
NOTES ON THE ARCHITECTURAL DESIGN OF TMINER
Design and Use of a Component-based Data Mining Framework
Fernando Berzal, Juan-Carlos Cubero and A
´
ıda Jim
´
enez
Department of Computer Science and Artificial Intelligence, University of Granada
ETSIIT, C/ Periodista Daniel Saucedo Aranda, s/n, 18071 Granada, Spain
Keywords:
Data Mining, component-based systems, application frameworks, software architecture, design patterns.
Abstract:
This paper describes the rationale behind some of the key design decisions that guided the development of
the TMiner component-based data mining framework. TMiner is a flexible framework that can be used as a
stand-alone tool or integrated into larger Business Intelligence (BI) solutions. TMiner is a general-purpose
component-based system designed to support the whole KDD process into a single framework and thus facil-
itate the implementation of complex data mining scenarios.
1 INTRODUCTION
Traditional on-line transaction processing systems,
also known as OLTP systems, work with relatively
small chunks of data at a time, while on-line analyt-
ical processing systems, or OLAP systems, require
the analysis of huge amounts of data (Chaudhuri and
Dayal, 1997). It comes as no surprise that OLAP sys-
tems have very specific needs that conventional appli-
cation frameworks do not properly address. This fact
has led to the development of data mining (Tan et al.,
2006) (Han and Kamber, 2006) and data warehousing
(Widom, 1995) (Kimball and Ross, 2002), which try
to satisfy the expectations of the so-called knowledge
workers (executives, managers, and analysts).
This paper describes the rationale behind some
key design decisions that led to the development of
a component-based data mining framework called
TMiner. As we will see, TMiner can be used as a
flexible stand-alone data mining tool, but it has also
been designed so that it can be easily incorporated
into larger Business Intelligence solutions.
It should be noted that the tools and techniques
TMiner collects somewhat overlap with existing Ma-
chine Learning algorithm collections, such as Weka
(Witten and Frank, 2005). However, TMiner is more
that a mere collection of independent algorithms for
data mining tasks that can be directly applied on pre-
pared datasets or invoked from your own code.
Some open-source and commercial data mining li-
braries (Prudsys, 2008) (Rapid-I, 2008) include facili-
ties for their integration into actual enterprise systems.
TMiner also provides usage modes specially designed
for its tight integration into larger solutions.
TMiner is a general-purpose component-based
system designed to support the whole KDD process
into a single framework and thus facilitate the im-
plementation of complex data mining scenarios. In
this sense, TMiner is designed to be useful in a wide
variety of application domains, in sharp contrast to
domain-specific data mining systems such as iKDD or
SA. While the Interactive Knowledge Discovery and
Data mining system, iKDD, was designed for partic-
ular bioinformatics-related problems (Etienne et al.,
2006), Perttu Laurinen’s Smart Archive, SA, has been
proposed for implementing data mining applications
using data streams. (Laurinen et al., 2005)
The rest of our paper is organized as follows. Sec-
tion 2 describes the architectural design of the TMiner
framework and its component model. Section 3 de-
scribes the facilities TMiner offers for different usage
scenarios, from the casual user who wants to perform
simple data analysis tasks and the researcher who
needs a more thorough experimentation, to the sys-
tems integrator who needs to incorporate data mining
features into final solutions. Finally, Section 4 con-
cludes our paper with some comments on the current
status of TMiner and our expectations for its future.
98
Berzal F., Cubero J. and Jiménez A. (2008).
NOTES ON THE ARCHITECTURAL DESIGN OF TMINER - Design and Use of a Component-based Data Mining Framework.
In Proceedings of the Third International Conference on Software and Data Technologies - ISDM/ABF, pages 98-103
DOI: 10.5220/0001870600980103
Copyright
c
SciTePress
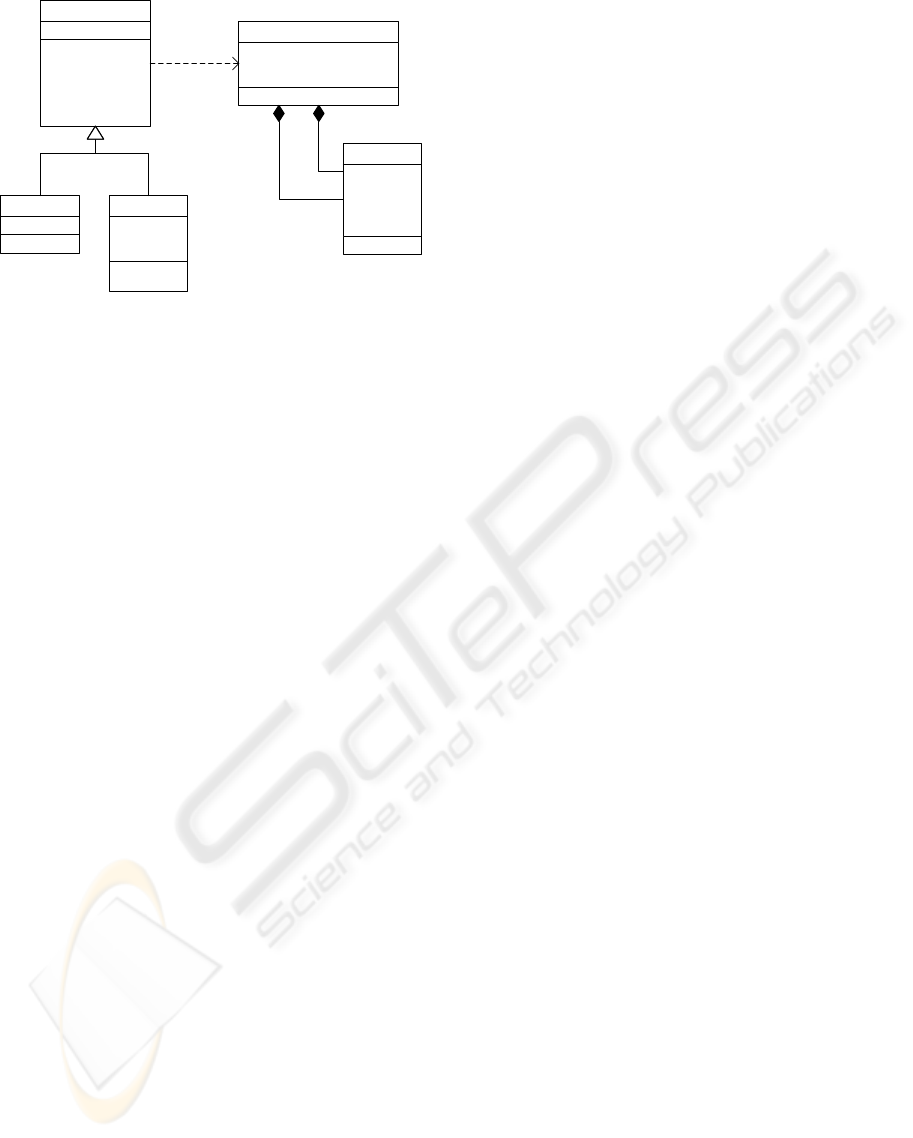
70LQHU&RPSRQHQW
70LQHU&RPSRQHQW0HWDGDWD
3RUW
70LQHU0RGHO
70LQHU7DVN
Figure 1: TMiner component model base classes.
2 TMINER COMPONENT
MODEL
This section describes the TMiner component model,
what TMiner components look like and the basic in-
frastructure provided by the TMiner framework for
the design and use of new components.
2.1 TMiner Components
A software component is “a unit of composition with
contractually defined interfaces and explicit context
dependencies” (Szyperski et al., 2002). These con-
text dependencies are specified by stating the re-
quired interfaces and the acceptable execution plat-
form(s) for the software component. TMiner com-
ponents have well-defined I/O ports whose specific
properties can be easily consulted by means of the
TMinerComponentMetadata object that is attached
to every TMinerComponent (see Figure 1).
Software components are units of independent de-
ployment, in contrast to objects in object-oriented
programming (OOP), which are mere units of instan-
tiation. Components are also units of third-party com-
position and they typically have no (externally) ob-
servable state. However, as objects in OOP, they en-
capsulate their state and behavior.
Obviously, components still act through objects in
object-oriented systems, but they do not only contain
classes. They can also contain additional resources.
In TMiner, components must include a component
descriptor describing its I/O ports and any additional
metadata that might be required for the component
to be used in practice. Figure 2 shows an example
of such a descriptor in XML format. The compo-
nent descriptor includes the names, textual descrip-
tions, and required interfaces for all the component
<?xml version="1.0" encoding="utf-8" ?> <component>
<type>tminer.kdd.association.ItemsetMiner</type>
<name>Itemset miner</name>
<description>TMiner base itemset miner</description>
<inputs>
<input>
<id>dataset</id>
<name language="en">Dataset</name>
<description language="en">Input dataset</description>
<type>tminer.data.Dataset</type>
</input>
<input>
<id>encoder</id>
<name language="en">Dataset encoder</name>
<description language="en">Dataset encoder</description>
<type>tminer.data.instance.DatasetEncoder</type>
</input>
</inputs>
<outputs>
<output>
<id>itemsets</id>
<name language="en">Itemset collection</name>
<description language="en">Itemsets</description>
<type>tminer.kdd.association.ItemsetCollection</type>
</output>
</outputs>
</component>
Figure 2: TMiner component descriptor.
I/O ports, as well as default values for component pa-
rameters. This information is extremely useful, for
instance, in the automatic generation of the user inter-
face for data mining tools (component developers do
not need to worry about user interface issues and they
can just focus on the development of the component
themselves).
In a data mining framework such as TMiner, the
user has to analyze large datasets with the help of min-
ing tools and techniques. Data is gathered from differ-
ent data sources and data mining algorithms are used
in order to build knowledge models (Berzal et al.,
2002). Hence TMiner components fall into two main
categories:
• TMinerModels represent the entities data miners
work with. They may provide the information our
user needs to access different data sources (i.e.
dataset metadata). They can also be descriptive or
predictive models built from those data sources.
They can even be used as the input to other min-
ing algorithms in order to solve second-order data
mining problems.
• TMinerTasks represent the tasks data miners
must perform to analyze data. They are the active
NOTES ON THE ARCHITECTURAL DESIGN OF TMINER - Design and Use of a Component-based Data Mining
Framework
99
objects that users need to build new models.
All components in TMiner must be serializable
(i.e. they can be stored as byte sequences for
later reconstruction). This is necessary because
TMinerModels must be stored for later use, while
TMinerTasks might need to be transferred to differ-
ent processing nodes in a distributed computing envi-
ronment.
Additionally, TMiner core classes include some
standardized interfaces designed to simplify the rep-
resentation, distribution, and use of the models dis-
covered in the KDD process. For instance, XMLable
components can be represented as XML documents,
hence facilitating their storage for later use, as well as
their visualization in standard web browsers (with the
help of the corresponding XSLT style sheets). Like-
wise SQLable components, such as many different
kinds of symbolic classification models, can be con-
verted into SQL scripts that might be invaluable in
practice, since they provide a very convenient method
for using such models on relational databases.
Any information system can be described by a
structure, a mechanism, and a policy following Perry
and Kaiser’s SMP model (Perry and Kaiser, 1991). In
our case, TMiner models determine the structure of
the system. TMiner tasks, which are responsible for
the implementation of data mining techniques, are the
mechanisms that let us solve data mining problems.
Finally, the set of rules and strategies imposed by the
system environment are used to establish its usage and
security policies. This is the job of the TMiner frame-
work we now proceed to describe.
2.2 The TMiner Framework
A component framework is “a collection of rules and
interfaces (contracts) that govern the interaction of
components plugged into the framework” (Szyperski
et al., 2002). Component frameworks can also be seen
as components that plug into higher-level component
frameworks (e.g. when integrated into larger solu-
tions).
Component-based frameworks are intended to
help developers to build increasingly complex sys-
tems, enhance productivity and promote component
reuse by means of well-defined patterns (Fayad and
Schmidt, 1997) (Larsen, 2000). Such frameworks are
widely-used in enterprise information systems, but
they usually only provide low-level information pro-
cessing capabilities, since they are OLTP-application-
oriented. In contrast, TMiner is a component-based
framework that has been custom-tailored to solve de-
cision support problems, even though it should be
noted that its approach could also be of use in a wide
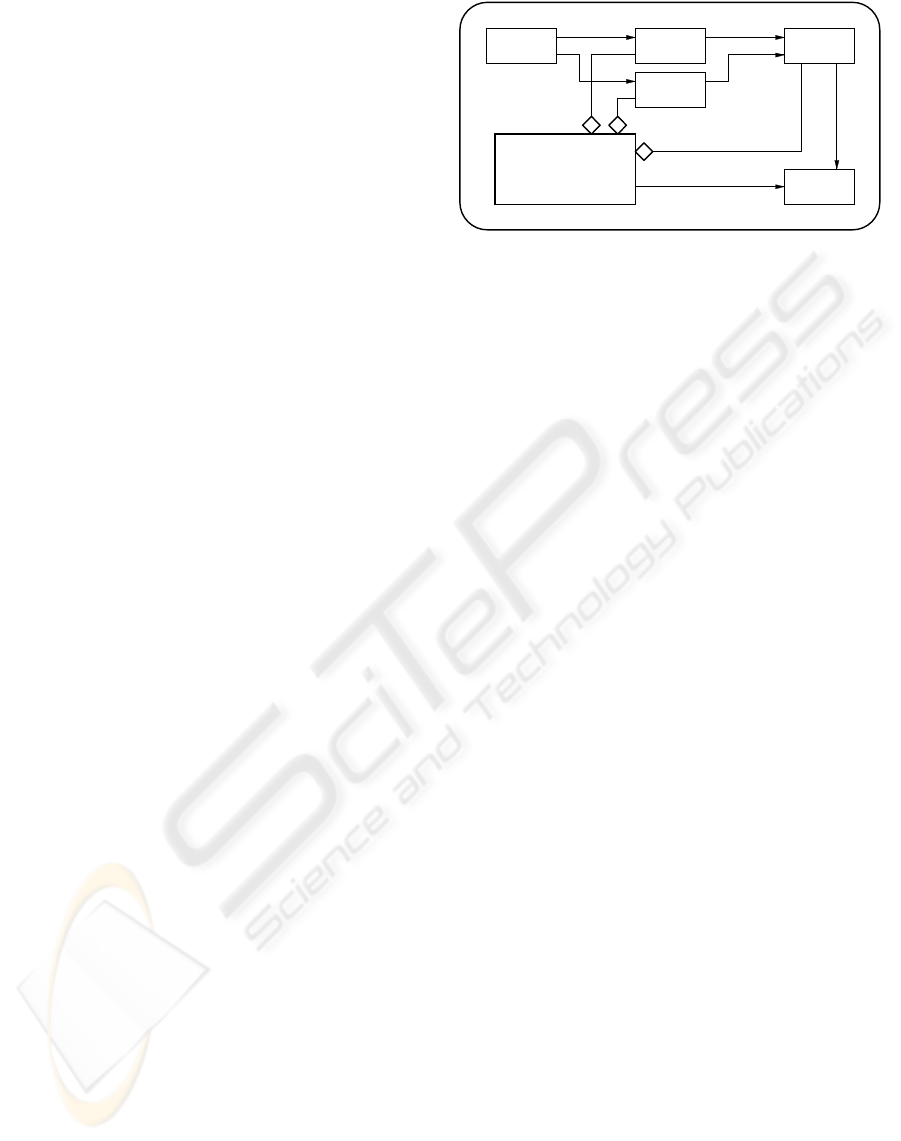
Container
Persistence
Service
Client
Factory
Proxy
Remote
Proxy
Component
Figure 3: The Enterprise Component Framework.
range of scientific computing applications.
Most commercial component-based frameworks,
such as Sun Microsystems Enterprise JavaBeans or
the Microsoft .NET Common Language Runtime,
are based on a common architectural pattern, known
as the Enterprise Component Framework (Kobryn,
2000). A simplified representation of this pattern is
depicted in Figure 3. This pattern contains six roles,
shown as rectangles in the figure, whose responsibili-
ties can be described as follows:
• Clients are the entities that request services from
a component in the framework. End users, com-
ponent developers, researchers, and other auto-
mated systems may act as clients in TMiner (see
Section 3 for more information on TMiner usage
modes).
• Components provide the services requested by
clients. As mentioned above, both data access
modules and knowledge models are full-fledged
components in TMiner. Data mining algorithms
could also be considered as components on their
own, but they are just used through factory prox-
ies to build knowledge models.
• Proxies relay calls from clients to components.
This level of indirection is hidden from the client
perspective and it makes location transparency
possible (when needed, it also supports message
interception). Factory proxies perform object fac-
tory operations that are common to all frame-
work components (such as creation or retrieval),
while remote proxies handle operations that are
component-specific (e.g. inspection and param-
eter setting). Proxies are usually supported by the
reflection capabilities found in modern computing
platforms.
• The Container represents the framework’s run-
time environment. The container provides dis-
tributed computing services, load balancing, in-
terprocess communication, security, persistence,
resource discovery, and hot deployment mech-
ICSOFT 2008 - International Conference on Software and Data Technologies
100

anisms. Transactions are usually supported by
enterprise frameworks but are not needed in the
TMiner data mining framework. TMiner, how-
ever, needs specific scheduling, monitoring, and
notification mechanisms to manage data mining
tasks.
• Finally, the persistence service, typically man-
aged and coordinated by the container, is used
for the storage and retrieval of framework com-
ponents.
Component-based frameworks are suitable for
large-scale systems because they provide a solid foun-
dation upon which whole applications and product
lines can be deployed in a systematic and controlled
way. The TMiner architecture makes the development
of new techniques and algorithms faster. Once a new
component has been devised and tested in the labo-
ratory, it can be easily deployed into production en-
vironments with the help of a simple component de-
scriptor. This simplifies maintenance and upgrade ef-
forts, hence smoothing the evolution any system must
face during its lifetime.
2.3 TMiner Subsystems
Apart from the common infrastructure needed to build
typical data mining tools, TMiner provides support
for flexible data access and many of the most com-
mon data mining algorithms and techniques:
• The TMiner data access subsystem acts as
its extract, transform, and load (ETL) front-end
and it makes heavy use of well-known object-
oriented design patterns for improving its flexibil-
ity (Gamma et al., 1995).
• The TMiner knowledge-discovery subsystem
provides a wealth of classification models and
clustering techniques, as well as efficient associa-
tion rule mining components and anomaly detec-
tion tools.
3 TMINER USAGE MODES
System usability is critical for user acceptance. Pro-
vided that knowledge workers are not necessarily
knowledgeable about computers, TMiner must pro-
vide different usage modes for different usage scenar-
ios.
TMiner supports the progressive usage model or
triphasic model. This model recognizes that patterns
of usage evolve as users build experience and that sup-
porting these patterns requires specific and somewhat
different facilities within the user interface architec-
ture (Constantine and Lockwood, 1999). TMiner,
therefore, provides different usage modes for novice,
intermediate, and advanced users:
3.1 Basic Usage Modes
Novice users tend to perform basic tasks, with a lim-
ited use of alternatives. The underlying complexity of
the system should be invisible to this kind of users.
TMiner acknowledges this fact and the default values
typically included in a component descriptor let users
employ a data mining component ‘out of the box’.
Beginners usually interact with the system by trial
and error, and they have a strong dependence on
help and guidance. For them, TMiner provides an
attractive Web interface that incorporates novel vi-
sualization techniques in order to motivate explo-
ration, such as VisAR (Techapichetvanich and Datta,
2005). This rule visualization technique is based on
parallel coordinates, a common way of visualizing
high-dimensional geometry and analyzing multivari-
ate data (Inselberg, 1985)
The ability to share data among system users is
another aspect that is closely related to a data mining
system usability. TMiner lets casual system users to
browse through already-discovered models and share
their own models with other system users. This
computer-supported cooperative work (CSCW) fo-
cus is especially relevant in data mining applications,
where the discovered knowledge must be properly
represented and communicated. (Berzal et al., 2003)
3.2 Intermediate Usage Modes
Intermediate TMiner users have expanding needs and
they typically exhibit changing patterns of interac-
tions. “Intermediates (those who are neither begin-
ners nor old hands, and who make up most of the user
population) are perhaps the most neglected user seg-
ment in terms of interface design, yet there are pos-
sibly more intermediate users than beginners or ex-
perts.” (Constantine, 1994)
TMiner component model facilitates the construc-
tion of data mining tools that let knowledgeable users
tune data mining techniques by playing with the
knobs TMiner components provide, i.e. their I/O
ports. Component descriptors are extremely useful
here, since they can be used to automatically gener-
ate the user interface needed for such knob-turning.
NOTES ON THE ARCHITECTURAL DESIGN OF TMINER - Design and Use of a Component-based Data Mining
Framework
101

// Database connection details...
var database = {
driver: "interbase.interclient.Driver",
url: "jdbc:interbase://localhost/datasets.gdb",
user: "SYSDBA",
password: "*****" };
// Dataset...
var id = "CENSUS";
var dataset = new tminer.data.wrapper.jdbc.JDBCDataset
(id, database.user, database.password,
database.url, database.driver);
// Attributes
var discreteAttributes = dataset.getAttributeIDs
(tminer.data.type.StringType);
var continuousAttributes = dataset.getAttributeIDs
(tminer.data.type.NumericType);
Figure 4: TMinerScript code snippet needed to access a par-
ticular dataset through the standard JDBC API.
3.3 Advanced Usage Modes
Expert users’ primary concerns are efficiency and pro-
ductivity. They need to perform complex, sophisti-
cated tasks that are often nonstandard or might be un-
supported. They need interfaces that operate in mul-
tiple modes, frequently changed to fit the particular
demands of the task at hand.
These advanced users can directly use TMiner
components from their own Java code. They can even
customize them by attaching dynamic ports to TMiner
components without having to modify their source
code nor create component subclasses. This can be
helpful when monitoring system performance or ad-
dressing other cross-cutting concerns that appear in
practice. AspectJ, an aspect-oriented extension for the
Java programming language, can also be used with
TMiner components to simplify the implementation
of such cross-cutting concerns.
Sometimes, advanced users prefer faster methods
to interact with TMiner components, without having
to go through a complete edit-compile-build-run cy-
cle each time they want to tweak anything. TMiner-
Script is included in TMiner for such users. TMiner-
Script is a scripting language that can be used to con-
trol TMiner using the syntax of JavaScript (Flanagan,
2006). Scripting languages such as TMinerScript, by
being accessible to the end user, enable the behavior
of an application to be adapted to the user’s specific
needs and thus provide the greatest possible degree of
control to the user. Figures 4 through 6 show some
simple TMinerScript scripts that can be used to per-
form common data mining tasks in TMiner.
...
// Classification model
var classifier = new classification.tdidt.TDIDTClassifier();
classifier.setDefault();
// Classifier parameters (common to all algorithms)
classifier.dataset = dataset; // e.g. JDBC Dataset
classifier.encoder = encoder; // ... to encode input data
classifier.classAttribute = "classLabel";
classifier.discreteAttributes = discreteAttributes;
classifier.continuousAttributes = continuousAttributes;
// Specific parameters (TDIDT algorithm)
classifier.divisionRule = "GainRatio";
classifier.pruning = true;
classifier.pruningCF = 0.25;
classifier.binarySplits = true;
classifier.balanceThreshold = 0.2;
// Classifier construction
classifier.build();
// Output (e.g. in SQL format)
classifier.toSQL("TABLE", "CLASS");
Figure 5: TMinerScript code snippet needed to build a de-
cision tree classifier.
4 CURRENT STATUS AND
FUTURE DIRECTIONS
We have described some of the main features of
TMiner, a component-based data mining framework.
TMiner can be used as a stand-alone web-based
data mining tool, providing components for many
of the tasks we might need to analyze data, ranging
from data access to knowledge discovery. Its current
version lets users build classification models, cluster
data, mine associations, and detect anomalies.
TMiner component model is also suitable for its
integration into larger solutions whose requirements
include some of the data mining features TMiner pro-
vides. In fact, TMiner offers alternative usage modes
intended to facilitate such integration. On the one
hand, it can be directly called from third-party code
as any other component library. On the other hand,
clients can use the scripting facilities TMiner provides
for automating the execution of data mining tasks.
Our current research efforts focus on the develop-
ment of novel data mining techniques (e.g. dealing
with different kinds of data sources) as well as on the
improvement of current data mining solutions by pro-
viding a scalable data mining system for scientific and
business applications.
ICSOFT 2008 - International Conference on Software and Data Technologies
102

...
// Algorithm details
var algorithm
= "tminer.kdd.classification.tdidt.TDIDTClassifier";
var parameters = new tminer.model.adt.Dictionary();
parameters.add("divisionRule", "GainRatio");
parameters.add("binarySplits", true); parameters.add("pruning",
true); parameters.add("pruningCF", 0.25);
// Cross-validation experiment
var experiment = new classification.CrossValidation();
experiment.type = algorithm;
experiment.parameters = parameters;
experiment.partitions = 10;
experiment.dataset = dataset;
experiment.encoder = encoder;
experiment.classAttribute = "classLabel";
experiment.discrete = discreteAttributes;
experiment.continuous = continuousAttributes;
experiment.run();
// Experiment results
experiment;
Figure 6: TMinerScript code snippet needed to run a cross-
validation experiment.
ACKNOWLEDGEMENTS
Work partially supported by research project
TIN2006-07262.
REFERENCES
Berzal, F., Blanco, I., Cubero, J. C., and Mar
´
ın, N. (2002).
Component-based data mining frameworks. Commu-
nications of the ACM, 45(12):97–100.
Berzal, F., Cubero, J. C., Mar
´
ın, N., Serrano, J.-M., and
Blanco, I. (2003). Usability issues in data mining sys-
tems. In ICEIS 2003: Proceedings of the 5th Interna-
tional Conference on Enterprise Information Systems
(Volume II - Artificial Intelligence and Decision Sup-
port Systems), pages 418–421.
Chaudhuri, S. and Dayal, U. (1997). An overview of
data warehousing and OLAP technology. SIGMOD
Record, 26(1):65–74.
Constantine, L. L. (1994). Interfaces for intermediates.
IEEE Software, 11(4):96–99.
Constantine, L. L. and Lockwood, L. A. D. (1999). Soft-
ware for Use: A practical guide to the models and
methods of usage-centered design. ACM Press /
Addison-Wesley.
Etienne, J., Wachmann, B., and Zhang, L. (2006). A
component-based framework for knowledge discov-
ery in bioinformatics. In KDD ’06: Proceedings of
the 12th ACM SIGKDD international conference on
Knowledge discovery and data mining, pages 916–
921.
Fayad, M. E. and Schmidt, D. C. (1997). Object-oriented
application frameworks. Communications of the
ACM, 40(10):32–38.
Flanagan, D. (2006). JavaScript: The Definitive Guide.
O’Reilly & Associates, Inc., Sebastopol, CA, USA.
Gamma, E., Helm, R., Johnson, R., and Vlissides, J. (1995).
Design Patterns: Elements of reusable object-oriented
software. Addison-Wesley.
Han, J. and Kamber, M. (2006). Data Mining: Concepts
and Techniques. Morgan Kaufmann.
Inselberg, A. (1985). The plane with parallel coordinates.
The Visual Computer, 1(2):69–91.
Kimball, R. and Ross, M. (2002). The Data Warehouse
Toolkit: The Complete Guide to Dimensional Model-
ing. John Wiley & Sons, Inc.
Kobryn, C. (2000). Modeling components and frameworks
with UML. Communications of the ACM, 43(10):31–
38.
Larsen, G. (2000). Component-based enterprise frame-
works. Communications of the ACM, 43(10):24–26.
Laurinen, P., Tuovinen, L., and Roning, J. (2005). Smart
archive: A component-based data mining application
framework. In ISDA’05: Proceedings of the 5th In-
ternational Conference on Intelligent Systems Design
and Applications, pages 20–25.
Perry, D. E. and Kaiser, G. E. (1991). Models of soft-
ware development environments. IEEE Transactions
on Software Engineering, 17(3):283–295.
Prudsys (2008). XELOPES library - eXtEnded
Library fOr Prudsys Embedded Solutions.
http://www.prudsys.com/.
Rapid-I (2008). RapidMiner (formerly YALE, Yet Another
Learning Environment). http://rapid-i.com/.
Szyperski, C., Gruntz, D., and Murer, S. (2002). Com-
ponent Software: Beyond Object-Oriented Program-
ming. Addison-Wesley.
Tan, P.-N., Steinbach, M., and Kumar, V. (2006). Introduc-
tion to Data Mining. Addison-Wesley.
Techapichetvanich, K. and Datta, A. (2005). VisAR: A
new technique for visualizing mined association rules.
In ADMA 2005: 1st International Conference on Ad-
vanced Data Mining and Applications, LNCS 3584,
pages 88–95.
Widom, J. (1995). Research problems in data warehousing.
In CIKM ’95, Proceedings of the 1995 International
Conference on Information and Knowledge Manage-
ment, November 28 - December 2, 1995, Baltimore,
Maryland, USA, pages 25–30. ACM.
Witten, I. H. and Frank, E. (2005). Data Mining: Practi-
cal machine learning tools and techniques. Morgan
Kaufmann.
NOTES ON THE ARCHITECTURAL DESIGN OF TMINER - Design and Use of a Component-based Data Mining
Framework
103
