TOWARDS COMPACT OPERATOR TREES FOR QUERY INDEXING
Hagen H¨opfner
School of Information Technology, International University in Germany, Campus 3, 76646 Bruchsal, Germany
Erik Buchmann
Institute for Program Structures and Data Organization, Universit¨at Karlsruhe (TH), Germany
Keywords:
Databases, Query Indexes, Query Semantics.
Abstract:
Application areas like semantic caches or update relevancy checks require query based indexing: They use
an algebra representation of the query tree to identify reusable fragments of former query results. This re-
quires compact query representations, where semantically equivalent (sub-)queries are expressed with iden-
tical terms. It is challenging to obtain such query representations: Attributes and relations can be renamed,
there are numerous ways to formulate equivalent selection predicates, and query languages like SQL allow a
wide range of alternatives for joins and nested queries. In this paper we present our first steps towards op-
timizing SQL-based query trees for indexing. In particular, we use both existing equivalence rules and new
transformations to normalize the sub-tree structure of query trees. We optimize selection and join predicates,
and we present an approach to obtain generic names for attributes and table aliases. Finally, we discuss the
benefits and limitations of our intermediate results and give directions for future research.
1 INTRODUCTION
Nowadays ubiquitous, nomadic, and pervasive com-
puting are not longer visions but realized in vari-
ous scenarios. Devices become smaller and easier
to carry around and wireless links connect to world
wide available information anytime and everywhere.
Due to slow, unreliable and/or energy-intensive wire-
less networks, efficient strategies to retrieve and cache
data from central servers on mobile devices are key
for almost all mobile applications. Related techniques
include hoarding (Kuenning and Popek, 1997), repli-
cation (Gray et al., 1996) or semantic caching (Lee
et al., 1999). For example, semantic caching mate-
rializes query results at the mobile devices and reuse
them for future queries, i.e., the queries are used for
indexing the cached data. Therefore, it is necessary
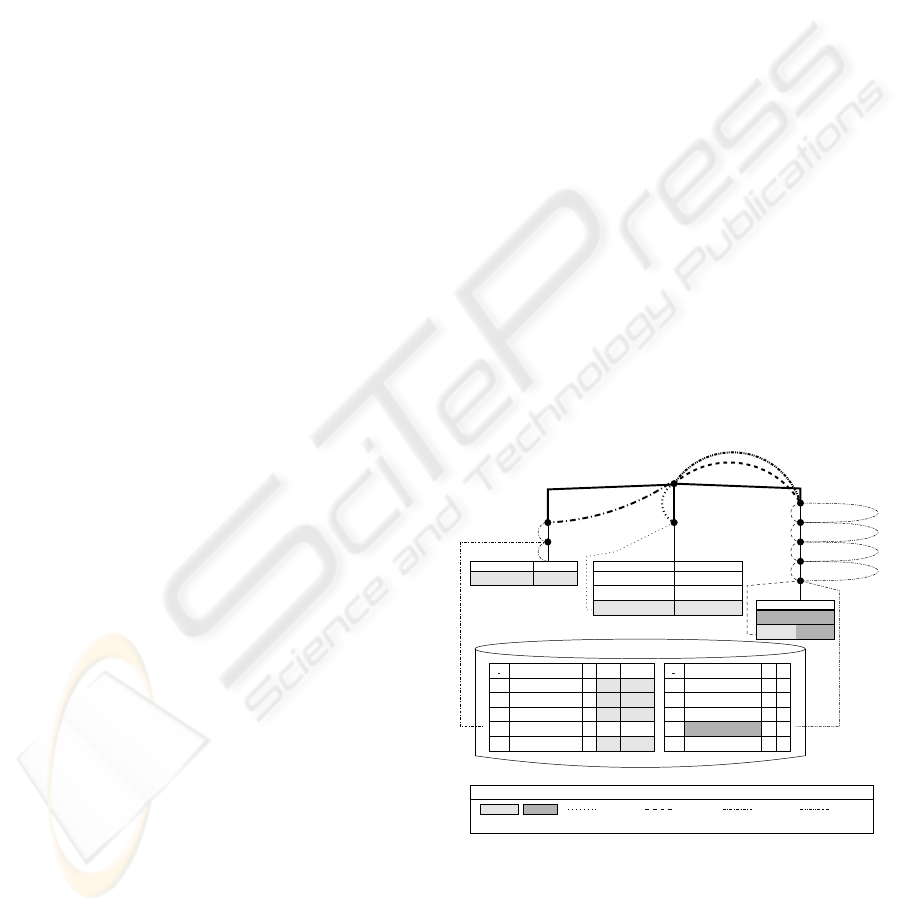
to find out if (sub-)queries overlap. Figure 1 illus-
trates this idea. The results of three queries X
1
, X
2
,
and X
3
were cached and can be reused for answering
the new queries X
4
, X
5
, X
6
, and X
7
. Queries are repre-
sented in form of conjunctively linked operator trees.
Hence, the re-usability of the cached data can be ana-
lyzed by traversing the tree (illustrated by dashed and
dotted lines in Figure 1). More details can be seen in
caption
result of the query
new query X
4
new query X
5
new query X
6
new query X
7
X
4
, X
5
, X
6
X
7
s
id
namename
type
phone
address
b
id
x
y
schools(address, phone)
buildings(name)
buildings.x>200
buildings.x<8000
buildings.y>1000
buildings.y<3000
schools.name=’ECOLE’
filter(X
1
, X
4
)
fi
lter(X
3
, X
5
)
hospitals(address,name)
.. .
.. . .. .
.. ... .
.. . . ..
.. .
.. . . ..
.. ... ... .
.. .
.. .
.. .
.. .
.. .
.. ... .
.. .
.. .
.. .
.. .
.. .
.. .
.. .
.. .
.. .
compensate(X
3
, X
7
)
c
ompensate(X
2
, X
6
)
Ada Lovelace School Ada Lovelace School
Ada Lovelace School
1st Primary School1st Primary School
1st Primary School
Ascaneum
ECOLE
Gustav-Nitsche School
St. Maria Hospital
St. Maria Hospital
University Hospital
Dr. Koch Hospital
P.O. Box 1100
18 Avenue of The Stars
5 Third Avenue
45 Church Place
445613334
1 1
2 2
3
4
5
6
Figure 1: Query index of a semantic cache (H¨opfner and
Sattler, 2003).
(H¨opfner and Sattler, 2003).
It is challenging to realize query indexing on the
basis of current SQL-based DBMS. SQL allows to
formulate semantically equivalent queries in syntac-
tically different ways. Even the straightforward Ex-
174
Höpfner H. and Buchmann E. (2008).
TOWARDS COMPACT OPERATOR TREES FOR QUERY INDEXING.
In Proceedings of the Third International Conference on Software and Data Technologies - ISDM/ABF, pages 174-179
DOI: 10.5220/0001888001740179
Copyright
c
SciTePress

ample 1 might result in two different representations
for the equivalent queries Q
1
and Q
2
. Furthermore,
current DBMS transform queries solely according to
the execution time. In contrast, semantic caches re-
quire
• minimal query representations that do not exhaust
the resources of mobile devices,
• identical representations of semantically equiva-
lent sub-trees in the query tree, and
• representations without contradictory renaming
operationsthat complicate the detection of seman-
tically overlapping (sub-)queries.
Example 1: Semantically but not syntactically equivalent
Q
1
:
SELECT * FROM TABLE1 AS T1
WHERE B=5 AND A=4
Q
2
:
SELECT * FROM (SELECT * FROM TABLE1
WHERE A=4 and B=5) AS T1
In this paper, we describe our first steps towards
transforming SQL into a compact query representa-
tion that is optimized for indexing purposes. There-
fore, we use existing equivalence transformations,
and we devise new transformations that adapt syntac-
tical properties of queries. This comprises:
1. We introduce rules to reduce the complexity of
query trees. Our rules utilize overwriting effects
and interdependencies between operators to re-
move or merge certain operations.
2. We rewrite logical expressions to represent se-
mantically equivalent terms as similar as possible
while considering existing decision problems.
3. We normalize the aliases in the query tree to
obtain identical representations for (sub-)queries
that are semantically equivalent but contain dif-
ferent renaming operations.
Paper Structure. Section 2 defines query trees and
specifies the set of operators that we support at the
moment. Section 3 discusses our approach to unify
the query representation, and Section 4 concludes.
2 QUERIES AND QUERY TREES
In this paper we focus on transforming SQL queries
for indexing purposes. As a starting point we as-
sume that the the SQL query has been translated into
a canonical query tree of relational algebra operators.
We focus on a relational complete set of algebra op-
erators (Elmasri and Navathe, 2007) consisting of se-
lection σ, projection π, set union ∪, set difference −,
and Cartesian product ×. In addition, we consider re-
naming of attributes, renaming of relations ρ and set
intersection ∩. Operators like aggregations or group-
ings will be part of our future work.
In order to meet the SQL semantics, we distin-
guish between set and multi-set operators. It is well-
known that multi-set relational algebras have nearly
the same properties as set based approaches. Thus,
we briefly introduce our notation and refer to liter-
ature (Dayal et al., 1982; Grefen and de By, 1994)
for further reading on relational algebra semantics.
A multi-set projection (
SELECT
) is denoted with an
enhanced relational projection operator π
a
, while the
projection operator π corresponds to the set seman-
tics (
SELECT DISTINCT
). We ease our presentation
by supposing that each query contains one projec-
tion operator π or π
a
. We implicitly assume multi-
set semantics for the Cartesian product, the set opera-
tors and the selection operator. If necessary, duplicate
elimination can be done by the projection operator π.
Assuming that the “*” means all attributes of relations
used by a query, translating the two SQL queries from
Example 1 could result in the relation algebra ex-
pression Q
1
= π
a
∗
(ρ
T1
(σ
B=5∧A=4
(
TABLE1
))) and Q
2
=
π
a
∗
(ρ
T1
(π
a
∗
(σ
A=4∧B=5
(
TABLE1
)))). Formally, a query
q can have the following recursive structure:
q : {π|π
a
}([σ]([ρ](R)))
q : {π|π
a
}([σ](ρ(q)))
q : {π|π
a
}([σ](cp))
cp : {[ρ](R)|ρ(q)} × {[ρ](S)|ρ(q)|cp}
q : {π|π
a
}(q{∪| − |∩}q)
Operators in square brackets encapsulate optional
operators. R and S are relations, and braces
mark alternatives. This structure spans a query
tree where leafs represent the relations and inner
nodes store query operators. The query tree is
processed by starting on the leaves and follow-
ing the edges of the tree. After performing the
operation in the root, the query is completely
answered. Sub-queries are boxed, i.e., they form self-
contained queries that are sub-trees of the query tree.
Example 2:
Q
3
:
SELECT DISTINCT B FROM TABLE1, TABLE2
WHERE TABLE2.B>TABLE1.A
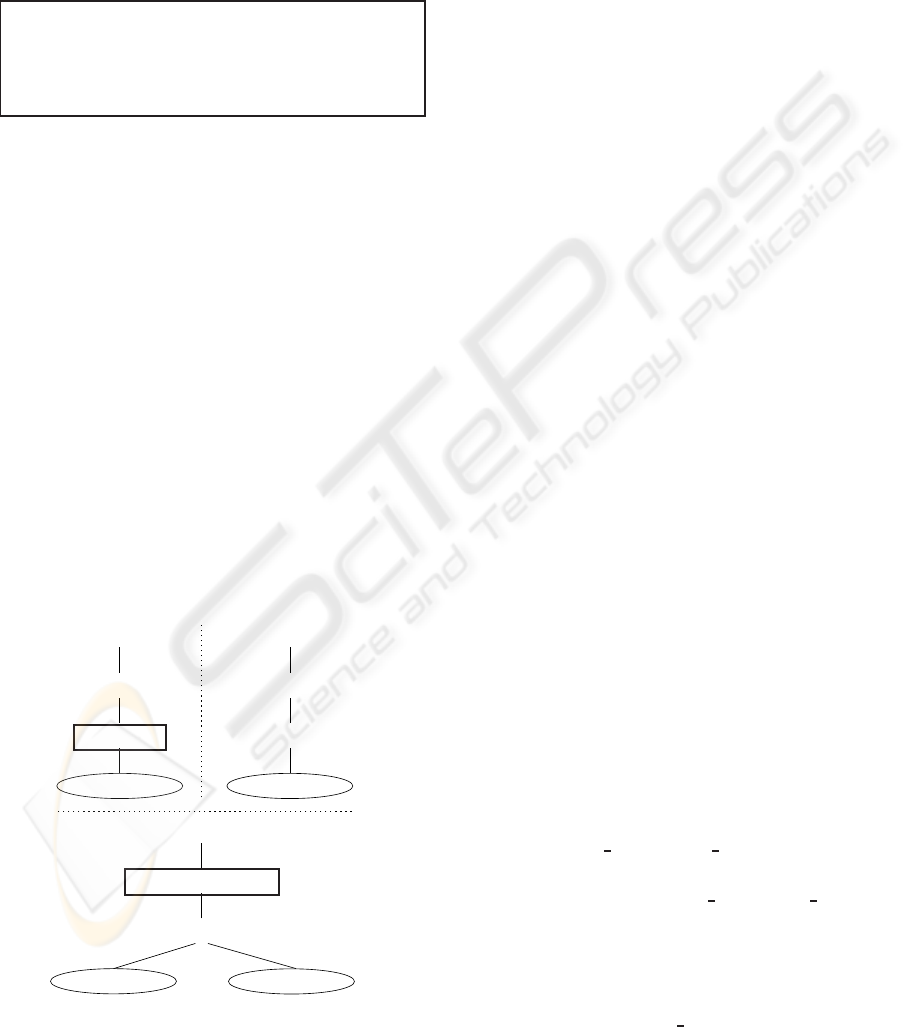
Figure 2 shows the query trees for the queries Q
1
,
Q
2
and Q
3
, which will be used as examples through-
out the paper. Operators of the sub-query in Q
2
are
highlighted by a gray box. The algebraic expression
of Q
3
is π
a
B
(σ
TABLE2
.B>
TABLE1
.A
(
TABLE1
×
TABLE2
)).
We start our transformations with the canonical
TOWARDS COMPACT OPERATOR TREES FOR QUERY INDEXING
175
TABLE1
TABLE1
TABLE1
TABLE2
sub-tree for the sub-query
π
a
∗
σ
B=5∧A=4
ρ
T1
π
a
∗
π
a
∗
ρ
T1
σ
A=4∧B=5
×
σ
TABLE2
.B>
TABLE1
.A
π
a
B
Figure 2: Query trees for the example queries (Q
1
left, Q
2
middle, Q
3
right).
query tree (Elmasri and Navathe, 2007). Thus, the
query tree is normalized so that a projection consti-
tutes the root of each (sub-)query, followed by an op-
tional selection, an optional renaming operation, and
either a Cartesian product, a relation name or another
boxed sub-query. Note that sub-queries in SQL must
have an unique name, i.e., if a query contains a sub-
query then the renaming operator of the including
(outer) query becomes mandatory.
3 COMPLEXITY REDUCING
QUERY REWRITING
In this section we describe our approach towards
less complex query representations for query index-
ing. We introduce three steps to rewrite the canoni-
cal query tree: (1) The removal of unnecessary sub-
trees, (2) the equivalence transformation of predicate
expressions and (3) a normalization of renaming oper-
ations. These steps can be implemented in the seman-
tic cache on the mobile client, on a mobility support-
ing middle-ware (H¨opfner, 2007), or in the back-end.
3.1 Sub-Tree Optimization
As Figure 2 shows, queries with a different sub-tree
structure can have the same semantics. In order to
assign equivalent queries with the same entry in a se-
mantic cache, the sub-tree structure has to be normal-
ized. Therefore, we reduce the number of unneces-
sary sub-trees in our first rewriting step. The result-
ing query is semantically equivalent to the initial one.
Since this paper describes our ongoing work, there
are still cases where two different but semantically
equivalent queriesresult in different representation af-
ter normalization. Thus, there is high potential for
future research. Different sub-trees can handle dupli-
cates differently. For this reason, we have to consider
duplicate elimination first.
π
a
-π-Optimization. Observe that duplicate elimi-
nation at the (sub-)root node of a certain sub-tree
implicitly holds for all of it’s sub-trees, too. In
other words, all sub-queries of a
SELECT DISTINCT
-
query can be written as
SELECT DISTINCT
-sub-
queries. The proof (Gupta et al., 1995) of this
observation is that
SELECT DISTINCT
D
FROM
R ≡
SELECT
D
FROM
R
GROUP BY
D, while groupings
can be pushed down and pulled up under certain con-
ditions. Hence, we traverse the query tree and replace
all duplicate preserving projections π
a
below a dupli-
cate eliminating π-operator by π. Note that this pa-
per leaves aside aggregations. Since the correctness
of some aggregates depend on duplicates, such oper-
ations constitute exceptions for this step.
Sub-Queries without Set Operations and Carte-
sian Products. Nested sub-queries of the form Q :
Q
out
(Q
in
1
(Q
in
2
. . . (Q
inmost
))) can be reduced if the in-
ner queries contain neither set-operations nor Carte-
sian products. Following the formal query represen-
tation in Section 2, the inmost sub-query Q
inmost
must
have the following structure:
Q
inmost
: {π|π
a
}([σ]([ρ](R))).
The handling of duplicates in nested sub-querieswith-
out Cartesian products is comparable to our π
a
-π-
optimization: the projections in all sub-queries Q
∗
can
be unified to π if at least one sub-query removes du-
plicates. Otherwise, all projections in Q
∗
are π
a
. For
simplification purposes we consider π only. The same
transformations can be applied for π
a
.
Remember that SQL requires the renaming of sub-
queries. As shown in Section 2 the inmost operator of
the outer query has to be a ρ. In our canonical query
tree structure, ρ is the parent of the projection node of
an inner sub-query. Our sub-tree optimization starts
at the inmost nested sub-query and is used bottom-up
until a set operation, a Cartesian product or the root-
node is reached. We combine a boxed sub-query with
its nesting query by merging the projections and se-
ICSOFT 2008 - International Conference on Software and Data Technologies
176

lection predicates, and by unifying all relation names
and attribute names which have been renamed in the
nesting query. Therefore, we distinguish two cases:
Case 1. Outer (sub-)query uses projection and re-
naming:
π
pl
o
(ρ
al
o
| {z }
outer sub-query
(Q
inmost
))
π
pl
o
overwrites the projection of the inner query but is
based on the renaming ρ
al
o
. Furthermore, ρ
al
o
over-
writes a potential renaming within Q
inmost
. So, both
queries are merged as follows:
1. Remove the projection of the inner query if it it
covers more attributes than the projection of the
outer query. Otherwise, replace the outer projec-
tion by the inner one.
2. If the inner query does neither contain a renaming
nor a selection, both queries have been merged:
Stop rewriting.
3. If the inner query contains a selection σ
sc
i
, change
the order of σ
sc
i
and ρ
al
o
.
If the inner query contains a renaming ρ
al
i
(R),
merge the set of aliases in the inner (al
i
=
RA
i
(AA
i
)) and outer (al
o
= RA
o
(AA
o
)) query, i.e.,
(a) Merge and reduce the attribute-name-aliases
set: AA
m
= reduce(AA
i
∪ AA
o
).
(b) For all relations in nested renaming sequences
R → RA
i
→ RA
o
: Replace ρ
al
i
(R) by ρ
al
m
(R)
where al
m
= RA
o
(AA
m
).
(c) For all inner attribute aliases al
i
← a with a ∈
R and al
i
∈ AA
i
that are overwritten by the outer
renaming al
o
← al
i
, al
o
∈ AA
o
: Replace al
i
←
a by al
o
← a.
(d) Remove al
o
← al
i
from AA
i
∪ AA
o
.
(e) Replace the outer renaming ρ
al
o
by the
merged renaming ρ
al
m
, and remove ρ
al
i
.
4. If the inner query contains a selection σ
sc
i
, adapt
the selection conditions sc
i
to the new aliases, i.e.,
(a) Replace all relation names of R and RA
i
in sc
i
by RA
o
.
(b) Replace an attribute name a in sc
i
by al
with al ← a ∈ AA
m
, if it has been renamed by
ρ
RA
m
(AA
m
)
.
Note that Step 3 is not an equivalence transforma-
tion, because ρ
al
o
might rename attributes or relations
needed for σ
sc
i
. Step 4 corrects this. Method reduce
replaces transitive aliases similar to the table aliases.
Case 2. Outer (sub-)query uses projection, selection
and renaming:
π
pl
o
(σ
sc
o
(ρ
al
o
| {z }
outer sub-query
(Q
inmost
)))
The difference to Case 1 is that the outer selection
σ
sc
o
and the inner selection σ
sc
i
have to be merged
after the other steps. Therefore, σ
sc
i
is removed from
from the sub-tree and and σ
sc
o
is replaced by a new
selection σ
sc
m
where sc
m
= sc
o
∧ sc
i
holds.
Example 3: Sub-query optimization
The initial tree representation of Q
2
is
π
a
∗
− ρ
T1
− π
a
∗
− σ
A=4∧B=5
−
TABLE1
In the first step the outer projection is replaced by
the inner one. The resulting tree is:
π
a
∗
− ρ
T1
− σ
A=4∧B=5
−
TABLE1
The remaining inner sub-query contains a selection.
Therefore, we have to continue with step 3. The
result of step 3 is:
π
a
∗
− σ
A=4∧B=5
− ρ
T1
−
TABLE1
Since the inner sub-query does not contain a re-
naming, ρ
T1
becomes the final renaming operator.
σ
A=4∧B=5
does not use the renamed relation name
and the attributes were not renamed. Therefore, the
select condition does not have to be changed.
3.2 Where-Condition Optimization
Our second optimization targets at selection and join
predicates. As semantically equivalent predicates can
be expressed in numerous ways, the usage of query
representations for indexing calls for normalization of
predicates. The equivalency problem of logical ex-
pressions is undecidable in the general case. How-
ever, when considering SQL, where-conditions are
first-order predicate logic expressions which do not
contain quantifiers and correspond to propositional
logic expressions. Thus, we can conduct a large num-
ber of equivalence transformations on such expres-
sions. We optimize the predicates in two phases:
Phase 1: Lexicographical Sorting. One difference
between two predicates can result from the order
of conjuncts. For example, the where-conditions
of Q
1
: B = 5∧ A = 4 and Q
2
: A = 4 ∧ B = 5 are
equivalent. Thus, the first phase orders the conjuncts
lexicographically. The following rules hold:
TOWARDS COMPACT OPERATOR TREES FOR QUERY INDEXING
177
B < A ≡ A > B B > A ≡ A < B
B ≤ A ≡ A ≤ B B ≥ A ≡ A ≤ B
B = A ≡ A = B B 6= A ≡ A 6= B
In particular, we rewrite all attribute-attribute-
comparisons (AAC) so that the first attribute is lex-
icographically smaller than the second one.
Example 4: Ordering of conjuncts
Given the AAC
TABLE2.B
>
TABLE1.A
of Q
3
we
force a lexicographic order by exchanging the at-
tributes and substituting the comparison operator.
The result is
TABLE1.A
<
TABLE2.B
.
Phase 2: Term Minimization. In the second phase
we analyze the attribute-value-comparisons (AVC).
AVCs might form an unnecessarily complex propo-
sitional logic expression. There exist algorithms for
transforming an arbitrary logical expression to a con-
junctive normal form (Russell and Norvig, 2002)
and to minimize this expression (Quine, 1952; Kar-
naugh, 1953; McCluskey, 1956; Biswas, 1984). How-
ever, all those algorithms find one minimal expres-
sion, but cannot exclude that there are other mini-
mal expressions as well. Hence, it cannot be guar-
anteed that equivalent expressions are reduced to the
same minimal expression. However, for the time be-
ing we take the algorithmically found term and order
it lexicographically. More specifically, we represent
each where-condition in a minimal conjunctive nor-
mal form where the atomic terms of each conjunct
are ordered lexicographically. After ordering the con-
juncts, we order the entire expression. The resulting
example query trees are shown in Figure 3.
TABLE1
TABLE1
TABLE1
TABLE2
π
a
∗
ρ
T1
σ
A=4∧B=5
π
a
∗
ρ
T1
σ
A=4∧B=5
×
σ
TABLE1
.A<
TABLE2
.B
π
a
B
Figure 3: Query trees for the example queries (Q
1
top left,
Q
2
top right, Q
3
bottom) after the where-condition opti-
mization.
3.3 Harmonizing Aliases
SQL queries can specify aliases for tables, views,
attributes etc. Since SQL allows many kinds of
nested queries, the SQL parser automatically inserts
renaming operations into query trees, too. However,
renamed attributes or relations can result in differ-
ent representations of semantically equivalent (sub-
)queries. Thus, it is important to normalize names in
query trees. Therefore, we replace aliases by generic
names. This requires:
P1 The alias substitution must be deterministic.
P2 The aliases must not be identifiers in used in the
base relations.
P3 The mapping must be isomorphic and complete.
When leaving aside SQL view definitions, the
deepest alias in a query tree always renames the orig-
inal relation; the second alias renames the first alias,
etc. Thus, we can guarantee a deterministic substitu-
tion (P1) by using the md5-Algorithm (Rivest, 1992)
on the renamed table/alias to compute generic names.
A sequence of renaming operations table→alias
1
→
··· →alias
n
is substituted by table→md5(table)→
··· →md5(. ..md5(table)). In order to avoid valid
SQL table names (P2), we propose to use special pre-
fix characters in aliases that are not allowed in SQL
names, such as “@”. An isomorphic and complete
mapping (P3) can be ensured by traversing the whole
query tree in a defined order. To distinguish base re-
lations used more than once in a query (e.g. in case of
self-joins), we maintain a counter table CT that stores
whether and how often a base relation is used. The
following algorithm does this for table aliases:
1. Traverse the query tree in a post-order manner.
2. For each renaming operation at each node,
(a) if its a renaming of a base relation
i. if base relations name is in the CT then in-
crease and fetch its counter c
ii. else insert the base relations name into CT
and set its counter c to 1
(b) substitute source→alias by
source→@
md5(source) c, and
(c) replace all appearances of alias as table alias
in all parent nodes by @ md5(target) c.
The same algorithm can be applied for attribute
aliases. However, attribute aliases and table aliases
must not be mixed, e.g., by using differentprefix char-
acters. Table aliases can appear in other renaming op-
eration or as prefix
TABLE ALIAS.ATTRIBUTE
of at-
tributesin selections and projections. Attributealiases
might also appear in further renaming operations or
ICSOFT 2008 - International Conference on Software and Data Technologies
178

as suffix of attribute names. Example 5 illustrates the
harmonizing of aliases.
Example 5: Alias harmonization
Before performing the alias harmonization, the
query trees of Q
2
and Q
4
are:
Q
2
: π
a
∗
− σ
A=4∧B=5
− ρ
T1
−
TABLE1
Q
4
: π
a
∗
− σ
A=4∧B=5
− ρ
T2
−
TABLE1
Both queries contain only one renaming opera-
tion each (Q
2
:
TABLE1
→
T1
, Q
2
:
TABLE1
→
T2
).
They rename
TABLE1
but do not use the alias in
any other operation. The md5-hash of
TABLE1
is
d20a1138c815109c831e910488ebf146. Hence, the
modified trees are:
Q
2
: π
a
∗
− σ
A=4∧B=5
− ρ
@ d20a...bf146
1
−
TABLE1
Q
4
: π
a
∗
− σ
A=4∧B=5
− ρ
@ d20a...bf146
1
−
TABLE1
Q
2
and Q
4
are now syntactically equivalent.
4 SUMMARY AND OUTLOOK
Due to the increasing complexity of mobile applica-
tions, query indexing is an emerging topic in research
and practice. In this paper we presented first ideas
towards finding a compact representation of semanti-
cally equivalent database queries. Our approach re-
duces the syntactical complexity of database queries
(1) by applying well known and proofed transfor-
mation rules, (2) by forcing an order within logi-
cal expressions, and (3) by normalizing the names
of attributes and relations. All algorithms are of
a deterministic nature, except the optimization of
the where-condition. For this reason, we can not
guarantee to transform all semantically equivalent
queries to the same index entry. This might re-
sult in some duplicates in the query index, which
might be acceptable for semantic caching and many
other application areas. Thus, we can already de-
clare success if we find rules that are applicable
to the majority of real-world queries. As part of
our ongoing research we plan to address further
cases of semantic equivalence. Examples include
self-joins like
SELECT * FROM T1 AS A, T2 AS B
WHERE A.a = B.b
and
SELECT * FROM T1 AS B,
T2 AS A WHERE A.a = B.b
. Both are equivalent
but represented in a different way. A solution could be
to order the From-list lexicographically. Furthermore,
we intend to evaluate our approach by implementing
a prototype that can be tested with well-known query
mixes, e.g., the TCP-H benchmark.
REFERENCES
Biswas, N. N. (1984). Computer aided minimization proce-
dure for boolean functions. In Proceedings of the 21st
conference on Design automation.
Dayal, U., Goodman, N., and Katz, R. H. (1982). An ex-
tended relational algebra with control over duplicate
elimination. In Proceedings of the SIGACT-SIGMOD
Symposium on Principles of Database Systems.
Elmasri, R. and Navathe, S. B. (2007). Fundamentals of
Database Systems. Addison Wesley.
Gray, J., Helland, P., O’Neil, P., and Shasha, D. (1996).
The Dangers of Replication and a Solution. SIGMOD
Record, 25(2):173–182.
Grefen, P. W. and de By, R. A. (1994). A multi-set extended
relational algebra: a formal approach to apractical is-
sue. In Proceedings of the 10th ICDE.
Gupta, A., Harinarayan, V., and Quass, D. (1995).
Aggregate-Query Processing in Data Warehousing
Environments. In Proceedings of the 21st VLDB.
H¨opfner, H. (2007). Query Based Client Indexing in
Client/Server Information Systems. Journal of Com-
puter Science, 3(10):773–779.
H¨opfner, H. and Sattler, K.-U. (2003). Towards Trie-Based
Query Caching in Mobile DBS. In Proceedings of
the Workshop Scalability, Persistence, Transactions -
Database Mechanisms for Mobile Applications.
Karnaugh, M. (1953). The Map Method for Synthesis of
Combinational Logic Circuits. Transactions of Amer-
ican Institute of Electrical Engineers, 72(7):593–599.
Kuenning, G. H. and Popek, G. J. (1997). Automated
Hoarding for Mobile Computers. ACM SIGOPS Op-
erating Systems Review, 31(5):264–275.
Lee, K. C. K., Leong, H. V., and Si, A. (1999). Semantic
query caching in a mobile environment. ACM SIG-
MOBILE Mobile Computing and Communications
Review, 3(2):28–36.
McCluskey, E. J. (1956). Minimization of Boolean Func-
tions. Bell System Techical Journal, 35(5):1417–1444.
Quine, W. V. O. (1952). The problem of Simplifying
Truth functions. American Mathematics Monthly,
59(8):521–531.
Rivest, R. L. (1992). The MD5 Message-Digest Algo-
rithm. Informational Errata.
http://tools.ietf.
org/html/rfc1321
.
Russell, S. J. and Norvig, P. (2002). Artificial Intelligence:
A Modern Approach.
TOWARDS COMPACT OPERATOR TREES FOR QUERY INDEXING
179
