
Informating HRM through »Data Mining«?
A Conceptual Evaluation
Stefan Strohmeier and Franca Piazza
Saarland University, Campus C3.1
66123 Saarbrücken, Germany
Abstract. Beyond mere automation of tasks, a major potential of HRIS is to in-
formate HRM. Within current HRIS the informate function is realized based on
a data querying approach. Given a major innovation in data analysis subsumed
under the concept of »data mining«, possibly valuable potentials to informate
HRM are lost while overlooking the data mining approach. Our paper therefore
aims at a conceptual evaluation of the potentials of data mining to informate
HRM. We hence discuss and evaluate data mining as a novel approach com-
pared to data querying as the conventional approach of informating HRM.
Based on a robust framework of informational contributions, our analysis re-
veals interesting potentials of data mining to generate explicative and prognos-
tic information and hence to enrich and complement the querying approach. To
deepen the knowledge on the contributions of data mining we finally derive
recommendations for future research.
1 Introduction
The usage of Information Technology (IT) in Human Resource Management (HRM)
is wide spread in the interim and corresponding Human Resource Information Sys-
tems (HRIS) provide a broad range of functionalities to support HR tasks. Current
systems cover operational HR tasks such as payroll processing, employee and con-
tract record keeping, attendance administration among others [e.g. 1, 14] as well as
managerial tasks such as recruiting and selection [e.g. 18], compensation and benefits
[e.g. 7], training and development [e.g. 34], performance management [e.g. 22] and
HR planning [e.g. 9]. Insofar, current HRIS aim at comprehensively automating and
informating the operational as well as the managerial side of HRM [31].
Traditionally, HRIS are applied to automate HR tasks and thus enable efficient
task fulfilment. To give a plain example, payroll systems allow the automated calcula-
tion and payment of salaries thereby easing the burden of a manual payroll process-
ing. Generally, automation hence enables efficient realisations of diverse HR task
thereby speeding up processes, reducing error ratios, and lowering costs of task ful-
filment. Given these advantages, the automation of HR tasks via HRIS offers exten-
sive potentials for HRM.
Strohmeier S. and Piazza F. (2008).
Informating HRM through Â
˙
zData MiningÂ
´
n? A Conceptual Evaluation.
In Proceedings of the 2nd International Workshop on Human Resource Information Systems, pages 51-62
DOI: 10.5220/0001735500510062
Copyright
c
SciTePress

Notwithstanding these advantages, a second and by far more advantageous func-
tion of HRIS is to informate HR managers so as to improve their operative as well as
strategic decision making [35, 36]. As HRIS are already widely applied to automate
HR processes, extensive and ever increasing data pools underlying these processes
are mandatorily stored in the database layer of any HRIS configuration. Thus beyond
automation, the unique value of HRIS lies in their capacity to analyse these large
amounts of data and support HRM with valuable information that will lead to better,
since more informed managerial decisions and actions. Hence based on automation it
is essential to exploit the potentials of HRIS to informate HRM thereby improving
HR practices and enabling a proactive and strategic HRM [12].
From the beginning of HRIS usage, conventional reporting features of HRIS pro-
vided possibilities to informate HRM by offering a broad variety of individually
specified as well as generally preconfigured data queries. Though there are improve-
ments such as multidimensional data analysis [5, 19, 24] up until now queries gener-
ally represent the common realisation of the information function in current HRIS.
However, given the persistent progress in information science, in the interim inno-
vative methods of data analysis are available that aim at the automatic recognition of
data patterns and hence at providing new, valid and potentially useful information
beyond mere data queries [8]. Metaphorically, such methods are subsumed under the
concept of “data mining” so as to demonstrate the “digging” of valuable information
out of databases and data storing components of application systems. Synonymous
terms are “knowledge discovery in databases (KDD)” or “data pattern recognition”
[8]. First applications of data mining in diverse areas of HRM show promising poten-
tials of mining HR data [e.g. 6, 10, 11, 16, 23, 26, 27, 28, 29]. However, the applica-
tion of data mining in the context of HRM is scarce and innovative, and data mining
is far from being a standard analysis instrument of current HRIS. Given the out-
standing importance of the informate function of HRIS, the question arises whether
valuable potentials to informate HRM are lost by overlooking data mining [21].
Hence, our paper aims at a conceptual evaluation of the potentials of data mining to
informate HRM.
To do so, we firstly discuss conventional data querying and novel data mining ap-
proaches to informate HRM. Based on a robust framework of information contribu-
tions we subsequently evaluate both approaches on a conceptual level. Conclusively,
we attempt to derive recommendations for future research in order to elaborate the
potentials of data mining to informate HRM.
2 Presentation of Approaches
Using the data pools of HRIS to informate HRM is by no means a new claim. On the
contrary, from the beginnings decades ago HRIS were (also) used to informate HRM.
As already mentioned, the conventional approach of informating is data querying,
while data mining constitutes an innovative approach that possibly shows diverse
advantages. We hence analyse both general approaches in the following so as to
elaborate commonalities and differences of querying and of mining HR data. How-
ever, since both approaches comprise of several different categories of analysis meth-
52

ods, a comprehensive comparative discussion of all categories is beyond the scope of
this paper. Hence, with standard queries and classification analysis we choose two
prototypical methods of each approach and discuss their procedures and possible
results. Strictly speaking, this focus restricts our comparison of querying and mining
to the respective categories. Results hence cannot be plainly transferred to the general
approaches of querying and mining. Nevertheless, a first comparison of prototypical
methods is provided and further querying and mining methods can be discussed ana-
logically.
Since particularly data mining methods are rather complex we additionally base
our analysis on a plain example so as to increase intelligibility. A high turnover rate
implies intensified recruiting and development efforts among others. These measures
lead to high costs, thus informating HRM to create retention strategies is of unmistak-
able importance. Therefore, we focus on turnover analysis as an exemplary applica-
tion area in the following.
2.1 Data Querying
Since employed for decades, data querying constitutes the well-established approach
of informating HRM. Roughly distinguishing different categories, “standard queries"
and “multidimensional queries” constitute two major categories of data querying.
Standard queries represent precise requests for information that use search values
combined with operators to specify the information needed. They are the exceedingly
common method of retrieving information out of structured data and are offered by
(nearly) every HR application of whatever kind and area. Multidimensional queries
(often also referred to as “Online Analytical Processing [OLAP]”) constitute a newer
query approach that is based on a specific preparation of data in n-dimensional cubes
(“hypercubes”) and allows analysing HR relevant figures in relation to several rele-
vant dimensions [e.g. 5, 19, 24]. As a newer query category multidimensional analy-
sis is offered only by few HR applications, as for instance data warehouse-systems
[19]. Due to their prevalent usage to informate HR, we focus on standard queries as a
prototypical query category in the following.
Technically, standard queries are realized based on common query algorithms or
query languages such as Structured Query Language (SQL) [e.g. 17] respectively.
Applying standard queries, HRM can receive information about historic and recent
events concerning any HR related aspect stored in any system or component of the
HRIS database layer. Applied to turnover analysis, standard queries are able to satisfy
information requests that may be expressed by questions like
“How many employees have left the company during the last year?”,
“What were the demographical attributes of these employees?” or
“What were the exit kinds of these employees?”
If not offered as a general predefined query, users have to specify such information
needs based on an individual query by firstly determining desired data items while
additionally stating desired values of certain data items by using operators and refer-
ence values. To satisfy the information requirements delineated above, a query can be
specified to display the items like name, gender, age, and exit kind among others
while selecting only records of employees that have left during the last year. After
53

specification the query is executed and results are usually presented in tables. The
following figure depicts a conceivable result of such a query.
n
ame gender age qualification ... exit kind
Smith
m
45 high ... employee’s reason
Kline f 59 medium ... early retirement
Pit
t
m
34 medium ... employee’s reason
Jolie f 56 high ... early retirement
Tarantino
m
65 high ... regular retirement
… … … … ... …
Fig. 1. Example of a data querying result.
Additionally, sorting functions may be applied to sort records with regard to gen-
der, age or exit kind among others. The general benefit of querying then lies in the
ability to filter the required information out of often huge amounts of data and present
it in a clearly arranged and hence easily intelligible form. Generally, standard queries
are able to satisfy information needs of HRM that can be clearly specified, concern
historic and recent information, and are represented by corresponding data items
stored in the data layer. Hence, as a first requirement, users must be able to concretely
specify the information needed. While sounding trivial at first glance, specifying
concrete information needs of HRM is often intricate. If, for instance, employees of a
certain ethnic category unexpectedly are significantly more frequently quitting, this
important information will be lost in the query above, since the item “ethnic group”
was not considered relevant and hence was not specified. Thus, queries show difficul-
ties in detecting “hidden” and unexpected information represented in the data layer.
Further, as a second requirement, the information needs which should be satisfied by
queries usually refer to historic and recent information. If HRM, for instance, should
be interested in a prognosis concerning which valued employees are likely to volun-
tarily quit in the future (so as to counteract with specific retention measures), query-
ing is usually not able to provide such prognostic information. Admittedly, users can
“manually” search for attribute patterns of typically quitting employees in the query
result and use this pattern for a prognosis. Given usually copious rows within a query
result, such a manual search is however at least intricate and laborious, if not impos-
sible. Hence, queries are suitable for providing historic information but usually show
difficulties in providing relevant prognostic information. Finally, a third and obvious
requirement is the availability of data items that correspond with the information
need. If HRM, for instance, is interested in concrete exit reasons of voluntarily leav-
ing valued employees but corresponding data items are missing, querying evidently is
not able to provide such information.
To sum up, data querying constitutes a well-established approach to informate
HRM concerning historic and descriptive information.
54

2.2 Data Mining
Not yet established as a general measure to informate HRM, data mining offers the
possibility to extract new, valid, understandable and potentially useful patterns in
larger amounts of data [8]. Roughly distinguishing different categories, “classification
analysis”, “association analysis” “segmentation analysis” and “deviation analysis”
constitute four major categories of data mining [e.g. 4]. Classification analysis aims
at automatically classifying objects to predefined classes, thereby detecting those
attributes that systematically discriminate between the classes. Classification hence
contributes to information by detecting attributes that predict the belonging of an
object to a certain predefined class. Association analysis aims at automatically detect-
ing significant associations between the attribute values of objects. Association hence
contributes to information by detecting connections and links in data. Segmentation
analysis (frequently also referred to as “cluster analysis”) aims at the automatic gen-
eration of homogeneous segments (groups or clusters) of objects. Segmentation hence
contributes to information by revealing different homogenous groups within larger
data pools. Finally, deviation analysis aims at automatically detecting objects that -
for whatever reasons - significantly differ from other objects. Hence, deviation analy-
sis contributes to information by detecting all kinds of “outliers” [e.g. 4]. Due to its
prototypical character for data mining we focus on classification analysis (also re-
ferred to as “rule induction” or “decision trees”) in the following.
Technically, classification analyses are realized based on classifier algorithms such
as the C5.0 algorithm [25]. Applying classification analysis, HRM can receive infor-
mation concerning attributes that - abstractly speaking - predict the belonging of an
object to a certain predefined class. Applied to turnover analysis classification analy-
ses are able to satisfy information requests that may be expressed by interrelated
questions like
“What are significant attributes of employees who have left the company?”,
“Why did these employees leave the company?” and
“Which type of employee is likely to leave in future?”
To answer these questions users have to specify objects and the classes, towards
which the objects should be classified. More concretely, given the information re-
quest delineated in the above questions, a user will specify that employees should be
classified to the different classes of the “exit kind” item, i.e. “regular retirement”,
“early retirement” and “employee’s reason”. Further specifications are not necessary,
since the algorithm will automatically search for attributes that systematically dis-
criminate between these specified classes. After executing, classification results are
usually presented as a set of rules, each of them comprising of premises (“If”-
component) and a conclusion (“Then”-component). The following figure depicts a
conceivable (partial) result of a classification analysis formulated as a rule.
IF age < 40
AND total salary < 31.500€
AND qualification = high
THEN exit kind = employee’s reason
Fig. 2. Example of a data mining result.
55

As can be seen from the rule, employees are classified to the class “exit kind =
employee’s reason” (conclusion of the rule), while the attributes listed before are
predictors of belonging to this class (premises of the rule). Hence, the information
provided is, that a certain age, salary and qualification of employees induce voluntary
turnover. Such rules then constitute the “pattern” that data mining has detected. As a
first central difference to queries, these predicting attributes (as their values) have not
to be specified by the user, but are automatically found by the classification algorithm
out of a large amount of possible attributes of the corresponding database. Users
hence need no previous knowledge or ideas concerning predictors of voluntary turn-
over. In addition, while queries deliver mainly descriptive and historic information,
generated rules at least have the potential to provide explanations and allow forecasts.
Accordingly, the rule delineated above offers a plain explanation for voluntary turn-
over: Since younger, high qualified persons with a rather low salary are leaving, the
discrepancy between compensation and qualification offers an obvious explication of
turnover. Moreover, assuming that the rule above represents a general explicative
pattern it also allows a forecast of future turnover. Hence, if there still are younger
qualified employees in the delineated salary class, this group is particular likely to
leave as compared to other employee groups. Rules, however, do not automatically
dispose of explicative and prognostic possibilities, but can also turn out to be merely
descriptive resembling the results of queries in this aspect. The following figure de-
picts a rule concerning early retirement received from mining real HR data of a MNC.
IF country = Germany
AND age ≥ 52
AND age ≤ 56
THEN exit kind = early retirement
Fig. 3. Example of a descriptive data mining result.
This rule does not show the potential to explain early retirement. Rather, it reflects
the regulations of early retirement legislation in Germany that allow early retirements
exactly within the presented age group. Though commonly of lower value such de-
scriptive information is not worthless, since for instance legal compliance can be
controlled based on such rules. Explicative as well as descriptive rules then are valid
outputs of classification analysis. Since classification algorithms select attributes
based on formal but not textual relevance criteria, specific data constellations may
also lead to invalid rules. Thus before further usage, generated rules in any case have
to be carefully evaluated and interpreted against the corresponding real HR back-
ground [8], while especially the explicative and prognostic validity of rules has to be
assessed.
Summed up, data mining is able to automatically generate new, valid, understand-
able and potentially useful patterns out of HR data. In the case of classification analy-
sis, rules concerning any interesting phenomenon can be generated, that show the
potential to explain the phenomenon under consideration as well as predict its ap-
pearance in future. Thereby data mining offers information that usually is unobtain-
able using mere querying of the same data.
56

3 Conceptual Evaluation of Approaches
Querying and mining of HR data both aim at exploiting the potential of existing data
pools to informate HRM. To provide a first general evaluation and to basically com-
pare the respective contributions of both approaches in informating HRM, we elabo-
rate on a general framework that robustly categorises different categories of informa-
tion necessary to informate HRM (as other units of the organisation).
As a first dimension of the framework, it is important to consider the time-
reference of the information provided. Roughly dichotomising this dimension, his-
toric and prognostic information can be distinguished. Historic information exclu-
sively refers to developments of the past, while prognostic information refers to de-
velopments that are (likely) to come in the future. Assessing these categories, both
kinds of information are traceably contributing to informate HRM. Initially historic
information evidently contributes to informate HRM, since desired and undesired
developments of the past can be controlled. All the more, prognostic information
contributes to HRM, since it emphasizes relevant future developments. Concerning
the derivation of appropriate management measures, however, prognostic information
is more favourable, since adequate (counter-)measures can be taken in advance, while
measures based on historic information necessarily happen after a triggering event
and hence may be too late. Referring to the above example of unwanted turnover of a
larger group of key employees, historic information is merely able to report such
undesired developments in the recent past, while (valid) prognostic information at
least offers the potential to prevent such developments. In brief, while mere historic
information urges HRM into a reactive position, additional prognostic information
facilitates a more proactive role of HRM.
As a second dimension of the framework, it is insightful to consider the quality of
the information provided. Also roughly dichotomising this dimension, descriptive and
explicative information can be distinguished. Descriptive information merely reports
relevant developments without offering any background information (answers to
“what”-questions). Explicative information exceeds this level since it additionally
offers insights concerning the reasons or causes of the developments reported (an-
swers to “why”-questions). Again, both kinds of information are obviously necessary
to comprehensively informate HRM. Concerning the derivation of appropriate man-
agement measures, however, explicative information is evidently more advantageous,
since it additionally explains developments thereby offering hints concerning kind,
starting point and success of corresponding (counter-)measures. Referring to the
above turnover example, descriptive information hence merely reports the fact of
unwanted turnover, while explicative information gives an explanation and hints at
possible retention measures as for instance changes in compensation. In brief, while
mere descriptive information leaves HRM unadvised, additional explicative informa-
tion usually offers some guideline for action.
The combination of both dichotomised information dimensions generates a robust
and general framework with four quadrants that is able to evaluate information con-
tributions of different analytical approaches (see Figure 4).
57
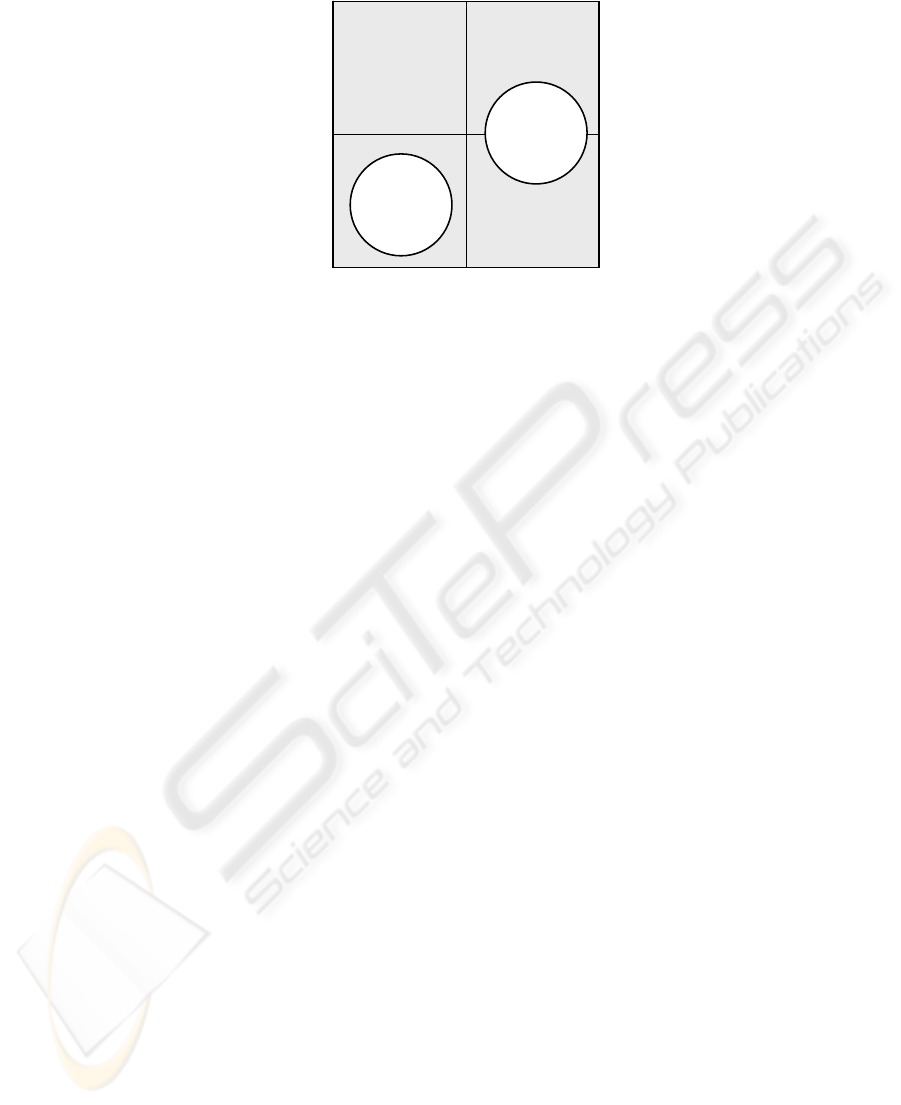
descriptive explicative
data
querying
data
mining
historic
prognostic
II
IVIII
descriptive explicative
data
querying
data
mining
historic
prognostic
II
IVIII
Fig. 4. Information dimensions and analytical approaches.
Classifying the delineated analytical approaches into the framework, the data que-
rying-approach clearly belongs to the quadrant I, since it offers historic and descrip-
tive information. By offering such historic-descriptive information valuable contribu-
tions to the informate-function can be achieved, as depicted above. Hence, now as
before diverse categories of data querying should be used to informate HRM. How-
ever, the more valuable information quadrants II, III and IV with prognostic and/or
explicative information usually cannot be served based on querying approaches of
whatever kind. This hence constitutes an evident major limitation of querying. Given
that querying currently constitutes the prevalent approach of informating HRM, even
a serious analytical lack has to be stated.
As explained above and therefore suggested in Figure 4, data mining shows the
potential of reducing this lack. Yet, again it has to be stressed that data mining does
not mandatorily provide explicative and prognostic information, since for instance
merely historic-descriptive information is also an imaginable result. Hence, the actual
classification of data mining into the framework depends on the concrete single appli-
cation and the corresponding concrete results of a data mining project, while all four
quadrants generally are conceivable. The classification provided in Figure 4. there-
fore represents a successful application of data mining. Since the provision of prog-
nostic and explicative information is feasible with (successful) data mining it offers a
valuable and desirable completion of the current analytical approach, facilitating a
more proactive role for HRM as required so often in research and practice.
To sum up, data querying and data mining constitute dissimilar analytical ap-
proaches that do not show rivalling positions since the kind of offered (or at least
intended) information clearly differs. Data mining then plainly demonstrates the po-
tential to complement and enrich current methods and corresponding information
levels with particularly valuable additional information. Hence based on a first con-
ceptual evaluation, data mining should be added to the standard inventory of analyti-
cal methods of HRIS in order to more comprehensively exhaust the potential of given
data to informate HRM.
58

4 Future Research
Given the positive results of the initial conceptual analysis above, much research
work remains to be done.
A first limitation of our work is the mentioned focus on prototypical categories of
querying as of mining. Future research hence should broaden the scope of analysis by
considering all relevant querying as particularly mining categories, for instance based
on the framework above or on further theoretical groundings. This will assess and
complement our statements and likely lead to a more comprehensive since more dif-
ferentiated understanding of the potentials of data mining to informate HRM.
A second and perhaps more serious limitation is constituted by the mere concep-
tual character of our evaluation and hence the lack of empirical evidence. Conse-
quently, the potentials evinced by conceptual analysis should additionally be empiri-
cally evaluated. However, the mere novelty of the data mining approach yields a
major problem for any empirical evaluation, since there is no larger set of organisa-
tions that comprehensively apply data mining in HRM. While there may be a small
number of pioneering organisations that may allow for initial case study approaches
[30] any survey approach will be pointless since the only result will be that data min-
ing is not adopted in HRM yet. Therefore, action research can be recommended as a
proactive research approach [e.g. 33] also feasible and valuable in information sys-
tems research in order to examine research questions of practical and scientific rele-
vance [e.g. 2, 13, 20]. Based on a cooperation of researchers and practitioners, action
research generally aims at solving novel practical problems while contributing to
corresponding scientific knowledge [3]. The practical problem under consideration
then generally is informating HRM via adequate analytical approaches, while the
corresponding scientific topic is constituted evaluation of diverse data mining ap-
proaches, as described above. Following a prominent suggestion, action research
projects may be described as a process comprising of diagnosing, action planning,
action taking and specifying learning [2, 32]. Diagnosing aims at the specification of
the practical problem and the corresponding research hypothesis. During the action
planning phase researchers and practitioners jointly specify the application area and
choose the corresponding data mining method and the data to be analysed. Subse-
quently, the data mining analyses are conducted, and the results generated are evalu-
ated by specifying the practical and scientific knowledge gained. Based on the
knowledge gained, eventually a next iteration of an action research cycle can be es-
tablished [2, 15].
One suggestion to structure this process is to use general application scenarios.
General application scenarios initially describe supposed application possibilities of
data mining that are likely to repeatedly occur in numerous organisations, by high-
lighting the general application area, the specific application purpose, the feasible
mining methods, the (likely) needed data pool, and the expected kind of results. Re-
ferring to the above example figure 5 outlines a brief example of a general application
scenario in turnover analysis.
59

General Application Scenario »Turnover Analysis«
application area: retention management
application purpose: explaining and predicting voluntary turnover
of (high performing) employees
data input: employee master data, compensation data,
development data, succession data, perfor-
mance and appraisal data, ..., turnover data
method catego
r
y: classification analysis
(static) association analysis
sequential association analysis
kind of result: (sequential) rules
Fig. 5. Example of a general application scenario.
So as to comprehensively evaluate data mining, diverse general application scenar-
ios stemming for different functional areas such as staffing, appraising, developing
and compensation are to be developed and evaluated. Additionally, so as to cope with
the generalisation problem - an inherent difficulty of any action research approach -
any application scenario should be iteratively evaluated in different organisations so
as to validate the obtained evaluation results in different contexts and settings [15].
Positively evaluated application scenarios can be recommended to be practiced. This
could be for instance offering (partially) predefined mining possibilities within future
(business intelligence modules of) HRIS. Additionally, generalising from diverse
positively as well as negatively evaluated application scenarios will distinctly con-
tribute to scientific knowledge concerning the contribution of data mining to infor-
mate HRM.
In any case, data mining constitutes an analytical approach worth intensive future
consideration in research as in practice.
References
1. Ball, K.S.: The Use of Human Resource Information Systems: A Survey. Personnel Re-
view, 30, 6 (2001) 677-693
2. Baskerville, R.L.: Investigating Information Systems with Action Research. Communica-
tions of the AIS, 2, 19 (1999)
3. Baskerville, R., Myers, M.D.: Special Issue on Action Research in Information Systems:
Making IS Research relevant to Practice - Foreword. MIS Quarterly, 28, 3 (2004) 329-335
4. Berry, M., Linoff, G.: Data Mining Techniques, Wiley, Indianapolis (2004)
5. Burgard, M., Piazza, F.: Data Warehouse and Business Intelligence Systems. In: Torres-
Corona, T., Aria-Oliva, M. (eds.): Encyclopedia Human Resources Information Systems:
Challenges in e-HRM, IGI Global, Hershey (2008), in press
6. Cho, V., Ngai, E.: Data Mining for Selection of Insurance Sales Agents. Expert Systems,
20, 3 (2003) 123-132
7. Dulebohn, J.H., Marler, J.H.: e-Compensation: The Potential to Transform Practice? In:
Gueutal, H.G., Stone, D.L. (eds.): Brave New World of e-HR. Human Resources Manage-
ment in the Digital Age, Jossey Bass, San Francisco (2005) 166-189
60

8. Fayyad, U., Piatetsky-Shapiro, G., Smith, P.: From Data Mining to Knowledge Discovery
in Databases. AI Magazine, 17, 3 (1996) 37-53
9. Hendrickson, A.R.: Human Resource Information Systems: Backbone Technology of
Contemporary Human Resources. Journal of Labour Research, 24, 3 (2003) 381-394
10. Hou, X.-D., Dong, Y.-F., Liu, H.-P., Gu, J.-H.: Application of Fuzzy Data Mining in Staff
Performance Assessment. International Conference on Machine Learning and Cybernetics,
Vol. 2 (2007) 835-838
11. Huang, L.-C., Wu, P., Kuo, R.J., Huang, H.C.: A Neural Network Modelling on Human
Resource Talent Selection. International Journal of Human Resources Development and
Management, 1, 2/3/4 (2001) 206-219
12. Hussain, Z., Wallace, J., Cornelius, N.E.: The Use and Impact of Human Resource Infor-
mation Systems on Human Resource Management Professionals. Information and Man-
agement, 44, 1 (2007) 74-89
13. Iversen, J.H., Mathiassen, L., Nielsen, P.A.: Managing Risk in Software Process Improve-
ment: An Action Research Approach. MIS Quarterly, 28, 3 (2004) 395-433
14. Kinnie, N.J., Arthurs, A.J.: Personnel Specialist’s advanced Use of Information Technol-
ogy. Personnel Review, 25, 3 (1996)
15. Kock, N.F., McQueen, R.J., Scott, J.L.: Can Action Research be Made More Rigorous in a
Positivist Sense? The Contribution of an Iterative Approach. Journal of Systems and In-
formation Technology, 1, 1 (1997) 1-24
16. Kovács, L., Lizák, M., Kolzca, C.: Selection with the Help of Data Mining. Production
Systems and Information Engineering, 2 (2004) 91-105
17. Lans, R.F. van der: Introduction to SQL. Addision-Wesley: Amsterdam (2006)
18. Lee, I.: An Architecture for a Next-Generation Holistic E-Recruiting System. Communica-
tions of the ACM, 50, 7 (2007) 81-85
19. Lin, B., Stasinskaya, V.S.: Data Warehousing Management Issues in Online Recruiting.
Human Systems Management, 21, 1 (2002) 1-8
20. Lindgren, R., Hendrickson, O., Schultze, U.: Design Principles for Competence Manage-
ment Systems: A Synthesis of an Action Research Approach. MIS Quarterly, 28, 3 (2004)
435-472
21. Long, L.K., Troutt, M.D.: Data Mining for Human Resource Information. In: Wang, J.
(ed). Data Mining: Opportunities and Challenges, IRM: Hershey (2003) 366-381
22. Miller, J.: High Tech and High Performance: Managing Appraisal in the Information Age.
Journal of Labour Research, 24, 3 (2003) 409-424
23. Min, H., Emam, A.: Developing the Profiles of Truck Drivers for their Successful Reten-
tion. A Data Mining Approach. International Journal of Physical Distribution & Logistics
Management, 33, 2 (2003) 149-162
24. Pemmaraju, S.: Converting HR Data to Business Intelligence. Employment Relations To-
day, 34, 3 (2007) 13-16
25.
Quinlan, J.R.: C4.5 programs for machine learning Morgan Kaufman Publisher, San Mateo
(1993)
26. Ramesh, B., Bui, T.: GPR: A Data Mining Tool using Genetic Programming. Communica-
tions of the AIS, 5, 6 (2001) 1-35
27. Romero, C., Ventura, S. (eds.): Data Mining in E-Learning, WitPress, Southampton (2006)
28. Sexton, R., McMurtrey, S., Michalopoulos, J.O., Smith, A.M.: Employee turnover: A
Neural Network Solution. Computers & Operations Research, 32 (2005) 2635-2651
29. Somers, M.J.: Application of two Neural Network Paradigms to the Study of Voluntary
Employee Turnover. Journal of Applied Psychology, 84, 2 (1999) 177-185
30. Strohmeier, S.: Research in e-HRM: Review and Implications. Human Resource Manage-
ment Review, 17, 2 (2007) 19-37
61

31. Strohmeier, S., Kabst, R.: Do Current HRIS Meet the Requirements of HRM? In: Bon-
darouk, T., Ruël, H. (eds.): Proceedings of the 1
st
International Workshop on Human Re-
source Information Systems - HRIS 2007, INSTINCC, Funchal (2007) 31-44
32. Susman, G., Evered, R.: An Assessment of the Scientific Merits of Action Research. Ad-
ministrative Science Quarterly, 23, 4 (1978) 582-603
33. Warmington, A.: Action Research: It’s Methods and it’s Implications. Journal of Applied
Systems Analysis, 7 (1980) 23-39
34. Welsh, E.T:, Wanberg, C.R., Brown, K.G., Simmering, M.J.: E-learning: Emerging Uses,
Empirical Results and Future Directions. International Journal of Training & Development,
7, 4 (2003) 245-259
35. Zuboff, S.: Automate/Informate: The Two Faces of Intelligent Technology. Organizational
Dynamics, 14, 2 (1985) 5-18
36. Zuboff, S.: In the Age of the Smart Machine. Basic Books, New York (1988)
62
