
CONCEPTS IN ACTION: PERFORMANCE STUDY OF AGENTS
LEARNING ONTOLOGY CONCEPTS FROM PEER AGENTS
Leila Safari
1
, Mohsen Afsharchi
1
and Behrouz H. Far
2
1
Department of Electrical and Computer Engineering,University of Zanjan, Zanjan, Iran
2
Department of Electrical and Computer Engineering, University of Calgary, Calgary, Canada
Keywords:
Ontology, Concept learning, Multi-agent communication.
Abstract:
The ability to share knowledge is a necessity for agents in order to achieve both group and individual goals. To
grant this ability many researchers have assumed to not only establish a common language among agents but
a complete common understanding of all the concepts the agents communicate about. But these assumptions
are often too strong or unrealistic. In this paper we present a comprehensive study of performance of agents
learning ontology concepts from peer agents. Our methodology allows agents that are not sharing a common
ontology to establish common grounds on concepts known only to some of them, when these common grounds
are needed by learning the concepts. Although the concepts learned by an agent are only compromises among
the views of the other agents, the method nevertheless enhances the autonomy of agents using it substantially.
The experimental evaluation shows that the learner agent performs better than or close to teacher agents when
it is tested against the objects from the whole world.
1 INTRODUCTION
In many situations efficient communication is the
main cornerstone of cooperation among agents.
While communication does not always have to in-
volve the use of a language, for many purposes utiliz-
ing a language is a very convenience way to convey
information between agents. In addition to this com-
mon language, a common semantics is also necessary
for communicative agents to interact and understand
each other. Ontology research community tries to ad-
dress issues arisen from violation or relaxation of any
of the above two requirements (Gruber, 1991).
For the sake of simplicity and/or convenience
many researchers in their works have assumed that
it is possible to establish a common language among
agents (e.g., using several variations of agent commu-
nication languages, ACL), and also the agents are pro-
vided with a complete common understanding of all
the concepts they need (e.g., having a common con-
ceptualization). In case that heterogeneity or interop-
erability is a requirement, many researchers assume
that it is possible to have an already existing common
ontology for the agents and that the agent developers
can use this common ontology when designing their
agents, perhaps by calling an ontology service, thus
allowing for easy communication and understanding
among the agents. However, the assumption of ex-
istence of a common ontology is often too strong or
unrealistic. For many application domains, there is
no agreement on ontology for the domain among de-
velopers. Also for many areas existing ontologies are
large, unwieldy and encompass more than what a par-
ticular agent will ever need.
A recent approach is to let the agent have their in-
dividualized ontologies and provide them with learn-
ing mechanisms to learn the concepts they need dur-
ing communication (Williams, 2004) (Steels, 1998).
In our previous work, we have devised a methodology
for having agents learn concepts from several peer
agents (M. Afsharchi and Denzinger, 2006). The ba-
sic idea behind our method is to have an agent, that
realizes that there seems to be a concept it does not
currently know of but expects to need to know, so
queries the other agents about this concept by provid-
ing features (and their values) or examples the agent
thinks are associated with the concept. The queried
agents provide the agent with positive and negative
examples from their understanding of their concepts
(i.e. concepts known by them) which seem to fit the
query which allows the learning agent to use one of
the known concept learning techniques from machine
learning to learn the concept. To help focus on the
negative examples, the teaching agents make use of
526
Safari L., Afsharchi M. and Far B. (2009).
CONCEPTS IN ACTION: PERFORMANCE STUDY OF AGENTS LEARNING ONTOLOGY CONCEPTS FROM PEER AGENTS.
In Proceedings of the International Conference on Agents and Artificial Intelligence, pages 526-532
DOI: 10.5220/0001662605260532
Copyright
c
SciTePress

selected relations between concepts from their ontolo-
gies. The agent that wants to learn the concept deals
with the fact that the other agents in this group might
not totally agree on which examples fit the concept
and which not, by letting the teaching agents vote on
the examples for which it got contradictory informa-
tion in the first place.
The work by Williams (Williams, 2004) intro-
duced the idea of using learning to improve the
mutual understanding about a concept between two
agents. In contrast to our method, Williams agents
uses only a flat repository of concepts and are not in-
volved in a multi agent learning .(Sandip. Sen, 2002)
presents a method of how one agent can train another
agent to recognize a concept by providing selected
positive training examples. The multi-agent dimen-
sion is not addressed and no usage of ontologies is
made. Steels (Steels, 1998), like us, allows for dif-
ferences in ontologies of agents and wants to min-
imize these differences for concepts that are of in-
terest to some of his agents. In contrast to us, his
agents do not use learning to allow for teaching a
concept to an agent. (J. v. Diggelen et al., 2006)
developed ANEMONE which is an minimal ontol-
ogy negotiation environment. A very important point
about ANEMONE is that it is not a concept learn-
ing environment, rather it is an environment which
facilitates ontology mapping between two agents in
a minimal way using a layered approach. Like other
related works, ANEMONE does not talk about fea-
ture diversity and it is not a multi-agent collaboration.
Apart from these works which are directly related to
our work, there are many others in different disci-
plines(e.g. Semantic Web) which we have extensively
reviewed in(M.Afsharchi, 2007).
In this paper, as an extension to(M. Afsharchi and
Denzinger, 2006), we present a comprehensive per-
formance study of the learner agent. We compare
the classification accuracy of the learner with teacher
agents against the set of all objects in the agents’
world. The experiments show that the learner perform
better than or close to the teachers in a multi-agent en-
vironment.
The structure of this paper is as follows: in Sec-
tion 2 we give definitions for the concepts that we use
throughout this paper. In Section 3 the concept learn-
ing mechanism is reviewed, Section 4 introduces our
experimental domain and is followed by our experi-
mental results.
2 BASIC DEFINITIONS
In this section, we provide a brief definition of each of
the two basic concepts involved in our system which
are ontologies and agents. Also we provide the in-
stantiations of these concepts that we require for our
methods.
2.1 Ontologies and Concepts
A formal definition for ontology has been presented
in (Stumme, 2002) in which an ontology has been de-
fined as a structure O := (C, ≤
C
, R, σ, ≤
R
). C and R
are two disjoint sets with members of C being called
concept identifiers and members of R are relation
identifiers. ≤
C
is a partial order on C called concept
hierarchy or taxonomy and ≤
R
is a partial order on R,
named relation hierarchy.
σ : R → C
+
is a function providing the argument
concepts for a relation such that |σ(r
1
)| = |σ(r
2
)| for
every r
1
, r
2
∈ R with r
1
≤
R
r
2
and for every projec-
tion π
i
(1 ≤ i ≤ |σ(r
1
)|) of the vectors σ(r
1
) and σ(r
2
)
we have π
i
(σ(r
1
)) ≤
C
π
i
(σ(r
2
)). If c
1
≤
C
c
2
for c
1
,
c
2
∈ C, then c
1
is called a subconcept of c
2
and c
2
is a
superconcept of c
1
. Obviously, the relation ≤
C
is sup-
posed to be connected with how concepts are defined.
In the literature, taxonomies are often built using the
subset relation, i.e. we have
c
i
≤
C
c
j
iff for all o ∈ c
i
we have o ∈ c
j
.
This definition of ≤
C
produces a partial order on C
as defined above and we will use this definition in the
following for the ontologies that our agents use.
Concepts often are seen as collections of objects
that share certain feature instantiations. In this work,
for an ontology O we assume that we have a set of
features F = { f
1
, ..., f
n
} and for each feature f
i
we
have its domain D
i
= {v
i1
, ..., v
im
i
} that defines the
possible values the feature can have. Then an ob-
ject o = ([ f
1
= v
1
], ..., [ f
n
= v
n
]) is characterized by
its values for each of the features (often one feature is
the identifying name of an object and then each object
has a unique feature combination). By U we denote
the set of all (possible) objects. In machine learning,
often every subset of U is considered as a concept. In
this work we want to be able to characterize a concept
by using feature values. Therefore, a symbolic con-
cept c
k
is denoted by c
k
([ f
1
= V
1
], ..., [ f
n
= V
n
]) where
V
i
= {v
′
i1
, ..., v
′
ij
i
} ⊆ D
i
(if V
i
= D
i
then we often omit
the entry for f
i
). An object o = ([ f
1
= v
1
], ..., [ f
n
=
v
n
]) is covered by a concept c
k
, if for all i we have
v
i
∈ V
i
. In an ontology according to the definition
above, we assign a concept identifier to each symbolic
concept that we want to represent in our ontology.
CONCEPTS IN ACTION: PERFORMANCE STUDY OF AGENTS LEARNING ONTOLOGY CONCEPTS FROM
PEER AGENTS
527

2.2 Agents
A general definition that can be instantiated to most
of the views of agents in literature sees an agent A g
as a quadruple A g = (Sit,Act,Dat, f
Ag
). Sit is a set of
situations the agent can be in, the representation of a
situation naturally depending on the agent’s sensory
capabilities, Act is the set of actions that A g can per-
form and Dat is the set of possible values that A g’s
internal data areas can have. In order to determine
its next action, A g uses f
Ag
: Sit × Dat → Act applied
to the current situation and the current values of its
internal data areas.
As we want to focus on the knowledge represen-
tation used by agents and how this is used for com-
munication, we have to look more closely at Dat. We
assume that every element of Dat of an agent A g con-
tains an ontology area O
Ag
that represents the agent’s
view and knowledge of concepts. There might be ad-
ditional data, beyond features, that the agent requires
from time to time, about concepts and this data is nat-
urally also represented in Dat. Also, there will be
additional data areas representing information about
the agent itself, knowledge about other agents and the
world that the designer of the agent may want to be
represented differently than in O
Ag
.
3 LEARNING CONCEPTS FROM
SEVERAL TEACHERS
In this section we provide a brief description of the
multi-agent concept learning we presented in (M. Af-
sharchi and Denzinger, 2006). As already stated, we
have developed a method that demonstrates how an
agent can learn new concepts for its ontology with the
help of several other agents. This assumes that not all
agents have the same ontology. We additionally as-
sume that there are only some base features F
base
⊆ F
that are known and can be recognized by all agents
and that there are only some base symbolic concepts
C
base
that are known to all agents by name, their fea-
ture values for the base features and the objects that
are covered by them. Outside of this common knowl-
edge, individual agents may come with additional fea-
tures they can recognize and additional concepts they
know. Given this setting, agents will develop prob-
lems in working together, since the common grounds
for communication are not always there. To come up
with a solution for this problem, agents need to ac-
quire the concepts outside of C
base
that other agents
have, at least those concepts that are needed to estab-
lish the necessary communication to work together on
a given task. The basic idea is to have an agent learn a
required concept (or at least a good approximation of
it) with the help of the other agents acting as teachers.
3.1 The General Interaction Scheme
In the following, A g
L
refers to the agent that wants to
learn a newconcept and the other agents, A g
1
,...,A g
m
,
will be its teachers. A g
L
has an ontology O
L
=
(C
L
,≤
C
,R
L
,σ
L
,≤
R
L
) and knows a set of features F
L
.
Analogously, A g
i
has as ontology O
i
= (C
i
,≤
C
,R
i
,
σ
i
, ≤
R
i
) and knows a set of features F
i
. For a con-
cept c known to the agent A g
i
, this agent has in its
data areas a set pex
c
i
⊆ U of positive examples for
c that it can use to teach c to another agent. Parts
of Act
L
are actions
QueryConcept
,
AskClassify
,
Learn
, and
Integrate
, while part of the Act
i
s are the
actions
FindConcept
,
CreateNegEx
,
ReplyQuery
,
ClassifyEx
and
ReplyClass
. For teaching A g
L
a new concept c
goal
, we have as general interaction
scheme:
After becoming aware that there is a concept that
it needs to learn, A g
L
performs the action:
QueryConcept
(identifier,{[ f
′
1
= V
′
1
],...,[ f
′
l
=
V
′
l
]},O
goal
).
The three parameters of
QueryConcept
allow for
three different ways to identify to the teachers what
A g
L
is interested in. The parameter identifier allows
A g
L
to refer to a concept name it observed from other
agents, which means that identifier is an element of
C
i
for some agent(s) A g
i
. By {[ f
′
1
= V
′
1
],...,[ f
′
l
= V
′
l
]},
A g
L
can use a selection of features f
′
j
∈ F
base
and the
valuesV
′
j
⊆ D
f
′
i
that A g
L
thinks are related to the con-
cept c
goal
. Finally, O
goal
⊆ U is a set of objects that
A g
L
thinks are covered by c
goal
.
Each A g
i
then reacts to A g
L
’s query by perform-
ing:
FindConcept
(identifier,{[ f
′
1
= V
′
1
],...,[ f
′
l
= V
′
l
]},
O
goal
).
Naturally, each of the parameters can already point to
different concepts that an agent A g
i
knows of. In fact,
if A g
L
provides several objects in O
goal
, they might
be classified by A g
i
into several of its concepts. So,
A g
i
first collects all the concepts that fulfill the query
into a candidate set C
cand
i
and then it has to evaluate
all these concepts to determine the concept that is the
best fit. So, the output of
FindConcept
is a set of can-
didate concepts C
cand
i
. To select the “best” candidate
c
i
out of C
cand
i
, there are many different ways how an
evaluation of the candidates can be performed. Each
of the 3 query parts can contribute to a measure that
defines what is “best”, but how these contributionsare
combined can be realized differently.
ICAART 2009 - International Conference on Agents and Artificial Intelligence
528

The number of examples communicated to A g
L
by each agent is a parameter of our system. So, in the
next step, each teacher selects the given number of el-
ements out of the set of positive examples, pex
c
i
i
, for
the best candidate concept c
i
and we call this set p
i
.
Again, there are many possible ways how this selec-
tion process can be done, so far we used random sam-
pling of pex
c
i
i
. By then performing
CreateNegEx
(c
i
),
the teacher agents produce a given number of (good)
negative examples for c
i
, which produces the set n
i
.
Since every concept c
j
other than c
i
(and its subcon-
cepts) can be categorized as a counter concept, the
number of objects associated with these c
j
s (which
naturally are negative examples) is often very high.
We used both taxonomy information (siblings of
c
i
) and a relation
is-similar-to
(similar concepts to
c
i
) to select the concepts from which we randomly
selected examples as elements for n
i
.
ReplyQuery
(c
i
,p
i
,n
i
) is the last action performed
by a teacher agent before the initiative goes back to
the learner. It sends the result back to the learner.
A g
L
collects the answers (c
i
,p
i
,n
i
) from all teachers,
pex
c
goal
= ∪
m
i=1
p
i
and nex
c
goal
= ∪
m
i=1
n
i
, and then uses
a concept learner to learn c
goal
from the combined ex-
amples (action
Learn
((p
1
,n
1
),...,(p
m
,n
m
))). Naturally,
the concept learner only uses features and their values
from F
L
.
Learning from a group of agents is a very con-
flict prone process compared to just learning from one
agent. It can easily happen that the best concepts c
i
and c
j
that A g
i
and A g
j
identified are not the same.
The worst case can be that an example that A g
i
sent
as being positive for c
goal
A g
j
sent as a negative one.
But we can also have more indirect conflicts where
a learning algorithm simply cannot come up with a
concept description that covers all objects in pex
c
goal
while not including any objects in nex
c
goal
. There are
several methods how we can solve this problem and
these methods represent different degrees of willing-
ness to satisfy the teacher agents (by A g
L
).
For our system, we have chosen the following
conflict resolution to produce c
goal
for A g
L
. After the
learning component of A g
L
has performed
Learn
and
produced a more precise c
goal
, A g
L
will test all ele-
ments of pex
c
goal
and nex
c
goal
for correct classification
by this new c
goal
. For all the example objects that
are not correctly classified, we go back to the teacher
agents and ask them to classify these examples ac-
cording to the c
i
they used to produce their examples.
We then treat the answers as votes and include all pos-
itive examples for which a majority of the teachers
voted, while requiring the exclusion of all negative
examples for which a majority voted. This produces
some kind of compromise concept that might appeal
to most of the teachers (although it might not be iden-
tical to any of the c
i
).
The result of this learning/teaching scheme is
the description of c
goal
in terms of A g
L
’s feature
set F
L
and an updated ontology O
new
L
= (C
new
L
, ≤
C
, R
L
, σ
L
, ≤
R
L
).
4 EXPERIMENTAL RESULTS
To study the performance of the learner agent, we
have chosen the course catalog ontology domain (see
(Il0, )). In the following, we will first introduce
this domain and then based on our basic setup from
(M. Afsharchi and Denzinger, 2006) we manage our
learner agent to learn 3 different concepts. Then we
evaluate the performance of the learner agent regard-
ing these newly learned concepts.
4.1 The University Units and Courses
Domain
The university units and courses domain consists of
files describing the courses offered by Cornell Uni-
versity, the University of Washington and the Univer-
sity of Michigan, together with ontologies for each of
the three universities describing their organizational
structure (see (Il0, ) and (Um0, )). In our exam-
ples, each of the three universities is represented by
an agent (A g
C
, A g
W
, A g
M
) and these agents are act-
ing on the one hand side as the teachers to an agent
A g
L
and on the other side as the agents A g
L
commu-
nicates with afterwards.
The objects of this domain are the course files that
consist of a course identifier, a plain text course de-
scription and the prerequisites of a course. All in all,
there are 19061 courses among the three universities
and each university’s ontology has at least 166 con-
cepts on top of their courses. The information for
the three universities does not come with the appro-
priate feature values (at least not directly), instead
we only know the taxonomy and for each unit what
courses belong to it. In order to create the ontologies
O
C
, O
W
and O
M
for the agents A g
C
, A g
W
and A g
M
we used the learning method of (M. Sahami, 1997)
to create feature-based descriptions of each concept
(as described in Section 2.1). Naturally, the examples
for the learning algorithm were only taken from the
courses of the particular universityand we used all the
courses as examples to achieve a perfect fit. To cover
exactly the courses of a particular unit, we also had
to adjust the initial key word sets of the agents, but
we were able to keep these sets different between the
CONCEPTS IN ACTION: PERFORMANCE STUDY OF AGENTS LEARNING ONTOLOGY CONCEPTS FROM
PEER AGENTS
529

agents. Also, since no examples from other universi-
ties were used for a particular agent, this agent really
reflects just the view of this university, so that dif-
ferences in the understanding of a concept (i.e. what
should be taught by what unit) between the universi-
ties are preserved.
4.2 Concepts in Action
It is very important to assess the performance of the
learner agent regarding a newly learned concept. As
stated before our main concern in this paper is to
have agents learn concepts to improve communica-
tion. Needless to say, to communicate about a con-
cept, an agent must distinguish an instance of the
concept (i.e.an object) from other instances. Based
on this fact, we conducted an experiment to see how
A g
L
classifies objects in U (i.e the set of all possi-
ble objects) when it learns a new concept. Also we
have chosen the set of examples which the majority
of agents vote for, to be learned by A g
L
.
First we enabled A g
L
to learn three different con-
cepts
Greek
,
Computer Science
and
Mathematics
.
We allowed A g
L
to use the most popular way of rely-
ing on a group decision which is to follow the major-
ity of votes as the representative examples of the con-
cept. Then we trained the learner using different per-
centages of positive examples in this area (i.e. Table 1
n% column). These percentages show us the classifi-
cation accuracy of A g
L
when the learner does not uti-
lize the maximum number of available examples from
the teachers. That is the case when due to the commu-
nication cost, the teachers could not send every possi-
ble example that they possess to the learner. Table 1
shows the classification results of the learner for the
three different concepts. In fact this table shows the
number of correctly classified examples both for pos-
itive examples and negative examples in two separate
columns. We should mention that, when we consider
the examples that a majority of agents agreed upon
as the boundary for the concept in the learner, every
other examples will be tested as the negative exam-
ples by A g
L
in the testing process. For instance and
for concept
Mathematics
, the majority set has 501
positive examples and the other objects (i.e 19061-
501=18560) could be considered as negative exam-
ples for it.
One interesting preliminary result, that in fact we
expected, was the significant increase of correctly
classified examples when the concept is mostly unan-
imous. For example the programs
Mathematics
and
Greek
have more common courses than
Computer
Science
among three different universities (which
also is very true among other universities). As Ta-
ble 1 shows the accuracy result for
Mathematics
is
much better than
Computer Science
. The last row
of Table 1 shows the performance of the learner when
it is trained by the whole set of examples it pos-
sess for each concept. For instance, the second and
third columns show that A g
L
classified 497 positive
and 17324 negative examples out of 501 positive and
18560 negative examples respectively. Therefore A g
L
classified 93% ((497+17324)/(501+18560)) of ob-
jects correctly for
Mathematics
while this accuracy
is 81% ((429+15104)/(505+18556)) for
Computer
Science
and 90% ((170+16991)/(171+18890)) for
Greek
. There is a small “dip” in
Greek
when A g
L
is
trained by 70% of examples when the accuracy jumps
to 91% and then comes back to 90%. Despite this
”dip” the learner shows a consistent behavior clas-
sifying positive examples. We conclude that having
agents with close viewpoints helps the learner to have
a concrete understanding of a concept which naturally
leads to a learner with better performance.
To compare the performance of A g
L
with the
teacher agents we had to compare the classification
capability of A g
L
with A g
W
, A g
C
, and A g
M
respec-
tively. As we discussed earlier, we assume that the
teacher agents have learned the concepts in their on-
tology before they start to teach a concept to the
learner. This learning has been achieved using some
supervised inductive learning mechanisms and using
the example objects that in each agent are associated
with every concept in its ontology. Therefore we are
supposed to simply compare the classification effi-
ciency of A g
L
with A g
W
, A g
C
, and A g
M
.
Nevertheless we can not guarantee that A g
L
learns
a concept using the same number of examples as each
teacher agent and ,obviously,the more examples are
provided to the agent the better a classifier it can
learn. This possibility causes an unbalanced situa-
tion in which A g
L
and other agents can not be com-
pared. To overcome this problem, we have to prepare
a fair situation in which the learner agent classifica-
tion efficiency could be compared with each teacher
agent. Therefore we selected a fragment of positive
examples in A g
L
which is quantitatively equal to the
number of positive examples in each teacher agent to
train A g
L
with the same number of examples that the
teacher agents utilized to learn the concept before.
Table 2, 3 and 4 show the results of comparisons
of A g
L
with A g
M
, A g
W
and A g
C
respectively. The
second column in each table shows the number of cor-
rectly classified examples, both positive and negative,
out of 19061 test examples (i.e. objects in U ) by
A g
L
. The third column shows the number of cor-
rectly classified examples by the teacher agent and
finally the forth row shows the percentage of exam-
ICAART 2009 - International Conference on Agents and Artificial Intelligence
530
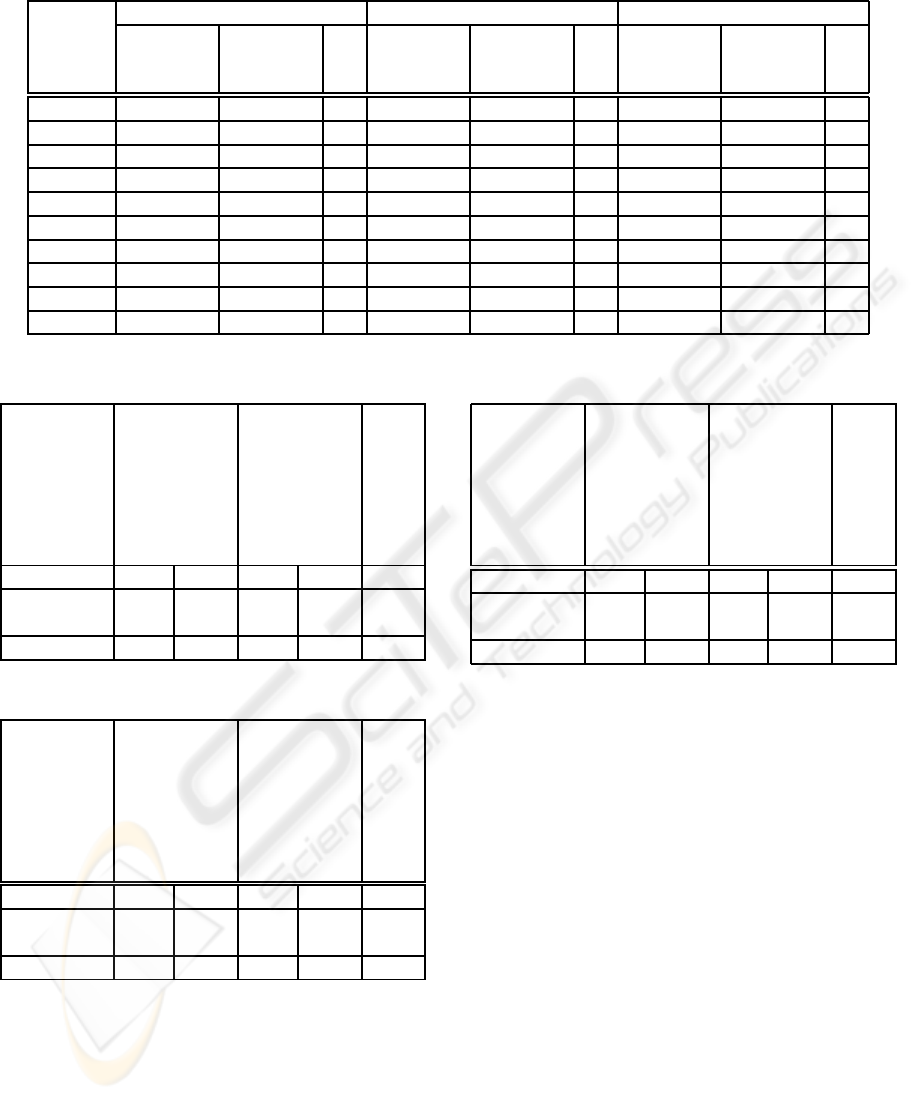
Table 1: Correctly classified examples for concepts
Mathematics
,
Computer Science
and
Greek
.
n% Mathematics Computer Science Greek
Positive
Out of
501
Negative
Out of
18560
% Positive
Out of
505
Negative
Out of
18556
% Positive
Out of
171
Negative
Out of
18890
%
10 400 13125 70 324 11375 61 128 13906 74
20 458 14157 77 339 11934 64 134 14551 76
30 460 15290 82 346 12307 66 142 14958 79
40 472 15267 82 354 12494 67 154 15681 83
50 481 15358 83 367 13053 70 159 16254 86
60 485 15501 83 380 13426 72 163 16808 89
70 484 15691 84 391 13613 73 165 17193 91
80 489 15886 85 399 14172 76 167 17005 90
90 495 16765 90 423 14731 79 170 16995 90
100 497 17324 93 429 15104 81 170 16991 90
Table 2: Comparison of the performance of A g
L
and A g
M
.
concepts correctly
classified
examples
by A g
L
correctly
classified
examples
by A g
M
%
of
ex-
am-
ple
from
A g
L
Mathematics 15859 83.2% 15886 83.3% 53%
Computer
Science
12962 68.0% 11009 57.7% 43%
Greek 17011 89.2% 16719 87.7% 68%
Table 3: Comparision of the performance of A g
L
and A g
W
.
concepts correctly
classified
examples
by A g
L
correctly
classified
examples
by A g
W
%
of
ex-
am-
ple
from
A g
L
Mathematics 15780 82.7% 15756 82.6% 44%
Computer
Science
12533 65.7% 11788 61.8% 28%
Greek 15492 81.2% 15121 79.3% 35%
ples that A g
L
has been trained with, to produce this
result. For instance the first row of Table 2 shows
that A g
L
has correctly classified 15859 examples out
of 19061 when it is trained by 53% of the whole set
of its positive examples for
Mathematics
. The third
column indicates that 15886 example objects are cor-
rectly classified by A g
M
. The last column indicates
that the number of associated examples with concept
Mathematics
in A g
M
is 53% of examples in A g
L
.
Table 4: Comparision of the performance of A g
L
and A g
C
.
concepts correctly
classified
examples
by A g
L
correctly
classified
examples
by A g
C
%
of
ex-
am-
ple
from
A g
L
Mathematics 15163 79.5% 15086 79.1% 26%
Computer
Science
12805 67.1% 12112 63.5% 39%
Greek 14894 78.1% 14597 76.5% 24%
A very interesting outcome of this experiment is that
A g
L
in the most cases has a better performance than
the teachers regarding to the learned concept.This em-
phasizes on the fact that A g
L
learns the compromise
concept and its learning reflects a mutual viewpoint of
agents. Therefore it will perform better when it tests
against the objects from the whole world.
As an example concept, if we look at the
Computer Science
we see that A g
L
is doing better
compared to the other agents. For instance its ac-
curacy is 68% (12962/19061) when it is trained by
43% of the training examples(see table 2). Clearly
this is a better performance than A g
M
which has clas-
sified 57.7% (11009/19061) correctly. Here we see
that A g
L
classifies 10.3% better than A g
M
while this
margin is 3.9% for A g
W
and 3.6% for A g
C
. We be-
lieve that this is because the viewpoint of the learner is
closer to A g
W
and A g
C
and the compromise concept
in A g
L
does not have too much of the characteristics
of
Computer Science
from A g
M
. Therefore A g
L
is
doing much better in classifying objects from U .
The story is different for
Mathematics
. The per-
formance of the A g
L
is worse than A g
M
(i.e. 83.2% vs
CONCEPTS IN ACTION: PERFORMANCE STUDY OF AGENTS LEARNING ONTOLOGY CONCEPTS FROM
PEER AGENTS
531

83.3%) but it is better than A g
W
(i.e. 82.7% vs 82.6%)
and A g
C
(i.e. 79.5% vs 79.1%) . This observation
shows that the performance of the learner is close to
the performance of other agents and that is because
Mathematics
is more unanimous than
Computer
Science
which makes the viewpoints close to each
other.
REFERENCES
Illinois semantic integration archive.
http://anhai.cs.uiuc.edu/archive/. As seen on Sep
20, 2006.
University of michigan academic units.
http://www.umich.edu/units.php. As seen on
Sep 20, 2006.
Gruber, T. R. (1991). The role of common ontology in
achieving sharable, reusable knowledge bases. In Pro-
ceedings of the Second Iniernanonal Conference on
Principles of Knowledge Representation and Reason-
ing, pages 601–602.
J. v. Diggelen, R. B., Dignum, F., van Eijk, R. M., and
Meyer, J. (2006). ANEMONE: An effective minimal
ontology negotiation environment. pages 899–906.
M. Afsharchi, B. F. and Denzinger, J. (2006). Ontology-
guided learning to improve communication between
groups of agents. In Proceedings of the Fifth Interna-
tional Conference on Autonomous Agents and Multi-
agent Systems (AAMAS06), pages 923–930.
M. Sahami, D. K. (1997). Hierarchically classifying docu-
ments using very fewwords. In Proceedings of ICML-
97, pages 170–178.
M.Afsharchi (2007). Ontology guided collaborative con-
cept learning in multi-agent systems. PhD Disser-
tation, Department of Electrical and Computer Engi-
neering, University of Calgary.
Sandip. Sen, P. (2002). Sharing a concept. In (AAAI Tech
Report SS-02-02).
Steels, L. (1998). The Origins of Ontologies and com-
munication conventions in multi-agent systems. Au-
tonomous Agents and Multi-Agent Systems, 1(2):169–
194.
Stumme, G. (2002). Using ontologies and formal con-
cept analysis for organizing business knowledge. In
Wissensmanagement mit Referenzmodellen - Konzepte
fr die Anwendungssystem- und Organisationsgestal-
tung, pages 163–174.
Williams, A. B. (2004). Learning to share meaning in a
multi-agent system. Autonomous Agents and Multi-
Agent Systems, 8(2):165–193.
ICAART 2009 - International Conference on Agents and Artificial Intelligence
532
