
AN INTERACTIVE INFORMATION SEEKING INTERFACE
FOR EXPLORATORY SEARCH
Hogun Park, Sung Hyon Myaeng, Gwan Jang, Jong-wook Choi, Sooran Jo and Hyung-chul Roh
Information & Communications University (ICU), Daejeon, Korea
Keywords: Information seeking interface, Exploratory search, Human-Web interaction.
Abstract: As the Web has become a commodity, it is used for a variety of purposes and tasks that may require a great
deal of cognitive efforts. However, most search engines developed for the Web provide users with only
searching and browsing capabilities, leaving all the burdens of manipulating information objects to the
users. In this paper, we focus on an exploratory search task and propose a framework for human-Web
interactions. Based on the framework, we designed and implemented a new information seeking interface
that helps users reduce cognitive burdens. The new human-Web interface provides a personal workspace
that can be created and manipulated cooperatively with the system, which helps users conceptualize their
information seeking tasks and record their trails for future uses. This interaction tool has been tested for its
efficacy as an aid for an exploratory search.
1 INTRODUCTION
For a traditional Web search engine, the process of
querying and viewing the search result is usually
regarded as a single isolated session that ends in
itself. As the Web has become a commodity,
however, it is used for a variety of tasks in many
different ways, encouraging new paradigms in
information seeking (e.g. berrypicking (Bates,
1989), information foraging (Pirolli and Card 1995),
and sense-making (Russel et al., 1993)). However,
most popular commercial search engines have taken
a conservative position and adhered to the traditional
model, leaving all the rest of the information seeking
and related tasks to users. More specifically, a user
would have all the burdens of manipulating the
information objects that have come to his attention
in a series of search activities.
An area in which this type of cognitive burden
affects significantly is exploratory search. An
exploratory search task (Marchionini, 2006; White
and Drucker, 2007) is to investigate on the
background information of a topic or gather
information sufficient to make an informed decision.
For example, assume that a user is considering
purchasing a DMB (digital multimedia broadcasting)
receiver. The user would want to learn more about
the DMB technology and the manufacturers of
various products related to it, so that he can select
the vendor and the product that best suit the needs.
We argue that most existing search engines and their
interfaces are not satisfactory for exploratory search
tasks because of the following.
1. Cognitive burdens: Compared to the task of
searching for a specific or known item, an
exploratory search task usually requires users to
send a series of queries during a search session,
visit new domains, and revisit previously visited
sites (especially branch pages) (White and
Drucker, 2007). These activities together mean a
significant amount of information and workload
to be handled by the user, which traditional
search engines have rarely attempted to reduce.
The workload is associated with representing
information needs (Taylor, 1968), determining
informativeness (Teevan et al., 2004), and
memorizing previously explored information
(Cockburn, 2001). Without explicit support from
a search engine, the difficulties resulting from
the workload are left as a cognitive burden to the
user.
2. Narrow interaction channel for incorporating
user interests: In an exploratory search, a user
needs to build up background information on a
topic gradually until she feels that a sufficient
amount of information has been gathered for the
given task. As such, it is important to remember
which information items have drawn the user’s
276
Park H., Hyon Myaeng S., Jang G., Choi J., Jo S. and Roh H. (2008).
AN INTERACTIVE INFORMATION SEEKING INTERFACE FOR EXPLORATORY SEARCH.
In Proceedings of the Tenth International Conference on Enterprise Information Systems - HCI, pages 276-285
DOI: 10.5220/0001711302760285
Copyright
c
SciTePress
attention as the system processes the current
query. However, current search systems rarely
support the notion of “session” and interactions
explicitly. While the one-time query/result model
is simple and natural with HTTP, it ignores what
has been done by the user in an attempt to
change her anomalous state of knowledge
(Belkin, 1980). Although there have been some
attempts to infer user interests explicitly (George
et al., 2002; Martin and Jose, 2004; Harper and
Kelly, 2006), implicitly (Shen et al., 2005), or
both (Zigoris and Zhang, 2006), the problem
remains challenging, especially within the
context of user-system interactions.
Given the limitations of traditional search
engines for an open-ended, exploratory search task,
we propose a new interaction tool that can provide
an interface between a user and a search engine,
called sketchBrain. Our aim is to provide an
effective interaction environment that facilitates the
series of activities in an exploratory search of the
Web.
There are several noble features in this
interaction environment. First of all, sketchBrain
keeps track of query trails and post-query navigation
trails (based on the click streams following the
issued queries) and allows the users to conceptualize
them. For an information seeking activity, a trail is
sketched on the user’s workspace of sketchBrain.
Over the trail, the user can associate user-defined
topics and system-provided semantic associations
between topics using the annotation facility in
sketchBrain. These annotations together with the
information items and queries are key objects in the
underlying model. In essence, the workspace serves
as a rich memory for the past and current search
efforts, which can be accessed later.
Second, our interaction tool is equipped with
operations on the objects created and manipulated in
the workspace. In addition to the annotation facility,
sketchBrain allows users to manipulate the objects
for their information seeking tasks. Implicit
operations such as project, select, and classification
(to be described in Section 3.1) can be utilized for
the activities necessary for an exploratory search.
Third, sketchBrain has an intelligent path
recommendation algorithm that can help users
choose the most promising page to be explored at
the next step in navigation. It assists users in quickly
determining informativeness of the pages that can be
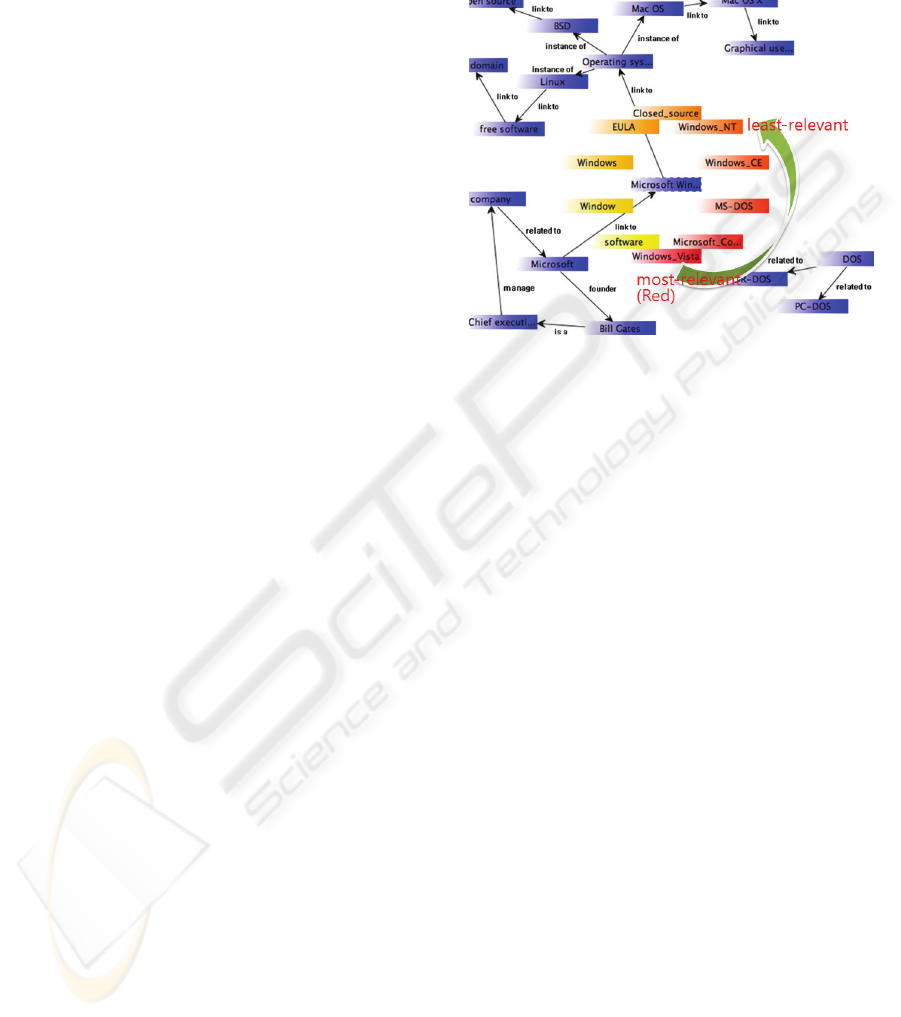
explored at the next step. Fig. 1 shows all the
suggested pages whose colours are on the spectrum
between yellow and red. The user is currently
visiting the page regarding “Microsoft Windows,”
the blue node, and about to choose one from the
available paths surrounding the node representing
the current visit. The degree of relevance is
determined by the algorithm and is shown in various
colours (red indicates the most relevant one).
Figure 1: An example screen shot of sketchBrain.
This new interactive tool, sketchBrain, is based
on an underlying interaction model, called two-level
model. It is based on the recognition that two spaces
are involved in human-Web interactions:
information space and knowledge space. The
information space is essentially the Web itself,
containing the information objects (e.g. Web pages),
whereas the knowledge space is superimposed on
the information space to contain a user’s conceptual
understanding of information objects and their
relations. Concepts in the user’s mind, emerged by
reading Web pages at the information level, are
expressed as topics and their associations (or
relationships) in the knowledge space. Topics are
also connected to information objects (called
occurrences) on the information space, which can be
seen as a manifestation of the topics. For
convenience, an occurrence can be of any
granularity, such as a page, a figure, or a phrase. The
connection between a topic and an occurrence
provides a way to establish a link between the two
spaces.
The three terms, topics, associations, and
occurrences, are borrowed from the Topic Maps
framework (ISO/IEC 13250). In our information
seeking interface, implicit knowledge-level
operations usually performed in user’s mind can be
explicated and automated to help reducing user’s
cognitive burdens. In essence, interactions between
the user and the system enabled by the two-level
model occur at the knowledge level and across the
two levels, in addition to the searching and browsing
AN INTERACTIVE INFORMATION SEEKING INTERFACE FOR EXPLORATORY SEARCH
277

operations of traditional search engines that occur at
the information level.
In sketchBrain, our path recommendation
algorithm supports a guided navigation for a
successful completion of a certain information
seeking task. Previous approaches to guided
navigation (Joachims et al., 1997; Olston and Chi,
2003) keep track of and utilize previous users’
browsing behaviours and queries. Although they
propose good ways to suggest paths that match the
inferred task on a specific point, they have utilized
relatively noisy information such as all previous
queries and pages visited. Our approach for
supporting guided navigation utilizes both explicit
and implicit feedback from the workspace in
sketchBrain. All the supports are geared toward
exploratory search tasks.
The remainder of this paper describes some
related work (Section 2), the interaction framework
for supporting an exploratory search task (Section 3),
and empirical evaluations (Section 4)
2 RELATED WORK
Various information seeking interfaces have been
proposed to support complex information seeking
activities. Sketchtrieve (Hendry and Harper, 1997)
employs Cognitive Dimension Framework to map
out the design space and provides an unstructured
canvas. In this canvas, searchers can freely represent
queries and corresponding search results with an
intuitive interface by using typographic and layout
cues that lie outside of a formal notation. George et
al. (2002) introduces information seeking workspace
called Garnet. They exploit implicit knowledge that
can be discovered from the contents in the
workspace and try to find direct connections
between the workspace and digital libraries. They
utilize spatial parsing to extract profiles of
documents and use them to learn a lexical classifier.
This classifier is to identify newly searched
documents that are relevant to each parsed cluster.
Martin and Jose (2004) suggest a personal
information retrieval tool that employs a folder-like
structure, so that searchers can bundle search results
into folders. In addition to the interface that
searchers can freely organize results, it assists query
formulation and recommends hot relevant
documents to each folder. Harper and Kelly (2006)
employ a topical structure for relevance feedback.
Their interface allows users to save documents in
user-defined piles for similar documents, which
could be used for relevance feedback. These
approaches suggest new information seeking
environments with some assistance. However, their
design goals are not to support exploratory search
explicitly, and the systems were not tested as such.
Our interface provides users with a cooperative
workspace and a proactive assistance, explicitly
aiming at exploratory searching tasks.
3 INTERACTION FRAMEWORK
We have designed an interaction framework for
sketchBrain and implemented a prototype system
that includes a search engine and the interaction tool,
capturing the key ideas of the two-level model
described below. sketchBrain is implemented with
an open source graphics library
(http://www.jgraph.com/) in Java, which we
extended for our purposes.
Figure 2: sketchBrain interaction framework.
As in Fig. 2, the framework connects users with
the Web through Interaction Mediation. On the
user’s side is a virtual workspace, and the Web side
is assumed to have a conventional search engine and
browsing facilities. When the user
searches/navigates the Web and attempts to make
informed decisions based on the information found,
Interaction Mediation provides a support with the
goal of relieving his cognitive burden in the
information seeking process. It consists of various
tools that facilitate users’ information seeking
activities in terms of searching and browsing and
work space creation/manipulation. Inter-space
Manager associates trails and user’s reification of
them with raw information in the Web and provides
facilities to manipulate them. A detailed description
of the components for Interaction Mediation is given
in Section 3.2.2.
3.1 The Underlying Model
Our interaction tool and user interface are based on
our two-level model that explicates information and
knowledge spaces where user information seeking
activities take place. Fig. 3 depicts a conceptual
ICEIS 2008 - International Conference on Enterprise Information Systems
278
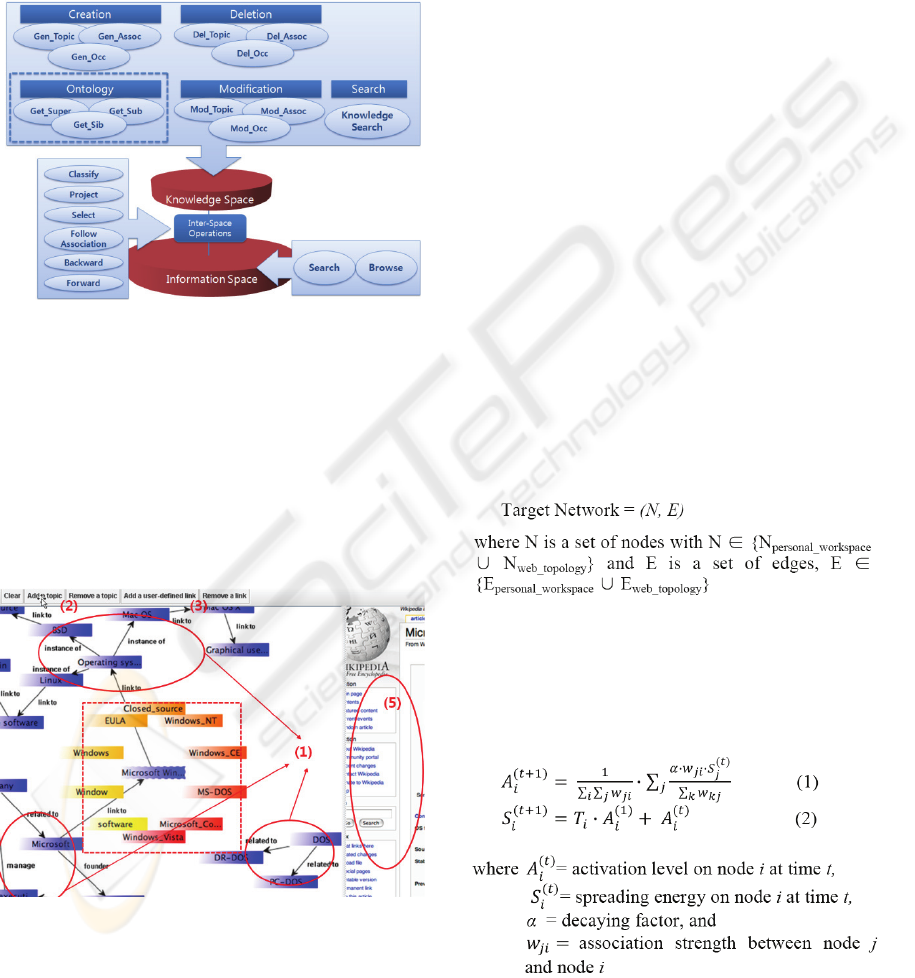
view of the underlying model and the relationship
between the information and knowledge spaces and
the operations. We attempt to split users’ conceptual
work space into two levels and define operations on
each space and inter-space operations (see Park et al.
(2007) for details). The set of operations in Fig. 3 is
by no means complete, and we intend to expand it as
additional needs arise.
Figure 3: A conceptual view of the two-level model.
3.2 Interaction Framework
Components
3.2.1 Personal Workspace
A screenshot for the user interface of sketchBrain is
shown in Fig. 4. On the left is the user workspace
where three workflows are sketched as indicated by
(1).
Figure 4: A snapshot of the sketchBrain user interface.
Using this tool, a sequence of queries and search
results and their relationships can be recorded as
much as the user wishes to remember for future use.
In effect, the network of topics and associations
expresses her own conceptual understanding of the
search results (e.g. creating a user-defined topic
using (2) or associating topic nodes using a semantic
association using (3)). In other words, our interactive
workspace keeps track of previous interactions such
as queries, browsed pages, and their relations to help
users create own knowledge space. Using this
knowledge space, the system can show what the user
previously has seen and accessed and the reasons
why she approached to them. In addition to this
feature, our system can provide the relevant context
of a specific page (like the one pointed by (5))
through time-variant multiple spreading activations,
which can be used as a guidance for further
navigation. The degree of relevance is determined
by the algorithm and is shown in various colours
(red indicates the most relevant one).
3.2.2 Interaction Mediation
Path Recommendation (Time-variant Multiple
Spreading Action). Spreading Activation is a well-
known information access technique in associative
networks. In this paper, we utilize Time-variant
Multiple Spreading Activation (TMSA) to
recommend the best relevant path from a certain
page. In order to analyze the current interest of an
exploratory searcher, our algorithm introduces a new
constraint and procedure.
Let us define
A target of TMSA is an integration of Web
topology and personal workspace. Because our
workspace refers to Web pages, the result from the
integration can be regarded as a single network.
Given the network, we define the iterative activation
procedure as follows:
In our network, each node i has an activation
level A
i
(t)
and a spreading energy S
i
(t)
at time t. Each
activation level computed as in Equation (1) is
AN INTERACTIVE INFORMATION SEEKING INTERFACE FOR EXPLORATORY SEARCH
279
determined by the spreading energy of adjacent
nodes. When adjacent spreading energy is summed,
the association strength between node j and node i,
w
ji
, is multiplied. This specifies how much adjacent
spreading energy influences node i. The amount of
spreading energy is determined by Equation (2)
where A
i
(1)
represents the initial activation level on
node i, and has a value when the user previously has
interacted with the node. In other words, it has a
value when it is from the personal workspace. T
i
is a
time decaying function and relieves its effects from
the time when it first interacted. Other constraints
will be described in the experimental settings (See
sections 4.1.1.)
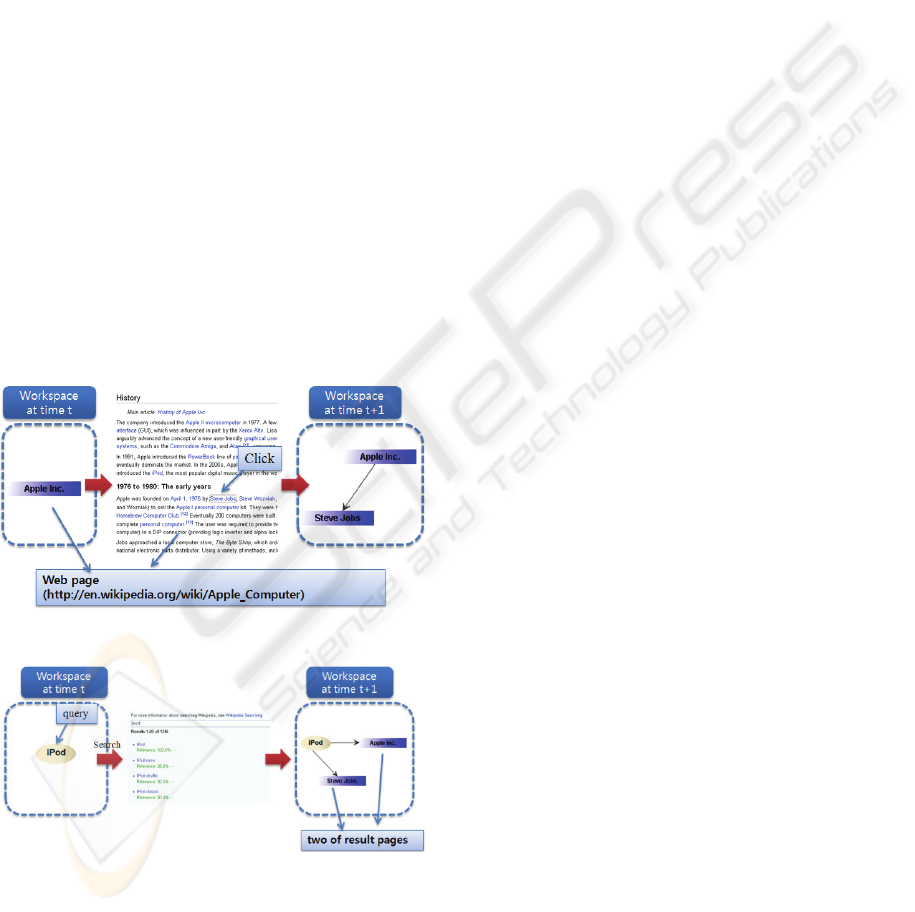
Search & Navigation Trails. Some past
applications (e.g. Google Notebook, Yahoo Myweb,
and Pathway) attempted to keep track of search or
navigation trails and showed their usefulness.
sketchBrain also keeps track of query trails and
post-query navigation trails, which are based on
click streams following issued queries. As in figures
5 and 6, search queries and post-navigations are
sketched in the workspace of sketchBrain. Using the
JDIC (JDesktop Integration Components) library,
sketchBrain gets action events and shows them in
our workspace.
Figure 5: A snapshot of the navigation trails.
Figure 6: A snapshot of the query trails.
Other Components. In the current implementation,
there are four components that are not as fully
developed as the other four introduced already. They
are Topic Extractor, Association Agent, Session
Identification, Interspace Manager. (1) Topic
Extractor creates a topic from an information object
when the user wants to record the information object
as an occurrence for a future use. (2) Association
Agent automatically generates and suggests an
association between two topics the user is interested
in. (3) Session Identification is to automatically
discover different session boundaries (4) Inter-space
Manager is responsible for the operations whose
domains and ranges are across the two spaces.
Although more complete development of these
components would provide added functionality and
make the interface more amenable for an exploratory
search, the lack of the full functionality does not
invalidate the main goal of reducing cognitive
burden in an exploratory search task through
Interaction Mediation, as proved by the experiments
in Section 4. It simply means that users need to do
some work manually or semi-automatically.
4 EXPERIMENTS
We tested our approach in three different ways. In
Subsection 4.1, we report our evaluation of the
guided navigation method as a component of the
interaction tool. The next subsection describes our
experiment on whether the proposed tool helps
reducing users’ workload (i.e. cognitive burdens) in
exploratory search tasks, the primary motivation for
devising the proposed method. In Subsection 6.3, we
show how the proposed tool helps users in
performing tasks that require organizing and
remembering the results from searching and
browsing. The second experiment in 4.2 was based
on users’ subjective opinions whereas the third one
in 4.3 attempts to use objective measures.
Wikipedia was selected as a test environment for
the second experiment where exploratory searching
was the main task. We chose Wikipedia instead of
the entire Web because it provided us with a
somewhat controlled environment for topic and
association generations. It contains a reasonably
large number of encyclopedia articles and covers a
very wide range of subject areas, providing a
suitable environment where exploratory searches can
take place.
4.1 Guided Navigation
This experiment was to find out whether our
automatic guided navigation method would help
users’ information seeking tasks in general. It was
targeted at our guided navigation’s utility in terms of
effectiveness by measuring recommendation
ICEIS 2008 - International Conference on Enterprise Information Systems
280

relevance. The participants manually evaluated
relevance of paths ranked among the top 10.
4.1.1 Constraints
For reasonable performance, we set constraints of
TMSA to best suit the characteristics of Wikipedia.
We defined the association strength,
w
ji
as:
These three constraints are dependent on the
characteristics of the network. The detailed
descriptions for the constraints are given below.
Fan-out Constraint. Nodes with a large branching
factor, which are connected to many others, may be
bypassed or have a penalty in the activation process.
Since Wikipedia we used as the testing environment
has the properties of a scale-free network, the nodes
follow power-law degree distribution, p(k)~k
-
γ
like
other scale-free networks. We employ this
distribution as a fan-out constraint.
Path Constraint. There may exist several different
kinds of links in a network that spread activations.
This constraint discriminates preferred paths from
others. In a semantic network, it gives preference to
meaningful links. In our algorithm, user-defined
paths are deemed more important.
User Participation Constraint. An online social
network like Wikipedia collectively facilitates the
spread of ideas. As a result, it is critical to record
how the network has evolved over time and which
users have participated in the spread of ideas. As a
way to be sensitive to this nature of Wikipedia and
take advantage of it for our tool, we decided to
utilize user participation as a constraint to be
considered for spreading activation, with two
variables, ‘fad’ and ‘stickiness’. Fad refers to a
fashion that become popular in a culture relatively
quickly but loses popularity dramatically.
where
The value for the user-participation constraint on
node i,
ε
i
, is computed by summation of cosine
similarity values between recently visited articles’
vector v
j
and itself.
Each vector v has two dimensions with the two
components, stickiness and fad.
4.1.2 Experimental Design and Result
We asked participants to evaluate how helpful it was
to use our tool based on Time-variant Multiple
Spreading Activation (TMSA). The participants
were divided into three groups: the first with our
time-variant spreading activation algorithm, the
second with a method based on TF-IDF using the
latest query, and the third with random
recommendations. The participants formulated their
own search queries and got engaged in browsing.
Their tasks were to find relevant homepages given a
broad question. The task is similar to Topic
Distillation Task in TREC 2003 Web track. We
allocated the need underlying the question like
“Korean IT industry” to the participants who had to
find a list of related homepages, not any pages about
the questions, which provide credible information on
the query topic.
In the course of finding relevant homepages, the
participants often had to get engaged in navigation,
at which time the system made recommendations.
The participants were asked to evaluate the
recommended paths within top 10 for their
relevance. The average number of links (including
internal links, external links, redirects, and binaries)
in articles that participants had visited was 38.9.
Each of the five participants performed six tasks,
and the total number of browsing actions was 112.
Table 1 shows the results that compares three
different methods.
Table 1: The Result of the first experiment.
TMSA TF/IDF Random
Accuracy for
Relevance
72.78% 57 % 33.4%
AN INTERACTIVE INFORMATION SEEKING INTERFACE FOR EXPLORATORY SEARCH
281

It clearly shows that our method based on TMSA
outperformed the other two methods. Moreover, the
absolute value for accuracy is very promising.
4.2 Reducing Workload
Our second interest was to find out whether the
system based on the two-level model would help
reducing workload of users. Given the motivations
of our work, workload is a reasonable measurement
to test the tool’s efficacy because it measures how
much effort is required to complete an exploratory
search task. In this experiment, we used a special
instrument, subjective workload assessment
technique (SWAT) (Reid and Nygren, 1988). This
method has been utilized for evaluating three
criteria: time, mental effort, and stress.
We asked the participants to perform a total of
10 exploratory search tasks in the Wikipedia
environment where the articles contributed by
experts around the world were judged to be
sufficient for learning background and detailed
information for exploratory search tasks. In this
experiment, we utilized a simple English Wikipedia
(http://simple.wikipedia.org/wiki/Wikipedia:Simple
_English_Wikipedia), and evaluated the efficacy of
our information seeking interface as an aid to
exploratory searches. Each task has one topic
selected from the topics of 10 different Wikipedia
categories. This topic classification scheme uses
nine shared categories for all Wikipedia articles
(http://en.wikipedia.org/wiki/Wikipedia:Requested_
articles#Other_classification_schemes.) During the
experiments, each participant performed semantic
annotation (Jijkoun and de Rijke, 2006) (e.g. “listing
of important people” and “specifying categories of at
least five important entities”), and summarizing the
content of Wikipedia articles (e.g. answering non-
factoid questions such as “writing a state of the art”
and “writing important background information”).
For a more realistic exploratory search environment,
in semantic annotation, we provided blank forms
that they had to fill out. To minimize potential biases
like learning effects, the participants applied two
methods, with and without the interface, in an
alternating fashion.
Table 2: The result of SWAT.
with interface
(Average SD)
without interface
(Average SD)
Time 1.6 (0.55) 1.8 (0.45)
Mental effort
1.2 (0.45) 2.4 (0.55)
Stress 1.8 (0.45) 2.2 (0.45)
Total 4.6 (0.89) 6.4 (0.89)
The participants’ rates of SWAT range between
1 (the best) and 3, and the result of workload
analysis are presented in Table 2. Our interface
received a mean score of 4.6, which is a significant
improvement over the case without the interface. In
particular, the difference was the greatest for mental
efforts as intended and expected for the interface.
These observations showed that our new information
seeking interface helped reducing workload in three
different ways in the exploratory search tasks.
4.3 Information Reuse
Since our two-level model and its manifestation as a
tool were devised to help users reducing cognitive
efforts in information seeking processes, typically
consisting of searching and browsing activities, we
decided to focus on information reuse activities in
information seeking. In the Web environment, users
often have to skim through an overwhelming amount
of information, suffering from information overload,
before their goals are achieved. Our experiment is an
exploratory study designed to investigate whether
our tool helps users in organizing, remembering, and
reusing the information that has been encountered.
Our tool was compared against two other systems
designed for the same purpose: the Favorites tool in
the Web browsers and the Stuff I’ve Seen (SIS)
system (Dumais et al., 2003). The Favorites tool (or
book mark tool) was found to be useful for PVR
(Post-valued Recall) (Wen, 2003) and SIS was
developed to search the information that has been
seen in the past.
4.3.1 Experimental Design
The three methods, the Favorites tool, SIS, and our
knowledge space tool, were compared in six
different tasks by ten groups of users, each
consisting of three undergraduate students. In total,
30 users were employed for six different tasks using
three different methods. Each task consists of five
questions and the six tasks are in six different
domains like Medicine and Sports. The tasks were
designed as follows. For a task, the participants
(users) were first asked to read 30 pre-selected Web
pages. One minute per page was given to simulate
an information skimming situation. The participants
were then asked to organize the pages using the
given tool within one minute. After the preparation
stage, they were given three information hunting
questions elicited from the 30 pages they read, such
as “Name the two new members to the Board of
Directors of Good Samaritan Hospital in New
York.” The participants were timed for completion
ICEIS 2008 - International Conference on Enterprise Information Systems
282
of each question answering. Since the maximum
time given to each question was five minutes, the
time taken for an unsolved question was assumed to
be solved in five minutes, the maximum. In order to
minimize user dependency and learning effects, the
users were assigned to six tasks using three different
methods in an alternating fashion (see Fig. 7). Each
user evaluated each method twice for different tasks,
and each task was given to the three users in an
effort to minimize user dependency. Three users
used the three methods in different sequences for
different tasks so that there is little learning effect on
average.
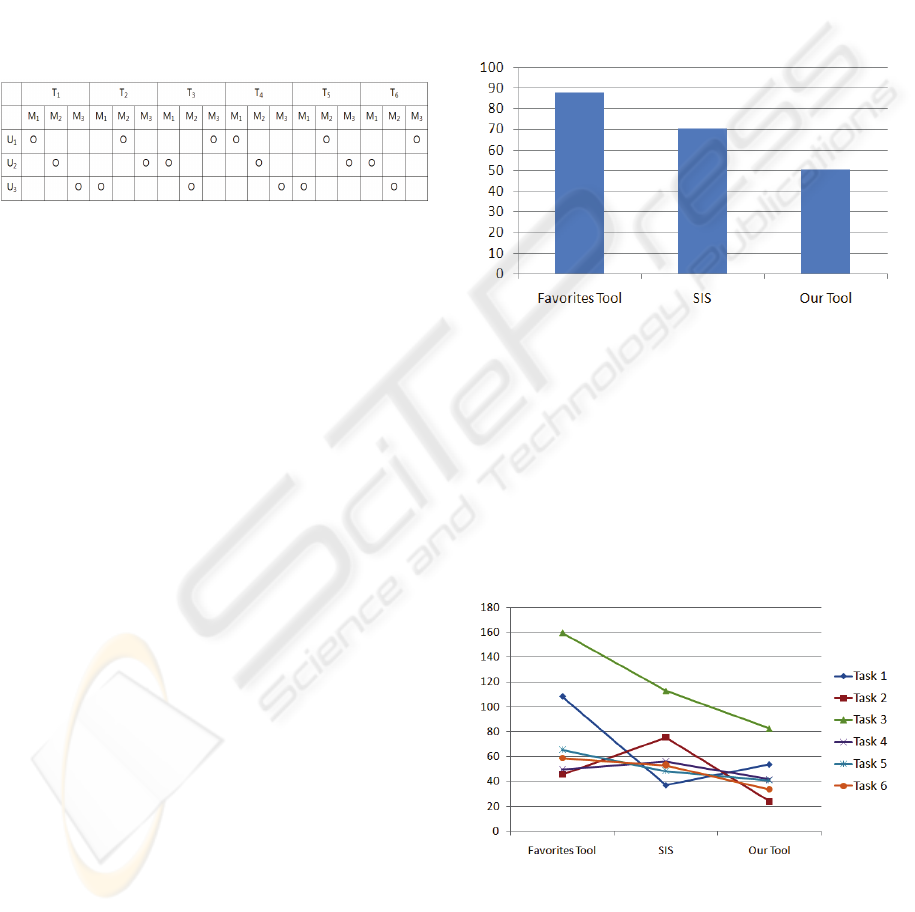
T: Task, M: Method, U: User
Figure 7: Experimental design for each group.
To ensure that every participant has some
familiarity with the three tools, we gave them a
tutorial with 10 minutes of practice sessions in the
same place with all the participants together.
Following is a brief description of the other two
methods compared against our knowledge space
tool.
The Favorites tool is often used to save visited
pages for future references. A user can create folders
and put a page to be remembered into a folder.
Folders are like topics in our tool and can be
organized in a hierarchy. Most browsers are
equipped with this tool.
SIS was developed to facilitate information reuse
for various information resources. It provides the
capabilities of fast unified indexing of various files
in a desktop and of filtering files based on queries,
file types, and time. It is now available on the
Windows desktop.
4.3.2 Result and Analysis
The time measures collected for individual users for
all the tasks were averaged to see the difference
among the three methods. Since there were ten
groups, each consisting of three participants, and six
tasks performed with each tool, a total of 180 data
was averaged for each tool. Each data point is for a
task consisting of three questions solved by a
participant using one of the tools.
The comparison result is shown in Fig. 8. It took
about 50 seconds on average to solve the problems
using our tool, but 88 (about 76% longer) and 70
seconds (about 40% longer) using the Favorites tool
and SIS, respectively. Using SIS that has the
extended search functions only, participants often
produced no answer within the time limit because
the pages were not pre-organized in their own ways.
Although SIS didn’t require any extra user efforts to
organize the pages, the time spent on the
organization was only one minute, once for all the
tasks. If the initial investment for our tool had been
spread across all the questions, the extra time spent
would have been very small.
Unit: seconds
Figure 8: Comparison for task completion time.
The comparison data for different tasks in Fig. 9
are even more encouraging in that our tool
outperforms the Favorites tool for all the tasks and
SIS for all but one case (task 1). Task 1 was easy for
SIS because a search query with a proper noun can
easily retrieve the relevant page but not so easy for
our tool because the proper nouns were not used as
topics.
Figure 9: Comparison by different tasks.
Our further analysis of the experimental results
revealed relative advantages and disadvantages of
the three methods for the given tasks. The Favorites
tool is easy and efficient to use in organizing pages
AN INTERACTIVE INFORMATION SEEKING INTERFACE FOR EXPLORATORY SEARCH
283

in a hierarchical way, but makes it rather difficult to
look for specific information. In a shallow hierarchy,
the granularity level is usually too high to pinpoint a
folder that may contain the information. When it is
deep or skewed with a deep branch, it would be
time-consuming to repeatedly go down the hierarchy
to locate a folder that may contain the information.
Besides it is impossible to express a semantic
relationship between two pages.
In the case of SIS, an advantage is that users do
not have to take an extra step for constructing a
knowledge space and yet find information using
various contextual cues. However, it suffers from all
the problems associated with query-based search
engines, such as inability to formulate a meaningful
query or recall contextual cues. It still has to rely on
searching information space without personalized
knowledge space.
Our tool based on the two-level model has the
best of the both worlds. With the knowledge level
operations, the information that has been
encountered in the past is semantically organized in
a personal conceptual space. The “Sequence Guide”
feature allows users to easily go back to a past query
session and the corresponding topic map in the
knowledge space to provide a simplified view.
Although the time required for the construction of a
knowledge space in the experiment was artificially
limited to one minute, it was entirely possible for
users to feel that the additional efforts necessary for
knowledge space construction was an added burden.
In order to see statistical significance of the
results, we employed ANOVA that is used for
determining statistical significance of differences
among different groups. Table 3 shows that the
mean for our tool was better than those of Favorite
and SIS.
Table 3: ANOVA result.
ANOVA puts all the data into one number (F)
and gives us one P for the null hypothesis. The value
was equal to F(2,177)=3.866 (p < 0.05), and the
difference was reliable at the 95% confidence level.
It means that users are more likely to say that our
tool has superior information reusability.
Table 4: Pairwise comparisons.
In addition, information reusability was different,
depending on the methods. Table 4 shows the
detailed analysis about statistical significance for
pair-wise comparisons. In the result, the difference
between our tool and Favorites was significant with
a very high level of confidence. However, the
significances of the differences between other pairs
were less confident.
5 CONCLUSIONS
We have proposed a new tool based on a our own
model for exploratory searches, which explicates
operations at the knowledge level and across the
information and knowledge spaces in addition to the
typical information level operations, searching and
browsing. The notion of knowledge space, in
conjunction with that of information space,
facilitates explication of knowledge level and inter-
space operations so that users can reduce their
cognitive burdens when the interactive tool is
available.
Although the superiority is not strongly
conclusive in some cases, due to the explorative
nature of the current study and the confidence level
in the significant tests, the result indicates that our
novel approach to an interaction mediation for
exploratory search based on the two level model and
the associated operations is very promising and
worth a further study.
ACKNOWLEDGEMENTS
This work was partially supported by the Korea
Foundation for International Cooperation of Science
& Technology (KICOS) through a grant provided by
the Korean Ministry of Science & Technology
(MOST) in K20711000007-07A0100-00710, and
partially supported by 2
nd
phase of Brain Korea 21
project sponsored by Ministry of Education and
Human Resources Development, Korea.
ICEIS 2008 - International Conference on Enterprise Information Systems
284

REFERENCES
Anderson, J. R. A spreading activation theory of memory.
(1983). Journal of Verbal Learning and Verbal
Behavior, 22, pp. 261-295.
Bates, M. (1989). The design of browsing and berry
picking techniques for the online search interface.
Online Re-view, vol. 13, no. 5, pp. 407-431.
Belkin, M. J. (1980). Anomalous states of knowledge as a
basis for information retrieval, Canadian Journal of
Information Science, 5, pp. 133-143.
Catledge, L. and Pitkow, J. (1995). Characterizing
browsing strategies in the World Wide Web.
Computer Networks and ISDN Systems, vol. 27, no. 6,
pp. 1065-1073.
Cui, H., Wen J.-R., Nie, J.-Y., and Ma, W.-Y. (2002).
Probabilistic query expansion using query logs.
Proceedings of WWW 2002.
Dumais, S. T., Cutrell, E., Sarin, R., and Horvitz, E.
(2004). Implicit queries (IQ) for contextualized search
(demo description). Proceedings of SIGIR 2004.
Dumais, S., Cutrell, E., Cadiz, J., Jancke, G., Sarin, R.,
and Robbins, D. C. (2003). Stuff I've seen: a system
for personal information retrieval and re-use.
Proceedings of the 26th ACM SIGIR 2003, pp. 72-79.
George Buchanan and Ann Blandford and Matt Jones and
Harold Thimbleby. (2002). Spatial Hypertext as a
Reader Tool in Digital Libraries. LNCS 2539, pp. 13-
24.
Google Notebook: http://www.google.com/notebook/
Harper, D. J. and Kelly, D. (2006). Contextual relevance
feed-back. Proceedings of the 1st international
Conference on information interaction in Context,
176, pp. 129-137.
Hendry, D. G., and Harper, D. J. (1997). An informal
information-seeking environment. Journal of the
American Society for Information Science, vol. 48, no.
11, pp. 1036-1048
Park, H., Myaeng, S. H., Jang, G., Choi, J.W., Jo, S., and
Roh, H.C., (2007). SnB project Tech. Report: Two-
level model,
http://ir.icu.ac.kr/~phg/snb_techReport1.pdf
JDesktop Integration Components:
https://jdic.dev.java.net/
Jijkoun, V., de Rijke, M. (2006). Pilot for Evaluating
Exploratory Question Answering. Proceedings SIGIR
2006 workshop on Evaluating Exploratory Search
Systems, pp. 39-41.
Joachims, T., Freitag, D., and Mitchell, T. (1997).
WebWatcher: A tour guide for the World Wide Web.
Proceedings of IJCAI 1997, pp. 770-770.
Liu, H. and Singh, P. (2004). ConceptNet: a practical
common-sense reasoning toolkit. BT Technology
Journal, vol. 22, no. 4, pp. 211-226.
Marchionini, G. (2006). Exploratory search: from finding
to understanding. Commun. ACM, vol. 49, no. 4, pp.
41-46.
Martin, I., Jose, J.M, (2004). Fetch: A personalized
information retrieval tool. Proceedings of the
RIAO'2004 Con.
McKenzie, B. and Cockburn, A. (2001). An empirical
analysis of web page revisitation. Proceedings of the
34th HICSS, 2001, CD Rom,.
Olston, C. and Chi, E. H. (2003). ScentTrails: Integrating
browsing and searching on the Web. ACM Trans.
Comput.-Hum. Interact. vol. 10, no. 3, pp. 177-197.
Pathway: http://pathway.screenager.be/
Pirolli, P. & Card, S.K. (1995). Information foraging.
Psychological Review, 106, 643-675.
Reid, G.B. and Nygren., T.E. (1988). The subjective
workload assessment technique: A scaling procedure
for measuring mental workload. P.A. HANCOCK and
N. MESHKATI, eds. Human Mental Workload.
Amsterdam: North Holland.
Richard Furuta, Frank M. Shipman III, Catherine C.
Marshall, Donald Brenner, and Hao-wei Hsieh. (1997).
Hyper-text Paths and the World-Wide Web:
Experiences with Walden's Paths. Proceedings of
Hypertext '97, pp. 167-176.
Russell, D. M. et al. (1993). The cost structure of sense-
making. Proceedings of CHI 1993, 269-276.
Shen, X., Tan, B., and Zhai, C. (2005). Context-sensitive
in-formation retrieval using implicit feedback.
Proceedings of the 28th ACM SIGIR 2005, pp. 43-50.
Sriram, S., Shen, X., and Zhai, C. (2004). A session-based
search engine (poster). Proceedings of SIGIR 2004.
Sugiyama, K., Hatano, K., and Yoshikawa, M. (2004).
Adaptive web search based on user profile constructed
without any effort from users. Proceedings of WWW
2004.
Tauscher, L. and Greenberg, S. (1997). How people revisit
Web pages: Empirical findings and implications for
the de-sign of history systems. International Journal
of Human Computer Studies, vol. 47, no.1, pp. 97-138.
Taylor, R. (1968). Question-Negotiation and Information
Seeking in Libraries. College & Research Libraries,
vol. 29, no. 3, pp. 178-194.
Teevan, J., Alvarado, C., Ackerman, M. S., and Karger, D.
R. (2004). The perfect search engine is not enough: a
study of orienteering behavior in directed search.
Proceedings of CHI 2004, pp. 415-422.
TREC-2003 Web Track: Guidelines.
http://es.csiro.au/TRECWeb/guidelines 2003.html.
Wen, J. (2003). Post-Valued Recall Web Pages: User
Disorientation Hits the Big Time. IT & Society, vol. 1,
no. 3, 2003.
White, R. W. and Drucker, S. M. (2007). Investigating
behavioral variability in web search. Proceedings of
WWW 2007, pp. 21-30.
X. Huang, F. Peng, A. An, and D. Schuurmans. (2004).
Dynamic web log session identification with statistical
language models. Journal of the American Society for
Information Science and Technology, vol. 55, no. 14.
pp. 1290–1303.
Yahoo Myweb: http://myweb.yahoo.com/
Zigoris, P. and Zhang, Y. (2006). Bayesian adaptive user
profiling with explicit & implicit feedback.
Proceedings of CIKM 2006, pp. 397-404.
AN INTERACTIVE INFORMATION SEEKING INTERFACE FOR EXPLORATORY SEARCH
285
