
TRAINING BELIEVABLE AGENTS IN 3D ELECTRONIC BUSINESS
ENVIRONMENTS USING RECURSIVE-ARC GRAPHS
Anton Bogdanovych, Simeon Simoff
School of Computing and Mathematics, University of Western Sydney, NSW, Australia
Marc Esteva
Artificial Intelligence Research Institute (IIIA-CSIC), Campus UAB, Barcelona, Catalonia, Spain
Keywords:
Autonomous Agents, Virtual Institutions, Implicit Training, Recursive-Arc Graphs.
Abstract:
Using 3D Virtual Worlds for commercial activities on the Web and the development of human-like sales as-
sistants operating in such environments are ongoing trends of E-Commerce. The majority of the existing
approaches oriented towards the development of such assistants are agent-based and are focused on explicit
programming of the agents’ decision making apparatus. While effective in some very specific situations, these
approaches often restrict agents’ capabilities to adapt to the changes in the environment and learn new behav-
iors. In this paper we propose an implicit training method that can address the aforementioned drawbacks.
In this method we formalize the virtual environment using Electronic Institutions and make the agent use
these formalizations for observing a human principle and learning believable behaviors from the human. The
training of the agent can be conducted implicitly using the specific data structures called recursive-arc graphs.
1 INTRODUCTION
Electronic marketplace is a space populated by com-
puterised players that represent the variety of human
and software traders, intermediaries, and information
or infrastructure providers. Believable marketplaces
are perceived as “marketplaces where people are”, as
“marketplaces that are alive and engaging”. The ma-
jority of present electronic markets are focused on the
backend transaction processing and catalogue-style
interaction, and do not provide such perceptions.
Overall, the believability of a marketplace de-
pends on the believability of the presence and inter-
actions in it, including the players’ behaviour and
the narrative scenarios of the marketplace. A high
degree of believability of the presence and interac-
tions in an electronic marketplace can be achieved
through its visualization as a 3D Virtual World (Bog-
danovych, 2007). However, the believability of the
players in this case becomes a serious concern, in par-
ticular when the marketplace accepts computerized
autonomous agents as active participants.
The creation of such believable computerized
agents, known as virtual humans, is an active area of
computer science research, which attempts to model
the full richness of human-like interactions including
natural language communication, gestures, emotional
expression, as well as the cognitive apparatus that un-
derlies these capabilities (Huang et al., 2007). Most
virtual human research has focused on the cognitive
behaviour on the source side of the interaction (Rist
et al., 2003), (Tomlinson et al., 2006) with a recent
shift towards the ”recipient” (Maatman et al., 2005).
The research in building models of different fea-
tures that contribute to the believability of virtual hu-
mans (i.e. personality, social role awareness, self-
motivation, illusion of life, etc.) utilizes contempo-
rary developments in cognitive modeling (Prendinger
and Ishizuka, 2001) and attempts to formalise those
models in computational forms in order to implement
them in virtual environments, in particular, in virtual
worlds (Magnenat-Thalmann et al., 2005). As the
complexity of such models increases, the complexity
of their implementation increases too. However, pass-
ing the Turing test (different adaptations of which re-
main the only known research method for believabil-
ity assessment) is still on the list of developers’ goals
(Livingstone, 2006).
In our research on believable electronic markets,
we look at personalising the believability features,
339
Bogdanovych A., Simoff S. and Esteva M. (2008).
TRAINING BELIEVABLE AGENTS IN 3D ELECTRONIC BUSINESS ENVIRONMENTS USING RECURSIVE-ARC GRAPHS.
In Proceedings of the Third International Conference on Software and Data Technologies - PL/DPS/KE, pages 339-346
DOI: 10.5220/0001901103390346
Copyright
c
SciTePress

adapting them towards the interacting player. In this
sense believable does not necessarily mean realistic.
We take a view of believability as providing an ”antic-
ipatory” feature of the technology (Pantic et al., 2006)
underlying electronic markets, i. e. we are looking for
(i) components of human behaviour that can be inte-
grated in electronic markets and (ii) the interpretation
of such components by the environment.
1.1 Learning Believable Behaviour
When the goal is to personalize the believability fea-
tures, instead of trying to discover and explicitly pro-
gram various believability characteristics some re-
searchers rely on the simulation theory. The key hy-
pothesis behind this theory can be best summarized
by the clich
´
e “to know a man is to walk a mile in his
shoes” (Breazeal, 1999). It is assumed that simulation
and imitation are the key technologies for achieving
believability. In particular, using these techniques to
produce more human-like behavior is quite popular in
cognitive systems research (Schaal, 1999).
The motivation for scholars to rely on the simula-
tion theory comes from observing human beings. Al-
most everything that constitutes humans’ personality
had to be learned at some point of their lives. The
newborns are initially supplied with some very basic
knowledge (reflexes) and have no knowledge about
how to walk, how to talk or how to behave in public.
All these behaviors are learned from observing and
simulating other humans (Bauckhage et al., 2007).
Applying simulation theory to the development
of autonomous agents is known as imitation learn-
ing. Up until recently most of the imitation learning
research was focused on autonomous machines in-
tended for deployment in physical world (Bauckhage
et al., 2007). This focus led to a situation where re-
search aimed at behavior representation and learning
still first and foremost struggles with issues arising
from embodiment dissimilarities (Alissandrakis et al.,
2001), uncontrollable environmental dynamics (Ale-
otti et al., 2003), perception and recognition problems
(Schaal, 1999) and noisy sensors (Schaal, 1999).
1.2 Imitation Learning in VWs
The aforementioned problems do not exist in Virtual
Worlds. The sensors available there are not noisy, all
the participants normally share similar embodiment
(in terms of avatars), the environment is controllable
and easily observable. Thus, using imitation learn-
ing for virtual agents represented as avatars within
Virtual Worlds ought to be more successful than ap-
plying imitation learning to robots situated in phys-
ical world. Despite this fact, up until recently not
many researchers from the imitation learning commu-
nity were concerned with Virtual Worlds and Virtual
Agents. Only a few scholars have taken this direction
and most of them are concerned with gaming envi-
ronments, where virtual agents are used as computer
controlled enemies fighting with human players (Gor-
man et al., 2006), (Le Hy et al., 2004).
Having a focus on video games made it possible
to introduce a number of limitations and simplifica-
tions, which are not acceptable in non-gaming Virtual
Worlds (like 3D electronic markets). The algorithms
described in (Gorman et al., 2006) seem to be quite
successful in teaching the agent reactive behaviors,
where next state an agent should switch into is pre-
dicted on the basis of the previous state and the set of
parameters observed in the environment. These algo-
rithms also prove to be quite useful in learning strate-
gic behavior inside a particular video game (Quake
II). The main limitation of this approach is that the
long term goals of the players are assumed to be quite
simple, namely to collect as many items as possible
and to defeat their opponents (Thurau et al., 2004).
Provided the human only has simple goals as de-
scribed above this method is quite sufficient and can
be successfully used for training autonomous agents
to execute human-like reactive behaviors while fight-
ing the opponents in the selected video game. In many
non-gaming Virtual Worlds, however, the situation is
not that simple. Not only are the goals more com-
plex, but there is also a need to be able to recognize
the goals, desires and intentions of the human. Under-
standing the goals and subgoals is required to be able
to assign the context to the training data and sort it
into different logical clusters. Recognizing the desires
and intentions is particularly important in situations
when the agent is to replace the human in doing a par-
ticular task. For example, a human may wish to train
a virtual agent to answer customer enquiries about the
product or to participate in an auction on the human’s
behalf. One of the reasons why such tasks are im-
possible to achieve using the algorithms presented in
(Gorman et al., 2006) and (Le Hy et al., 2004) is that
there is no mechanism provided there to communicate
human requests, as well as there is no method for the
agent to infer human’s desires and intentions.
In respect to making agent understand the desires
and intentions of the human, existing approaches fall
under one of the following two extreme cases. First
case is to purely rely on explicit communication be-
tween agents and humans, when every goal, belief,
desire, intention of the human and action the hu-
man trains the agent to perform is formalized for the
agent. Second case is the fully implicit communica-
ICSOFT 2008 - International Conference on Software and Data Technologies
340

tion between humans and agents, when any explicit
form of communication is considered unacceptable.
In the first case it often becomes easier to program the
agents than to train them and in the second case only
simple reactive behaviors can be learned and strate-
gical or tactical behaviors are mostly left out (as it is
not possible to recognize complex human desires or
intentions, like a human wanting to leave the agent to
participate in an auction on his/her behalf).
1.3 The Scope of the Paper
In this paper we suggest that to be able for the agent to
handle the complexity of the human actions and goals,
the agent should not purely rely on its own intelli-
gence but should expect some help from the environ-
ment it is situated in. As an example of such environ-
ment we consider the concept of Virtual Institutions
(Bogdanovych, 2007), which are Virtual Worlds with
normative regulation of participants’ interactions.
In order for the agent to make use of the environ-
ment’s formalization provided by Virtual Institutions
the data structures that can map these formalisms onto
the logical states of the agents are required. Most of
the popular methods used for modeling the represen-
tation of the states of the agents and the mechanism
of progressing trough these (i.e. final state machines,
neural networks, decision trees etc.) utilize graphs for
this task. Furthermore, Virtual Institutions also use
graphs in many parts of the formalization. Therefore,
using a graph-like structure for our purpose was a nat-
ural choice. For these graphs to satisfy our needs and
allow for a general kind of learning we created a new
data structure called the recursive-arc graphs.
The remainder of the paper is structured around
the recursive-arc graphs concept. Before going into
details of the proposed solution, Section 2 provides
a description of the Virtual Institutions concept. In
Section 3 it is shown how using Virtual Institutions
enables implicit training of virtual agents and the
recursive-arc graphs that are used for modeling the
agent’s state space are throughly explained. Finally,
Section 4 summarizes the contribution and outlines
the directions of future work.
2 VIRTUAL INSTITUTIONS
Virtual Institutions (Bogdanovych, 2007) are a new
class of normative Virtual Worlds, that combine
the strengths of 3D Virtual Worlds and normative
multiagent systems, in particular, Electronic Institu-
tions (Esteva, 2003). In this ”symbiosis” the 3D Vir-
tual World component spans the space for visual and
audio presence, and the electronic institution compo-
nent takes care for enabling the formal rules of inter-
actions among participants.
The interaction rules include the roles the par-
ticipants can play, the groups of activities each role
can engage into, the interaction protocols associated
with each group of the activities and a set of actions
they can perform (see (Esteva, 2003) for more de-
tails). The Virtual World is separated into a number
of logical spaces (scenes), connected with each other
through corridors or teleports (also called transition).
Only participants playing particular roles are admit-
ted to a scene. Once admitted the participants should
follow the interaction protocol specified for each of
them.
The correct application of the institutional rules
and the functioning of the 3D environment of the vir-
tual institution is enabled by a three-layered architec-
ture. Figure 1 presents a high-level overview of this
architecture. It is presented in three conceptually (and
technologically) independent layers, as follows.
Figure 1: Three-layered architecture of Virtual Institutions.
Normative Control Layer. Its task is to regulate the
interactions between participants by enforcing the in-
stitutional rules.
Communication Layer. Its task is to causally con-
nect the above discussed institutional dimensions with
the virtual world representation of the institution and
transform the actions in the virtual world into mes-
sages, understandable by the institutional infrastruc-
ture and vice versa.
Visual Interaction Layer. Its task is to support the
immersive interaction space of a virtual institution
and indicate institutional actions, if such occur, to the
inhabitants. Technologically, this layer includes a 3D
virtual world and the interface that converts commu-
nication messages from the Communication Layer.
TRAINING BELIEVABLE AGENTS IN 3D ELECTRONIC BUSINESS ENVIRONMENTS USING RECURSIVE-ARC
GRAPHS
341
3 IMPLICIT TRAINING
Existing 3D Virtual Worlds are mostly human cen-
tered with very low agent involvement. Virtual insti-
tutions, in contrast, is an agent-centered technology,
which treats humans as heterogenous, self-interested
agents with unknown internal architecture. Every hu-
man participant (principal) is always supplied with
a corresponding software agent, that communicates
with the institutional infrastructure on human’s be-
half. The couple agent/principal is represented by
an avatar. Each avatar is manipulated by either a hu-
man or an autonomous agent through an interface that
translates all activities into terms of the institution
machine understandable language. The autonomous
agent is always active, and when the human is driving
the avatar the agent observes the avatar actions and
learns how to make the decisions on human’s behalf.
At any time a human may decide to let the agent con-
trol the avatar via ordering it to achieve some task. If
trained to do so the agent will find the right sequence
of actions and complete the task imitating the human.
The research conducted by (Bauckhage et al.,
2007) suggests that in order to achieve believable
agent behavior the agent should learn reactive behav-
iors, localized tactics and strategical behaviors. The
authors, however, do not suggest an integrated solu-
tion for learning all these behaviors in a consistent
manner and their method has a number of limitations.
To address these limitations in the implicit training
method we rely on the concept of the pyramid of vir-
tual collaboration proposed by (Biuk-Aghai, 2003).
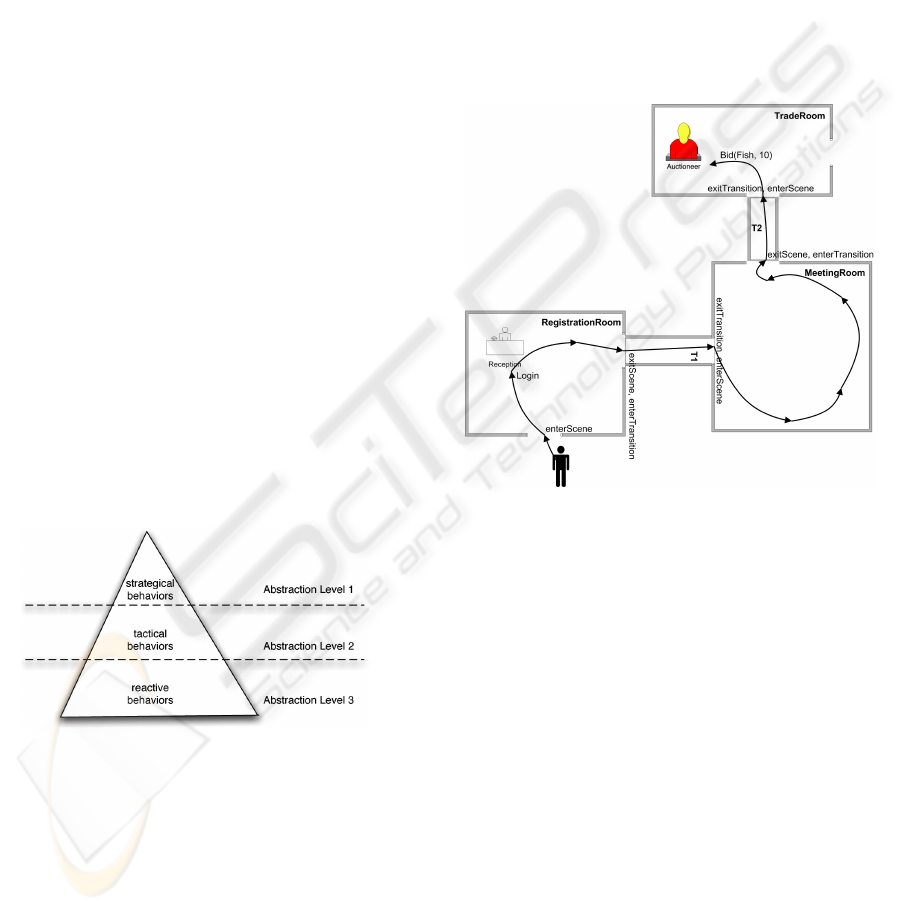
Figure 2: The Pyramid: Different Levels of Abstraction.
Figure 2 outlines the adaptation of this concept to
implicit training of autonomous agents in Virtual In-
stitutions. The pyramid shows the integration of dif-
ferent levels of abstraction of the training data and
suggests that training should happen on each of the
abstraction levels simultaneously. We distinguish be-
tween three abstraction levels, where the lowest level
corresponds to pure reactive behaviors, middle lev-
els represents tactical behaviors and the highest level
stands for strategical behaviors. Next, we present
the scenario that illustrates the capabilities of implicit
training and explains each of the abstraction levels.
3.1 Training Scenario
To simplify the understanding of the implicit train-
ing concept we propose the scenario outlined in Fig-
ure 3. The virtual institution presented here consists
of a building containing three rooms (scenes) con-
nected by corridors (transition). The task an agent has
to learn is walking into the last room and participat-
ing in an auction there. The human trains the agent
by controlling the avatar while performing a task of
buying fish in the TradeRoom.
Figure 3: Outline of a prototypical Virtual Institution.
The actions of the highest level of abstraction in
this scenario are strategical behaviors. Such actions
are strictly controlled by the institution and can be
prohibited if a certain activity is not consistent with
the institutional state or with the role a participant is
playing. In our scenario those are “enterScene”, “ex-
itScene”, “enterTransition”, “exitTransition”, “login”
and “bid”. The tactical behaviors from abstraction
level 2 in this case are actions not controlled by the
institution and actions independent from a particular
Virtual World. These are approaching the reception-
ist, leaving the receptionist, approaching the auction-
eer and leaving the auctioneer. The lowest level of
abstraction deals with the actions tightly connected
with the selected Virtual World. Learning such ac-
tions helps the agent to learn correct reactive behav-
iors influenced by static and dynamic objects located
in the training environment.
Let’s assume that after participating in the fish
auction the human has entered the building, regis-
tered himself at the reception desk, walked into the
ICSOFT 2008 - International Conference on Software and Data Technologies
342

TradeRoom and bought a box of fish for the price of
$10 . In meanwhile the agent was observing the hu-
man and learning from him on each of the abstrac-
tion levels. Now the human decides to use a special
command “Do:bid(fish, 10)” instructing the agent to
buy fish. To satisfy this request the agent searches
the prerecorded sequence of the actions of the high-
est abstraction level for the presence of bid(x,y) func-
tion. Once the function is found, the agent knows
which sequence of institutional level actions will lead
to achieving the goal. At the second level it knows
that for doing so it will first need to approach the re-
ceptionist and then approach the auctioneer. Finally,
at the lowest level the agent knows which actions it
has to execute for a believable imitation of the human
movement. The aforementioned reasoning will result
in the following behavior: the avatar enters the Regis-
tration Room, the avatar reproduces the trajectory of
the human and approaches the reception desk, the re-
quest for login information is received and the agent
sends the login details. In the similar way the agent
continues its movement to the Trade Room, where it
offers $10 for the box of fish. If the agent wins the
lot - the scenario is finished; if the price this time is
higher - the agent will request the human intervention.
3.2 Technological Solution
The implicit training is implemented as a lazy learn-
ing method, based on graph representation. The Vir-
tual Institution corresponds to the scenario outlined
in Figure 3. The implicit training method is demon-
strated on learning movement styles.
3.2.1 Training Data
The data provided by Virtual Institution consists of:
institutional messages executed as a result of human
actions in the Virtual World, the attributes of the ob-
jects located in the environments, the attributes of the
avatars located in the environment and the informa-
tion about the actions executed by the avatars. The
aforementioned attributes are updated by the system
every 50 Msc and contain information like the coor-
dinates, transformation vectors and other parts of the
mathematical model of the Virtual World.
This data is expressed using the coordinate space
of the 3D Virtual World we are dealing with and,
therefore, is highly environment dependent. Using it
for agent training in such form would make it impos-
sible to come up with a general solution that could be
used in a different Virtual World or handle the situ-
ations the agent wasn’t directly trained to deal with.
Therefore, this data has to be further processed and
filtered into the above described levels of abstractions.
In our scenario we use the parameters of the ob-
jects visible to the agent’s avatar as the learning at-
tributes and the action performed by the agent as the
variable to be learned. To avoid operating with co-
ordinates, on the lowest level of abstraction we can
substitute coordinates of the visible objects by dis-
tances and space orientation. For example, instead
of recording that the object “PineTree” is located at
(10,30,158) we could say that it is located NE (north
east from the avatar) and the distance to it is 10 m.
The actions of the agent should also be abstracted. On
this level, instead of using coordinates we approxi-
mate the current avatar position based on the previous
position and describe the change as either of the fol-
lowing: “MF”, “TR”, “TL”, or “J”. Here “MF” cor-
responds to the avatar moving forward by one unit,
“TR” corresponds to turning right by one unit, “TL”
stands for turning left and “J” represents jumping up.
This kind of representation helps to train the agent
to perform localized reactive behaviors (like different
ways of approaching an avatar or an object) on the
lowest level of abstraction.
On the second level of abstraction the agent learns
tactical movement behaviors like an avatar approach-
ing an object or another avatar, leaving an object or
avatar, following an avatar, etc. On the highest level
of abstraction we use the data provided by the for-
malization of the institution as the source for teaching
agent to perform the normative level actions. These
include entering rooms, placing bids on auctions, ini-
tiating conversations with agents, etc.
Next, we describe the recursive-edge graph data
type that can successfully integrate the data from all
the aforementioned levels of abstraction.
3.2.2 Constructing the Learning Graph
To be able to collect and use the data on different lev-
els of abstraction we introduce the recursive-arc graph
data structure outlined in Figure 4. The figure is di-
vided into three parts (a,b,c) each representing a dif-
ferent abstraction level.
The part a) of the figure corresponds to the high-
est level of abstraction represented by the institutional
specification. On this level the agent learns which
combinations of the institutional messages will lead
to achieving which goals. When a human princi-
pal that conducts the training enters the institution,
the corresponding autonomous agent begins record-
ing principal’s actions, storing them inside a learning
graph. At this level of abstraction the nodes of this
graph correspond to the institutional messages, exe-
cuted in response to the actions of the human. Each
of the nodes is associated with two variables: the mes-
sage name together with parameters and the probabil-
TRAINING BELIEVABLE AGENTS IN 3D ELECTRONIC BUSINESS ENVIRONMENTS USING RECURSIVE-ARC
GRAPHS
343
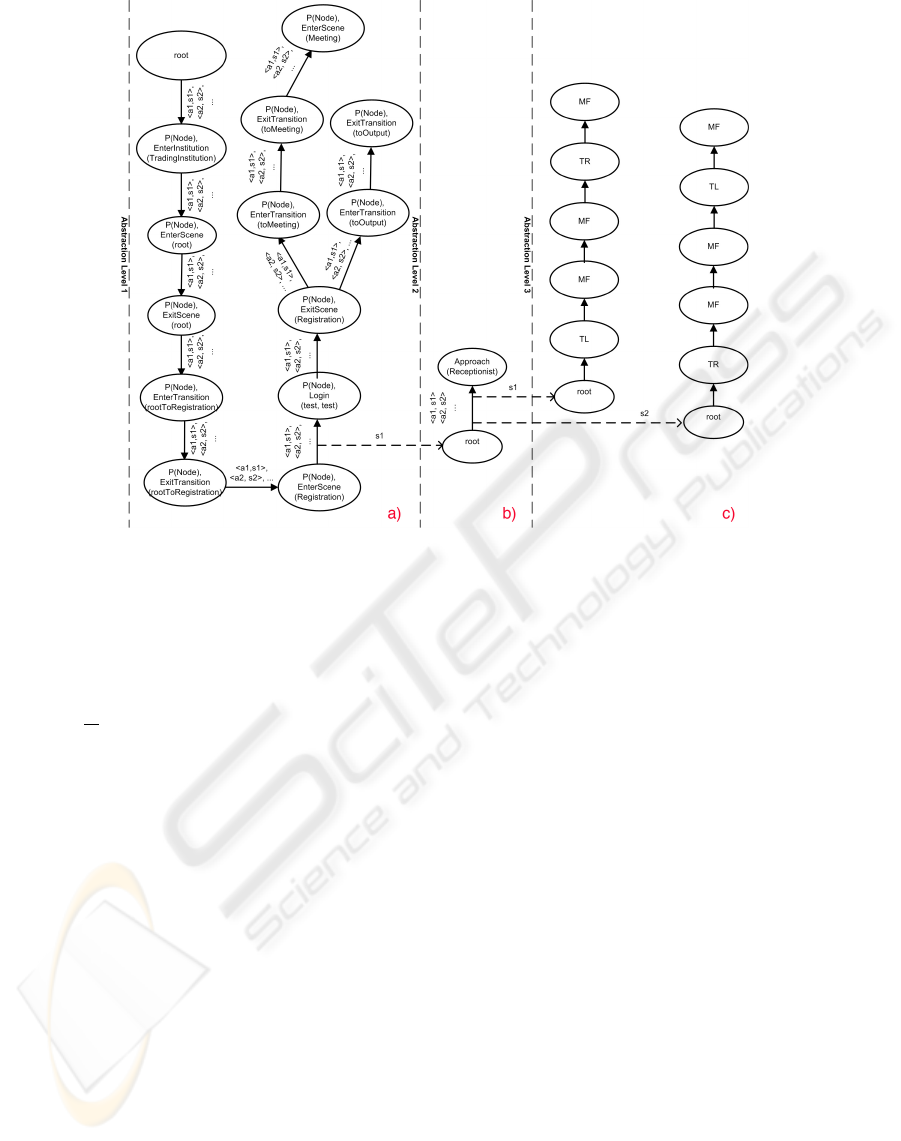
Figure 4: A fragment of the learning graph.
ity P(Node) of executing the message. The proba-
bility used for estimating the likelihood of executing
a particular institutional message in a given state of
the agent. This probability is continuously updated,
and in the current implementation it is calculated as
P(Node) =
n
a
n
o
. Here n
o
is the number of times a prin-
cipal had a chance to perform a particular action and
n
a
shows how times s/he actually did perform it.
The arcs connecting the nodes are associated with
the data from the next level of abstraction. On the
figure the arcs are marked with an array of pairs
ha
i
, s
i
i. Here (a
1
, . . . , a
n
) are the attribute vectors that
the avatar associated with the agent was able to ob-
serve and (s
1
, . . . , s
l
) are the sequences of actions that
were executed as the result. Each pair ha
n
, s
n
i is
stored in a hashtable, where a
i
is the key of the ta-
ble and s
i
is the value. Each a
i
consists of the list of
parameters: a
i
= hp
1
, . . . p
k
i.
The simplifying assumption behind the training
is that the behaviour of the principle is only influ-
enced by what is currently visible to the avatar. We
limit the visible items to the objects located in the
environments and other avatars. So, the parameters
used for learning are recorded in the following form:
p
i
= hV
o
, V
av
i, where V
o
is the list of currently visible
objects; V
av
is the list of currently visible avatars. The
list of the visible objects is represented by the follow-
ing set: V
o
= {hO
1
, D
1
, P
1
i, . . . , hO
m
, D
m
, P
m
i. Each
O
j
here is an object that visible to the agent. D
j
are
the distances from the current location of the agent
to the centers of mass of such objects and P
j
are the
textual labesl assigned to the direction vector point-
ing from the center of mass of the avatar towards an
object (i.e. “NE” – North-East).
The list of visible avatars is specified as follows:
V
av
= {hN
1
, R
1
, DAv
1
, PAv
1
i, . . . , hN
p
, R
k
, DAv
p
, PAv
p
i.
Here, N
k
correspond to the names of the avatars that
are visible to the user, R
k
are the roles played by
those avatars, DAv
k
are the distances to those avatars
and PAv
k
are again the direction vectors.
Each of the sequences (s
i
) is represented as a new
graph from the next level of abstraction as shown in
Figure 4 b). In these graphs the lower level actions
(“Approach” in our example) mark the nodes and the
arcs have similar format as in Figure 4 a), except for
the fact that an even lower level of abstraction is used
there. In our example of this lowest level we are deal-
ing with moving, turning, jumping, etc.
The training is continuously conducted on each
level of abstraction as new actions are observed there.
3.2.3 Applying the Learning Graph
When the construction of the learning graph is com-
pleted an agent is ready to accept commands from the
principal. We have specified a list of textual com-
mands that are typed into the chat window of the
ICSOFT 2008 - International Conference on Software and Data Technologies
344

simulation engine. Each command includes a special
keyword “Do:” and a valid institutional level mes-
sage, e.g.“Do:EnterScene(Meeting)”.
The nodes of the learning graph are seen as inter-
nal states of the agent, the arcs determine the mech-
anism of switching between states and P(Node) de-
termines the probability of changing the agent’s cur-
rent state to the state determined by the next node.
Once the agent reaches a state S(Node
i
) it considers
all the nodes connected to Node
i
that lead to the goal
node and conducts a probability driven selection of
the next node (Node
k
). If Node
k
is found: the agent
changes its current state to S(Node
k
) by executing the
best matching sequence of the lower abstraction level
stored on the arc that connects Node
i
and Node
k
. If
there are no such actions present on the arc - the agent
sends the message associated to Node
k
and updates
it’s internal state accordingly. This process is contin-
ued recursively for all the abstraction levels.
The parameters currently observed by the agent
must match the parameters of the selected sequence as
close as possible. To do so the agent creates the list of
parameters it can currently observe and passes this list
to a classifier (currently, a nearest neighbor classifier
(Hastie and Tibshirani, 1996)). The later returns the
best matching sequence and the agent executes each
of its actions. The same procedure continues until the
desired node is reached.
4 CONCLUSIONS
We have developed our argument for the need of im-
plicit training of virtual agents participating in 3D
Electronic Business Environments and highlighted
the role of the environment itself in the feasibility
of implicit training. Formalizing the environment
with Virtual Institutions can significantly simplify the
learning task. However, for the agent to use these for-
malization successfully it requires specific data struc-
tures to operate with. The paper has presented an ex-
ample of the data structure called recursive-arc graphs
that could be used by the agents participating in Vir-
tual Institutions. Future work includes the develop-
ment of the prototype that would confirm that such
data structures are indeed suitable for training believ-
able agents in 3D electronic business environments.
ACKNOWLEDGEMENTS
This research is partially supported by an ARC
Discovery Grant DP0879789, the e-Markets Re-
search Program (http://e-markets.org.au), projects AT
(CON-SOLIDER CSD2007-0022), IEA (TIN2006-
15662-C02-01), EU-FEDER funds, and by the Gener-
alitat de Catalunya under the grant 2005-SGR-00093.
REFERENCES
Aleotti, J., Caselli, S., and Reggiani, M. (2003). Toward
Programming of Assembly Tasks by Demonstration in
Virtual Environments. In IEEE Workshop Robot and
Human Interactive Communication., pages 309 – 314.
Alissandrakis, A., Nehaniv, C. L., and Dautenhahn, K.
(2001). Through the Looking-Glass with ALICE: Try-
ing to Imitate using Correspondences. In Proceed-
ings of the First International Workshop on Epige-
netic Robotics: Modeling Cognitive Development in
Robotic Systems, pages 115–122, Lurid, Sweden.
Bauckhage, C., Gorman, B., Thurau, C., and Humphrys, M.
(2007). Learning Human Behavior from Analyzing
Activities in Virtual Environments. MMI-Interaktiv,
12(April):3–17.
Biuk-Aghai, R. P. (2003). Patterns of Virtual Collabora-
tion. PhD thesis, University of Technology Sydney,
Australia.
Bogdanovych, A. (2007). Virtual Institutions. PhD thesis,
University of Technology, Sydney, Australia.
Breazeal, C. (1999). Imitation as social exchange between
humans and robots. In Proceedings of the AISB Sym-
posium on Imitation in Animals and Artifacts, pages
96–104.
Esteva, M. (2003). Electronic Institutions: From Spec-
ification to Development. PhD thesis, Institut
d’Investigaci
´
o en Intellig
`
encia Artificial (IIIA), Spain.
Gorman, B., Thurau, C., Bauckhage, C., and Humphrys,
M. (2006). Believability Testing and Bayesian Imita-
tion in Interactive Computer Games. In Proceedings
of the 9th International Conference on the Simulation
of Adaptive Behavior (SAB’06), volume LNAI 4095,
pages 655–666. Springer.
Hastie, T. and Tibshirani, R. (1996). Discriminant adap-
tive nearest neighbor classification and regression. In
Touretzky, D. S., Mozer, M. C., and Hasselmo, M. E.,
editors, Advances in Neural Information Processing
Systems, volume 8, pages 409–415. The MIT Press.
Huang, T. S., Nijholt, A., Pantic, M., and Pentland, A., edi-
tors (2007). Artifical Intelligence for Human Comput-
ing, ICMI 2006 and IJCAI 2007 International Work-
shops, volume 4451 of Lecture Notes in Computer
Science. Springer.
Le Hy, R., Arrigony, A., Bessiere, P., and Lebeltel,
O. (2004). Teaching bayesian behaviors to video
game characters. Robotics and Autonomous Systems,
47:177–185.
Livingstone, D. (2006). Turing’s test and believable AI in
games. Computers in Entertainment, 4(1):6–18.
Maatman, R. M., Gratch, J., and Marsella, S. (2005). Nat-
ural behavior of a listening agent. Lecture Notes in
Computer Science, pages 25–36.
TRAINING BELIEVABLE AGENTS IN 3D ELECTRONIC BUSINESS ENVIRONMENTS USING RECURSIVE-ARC
GRAPHS
345

Magnenat-Thalmann, N., Kim, H., Egges, A., and
Garchery, S. (2005). Believability and Interaction in
Virtual Worlds. In Proceedings of the Multimedia
Modelling Conference (MMM’05), pages 2–9, Wash-
ington, DC, USA. IEEE Computer Society.
Pantic, M., Pentland, A., Nijholt, A., and Huang, T. (2006).
Human computing and machine understanding of hu-
man behavior: a survey. In ICMI ’06: Proceedings of
the 8th international conference on Multimodal inter-
faces, pages 239–248, New York, NY, USA. ACM.
Prendinger, H. and Ishizuka, M. (2001). Let’s talk! socially
intelligent agents for language conversation training.
IEEE Transactions on Systems, Man, and Cybernet-
ics, Part A, 31(5):465–471.
Rist, T., Andre, E., and Baldes, S. (2003). A flexible plat-
form for building applications with life-like charac-
ters. In IUI ’03: Proceedings of the 8th international
conference on Intelligent user interfaces, pages 158–
165, New York, NY, USA. ACM.
Schaal, S. (1999). Is imitation learning the route to hu-
manoid robots? Trends in cognitive sciences, (6):233–
242.
Thurau, C., Bauckhage, C., and Sagerer, G. (2004). Learn-
ing Human-Like Movement Behavior for Computer
Games. In Proceedings of the 8-th Simulation of
Adaptive Behavior Conference (SAB’04), pages 315–
323. MIT Press.
Tomlinson, B., Yau, M. L., and Baumer, E. (2006). Embod-
ied mobile agents. In Proceedings of AAMAS ’06 con-
ference, pages 969–976, New York, NY, USA. ACM.
ICSOFT 2008 - International Conference on Software and Data Technologies
346
