
DISTRIBUTED LEARNING ALGORITHM BASED ON DATA
REDUCTION
Ireneusz Czarnowski and Piotr Je¸drzejowicz
Department of Information Systems, Gdynia Maritime University, Morska 83, 81-225 Gdynia, Poland
Keywords:
Distributed data mining, Distributed learning classifiers, Data reduction, Agent-based approach.
Abstract:
The paper presents an approach to learning classifiers from distributed data, based on a data reduction at
a local level. In such case, the aim of data reduction is to obtain a compact representation of distributed
data repositories, that include non-redundant information in the form of so-called prototypes. In the paper
data reduction is carried out by simultaneously selecting instances and features, finally producing prototypes
which do not have to be homogenous and can include different sets of features. From these prototypes the
global classifier based on a feature voting is constructed. To evaluate and compare the proposed approach
computational experiment was carried out. The experiment results indicate that data reduction at the local
level and next merger of prototypes into the global classifier can produce very good classification results.
1 INTRODUCTION
Usually data mining algorithms base on the assump-
tion that all the training data can be pooled together
in a centralized data repository. In the real life there
are, however, numerous cases where the data have to
be physically distributed due to some constraints (for
example, data privacy or others).
Applying traditional data mining tools to discover
knowledge from distributed data sources may not be
possible (Kargupta et al., 1999). In the real life it is of-
ten unrealistic or unfeasible to collect distributed data
for centralized processing. The need to extract po-
tentially useful patterns out of separated, distributed
data sources created a new, important and challenging
research area, known as the distributed data mining
or knowledge discovery from multi-databases (Xiao-
Feng Zhang et al., 2004).
Recently, several approaches to distributed clas-
sification have been proposed. In (Prodromidis et
al., 2000) a meta-learning process was proposed as
a learning tool for combining a set of locally learned
classifiers into the global classifier. Meta-learning in-
volves running, possibly in parallel, learning algo-
rithms for each distributed database or set of data
subsets from an original database, and than combin-
ing predictions from classifiers learned from the dis-
tributed sources by recursively learning ”combiner”
and ”arbiter” models in a bottom-up tree manner.
Generally, meta-learning methodologies view data
distribution as a technical issue and treat distributed
data sources as parts of a single database. It was
pointed out in (Tsoumakas et al., 2004) that such an
approachoffers rather a narrowviewof the distributed
data mining, since the data distributions in different
locations often are not identical, and is considered as
sub-optimal heuristic.
Tsoumakas et al. (2004) proposed approach based
on clustering local classifier models induced at phys-
ically distributed databases. This approach groups to-
gether classifiers with their similar behavior and with
final indication of a classification model for each clus-
ter that together guarantees a better results than the
single global model. This approach belongs to the
set of methods based on common methodology for
distributed data mining known as a two-stage (Xiao-
Feng Zhang et al., 2004).
Generally, two-stage methods base on extraction
of prototypes from distributed data sources. The first
stage involves the local data analysis, the second com-
bines or aggregates the local results producing the
global classifier.
Another two-stage approach to confront the dis-
cussed problem is to move all data from distributed
repositories to a central location and to merge the data
together for a global model building. Such approach
escapes the sub-optimality problems of local models
combination as it was pointed out by Tsoumakas et
198
Czarnowski I. and JÄ
´
Zdrzejowicz P. (2009).
DISTRIBUTED LEARNING ALGORITHM BASED ON DATA REDUCTION.
In Proceedings of the International Conference on Agents and Artificial Intelligence, pages 198-203
DOI: 10.5220/0001655401980203
Copyright
c
SciTePress

al. (2004). However, moving all data into a central-
ized location can be limited by communication band-
width among sites and may be too expensive. Select-
ing out of the distributed databases only the relevant
data can eliminate or reduce the above restriction. Se-
lection of relevant data at local sites can also speed up
the data transfer for centralized learning and global
knowledge extraction. Selection of relevant data is
very often referred to as data reduction with the objec-
tive to find patterns, called prototypes, references vec-
tors, or regularities within certain attributes (see e.g.,
Liu et al., 1998). Generally, the goal of data reduc-
tion approaches is to reduce the number of instances
in each of the distributed data subsets without loss
of extractable information, to enable either pooling
the data together and using some mono-database min-
ing tools or effectively applying meta-learning tech-
niques. Learning models based on the reduced data
sets combined later into a meta-model seems to be
one of the most successful current approaches to dis-
tributed data mining (Stolfo et al., 1997). Learning
classifiers on the reduced data sets and then combin-
ing them is computationally much more efficient then
moving all distributed data sets into a centralized site
for learning a global model.
The paper deals with a distributed learning clas-
sifier. The proposed approach involves two stages.
At the local level the prototype selection from dis-
tributed data is carried out. Prototypes are selected
by simultaneously reducing data set in two dimen-
sions through selecting reference instances and re-
moving irrelevant attributes. The prototype selection
proposed in this paper is an extension of the approach
introduced by Czarnowski and Je¸drzejowicz (2008a),
where instance reduction only was proposed. In the
present approach the data reduction scheme is car-
ried out independently at each site through applying
an agent-based population search. Thus obtained pro-
totypes do not have to be homogenous and can be
based on different sets of of features. Next, at the
second stage, the prototypes are merged at the global
level and classifier models are combined to produce a
meta-classifier called combiner.
The paper is organized as follows. Section 2 con-
tains problem formulation and provides basic defini-
tions. Section 3 explains the proposed agent-based
population learning algorithm, that has been used for
reducing distributed data sets, and provides details
on how the combiner classifier is constructed. Sec-
tion 4 contains results of the computational experi-
ment carried out with a view to validate the proposed
approach. Finally, the last section contains conclu-
sions and suggestions for future research.
2 DEFINITIONS AND PROBLEM
FORMULATION
The problem of learning from data can be formulated
as follows: Given a data set D, a set of hypothesis H,
a performance criterion P, the learning algorithm L
outputs a hypothesis h ∈ H that optimize P. In pattern
classification application, h is a classifier. The data
D consists of N training examples. Each example is
described by a set of attributes A and is labeled with
a class. The total number of attributes is equal to n.
The goal of learning is to produce a hypothesis that
optimizes the performance criterion (e.g. function of
accuracy of classification, complexity of the hypothe-
sis, classification cost or classification error).
In the distributed learning a data set D is dis-
tributed among K data sources D
1
, . . . , D
K
, with
N
1
, . . . , N
K
respectively, where
∑
K
i=1
N
i
= N and where
all attributes are presented at each location. In the dis-
tributed learning a set of constraints Z can be imposed
on the learner. Such constraints may for example pro-
hibit transferring data from separated sites to the cen-
tral location, or impose a physical limit on the amount
of information that can be moved, or impose other re-
strictions to preserve data privacy. The task of the
distributed learner L
d
is to output a hypothesis h ∈ H
optimizing P using operations allowed by Z.
In case of using prototypes as suggested in this
paper, the data sources D
1
, . . . , D
K
are replaced by re-
duced subsets S
1
, . . . , S
K
of local patterns, which in
general are heterogeneous. In this case A
1
, . . . , A
K
are sets of attributes from sites 1, . . . , K respectively.
However, it is possible that some attributes can be
shared across more then one reduced data set S
i
,
where i = 1, . . . , K.
Thus, the goal of data reduction is to find subset
S
i
from given D
i
by reducing of number of exam-
ples or/and feature selection and with retaining essen-
tially extractable knowledge and preserving the qual-
ity of data mining results. Let the cardinality of the
reduced data set S
i
be denoted as card(S
i
). Then the
following inequality holds card(S
i
) < card(D
i
). Sim-
ilarly, when the cardinality of the set of attributes A
i
is denoted as card(A
i
), the following inequality holds
card(A
i
) < card(A). Ideally card(A
i
) ≪ card(A). It
is expected that the data reduction results in data com-
pression. The instance reduction compression rate C
D
is defined asC
D
=
N
∑
K
k=1
card(S
k
)
. The attribute selection
compression rate C
A
is defined as C
A
=
n
card(
S
K
i=1
A
i
)
.
Overall, data reduction guarantees total compression
equal to C = C
D
C
A
.
DISTRIBUTED LEARNING ALGORITHM BASED ON DATA REDUCTION
199

3 AN AGENT-BASED APPROACH
TO LEARNING CLASSIFIER
FROM DISTRIBUTED DATA
3.1 Main Features of the Proposed
Approach
It is well known that instance reduction, feature selec-
tion and also learning classifier from distributed data
are computationally difficult combinatorial problems
(Dash and Liu, 1997; Rozsypal and Kubat, 2003).
Although a variety of data reduction methods have
been so far proposed in the literature (see, for exam-
ple Dash and Liu, 1997; Raman and Ioerger, 2003,
Rozsypal and Kubat, 2003; Skalak, 1994; Vucetic and
Obradovic, 2000), no single approach can be consid-
ered as superior nor guaranteeing satisfactory results
in the process of learning classifiers.
To overcome some of the difficulties posed by
computational complexity of the distributed data
reduction problem it is proposed to apply the
population-based approach with optimization proce-
dures implementedas an asynchronousteam of agents
(A-Team). The A-Team concept was originally intro-
duced by Talukdar et al. (1996). The design of the
A-Team architecture was motivated by other archi-
tectures used for optimization including blackboard
systems and genetic algorithms. Within the A-Team
multiple agents achieve an implicit cooperation by
sharing a population of solutions, also called individ-
uals, to the problem to be solved. An A-Team can be
also defined as a set of agents and a set of memories,
forming a network in which every agent remains in a
closed loop. All the agents can work asynchronously
and in parallel. Agents cooperate to construct, find
and improve solutions which are read from the shared,
common memory.
In our case the shared memory is used to store a
population of solutions to the data reduction problem.
Each solution is represented by the set of prototypes
i.e. by the compact representation of the data set from
given local level. The team of agents is used to find
the best solution at the local level and them the agent
responsible for managing all stages of the data mining
is activated.
3.2 Solution Representation
Population of solutions to data reduction problem
consists of feasible solutions. A feasible solution s,
corresponding to the set of selected data, is repre-
sented by a string consisting of numbers of selected
reference instances and numbers of selected features.
The first t numbers represent instance numbers from
the reduced data set D
i
, where t is determined by a
number of clusters of potential reference instances.
The value of t is calculated at the initial popula-
tion generation phase, where at first, for each in-
stance from original set, the value of its similarity co-
efficient, proposed by Czarnowski and Je¸drzejowicz
(2004), is calculated, and then instances with identi-
cal values of this coefficient are grouped into clusters.
The second part of the string representing a feasible
solution consists of numbers of the selected features.
The minimum number of features is equal to one.
3.3 Agents Responsible for Data
Reduction
Data reduction is carried out, in parallel, for each dis-
tributed data site. Data reduction, carried-out at a data
site, is an independent process which can be seen as
a part of the distributed data learning. Each data re-
duction subproblem is solved by two main types of
agents. The first one - optimizing agents, are imple-
mentations of the improvement algorithms, each op-
timizing agent represents a single improvement algo-
rithm. The second one, called the solution manager,
is responsible for managing the population of solu-
tions and updating individuals in the population. Each
solution manager is also responsible for finding the
best solution for the given learning classifier subprob-
lem.
The solution manager manages the population of
solutions, which at the initial phase is generated ran-
domly and stored in the shared memory. When the
initial population of solutions is generated the solu-
tion manager runs a procedure producing clusters of
potential reference instances. Next the solution man-
ager continues reading individuals (solutions) from
the common memory and storing them back after
attempted improvement until a stopping criterion is
met. During this process the solution manager keeps
sending single individuals (solutions) from the com-
mon memory to optimizing agents. Solutions for-
warded to optimizing agents for improvement are ran-
domly drawn by the solution manager. Each optimiz-
ing agent tries to improvequality of the received solu-
tions and afterwards sends them back to the solution
manager, which, in turn, updates common memory
by replacing a randomly selected individual with the
improved one.
To solve the data reduction problem four types
of optimizing agents representing different improve-
ment procedures, proposed earlier by Czarnowski and
Je¸drzejowicz (2008b) for the non-distributed case,
have been implemented.
ICAART 2009 - International Conference on Agents and Artificial Intelligence
200

These procedures include: local search with tabu
list for instance selection, simple local search for in-
stance selection, local search with tabu list for feature
selection and hybrid local search for instance and fea-
ture selection, where the both parts of the solution are
modified with the identical probability equal to 0.5.
In each of the above cases the modified solution
replaces the current one if it is evaluated as a better
one. Evaluation of the solution is done by estimat-
ing classification accuracy of the classifier, which is
created taking into account the instances and features
indicated by the solution. In all cases the constructed
classifier is based on the C 4.5 algorithm (Quinlan,
1993).
If, during the search, an agent successfully has
improved the received solution then it stops and
the improved solution is transmitted to the solution
manager. Otherwise, agents stop searching for an
improvement after having completed the prescribed
number of iterations.
3.4 Agent Responsible for Managing
the Process of Distributed Learning
The proposed approach deals with several data reduc-
tion subproblems solved in parallel. The process is
managed by the global manager, which is activated
as the first within the learning process. This agent is
responsible for managing all stages of the data min-
ing. At the first step the global manager reads the dis-
tributed data mining task that should be solved. Than
global manager runs, in parallel, all subtasks, that
correspond to independent learning classifiers prob-
lem.
When all the subtasks have been solved, solutions
from the local level are used to obtain a global solu-
tion. Thus, the global manager merges local solutions
and finally produces the global classifier, called also
meta-classifier.
To compute the meta-classifier a combiner strat-
egy based on voting mechanism has been applied.
This combiner strategy is used to obtain a global clas-
sifier from the global set of prototypes. The global set
of prototypes is created by integration of local level
solutions representing heterogeneous sets of proto-
types. To integrate local level solutions it has been de-
cided to use the unanimous voting mechanism. Only
features that were selected by data reduction algo-
rithms from all distributed sites are retained and the
global classifier is formed based on the C 4.5 algo-
rithm.
4 COMPUTATIONAL
EXPERIMENT RESULTS
To validate the proposed approach computational ex-
periment has been carried out. The aim of the ex-
periments was to evaluate to what extend the pro-
posed approach could contribute towards increasing
classification accuracy of the global classifier induced
on the set of prototypes selected from autonomous
distributed sites by applying an agent-based popula-
tion learning algorithm. Classification accuracy of the
global classifiers obtained using the set of prototypes
has been compared with the results obtained by pool-
ing together all instances from distributed databases,
without data reduction, into the centralized database
and with results obtained by pooling together in-
stances selected from distributed databases based on
the reduction of example space only. Generalization
accuracy has been used as the performance criterion.
The experiment involved three data sets - cus-
tomer (24000 instances, 36 attributes, 2 classes), adult
(30162, 14, 2) and waveform (30000, 21, 2). For
the first two datasets the best known and reported
classification accuracies are respectively 75.53% and
84.46%. These results have been obtained from
(Asuncion and Newman, 2007) and (”The European
Network”, 2002). The reported computational exper-
iment was based on the ten cross validation approach.
At first the available datasets were randomly divided
into the training and test sets in approximately 9/10
and 1/10 proportions. The second step involved the
random partition of the previously generated training
sets into the training subsets each representing a dif-
ferent dataset placed in a separate location. Next,
each of the obtained datasets has been reduced us-
ing the agent-based population algorithm. The re-
duced subsets have been then used to compute the
global classifier using the proposed combiner strat-
egy. Such scheme was repeated ten times, using a dif-
ferent dataset partitions as the test set for each trial.
Computations have been run with the size of ini-
tial population set to 50. A number of repetitions for
each improvement procedure was set to 100.
The above described experiment has been re-
peated four times for the four different partitions of
the training set into a multi-database. The original
data set was randomly partitioned into 2, 3, 4 and 5
multi-datasets of approximately similar size. The re-
spective experiment results are shown in Table 1. The
results cover two independent cases. In the first case
only reference instance selection at the local level has
been carried out, and next the global classifier has
been computed based on the homogenous set of pro-
totypes. In the second case full data reduction at the
DISTRIBUTED LEARNING ALGORITHM BASED ON DATA REDUCTION
201
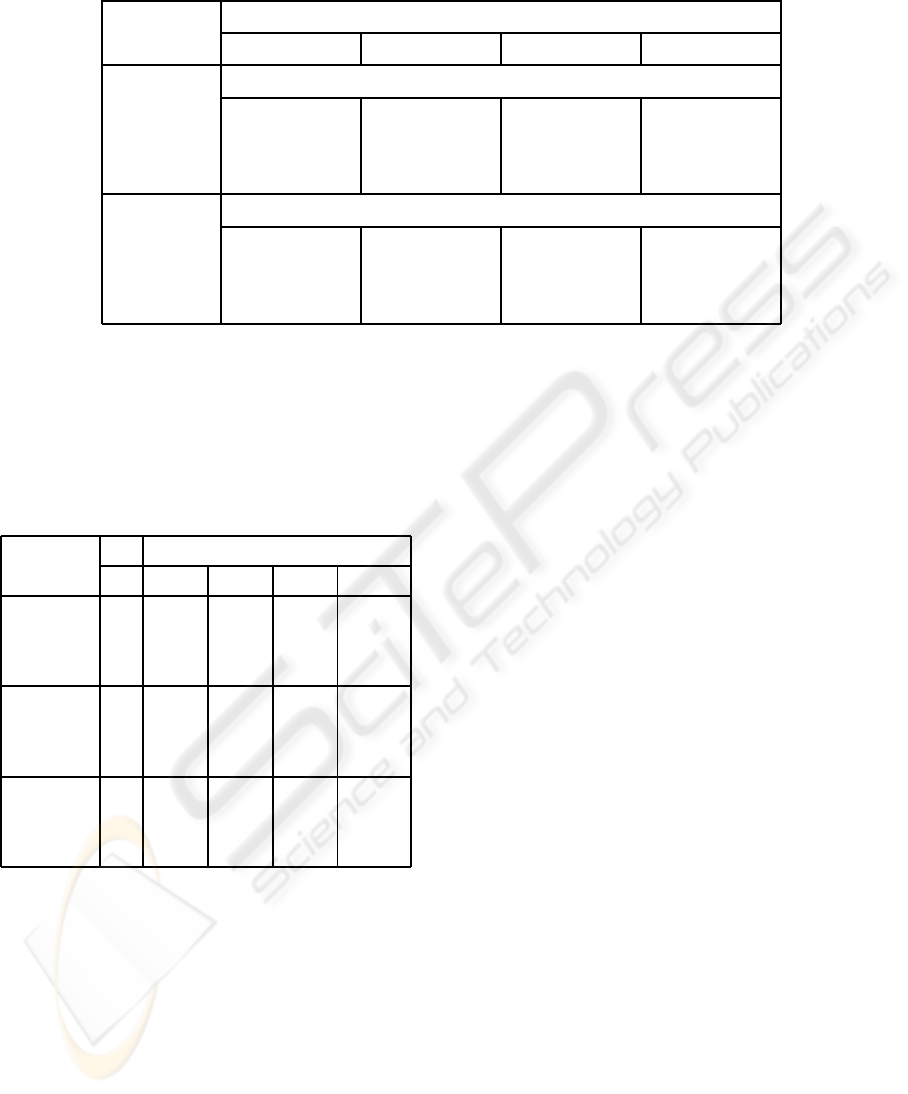
Table 1: Average classification accuracy (%) obtained by the C 4.5 algorithm and its standard deviation.
number of distributed data sources
Problem 2 3 4 5
Selection of reference instances at the local level only
customer 68.45±0.98 70.40±0.76 74.67±2.12 75.21±0.7
adult 86.20 ±0.67 87.20±0.45 86.81±0.51 87.10±0.32
waveform 75.52±0.72 77.61±0.87 78.32±0.45 80.67±0.7
Combiner strategy based on the feature voting
customer 69.10 ±0.63 73.43 ±0.72 75.35 ±0.53 77.20 ±0.49
adult 88.90 ±0.41 87.45 ±0.31 91.13 ±0.23 91.58 ±0.41
waveform 80.12 ±1.03 82.46 ±0.98 85.04±0.73 83.84±0.64
local level has been carried out and the global clas-
sifier has been computed by the combiner strategy
based on the feature voting.
Table 2: Compression ratio versus the number of distributed
data sources.
number of distributed data sources
Problem 2 3 4 5
C
D
192.9 124.1 100.5 88.2
customer C
A
1.9 1.6 1.8 1.6
C 357.9 196.0 177.3 140.4
C
D
79.6 68.0 60.7 52.7
adult C
A
1.2 1.4 1.3 1.2
C 98.6 98.2 81.0 62.5
C
D
56.5 51.8 46.7 39.7
waveform C
A
1.3 1.4 1.2 1.3
C 71.0 73.2 56.0 52.1
It should be noted that data reduction in two di-
mensions (selection of reference instances and fea-
ture selection) assures better results in comparison to
data reduction only in one dimension i.e. instance
dimension. The approach to learning classifier from
distributed data, based on data reduction at the local
level, produces reasonable to very good results. The
data reduction at the local level resulted in both: a
very good accuracy of classification, better then for
”full dataset” (calculated though pooling at the global
level all instances from local levels), and a very high
data compression rate (see, for example, Table 2).
5 CONCLUSIONS
The paper presents an approach to learning classifiers
from distributed data, based on a data reduction at the
local level. At the global level the combiner classi-
fier with feature selection through majority voting has
been constructed and implemented. Computational
experiment carried out has shown that the proposed
approach can significantly increase classification ac-
curacy as compared with learning classifiers using
centralized data pool. An extensive compression of
the dataset size at the global level and parallel compu-
tations at distributed locations are additional features
increasing the efficiency of the approach.
Computational experiment results confirmed that
the global classifier based on data reduction at the lo-
cal level can produce very good results. However, the
quality of results depends on the choice of strategy
used for constructing the combiner.
Future work will focus on evaluating other com-
biner classifier strategies in terms of classification ac-
curacy and computation costs.
ACKNOWLEDGEMENTS
This research has been supported by the Polish Min-
istry of Science and Higher Education with grant for
years 2008-2010.
REFERENCES
Asuncion, A., Newman, D.J. (2007).
UCI Machine Learning Repository
(http://www.ics.uci.edu/ mlearn/MLRepository.html).
ICAART 2009 - International Conference on Agents and Artificial Intelligence
202

Irvine, CA: University of California, School of
Information and Computer Science.
Czarnowski, I., Je¸drzejowicz, P. (2004) An approach to
instance reduction in supervised learning. In: Co-
enen F., Preece A. and Macintosh A. (Eds.), Research
and Development in Intelligent Systems XX, Proc. of
AI2003, the Twenty-third SGAI International Confer-
ence on Innovative Techniques and Applications of
Artificial Intelligence, Springer-Verlag London Lim-
ited, 267-282.
Czarnowski, I., Je¸drzejowicz, P., Wierzbowska, I. (2008a)
An A-Team Approach to Learning Classifiers from
Distributed Data Sources. In: Ngoc Thanh Nguyen,
Geun Sik Jo, Robert J. Howlett,an Lakhmi C. Jain
(Eds.), KES-AMSTA 2008, Lecture Notes in Com-
puter Science, LNAI 4953, Springer-Verlag Berlin
Heidelberg, 536-546
Czarnowski, I., Je¸drzejowicz, P. (2008b) Data Reduction
Algorithm for Machine Learning and Data Mining.
In: Nguyen N.T. et al. (eds) IEA/AIE 2008, Lecture
Notes in Computer Science, LNAI 5027, Springer-
Verlag Berlin Heidelberg, 276-285.
Dash, M., & Liu H. (1997). Feature selection for classifica-
tion. Intelligence Data Analysis 1(3), 131-156.
Kargupta, H., Byung-Hoon Park, Daryl Hershberger, &
Johnson, E. (1999). Collective Data Mining: A New
Perspective Toward Distributed Data Analysis. In Kar-
gupta H and Chan P (Eds.), Advances in Distributed
Data Mining. AAAI/MIT Press, 133-184.
Liu, H., Lu, H., & Yao, J. (1998). Identifying Relevant
Databases for Multidatabase Mining. In Proceedings
of Pacific-Asia Conference on Knowledge Discovery
and Data Mining, 210-221.
Prodromidis, A., Chan, P.K., & Stolfo, S.J. (2000). Meta-
learning in Distributed Data Mining Systems: Issues
and Approaches. In H. Kargupta and P. Chan (Eds.)
Advances in Distributed and Parallel Knowledge Dis-
covery, AAAI/MIT Press, Chapter 3.
Raman, B., & Ioerger, T.R. (2003). Enhancing learning us-
ing feature and example selection. Journal of Machine
Learning Research (in press)
Rozsypal, A., & Kubat, M. (2003). Selecting Representa-
tive Examples and Attributes by a Genetic Algorithm.
Intelligent Data Analysis, 7(4), 291-304.
Quinlan, J.R. (1993). C4.5: programs for machine learning.
Morgan Kaufmann, SanMateo, CA.
Skalak, D.B. (1994). Prototype and Feature Selection by
Sampling and Random Mutation Hill Climbing Algo-
rithm. Procciding of the International Conference on
Machine Learning, 293-301.
Stolfo, S., Prodromidis, A.L., Tselepis, S., Lee, W., & Fan.
D.W. (1997). JAM: Java Agents for Meta-Learning
over Distributed Databases. In Proceedings of the 3rd
International Conference on Knowledge Discovery
and Data Mining, Newport Beach, CA, AAAI Press,
74-81.
Talukdar, S., Baerentzen, L., Gove, A., & P. de Souza
(1996). Asynchronous Teams: Co-operation Schemes
for Autonomous. Computer-Based Agents, Technical
Report EDRC 18-59-96, Carnegie Mellon University,
Pittsburgh.
The European Network of Excellence on Intelligence Tech-
nologies for Smart Adaptive Systems (EUNITE) -
EUNITE World Competition in domain of Intelligent
Technologies (2002). Accesed on 1 September 2002
from http://neuron.tuke.sk/competition2.
Tsoumakas, G., Angelis, L., & Vlahavas, I. (2004). Cluster-
ing Classifiers for Knowledge Discovery from Phys-
ical Distributed Database. Data & Knowledge Engi-
neering, 49(3), 223-242.
Xiao-Feng Zhang, Chank-Man Lam, & William K. Che-
ung (2004). Mining Local Data Sources For Learn-
ing Global Cluster Model Via Local Model Exchange.
IEEE Intelligence Informatics Bulletine, Vol. 4, No. 2.
Vucetic, S., & Obradovic, Z. (2000). Performance Con-
trolled Data Reduction for Knowledge Discovery in
Distributed Databases, Procciding of the Pacific-Asia
Conference on Knowledge Discovery and Data Min-
ing, 29-39.
DISTRIBUTED LEARNING ALGORITHM BASED ON DATA REDUCTION
203
