08−31T22:02:16Z</dc:date>
<dc:subject>API Code Google ajax</dc:subject>
<taxo:topics><rdf:Bag>
<rdf:li resource=”http: // del. icio .us/tag/Google”/>
<rdf:li resource=”http: // del. icio .us/tag/Code”/>
<rdf:li resource=”http: // del. icio .us/tag/API”/>
<rdf:li resource=”http: // del. icio .us/tag/ajax”/>
</rdf:Bag></taxo:topics> </item>
Listing 1: Example of RSS feed item.
Past research either fully relied on site grabs or
at least initial grabs with further incremental updates
using feeds. Grabs are subject to changes in HTML
structure, its dynamical generation, as well as site
growth, hence need to regard current site properties.
Full grabs are not well accepted by many services
(site ban warnings, read FAQs), and full dumps are
rarely available, e.g. here from CiteULike (direct
download), and BibSonomy (acceptance of condi-
tions, download link per mail).
Contrarily, feeds have very similar content struc-
ture and XML markup. Service dependency is much
lower, though there are minor differences in XML
tags or in availability of specific properties for feed
items. An example item is given in listing 1.
With feeds we generate less load on service sites,
and are unlikely to become subject to site bans. Feed-
based growth in tags, users, resources promises statis-
tically relevant data amounts in relatively short time
as our analysis will reveal. We can operate without
storing site history as we are primarily interested in
supporting users with actual tag data, as sites dynam-
ically evolve including interest shifts. Furthermore
site growth since service launch has produced such
a tremendous amount of data, which cannot be effi-
ciently handled anymore for popular sites, e.g. refer
to del.icio.us properties in Table 2.
As we want to support users in uniform tagging
with heterogeneous tagging services we need to ex-
ploit the same data users have access to. Users do not
want to download full dumps or grab histories. Using
RSS we benefit from a widely uniform format based
on RDF / XML, being UTF8-encoded in most cases,
and thus can seamlessly integrate new services com-
plying to this format and services using it, e.g. feeds
based on RSS or ATOM standards.
After profound reading of publications emerged
in the context of quantitative analysis of tagging ser-
vices during the last two years we have to pose a basic
question: Do we need complete history-scale dumps
of tag spaces, or is it sufficient, and more efficient to
just evaluate current and future data with less scale,
but similar properties concerning distribution, conver-
gence and stability of tag spaces - over some time -
to get and stay operational? Interestingly, feeds of-
fer richer semantics in tag data than service backends
(read Section 4.6).
4 ANALYSIS AND EVALUATION
In the following section we provide insight into our
test environment, and relevant evaluations. Finally we
assess our method of data retrieval.
4.1 Test Environment
For our analysis we selected the highly popular site
del.icio.us (10 sec interval, fast item updates), the
popular sites CiteULike (10 min) and Connotea (3
min, less items per feed), and the less popular site
BibSonomy, distinguishing between feeds for book-
marks (Bib1, 10 min) and publications (Bib2, 10
min). Refer to Tables 1 and 2, from now on we will
address the services with the given IDs.
Table 1: Service URLs for recent RSS feeds.
Service URL (http://) ID
BibSonomy www.bibsonomy.org/rss Bib1
www.bibsonomy.org/publrss Bib2
CiteULike www.citeulike.org/rss Cit
Connotea www.connotea.org/rss Con
del.icio.us del.icio.us/rss Del
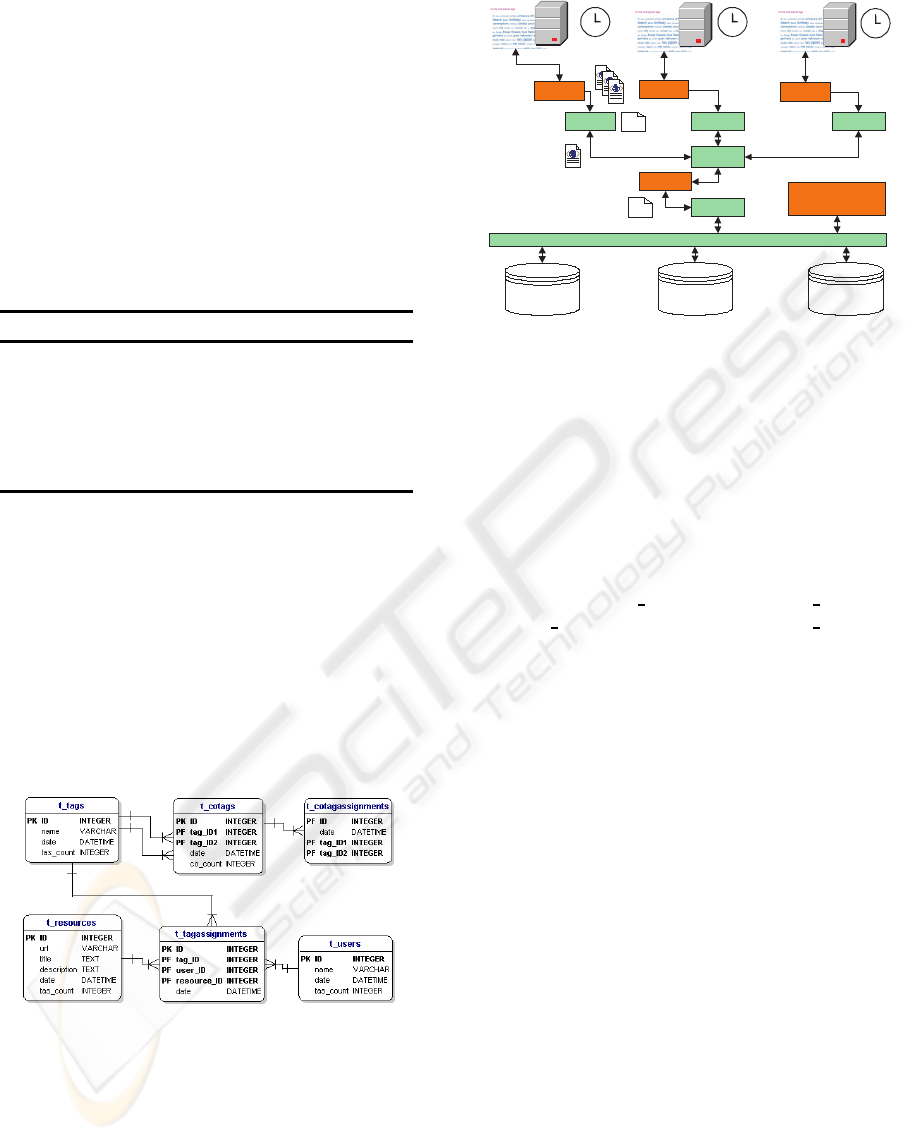
The database schema of our current testbed is
illustrated in Figure 1. We use separate schemas
for each folksonomy in test. Tags t ∈ T =
{t
1
, t
2
, ..., t
k
}, users u ∈ U = {u
1
, u
2
, ..., u
l
}, and
resources r ∈ R = {r
1
, r
2
, ..., r
m
} are stored with
time stamps, and tag assignment counters in separate
tables and associated to each other in the tag assign-
ments table (TAS) as quadruples tas = (t, u, r, ts) ∈
WEBIST 2008 - International Conference on Web Information Systems and Technologies
396
T AS ⊆ T × U × R × T S with a time stamp
ts ∈ T S = T S
ISO8601
= {ts
0
≤ ts ≤ ts
n
}
with ts
0
= 01.08.07T16:00:00, and
ts
n
=01.09.07T23:59:59. Triples (t, u, r)
are unique. Items (posts) i ∈ I ⊆ U × R × T S × T
∗
extracted from RSS feeds - we only process non-
empty items (T
+
) - are not directly reflected in the
database. They can be retrieved using SQL grouping
or MD5 hashes on tag assignment attributes (u, r, ts).
Table 2: Sizes of tags (T), users (U), resources (R), tag as-
signments (A, in text TAS), co-tags / edges (E), co-tag as-
signments (C, in text CAS, factor 10
6
), and items (I).
Bib1 Bib2 Cit Con Del
T 8716 1664 14282 12215 238047
U 1433 135 1683 2352 213190
R 4726 1529 17912 17032 823411
A 24424 5554 67395 71325 5485163
E 68163 7953 160474 131400 2661505
C 0,114 0,012 3,918 0,299 10,786
I 5285 1570 18221 17440 1822456
The co-tags table stores edges e = (t
i
, t
j
) ∈
E ⊆ T × T, t
i
≤
alpha−numeric
t
j
, t
i
6= t
j
of the
tag co-occurrence network with usage counters as
weights. For each RSS item we sort the local tag
list and combine each tag with all its successors (fil-
tering self-co-occurrences), resulting in a local fully
connected undirected graph with n
i
∗ (n
i
− 1)/2 tags
(clique) for item i with n tags. Each co-tag assign-
ment cas ∈ CAS ⊆ E × T S is stored in the co-tag
assignments (CAS) table.
Figure 1: Database schema for test bed.
We requested recent RSS feeds using service spe-
cific manually adjusted request intervals. For an
overview of data retrieval refer to Figure 2.
Depending on the interval chosen we receive 144
(10 min interval) up to 8640 (10 sec) XML files
(feeds) per day, being archived on a daily basis. Item
features, e.g. resources and tags, are extracted from
archived feeds into CSV tuples using regular expres-
Load CSV
Write extracted
data to CSV
Daily archive
Recent items
(XML)
...
7 5
6
12
11
10
8 4
2
1
9 3
Interval 10s
7 5
6
12
11
10
8 4
2
1
9 3
10min
7 5
6
12
11
10
8 4
2
1
9 3
3min
RSSZip
RSSRead
RSSZip
RSS2DB
RSS
Extract
...
data_delicious
data_citeulike data_connotea
del.icio.us
CiteULike Connotea
RSSDB
csv
RSSZip
RSSRead
RSSRead
Temporary
XML to extract
Plot, Graph, Mining,
Statistics … modules
...
DBDefaultConnection
zip
Figure 2: Analysis architecture for test bed.
sions. Finally they are propagated to the appropriate
database schema. To preserve a maximum of compa-
rability the extraction restricts to use non-empty items
(at least one tag), containing only unreserved charac-
ters according to RFC 3986, among these at least one
character from [a-zA-Z0-9]. Space separated word
groups are split, tags are unescaped (HTML), we de-
code UTF-8 %-encoding, and remove [,;"\]. For
details refer to Tables 2, 5 and Figure 1. The integrity
conditions
P
t∈T
tas count =
P
u∈U
tas count =
P
r∈R
tas count = |T AS|, and
P
e∈E
co count =
|CAS| are satisfied.
Tests were conducted on a machine with 1.5 GB
RAM, 2 GHz T7200 Dual Core CPU, running Win-
dows XP SP2, MySQL v5.0.27 with large configura-
tion and MYISAM engine, and Sun Java SE v1.6.
4.2 Power-law Analysis
Does RSS feed extracted data reveal typical distribu-
tion features? In order to determine whether our data
is representative for a folksonomy we need to show
that typical distributions comply to a power-law.
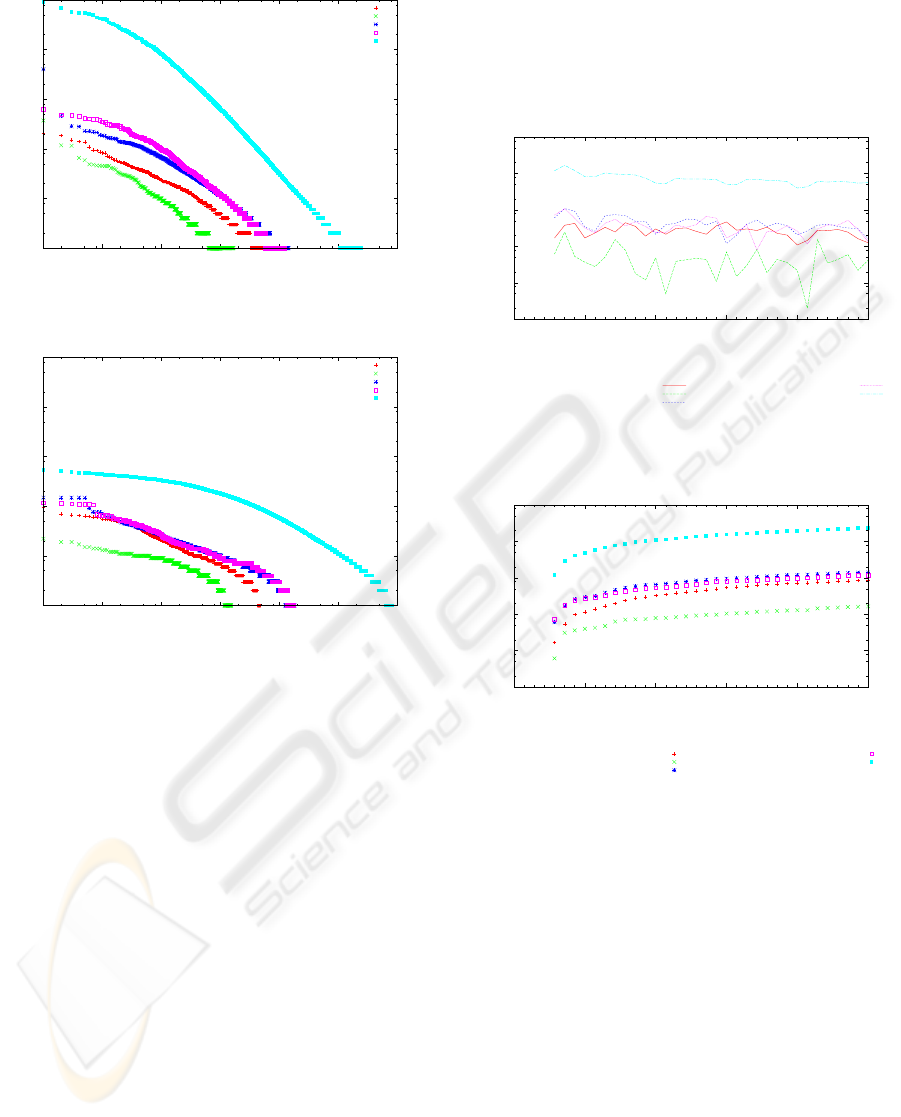
Here we present the distributions for tags (see Fig-
ure 3), and resources (see Figure 4) per tag assign-
ment. The plots reveal typical power-law behaviour
(nearly linear in log-log scale) with small head and
big tail at different scales. Del.icio.us represents the
most popular folksonomy in test, BibSonomy pub-
lications the least frequented one, followed by Bib-
Sonomy bookmarks. Connotea and CiteULike re-
veal very similar properties which is not only visi-
ble in these plots. The plots indicate that RSS feeds
are an absolutely satisfying data source, as feed data
very rapidly establish typical power-lawdistributions.
Subsequently, feeds are satisfactory resources for tag
analysis and tag suggestions. We do not have to
favour tagging history, but can focus on recent tag re-
COMPARATIVE STUDIES OF SOCIAL CLASSIFICATION SYSTEMS USING RSS FEEDS
397
1
10
100
1000
10000
100000
1 10 100 1000 10000 100000 1e+006
Tag assignments per tag (logarithmic scale)
Tag rank (logarithmic scale)
Tag assignment frequencies (power law): Folksonomy RSS feeds (01.08.07 - 01.09.07)
http://www.bibsonomy.org/rss/
http://www.bibsonomy.org/publrss/
http://www.citeulike.org/rss/
http://www.connotea.org/rss
http://del.icio.us/rss/recent/
Figure 3: Tag assignments per tag (power-law).
1
10
100
1000
10000
100000
1 10 100 1000 10000 100000 1e+006
Tag assignments per resource (logarithmic scale)
Resource rank (logarithmic scale)
Tag assignment frequencies (power law): Folksonomy RSS feeds (01.08.07 - 01.09.07)
http://www.bibsonomy.org/rss/
http://www.bibsonomy.org/publrss/
http://www.citeulike.org/rss/
http://www.connotea.org/rss
http://del.icio.us/rss/recent/
Figure 4: Tag assignments per resource (power-law).
lated information. Less data produces less load on the
tagging service, and can be analysed more efficiently.
A major drawback is, that we do not retrieve the same
number of tail level tags as with site grabs, the part
of the distribution bearing most spam, but also less
frequently used relevant tags.
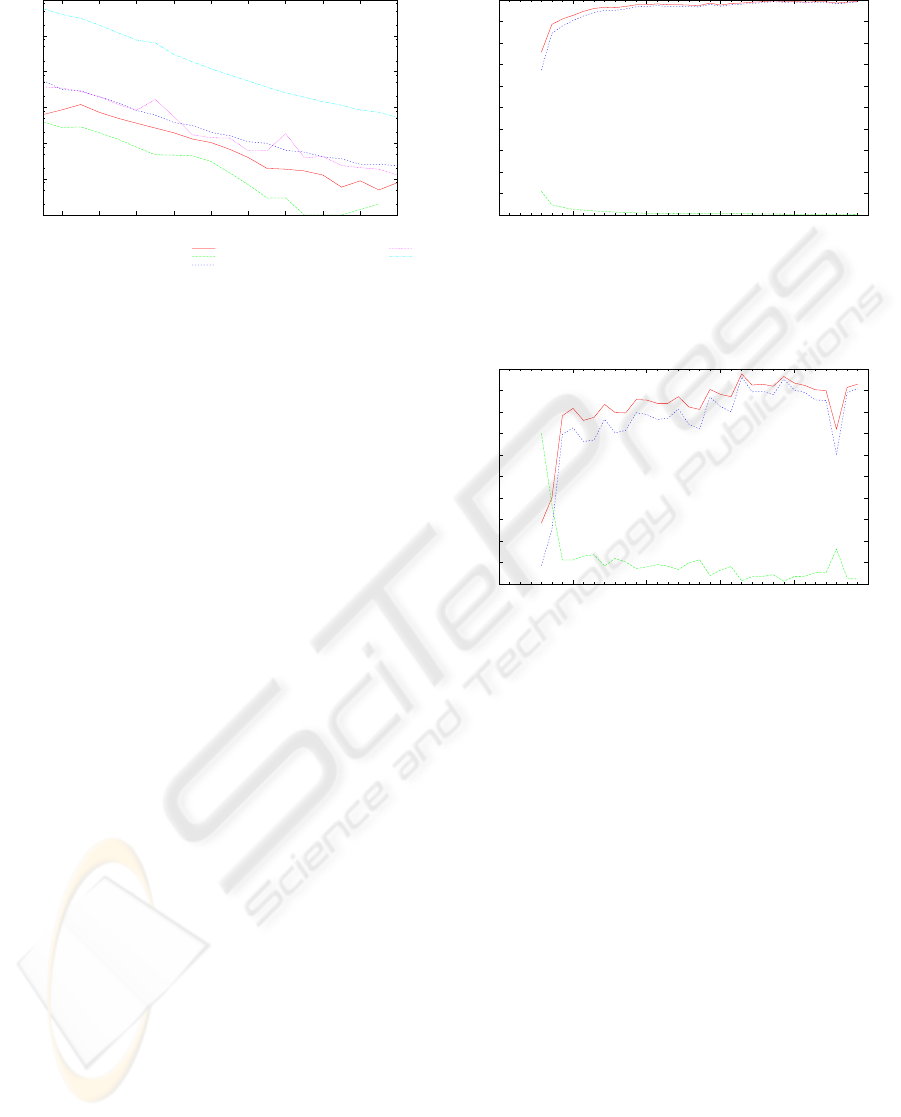
4.3 Growth and Convergence Analysis
A further question is whether tag related distribu-
tions retrieved from RSS feed data converge quickly
enough to get stable after short time, and how long
feeds need to be requested to achieve that stability.
We provide a general overview about per-day growth
and cumulative growth - here tags only - in Figures 5
and 6. Both plots are in log-normal scale to reveal
scale (popularity) differences between the services.
Per-day tag (resource, user) growth reveals falling
trends for del.icio.us, CiteULike, and Connotea, in-
dicating that the longer the studies go the more of
the most frequently used tags (actual resources, ac-
tive users) have been retrieved. Normal-normal scale
is nearly linear for cumulative growth. The corre-
sponding distribution of tags concerning number of
tags per item is presented in Figure 7. This distribu-
tion will become relevant for upcoming tag sugges-
tion research, e.g. for local co-occurrence analysis of
2-, 3-, or n-tag networks.
1
10
100
1000
10000
100000
28.07.2007
04.08.2007
11.08.2007
18.08.2007
25.08.2007
01.09.2007
Tag Count
Date
New tags per day: Folksonomy RSS feeds (01.08.07 - 01.09.07)
http://www.bibsonomy.org/rss/
http://www.bibsonomy.org/publrss/
http://www.citeulike.org/rss/
http://www.connotea.org/rss
http://del.icio.us/rss/recent/
Figure 5: Per day tag growth over time, log-normal scale.
10
100
1000
10000
100000
1e+006
28.07.2007
04.08.2007
11.08.2007
18.08.2007
25.08.2007
01.09.2007
Tag count
Date
Cumulative tag count: Folksonomy RSS feeds (01.08.07 - 01.09.07)
http://www.bibsonomy.org/rss/
http://www.bibsonomy.org/publrss/
http://www.citeulike.org/rss/
http://www.connotea.org/rss
http://del.icio.us/rss/recent/
Figure 6: Cumulative tag growth (tags per day) over time,
log-normal scale for better visibility due to outscaling of
del.icio.us.
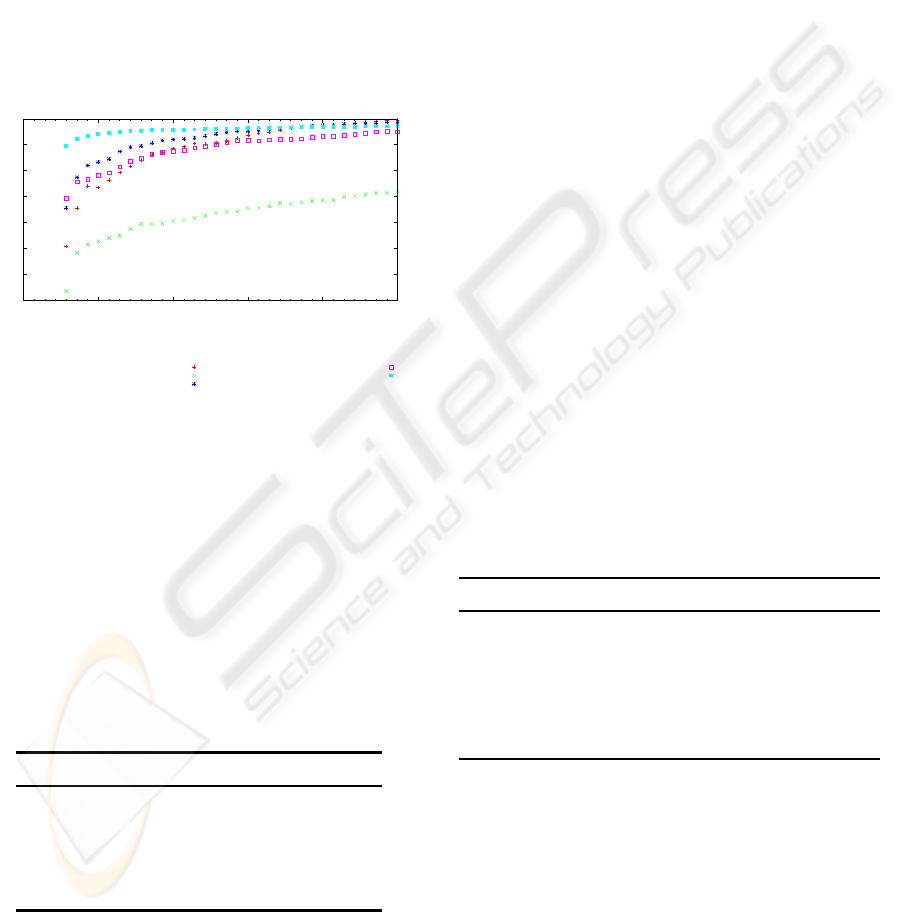
How can we assess pairwise similarity between
subsequent feeds, e.g. for tag sets? Therefore we
retrieved top 1000 tags, users and resources, and
computed pairwise similarity between subsequent top
sets. For space reasons we only present top 1000 tags
for popular del.icio.us site (Figure 8) and top 1000
resources for Connotea (Figure 9), the last one be-
ing representative for convergence of all top distri-
butions other than del.icio.us. Del.icio.us distribu-
tions stabilize very quickly (90% similarity threshold
after two days), the other services need about four
days to reach 80% similarity. We use the Jaccard
measure for basic set similarity (no regard of rank):
j = sim
Jaccard
(X, Y ) = |X ∩ Y |/|X ∪ Y |.
In order to regard an element’s rank we introduce
a shift distance measure on sets to assess the num-
WEBIST 2008 - International Conference on Web Information Systems and Technologies
398
1
10
100
1000
10000
100000
1e+006
2 4 6 8 10 12 14 16 18 20
Number of items (logarithmic scale)
Tag count
Items per tag count group: (01.08.07 - 01.09.07)
http://www.bibsonomy.org/rss/
http://www.bibsonomy.org/publrss/
http://www.citeulike.org/rss/
http://www.connotea.org/rss
http://del.icio.us/rss/recent/
Figure 7: Tagged items grouped according to number of
used tags, log-normal scale.
ber of position shifts. For two sets X and Y with
n = size(X) = size(Y ) in order to transform
X into Y for all elements e we calculate shift costs
c
shift
(X, Y ) =
P
e∈X∧e∈Y
|r
X
(e) − r
Y
(e)|, insert
costs (shift into set) c
ins
(X, Y ) =
P
e/∈X∧e∈Y
|n −
r
Y
(e)+1|, delete costs (shift out of set) c
del
(X, Y ) =
P
e∈X∧e/∈Y
|n − r
X
(e) + 1| with rank r(e) : 1 ≤
r(e) ≤ n, and summarize c
abs−shifts
(X, Y ) =
c
del
(X, Y ) + c
ins
(X, Y ) + c
shift
(X, Y ). The shift
weight s then reads s = c
abs−shifts
/c
max−shifts
with c
max−shifts
= n ∗ (n + 1), applied on j:
sim
Jaccard,weighted
= j ∗ (1 − s). c
max−shifts
oc-
curs for two disjoint sets with n ∗ (n + 1)/2 delete
as well as insert shifts, e.g. e
1
shifts down (up) by n
positions, e
n
by 1 to leave (claim) positions in X (Y).
Assumption 1 is that the sets are equal-sized, oth-
erwise we choose the lower size as reference. As-
sumption 2 is that only insertion is allowed, assum-
ing only equal-sized or growing sets, which of course
is true for our feed-based folksonomy data in test.
Hence, between subsequent sets X
i
, X
i+1
holds: ∀i :
|X
i
| ≤ |X
i+1
|. Our shift distance does not perform
any reordering, it only looks ahead to assume a mea-
sure on it, not taking into account any improved item
order after some reordering step. We penalize the ini-
tial state of disorder. Other distance metrics may be
applied as well, e.g. Levenshtein or Ulam (longest
common subsequence) distances.
4.4 Navigability Analysis
Motivated by (Chi and Mytkowicz, 2007), we apply
the entropy measure to assess tagging navigability:
H(T ) = −
P
t∈T
p(t) ∗ log
2
(p(t)) with tag proba-
bility p(t) = |T AS(t)|/|T AS|, TAS denotes tag as-
signments, T AS(t) the tag assignments with tag t.
With increasing size of T the entropy will grow as
well as with the distribution of t ∈ T over TAS be-
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
28.07.2007
04.08.2007
11.08.2007
18.08.2007
25.08.2007
01.09.2007
Similarity / shift distance
Dates
Pairwise similarity: http://del.icio.us/rss/recent/ (01.08.07 - 01.09.07)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Figure 8: Pairwise similarity of top 1000 tags, del.icio.us.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
28.07.2007
04.08.2007
11.08.2007
18.08.2007
25.08.2007
01.09.2007
Similarity / Shift distance
Dates
Pairwise similarity: http://www.connotea.org/rss (01.08.07 - 01.09.07)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Jaccard similarity (red)
Weighted Jaccard similarity (blue)
Shift distance (green)
Figure 9: Pairwise similarity of top 1000 resources, Con-
notea.
coming more uniform. The higher the entropy value
grows, the less information is contained, and the less
efficient any tag space navigation will become.
Our analysis reveals a similar growth in entropy
for all services (at different scales), getting flatter
over time (plateau). It is obvious that navigability in
del.icio.us is flattening fastest (plateau nearly paral-
lel to x-axis) in comparison with the other services
because this service has the highest tag (assignment)
growth rate (compare Figure 6). The nearly constant
entropy is due to the tag distribution getting less uni-
form over time. This implies an increasing difficulty
for users or tag suggestion algorithms to find unique
tags or at least tags with less recall and higher preci-
sion. Our analysis result is given in Figure 10. As
entropy over time nearly looks the same for all ser-
vices, this raises the question whether it is the optimal
measure to assess efficient navigability.
Entropy in current research is used to evaluate
the navigability concerning distribution of single tags
only. However, in real life users apply more than one
tag to discover a resource. Either the service in use
COMPARATIVE STUDIES OF SOCIAL CLASSIFICATION SYSTEMS USING RSS FEEDS
399
supports the usage of multiple tags at the same time,
or it may offer the opportunity to search in previous
search results, e.g. try Connotea in-collection search
feature. Thus, it would be more interesting to analyse
the entropy of tags in context, e.g. co-tags of 2 and
more correlated tags because using more than one tag
efficiently reduces search space. Thus, the entropy
of tag combinations should result in values indicat-
ing better efficiency and specifity. This idea is also
motivated by rapidly increasing conditional entropies
of documents on tags presented in (Chi and Mytkow-
icz, 2007) indicating decreasing (single!) tag speci-
fity. This idea will be investigated in future research.
5
6
7
8
9
10
11
12
28.07.2007
04.08.2007
11.08.2007
18.08.2007
25.08.2007
01.09.2007
Entropy
Date
Entropy of tags over time: Folksonomy RSS feeds (01.08.07 - 01.09.07)
http://www.bibsonomy.org/rss/
http://www.bibsonomy.org/publrss/
http://www.citeulike.org/rss/
http://www.connotea.org/rss
http://del.icio.us/rss/recent/
Figure 10: Entropy of single tags over time.
4.5 Intersections between Tag Spaces
Before covering interoperability or integration issues
of tag spaces from different folksonomies we have to
analyse whether there is a fundamental need. This
need arises if tag spaces reveal significantly different
thematic focuses with relevant portions of unique tags
not being contained in pairwise intersections.
Table 3: Ratio of pairwise intersections between folkson-
omy tag spaces (row T
i
, column T
j
): Ratio[T
i
, T
j
] = |T
i
∩
T
j
|/|T
i
|, with T
i
, T
j
∈ {Bib1, Bib2, Cit, Con, Del}.
Bib1 Bib2 Cit Con Del
Bib1 1,00 0,06 0,19 0,33 0,68
Bib2 0,34 1,00 0,46 0,38 0,68
Cit 0,11 0,05 1,00 0,22 0,44
Con 0,24 0,05 0,26 1,00 0,63
Del 0,02 0,01 0,03 0,03 1,00
Therefore we first explore common parts of tag
spaces using pairwise intersections based on tag string
equality (see Table 3). It is obvious and it was ex-
pected that del.icio.us has the highest coverage of
common language words or typical top tags (column
Del) used in other tag spaces. However, there are dif-
ferences in usage of tag assignments for common tags
as well as a significant portion of tags not being con-
tained in the intersection (difference between 100%
and value given in table). For example the intersec-
tion of del.icio.us and Connotea makes up to 67% of
Connotea tag space (row Con, column Del) and 3%
of del.icio.us tag space (row Del, column Con). This
initially motivates a preferred usage of del.icio.us for
tagging or tag suggestion retrieval. However, there
is a 33% portion of tags in Connotea not being con-
tained in del.icio.us, motivating a preferred usage of
Connotea for such topics exclusively coveredby these
tags, e.g. Connotea and CiteULike have a thematic
focus on natural sciences.
As Table 4 reveals, the differing portions of tag
spaces are growing over time (decreasing ratios), e.g.
see values for full dump intersections. We calculated
pairwise intersections, revealing the ratios between
tag spaces from full dumps (full long-time data sets)
and / or feeds (short time). We use dumps from CiteU-
Like and BibSonomy (both actual as of December 31,
2007), and regard all tag data until the end of our anal-
ysis scope. The dump-only intersections more clearly
reveal different thematic focuses than feed-only inter-
sections, hence strongly motivate comparative analy-
sis.
Table 4: Ratio of pairwise intersections between folk-
sonomy tag spaces (feeds, full dumps, row T
i
, column
T
j
): Ratio[T
i
, T
j
] = |T
i
∩ T
j
|/|T
i
|, with T
i
, T
j
∈
{B1, B2, B1D, B2D, Ci, CiD} with B1=BibSonomy,
B2=BibSonomy-Pub., Ci=CiteULike, D denotes a dump.
B1D has 33719, B2D 13893, and CiD 197463 tags.
B1 B2 B1D B2D Ci CiD
B1 1,00 0,06 0,51 0,23 0,19 0,75
B2 0,34 1,00 0,61 0,95 0,46 0,74
B1D 0,13 0,03 1,00 0,16 0,12 0,44
B2D 0,14 0,11 0,38 1,00 0,27 0,66
Ci 0,11 0,05 0,29 0,26 1,00 0,98
CiD 0,03 0,01 0,08 0,05 0,07 1,00
Further research will cover intersection rates be-
tween tags according to rank, e.g. top level tags, as
well as a comparison of the two co-occurrence net-
works resulting from each pairwise intersection. We
assume to unveil significantly different thematic fo-
cuses and co-tag distributions. Other intersection op-
tions assume a prior mapping of semantically similar
tags, or to filter out spam or irrelevant tags, e.g. ap-
plying a tag usage threshold of 2 reduces the tag space
significantly by about 50% (long power-law tail, see
Figure 3).
WEBIST 2008 - International Conference on Web Information Systems and Technologies
400

4.6 Fairy Tale of Freely Chosen Tags
Why is it useful to analyse and compare tag creation
and storage? During our analysis we stumbled upon
many slang and spam tags as well as tags with high
portion of non-numbers and non-characters. We se-
lected some of these tags and checked, whether these
tags retrieve a search result at all, and whether these
search results are specific or coincide with those re-
trieved using normalized tags. All services in test
provide a web interface to search for a specific tag as
well as a feed interface to request the corresponding
recently tagged items.
The idea is also motivated having a look into Ci-
teULike and BibSonomy dumps, revealing that the ef-
fective, normalized tags (stored in the service back-
end) are not equal to those applied in feeds (user in-
tended tags), neither in semantic richness nor (proba-
bly) in number. Applying non-normalized tags from
feeds either gains no or different search results (ex-
act queries), or the same search result using nor-
malized tags (similarity query, like query). For in-
stance del.icio.us allows usage of unreserved charac-
ters (RFC 3986) for tag creation, e.g. @, !, #, +. They
are used for tags in feeds, but queries skip them us-
ing like-queries. They are not used to enforce specific
semantics, e.g. query(c++) = query(c) = query(c#)
or query(.net) = query(net). The result feeds con-
tain combinations of tags c, c++, c# or respectively
.net and net, not only the tag being searched for.
Finally this observation contradicts the widely
used tagging promise that any freely chosen keyword
can be used as a tag. We notice a loss of user specific
semantics from feed to backend as well as a much
smaller character space to assemble tag words from.
Another aspect is that tags are mostly provided in con-
text with other tags (co-occurrences). Even full chap-
ter titles, word groups or sentences are used as tags
according to CiteULike and Connotea feeds. In the
backend the context between tags is lost due to split-
ting of word groups, normalizing words in, or elimi-
nating words from them.
This information is not provided by services, e.g.
del.icio.us FAQ says that users are allowed to use
character
*
in tags to express emotions or ranking,
however these characters have no effect. Either they
get removed from a tag or the tag is not stored in
backend. This cannot be reliably determined using
feeds without a dump to compare to. BibSonomy
FAQ states that feeds are periodically propagated into
backend database, hence does not exclude that effec-
tive tags might differ from those applied by users.
Users have to knowabout restrictions in order to adapt
their tag spelling and semantic mapping accordingly.
Table 5: Effective tag spaces and queries: F denotes tag
feeds, D: tag dumps, e: exact query (q), l: like q., w: wild-
card q., b: boolean q., c: in-collection q., r: ranked order.
Unreserved (a-zA-Z0-9 -.˜) / reserved characters, and
URL per-cent encoding refer to RFC 3986.
Bib1 Bib2 Cit Con Del
Method F/D F/D F/D F F
Query e/r e/r b/e/w c/e e/l
Case-sens. no no no yes no
Unreserved yes yes yes yes yes
Reserved yes yes no no yes
¨
a
¨
o
¨
u yes yes no yes yes
%-Enc. no no no no yes
Hence, there is a motivation for deeper analysis of in-
tended and effective semantics to evaluate the extent
to which different tagsonomies can be compared to
and integrated into each other or a separate unified
tagsonomy (user based, group based) to support effi-
cient context-based tag suggestions / (semi) automatic
classification. For bootstrapping and dynamic evolu-
tion (e.g. merging, import, export) of tag spaces it is
necessary to know differences and commonalities as
well as mutual interpretation of tags and tag proper-
ties. Here we provide a brief overview of our obser-
vations in Table 5.
4.7 Evaluation of Data Retrieval
For our analysis we requested RSS recent feeds from
social classification services, presenting here the re-
sults for the continuous feed stream from August 01,
2007 until September 01, 2007 (first day partially).
Service-specific item request intervals were manually
adjusted and stayed constant from 2nd day on (see Ta-
ble 1). Table 7 displays the per feed statistics.
A confidential request interval directly depends on
the number of items per feed. The lower the number
is the more frequently the feed must be requested. A
higher number allows for more relaxed intervals. In
order to evaluate the confidence in coverage of re-
trieved data compared to available data, we present
an analysis of feed overlapping between subsequent
items, for an example see Figure 11, for statistics
Table 6. All key figures have been computed us-
ing Apache Jakarta Commons Math Statistics
3
. An
overlap in our context is defined as follows: be F =
{f
ts
0
, · · · , f
ts
n
} the stream of feeds with time stamps
ts
0
≤ ts
k
≤ ts
n
. An overlap is the item sequence in
the intersection O
k,k+1
= I(f
ts
k
) ∩ I(f
ts
k+1
). For
all items i we count the occurrences occ(i) denoting
3
http://commons.apache.org/math/
COMPARATIVE STUDIES OF SOCIAL CLASSIFICATION SYSTEMS USING RSS FEEDS
401

Table 6: Overlap statistics with Item Efficiency = |Items
Stored
|/|Items
Extracted
|, see table sizes in Table 2. del.icio.us
max = 25 was a single peak due to a short-time forgotten interval, connotea single peak max = 226 due to request issues.
Service Extr. Items Avg Min Max Deviation Kurtosis Skewness Efficiency
Bib1 83219 11,66 1 87 11,09 -0,43 -0,38 6,35%
Bib2 61768 34,27 1 297 50,08 -0,64 0,95 2,54%
Cit 228939 12,52 1 62 9,10 -0,99 -0,16 7,96%
Con 139058 7,73 1 226 8,73 -0,76 0,37 12,54%
Del 3838134 1,90 1 25 0,84 -0,22 -0,08 47,48%
Table 7: Items per feed statistics, empty items are filtered.
Service Avg Min Max Dev
Bib1 18,75 1 19 1,47
Bib2 14,00 14 14 0,00
Cit 51,00 51 51 0,00
Con 9,92 1 10 0,41
Del 15,03 2 28 2,86
the number of feeds including that item, a value of
occ(i) ≥ 2 indicates an overlap. Initial value is 1,
otherwise occ(i)
ts
k
= occ(i)
ts
k−1
+ 1, if i ∈ O
k−1,k
.
The table shows very small overlap for del.icio.us,
80,3% of items have overlap ≤ 2 (99,9% ≤ 5).
The extreme is BibSonomy-Pub. (max 297) with a
roughly sporadic item stream with just 62,3% ≤ 20.
In between are BibSonomy (82,3% ≤ 20), CiteULike
(83,8% ≤ 20), and Connotea (95.8% ≤ 20).
These values could be used to estimate a dynamic
back-offfor the request interval in order to reduce ser-
vice load and feed data. Alternatively we could mea-
sure item distribution over time based on time stamp
differences between subsequent items, but CiteULike
RSS feeds do not contain item time stamps.
10
20
30
40
50
60
70
80
90
100
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
Count of identical items in subsequent feeds (>1 is redundant)
Item rank in temporal order
RSS feed overlapping (01.08.-01.09.2007)
Connotea, interval 3min
Arithmetic mean, window 100
Figure 11: Feed overlapping between subsequent items for
Connotea.
5 CONCLUSIONS AND
OUTLOOK
We presented comparisonresults from feed-onlyanal-
ysis of 5 leading social classification services, to
the best of our knowledge first work focusing on
tag space comparison, integration and interoperabil-
ity. Our analysis reveals that feed-only data satisfy
typical distributions well, stabilize very rapidly con-
cerning top-ranked data, and bear significant focus-
dependent pair-wise intersections and thematic differ-
ences. Thus, they serve as a promising space saving
source for comparative and integrative social network
investigations.
Further mid-term research will cover a deeper
comparison of feeds and dumps concerning seman-
tic differences and coverage. As indicated in section
4.6 there is need for an analysis of loss in semantics
between feeds and backend data. Promising results
we also expect from a comparison of co-occurrence
networks in order to offer context-specific tag sugges-
tions as well as to unveil network differences for tag
space intersections (same tags, different co-tag net-
works). Currently there is an ongoing master thesis
evaluating tag suggestion algorithms concerning effi-
ciency, quality and complexity of resulting tag spaces.
A further study scheduled is about the correlations
between tag spaces and tagged content using Vector
Space Model (VSM, TF-IDF) in order to bootstrap
tags for untagged content.
REFERENCES
Ames, M. and Naaman, M. (2007). Why We Tag: Motiva-
tions for Annotation in Mobile and Online Media. In
Proceedings of Computer/ Human Interaction Confer-
ence (CHI’07).
Begelman, G., Keller, P., and Smadja, F. (2006). Automated
Tag Clustering: Improving search and exploration in
the tag space. In WWW ’06: Proceedings of the 15th
international conference on World Wide Web.
WEBIST 2008 - International Conference on Web Information Systems and Technologies
402

Berendt, B. and Hanser, C. (2007). Tags are not meta-
data, but ”just more content” - to some people. In
International Conference on Weblogs and Social Me-
dia (ICWSM’07).
Bhagat, S., Rozenbaum, I., Cormode, G., Muthukrishnan,
S., and Xue, H. (2007). No Blog is an Island - Ana-
lyzing Connections Across Information Networks. In
ICWSM’2007 Boulder, Colorado, USA.
Brooks, C. H. and Montanez, N. (2006). An Analysis of the
Effectiveness of Tagging in Blogs. In AAAI Spring
Symposium on Computational Approaches to Analyz-
ing Weblogs.
Capocci, A. and Caldarelli, G. (2007). Folksonomies
and clustering in the collaborative system CiteULike.
http://arxiv.org/abs/0710.2835.
Cattuto, C. (2007). Structure and Evolutionof Collaborative
Tagging Systems. In WM 2007: Proceedings of the
4. Konferenz f¨ur Professionelles Wissensmanagement.
Workshop on Collaborative Knowledge Management.
Cattuto, C., Loreto, V., and Pietronero, L. (2006).
Collaborative Tagging and Semiotic Dynamics.
http://arxiv.org/abs/cs.CY/0605015.
Chi, E. H. and Mytkowicz, T. (2007). Understanding Navi-
gability of Social Tagging Systems. In Proceedings of
Computer Human Interaction (CHI’07).
Golder, S. and Huberman, B. A. (2005). The Structure of
Collaborative Tagging Systems. Journal of Informa-
tion Science, 32:198–208.
Gruber, T. (2005). TagOntology - A way to
agree on the semantics of tagging data.
Presentation to Tag Camp, Palo Alto,
CA,http://tomgruber.org/writing/tagontology.htm.
Halpin, H., Robu, V., and Shepherd, H. (2007). The Com-
plex Dynamics of Collaborative Tagging. In WWW
’07: Proceedings of the 16th international conference
on World Wide Web. Track E* Applications.
Hotho, A., J¨aschke, R., Schmitz, C., and Stumme, G.
(2006). BibSonomy: A Social Bookmark and Pub-
lication Sharing System. In de Moor, A., Polovina, S.,
and Delugach, H., editors, Proceedings of the Concep-
tual Structures Tool Interoperability Workshop at the
14th International Conference on Conceptual Struc-
tures, Aalborg, Denmark. Aalborg University Press.
Lambiotte, R. and Ausloos, M. (2006). Collaborative
tagging as a tripartite network. Springer LNCS,
3993:1114–1117.
Li, R., Bao, S., Fei, B., Su, Z., and Yu, Y. (2007). To-
wards Effective Browsing of Large Scale Social An-
notations. In WWW ’07: Proceedings of the 16th in-
ternational conference on World Wide Web. Track:
Web Engineering, Session: End-User Perspectives
and measurement in Web Engineering.
Mathes, A. (2004). Folksonomies - Cooperative Classifica-
tion and Communication Through Shared Metadata.
http://www.adammathes.com/academic/computer-
mediatedcommunication/folksonomies.html
Santos-Neto, E., Ripeanu, M., and Iamnitchi, A. (2007).
Tracking User Attention in Collaborative Tagging
Communities. In Proceedings of International
ACM/IEEE Workshop on Contextualized Attention
Metadata: personalized access to digital resources.
Schmitz, C., Grahl, M., Hotho, A., Stumme, G., Cattuto,
C., Baldassarri, A., Loreto, V., and Servedio, V. D. P.
(2007). Network Properties of Folksonomies. In
WWW ’07: Proceedings of the 16th international con-
ference on World Wide Web. Workshop on Tagging
and Metadata for Social Information Organization.
Shaw, B. (2005). Utilizing Folksonomy: Simi-
larity Metadata from the Del.icio.us System.
http://www.metablake.com/webfolk/webproject.pdf.
Shirky, C. (2005). Ontology is Overrated:
Categories, Links, and Tags. http://
www.shirky.com/writings/ontology overrated.html
Veres, C. (2006). Concept Modeling by the Masses: Folk-
sonomy Structure and Interoperability. Conceptual
Modeling - ER 2006, pages 325–338.
Zhang, L., Wu, X., and Yu, Y. (2006). Emergent Semantics
from Folksonomies: A Quantitative Study. Journal on
Data Semantics VI, Springer LNCS, 4090:168–186.
Zollers, A. (2007). Emerging Motivations for Tagging: Ex-
pression, Performance, and Activism. In WWW ’07:
Proceedings of the 16th international conference on
World Wide Web.
COMPARATIVE STUDIES OF SOCIAL CLASSIFICATION SYSTEMS USING RSS FEEDS
403
