
NEW SCHEMES FOR ANOMALY SCORE AGGREGATION AND
THRE
SHOLDING
Salem Benferhat and Karim Tabia
CRIL - CNRS UMR8188, Universit´e d’Artois, Rue Jean Souvraz SP 18 62307 Lens Cedex, France
Keywords:
Anomaly intrusion detection, anomaly scoring and aggregating, thresholding, Bayesian networks.
Abstract:
Anomaly-based approaches often require multiple profiles and models in order to characterize different aspects
of normal behaviors. In particular, anomaly scores of audit events are obtained by aggregating several local
anomaly scores. Remarkably, most works focus on profile/model definition while critical issues of anomaly
measuring, aggregating and thresholding are dealt with ”simplistically”. This paper addresses the issue of
anomaly scoring and aggregating which is a recurring problem in anomaly-based approaches. We propose a
Bayesian-based scheme for aggregating anomaly scores in a multi-model approach and propose a two-stage
thresholding scheme in order to meet real-time detection requirements. The basic idea of our scheme is the fact
that anomalous behaviors induce either intra-model anomalies or inter-model anomalies. Our experimental
studies, carried out on recent and real http traffic, show for instance that most attacks induce only intra-model
anomalies and can be effectively detected in real-time.
1 INTRODUCTION
Intrusion detection aims at detecting any mali-
cious action compromising integrity, confidentiality
or availability of computer and network resources or
services (Axelsson, 2000). Intrusion detection sys-
tems (IDSs) are either misuse-based such as SNORT
(Snort, 2002) or anomaly-based such as EMERALD
(Neumannand Porras, 1999) or a combinationof both
the approaches in order to exploit their mutual com-
plementarities (Tombini et al., 2004). Anomaly ap-
proaches build profiles or models representing normal
behaviors and detect intrusions by comparing cur-
rent system activities with learnt profiles. In practice,
anomaly-based IDSs are efficient in detecting new at-
tacks but cause high false alarm rates which really
encumbers the application of anomaly-based IDSs
in real environments. In fact, configuring anomaly-
based systems to acceptable false alarm rates result
in failure to detect most malicious activities. How-
ever, a main advantage of anomaly detection lies in
its potential capacity to detect both new and unknown
(previously unseen) as well as known attacks.
Several anomaly-based systems use statistical profiles
(Kruegel and Vigna, 2003) (Staniford et al., 2002)
(Neumann and Porras, 1999) (Kruegel et al., 2005)
to represent normal behaviors of network, host, user,
program, etc. In most profile-based IDSs, anomaly
score of a given audit event (network packet, system
call, etc.) often depends on several local deviations
measuring how much anomalous is the audit event
with respect to the different normal profiles and mod-
els (Kruegel et al., 2005). Critical issues in statistical
anomaly detectionarenormal profile/modeldefinition
and anomaly scoring and thresholding. The first issue
is concerned with extracting and selecting features to
analyze in order to detect anomalies. The second is-
sue is also critical since it providesthe anomalyscores
determining whether audit events should be flagged
normal or anomalous.
We believe that the problem of bad tradeoffs be-
tween detection rates and underlying false alarm ones
characterizing most anomaly-based IDSs are in part
due to problems in anomaly measuring, aggregating
and thresholding methods. In this paper, we address
drawbacks of existing methods for measuring and ag-
gregating anomaly scores and anomaly thresholding.
More precisely, we propose two schemes for anomaly
thresholding suitable for multi-model anomaly-based
approaches. The first scheme is a two-stage thresh-
olding method aiming at effectively detecting intra-
model anomalies as well as inter-model ones. The
second thresholding scheme relies on ranking anoma-
lous events according to their anomaly scores in or-
der to cope with huge amounts of alerts characteriz-
ing most anomaly-based IDSs. As for anomaly score
aggregation, we propose a Bayesian-based approach
in order to exploit Bayesian network learning capa-
21
Benferhat S. and Tabia K. (2008).
NEW SCHEMES FOR ANOMALY SCORE AGGREGATION AND THRESHOLDING.
In Proceedings of the International Conference on Security and Cryptography, pages 21-28
DOI: 10.5220/0001927900210028
Copyright
c
SciTePress

bilities. Moreover, Bayesian networks enable us to
in
tegrate expert knowledge. The proposed schemes
overcome most existing methods’ drawbacks. Experi-
mental studies carried out on real and recent http traf-
fic show the efficiency of our schemes.
The rest of this paper is organized as follows: Section
2 provides basic backgrounds about anomaly mea-
suring and aggregating. It also points out problems
with existing methods for anomaly measuring, aggre-
gating and thresholding. A Bayesian-based approach
for anomaly score aggregation and two thresholding
schemes are proposed in section 3. In section 4, we
present our experimental studies carried out on http
traffic. Finally, section 5 concludes this paper.
2 RELATED WORK
SPADE (Staniford et al., 2002), NIDES(Javits and
Valdes, 1993) are well-known anomaly-based IDSs
where anomaly detection is ensured by computing de-
viations from normal activity profiles/models. Sta-
tistical profiles represent normal behaviors using sta-
tistical methods like frequencies, means, variances,
etc. Then anomaly scoring functions evaluate the de-
viation of a given audit event with respect to learnt
profiles. According to intrusion detection field, an
audit event can be a packet or a connection in case
of network-oriented intrusion detection, a system log
record in case of host-oriented intrusion detection, a
Web server log record in case of Web-oriented intru-
sion detection, etc.
2.1 Anomaly Measuring, Aggregating
and Thresholding
Profile-based anomaly IDSs rely on the following el-
ements:
1. Profile/Model Definition: Anomalous behaviors
are those that do not conform to the expected
normal behavior. Namely, there are aspects and
characteristics of anomalous events which behave
significantly different from known normal behav-
iors. Accordingly, normal profiles ideally con-
sist in ”all” features/aspects that can show dif-
ferences between normal activities and abnormal
ones. Note that most common form of audit
events used in statistical-based IDSs are multi-
variate audit records describing network packets,
connections,system calls, application log records,
etc. These audit records involve different data
types among which continuous and categorical
data are common. In practice, several models and
profiles are used in order to characterize the dif-
ferent aspects of normal behaviors.
2. Anomaly Scoring Measures: They are func-
tions computing anomaly scores for every ana-
lyzed event. According to a fixed or learned
threshold, an anomaly score associated with an
event allows flagging it normal or anomalous. To
compute such anomaly scores, anomaly scoring
measures use the following functions:
(a) Set of ”individual” (or ”local”) Anomaly
Scoring Measures: They are functions that
evaluate the normality of audit event with re-
spect to normal profiles individually. For ex-
ample, in (Krugel et al., 2002) three statisti-
cal profiles represent normal http and DNS re-
quests: Request type profile, Request length
profile and Character distribution profile. Then
three anomaly scoring functions are used in or-
der to compute local anomaly scores. Most
used anomaly measures are distance measures
(which are widely used in outlier detection
(Angiulli et al., 2006), clustering (Gerhard Mnz
and Carle, 2007)), probability measures (Stani-
ford et al., 2002), density measures (Ertz et al.,
) and entropy measures (Lee and Xiang, 2001).
(b) Aggregating Functions: Aggregating func-
tions are used to fuse all individual anomaly
scores into a single anomaly score which will
be used to decide whether the analyzed event
is normal or anomalous. Namely, a global
anomaly score AS for an audit event E is com-
puted using aggregating function G which ag-
gregates all local anomaly scores AS
M
i
(E) rel-
ative to corresponding profiles/models M
i
.
AS(E) = G(AS
M
1
(E),AS
M
2
(E)..,AS
M
n
(E))
(1)
In practice, aggregating functions range
from simple summations (Javits and Valdes,
1993)(Krugel et al., 2002) to complex models
such as Bayesian networks (Kruegel et al.,
2003)(Staniford et al., 2002).
3. Anomaly Thresholding: Thresholding is needed
to transform a numeric anomaly score into a sym-
bolic value (Normal or Anomalous) in such a way
an alert can be raised. Namely, thresholding is
done by specifying value intervals for both normal
and anomalous behaviors. Surprisingly, only few
works addressed anomaly thresholding issues. In
fact, some authors just use a single value(Krugel
et al., 2002)(Staniford et al., 2002) to fix the limit
between normal and abnormal scores while oth-
ers use range of values to fix this limit and flag
events as normal, abnormal or unknown. In prac-
SECRYPT 2008 - International Conference on Security and Cryptography
22

tice, thresholds are often fixed according to the
fal
se alarm rate which must notbe exceeded. Note
that thresholds can be statically or dynamically
set. The advantage of dynamically fixing a thresh-
old is the ability to reassign its value in such a way
to limit the amount of triggered alerts.
It is clear that the effectiveness of anomaly-based ap-
proaches strongly depend on profile/model definition
and anomaly scoring measure relevance. In order to
illustrate our ideas, we use a simple but widely used
Web-based anomaly approach developed by Kruegel
& Vigna (Kruegel and Vigna, 2003). These authors
proposeda multi-model approachto detect web-based
attacks relying on six detection models (Attribute
length, Character distribution, Structural inference,
Token finder, Attribute presence or absence and At-
tribute order). During detection phase, the six models
output anomaly scores which are aggregated using a
weighted sum. Recently, this model has been exam-
ined in depth in (Ingham and Inoue, 2007).
2.2 Drawbacks of Existing Schemes for
Anomaly Measuring, Aggregating
and Thresholding
Existing anomaly measuring, aggregating and thresh-
olding methods suffer from several problems:
• Probability Distribution Assumption Prob-
lems: This problem is particularly encountered in
mean and variance models (Denning, 1987) and
anomaly measures using probability measures.
For example, anomaly score relative to attribute
length model in Krugel & Vigna model is propor-
tional to the difference from the mean length µ.
However, attributes with lesser lengths (l ≪ µ)
are scored like attributes whose lengths are ex-
ceeding µ (l ≫ µ). However, since anomalous-
ness caused by attribute lengths are mostly due to
oversized values, then anomaly measure relative
to attribute length should handle differently over-
sized and undersized values. Basically, the prob-
lem is due to assuming that normal values follow
a Gaussian distribution while this assumption is
not valid in many detection models.
• Frequency Bias: Most frequency-based anomaly
measures often associate significantly different
anomaly scores to typicallynormal behaviors. For
example, in (Krugel et al., 2002), authors use
three models in order to detect anomalies in http
requests. In this work, anomaly score relative to
request type (GET, POST, HEAD, etc.) is pro-
portional to the frequency of each request method
in training data. However, consider that GET
requests represent 95% while POST ones repre-
sent 3% (remaining proportion represents other
request types). Then anomaly score of a POST
request will be hundred times bigger than a GET
score. However, all of them are typically normal
request types present in training data.
• Anomaly Score Aggregation: As mentioned
above, aggregating anomaly scores is done in
most cases using ”simplistic” methods (Kruegel
et al., 2003). For instance, most used aggregation
scheme is the weighted sum-based method which
suffers from several problems such as:
1. Firstly, weighting local anomaly scores is often
done in a ”questionable” way. For example, au-
thors in (Krugel et al., 2002) neither explained
how they assign weights nor why they use same
weighting for htt p and DNS requests.
2. The accumulation phenomena which causes
several small local anomaly scores to cause,
once summed, a high global anomaly score.
3. The averaging phenomena which causes a very
high local anomaly score to cause, once aggre-
gated, a low global anomaly score.
4. Commensurability problems are encountered
when different detection model outputs do not
share the same scale. Then some anomaly
scores will have much more importance in the
overall score than others.
5. Ignoring inter-model dependencies existing be-
tween the different detection models.
• Thresholding: This problem is basically due to
the fact that the border line between normal and
anomalous behaviors is not well precise. More-
over, this problem is impacted by the quality of
features, models and measures used to evaluate
the normality of audit events.
• Real-time Detection Capabilities: The decision
of raising an alert is taken on the basis of the
global anomaly score which requires computing
all local anomaly scores then aggregating them.
This method causes several problems especially
for effectiveness considerations. For example,
when analyzing buffer-overflow attacks, the re-
quest length can be sufficient and there is not need
to compute the other anomaly scores. Moreover,
in buffer-overflowattacks, the request is oftenseg-
mented over several packets which are reassem-
bled at the destination host. However, such attack
can be detected given the first packets of the re-
quest and there not need to wait for all packets in
order to detect such an anomaly.
• Handling Missing Inputs: Missing data is an
important issue that existing systems have not
NEW SCHEMES FOR ANOMALY SCORE AGGREGATION AND THRESHOLDING
23

dealt with conveniently. In fact, many intentional
or
accidental causes can provoke the missing of
some data pieces. For example, in gigabyte net-
works, network packet sniffer may drop packets.
Though, when applied to network traffic, how can
the model proposed in (Krugel et al., 2002) deal
with a request if the sniffer dropped the packet
containing the request method? The problem is
how to analyze audit events given that some in-
puts are missing.
3 NEW SCHEMES FOR
ANOMALY SCORE
AGGREGATING AND
THRESHOLDING
In this section, we propose new schemes for aggre-
gating anomaly scores and thresholding suitable for
multi-model anomaly detection approaches.
3.1 What is ”Anomalous Behavior”
The premise of anomaly-based approaches is the as-
sumption that attacks induce abnormal behaviors.
There are different possibilities about how anomalous
events affect and manifest through elementary fea-
tures. For instance, anomalous events can be in the
form of anomalous (new or outlier) value in a feature,
anomalous combination of known normal values or
anomalous sequence of events. Accordingly, alerts
raised by a multi-model anomaly-based approach can
be caused by two anomaly categories:
• Intra-model Anomalies: They are anomalous
behaviors affecting one singlemodel. Namely, the
anomaly evidence is obvious only throughone de-
tection model. For example, in Krugel & Vigna
model, there are buffer-overflow attacks which
heavily affect the length model without affecting
the other models. Then anomaly score computed
using length model should suffice in order to de-
tect such attacks.
• Inter-model Anomalies: They are anomalies that
affect regularities and correlations existing be-
tween different models. For instance, in Krugel &
Vigna model, authors pointed out correlations be-
tween Length model and Character distribution
model. Then audit events violating such regulari-
ties are anomalous.
It is obvious that intra-model anomalies can be de-
tected without aggregating the different anomaly
scores. Moreover, this is interesting because such
anomalies can be detected in real-time. In fact, any
anomaly revealed by a detection model is sufficient
to raise an alert even if other detection models have
not yet returned their anomaly scores. This is the
idea motivating the multi-stage thresholding scheme.
Namely, each detection model has its own anomaly
threshold T
M
i
. During the detection phase, once in-
put data for detection model M
i
is available, then the
system can trigger an alert whenever anomaly score
As
M
i
(E) exceeds corresponding threshold T
M
i
. If no
intra-modelanomalyis detected, then we need to look
for inter-model anomalies.
3.2 New Thresholding Schemes
In the following, we propose a two-stage thresholding
scheme in order to effectively detect intra-model and
inter-model anomalies and a ranking-basedthreshold-
ing scheme for coping with large amounts of alerts
characterizing most anomaly-based IDSs.
3.2.1 Scheme 1: Local vs Global Thresholding
Since anomalous events can either affect detection
models individuallyor violateregularitiesexisting be-
tween detection models, then we propose a two-stage
thresholding scheme aiming at raising an alert when-
ever an anomalous behavior occurs be it intra-model
or inter-model.
• In order to detect intra-model anomalies, we fix
for each detection model M
i
a local anomaly
threshold in the following way:
Threshold
M
i
= Max(As
M
i
(E
Normal
)) ∗θ (2)
Threshold Threshold
M
i
associated with detec-
tion model M
i
is set to the maximum among
all anomaly scores computed on normal train-
ing behaviors E
Normal
. θ denotes a discount-
ing/enhancing factor in order to control detection
rate and underlying false alarm rate. In case when
no intra-model anomaly is detected, then we need
to check for inter-model anomalies.
• Similarly to intra-model thresholding, a threshold
can be fixed for global anomaly score as follows:
Threshold = Max(As(E
Normal
)) ∗θ (3)
Note that term As(E
Normal
) denotes the anomaly
score aggregating function and E
Normal
denotes a
normal audit event. In order to control detection
rate/false alarm rate tradeoff, one can use the dis-
counting/enhancing parameter θ.
Local and global thresholding schemes can be com-
bined in order to exploit their complementarities:
SECRYPT 2008 - International Conference on Security and Cryptography
24

• Real-time detection: With local thresholding, ev-
er
y intra-model anomaly is detected without wait-
ing for other detection model results.
• Handling missing inputs: Missing inputs only af-
fect models requiringthese input. Then remaining
models can work normally and detect intra-model
anomalies.
• Intra-model and inter-model anomaly detection:
As we will see in experimental studies, combin-
ing local with global thresholding allows detect-
ing more effectively both intra-model and inter-
model anomalies.
Note that the motivation of setting the anomaly
thresholds to the maximum among all anomaly scores
computed on normal training behaviors is to detect
any event whose anomaly score exceeds all normal
behavior scores used to build the detection mod-
els. This maximum-based thresholding is intuitive
and does not require any assumption about anomaly
scores. In fact, the greatest anomaly score on train-
ing behaviors is the one associated with normal but
unusual behavior. Then behaviors having greater
anomaly score are anomalous.
3.2.2 Scheme 2: Ranking-based Thresholding
In many domains and environments, security admin-
istrators know from experience that there is always
some percentage of behaviors that are not totally nor-
mal. This is for instance what happens with zero-day
attacks where vulnerabilities are exploited before se-
curity patches are released. Moreover, security ad-
ministrators are often incapable to manually analyze
the whole amount of triggered alerts. Hence, they
prefer to focus only on most anomalous behaviors.
Accordingly, instead of just flagging events normal
or anomalous according to a fixed threshold, we pro-
pose to rank anomalous auditevents accordingto their
anomaly scores. Then security administrator can ana-
lyze alerts according to anomaly score ranking. This
simple method has several advantages:
• The administrator can firstly analyze most anoma-
lous events and the amount of events he wants.
• Coping with zero-day attack problem since there
will always be events causing alerts.
• There is not need to fix any anomaly threshold.
However, this thresholding scheme is more suitable
for off-line analysis than real-time one. In off-line
detection, this method returns the top n% anomalous
events or a ranking of most anomalous events.
3.3 Bayesian-based Aggregation
Bayesian networks (BN) are powerful graphical mod-
els for representing and reasoning under uncertainty
conditions (Jensen, 1996). They consist of a graphi-
cal component DAG (Directed Acyclic Graph) and a
quantitative probabilistic one. The graphical compo-
nent allows an easy representation of domain knowl-
edge in the form of an influence network (vertices rep-
resent events while edges represent ”influence” rela-
tions between these events). The probabilistic com-
ponent expresses uncertainty relative to relationships
between domain variables using conditional probabil-
ity tables (CPTs). Learning Bayesian networks re-
quires training data to learn structure and compute
the conditional probability tables. Note that sev-
eral works used BN for anomaly detection (Gowadia
et al., 2005)(Staniford et al., 2002)(Valdes and Skin-
ner, 2000). For instance, authors in (Kruegel et al.,
2003) used a BN in order to assess the anomalousness
of system calls. In our case, main advantages of BN
are learning capabilities in order for instance to ex-
tract inter-model regularities and inference capacities
which are very effective. Moreover, BN can combine
user-supplied structure with empirical data.
3.3.1 Training the Bayesian Network:
Extracting Intra-model and Inter-model
Regularities
Given a data set of m normal audit events E
Normal
,
we build a data set of anomaly score vectors (A
1
,
A
2
,.., A
m
) where each anomaly vector is composed
of all local anomaly scores (namely A
i
= (a
i1
,..,a
in
)
corresponds to anomaly vector relative to normal au-
dit event E
Normal
with respect to detection models
M
1
,..,M
n
and anomaly measure As
M
1
,..,As
M
n
respec-
tively). Then learning a BN from these anomaly
vectors will learn intra-model regularities as well as
inter-model ones. Then network structure qualita-
tively represents inter-model regularities while con-
ditional probability tables quantify inter-model influ-
ences. Note that the structure can be specified by do-
main expert in order to fix detection model dependen-
cies according to expert knowledge.
3.3.2 Detection using the Bayesian Network
Once the BN built, it can be used to compute the
probability of any anomaly vector. We first compute
the different anomaly scores then using the BN, we
compute the probability of the current anomaly vec-
tor. The normality of audit event E is proportional to
the probability of the corresponding anomaly vector.
NEW SCHEMES FOR ANOMALY SCORE AGGREGATION AND THRESHOLDING
25

The anomaly threshold can be fixed as follows:
Th
reshold = Max(1− p
BN
(A
1
,A
2
,..,A
m
)) ∗θ (4)
Term p
BN
in Equation 4 denotes the probability de-
gree computed using BN. This threshold flags anoma-
lous any event having a probability degree smaller
than the most improbable normal training event.
4 EXPERIMENTAL STUDIES
In order to evaluate our anomaly aggregating and
thresholding schemes, we use a multi-model ap-
proach designed to detect anomalies and attacks
against server-side and client-side Web applications
(Benferhat and Tabia, 2008). The detection models
are built on real and recent attack-free http traffic and
evaluated on real and simulated http traffic involving
normal data as well as several Web-based attacks.
4.1 Detection Model Definition
Our experimental studies are carried out on Web-
based attack detection problem which represents ma-
jor part of nowadays cyber-attacks. In (Benferhat
and Tabia, 2008), authors proposed a set of detec-
tion models including basic features of http connec-
tions as well as derived features summarizing past
http connectionsand providinguseful informationfor
revealing suspicious behaviors involving several http
connections. Note that detection model’s inputs are
directly extracted from network packets instead of us-
ing Web application logs. Processing whole http traf-
fic is the only way for detecting suspicious activities
and attacks targeting either server-side or client-side
Web applications. The detection model features are
grouped into four categories:
1. Request General Features: They are features that pro-
vide general information on http requests. Examples of
such features are request method, request length, etc.
2. Request Content Features: These features search for
particularly suspicious patterns in htt p requests. The
number of non printable/metacharacters, number of di-
rectory traversal patterns, etc. are examples of features
describing request content.
3. Response Features: Response features are computed
by analyzing the http response to a given request. Ex-
amples of these features are response code, response
time, etc.
4. Request History Features: They are statistics about
past connections given that several Web attacks such
as flooding, brute-force, Web vulnerability scans per-
form through several repetitive connections. Examples
of such features are the number/rate of connections is-
sued by same source host and requesting same/different
URIs.
Note that in our experimentations, we consider each
feature as a detection model. Then numeric features
are modeled by their means µ and standard deviations
σ while nominal and boolean features are represented
by the frequencies of possible values. During the de-
tection phase, anomaly score associated with a given
http connection lies in the local anomaly scores of the
connection features with respect to the learnt profiles.
We use different anomaly measures according to each
profile type(numeric, nominal or boolean) and its dis-
tribution in training data. It is important to note that
most numeric features in training data have rather ex-
ponential distributions than Gaussian ones. In order
to compute anomaly score of a given feature F
i
with
respect to the corresponding detection model M
i
, we
consider two cases:
• if F
i
is numerical then the anomaly score is com-
puted as follows:
As
M
i
(F
i
) = e
F
i
−µ
i
σ
i
(5
)
Terms µ
i
and σ
i
denote respectively the mean and
standard deviation of feature F
i
in normal data. σ
i
is used as a normalization parameter. Note that
only exceeding values cause high anomaly scores.
Intuitively, if the value of F
i
is less, equal or closer
to the average µ
i
then the anomaly score will be
negligible. Otherwise, the wider the margin, the
greater will the anomaly score.
• if F
i
is a boolean or symbolic feature then the
anomaly score is computed according to the im-
probability of the value of F
i
in normal training
data. Namely,
As
M
i
(F
i
) = −log(p(F
i
)) (6)
Term p(F
i
) denotes the frequency of F
i
’s value in
normal training data. Intuitively again, the more
exceptional is the value of F
i
in training data, the
higher will be the anomaly score. Conversely, fre-
quent and usual values will be associated with low
anomaly scores.
4.2 Training and Testing Data
Our experimental studies are carried out on a real
http traffic collected on a University campus during
2007. Note that this traffic includes both inbound and
outbound http connections. We extracted http traf-
fic and preprocessed it into connection records using
only packet payloads. As for attacks, we simulated
most of the attacks involved in (Ingham and Inoue,
2007) which is to our knowledge the most extensive
and uptodate open Web-attack data set.
Attacks of Table1 are categorized accordingto the
vulnerability category involved in each attack. Re-
SECRYPT 2008 - International Conference on Security and Cryptography
26
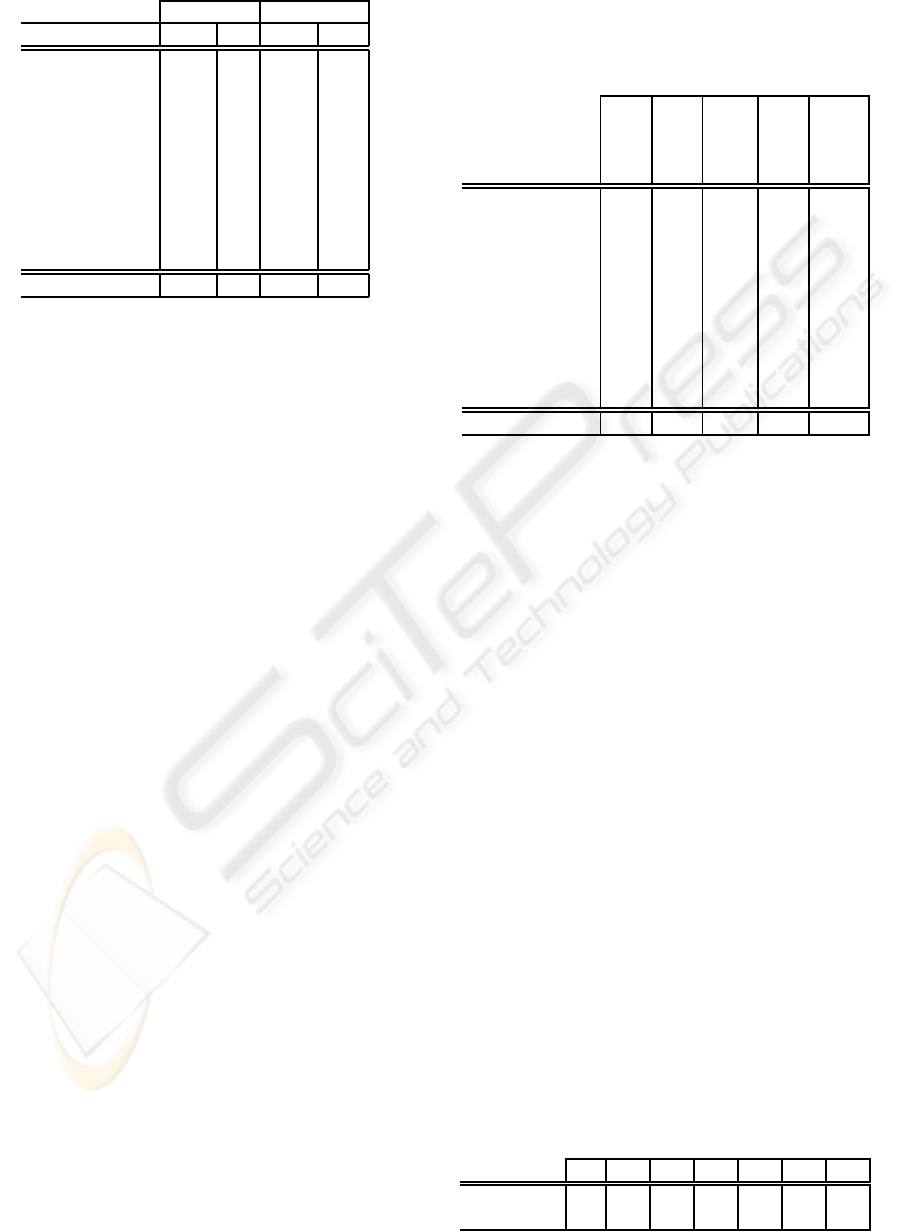
Table 1: Training/testing data set distribution.
Training data Testing data
Class Number % Number %
Normal connections 55342 100% 61378 58.41%
Buffer overflow – – 18 0.02%
Input validation – – 46 0.04%
Value misinterpretation – – 2 0.001%
Poor management – – 3 0.001%
Flooding – – 12485 11.88%
Vulnerability scan – – 31152 29.64%
Cross Site Scripting – – 6 0.01%
SQL injection – – 14 0.01%
Command injection – – 9 0.01%
Total 55342 100% 105084 100%
garding attacks effects, attacks of Table 1 include de-
nia
l of service attacks, Scans, information leak, unau-
thorized and remote access (Inghamand Inoue,2007).
4.3 Comparison of Thresholding and
Aggregation Schemes
Table 2 compares results of different thresholding and
aggregation schemes described in section 3. Note that
the different schemes compared in Table 2 are:
• Non Weighted Sum-based Aggregation: This is
a standard scheme using a non weighted sum and
a maximum-based global threshold (see Equation
3). It is used as a reference scheme for evaluating
our aggregation and thresholding ones.
• Local Thresholding: This scheme aims at de-
tecting intra-model anomalies and it is relies on
thresholding of Equation 2.
• Global Thresholding: Global thresholding aims
at detecting anomalies violating inter-model reg-
ularities. We used a BN built on anomaly score
records computed for audit event using the differ-
ent detection models. Note that structure learn-
ing is performed using the hill-climbing algorithm
(Heckerman et al., 1995). We fixed anomaly
thresholds according to Equation 4.
• Local+Global Thresholding: This scheme takes
advantage of both local and global thresholding
schemes in order to detect both intra-model and
inter-model anomalies.
Note that all the anomaly thresholds are computed on
normal training data and we do not use any discount-
ing/enhancing parameter θ (θ=1). Table 2 compares
on one hand results of a sum-based aggregation us-
ing a single global threshold with a sum-based ag-
gregation combined with local and global threshold-
ing. On the other hand, we evaluate the Bayesian-
based approach using a single global threshold and
the combination of the local and global thresholding
with Bayesian-based aggregation.
Table 2: Evaluation of different aggregation/threshodling
schemes on http traffic.
Sum Bayes
Sum- aggreg+ aggreg+
based local local Bayes local
Audit event class aggreg thresh thresh aggreg thresh
Normal connections 99.94% 97.37% 97.37% 99.79% 99.66%
Buffer overflow 16.67% 94.44% 94.44% 27.78% 94.44%
Input validation 2.17% 86.96% 86.96% 23.91% 91.30%
Value misinterpretation 100% 100% 100% 50% 100%
Poor management 100% 100% 100% 66.67% 100%
Flooding 95.46% 99.62% 99.62% 86.22% 99.93%
Vulnerability scan 0.00% 51.84% 51.84% 83.06% 90.56%
Cross Site Scripting 0.00% 100% 100% 100% 100%
SQL injection 0.00% 100% 100% 100% 100%
Command injection 0.00% 100% 100% 100% 100%
Total 69.72% 84.16% 84.16% 93.20% 97.02 %
Firstly, Table 2 shows that our schemes perform bet-
ter
than the reference sum-based scheme. Moreover,
it is important to note that most attacks induce only
intra-model anomalies and can be detected without
any aggregation. In fact, the combination of sum-
based scheme with local thresholding significantly
enhances the detection rates without triggering higher
false alarm rates. Similarly, Bayesian aggregation en-
hanced with global thresholding achieves better re-
sults regarding detection rates and false alarm rate.
Note that best results are achieved by Bayesian aggre-
gation combined with local and global thresholding
schemes (see correct classification rates over normal
connections and Web attacks). This is due to the fact
that this scheme detects both intra-model and inter-
model regularities learnt by the Bayesian network.
4.4 Evaluation of Ranking-based
Thresholding
Table 3 provides results of ranking-based threshold-
ing evaluation on http traffic involving normal traf-
fic and several Web-based attacks (see Table 1). For
different anomaly thresholds, Table 3 shows the true
positive rate (attacks for which alerts are raised) and
underlying false alarm rate.
Table 3: Evaluation of ranking-based thresholding on http
traffic.
Threshold 0.1% 1% 2% 3% 4% 5% 10%
True positive rate 100% 99.4% 98.4% 97.2% 96.3% 94.1% 92.7%
False alarm rate 0% 0.57% 1.51% 2.73% 3.63% 5.89% 7.24%
NEW SCHEMES FOR ANOMALY SCORE AGGREGATION AND THRESHOLDING
27

It is important to note that this evaluation is carried
ou
t in off-line mode. Results of Table 3 clearly show
that when ranked according to anomaly scores, most
anomalous events are actually attacks. For instance,
when anomaly threshold is set to 0.1% of analyzed
events, then all the triggered alerts are actually caused
by attacks. Setting the anomaly threshold to greater
values causes true positive rate to decrease slightly
while false alarm rate proportionally increases. Note
that most false alarms correspond to new and unusual
audit events. Given that security administrators can
only check small amounts of alerts, then ranking-
based thresholding is an interesting scheme since it
focuses on most anomalous events.
5 CONCLUSIONS
The main objective of this paper is to address anomaly
thresholding and aggregating issues in multi-model
anomaly detection approaches. We proposed a two-
stage thresholding scheme suitable for detecting in
real-time intra-model and inter-model anomalies. In
order to cope with large numbers of alerts charac-
terizing most anomaly-based IDSs, we proposed a
ranking-based thresholding method allowing to limit
the alert quantities while focusing on most anoma-
lous events. As for anomaly score aggregation, we
proposed to use a Bayesian network whose struc-
ture can be fixed by the expert or extracted auto-
matically from attack-free training data. Experimen-
tal studies carried out on real and recent http traffic
showed that most Web-related attacks induce intra-
model anomalies and can be detected in real-time us-
ing local thresholding scheme. Future works will ex-
plore the application of our schemes in order to detect
anomalies and attacks when input data relative to au-
dit event is uncertain or missing.
ACKNOWLEDGEMENTS
This work is supported by a French national project
entitled DADDi.
REFERENCES
Angiulli, F., Basta, S., and Pizzuti, C. (2006). Distance-
based detection and prediction of outliers. IEEE
Trans. on Knowl. and Data Eng., 18(2):145–160.
Axelsson, S. (2000). Intrusion detection systems: A sur-
vey and taxonomy. Technical Report 99-15, Chalmers
Univ.
Benferhat, S. and Tabia, K. (2008). Classification features
for detecting server-side and client-side web attacks.
In 23rd International Security Conference, Italy.
Denning, D. E. (1987). An intrusion-detection model. IEEE
Trans. Softw. Eng., 13(2):222–232.
Ertz, L., Eilertson, E., Lazarevic, A., Tan, P.-N., Kumar,
V., Srivastava, J., and Dokas, P. Minds - minnesota
intrusion detection system.
Gerhard Mnz, S. L. and Carle, G. (2007). Traffic anomaly
detection using k-means clustering.
Gowadia, V., Farkas, C., and Valtorta, M. (2005). Paid: A
probabilistic agent-based intrusion detection system.
Computers & Security, 24(7):529–545.
Heckerman, D., Geiger, D., and Chickering, D. M. (1995).
Learning bayesian networks: The combination of
knowledge and statistical data. Machine Learning,
20(3):197–243.
Ingham, K. L. and Inoue, H. (2007). Comparing anomaly
detection techniques for http. In RAID, pages 42–62.
Javits and Valdes (1993). The NIDES statistical component:
Description and justification.
Jensen, F. V. (1996). An Introduction to Bayesian Networks.
UCL press.
Kruegel, C., Mutz, D., Robertson, W., and Valeur, F. (2003).
Bayesian event classification for intrusion detection.
In Proceedings of the 19th Annual Computer Security
Applications Conference, page 14, USA.
Kruegel, C. and Vigna, G. (2003). Anomaly detection of
web-based attacks. In CCS ’03: Proceedings of the
10th ACM conference on Computer and communica-
tions security, pages 251–261, New York, NY, USA.
Kruegel, C., Vigna, G., and Robertson, W. (2005). A multi-
model approach to the detection of web-based attacks.
volume 48, pages 717–738.
Krugel, C., Toth, T., and Kirda, E. (2002). Service specific
anomaly detection for network intrusion detection. In
Proceedings of the 2002 ACM symposium on Applied
computing, pages 201–208, USA.
Lee, W. and Xiang, D. (2001). Information-theoretic mea-
sures for anomaly detection. In Proceedings of the
IEEE Symposium on Security and Privacy, USA.
Neumann, P. G. and Porras, P. A. (1999). Experience with
EMERALD to date. In First USENIX Workshop on
Intrusion Detection and Network Monitoring, pages
73–80, Santa Clara, California.
Snort (2002). Snort: The open source network intrusion
detection system. http://www.snort.org.
Staniford, S., Hoagland, J. A., and McAlerney, J. M. (2002).
Practical automated detection of stealthy portscans. J.
Comput. Secur., 10(1-2):105–136.
Tombini, E., Debar, H., Me, L., and Ducasse, M. (2004).
A serial combination of anomaly and misuse idses
applied to http traffic. In Proceedings of the 20th
Annual Computer Security Applications Conference,
pages 428–437.
Valdes, A. and Skinner, K. (2000). Adaptive, model-based
monitoring for cyber attack detection. In Proceed-
ings of the Third International Workshop on Recent
Advances in Intrusion Detection, pages 80–92, UK.
SECRYPT 2008 - International Conference on Security and Cryptography
28
