
IMPROVING CASE RETRIEVAL PERFORMANCE THROUGH THE
USE OF CLUSTERING TECHNIQUES
Paulo Tom´e
Department of Computing, Polytechnic of Viseu, Viseu, Portugal
Ernesto Costa
Department of Computing, University of Coimbra, Coimbra, Portugal
Lu´ıs Amaral
Department of Information Systems, University of Minho, Guimar˜aes, Portugal
Keywords:
Case-Based Reasoning, Clustering Techniques, Case-Base Maintenance.
Abstract:
The performance of Case-Based Reasoning (CBR) systems is highly depend on the performance of the re-
trieval phase. Usually, if the case memory has a large number of cases the system turn to be very slow. Several
mechanisms have been proposed in order to prevent a full search of the case memory during the retrieval
phase. In this work we propose a clustering technique applied to the memory of cases. But this strategy is
applied to an intermediate level of information that defines paths to the cases. Algorithms to the retrieval and
retention phase are also presented.
1 INTRODUCTION
CBR is a method (Watson, 1999) that allows to solve
problems based in previous resolved ones (Kolodner,
1993; Mantaras et al., 2006). Every CBR system
comprises a retrieval phase, a re-using phase and a
retention phase (Aamodt and Plaza, 1994). These
phases have different impacts on the performance
of the CBR. According with Smyth and McKenna
(Smyth and McKenna, 1999), the performance of a
CBR system can be measured according to three cri-
teria:
• Effiency - the average problem solving
time;
• Competence - the range of target problems
that can be successfully solved;
• Quality - the average quality of a proposed
solution.
As mentioned by Smyth and McKenna (Smyth
and McKenna, 1999), the retrieval process deserved
always highest interest of the CBR research commu-
nity because it has an high influence on the CBR sys-
tem performance.
The retrieval process involves the combination of
two procedures: similarity evaluation and searching
in the memory case. The first procedure judges the
similarity of the current problem with the ones previ-
ously resolved. If the case memory have a large num-
ber of cases, the number of similarity evaluations is
large representing a computational burden.
Some authors tried to improve the retrieval phase
performance using case memory structures. The aim
of these structures is to organize the case memory in
way that enable a fast case access avoiding the sim-
ilarity evaluation of all cases in memory. There are
several examples of case memory structures propos-
als, for example, Kolodner (Kolodner, 1993) identi-
fies four ways of organizing the case memory. Fol-
lowing those proposals Schaaf (Schaaf, 1996) orga-
nizes cases in a network by considering cases as a
polyhedron with a face for each aspect. And Wolver-
ton (Wolverton, 1994) organizes the case memory in
a semantic network. Within that semantic network,
small subgraphs of nodes and links which represent
aggregate concepts are explicitly grouped together
as conceptual graphs. More recently Yang and Wu
(Yang and Wu, 2000) split the case into a set of clus-
450
Tomé P., Costa E. and Amaral L. (2008).
IMPROVING CASE RETRIEVAL PERFORMANCE THROUGH THE USE OF CLUSTERING TECHNIQUES.
In Proceedings of the Tenth International Conference on Enterprise Information Systems - AIDSS, pages 450-454
DOI: 10.5220/0001687704500454
Copyright
c
SciTePress
ters distributed by different sites/machines.
Furthermore, the structure of the case mem-
ory are directly related with the case base mainte-
nance (CBM) methods (Wilson and Leake, 2001).
The objective of the CBM is maintaining consis-
tency, preserving competence and controlling case-
base growth.
The previous presented approaches does not ad-
dress the problem of missing case features. This prob-
lem is currently addressed in CBR research field (GU
and Aamodt, 2005; Gu and Aamodt, 2006).
We propose the use of clustering techniques to im-
prove the performance of the CBR during the retrieval
phase. However, we use different approach of Yang
and Wu (Yang and Wu, 2000). We do not split the
case memory into distinct locations instead we use
clusters of links to cases. Besides that, our proposal
also deals with cases with missing features. In Sec-
tion 2 we review some clustering concepts essential
to the understanding of our proposal shown in section
3. In section 3 we present also the results of the ap-
plication of our proposal to a CBR system with 915
cases.
2 THE CLUSTERING
TECHNIQUE
Clustering techniques organizes data into groups that
are meaningful, useful or both (Tan et al., 2006). One
group of data is called a cluster, while the entire col-
lection of clusters is commonly referred to as a clus-
tering.
Two types of clustering can be considered: par-
tional and hierarchical. A clustering is hierarchical if
we permit clusters to have subclusters. In partional
clustering the data is divided into non-overlapping
clusters. Tan et al. (Tan et al., 2006) identified five
types of clusters: well-separated, prototype-based,
graph-based, density based and shared-based. In our
work we will consider prototype-based type. A set of
cases is grouped into a cluster with one representative
element. Then, in the retrieval phase the number of
similarity evaluations is reduced considerably.
There are several techniques to split the data, but
k-means and k-medoid are two of the most prominent
techniques associated to prototype-based techniques
(Tan et al., 2006). K-means defines a prototype in
terms of a centroid, while k-medoid defines defines a
prototype in terms of a medoid. The medoid is one
element of the cluster while the centroid is the mean
of the cluster. In our work we use the k-medoid tech-
nique. So each cluster is represented by the most rep-
resentative case among all cases in the group. There
are also different proposals to measure similarity be-
tween data: the Euclidean and cosine distance are the
most used similarity measures. The similarity mea-
sure is used whenever a new case has to be added to
the case memory. Naturally the updated cluster need
to update its prototype.
3 THE APPLICATION OF
CLUSTERING TECHNIQUES
TO THE CBR RETRIEVAL
PHASE
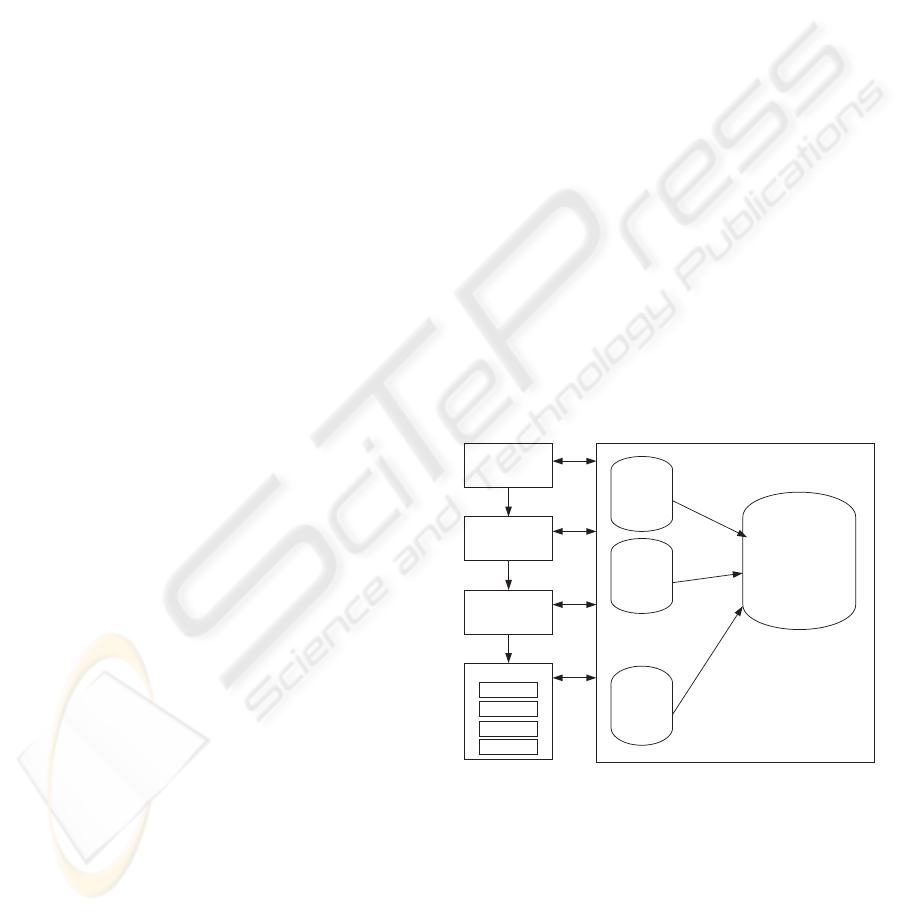
Our proposal, shown in figure 1, has two levels of in-
formation. The first level is formed by a set of links
to the case memory and the second level is the case
memory database. The case links are paths to cases
memory. And the clustering technique is applied to
case links information. The first level of information
requires a low amount of storage space however de-
creases the waiting time of the retrieval process. We
do not considered the division of the database case
memory because it is useful to access a case from
different ways. The figure 1 illustrates the storage
scheme and we can see that groups of clusters are the
interface between CBR process and the database of
cases.
Group of clusters
Case Links
1
Case Memory
Group of clusters
Case Links
2
Group of clusters
Case Links
n
Retrieval Process
Reusing
Revision
Process 1
…
Process 2
Process n
Retention
...
Figure 1: CBR system structure.
Each group has clusters of links to cases. And
each cluster, as shown in table 1, has a reference to
the medoid of the cluster and links to a set of cases
that constitute the cluster.
Each Group of clusters is identified by a binary ar-
ray codification. The binary codification scheme fol-
lows the proposal of Kolodner, table 2, who defines
that a case is formed by a Problem and by a Solu-
tion. And the Problem consists in Objective and a set
IMPROVING CASE RETRIEVAL PERFORMANCE THROUGH THE USE OF CLUSTERING TECHNIQUES
451
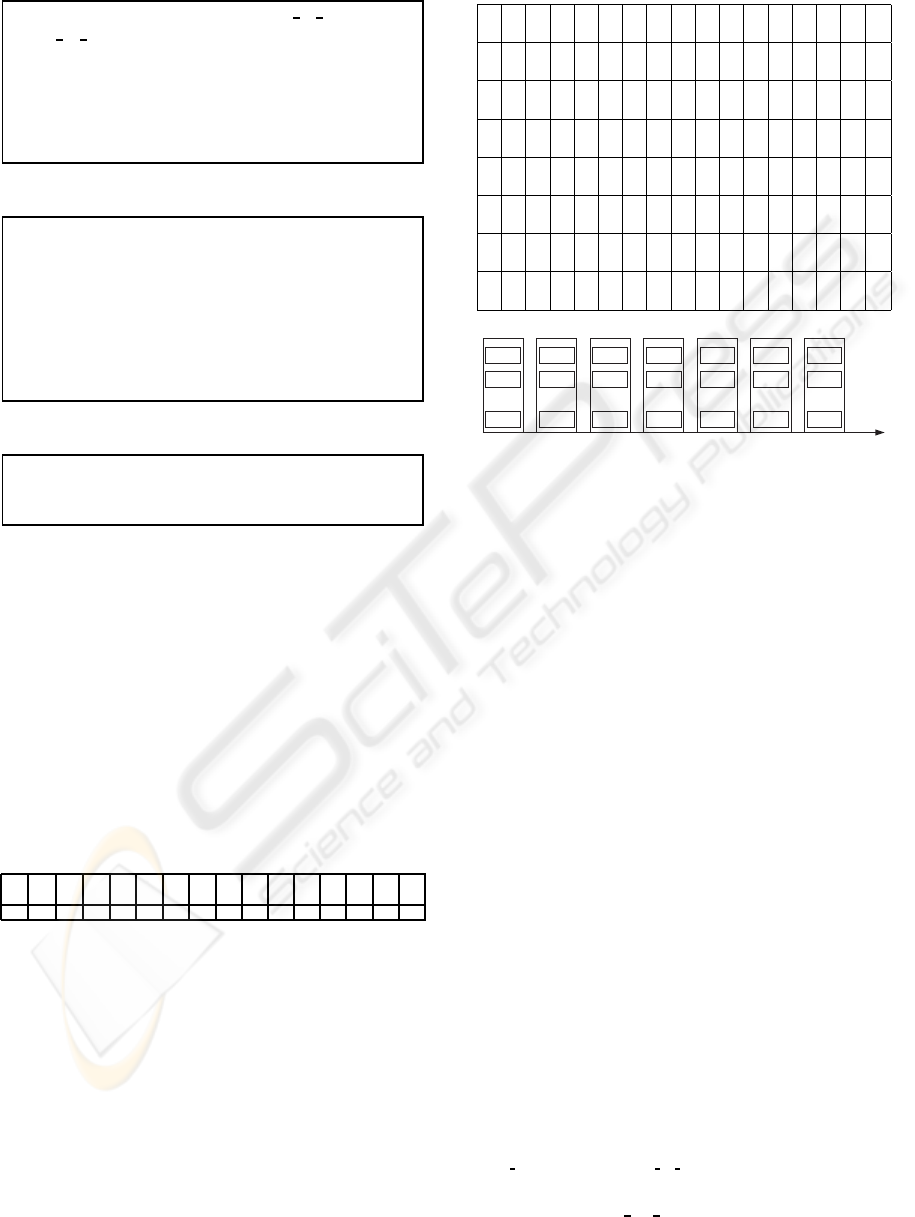
Table 1: Cluster definition.
Clus =< LMed, SCl > Med = link to case SCl =
{link to case}
Where:
Clus - Cluster
LMed - Link to medoid
SCl - Set of Cluster link;
C - Characteristic
Table 2: Case Structure.
Case =< P, S >
P =< O,Cs >
Cs = {C}
Where:
P - Problem
O - Objective
Cs - Set of characteristics;
C - Characteristic
Table 3: Case Example.
Cas
1
=< P, S >
P =< O1,Cs >
Cs =< C
1
,C
2
,C
3
>
of Characteristics. Table 3 shows a case with three
Characteristics. So each position of the binary array
is associated to a particular feature of a case, where
1 (0) indicates the availability (non-availibility) of the
feature.
The first positions on the right side of the array are
used to represent objectives. The remaining positions
are used to represent characteristics. For example, us-
ing sixteen bits with the division illustrated in table 4,
the case Cas
1
, shown in table 2, addresses the group
with the following binary array 0000000001110001.
Table 4: Addressing Group Cluster.
C
12
C
11
C
10
C
9
C
8
C
7
C
6
C
5
C
4
C
3
C
2
C
1
O
4
O
3
O
2
O
1
However to deal with missing characteristics the
cases belong to more than one group. All combination
of the available characteristics and objective define
different groups. In table 5 it is presented the com-
binations of characteristics and objective for the case
Cas
1
. The case Cas
1
is associated to seven groups
(figure 2), in each group clustering might be achieved
with a distinct number of clusters.
The Retrieval process was modified to enable the
adoption of the principles previously described. Table
6 shows the steps of the algorithm when a new prob-
lem is presented: 1)- identification of the clustering
Table 5: Combinations example to Cas
1
case.
C
12
C
11
C
10
C
9
C
8
C
7
C
6
C
5
C
4
C
3
C
2
C
1
O
4
O
3
O
2
O
1
Id
0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 Co
1
0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 Co
2
0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 Co
3
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 Co
4
0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 1 Co
5
0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 Co
6
0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 1 Co
7
Co
1
Cluster
A1
Cluster
A2
Cluster
An
...
Cluster
B1
Cluster
B2
Cluster
Bn
...
Cluster
C1
Cluster
C2
Cluster
Cn
...
Cluster
D1
Cluster
D2
Cluster
Dn
...
Cluster
E1
Cluster
E2
Cluster
En
...
Cluster
F1
Cluster
F2
Cluster
Fn
...
Cluster
G1
Cluster
G2
Cluster
Gn
...
Co
2
Co
3
Co
4
Co
5
Co
6
Co
7
Groups of clusters
Figure 2: Example of a database of group of case links.
group 2)-identification of the cluster within the group
using a similarity measure; 3)- finally the case is com-
pared with all cases in the cluster. In the second step
the Default Difference measure strategy (Bogaerts
and Leake, 2004) is applied only to the medoid of the
clusters. In the third step, different similarity evalua-
tions are used.
The retention process algorithm, shown in table 7,
was also redefined. This process was parallelized, e.g.
the retention in each Group of cluster is implemented
by different program processes. The process begins
with the determination of all possible combinations
between the available characteristics and the objective
of the case. Then for each combination, the case is in-
serted in respective Group of clusters. This insertion
process is parallelized. Each insertion in a Group de-
termines: 1)-evaluation of the similarity with the clus-
ter medoids 2)- identification of the cluster to insert
the case, 3) actualization of the medoid of the cluster
where the case was assigned. The similarity measure
strategy used in step two is also Default Difference.
In a group a new cluster is created whenever a binary
similarity evaluation results in a zero.
The medoid is computed using the use of the ex-
pression
pos med =
nf eatures
∑
i=1
pos(value o f feature(i)) ∗ weight( feature(i)) (1)
where pos(value o f feature(i)) is the posi-
ICEIS 2008 - International Conference on Enterprise Information Systems
452
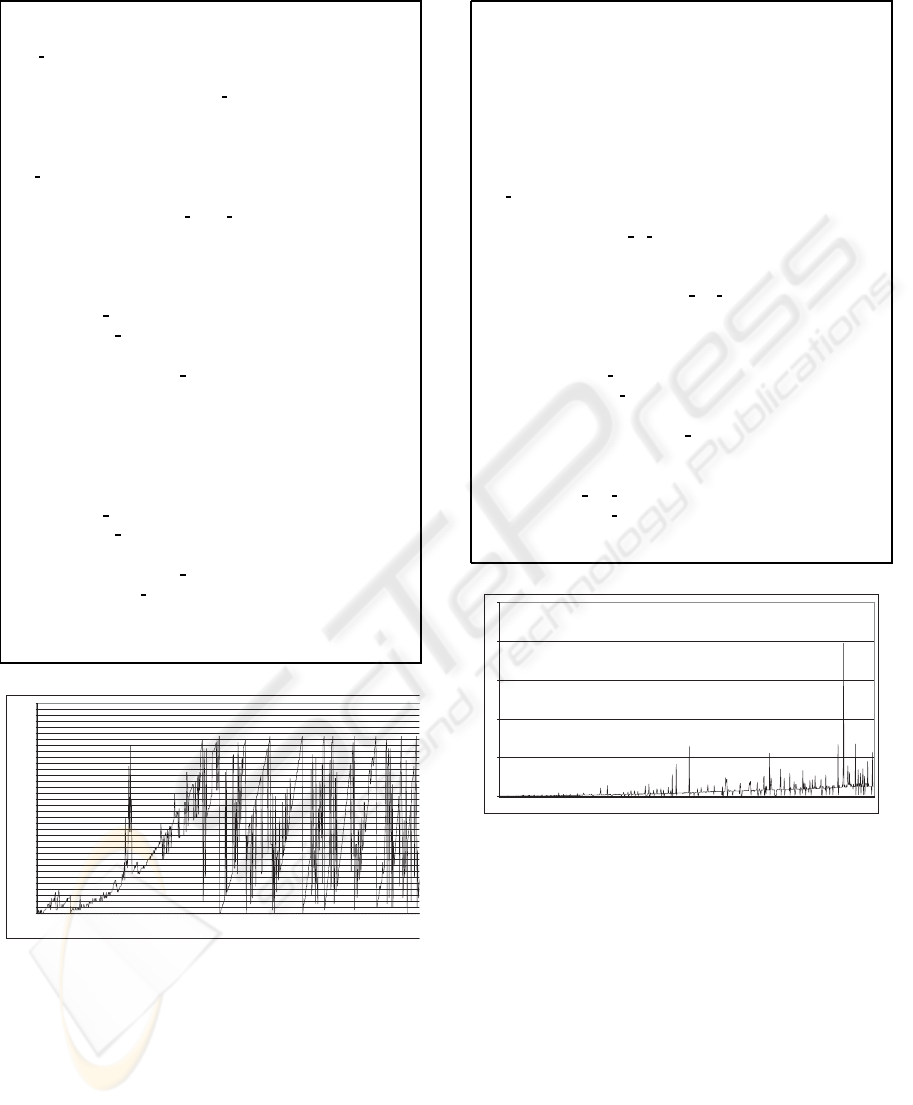
Table 6: Retrieval Algorithm.
/* —————————————————————-
Cas is the case for which it is search a solution
Prop Cas is the proposed case
—————————————————————-*/
procedure retrieval(Cas in Case, Prop cas out Case)
Clusgroup ClusterGroup;
Clus Cluster;
Sim Similarity;
Sim a Similarity;
begin
Clusgroup ← Determine cluster group(Cas.Obj,Cas.Cars);
Clus ← 0;
Sim ← 0;
For each Cluster in Clusgroup do
begin
Sim a ← Similarity(Cas, Cluster(i).medoid);
if Sim a > Sim then
begin
Sim ← Sim a;
Clus ← Cluster(i);
end;
end;
Sim ← 0;
For each Case in Clus do
begin
Sim a ← Similarity(Cas, case(i));
if Sim a > Sim then
begin
Sim ← Sim a;
Prop cas ← Case(i);
end;
end;
end;
0,00
2,00
4,00
6,00
8,00
10,00
12,00
14,00
16,00
18,00
20,00
22,00
24,00
26,00
28,00
30,00
32,00
34,00
36,00
38,00
40,00
42,00
44,00
46,00
48,00
50,00
52,00
54,00
56,00
58,00
60,00
62,00
64,00
66,00
68,00
70,00
1 21 41 61 8 1 10 1 121 141 161 181 201 221 24 1 2 61 281 30 1 3 21 341 36 1 381 401 42 1 441 461 481 5 01 521 54 1 5 61 581 60 1 6 21 641 66 1 6 81 701 72 1 7 41 761 78 1 801 821 841 8 61 881 901
Numbe r of cases
Recall time
Figure 3: Waiting time before clustering technics applica-
tion.
tion of feature in a ordered set of values and
weight( feature(i)) is the weight of the f eature(i).
We compare the described strategy with a flat
memory case for a CBR system with 915 cases. As
we can see in figure 3, the system had bad perfor-
mance after the insertion of three hundred cases in the
case memory.
After the application of the clustering approach
Table 7: Retention Algorithm.
/* ———————————————-
Cas is the case that will be retained
———————————————–*/
procedure retention(Cas in Case)
Combs Combinations;
Combination TCombination;
Clusgroup ClusterGroup;
Clus Cluster;
Sim Similarity;
Sim a Similarity;
begin
Combs ← Generate all combinations(Cas.Obj,Cas.Cars);
For each Combination in Combs do
begin
Clusgroup ← Determine clus group(Combination(i));
Sim ← 0;
For each Cluster in Clusgroup do
begin
Sim a ← Similarity(Cas, Cluster(j).medoid);
if Sim a > Sim then
begin
Sim ← Sim a;
Clus ← Clus(i);
end;
insert case cluster(Clus,Cas);
recalculate medoid(Cluster(i));
end;
end;
0
5
10
15
20
25
1 26 51 76 101 126 151 176 201 226 251 276 301 326 351 376 401 426 451 476 501 526 551 576 601 626 651 676 701 726 751 776 801 826 851 876 901
Figure 4: Waiting time after clustering technics application.
the waiting time for each of the 915 cases was less
than 1 second. Although, the retention process takes
more time than the flat memory case. The figure 4
shows the retention waiting time for all of the 915
cases. Although, the total waiting time is smaller after
the application of the clustering techniques as shown
in figure 4.
4 CONCLUSIONS
This paper presents an approach that can be used to
improve the performance of CBR system Retrieval
phase. The approach uses clustering techniques to
IMPROVING CASE RETRIEVAL PERFORMANCE THROUGH THE USE OF CLUSTERING TECHNIQUES
453

structure the case memory. The use of clustering tech-
niques define a particular case memory structure and
consequently algorithms for the retrieval and reten-
tion phase are proposed.
The approach was tested in a CBR system with
915 cases. The result show that the overall system
performance is improved. It is important to notice that
the retrieval waiting time was considerably reduced
and the total waiting time (time of retrieval and reten-
tion) is also substantially smaller than with a flat case
memory organization.
REFERENCES
Aamodt, A. and Plaza, E. (1994). Case-based reasoning:
Foundational issues, methodological variations and
systems approaches. AI-Communications, 7(1):39–
52.
Bogaerts, S. and Leake, D. (2004). Facilitating cbr for
incompletely-described cases: Distance metrics for
partial problem descriptions. In ECCBR 2004, pages
62–74.
GU, M. and Aamodt, A. (2005). A knowledge-intensive
method for conversational cbr. In 6th International
Conference on Case-Based Reasoning, pages 296–
311. Springer-Verlag.
Gu, M. and Aamodt, A. (2006). Dialog learning in con-
versational cbr. In 19th International FLAIRS Confer-
ence, pages 358–363, Florida, EUA. AAAI Press.
Kolodner, J. (1993). Case-Based Reasoning. Morgan Kauf-
mann Publishers.
Mantaras, R. L., Mcsherry, D., Bridge, D., Leake, D.,
Smyth, B., Craw, S., Faltings, B., Maher, M. L., Cox,
M. T., Forbus, K., Keane, M., Aamodt, A., and Wat-
son, I. (2006). Retrieval, reuse, revison and retention
in case-based reasoning. The Knowledge Engineering
Review, 20(3):215–240.
Schaaf, J. W. (1996). Fish and shrink. a next step towards
efficient case retrieval in large scale case bases. In
Smith, I. and Faltings, B., editors, Advances in Case-
Based Reasoning, pages 362–376. Springer-Verlag.
Smyth, B. and McKenna, E. (1999). Footprint-based re-
trieval. In Third International Conference on Case-
Based Reasoning, pages 343–357, Munich, Germany.
Springer Verlag.
Tan, P. N., Steinbach, M., and Kumar, V. (2006). Introduc-
tion to Data Mining. Pearson Education.
Watson, I. (1999). CBR is a methodology not a technology.
Knowledge Based Systems Journal, 12(5-6).
Wilson, D. C. and Leake, D. (2001). Maintaining case-
based reasoners: Dimensions and directions. Com-
putational Intelligence, 17(2):196–213.
Wolverton, M. (1994). Retrieving Semantically Distant
Analogies. Ph.d thesis, Stanford University.
Yang, Q. and Wu, J. (2000). Keep it simple: A case-base
maintenance policy based on clustering and informa-
tion theory. In Canadian AI 2000, pages 102–114.
Springer-Verlag.
ICEIS 2008 - International Conference on Enterprise Information Systems
454
