
A DOCUMENT MANAGEMENT SYSTEM AND WORKFLOW TO
HELP AT THE DIAGNOSIS OF HYPERTROPHIC
CARDIOMYOPATHY
Lorenzo Montserrat
Departamento de Cardiolog´ıa, Hospital Juan Canalejo, A Coru˜na, Spain
Jose Antonio Cotelo-Lema, Miguel R. Luaces, Diego Seco
Database Lab., University of Coru˜na, Campus de Elvi˜na, S/N 15071, A Coru˜na, Spain
Keywords:
e-Health, Document Management System, Hypertrophic Cardiomyopathy.
Abstract:
We present in this paper the architecture and some implementation details of a Document Management System
and Workflow. This system is used to help in the diagnosis of the Hypertrophic Cardiomyopathy, one of the
most frequent genetic cardiovascular diseases. The system allows a gradual and collaborative creation of
a knowledge base about the mutations associated with this disease. The system manages both the original
documents of the scientific papers and the data extracted from this papers by the experts. Furthermore, a
semiautomatic report generation module exploits this knowledge base to create high quality informs about the
studied mutations.
1 INTRODUCTION
In the last decades, Document Management Systems
(DMS) have become indispensable for many organi-
zations. The majority of organizations need to access
and consult stored information frequently. Thus, effi-
ciency requirements must be considered by the Docu-
ment Management Systems in order to provide a fast
access to the information. Furthermore, documents
need to pass from one person to another in many of
these organizations. Therefore, DMS must define a
set of rules for this process (a workflow process).
We present in this paper a Document Manage-
ment System and Workflow for a medical organiza-
tion (Health In Code
1
). This system allows the cre-
ation, management, and exploitation of a knowledge
base about genetic mutations associated with the Hy-
pertrophic Cardiomyopathy (HCM).
Health In Code is a medical company dedicated to
the identification of health problems that can benefit
from a genetic diagnosis. Family heart diseases are
the main field of work at this organization. Usually,
these heart diseases have a genetic origin and they af-
fect to the myocardium. They usually have heteroge-
neous symptoms and a hard to predict clinical evolu-
1
http://www.healthincode.com
tion. HCM is one of the most important family heart
diseases. Furthermore, it is one of the most frequent
genetic cardiovascular diseases. It has a prevalence
of 1:500 in the general adult population (one of each
five hundred people suffer this disease). Moreover, it
is the most frequent cause of sudden death in young
adult people, adolescents, and sportsmen. Clinical di-
agnosis of this disease is very complex, and there are
many problems to determine a prediction and opti-
mum treatment because more than 400 different mu-
tations in more than 10 different genes can be the ori-
gin of the HCM.
The Document Management System that we
present in this paper makes possible a comprehen-
sive genetic diagnosis of all the mutations and genetic
variants associated with the HCM, where the differ-
ential diagnosis can be confuse. Furthermore, this
system makes possible to identify many genetic in-
teractions. Thousands of papers related to the HCM
are published each year, and many of these papers are
contradictory. Therefore, most of this information is
completely ignored by people in charge of the diag-
nosis of the disease. The system that we present can
help clinicians to take into account this information,
and thus, it can help to improve the clinical diagnosis.
There are a lot of people that can be benefit from this
improvement:
3
Montserrat L., Cotelo-Lema J., Luaces M. and Seco D. (2009).
A DOCUMENT MANAGEMENT SYSTEM AND WORKFLOW TO HELP AT THE DIAGNOSIS OF HYPERTROPHIC CARDIOMYOPATHY.
In Proceedings of the International Conference on Health Informatics, pages 3-10
DOI: 10.5220/0001429400030010
Copyright
c
SciTePress
• Patients with a clinical diagnosis about HCM
(80000 people in Spain, more than 500000 peo-
ple in the EU, etc.).
• Relatives of these patients (a mean of 4 per pa-
tient).
• Patients with left ventricular hypertrophy with
doubts about the possibility of HCM. We consider
in this group hypertensive patients with moderate
to severe hypertrophy (5% of the hypertensives),
differential diagnosis with athlete’s heart, obese
patients with hypertrophy, etc.
• Patients with an abnormal electrocardiogram
(ECG) without apparent cause.
• Sudden death patients.
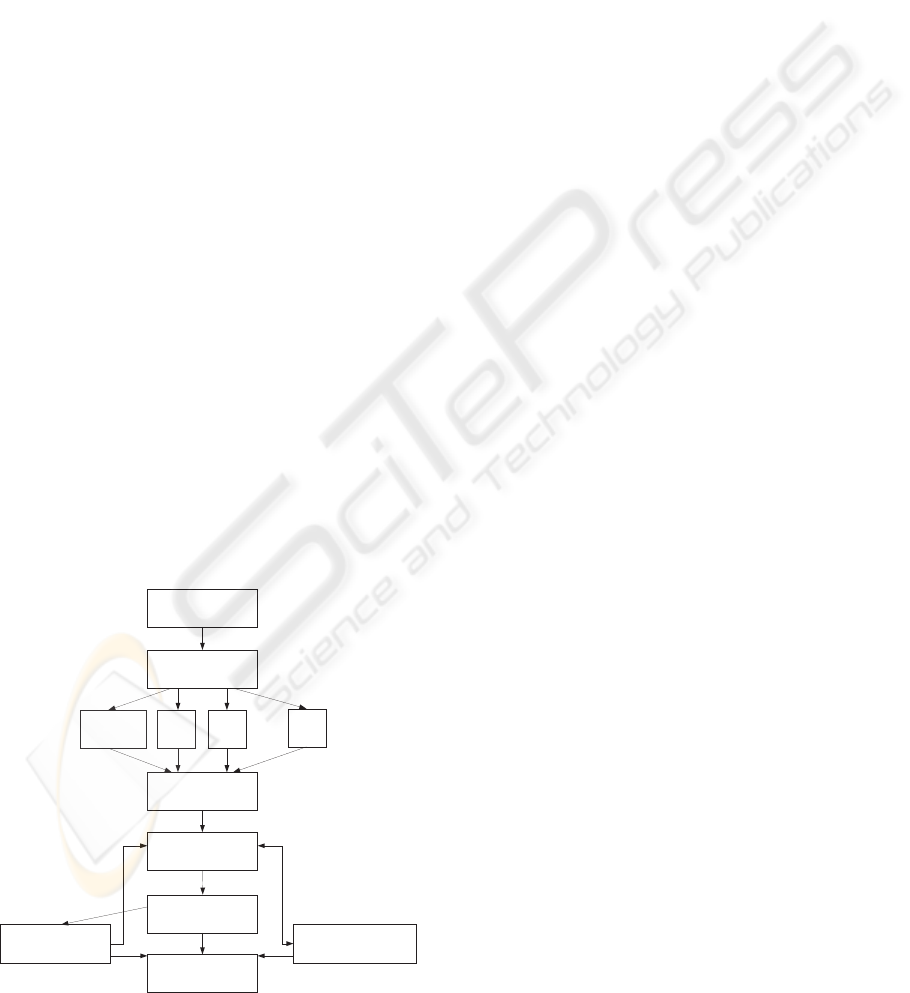
Figure 1 shows the operativeprocess supported by
the developed system. First, interesting scientific pa-
pers are collected by a group of documentalists from
different databases, conferences, journals, etc. After
that, the scientific committee evaluates these papers.
Selected papers that pass the quality controls are as-
signed to the experts who are in charge of reviewing
them. A critical reading of the paper is the first task
that must be done by these experts. After that, they
have to analyze the data about patients described in
the paper and they have to type these data in the appli-
cation. An evaluation of the quality of the information
is done by the scientific committee at this stage of the
process. When the process passes these controls, the
information is marked as valid and it becomes part of
the knowledge base.
This operative process ends with an e-commerce
stage where clients provide samples about patients
DOCUMENTALISTS
SCIENTIFIC
COMMITTEE
EXPERT 1 E2
En
E3
...
DATABASES
SCIENTIFIC
COMMITTEE
FINAL REPORT
CLIENT
REPORTS
DATABASE
FEEDBACK
Figure 1: Operative Process.
and the companyanalyzes these samples and provides
all the relevant clinical information available about
the identified mutations. A semi-automatic subsys-
tem to generate reports about mutations is the base of
the business model of the company. In this context,
a report is a set of pre-processed information from
the knowledge base or a meta-analysis of the infor-
mation about each mutation. These reports must be
reviewed and edited to elaborate the final version of
them. These final reports are elaborated for all the
mutations identified in the samples provided by the
clients. The company does not replace clinicians, but
it supplies them with the best tools to take the best
decisions based on the available knowledge of each
mutation. Furthermore, the operative process con-
templates a feedback offer where clients can provide
clinical information about new mutation carriers and
their relatives. This information is evaluated and in-
troduced in the knowledge base if it passes the qual-
ity controls. The company offers the possibility of
reinterpreting the mutation implications when clients
provide clinical details about these new mutation car-
riers.
Therefore, the operative process requires the or-
dered execution of a set of activities, with several peo-
ple participating in each of them. In such a complex
process, the lack of control on the workflow can re-
sult in dead times, errors in the obtained results, and
loss of data. In general, an unsatisfactory coordina-
tion of the people increases the overall cost and de-
creases the quality of the results. Because this process
requires significant effort, the more automated tools
that can be built and used, the better the use of human
resources will be. The control of the workflow inside
this work team is a key factor in the success of the
process. This control can be achieved by the use of
a workflow management tool specially designed for
this process. That is, a system which allows to coordi-
nate and control all the involved people, monitor and
manage factors as the current state of each scientific
paper, store intermediate results, control the average
time to process each document, record all the people
who have worked in each scientific paper, etc.
The rest of the paper is organized as follows. First,
in Section 2 the architecture of the system and some
technical details are described. Then, in Section 3,
we present the user interface of the collaborativeweb-
based application to create the knowledge base. After
that, the interest of its use is emphasized in Section 4.
Finally, Section 5 presents the conclusions and some
ideas for future lines of work.
HEALTHINF 2009 - International Conference on Health Informatics
4

2 SYSTEM ARCHITECTURE
AND TECHNOLOGY
2.1 System Architecture
According to (Hollingsworth, 1995), workflow is con-
cerned with the automation of procedures where doc-
uments, information, or tasks are passed between par-
ticipants following a defined set of rules to achieve
or contribute to an overall business goal; the com-
puterized facilitation or automation of a business pro-
cess, in whole or part. Workflow management sys-
tems can be classified in several types depending on
the nature and characteristics of the process (van der
Aalst and van Hee, 2002)(Fischer, 2003). Collabo-
rative workflow systems automate business processes
where a group of people participate to achieve a com-
mon goal. This type of business processes involves a
chain of activities where the documents, which hold
the information, are processed and transformed until
that goal is achieved. As the problematic of building a
repository about mutations associated with the Hyper-
trophic Cardiomyopathy (HCM) fits perfectly in this
model we based the architecture of the system in this
model.
In general, we can differentiate three user profiles
involved in the repository building:
• Administrator. Administrators are the people re-
sponsible of the process as a whole. They are
the responsible of managing (add/delete/update)
users and controlling the state of the application.
• Supervisor Users. The supervisor users are the
people in charge of carrying out critical activities
such as the metadata storage, assigning tasks to
different workers (inspectors), or supervise their
work. They are members of the scientific com-
mittee and they are in charge of performing the
quality controls over the scientific papers and the
inspection process.
• Inspector Users. The inspector users are the work-
ers who carry out tasks such as inspecting scien-
tific papers. This task involves a critical reading of
the paper and typing relevant data in the system.
This role is played by users with some knowl-
edge in the mutations associated with the HCM
but without any responsibility on the management
of the system.
Supervisor and inspector users are the two user
profiles involved in the repository building process.
Therefore, a communication protocol between these
user profiles has been implemented. Supervisor users
can publish news, send messages to the inspector
users, and answer their questions.
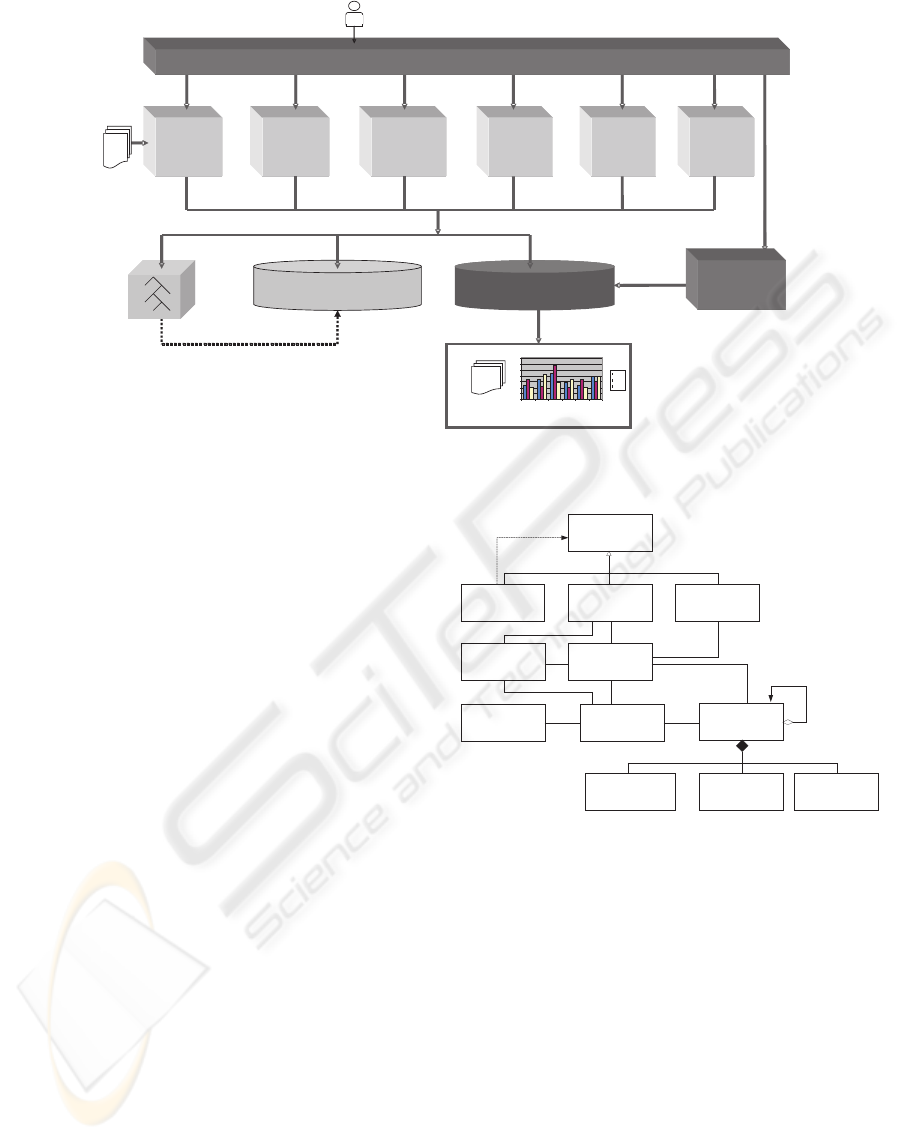
Figure 2 shows the overall system architecture.
When we define it, we followed the recommenda-
tions of the Workflow Reference Model (van der Aalst
and van Hee, 2002), a commonly accepted framework
for the design and development of workflow manage-
ment systems, intended to accommodate the variety
of implementation techniques and operational envi-
ronments which characterize this technology. Thus,
although we used this architecture for the implemen-
tation of a specific system, it can be used in other en-
vironments and situations. Furthermore, design pat-
terns (Gamma et al., 1996)(Grand, 1998)(Alur et al.,
2003) were used in order to obtain a modular, robust,
and easily to extend architecture.
As we can see in the Figure 2, the authentication
and authorizing module is in charge of the authentica-
tion of the workers who want to access to the system.
Each user has a system role depending on the tasks
he/she is going to work on. In terms of this system
role, the authorizing module only provides the user
with access to the needed features. The system ar-
chitecture is composed of a module for each activity
carried out during the operative process.
• Scientific Papers Selection. As we noted in the
previous section, thousands of scientific papers re-
lated to the HCM are published each year. There-
fore, the scientific committee has to select the
most prominent papers. This subsystem provides
integration with software for publishing and man-
aging bibliographies such as EndNote
2
.
• Metadata Storage. This subsystem is in charge of
the introduction and storage of the metadata for
each scientific paper (title, author, year, source,
described mutations, etc.). Furthermore, each pa-
per must be assigned to the inspector user who
will be in charge of analyzing it. This task is
performed by the supervisor users of the system,
therefore only they have access to this module.
• Inspection Process. This module allows inspec-
tor users to access the scientific papers previously
assigned to them. They analyze these papers and
type relevant data in the application.
• Supervision process. It provides access to the sci-
entific papers and analyzed data introduced using
the previous module. This task is performed by
the supervisor users who are in charge of perform-
ing quality controls about the previous stage.
• Correction. If supervisor users detect some mis-
takes in the inspection process they can correct
them using this module. Moreover, supervisor
users can delegate this task to the inspector.
2
http://www.endnote.com
A DOCUMENT MANAGEMENT SYSTEM AND WORKFLOW TO HELP AT THE DIAGNOSIS OF
HYPERTROPHIC CARDIOMYOPATHY
5
Index
Document
Database
Workflow
Database
Reports
0
5
1 0
1 5
2 0
2 5
3 0
3 5
E n e F e b Ma r Ab r M a y Jun
Co mid a
T ran sp o rte
A loja mien to
Statistics
PublishingCorrectionSupervision
Process
Inspection
Process
Reports
Publishing
Workflow
Administration
module
Administrators
System users
(inspector, supervisor, and administrator users)
Scientific
Papers
Metadata
storage
Identification and authorizing module
Figure 2: System architecture.
• Publishing. Once the analysis process is accepted,
this module is in charge of committing its con-
tents.
• Reports Publishing. Reports about the mutations
associated with the HCM can be generated using
the data analyzed in previous stages of the work-
flow. Supervisor users must review and edit these
reports in order to commercialize them. This sub-
system provides functionalities to generate, edit,
and store the reports in a database.
• Workflow Administration Module. This subsystem
is in charge of managing the workflow between all
these activities. It also providesreporting tools for
monitoring purposes.
2.2 Data Model
Figure 3 shows our proposal for the data model that
supports the architecture. This data model is orga-
nized around the entities Paper and Report. Both of
them constitute the core of this architecture because
the system is feeding with information from the pa-
pers, and the reports are generated by the system to
be commercialized.
As we noted before, both scientific papers ana-
lyzed by the experts and the resultant information
of this analysis are stored together by the Document
Management System (DMS). Therefore, the entity
paper (and the entities associated with it such as mu-
tation, gene, and patient) represents both the origi-
nal scientific paper (scanned PDF file, title, authors,
PATIENT
GENE MUTATION
1
*
* *
DEMOGRAPHIC
VARIABLES
GENOTYPE PHENOTYPE
USER
ADMIN SUPERVISOR INSPECTOR
PAPER
1
*
*
1
*
*
<<MANAGES>>
1
*
REPORT
* *
*
*
*
1
FAMILY
Figure 3: Data Model.
and other metadata) and the data obtained from the
analysis of this paper (mutations associated with each
paper, number and type of control cases, information
about described patients, etc.).
Furthermore, the workflow process described in
the previous section is contemplated, and therefore,
there are several entities in the data model to support
it. Admin, Supervisor, and Inspector represent the
three User profiles involved in the workflow process.
All the entities, and modules that manage these enti-
ties, are associated with a set of user profiles. There-
fore, only these user profiles have access to the infor-
mation stored in such entities.
The most important characteristic of a DMS is the
informationthat can be managed with it. As we noted,
Paper is one of the most important entities of the data
HEALTHINF 2009 - International Conference on Health Informatics
6

model. Metadata about original scientific papers are
directly stored in this entity. Data obtained from the
analysis of the papers are organized centred around
the entity patient. Therefore there are a relationship
between the entities paper and patient (a paper de-
scribes N patients and a patient is described in 1 pa-
per). Thousands of scientific papers about the muta-
tions associated with the Hypertrophic Cardiomyopa-
thy (HCM) have been published in journals, confer-
ences, etc. Moreover there are many internal docu-
ments in cardiology departments of the hospitals that
describe patients with these mutations. Both types of
data sources describe patients and information about
their relatives to a greater or lesser extent. Informa-
tion about these families can be entered in the system
in a very intuitive, progressive, and simple way (the
carefully designed user interfaces can be seen in Sec-
tion 3). Information about patients and their relatives
can be categorized in the following types:
• Identification Data. Both application internal
identifiers (patient identifier, family identifier,
etc.) and external domain identifiers (position in
the pedigree) are included in this category.
• Demographic Variables. Data about the sex, eth-
nicity, age at the diagnosis of the disease, etc. are
included here.
• Genotype. This category includes the results of
the genotype study. These results present the re-
lationship between the patients and the mutations
associated with the paper where the patient is de-
scribed. Obligate carrier, homozygous carrier,
normal carrier, and not carrier are the possible
values for this relationship. However, not all the
scientific papers describe this relationship for all
the mutations and patients. Therefore, an un-
known value is available for the relationship. This
philosophy is applicable for most of the variables
managed by the system.
• Phenotype. This category includes the results of
the different clinical tests that can be done in or-
der to determine the appearance of a patient re-
sulting from the interaction of the genotype and
the environment. There are several subcategories
in accordance with its nature. First, results about
the clinical diagnosis are collected. These results
determine whether the patient is affected or not
by some phenotypes, which phenotypes, etc. The
second group includes environmental factors or
triggers (alcohol, hypertension, tobacco, obesity,
etc.). There are many variables that can be de-
termined in a echocardiography,MRI, or autopsy.
These variables constitute the third group. Hyper-
trophy, dilatation, systolic and diastolic dysfunc-
tions are some examples of these variables. The
fourth group includes symptoms and risk factors
(dyspnea, chest pain, abnormal blood pressure
response, etc.). Variables of the ECG (rhythm,
pre-excitation, abnormal voltage or repolariza-
tion) constitute the fifth group. The sixth group
includes data about the electrophysiological study
(inducibility of malignant arrhythmias, conduc-
tion disturbance, etc.). Finally, the last two groups
include data about the treatment (medical treat-
ment, surgery, etc.) and the events (death, cere-
brovascular accident, etc.).
In brief, more than 200 variables are currently col-
lected about each patient. However, new variables of
interest can be easily introduced in the system.
2.3 Technology
This section briefly describes the most important tech-
nologies used in the development of the system. First,
Java 2 Platform, Enterprise Edition (J2EE) (Perrone
and Chaganti, 2003)(Bodoff, 2004) was the selected
development platform. J2EE is a widely-used plat-
form for server programming. This platform allows
developers to create portable and scalable applica-
tions. J2EE provides a set of technologies that make
the development process easier. JDBC (an API to
access relational databases), JavaServer Pages (JSP,
a technology to dynamically generate HTML), or
JavaServer Pages Standard Tag Library (JSTL, a tag
library for JSP) are several examples of such tech-
nologies provided by J2EE and used in this project.
Furthermore, other technologies can be easily inte-
grated with this platform. For example, Jakarta Struts
(Holmes, 2006), a framework that allows software en-
gineers to develop applications following the archi-
tectural patterns Model-View-Controller and Layers,
has been used. CSS (Shafer, 2003) is the technology
used to enhance the user interface. Finally, we have
widely used JavaScript (Flanagan, 2006) to improve
the dynamism and interaction of the user interface.
Technologies employed in the development of the
reports generation module deserve special mention.
eXtensible Stylesheet Language Formatting Objects
(XSL-FO) (W3C Recommendation, 2006) is the most
important technology used in this module. XSL-FO
is a mark-up language for XML document format-
ting which is most often used to generate reports. An
XSL-FO document is an XML document where the
format of a dataset is defined. This format defines the
presentation of these data in a paper, screen, or other
media. The XSL-FO document does not describe the
layout of the text on various pages. Instead, it de-
scribes what the pages look like and where the various
A DOCUMENT MANAGEMENT SYSTEM AND WORKFLOW TO HELP AT THE DIAGNOSIS OF
HYPERTROPHIC CARDIOMYOPATHY
7
contents go. However, the developed system does not
write XSL-FO documents. An XSLT transformation
is used to convert the semantic XML, generated from
data in the knowledge base of the system, into XSL-
FO documents. This issue is very important because it
provides independence between data and their output
format. Finally, Apache FOP (Apache FOP, 2007) is
used to render the XSL-FO document to a specified
output format. Output formats currently supported
by Apache FOP include PDF, PS, PCL, AFP, XML,
Print, AWT and PNG, RTF and TXT. The primary
output target is PDF. However, our system generates
RTF documents because the reports must be editable
by the experts.
3 USER INTERFACES
The usability of the system is a key factor to guar-
antee its acceptance. In this context, this term de-
notes the ease with which users employ the appli-
cation (Shneiderman, 1998). Therefore, in applica-
tion domains where users do not have the required
expertise level about computers, it is very important
to design the user interfaces in accordance with the
user preferences. For example, this system is used by
experts in Hypertrophic Myocardiopathy (HCM) but
they do not have to know the way typical web appli-
cations work. The main issues of the user interface
design are presented in this section.
Typing in the application the data resultant from
the analysis of the scientific papers is the most ex-
pensive task. An average time of 3 hours has been
estimated by the experts in charge of this task. There-
fore, the user interface has to allow doing this task
in several steps. Furthermore, scientific papers about
the HCM usually present a common format. Patients
and their relatives are described to a greater or lesser
extent. However, sometimes these descriptions are or-
ganized by family, other times they are organized by
type of data, etc. Therefore, the user interface has to
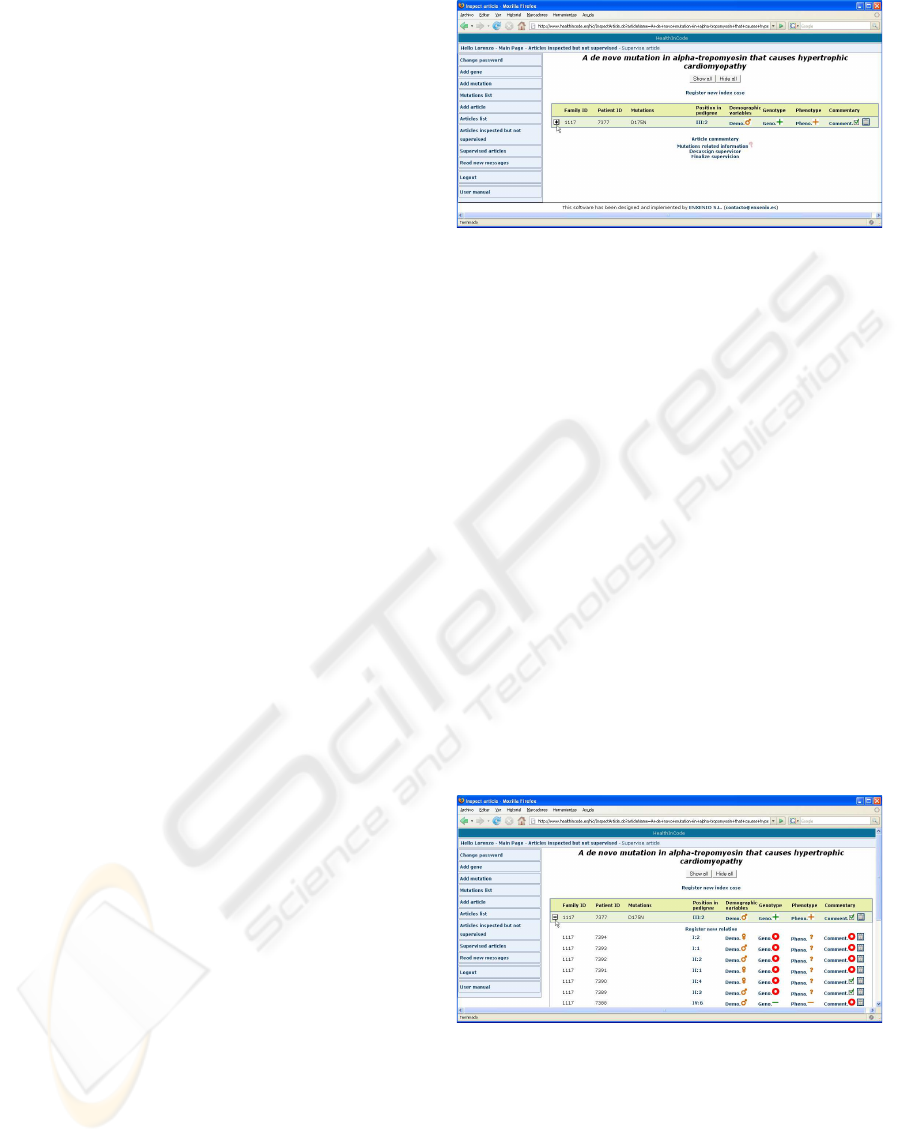
take this issue into account. Figure 4 shows the devel-
oped user interface for typing data resultant from this
process in the system.
The most important feature of this user interface is
that it can manage a lot of information in each screen.
As we noted before, each article can describe several
families and each of them could have tens of studied
cases. Moreover, more than 200 variables about each
studied case are collected in the system. The designed
interface provides the users with a centralized access
point where they can introduce, consult and update
all the data about the studied cases described in an
article. Furthermore, a requirement of flexibility has
Figure 4: Screenshot of the user interface (I).
been considered in the design of this interface. The
experts that have to enter the data in the application
can do it following the same organization presented in
the original scientific paper. For example, they can in-
troduce the data that identify all the patients and their
relatives and, after that, they can complete other in-
formation such as genotype, phenotype, etc. But, they
could type all the data about a patient before introduc-
ing other one. Some graphical icons help the user to
know the state of each data category.
This design of the user interface implies that there
is a lot of information in the same screen. All this
information is organized and categorized in a natu-
ral way for the experts that have to use the system.
First, data about each patient are organized in cate-
gories (demographic variables, genotype, phenotype,
etc.). Moreover, these patients are grouped in fami-
lies. A dynamic technique has been used in the im-
plementation of the interface that allows the experts
to fold and unfold the families. Figure 5 presents the
same family of the previous screenshot unfolded.
Figure 5: Screenshot of the user interface (II).
These screenshots belong to a small example, with
just a few cases, to improve the quality of the fig-
ures. However, there are scientific papers where more
than one thousand cases are described. These papers
would be unapproachable without the techniques pre-
sented in this work.
HEALTHINF 2009 - International Conference on Health Informatics
8

4 USE INTEREST
The main goal of this section is to emphasize the use-
fulness of the development system. As we noted in
previous sections, thousands of scientific papers about
the mutations related to the Hypertrophic Cardiomy-
opathy are published each year. Therefore, the task of
generating reports that summarize each of these muta-
tions would be unapproachable without a system like
the one presented in this paper. There are two key
factors in the design of the system. First, our system
defines a workflow process. The scientific document
repository building requires the ordered execution of
a set of activities on the documents, with several peo-
ple participating in each of them. In such a complex
process, the lack of control on the workflow can result
in dead times, errors in the obtained results and loss of
data. Second, our system is web-based. This allows
the users to collaborate all over the world in order to
keep the information constantly up to date.
Nowadays, there are 50 users registered in the sys-
tem. One of this users has the role of administrator,
20 users havethe role of supervisor, and 29 users have
the role of inspector. These users have collaborated in
the creation of a database with more than 300 GB of
information. More than 1080 mutations, categorized
in 71 genes, and more than 1030 scientific papers are
registered in the system database. Furthermore, data
about more than 9000 patients (or relatives) described
in these scientific papers are available to generate high
quality reports.
On the other hand, carefully designed user inter-
faces have a significant reduction in the time that ex-
perts need to analyze a scientific paper and to type
relevant data in the application. This means a reduc-
tion of cost for the organization. But also, and much
important, information can be up to date easily with-
out expending a lot of money to hire more experts.
5 CONCLUSIONS AND FUTURE
WORK
We have presented in this paper the architecture and
some implementation details of a Document Manage-
ment System (DMS) to help at the diagnosis of the
Hypertrophic Cardiomyopathy. The creation of the
DMS repository is not a simple process. It requires
the coordination of people and tools to carry out ev-
ery activity that is part of the process. For all these
process to be correctly and efficiently made, it is nec-
essary the use of support tools that facilitate the work
of each participant and ensure the quality of the ob-
tained results.
The proposed workflow strategies and system ar-
chitecture support the control and coordination of
people and tasks involved in the whole process. The
use of this architecture automates the completion of
prone to error activities and optimizes the perfor-
mance of the process and the quality of the obtained
results. This architecture was defined following the
recommendations of the Workflow Reference Model.
Furthermore, several architectural and design patterns
were used in order to obtain a modular, robust, and
easy to extend system. This system was built as a web
application which provides an integrated environment
for the execution of all the tasks.
As lines of future work, the developed system is
going to be applied to new projects of similar charac-
teristics involving other Cardiomyopathies (Dilated,
Restrictive, etc.) and Channelopathies (Brugrada syn-
drome, Long QT syndrome, Short QT syndrome,
etc.). In addition, we are working on different im-
plementations of the activities considered to optimize
the performance of the overall process. Another fu-
ture development could be the extension of the report
generation module in order to support reports about
several mutations. It could be very useful to analyze
some mutations that occur in nearby areas of the pro-
tein. Finally, a statistical module could be developed
to provide research capabilities inside the system. For
example, a study about the correlation between vari-
ables could improve the quality of the final reports.
ACKNOWLEDGEMENTS
This work has been partially supported by “Minis-
terio de Educacin y Ciencia”(PGE y FEDER) ref.
TIN2006-16071-C03-03, and by “Xunta de Galicia”
ref. 2006/4 and ref. 08SIN008E.
REFERENCES
Alur, D., Crupi, J., and Malks, D. (2003). Core J2EE Pat-
terns. Prentice Hall.
Apache FOP (2007). Retrieved from http:// xmlgraph-
ics.apache.org/fop/ in october 2007.
Bodoff, S. (2004). The J2EE Tutorial. Addison-Wesley.
Fischer, L. (2003). Workflow handbook 2003. Future Strate-
gies Inc., USA.
Flanagan, D. (2006). JavaScript: The Definitive Guide, 5th
Edition. O’Reilly.
Gamma, E., Helm, R., Johnson, R., and Vlissides, J.
(1996). Design Patterns: Elments of Reusable Object-
oriented Sofware. Addison-Wesley.
A DOCUMENT MANAGEMENT SYSTEM AND WORKFLOW TO HELP AT THE DIAGNOSIS OF
HYPERTROPHIC CARDIOMYOPATHY
9

Grand, M. (1998). Patterns in Java, volume 1. John Wiley
& Sons.
Hollingsworth, D. (1995). Workflow management coali-
tion - the workflow reference model. Technical report,
Workflow Management Coalition.
Holmes, J. (2006). Struts: The Complete Reference, 2nd
Edition. McGraw-Hill Osborne Media.
Perrone, P. J. and Chaganti, K. (2003). J2EE Developer’s
Handbook. Sam’s Publishing.
Shafer, D. (2003). HTML Utopia: Designing Without Ta-
bles Using CSS. Sitepoint Pty Ltd.
Shneiderman, B. (1998). Designing The user interface,
Strategies for effective Human-computer interaction.
Addison-wesley.
van der Aalst, W. and van Hee, K. (2002). Workflow man-
agement: Models, methods, and systems.
W3C Recommendation (2006). Extensible stylesheet lan-
guage (XSL) version 1.1. Technical report, W3C.
HEALTHINF 2009 - International Conference on Health Informatics
10
