
A SURVEY ON WEB SERVICE DISCOVERING AND COMPOSITION
Elena del Val Noguera and Miguel Rebollo Pedruelo
Department of Information Systems and Computation
Technical University of Valencia, Camino de Vera s/n, Valencia, Spain
Keywords:
Web services, semantic web, intelligent agents, discovering, composition, planning, model checking.
Abstract:
This paper reviews the existing techniques used in the discovering and composing of services. The task of
selecting an adequate service can quickly grow tedious if all services that are listed under a certain description
have to be compared manually for the final selection. And what is more, the final selection does not only
depend on service parameters like executions costs or accuracy, but depends on the usefulness of objects or
information that service offers. This problem is present in open environments where entities like web services
or agents need to locate other entities to achieve cooperation, delegation or interoperation. For these reason
these two approaches, web services an agents have deal with these problem proposing an automated and
efficient mechanism to determine a structural and semantic match descriptions between entities.
1 INTRODUCTION
The application of thesemantic web in the area of web
services has as aim a more intelligent web in which is
possible to achieve a more effective communication
among computers. It concentrates its efforts towards
web service semantic descriptions search. Descrip-
tive languages are not enough to describe complex re-
lationships between ontologies. For that reason, other
languages as OWL-S or WSMO have been proposed
with the aim that other machine can read these de-
scriptions and reason about how interact with the ser-
vices.
Automatic location of services can considerably
reduce the cost of making applications that work to-
gether and enable a more flexible integration, where
providers are dynamically selected based on what
they provide and other non-functional properties. To
deal with these issues agent orientation is an ap-
propriate design paradigm to enforce automatic and
dynamic collaborations, especially in e-business and
complex environments.
In this paper we present a revision of the different
solutions that have contributed to deal with problem
of the service discovery. The rest of the paper is struc-
tured as follows. Section 2 gives a service discovery
description and it also presents the fundamentalstages
that are involve in the discovery process. Section 3
introduces the main approaches used in matchmaking
algorithms. Section 4 surveys the existing state of the
art in web service matchmaking algorithms. Section 5
the contribution of agent systems to service discovery
process and we close with a summary and concluding
remarks in section 6.
2 SERVICE DISCOVERY
Semantic service discovery consist of searching ser-
vice descriptions with exact or similar properties.
These properties, in most cases, are IOPE’s (Inputs,
Outputs, Preconditions and Effects). Basically, the
matchmaking process consist of bounding the number
of possible matches between offered and requested
services. This matchmaking process can be divided
in three stages:
Selection Process. A service request is receivedand
sent to a matchmaker. The matchmaker is responsible
of finding a suitable service or set of services accord-
ing with the requested description. The suitability de-
pends on the information that the algorithm considers.
Usually, the degree of similarity between service de-
scription and the request is used and it will depend
on the degree of similarity between input and output
parameters (IO’ s).
135
del Val Noguera E. and Rebollo Pedruelo M. (2008).
A SURVEY ON WEB SERVICE DISCOVERING AND COMPOSITION.
In Proceedings of the Fourth International Conference on Web Information Systems and Technologies, pages 135-142
DOI: 10.5220/0001524101350142
Copyright
c
SciTePress

Ranking. The set of possible service providers is
refined according to additional information that the
client has defined previously to choose the more suit-
able provider. The concept of non functional at-
tributes, in most of cases related to quality of ser-
vice (QoS), is introduced. These attributes are used
in ranking functions that gives a mark or punctuation
to each provider selected in the previous stage. Fur-
thermore, the user can define an threshold to filter the
obtained services.
Evaluation. When the results of the matchmak-
ing process are obtained, it is recommended evalu-
ate these results to identify possible modifications in
some matchmaking parameters. The most important
points to be evaluated are the quality of the results
and the system execution. Precision and recall are the
most commonly used measures.
3 SERVICE DISCOVERY
APPROACHES
At the beginning, all the approaches used syntactic
similarity to establish the degree of matching between
two service descriptions. With the arrival of semantic
web, service descriptions include data structures and
also relationships between other concepts, restrictions
and rules. At this situation, the proposed algorithms
are based on semantics. Furthermore, in some com-
plex environments, where negotiations and protocols
to interact between entities, it can be possible to es-
tablish discovery models based on them.
Service Discovery based on Keywords. Services
can be filtered by doing a search based on keywords.
A typical keyword scenario is a search engine that re-
ceives keywords as a query and the engine engages
query keywords with service description keywords.
In (Bachlechner et al., 2006) there is a review of this
kind of discovery process.
Service Discovery based on Semantics. Keywords
do not use explicit semantic and, therefore, they do
not allow to make inferences to achieve better search
results. The use of vocabularies with a formal and
explicit semantic is considered as a second approach.
Ontologies give us a shared and explicit terminology
to describe web services and queries with a logic for-
malization that will allow the use of inference. We
found different approaches according to the service
description language used. Among them, the most
important ones use OWL-S, WSMO and SAWSDL
(based on WSDL-S) languages. These languages pro-
vide the answer to the main questions that arise when
a web service has to be described: What are the ser-
vice requirements from the users? What the service
provides to the users? How does the service work?
How the service can be used?.
Service Discovery based on Complex Discovery
Model and Negotiation/Contracting. It comprises
discovery models based on interaction protocols, for-
warding QoS and privacy requirements, negotiation
dialogs for refining discovery and establishing ser-
vice requirements. This kind of service discovery is
also being used in multiagents systems (Caceres et al.,
2006) and in e-market environments.
4 SERVICE DISCOVERY BASED
ON SEMANTICS
There are many matchmaking proposals in the area of
web services and semantic web. In this section, we
review some of them paying attention to characteris-
tics such as the information that they use to deal with
the matchmaking process, if they take into account
service composition or cross ontologies or if they use
QoS information during the discovery process.
4.1 Iope’s Algorithms
In general, most of the existing matchmaking al-
gorithms use just inputs and outputs to determine
the matching degree between requests and advertise-
ments. But there are some algorithms that, apart from
that information, take into account preconditions and
postconditions (IOPE parameters).
The first service discovery algorithm is based on
DAML-S (OWL-S predecessor) and uses IO’s. It was
developed by Paolucci et al. (Paolucci, 2002). This
approach uses the semantic of the Service Profile and
UDDI registries to maintain the descriptions of the
services. The algorithm deals with the importance
in matchmaking classification of the service outputs.
A matching between a service advertisement and a
service request consists of matching all the service
request outputs with those of the service advertise-
ment; and all the inputs of the service advertisement
with those of the service request. The degree of sim-
ilarity between service provider and server request
will depend on the degree of similarity between in-
put and output parameters (IO’ s) and it is reduced
generally to the minimal distance between them in
the taxonomic tree. The denomination of the degrees
varies according to literature (Abela and Montebello,
2002)(Lei and Horrocks, 2003)(Paolucci, 2002)(Con-
stantinescu and Faltings, 2002). Paolucci’s algorithm
WEBIST 2008 - International Conference on Web Information Systems and Technologies
136

is limited to discover simple services. It does not
consider the composition discovery nor the use of
different ontologies. Another lack is that the pro-
cess of matching does not consider parameters re-
lated with quality of service (QoS). From this algo-
rithm arose others that made some modification to
deal with some of its deficiencies (Abela and Mon-
tebello, 2002)(Klusch et al., 2006)(Aversano et al.,
2004)(Cardoso and Sheth, 2002).
(Wolf-Tilo and Matthias, 2003) define a different
matchmaking algorithm. In this algorithm, they make
first a search based on keywords and, once obtained
a list of results, the user could introduce IO’s param-
eters that must have the services and the values for
these parameters. Finally, a reasoner eliminates those
services that do not have these defined parameters and
the resultants will be executed with the values that
were introduced by the client. The results of the ex-
ecutions are ordered following some constraints that
benefit the client, as the quality of service.
(Klusch et al., 2006) present OWLS-MX, a hy-
brid matchmaking algorithm that computes the de-
gree of semantic matchmaking for a given pair of
service advertisement and request by successively ap-
plying five different filters: exact, plug-in, subsumes,
subsumed-by and nearest-neighbor. The first three
are logic based only whereas the last two are hybrid
due to the required additional computation of syntac-
tic similarity values. The objective of hybrid seman-
tic web service matching is to improve semantic ser-
vice retrieval performance by appropriatelyexploiting
means of both crisp logic based and approximate se-
mantic matching.
In the matchmaking process is also important to
consider the global schema of execution, which is
given by the choreography. The task of selecting a
web service, that should play a role in a choreogra-
phy, implies verifying two things: the conformance
of the service to the specification of a role of interest
(guarantees that the message exchange will produce
correct and accepted conversations), and that the use
of that service (allows the achievement of the goal).
In (Baldoni et al., 2007) is shown that performing
a match operation by operation does not preserve the
global goal. They also show how to overcome these
limits by exploiting the choreography definition. Ac-
tually, it is possible to extract from the choreography
some information that can be used to bias the match-
ing process so that the global goal will be preserved.
4.2 Composition
The algorithms above presented address the match-
making process. However, they are limited to dis-
cover a single service. In many situations, queries
that cannot be satisfied by a single service might be
frequently satisfied by composing several services.
(Aversano et al., 2004) display a discovery algo-
rithm that analyses DAML-S service profile, takes as
objective the outputs of the user request and consid-
ers the possibility of reaching it with only one service.
If it is not possible, the method includes a backward-
chaining algorithm with the purpose of verifying the
possibility of finding a match for the user request by
means of a composition of several services. This al-
gorithm is also capable of performing a cross ontol-
ogy matching for service descriptions that use dif-
ferent ontologies. However, it crosses ontologies at
query time, hence severely affecting the efficiency of
the whole procedure.
The matching algorithms described until now are
based on DAML-S/OWL-S and use the service pro-
file. Analyzing web services only through their ser-
vice profile (i.e., their IOs), can severely affects the
process of discovery of service aggregations that sat-
isfy a request. Indeed, the service profile does not
describe the internal behavior of services, so in some
cases it does not provide valuable information needed
for composing services.
The first discovery algorithm based on the anal-
ysis of the OWL-S Process Model was proposed by
(Bansal and Vidal, 2003). It stores advertisements
of services as tree structures corresponding to their
process models. The compound processes correspond
with intermediate nodes whereas the atomic processes
correspond with the leaves. The matchmaking algo-
rithm begins in the root of the tree of the advertise-
ment of the service and visits all the subtrees finish-
ing in the leaves. For each node, the algorithm verifies
the compatibility between the IOs and the IOs of the
request.
SAM (Brogi et al., 2003) is an extension of the
Bansal algorithm that return, when a complete match-
making is not possible, a list of partial matchings (a
composition of subservices that can provide only cer-
tain requested outputs by the client). Besides, when
it does not find any match, SAM is able to suggest to
the user additional inputs that can be enough to reach
complete match. The main lack of this algorithm is
that does not consider the use of different ontologies.
Another interesting point to take into account is
related with goals. Languages as WSMO, that con-
sider goals to achieve a composition. The work pre-
sented in (van Riemsdijk and Wirsing, 2007) points
out how goal-oriented techniques, which increase
flexibility in handling failures, can be applied in the
context of service-oriented systems and specifically
in web services composition.
A SURVEY ON WEB SERVICE DISCOVERING AND COMPOSITION
137

4.3 Crossing Ontologies
Currently, individual users or user communities hope
to be able of making queries about interesting ser-
vices using descriptions that are expressed in terms
of their own ontologies, which do not have to fit in
with the searched service descriptions. The above-
named algorithms do not address properly the prob-
lem of crossing ontologies.
(Cardoso and Sheth, 2002) propose an algorithm
that allows to manage multiple ontologies. The simi-
larity function used to compare concepts is based on
the ontology taxonomy. The algorithm tries to man-
age concepts that are not related using the concepts
properties. (Aversano et al., 2004) present a cross on-
tology matching that can cancel the problem of differ-
ent ontologies. Therefore, there is no need of classify
in a semantic domain the web service when creating
the service description.
(Pathak et al., 2005) propose an ontology mapping
during service discovery, such that terms and con-
cepts in the service requester’s ontologies are brought
into correspondence with the service provider’s on-
tologies. To do the mappings they use interoperation
constraints, i.e. a set of relationships that exist be-
tween elements from two different hierarchies.
(Brogi et al., 2006) present an extension of SAM
based on hypergraphs who allows to cross differ-
ent ontologies. The matchmaking system consists of
two main modules: the Hypergraph Builder and the
Query Solver. The Hypergraph Builder analyzes the
ontology-based descriptions of the registry-published
services in order to build a labeled directed hyper-
graph, which synthesizes all the data dependencies of
the advertised services. The vertexes of the hyper-
graph correspond to the concepts defined in the on-
tologies employed by the analyzed service descrip-
tions, while the hyperedges represent relationships
among such concepts (subConceptOf, equivalentCon-
ceptOf and intra-service dependency). The Query
Solver explores the hypergraph by suitably consider-
ing the intraservice and inter-service dependencies to
address the discovery of (compositions of) services as
well as by considering the subConceptOf and equiva-
lentConceptOf relationships to cope with differenton-
tologies.
4.4 Hypergraphs
A hypergraph is a generalization of a graph, where
edges (hyperedges) can connect any number of ver-
texes. Formally, a hypergraph is a pair (V, E) where
V is a set of nodes or vertexes and E is a set of non-
empty subsets of V called hyperedges. While graph
edges are pairs of nodes, hyperedges joints arbitrary
sets of nodes.
(Yang et al., 2005) use arc-labeled and arc-
weighted trees to represent product/service require-
ments and offers. They propose a tree similarity al-
gorithm that traverses input trees top-down and then
computes their similarity bottom-up. During tree sim-
ilarity computation, when a subtree in T
1
is miss-
ing in tree T
2
(or viceversa), the algorithm compute
the simplicity of the missing subtree. The tree sim-
plicity measure takes into account the node degree
at each level, the depth of the leaf node and the arc
weights. This algorithm allows partial product de-
scriptions representations via subtrees missing.
(Hashemian and Mavaddat, 2005) use a specific
notation, called interface automata (state-base model)
in order to formally model web services. The infor-
mation that an interface automaton exposes is the IO
of a component and the temporal ordering of the ac-
tions it performs. This information can be extracted
form the OWL-S specification of web services. Based
on the properties exposed by interface automaton of
each web service ws, three pieces of information are
stored in the repository: its set of inputs, its set of out-
puts and dependency information between IOs of the
web service. The repository is stored as a graph that
contains web services information. The nodes repre-
sents I/O and there is a directed edge form node v
1
to node v
2
if and only if there is a dependency be-
tween the input and the output. They solve the prob-
lem in two steps: (i) finding web services that can po-
tentially participate in the composition, and (ii) find-
ing the composition setup based on the web services
found in the previous step.
4.5 Model Checking
Web services are composed online from pieces of
software created by different programmers. Individ-
ual services can be checked to ensure that they are
error free, but when new services are composed there
are no means to check whether the composed service
fulfils its purpose. Some formal methods, as model
checking, has been proposed to verify the correctness
of complex services. But current languages are semi-
formal, so the correctness of the composition depends
on the cleverness of the designer. To use formal mod-
els requires translations from the languages used to
describe WS into more formal ones.
(Gao et al., 2006) translate web services specified
in BPEL4WS into pi-calculus, which is nearer to pro-
gramming languages than finite automata or tempo-
ral logics. Nevertheless, this formal description is
not soundness and some manual translation is still
WEBIST 2008 - International Conference on Web Information Systems and Technologies
138

needed. The model checking is used with two pur-
poses: (i) to check if services satisfy customer’s de-
mands and and designer’s specifications, and (ii) to
check if orchestration satisfies liveness, safety, fair-
ness and reachability. Different methods are used:
bisimulation to verify the specification, mu-calculus
to check properties as safety or reachability and pi-
calculus to eliminate ill behaviors.
Nakajima claims that to verify a composite web
service prior to its execution may be mandatory
(Nakajima, 2002). First, translates a WSFL descrip-
tion into Promela, the specification language for SPIN
model checker. Furthermore, additional properties are
expressed in LTL to be added to the model checking
process. The verification process detects reachability,
deadlock freedom and specific user properties.
Planning as model checking (Giunchiglia and
Traverso, 1999) is a method of solving planning prob-
lems modeling them as model checking problems.
This solution is based on transition systems, but web
services are a message passing paradigm, so some
special considerations have to be made. (Yu and
Reiff-Marganiec, 2006) make a formulation of the so-
lution by modifying the strong cycle planning algo-
rithm, which guarantees that all paths reach a solu-
tion and they are fair. A four-phased algorithm is pro-
posed. First, the planning goal and the initial knowl-
edge is specified. After that, automatically selects
from the repository relevant web services to build the
plan. In third place, the algorithm search for plans.
Finally, a physical composition step allows clients to
choose the better plan, generates a executable plan
specified in BPEL and monitors its execution, re-
planning when a failure is detected.
(Walton, 2004) uses model checking to validate
the correctness of communication protocols between
agents in an platform that integrates agents and web
services. The services are described in WSDL. Com-
plex interactions among the entities that offer services
are represented by the protocols, who are specified
in a directly executable language called MAP. As the
Nakajima’s algorithm, the specification is translated
into Promela language. This one provides a complete
automatic translation that allows non-expert to vali-
date their services.
The main problem in all these approaches is the
complexity of the state space. All of them make dif-
ferent simplifications to the problem to be capable of
managing the validation process by limiting the num-
ber of services (or agents) and the length of the mes-
sage interchanging mainly. Moreover, designer’s in-
tervention is often needed to translate service descrip-
tions into formal languages for model checking.
4.6 Non-Functional Parameters
In some algorithms, the service selection process
is based in non-functional parameters and, in other
cases, the algorithms refine the set of candidate ser-
vice providers based on user-specified non-functional
attributes, namely Quality of Service (QoS). These
factors and domain specific characteristics affect on
the service selection.
According to (J.Radatz and Sloman, 1988) the
Quality of Service is a set of non-functional attributes
that may impact the service quality offered by a web
service. The main problem of this kind of information
is that we cannot trust the QoS characteristics pub-
lished by provider.
(Pathak et al., 2005) establish a categorization
in two groups: domain-dependent and domain-
independent attributes. The domain-independent at-
tributes represent those QoS services characteristics
which are not specific to any particular service (for in-
stance, scalability or availability). On the other hand,
domain-dependent attributes capture those QoS prop-
erties which are specific to a particular domain and
most of the times are dynamic and depends on the in-
stant in which the service is executed.
To deal with information reliability, service repu-
tation is an specially interesting property that could be
regarded as a measure that accumulates a user opinion
about QoS in general. (Kalepu et al., 2004) address
this problem.
(Pathak et al., 2005) propose a taxonomy for
the non-functional attributes which provide a better
model for capturing various domain-dependent and
domain-independent QoS attributes of the services.
These attributes allow users to dynamically select ser-
vices based on their non-functional aspects. This
work also introduce the notion of personalized rank-
ing criteria, which enhances the traditional ranking
approach, primarily based on the degree of match.
Furthermore, in this work a kind of ontology mapping
is presented .
Following this trend, (Kokash, 2005) present an
approach based on the application of a distributed rec-
ommendation system to provide QoS information and
on testing of retrieval methods on service specifica-
tions.
(Aversano et al., 2004) base the searching process
on syntactic information and on service quality met-
rics and semantics to increase the precision of the dis-
covery process. To take into consideration the QoS in
the discovery process, the customer of the service will
assign a weight to every attribute. For each selected
service, a weighted sum is performed among all the
attributes an the final value represents the quality of
A SURVEY ON WEB SERVICE DISCOVERING AND COMPOSITION
139
the service.
4.7 Efficient Matching
Due to the complexity of the underlying semantic rea-
soning, matching semantic web service capabilities is
a heavy process. Furthermore, the matchmaking pro-
cess could be intractable when the number of avail-
able services gets large. (Mokhtar et al., 2006) de-
scribe a solution towards the efficient matching of se-
mantic service capabilities. This approach combines
optimizations of the discovery process at reasoning
and matching levels. Towards the optimization of
the discovery process at reasoning level, they use the
solution proposed by (Constantinescu and Faltings,
2002) for encoding concept hierarchies, represented
by hierarchies of concepts, using intervals. These hi-
erarchies represent the subsumption relationships be-
tween all the concepts in the ontologies used in the
directory. The main idea is that any concept is associ-
ated with an interval. Under the assumption that ser-
vice advertisements and service requests already con-
tain the codes corresponding to the concepts that they
involve, semantic service reasoning reduces to a nu-
meric comparison of codes.
(Srinivasan et al., 2004) present an approach to
optimize service discovery in a UDDI registry, aug-
mented with OWL-S for the description of seman-
tic web services. This approach is based on the fact
that the publishing phase is not a time critical task.
Therefore, the authors propose to exploit this phase to
pre-compute and store information about the incom-
ing services. This proposal increases the time spent
for publishing service advertisements, but it consider-
ably reduces the time spent to answer a user request
compared to approaches based on on-line reasoning.
The majority of the algorithms presented in the
area of web services faces the discovery problem us-
ing the IO’s parameters and trying to solve problems
such as service composition or cross ontologies and
also in some of them non-functional parameters are
taken into consideration. But they do not explote all
the possibilities that semantic offers.
5 AGENTS AND DISCOVERY
PROCESS
Nowadays, service oriented computing (SOC) brings
additional considerations, such as the necessity of
modeling autonomous and heterogeneous compo-
nents in uncertain and dynamic environment. Such
components must be autonomously reactive and
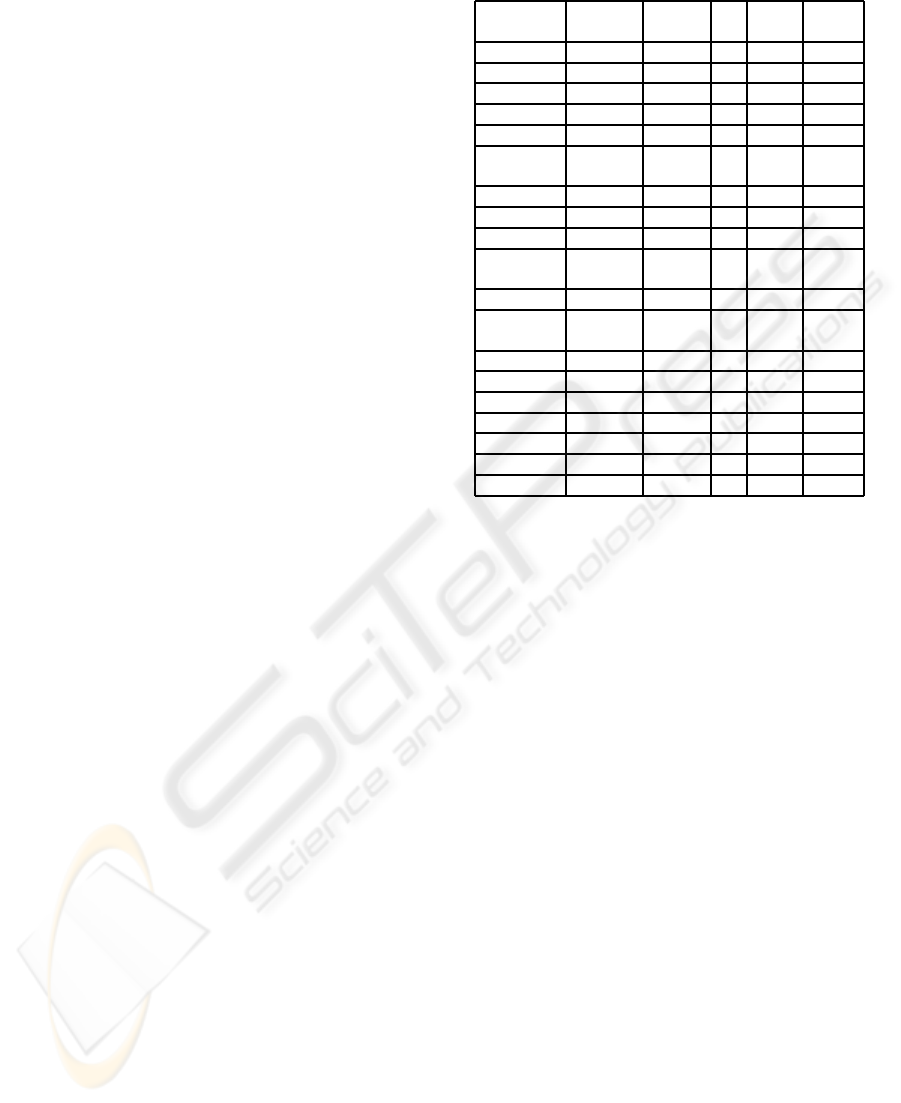
Table 1: Service Discovery Algorithms.
Alg. Lang. IO’S/ C. Cross QoS
IOPE’S Ont.
Paolucci02 DAML-S IO’s
Abela02 DAML-S IO’s
Constant.02 DAML-S IO’s
√
Cardoso02 DAML-S IO’s
√ √
Lei03 DAML-S IO’s
Wolf03 IO’s Soft
constr.
Bansal03 DAML-S IO’s
√
Brogi03 OWL-S IO’s
√
Benata.03 DAML-S IO’s
√
Aversa.04 DAML-S IO’s
√ √ √
PE’s?
Sriniv.04 OWL-S IO’s
√
KluS05 OWL-S IO’s
√
PE’s?
Pathak05 OWL-S IOPE’s
√ √
Hashem.05 OWL-S IO’s
√
Yang05 OWL-S IO’s
√
Kokash05 WSDL IO’s
√
Klusch06 OWL-S IO’s
√
Brogi06 OWL-S IO’s
√ √
Mokhtar06 DAML-S IO’s
√
proactive yet able to interact flexibly with other com-
ponents and environments. Agent orientation is an
appropriate design paradigm to enforce automatic
and dynamic collaborations, especially for systems
with complex and distributed transactions. Agent
paradigm has technical advantages in software con-
struction, legacy systems integration, transaction-
oriented composition and semantics-based interac-
tion. For this reason, many ideas from the research in
multiagent systems could be used in service-oriented
computing approaches. Key MAS concepts are re-
flected directly in SOC with ontologies, process mod-
els, choreography, directories and facilitators, service
level agreements and quality of service measures.
Agent paradigm has presented several ideas that
can be taking into consideration for web service dis-
covery algorithms. (Caceres et al., 2006), presents
an approach that complement the existing methods
by considering the types of interactions and roles
that services can be used in. Other approaches (Sen-
soy et al., 2007) use the objective experience data of
agents in order to evaluate its expectation from a ser-
vice provider and makes decisions using its own cri-
teria and mental state. Basically, service consumers
collect previous experiences form other service con-
sumers with similar demand and make decisions us-
ing different methods. By simply sharing their expe-
riences, service consumers lead to the emergence of a
consumer society in which increase the overall satis-
faction.
WEBIST 2008 - International Conference on Web Information Systems and Technologies
140

In some MAS, brokers are used as the mecha-
nism of discovery and synchronization mechanisms
among autonomous agents. (Sycara et al., 2004)
present a brokering protocol which consist on two
complex reasoning tasks: discovery and mediation.
Discovery task is divided in two different reasoning
tasks: abstraction from the query to the provider’s re-
quired capabilities and comparison and matching of
required capabilities with providers capabilities. Me-
diation task requires the broker to transform the orig-
inal query into one that can send to the provider.
Sometimes, matchmaking process is considered
as a query to a static set of available options. This
view is to simple. We can consider matching as a typ-
ical example of symmetry and iterative nature (Heep,
2006). Symmetric because the visibility of character-
istics might equally depend on whether the other party
meets specific criteria. Iterative because we learn the
option space by analyzing our initial query’s result
set, and might restrict or weaken our requirements
and preferences in response. Negotiation protocols
are another mechanism used in MAS. The participant
agents negotiate about the properties of the services
they request and provide to bind agreements and con-
tracts with each other. In (Dang and Hungs, 2006)
is presented a protocol that supports many-to-many
negotiation in which several agents negotiating with
many other agents simultaneously using colored petri
nets.
6 CONCLUSIONS
After the review process, some common weakness
have been detected. Most of them they do not exploit
all the data provided in the service profile. The ma-
jority of the algorithms use IO’s but forget the precon-
ditions and postconditions and the capability to make
inference about this data to obtain new information
that could be useful to eliminate false suitable ser-
vices. Moreover, only a few take into account infor-
mation related with QoS and theyuse this information
just for ranking, they are not used to select services
or reduce the search space with this data. Further-
more, they not emphasize in other aspects that could
give them more flexibility in the discovery process
such as allowing partial matching or fuzzy data. In
general, web services nor have internal state and nei-
ther awareness of changes in its environment and their
algorithms do not consider temporal constraints over
services.
Current web services technologies have not ex-
ploited sufficient semantics and approaches to dy-
namic service-oriented operations in open environ-
ments. Agents present an extended proposals that pro-
vide a more flexible and efficient matchmaking pro-
cess. Some of the proposals use algorithms very simi-
lar to web services but they add use the characteristics
of the agents to achieve a more efficient and flexible
matching. We have seen in this article that the use of
roles, interaction patterns, trust or negotiation. Agents
solve problems present in web services such as in-
ternal state and communication. Agents have aware-
ness of theirs internal states and for communication
use asynchronous message interchange which allows
to stablish conversations. There are some open issues
such as consider QoS in matchmaking process and,
as in web services, take into account temporal con-
straints.
To conclude, after analyse the proposals from
these two worlds, the highest benefit would be
achieved combining the advantages of each world.
The problem of service discovery is faced by the web
services using semantic languages, taking into ac-
count service composition and other points as cross-
ing ontologies or QoS. But these items provide a func-
tional matching that do not consider other informa-
tion, more subjective or in a higher level of abstrac-
tion, but that can be also important to provide a more
accurate service discovery that fits better with the user
request. To achieve that, we have to consider no only
the information present in the current descriptions of
web services. We have also to consider the kind of in-
teractions between the entities, the type of role that is
necessary to interact with or the reputation of the in-
volved providers. These characteristics are useful to
limit the possible candidates to be a suitable provider
and to make easier to find what you want. In some
web services proposals, these ideas are being taken
into account, but it is difficult task due to the differ-
ence between web services and agents, although grad-
ually the difference between them is becoming lower.
REFERENCES
Abela, C. and Montebello, M. (2002). Daml enabled web
services and agents in the semantic web. In WS–
RSD’02, Germany.
Aversano, L., Canfora, G., and Ciampi, A. (2004). An al-
gorithm for web service discovery through their com-
position. In IEEE International Conference on Web
Services (ICWS04).
Bachlechner, D., Siorpaes, K., Lausen, H., and Fensel, D.
(2006). Web Service Discovery - A Reality Check.
Baldoni, Baroglio, Martelli, Patti, and Schifanella (2007).
Service selection by choreography-driven matching.
In ECOWS Workshop on Emerging Web Services
Technology.
A SURVEY ON WEB SERVICE DISCOVERING AND COMPOSITION
141

Bansal, S. and Vidal, J. (2003). Matchmaking of web ser-
vices based on the daml-s service model. In Second
International Joint Conference on Autonomous Agents
(AAMAS03). T. Sandholm and M. Yokoo.
Brogi, A., Corfini, S., Aldana, J., and Navas, I. (2006).
Automated discovery of compositions of services de-
scribed with separate ontologies.
Brogi, A., Corfini, S., and Popescu, R. (2003).
Composition-oriented service discovery. Proceed-
ings of 5th International Conference on Autonomous
Agents and Multi-Agent Systems (AAMAS).
Caceres, C., Fernndez, A., Ossowski, S., and Vasirani, M.
(2006). Role-based service description and discov-
ery. In International Joint Conference on Autonomous
Agents and Multi-Agent Systems.
Cardoso, J. and Sheth, A. (2002). Semantic e-workflow
composition. Journal of Intelligent Information Sys-
tems (JIIS).
Constantinescu, I. and Faltings, B. (2002). Efficient match-
making and directory services. Technical Report No
IC/2002/77.
Dang, J. and Hungs, M. (2006). Concurrent multiple-issue
negotiation for internet-based services. In IEEE Inter-
net Computing, number Vol.10 - 6, pages 42–49.
Gao, C., Liu, R., Song, Y., and Chen, H. (2006). A model
checking tool embedded into services composition en-
vironment. In GCC ’06: Proceedings of the Fifth
International Conference on Grid and Cooperative
Computing (GCC’06), pages 355–362, Washington,
DC, USA. IEEE Computer Society.
Giunchiglia, F. and Traverso, P. (1999). Planning as model
checking. In ECP, pages 1–20.
Hashemian, S. and Mavaddat, F. (2005). A graph-based
approach to web services composition. In IEEE Com-
puter Society.
Heep, M. (2006). Semantic web and semantic web services.
In IEEE Internet Computing, number Vol.10 - 2, pages
85– 88.
J.Radatz and Sloman, M. (1988). A standard dictionary for
computer terminology: Proyect 610. IEEE Computer.
Kalepu, S., Krishnaswamy, S., and Loke, S. (2004). Reputa-
tion = f(user ranking, compliance, verity). In Proceed-
ings of the IEEE International Conference on Web
Services.
Klusch, M., Fries, B., and Sycara, K. (2006). Automated
semantic web service discovery with owls-mx. In
Proceedings of 5th International Conference on Au-
tonomous Agents and Multi-Agent Systems (AAMAS),
Hakodate, Japan.
Kokash, N. (2005). Web service discovery with implicit
qos filtering. In Proceedings of the IBM PhD Student
Symposium.
Lei, L. and Horrocks, I. (2003). A software framework
for matchmaking based on semantic web technol-
ogy. In Twelfth International World Wide Conference
(WWW2003), Germany.
Mokhtar, S., Kaul, A., Georgantas, N., and Issarny, V.
(2006). Towards efficient matching of semantic web
service capabilities. In Proc. of WS-MaTe06.
Nakajima, S. (2002). Model-checking verification for re-
liable web service. In OOPSLA 2002 Workshop on
Object-Oriented Web Services, Seattle, Washington.
Paolucci, M. (2002). Semantic matching of web services
capabilities. In The First International Semantic Web
Conference.
Pathak, J., Koul, N., Caragea, D., and Honavar, V. (2005).
A framework for semantic web service discovery. In
WIDM’05, Germany.
Sensoy, M., Pembe, C., Zirtiloglu, H., Yolum, P., and Bener,
A. (2007). Experience-based service provider selec-
tion in agent-mediated e-comerce. In Engineering Ap-
plications of Artificial Intelligence, number 3, pages
325–335.
Srinivasan, N., Paolucci, M., and Sycara, K. (2004). Adding
owl-s to uddi implementation and throughput. In In
Workshop on Semantic Web Service and Web Process
Composition.
Sycara, K., Paolucci, M., Soudry, J., and Srinivasan, N.
(2004). Dynamic discovery and coordination of agent-
based semantic web services. In IEEE Internet Com-
puting, number Vol.8 - 3, pages 66–73.
van Riemsdijk, M. B. and Wirsing, M. (2007). Goal-
oriented and procedural service orchestration - a for-
mal comparison. In In MALLOW-AWESOME’007.
Walton, C. (2004). Model checking multi-agent web ser-
vices. In Proceedings of the 2004 Spring Symposium
on Semantic Web Services, Stanford, CA, USA.
Wolf-Tilo, B. and Matthias, W. (2003). Towards personal-
ized selection of web services. In The Twelfth Inter-
national WWW Conference en Budapest.
Yang, L., Sarker, B. K., Bhavsar, V. C., and Boley, H.
(2005). A weighted-tree simplicity algorithm for sim-
ilarity matching of partial product descriptions. In In
Proceedings of ISCA 14th International Conference
onIntelligent and Adaptive Systemsand Software En-
gineering, Toronto.
Yu, H. Q. and Reiff-Marganiec, S. (2006). Semantic web
services composition via planning as model checking.
Tech. Report CS-06-003, University of Leicester.
WEBIST 2008 - International Conference on Web Information Systems and Technologies
142
